
CHAPTER 8
![]()
Release Management
The very nature of a database system is to be dynamic, rarely static. The applications that use databases tend to change, thus requiring changes within the associated databases. The totality of pieces and parts that comprise this “change” will be combined into a “release” that will be applied to the system. Controlling this change is not rocket science, but it is not without its complexities. In this chapter, we will discuss various terms, processes, and ideas, and suggest tools to assist you in performing this necessary function, while minimizing risk, and impacting your system in a graceful fashion.
While there are many factors that influence a system, we will specifically discuss changes to databases. There are several concerns that we need to keep in mind as we contemplate making changes in our databases. There is always a risk to making a change to a system. Changes typically will come in the form of newly released features, or fixes to existing features. Assuming that your system is in a preferred state and running as designed, any new changes should, hopefully, be for the best. As we delve into how to create your own release management process, remember that minimizing risk will be the goal of this chapter.
My Release Management Process
The following information has come to you via many years of release process executions, and will impart details learned over a few hundred separate releases, some even being heralded as successful. In the beginning, when I first embarked on this journey of release management, I had no idea what I was doing. I simply knew that changes needed to occur.
I took it upon myself to look at the process as a whole and try to make it better. It was a difficult road, and had many late nights, early mornings, and other frustrations. Having to speak to my company, both within and outside of my department, was a difficult task. Getting them to commit to a process that they didn't understand or care about was even more difficult.
Slowly, we made progress. We started by implementing small changes, such as a rule disallowing adhoc queries. The reasoning behind this was sane, and though it generated frustrations from others, its enforcement was successful. This lead us to the need to wrap our changes into stored procedures that we could introduce into our system, execute, and then drop. This allowed us to minimize human involvement at release time.
Soon, we discovered that we needed many additional steps in the process. Eventually, I started keeping track of everything we did to prepare for a release. This led me to the realization that many of the tasks were unknown to many people, and I was able to share these with others via documentation. Once folks realized how complex a release was, they were more inclined to be open and helpful, especially when I would show them that their release would require hundreds of steps. No more were they shy about being available and helping me out. They learned that their simple request (or so it seemed to them) required multiple people to work many hours to prepare and perform. When they saw the level of documentation that we requested them to review, they suddenly caught the vision. This vision spread and was infectious.
In the beginning, we would hold our breath as we embarked upon a release. Often, we would hold our breath through the entire release. Many of our initial releases failed, had to be rolled back, or had some otherwise undesirable outcome. Soon, through the careful implementation of this release process, we started becoming proficient at not only planning, but also executing the releases. Soon, we could scarcely recall a failed release. Well, that's a bit of an exaggeration. We always remembered the failed releases, but we started putting time between us and them. This experience made us happy, but ever vigilant.
One release, well into our successful period, showed us that even though we had been doing a good job, we were not beyond error. An unforeseen functionality occurred immediately after the release, and the decision to rollback was made. However, in our confidence, we had started skimping on the rollback procedures. In this case, it was left to the release engineer to decide how to rollback, and the choice that was made turned out to be a bad one. Who was at fault? Was it the individual that rolled back in an improper way? No. Was it the developer that released the bad code? No. It was me, the creator of the release plan. Because I had not spent time creating and documenting the rollback process sufficiently, the onus rested upon me. I still feel the sting of this experience, and I use that feeling to remain more diligent.
By sharing such experiences with you, I intend to show you that the release management process isn't a new idea; it has been in practice in various organizations for quite a while. I have continued to perfect and alter this process over time. Each time the process iterates, it gets stronger. It might never be perfect, but as long as the process evolves to meet needs, it will greatly benefit us.
A Change Is Requested
As you can probably guess, a change will eventually be requested in your application and/or database system. How this request comes into existence is not important. The request will come, and it will need to be dealt with. We want to determine the best ways we can deal with them, control them, and gracefully introduce them into our respective systems.
Unfortunately, many release processes might be similar to the one detailed in Figure 8-1. This shows a process that contains very few steps, very few tests, very little verification, and a large chance of failure. Granted, for certain releases, success could be achieved with this simplistic process.

Figure 8-1. A typical (and ineffective) release process
The following basic steps are involved in this minimalistic release process:
- A change is requested.
- T-SQL code is created to support this change.
- T-SQL code is tested.
- T-SQL code is deployed.
![]() Note When we refer to T-SQL code, this could be T-SQL that creates or alters functions, tables, stored procedures, data, and so on.
Note When we refer to T-SQL code, this could be T-SQL that creates or alters functions, tables, stored procedures, data, and so on.
The minimum tasks from the preceding steps could be steps 2 and 4: create and deploy the code. The actual request (step 1) might not come as an official request; it might be received in a variety of unofficial ways. Unfortunately, testing (step 3) does not often occur. This leaves us with only two core tasks transpiring.
Saying this out loud should make you realize that this greatly increases our risk to an unacceptable level. To mitigate this risk, we should apply a series of tasks to a release management process. These tasks need not be cumbersome. We should apply them to our process to simply ensure the safety of our individual systems. It is up to you to find the balance in making sure that your tasks are sufficient, yet not cumbersome. This will take time, and involves creating a flexible process. Add some tasks, take some away. Let's talk about how to get achieve that balance. This is our goal.
Release Process Overview
As we discuss this large topic of release management, there will be many considerations, documents, and tasks that will come to light. In fact, these are the three areas of concentration for the rest of this chapter. We will dig into considerations that you should put at the forefront of your thought. This will help you develop documents that detail tasks. As you read the ideas that follow, please contemplate how you can apply them to your topology and system. Remember that no process is absolutely perfect for everyone, or for every situation. Take those ideas that fit and add them to your release management process. If you do not have a process currently, this chapter will help you create one.
Considerations
While there are many considerations in planning a release management strategy, we will delve into some specific ones and, hopefully, bring to light some of the reasons why you should consider them. Our goal is to create a balanced process that will allow you create your release in a controlled fashion, without negative incidents. As this discussion occurs, please take into account the particulars of your system. The following is an overview of the considerations we will discuss:
- Goals: Define the goals for your release process.
- Environments: Detail your environments, from top to bottom, from development to production.
- Release Process: Define a release process to share with all involved and get their commitment.
- Players Involved: Indicate who will be involved in the process.
- Version Control: Determine a safe place to keep track of your code.
- Rollback Process: Always have a way to revert back to a known state.
Goals
First and foremost, you should detail what your goals are for release management. My goals may differ from yours. Your goals might change as time passes and you might need to alter them with the introduction of new ideas, new managers, and so on. Regardless of what your current goals are, continue to review them, and discuss them with others as you perform your release process. If speed is of vital importance, this will help you streamline your tasks and procedures for your release process. If safety is your goal, other tasks may grow and entwine themselves in your process. Let's minimize the goals down to a few simple ones and further define those terms. I consider the following items to be a core set of goals for my release management process:
- Reduce risk
- Control change
- Perform successful change
- Follow best practices
- Architect/design changes
- Review changes
Reduce Risk
Your system exists and functions for a purpose, so reducing risk to it should be an obvious goal. Not allowing a change to occur that would impact your system is more easily said than done. Keeping it stagnant is not an option, so let's face the inevitable, and attempt to reduce the risk that change will introduce.
We need to take measures to create a process that is molded to each system, with elements borrowed from other iterations of release management processes to find that perfect one that will suit you, protect you, and reduce your risk. As you review code, test your release process, and perform other tasks, always keep in mind that you need to do all tasks with an eye on reducing risk. This doesn't mean that you shouldn't implement change; rather, it attempts to wrap that change into a process that will be graceful, controlled, and successful.
Controll Change
Controlling change simply means that whatever change occurs in your system follows a process that has been vetted, agreed upon, detailed, and documented. In other words, the right people performing the right tasks, in the right order, at the right time. You need to define all this. Others can give you suggestions, even plan out the process for you and with you; however, you will be the ultimate authority on what is actually decided upon. Remember that you are the data professional and it falls to you to ensure your system is secure, available, and properly used.
In order to control this change, you should take the time to understand your entire topology. Understand how data flows in and out. Learn as much as you can about your system. Knowing how your system functions, how it is secured, and how data moves within it will better enable you to control how changes will impact it.
Perform Successful Change
A successful change can be defined as one that was executed as expected, with no negative impact. No exceptions were raised once the change was introduced to your system and there was no unforeseen degradation of system functionality. This does not mean that the change contains flawless code or perfect functionality. We have seen before that functionality can be introduced that is not expected or simply performs differently than expected. A successful change is one that simply introduces a change in a successful manner, requiring no rollback of code to a previous state. Even though the goal is to perform successful change, it behooves you to take the steps necessary to ensure that you include proper testing and a foolproof rollback process. We will discuss this later in this chapter.
Follow Best Practices{“
Determine and document what your best practices will be for releases. You should refer to Microsoft for published best practices (for example, some can be found at http://msdn.microsoft.com/en-us/practices/ff921345). You should also look for best practices in books, blogs, training, and so on. Search out sources that can impart what others believe to be best practices. There are many examples available from which you can pick and tailor those that make sense for your system. You will probably already have some best practices that are alive and well within your organization. Use these practices as well.
Whatever the source, include these rules into your release management process and documentation. Do not be afraid to add to them, or remove from them, as you repeat iterations of your release management process. Always review your process and continually tweak it. When you find something that will help you perform better releases, integrate it into your process.
When you implement best practices, ensuring that these rules are followed is the next logical step. If you choose to go this extra mile, you can include a means to monitor your system to prevent changes that would violate your chosen best practices. Policy Based Management (PBM) is a solution that is available with SQL Server that does just that. PBM allows you to define and enforce policies on your SQL Server systems, thus preventing unwanted changes. This chapter will not delve into how to implement PBM. Homegrown solutions can prevent and track changes as well. Using tools to control change will also help.
Best practices can also be found in various SQL Server books. Joe Celko has written a book called SQL Programming Style (Morgan Kaufmann, 2005) and Louis Davidson has a book called Pro SQL Server 2012 Relational Database Design and Implementation (Apress, 2012). Both these resources will help you find best practices. Look to your managers, teammates, and other coworkers to determine what best practices are already being followed, and find where they can fit into your release process.
Let us assume that you have decided to implement a best practice that prohibits the use of ad-hoc queries in your system. If such a rule exists and all parties agree upon it, then when a review is performed of a proposed release, the code can be kicked back for redesign because it contains ad-hoc queries. This leaves the reviewer out of the mess of explaining why this is a bad thing. It has been agreed upon already, added to your process, and simply becomes a checkmark to look for upon review.
A suggestion that has helped me time and time again is to create stored procedures that actually contain a database change. Let us assume that a change to be released will perform an alter table statement, adding a column to an existing table. This change will be an ALTER TABLE T-SQL statement that adds a column. You can put this code within a stored procedure. The stored procedure can contain code that performs validations. Maybe there should be a validation that checks for the existence of this column, prior to performing the ALTER TABLE statement. After the statement has been performed, you can check for the existence of this column. I would suggest that this entire T-SQL code be wrapped with a transaction, so that the post validation can either commit or roll back your change, based on the validation results. As part of your release, you would create this stored procedure, execute it, and then drop it. When the stored procedure is executed, it will perform the ALTER TABLE command for you.
You can bundle all the changes into a single stored procedure or multiple stored procedures. These stored procedures are what you actually release. Then you execute them, which executes the changes, and finally you drop them. So, they exist for a short period within your environment. They perform a task and are removed. This allows for a controlled change, and will ensure that when executed, they perform their desired tasks only. Saving these scripts into a release storage location will allow you to keep track of these in the future. You could also save these scripts in your favorite source control system. We will discuss this further, later in the chapter.
By executing changes via a controlled method, as previously explained, you will limit the quantity of ad-hoc changes that can be introduced into your system. Once you reach the stage of releasing code changes, you can easily execute the changes via a tool that will perform the executions for you, which further removes the human element from the change process. You would click the button; it would perform all the tasks possible, and commit them or roll back, depending on the result. You could also save the performed steps within a historical collection system. Remember that this is one of our goals.
Other best practices that you might want to include could be naming conventions, transaction levels limiting quantity of data changes, coding a breakout point in automated processes, and so on.
Naming conventions will help your database objects be cleaner and better understood. Well chosen and followed naming conventions will help with navigating and understanding your database. I would venture to say that even a bad standard, as long as it is followed, is better than choosing random standards and following them all simultaneously. Take some time to research the naming conventions that you already have in place, and ensure that going forward you have a documented naming standard and follow it completely.
When changes involve large quantities of data, implementing a cap on how many changes will occur at once, and wrapping this quantity within a transaction, can help speed up the overall process. This is much more efficient than applying all data changes at once and then committing, or worse yet, applying them one at a time. You might need to do some research to find the proper quantity for each large data change. Some data changes might not need a transaction and quantity. You will have to test this out in a nonproduction environment. You can and should ensure that you compare appropriate quantities of data in your testing. Testing a small version of similar data will not help you when you actually perform the change in production.
Some changes might take a long time to perform. While the change is churning on and on, if you had the ability to stop it midstream, gracefully, you could easily halt a potentially long-running process. For example, you could implement a loop that checks a table for a certain value. Then, based on the result of this value, you could continue or halt the change, thereby giving you an out. This is a feature that is not usually implemented in changes. However, you can implement this, and instill a breakpoint in long-running processes or updates.
Architect/Design Changes
The earlier that you can be involved in the change process, the better you will be able to mitigate risk. It's not to say that you are the subject matter expert (SME) in all things database. However, being an expert in this field does allow you the ability to weigh in on decisions early on that could impact the final product. Just as you are the expert in databases, lean on other SMEs in other areas, and ensure that you are all involved in the change process as early on as possible. Take the time necessary to learn as much as you can about your respective systems, and how they interact with data and, especially, with your databases. Be as involved as you can with all things database, and you will be better prepared for a successful release.
You might be hesitant at stepping into this stage of the process. It might seem to you, your managers, and to others that this is not your place or job description. Simply remind yourself and others that you have experience with databases. Remind them all that you are a resource. Get in there. Force yourself in on the development process. Do it gingerly, respectfully, but do it. If you can gain access to this stage of development, you will be armed to impact changes all through the development process and into the actual release period.
Review Changes
It is imperative that each piece of code be reviewed, hopefully by multiple parties, along the route to becoming part of your permanent topology. If you ensure that you and others, with the necessary skills, perform a thorough review of changes, you'll be better armed to reduce risk to your system. It takes time. You must schedule this time. You must take the time necessary that will allow you and others to appropriately review the code, weigh its changes against the entire topology, and proceed accordingly. Even a simple change is a “change” and needs to be given proper attention. The process that you ultimately create will likely have several steps. Even if these steps take little time, make sure you take them, in their respective order, so as to reduce risk.
Don't be afraid to reject code that you feel might negatively impact your system. You will be the one that gets in trouble for it, not the creator of the code. Be firm, but be respectful. Back up your concerns with good information and best practices. Share with others the the agreements you've reached. Let them know that you are simply trying to protect your system, and minimize impact for the entire organization.
Involving others as you review code will be an excellent opportunity for team and cross-team unity. Do not be afraid of letting others help you out and helping others out as well. Peer reviews will let you get more folks involved, more eyes on the code, and many more chances to perfect the code and minimize risk to your system.
Environments
Take the time to detail all vital pieces of your environment that will receive change. This may start at the development layer, and work its way up through many layers of various systems that influence your release management process. As a way to reduce risk, take time to create various testing ground environments through which your code can pass, allowing for various forms of testing, as well as testing of the actual release plan (we will discuss release plans in a bit). Only through properly tested iterations, can we truly reduce risk.
Involve your development group in your discovery and documentation of environments. They might already have various environments in play that allow them to test their changes prior to reaching any other environments. They might also have tools that can help with unit testing. If not, together you need to find such tools and add them to your arsenal. Together, you can discuss the best ways you can determine how to test code in these early stages of change development. You can pull out each new change and test it separately, but make sure you test the completed code as it would behave in a live, production environment.
At a minimum implement a development environment and a testing environment before your actual production environment. Beyond the minimum, implement as many layers as you feel comfortable implementing without adding burden to the process. Ensure that each layer is understood, managed, and controlled. I would suggest that you do not implement an environment that will become a burden, or be skipped, or become out of date and cause problems with your release testing. Each environment needs to provide a playground for you to perform tests within, yet remain valid and viable.
Ensure that no change enters the actual production environment without passing through the lower levels first. Ensure that only properly authorized individuals can access production and push out changes in a controlled manner. In fact, ensure that each layer of environment is secured to only those that should access it. By minimizing the quantity of individuals that have access to your production (and prior) environment, as well as having environments through which validations occur, you will more easily reach the goals we are striving for.
Realize also that this will create tasks for other individuals in your organization besides yourself. You will need to take the time to get their commitment on this process so that it is used, and not just dreamt about. This will take time and force you to show that having these other environments will greatly decrease your risk to change.
Some possible environments to consider are shown in Figure 8-2.
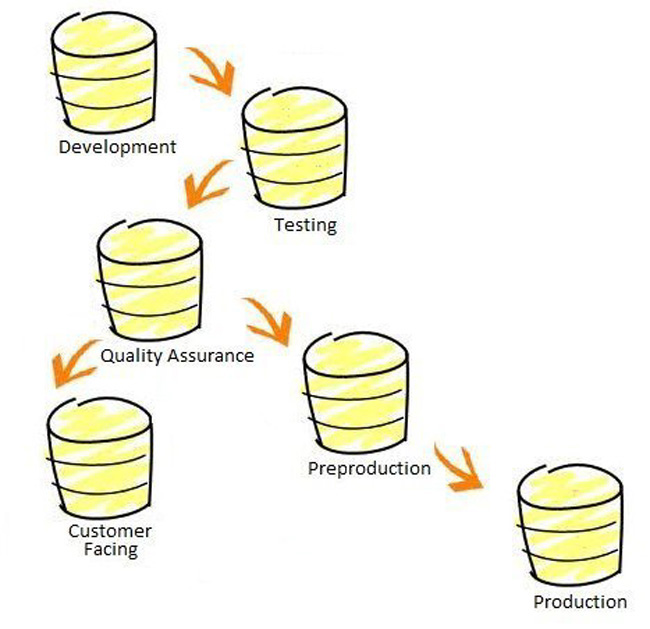
Figure 8-2. Possible database environments
The development environment may be a single environment or multiple environments. This area will be the playground for developers to make changes at their whim. You should ensure that they have sufficient quantities of data to approximate a production environment. Ensure that the development environments match in structure and objects with the production environment. If you have a development environment that has differences in objects, missing indexes, or only small amounts of data, you are setting yourself up for future problems.
The testing environment can be used by development, and even the DBAs that perform the release, to start testing the release plans. This environment, like others, should match production as closely as possible. Performing release plan testing is a vital step that needs to be performed to ensure that the plan you have created is accurate. The environment needs to be valid enough to be a good test for the release plan.
The quality assurance environment will be used primarily by the QA group for their own testing procedures. This environment also needs to match production and provide a decent playground for them to perform valid tests. You may or may not be involved in keeping this environment intact.
A customer facing environment would be used to provide a place where folks outside your company can preview changes. This environment will provide you very valuable data about how others perceive your product. There will be many opportunities for information to be collected about how a small change can affect your system as a whole. You will need to ensure that this environment has very up-to-date data compared to production. Your external users will want this to be as close to production as possible.
The preproduction environment is very similar to the customer facing environment, except that it is internally facing. This environment is the last stage before the change is released into the wild, into production. By this stage, your release plan should have been buttoned down and tested through the other environments. The steps to successfully perform the release will have been put to the test through the various environment releases. This last phase will let you test it one last time, and should include all pieces and parts, including replication, and so on. Do not skimp on this environment. Ensure it matches production in as many ways as you can implement. Having matching hardware and storage can only help you in the minimization of risk while testing your process and the actual release of the change.
The production environment doesn't need an introduction or explanation. This is the goal environment. All the others exist simply to allow you to prepare to push a change out to production.
Release Process
The end goal of this chapter is that you will have created a release process that encompasses the necessary tasks to accomplish our goals of release management. Document this process and know that it will change over time to encompass any future possibilities. It must be rigid and always followed as its design intended. This means that, at any given time, the rules that you have created for this process must be followed. To ensure that all involved know the process, it must be discussed with the proper individuals; it must be accepted and agreed upon by all involved. Keep in mind that this process may change over time. Allowing it to be malleable will help you to improve your process as time marches on and your needs change.
This chapter provides many pieces and parts that you will be able to implement within a process. If you can automate pieces of this process, or even the entire process, you will greatly minimize risk. Humans are fallible. No matter how careful we are, we can make mistakes. As you review your process and as you perform a release, keep a wary eye on each step and make attempts to perfect it. Performing the steps manually initially will help you to understand what is needed to accomplish said task. But as you continue performing these steps, you will see ways to automate them. Automation is your friend, and will minimize risk if performed properly.
An example of automating release steps can be shown when a release involves replication. There will be a few steps to perform replication changes. These changes can be scripted out beforehand and tested in other environments. The actual scripts that you create to perform a step, such as adding an article to a publication, can be encapsulated into a tool and executed when you reach that step of the release plan.
Soon you will see other parts of your release plan that can also be automated.
Players Involved
Because you are not an island, and change processes don't occur within a vacuum, you will need to be involved with multiple people throughout the entire release process. As you are planning your own release process, ensure that you have involved all the appropriate players. In this section, you will find some suggested groups that might need to be involved. Keep in mind that you may involve more than one person from each group.
Meet with the teams and managers that will ultimately be involved with the process. Start with your manager and team, and branch out to the other teams and managers. Get them to commit to this process, get them involved, spread the ownership, and the goals that you are pursuing.
Identify the potential individuals that should be involved from the following list:
- Project managers
- Product managers
- Development
- Quality assurance
- QA engineers
- QA managers
- QA team leads
- QA subject matter experts
- Database administrators (DBAs)
- Development
- Tech ops
- Infrastructure engineers
- Production
- Network engineers
- Storage area network (SAN) engineers
- IT staff
Version Control
If you do not currently have version control to contain a golden copy of your code and database objects, it is strongly suggested that you do so going forward. You should begin implementing a solution to keep different versions of code protected. There are many different ways to implement a comprehensive version control process, depending on your needs. At a minimum, you need to store versions of objects and other T-SQL code externally from your database, so that in the event of a change disrupting your systems, you can revert to the original version of said objects.
An easy way to implement version control is to capture a snapshot of the database schema before and after changes have occurred. If data changes are involved, those changes should be snapshotted as well. Keeping track of these changes before and after a release will also allow you to document what changed and reconcile it with the actual release plan that was created.
You could use PowerShell or SMO to script out objects to files or scripts. Third-party tools are also available, such as Git, Mercurial, SVN, Red Gate's SQL Source Control, and Microsoft's Team Foundation Server, among others. Each of these options affords you the opportunity to collect database objects and store them outside your database.
Keep in mind that the simplest way to perform version control is to create a backup of your database moments before you perform a release. I would suggest that you perform a backup each and every time that you release. Regardless of what version control system you implement or currently have, creating backups prior to a release will give you a failsafe. This process, like all others, should be malleable and allow you to change it from time to time, thus improving the process along the way.
Keeping track of your database objects and data is often difficult, but is worth it.
Rollback Process
Just as you are preparing a process to ensure that your changes occur cleanly, you must be prepared to roll back your changes. Each time that you produce a change, ensure that you have created the proper scripts that will allow you to roll back those changes. You can rely on snapshots prior to a release, version-controlled objects, scripts generated, database backups, among other options.
You may implement a drop command that removes objects that you will be releasing. As mentioned earlier, you can use SMO and PowerShell to generate scripts of objects. You will also notice on most windows in SQL Server Management Studio (SSMS) that you can click on a scripting menu to generate a script of various objects, changes, and so on. You can generate these scripts on the fly via SSMS, and then save them as potential rollback scripts. You might need to create a script that adds or removes data. You must always be prepared to quickly recover your system to a state prior to the beginning of your release process execution.
Even if the change you are to introduce is one that “shouldn't affect anything,” you should still create a rollback process. This means always, no matter how small of a change! You should accompany any change with a rollback process. Realize that you might need to involve other individuals in the creation of the process, or it could simply be you alone. Either way, be involved to ensure that it gets done. Before the release is the best time to have a cool head and plan appropriately. During the stress of a failed release, when your brain is inevitably compromised with emotion, you will be less likely to create a clean and graceful rollback. Do it when your head is clear, when you have the time to interact and get answers to the many questions you might have. I know from experience that in the heat of the moment, it seems that my brain seems less able to think clearly.
Documents
Remembering that the goal is to create a balanced process that will allow you to create releases in a controlled fashion and without incident, we will now go over several documents that you can create and use to reach that goal. These documents will help you with the release process, as well as help you keep track of where you are within the process. Some of these documents will be templates that will quicken your steps to creating a release.
- Release notes
- Release plan template
- Release plan(s)
At a basic level, it is a good idea to keep a simple record of each requested change that is made, and keep a list of tasks associated with your release management process as they are accomplished. Keeping track of these tasks, and the dates performed or reperformed, will allow you to measure the success of the actual release. Collecting this information will help with future releases as well as help fine-tune your release management tasks. Allowing your process to change and refine will ensure that you create a successful release management process, filled with appropriate tasks.
Two documents that will help out are a release notes document and actual release plan documents. The release notes will be a single document that contains summary information about each release, and the tasks associated with said releases. Dates and other information will be gathered and saved within this document to help you plan better for each new release. The actual release plan documents will be created, filled out, tested, and ultimately performed, releasing change to your production environment. As each release is performed, keep track of these pieces of information for future review. As your steps within your release management process change, update future versions of your release plan. It's a good idea to have a template of this release plan on hand, which will receive any changes as you see fit to update it. This template will help you in the creation of each release plan by providing a starting point with much of the information already filled in.
Release Notes
Keep a record of each release request. Keep a record of each date associated with each task you have performed. As you perform a release, and the next release, and the next, you will soon have a document with quite the collection of information. You can use this information to not only remember past releases, but review how they were performed, how many steps were repeated, what steps had a tough time, what steps were not as useful, and even holes in your process where steps are missing. Keeping track of where you are in the process as you prepare to release each change will also be made easy as you keep accurate information in these release notes.
An easy way to accomplish this task is to start an Excel document, similar to that shown in Figure 8-3. This document can continue to grow with each change request that comes in, and will help you keep track of each one along with its tasks.
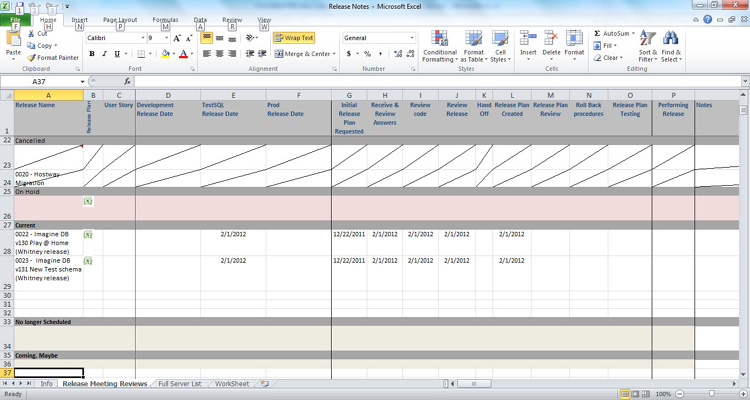
Figure 8-3. Release notes sample document
The information that you can keep track of within these release notes will contain information, tasks, and dates. For example:
Release Name
A release name will be associated with each release. How you name each release will be up to you, but keep in mind that a unique naming convention will assist in keeping track of each individual release.
Release Plan
You should create a document that contains all information and steps to perform the actual release. You will refer to this document as a release plan. Within your release notes, keep a link or reference to this release plan. While you are in the midst of preparing and performing a release, this information will be at your fingertips. When the release has been completed and some time has passed, having this reference will be valuable for your future releases.
Dates Released to Various Environments
Keep track of the dates that the release has been executed in each of your environments. Performing these in order is vital, and keeping track of each of these executions as they occur in the proper order will also help you keep your process in order. Ensure that you do not leapfrog your ordered environments by skipping to another environment before its proper time.
Initial Release Plan Requested
When a change has been requested, log this date in your release notes as the initial date that the release was requested. This will become your starting point. The end goal will be a successful release. You might never release it, which is fine. Keeping track of these dates will help you keep organized and follow your process. When you have received a request for change, at this point you can use a template to create a release plan and start to populate it with the information you are collecting and creating.
Receive and Review Answers
As you prepare the release plan document and fill it with information, and as you review the code that is proposed for change, you will inevitably have questions that need answering. This iterative process can involve many cycles before you and the others involved are satisfied. Allow this cycle to occur, and continue to seek out answers to your questions. Keep track as you traverse each of the iterations, noting the dates associated with the receipt of answers.
Review Code
Ensure that you review the code thoroughly; especially weighing how these changes will impact your system and topology. Each time that you touch the code, keep track of the dates, your observations, your progress, any notes, and any other information that you can gather during this process. Keep this information within your release notes. Share this information with all involved. You might have to plan various meetings between yourself and other individuals involved in the release process. As you collect information, ensure that you reference this information during and after the release process.
Review Release
As you collect all this information, inevitably you will be creating a release plan that has great information, all the moving parts of the release, as well as various steps to perform. Ensure that you review this plan. If possible, perform a dry run of the release plan in another environment to validate the steps. Review these steps with the developers and architects of the change. Review these steps with your teammates and any others involved. Validating that these steps are appropriate will ensure that your release will perform successfully.
Hand Off
Once the release plan has reached the point in which all the steps have been mapped out, and you have reviewed the steps, information, and code, you have reached a point in which you can consider the release “handed off” from development. Ensure that you have done your due diligence to get the release to this point. Do not accept a release as “handed off” until it has been vigorously vetted. If it has not reached this point, repeat any of the previous steps that are yet unfulfilled. Repeat these steps until you are satisfied.
Release Plan Created
Now that you have created a release plan, note the date that this occurred in your release notes. This information will come in handy to help you create a baseline for future releases. Knowing the dates that a release is requested, knowing the length of time it takes to perform the various tasks, and knowing all the necessary parts needed to ensure a successful release will help you plan future releases. Saving this information and reviewing after your successful release will assist you.
Release Plan Review
As mentioned before, reviewing the release plan can be an iterative process. Keeping track of each date you alter the plan will help you baseline and plan for future releases. Some of these future releases could entail similar steps, and your plan could be reused, which should save you time.
Rollback Procedures
In addition to meticulously planning all the steps to perform a release, reviewing code, augmenting your documentation with notes and information, you should also painstakingly create rollback procedures. Just as there are steps to create a change, you should always have steps to back out of that change. This might entail a snapshot of your schema, and a process to revert object changes to original state. It might entail scripts that can be executed to reverse data changes, insertions, updates, or deletions. Ensure that you add this information to your release plan, so that if the inevitable happens and you are forced into a situation in which you must roll back a change, you will be prepared. You will have the steps, will have tested the steps as part of your release plan testing phase, and will have the knowledge to easily and gracefully perform the rollback procedures. You will certainly be happy you have these steps in place on the day you need it. As with all other steps within this release plan, these need to be vetted, tested, and approved by others.
Release Plan Testing
It has been alluded to before, but let's say it again: test your release plan. Test and test and retest. Create a sandbox environment that mimics your production environment to the best of your ability, and perform the release in this environment. Doing so will also allow you to test the rollback procedures to return the environment's previous state. Perform your pre- and postvalidations. Perform any quality assurance tasks necessary in this environment. Use this environment as your testing ground. Giving yourself the ability to perform an actual release, and vet all the steps prior to the actual production release, will help you. Having to perform it multiple times when something goes wrong (and it might go wrong) will make you better prepared for the real release to production.
Performing the Release
At this point you have done a lot of work, and all that is left is that fateful day, release day. All your ducks are in a row. Others have done their parts. You have performed countless tests on your release plan. It's ready. You can actually say with a level of certainty what the outcome will be. Hopefully, you will not be saying, “I hope that this works.” You should know at this point. However, be wary and don't be over confident. Perform the release as you have outlined it in your release plan steps. Don't run the risk of skipping steps because you have performed them previously and probably know them by heart. Be meticulous, follow your plan, and perform the release as outlined.
While you perform the release, ensure that there is proper monitoring occurring on your environments. There should be many folks meticulously watching your processes for any falters in functionality, various monitoring results, and any alerts that might occur. These individuals should be aware that a release is occurring, and be able to indicate that something is awry. This awareness will allow you to halt the release and perform any rollback procedures you have in place, if necessary.
Just after the release has been performed, you might think that you are done. You could quit here. But why not take a little extra time to make any notes about the actual release? Detail any issues that you or others had while performing the steps. Maybe something was off in the execution that was not found in the previous iterations of testing. If you note those details now, making action items for the next release, your process will be that much more fine-tuned next time. Don't be afraid to make notes about what others could do better. Be even less afraid to make those same notes about yourself. The only way you get better is through practice and observation of the technique. Often, a root cause analysis will be performed after an error has occurred in an IT system, in order to investigate the causes and possible fixes. Why not do this on a positive note to your release process. Each performed iteration of a release, no matter how small or complex, can provide tips to make the next iteration more stable. Recall that our goal was to reach that perfect balance where the tasks are at once sufficient, yet not cumbersome. This will take you time and most likely involve various iterations of this malleable release process. Taking notes along the way is crucial to making your next release a more streamlined success.
Release Plan Template and Release Plans
You will notice that in the documents that we have discussed, several tasks were intermingled among the information. Let's discuss the actual tasks that will go into a release plan. Here, I do not mean the tasks to create the release plan, rather the tasks that will be performed in the actual release, which you should document within a release plan.
You should create a release plan template to keep track of the generic tasks you want to perform for each release. Each release will have specific tasks, skipping some of the generic tasks, saving some, and maybe even adding unique tasks for that particular release. Using this template document as a launch pad into each release plan will greatly help your effectiveness, as well as be able to allow you to control your release, matching similar tasks to past releases. As your release management tasks evolve, so should this document.
My release plan template has three major sections. The first section contains generic information about a release. The next section has various questions that should be asked for each release. The last section will be the actual steps to be performed to execute the release. This last section will be created once, and then duplicated for each environment that will receive the changes.
Generic Release Information
Within the template for release plans, as well as the actual release plans, you should document the generic information about the release. For the template, simply leave sections of the document ready to be filled in with the information shown in Figure 8-4.
In the actual release plan that you create for a given release, fill in this information as you collect it. This information will paint a picture of what these changes will impact. It will require you to go out and talk to people, to understand your topology, and find out the needed information. Do not skimp when you fill out these answers. Really dig into the questions and ask the appropriate people to glean as much information as you can. Collect this information in this section of the document so that you can refer to it during release preparation and after. Figure 8-4 is an example spreadsheet that has been used to collect this information.
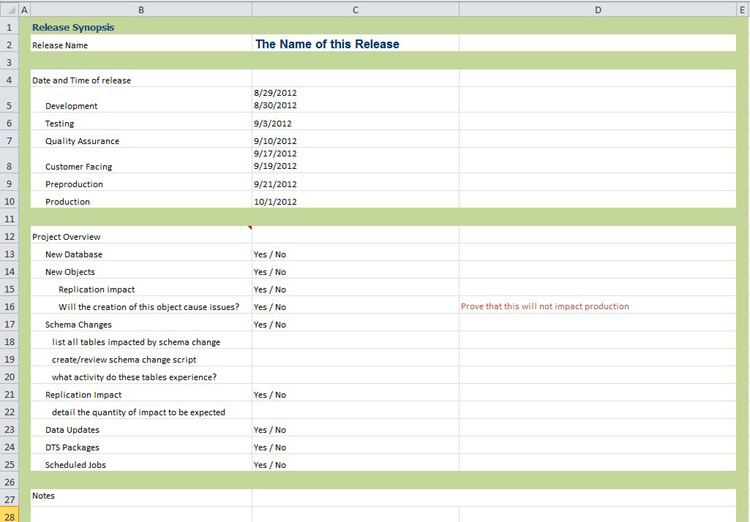
Figure 8-4. Release plan template—release synopsis
The following list explains some of the information detailed in Figure 8-4. Do not stop here; add to these as your system and topology reveals questions you should be asking to prepare for a successful release. This list is meant to be a quick reference guide that is filled out with quick answers.
- The release name
- The dates to release to each environment
- Each environment should get a date Multiple dates can be added for each attempt
- Project Overview
- Will there be a new database?
- Will there be new objects?
- Will these objects affect replication?
- Will the creation of this object cause issues? (It's important to prove this while testing this release.)
- Will there be schema changes?
- List all tables impacted by schema changes
- Ensure that you create or review the schema change script
- Detail the activity that these tables experience
- Will there be replication impact?
- Detail the quantity of impact to be expected
- Will there be data updates?
- Will there be DTS package updates? (similar for SSIS)
- Will there be changes to Scheduled Jobs?
- Notes
- General notes about the release
- Notes from any preproduction environments
- Notes about replication
- Notes about data changes
- Handoff notes
Questions and Answers
You should also keep track of various questions and answers that you typically ask of the developers. Keep these questions within the release plan template. As you fill out individual release plans, you can reference these questions and fill in the answers, as well as any others that arise. These will help you to collect the information necessary to prepare for the releases. Figures 8-5 show an example spreadsheet of several questions that I have used in the preparation of my releases.
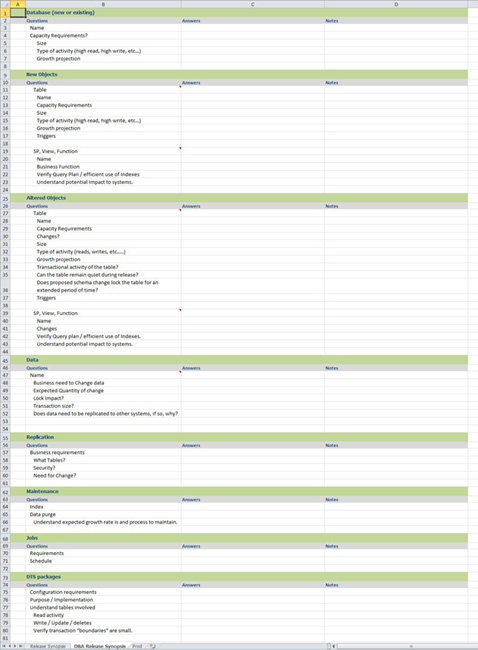
Figure 8-5. Release plan template—release questions
The following list goes into detail about the information shown in Figures 8-5. These are all questions you should pose to the developers within your organization.
- Does this release create a new or alter an existing database?
- What is the name of the affected/new database?
- What are the capacity requirements?
- What is the database size?
- What type of activity occurs?
- Read only
- Write only
- Highly transactional
- Reporting
- Periodic lookup
- What are the growth projections?
- Detail how many rows will be created, how often, and so on
- Does this release create new objects?
- If the object is a table, ask the following:
- If the object is a stored procedure, view or function, ask the following:
- What is the name of the object?
- What is the businesss function? (This might be a political hot button. Ensure that you find out as much as possible as why this needs to exist and how it will help your system.)
- Have you verified the query plan or efficient use of indexes?
- Do you understand the potential impact to your system?
- Does this release contain alterations to objects?
- If the object is a table, ask the following:
- What is the name of the new or affected object?
- What are the capacity requirements?
- What are the changes to the table?
- What is the size of this object?
- What type of activity occurs?
- What are the growth projections?
- What will the transactional activity be?
- Can the table remain quiet during release?
- Does the proposed schema change lock the table for an extended period of time?
- Are there triggers involved with this object?
- If the object is a stored procedure, view, or function, ask the following:
- What is the name of the object?
- What are the changes to the object?
- Have you verified the query plan or efficient use of indexes?
- Do you understand the potential impact to your system?
- Are there data updates?
- Is there an impact to replication?
- What tables will be involved?
- What will the security impact be?
- Why does this change need to occur?
- Is there impact to regular database maintenance tasks?
- Will this change impact indexes?
- Will there be any data purge? If so, understand the expected growth rate and any processes to maintain
- Is there any impact to SQL Server Agent Jobs?
- Explain the requirements for this job change
- Detail the schedule for this job
- Are there changes/new SSIS/DTS packages?
- Detail the configuration requirements for these packages.
- Detail the purpose and implementation steps
- Understand the tables involved
- What read activity will occur?
- Detail the write / update / deletes that will occur.
- Verify the the transaction boundries are small.
Obviously, your environment will be different and might require additional questions. These are only samples to get you thinking about the possible questions you should ask before each release. Ask these or similar questions to determine what this change will entail, so that you can properly plan for it. Some of the preceding questions are just the tip of the iceberg, and depending on the answers receive, you might need to dig deeper.
For example, if a new object is to be introduced as part of the change, you will want to follow up with questions about the name of the object, the capacity requirements if it is a database or table, the size it should start out at and possibly grow to, the type of activity it will experience, and what interactions it will have with other objects within your database.
Or, if the change requires an alteration to an existing object, you might need to know about its type of activity, and if the proposed change will impact it, lock it, or otherwise cause the object to be inaccessible for a period. If so, how can you ensure that the rest of your topology, system, applications, and so forth are minimally impacted? You might have to gracefully shut down services prior to this change being released to production, and finding this out early on will help you create the proper steps to perform this graceful shutdown.
When a change impacts replication, you might have to take special precautions to ensure that replication continues functioning as currently designed and implemented. There could be extra steps that need to be performed to introduce this change into a replicated environment that would not be necessary in a nonreplicated environment. Maybe you rely on a third-party replication scheme that is difficult to maintain and could generate many extra steps. In any event, knowing the impact to replication as you create your release plan will help.
The point is that there is always room for more digging to find out as much as you possibly can. Think about how this change could affect your regular, automated, or even manual maintenance of your database systems. You will need to plan this into the release plan as well. If you are introducing a new database to your system, ensure that your regular maintenance processes pick up this new database and perform the necessary tasks upon it. You might need to create or alter backup jobs. Other maintenance processes will likely be impacted. Identify and plan for these changes.
If you are changing any jobs, ensure that you collect the details about the job. Review the schedule that it will execute. You will want to make sure that this doesn't conflict with other existing jobs. Review the details of the job to see what the job will affect. It would be bad for new or existing jobs to be negatively impacted through a change.
If your change affects any DTS packages or SSIS packages, there will be many details that you should investigate. There will be configurations and steps that you should review, as well as determining which objects will be affected with the various steps of the packages.
Release Steps
As you create the steps to perform a release, realize that these steps will be repeated for most environments. Some of the steps might not occur in some environments, and some environments might need extra steps. This will depend on how you have set up each of these environments. I suggest that you create these steps for a single environment, and then make adjustments for each of the other environments as needed. This means that general steps could be created for all environments, and then multiple environments can be copied from the original, creating unique steps for each. Ensure that you detail the steps necessary for each environment. Be methodical and list them all. I find it imperative to create individual step lists for each environment and check off each task as they are performed. Figure 8-6 shows the release steps portion of the plan template.
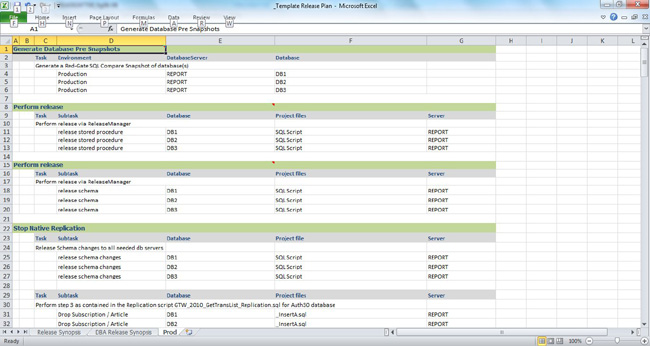
Figure 8-6. Release plan template—release steps
List each database that will be touched by the release, and the people who work on those databases that need to be informed of the impending release. This is important to keep things organized. This database list will also become a series of steps you will take to ensure snapshots are taken for each affected database. Generating a snapshot of each database schema will give you a baseline to compare against before, during, and after the release.
There will be many options to generate these snapshots. Third-party applications can perform this task, scripting objects directly from Management Studio, SMO, or PowerShell. One of my favorite tools is Red Gate SQL Compare, which lets you generate a snapshot as a single file containing the schema of the selected database. You can then compare this snapshot to another snapshot of that same database at a later time. Comparisons will show the different objects that were altered by your change. The main point is that it's an important step to perform. Generating a before-and-after snapshot of your various database schemas, and using this comparison to show what was affected, can assist with rollback, if necessary.
Along with generating a snapshot, there might be other steps that you need to perform to get ready for the release. These could include a graceful shutdown of other services or application, or you might need to make changes to your replication configuration to properly prepare for the release. Each of these steps needs to be detailed, thought out, and planned. You should identify and document preparatory tasks as individual steps.
At some point, you will need to list all the objects and/or scripts that will be executed to affect the needed changes. You could simply execute these changes directly in Management Studio, which will require someone to generate a script.
You could also use a tool to perform a compare between production and a lower environment, and affect the changes via this generated script. You can use a release tool that controls the execution of changes, documenting each step, with ability to roll back failed changes. Creating this tool will take some time and effort, but it will help you gracefully release change into your environment. Using a comparison tool will let you manually decide which objects will be compared and ultimately altered.
Whether you use a comparison tool or Management Studio, a script that details the changes will need to be created by someone intimately involved with the requested changes. A script will need to be generated that can perform a rollback as well. Creating a single script with all changes, or multiple scripts with individual changes will be your prerogative. Single or multiple scripts will also impact the rollback process. How you execute this change will be an important factor in your release process, allowing for a graceful and controlled change.
If you have replication involved in your topology, your release might need some extra steps. You might need to drop subscriptions and/or articles, add articles back, stop distribution agents, refresh subscriptions, and maybe even resnapshot publications. These steps will need to be tested in a similarly replicated environment, to ensure that the steps taken will succeed.
Just as you detailed all the steps to gracefully shut down applications and services, you will now want to detail the reverse of those steps that will need to be taken to seamlessly turn them back on. List each of these steps, in the proper order.
After everything has been released, generate another schema snapshot and use it to compare to the original snapshot. This should prove which objects where altered. This can be used to generate reports to show what was accomplished for the release.
As you perform each step within the release plan, mark it as completed. Even though this is just for you, you will be able to refer to this document on many occasions in the future, and it will certainly help in planning future similar releases. Use this as proof of what steps were taken, or what steps were not taken. Let this documentation validate that your release process steps were executed in the proper order. You can always refer to these and make alterations to your process and your release plan template to accommodate new information, new knowledge, and new ways of accomplishing successful releases.
Create this document with the intent that you may hand it over to another individual to perform all the steps themselves, without your involvement. This will force you to include a level of detail and explanation that will make the steps easily accomplished. Being as thorough as possible with all the steps will foster success.
Document Repository
Because we have been creating several files, including the release plan and release plan template documents, a folder structure to contain all of these files will assist you in organizing your releases. Acquire a central location that everyone involved with the release process can access to store documents associated with each release. You will be generating pre and post snapshots of each database to be affected, the actual scripts that will effect change, and other files. All these files can reside in the following folder structure to easily help:
- Release name
- Pre snapshots
- Post snapshots
- Database objects
- Web objects
- Application objects
- Release plan
- Other
As soon as you receive the request to make a change, create a location (similar to the previous suggestion) to store all the relevant files and information. Keep adding to this repository as you create files. You could store these files in your version control system as well. Ensure that you store them somewhere that is secure and can allow you and others to access them during the release period, as well as before and after.
This will ultimately be the location from which you pull all relevant information to perform the production release. If done properly, you will have used these files for release to each environment as you march this release to production. Keep all these files as proof and reference of the actual release. You can even refer your supervisor to this location to review your work for year-end reviews.
Conclusion
Accept change, embrace it, plan for it, and then gracefully introduce it into your environment. And then repeat. As you repeat, you will learn how to modify your release process to achieve that perfect balance where change is introduced into your topology, yet risk is minimized and the impact is graceful. You can do this, though you probably can't do this alone. You will need to include others along the way. Realize that there are quite a few tasks, several documents, and many considerations that have been discussed—quite a few, indeed! Please take the necessary time to dig into all these and formulate your own release process. Do it for your systems. Do it for yourself. Become the hero.