
CHAPTER 11
![]()
The Fluid Dynamics of SQL Server Data Movement
One of my favorite tasks as a database administrator (DBA) is configuring and administering solutions that get data from one place to another. Very early in my career, I was fortunate to work in an environment where we had to replicate data all over the globe. Supporting a system where I was responsible for data redundancy across seven major geographic hubs was very exciting, and it was a new challenge for me to tackle. Only later did I realize moving data is seen as a daunting task to many. Over the years, I have seen how the need for data replication has become more widespread
Since I started with Microsoft SQL Server, I have used numerous methods to achieve data redundancy. However, what I do depends on the task I am trying to accomplish. Is the copy of data for reporting? High availability? Disaster recovery? In this chapter, I will give practical advice on how to choose the right feature to get your data from point A to point B based on my experience, and I will let you know about the pros and cons of each method as well.
Why the Need for Replicating Data?
The need to have multiple copies of the same data in more than one place is ever-increasing. Companies both large and small are bombarded from all directions with requests for access to their data stores from both internal and external users. Everyone wants to see the data, and they want to see the data as quickly as possible. Often, that data needs to be current and clean. Here is a short list of reasons why an organization might need replicas of its data:
This list is, of course, not comprehensive, and I’m sure you can come up with a few additional scenarios that are not shown here and specific to your company’s needs. The point is that there is a lot more to data replication than just having copies for HA or DR. Although those are the most common reasons people have redundant copies of data elsewhere, the other reasons might be just as important.
For example, if your company has its own team of developers, there will be at least one development environment in your datacenter, and possibly others for testing, quality assurance, or pre-production release reviews. As a database administrator, you will be responsible for refreshing this data on some type of scheduled basis. I have seen everything from yearly to nightly refreshes, and even the need for on-demand capabilities.
How about overcoming issues with latency in data retrieval? There have been two key jobs where I worked for global companies, and both had similar issues with geographically dispersed offices maintaining current data stores locally. While both companies worked with replication models to distribute their data, they each went about it in completely different ways. For both companies, though, the key was to have the data physically closer to the users to ease the long synchronization times associated with connecting to a single data store that could be on the other side of the world.
A similar problem occurs when many users are attempting to create or run reports against a single data store. Too many connections simultaneously trying to access the same pieces of information can result in apparent latency issues for your users. Additionally, if your company allows ad-hoc reporting or has departments that access your databases through Microsoft Excel or Access data sources, you cannot control any bad querying of the data. One poorly written query can have a serious impact on your system. In this case, having a copy of the data available for those reports that are not using the same system resources as the true production source could alleviate much of that resource contention.
What do you do if you need to run batch processes against your data, but you need to ensure there is no negative impact on your daily business functions? You might choose to set up a secondary copy of your data to test the effect of the batch processes before pushing those changes to production.
Before I move on, let me say a few words about high availability and disaster recovery. A highly available system is one that is ready to use as instantly as possible with as little data loss as possible in the event of a single hardware failure. Some of the technologies I will describe here are great for providing highly available systems. Disaster recovery, on the other hand, is your company’s contingency plan in the event of a major disaster. Think of earthquakes, atom bomb explosions—the types of events we pray never come to pass but that could knock out entire communities, or your entire facility. If faced with a true disaster situation, could your company still recover and be back up and running in a matter of hours, days, or weeks? I will leave discussions about planning for those types of contingencies to other sources, because they are quite complex. One thing is guaranteed, though, and that is the fact you will need to account for a replica of your core data stores in the event of a disaster.
Let’s examine a few scenarios that illustrate the need for different data-distribution implementations.
SCENARIO 1: Global Organization Consulting Firms R Us is a global professional services company. They have a headquarters in Chicago, Illinois (USA) with two datacenters. One is located onsite at their main facility, and the other is in Columbus, Ohio (USA) at a co-hosting facility. They have business offices across the globe in Mexico City, Rio de Janeiro, Sydney, Tokyo, Istanbul, London, and Johannesburg. Worldwide, business operations must be online 24 hours a day, with a short available outage window on Saturday mornings.
SCENARIO 2: High-Volume Reporting Needs The firm has several databases that are accessed for reports. A number of users attempting to query these databases concurrently are causing issues with data access.
SCENARIO 3: Overnight Processing Jobs With a particularly large database, taking a nightly backup has started to cause issues with overnight processing jobs. These jobs are critical to starting business the next morning and are required to finish before the employees arrive at 8 a.m.
SCENARIO 4: Hardware Failure The main database server has failed due to a hardware issue. The vendor, while providing prompt service, cannot guarantee a subsequent failure without upgrading to the newest hardware it offers. Everything appears to be running smoothly, but having more than just the nightly backup to rely upon is now a number 1 priority.
SQL Server Solutions
Without having a clear understanding of the technology you want to use, it is easy to work yourself into trouble. SQL Server provides a variety of options for data replication. Shown here are various methods available to you just by using the product:
- Replication
- Snapshot
- Transactional
- Peer-to-Peer
- Merge
- Log shipping
- Database mirroring
- Asynchronous
- Synchronous
- AlwaysOn (requires Windows Server Failover Cluster)
- Availability groups
- Failover cluster instance (FCI)
- Custom ETL (Extract, Transform, Load) using SQL Server Integration Services
- Bulk copy process (BCP)
Each of these methods has certain benefits and limitations compared to the others, and certain ones are better suited to different needs. The flexibility gained by having so many choices can be daunting. Once you are familiar with the strengths of each, it becomes easier to determine which is best for the purpose at hand.
The sections that follow provide descriptions of each option, along with the benefits offered by each. Also covered are some potential hurdles you should be aware of with a given solution. Keep in mind as you read, though, that nothing is ever “set and forget.” You will always need to monitor and tune as your servers continue to support your company’s applications.
Replication
Many data professionals, upon hearing the word “replication,” get a wary look and start moving away from you. I have yet to understand why people can be so antireplication—unless they haven’t worked with it since SQL Server version 6.5 “back in the day.” Today’s options for using SQL Server replication cover a wide variety of scenarios and offer a lot of flexibility.
![]() NOTE In general, replication involves three players: the publisher, the distributor, and one or more subscribers.
NOTE In general, replication involves three players: the publisher, the distributor, and one or more subscribers.
The main use for replication is for redundancy and geographic distribution of data. There is no tenet for failing over services or applications when using replication. However, subscribers can be used to support outages of other subscribers when needed.
Snapshot
Just as the name implies, a snapshot is a point-in-time picture of the data. The snapshot method can be good for making quick copies that do not need to be updated frequently. Snapshots are typically used to initialize other replication topologies, but they can also be useful for creating mainly read-only copies of an entire database. The process is comparable to a backup/restore operation that runs on a scheduled basis—for example, daily, weekly, or monthly.
![]() NOTE Snapshot replication uses the same topology as transactional replication, which is described in the next section.
NOTE Snapshot replication uses the same topology as transactional replication, which is described in the next section.
If you decide to implement snapshot replication, the size of the data being replicated is a paramount concern. If the amount of data is too large and takes a long time to replicate to the subscribers, the frequency of snapshots should be limited significantly.
Transactional
Picture a three-ring circus consisting of a publisher database, distribution database (DB), and at least one subscriber database, all brought together with the use of the SQL Server Agent as the ringmaster. (Figure 11-1 illustrates the topology.) There are several options for configuring transactional replication that make this solution scalable by parceling off each component. Another strength of this solution is that you can choose to replicate portions of your data, whether it’s a single table, a few columns in a table, or even a subset of data from a table.
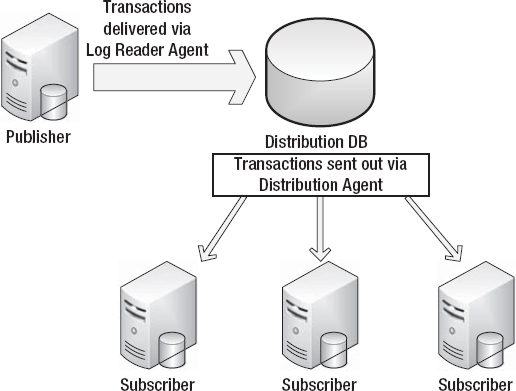
Figure 11-1. Transactional replication.
Additionally, you can have multiple subscriber databases, so you have the ability to create many copies of the data and keep them synchronized with the data from the publisher. By using stored procedures to apply data changes, you can gain even greater flexibility because you can create your own custom logic if needed.
Another win here is the option to not only pass along data changes, but also pass along changes to the objects themselves. Data Definition Language (DDL) changes to tables, views, stored procedures, and so on can also be replicated. Multiple databases can be set up as publishers, subscribers, or both on any given server.
In the transactional replication setup, data changes are made at the publisher database. Then the transaction details are sent to the distribution database, which in turn sends those changes to all of the subscriber databases. SQL Server Agent jobs called log readers facilitate the collection and delivery of transactions.
The benefits include the following:
- Flexibility in the topology so that you can use it in a wide variety of environments
- Customizability through the implementation of stored procedures for insert, update, and delete transactions
- Ability of the distribution agent to push changes out to subscribers, or to allow each subscriber to have its own distribution agent to pull changes from the distribution database
- Availability in all versions of SQL Server
- Table-level data replication, with options for partitioning and filtering
- Ability for a subscriber to have a completely different set of data replicated to it
The limitations include the following:
- Every table included in a replication topology must have a Primary Key defined.
- There is potential for varied degrees of latency due to network traffic or significant or frequent data changes.
Peer-to-Peer
In the peer-to-peer topology, all database servers—referred to as nodes—act as both publishers and subscribers. The distribution agents facilitate the delivery of all changes to all nodes, essentially making peer-to-peer a hybrid of transactional and merge replication.
There is an option for conflict detection. If conflict detection is enabled, conflicts are handled at the distribution database and will cause a failure of the distribution agent until the conflict has been manually resolved.
The benefits of peer-to-peer replication are the following:
- Can be useful in load-balancing architectures
- Possibility to fail over to any node (application level)
The price you pay is that you have to deal with a somewhat longer list of limitations:
- Every table included in a replication topology must have a Primary Key defined.
- Row and column partitioning is not supported.
- Snapshots cannot be used for the initialization of a new node.
- Conflict detection requires manual intervention.
- The recommended setup is to have only one node updateable due to conflict-detection intervention.
- Peer-to-peer replication is an Enterprise edition–only feature.
Merge
Merge is the granddaddy of the replication topologies (shown in Figure 11-2), allowing updates of the data to originate from any source (publisher or subscriber). These updates are then consolidated by the publisher. By using conflict-resolution rules, the publisher ultimately determines the state of each data point and then replicates those to other subscribers. Instead of log readers, merge replication uses table triggers and system tables plus the merge agent, which tracks table changes and then logs actions to the distributor.
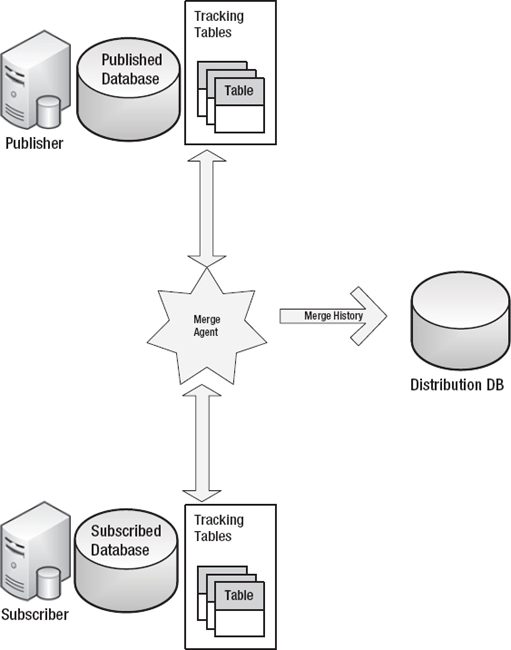
Figure 11-2. Merge replication.
So what is the difference between peer-to-peer and merge replication, then? The key is in conflict detection and management. With peer-to-peer replication, the entire distribution process is halted until someone manually resolves the conflict. With merge replication, custom business rules for resolving conflicts can be implemented without any interruption of service.
Merge replication provides numerous benefits:
- It is ideal for use in systems where you are working with point of sale (POS) data or a remote sales force.
- Conflict detection does not cause any interruption of service.
- Synchronizations can be pushed out to subscribers, or subscribers can pull from the publisher.
- You can perform table-level data replication, with options for partitioning and filtering.
- Each subscriber can have a completely different set of data replicated to it.
Yet you cannot completely escape limitations, such as the following:
Replication Examples
Following are examples of how replication can be applied to the four scenarios introduced earlier in the chapter:
SCENARIO 1: Global Organization This is a good scenario for replication. Choose one server as the publisher (transactional replication)—let’s say Chicago—and set up each other city as a subscriber. Data can be shared among all of the major hubs. You can implement a peer-to-peer setup that allows data updates from any major city. You can use merge replication to manage data updates from any of the subscribers.
SCENARIO 2: High-Volume Reporting Needs Consider the reporting requirements first. If up-to-the-minute data is needed for reporting, transactional replication could be a good fit. Another bonus to having a subscriber copy of the database is that you can set up different indexing strategies on each subscriber, thereby giving you the ability to performance tune for individual reporting needs. Alternatively, peer-to-peer replication can be configured with only one node updateable, allowing for read-only access at a given node and no possibility for conflicts to occur.
SCENARIO 3: Overnight Processing Jobs If your subscribers are exact copies of your publisher, replication might help out here. Ensure that all objects in the database are identical (table definitions, indexing, stored procedures—everything!), and set your backups to run against a subscriber. Your doing so will enable the overnight processing to run against the publisher, and replication will then distribute any changes made to the subscriber or subscribers. Alternatively, peer-to-peer replication can be configured with only one node updateable, allowing backups to be performed on the nonupdateable node.
SCENARIO 4: Hardware Failure Replication is not ideal in the case of a hardware failure. Having said that, if you have multiple subscribers and one of those fails, you might be able to use a second subscriber in its place until the first one is recovered. Your application will need to be configured to have that flexibility of connecting to an alternate subscriber. If, however, you lose your publisher, replication will not help. Peer-to-peer replication is an option here, and it can be useful as long as your application can easily switch to using another node and all nodes are updateable.
Log Shipping
A log-shipping solution (shown in Figure 11-3) involves taking transaction log backups of a primary database, copying them, and applying them to a secondary database located on another server. The SQL Server Agent services on the primary and secondary servers manage the process flow of backups, file copy, and restore. There is a mandatory delay between when the backup is taken on the primary and when it is then applied to the secondary. At a minimum, this delay is the time it takes for the backup operation to complete and the file copy to occur before the restore operation begins. The delay prior to a restore can be configured for specific time intervals—for example, 15 minutes, 2 hours, and so forth.
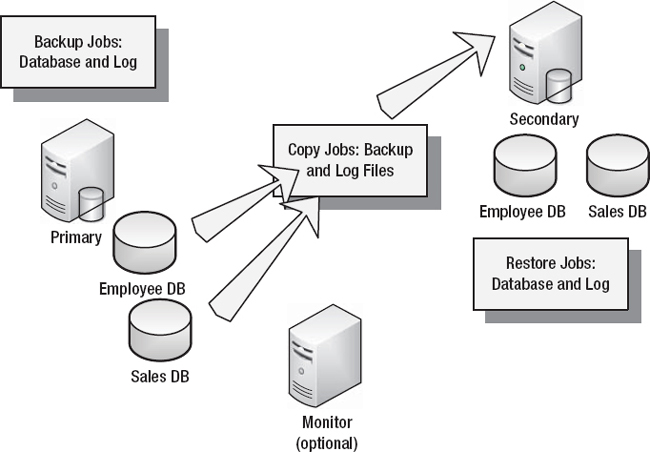
Figure 11-3. Log shipping.
There are several benefits to implementing log shipping. First, you can copy the logs to multiple destinations, much like having multiple subscribers in replication. Second, the secondary database or databases can be used for read-only activity when the logs are not being actively applied. Finally, the delay in applying the transaction log backups on the secondary database can allow for data recovery in the event of a mass data update or a delete applied accidentally. An optional monitor instance can be used to detect any failures in the log backup/delivery/restore process and send out a notification of the need for a failover.
Log shipping is most often used for disaster-recovery scenarios, because the built-in latency is often not desired for other data-replication needs.
Benefits from log shipping include the following:
- Multiple secondaries are allowed.
- Limited, read-only use of secondary databases is allowed.
- The entire database is sent to the other instance.
The limitations include the following:
- A database cannot be used while log files are being restored.
- Failover to a secondary database is a manual process.
- There is no support for partitioning or filtering data.
Following are examples of how replication can be applied to the four scenarios:
SCENARIO 1: Global Organization Log shipping will not help distribute the data across the globe for daily use. Because the database will be repeatedly taken offline to apply log backups, even having a read-only copy in each of the major cities would not be of any benefit. However, if you need read-only activity during an upgrade or outage window, you might want to set up log shipping and perform a role change for your applications to the secondary database while performing maintenance. This is not a perfect solution, but it could provide some uptime for users globally.
SCENARIO 2: High-Volume Reporting Needs Log shipping might be useful here. There would need to be a more sizable delay in applying the log backups to the secondary database, however. For example, if a secondary is set up to apply logs only once or twice per day (perhaps at 7 a.m. and 7 p.m.), the times when users are accessing the data will not be interrupted. Data will be up to 12 hours old, depending on when it is accessed.
SCENARIO 3: Overnight Processing Jobs Log shipping is not a viable option for distributing the load because of the high-volume tasks.
SCENARIO 4: Hardware Failure In the event of a hardware failure, log shipping can be useful but should not be seen as a permanent solution. The primary should be repaired or rebuilt as needed. While this is in process, the secondary database can be brought online and fully recovered. At this point, it will no longer be secondary. The application using the database needs to be configured to access the new database source. Once the primary database is ready to be brought back online, the secondary database can be backed up and restored to the primary database. Log shipping needs to be reconfigured and restarted so that it can be ready for the next failover occurrence.
Database Mirroring
Database mirroring has a tendency to be confused with log shipping (I still can’t figure out why), but really it has nothing in common with log shipping. The use of mirroring takes you back to applying changes at the transaction level; however, unlike replication, the transactions are batched together and applied as quickly as possible without the use of a distributor. With mirroring, there is a single principal server and there can only be a single mirror server. An optional witness server also can be used to verify communication to both the principal and the mirror.
If you are looking to implement some type of data replication in your environment—and you have a shiny, new installation of SQL Server 2012—I would not recommend setting up database mirroring. This feature has been deprecated and eventually will not be available in future versions of the product. The upgrade is to convert a mirroring configuration to an AlwaysOn availability group.
If you currently need to support mirroring in a SQL Server 2008 or 2008 R2 version that will be upgraded to 2012, there is no problem with keeping mirroring in place. Remember when a technology is deprecated, you have a grace period in which to make changes and plan for replacements. But having that grace period doesn’t mean you should continue to encourage the use of the deprecated feature for new systems!
The single-most important feature of mirroring is the ability to easily fail over when communication to the primary database is lost or interrupted. Additionally, with the options for data “safety,” you can control the amount of potential data loss on failover. Following are the two options:
High-Performance Mode (Asynchronous) Transactions are batched up and applied on the mirror as they come in. There is the possibility on failover that some transactions have not yet been applied on the mirror. This option is available only with the Enterprise edition.
High-Safety Mode (Synchronous) Transactions are applied to the mirror before being committed to the primary. The ensures no data is lost on failover. There is a potential for latency when using synchronous mode. With high-safety mode, you can also have automatic failover if a witness server is configured.
The benefits from mirroring include the following:
- Compression when delivering the transactions
- The entire database is mirrored.
- There is support for automatic failover.
- On failover, the roles of the principal and mirror are swapped.
- No data loss occurs with synchronous mirroring.
- Early detection of corruption in your database is possible.
The imitations form a rather long list this time:
- Mirroring requires the FULL recovery model.
- The mirror copy is not online and cannot be used until failover.
- There is no support for data partitions or filtering.
- Mirroring requires Transmission Control Protocol (TCP) endpoints for communication.
- Mirroring cannot support cross-database transactions or distributed transactions.
- You cannot mirror any system databases (for example, master, msdb, tempdb, or model).
- Mirroring’s asynchronous option is only available only in the Enterprise edition.
- You might need to manually set applications to use the mirror in the event of failover.
Following is how you might benefit from mirroring in the four scenarios we’ve been considering so far in this chapter:
SCENARIO 1: Global Organization Using mirroring here would not provide a benefit in terms of distributing the user load, because mirroring is more useful for HA/DR scenarios. Because the mirror database cannot be used until failover, only the principal is in use at any given time.
SCENARIO 2: High-Volume Reporting Needs Much like Scenario 1, mirroring is of limited use here. Having said that, I have seen setups that use mirroring, coupled with log shipping on top of the mirror instance, to provide users with a read-only copy of the database.
SCENARIO 3: Overnight Processing Jobs Mirroring will not provide any benefit in this scenario, because the mirror is not accessible for data reads or writes.
SCENARIO 4: Hardware Failure Here is where mirroring can shine. If a hardware failure happens, failover is immediate. Applications might still need manual intervention to point to the new data source, however, depending upon how those applications are designed. Once the failover condition has been cleared, failing the database back over to the principal is simple.
![]() NOTE In Scenario 4, failover is immediate when synchronous mirroring is used. Asynchronous mirroring brings the possibility of delay while the target database clears the redo queue.
NOTE In Scenario 4, failover is immediate when synchronous mirroring is used. Asynchronous mirroring brings the possibility of delay while the target database clears the redo queue.
AlwaysOn
“AlwaysOn” is an umbrella term that covers two features are in SQL Server 2012:
- Availability groups
- Failover clustering instance (FCI)
Availability Groups
Availability groups (shown in Figure 11-4) incorporate the best of database mirroring, but they are enhanced beyond that. Availability groups require that the servers hosting the SQL Server instances are part of a Windows Server Failover Cluster (WSFC). SQL Server can also be installed as a standalone instance on a server in a WSFC with no shared storage requirement; it is not required to be a failover cluster instance (FCI) to implement availability groups. To review all of the prerequisites needed for using AlwaysOn, see the documentation from Microsoft here: http://msdn.microsoft.com/en-us/library/ff878487.aspx.
Once you have installed a SQL Server instance and the AlwaysOn feature has been enabled, you can configure availability groups. Each availability group serves as a host to a number of user databases (availability databases) in a primary replica, and up to four additional secondary replicas can be configured, for a total of up to five replicas. This is different from mirroring, where only a single principal database can be configured to a single mirror.
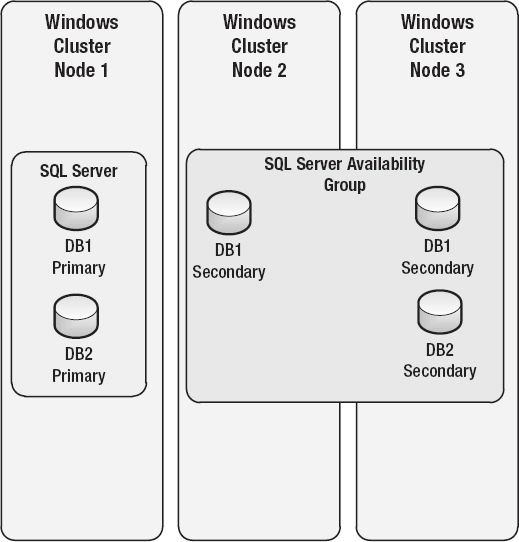
Figure 11-4. AlwaysOn availability groups.
The primary replica and all secondary replicas are kept in sync by a process called data synchronization, where the transaction log entries from the primary are applied to each secondary. Each database in the availability groupwill have its own data-synchronization process. Data is not synchronized for the entire availability group, but for each individual database. As with mirroring, synchronization can be synchronous or asynchronous per database. Recall that with synchronous replicas, latency might occur while the primary replica database waits for the secondary replica database transaction to be committed. Unlike mirroring, secondary replicas can be configured for read-only access and can also be used to support full (copy-only) or transaction log backups.
In the event of a failover, one of the secondary replicas will become the primary and the original primary replica will become a secondary. There can only be one primary replica for any given availability group. All databases in a replica will be failed over together.
One of the biggest benefits of availability groups is that you have the ability to configure a listener name, which acts as a single point of entry for applications that stays the same name no matter where it lives (which is always where the primary replica is). As with an FCI, this allows applications to not worry about connecting after a failover to a different name.
Benefits include the following:
- Availability groups allow for more than one database to fail over as a group if they are configured that way.
- Automatic failover can be configured.
- Secondary replicas can be configured for read-only access by users and applications.
- Secondary replicas can be used for some backup operations.
Limitations are the following:
You can apply availability groups to our four scenarios as follows:
SCENARIO 1: Global Organization Availability groups can be used to enable particular offices to connect to read-only secondary copies of the database. However, there might still be significant issues with latency due to the time it takes for the data request and delivery to occur as it would be in any dispersed scenario. Think of this scenario as having three copies of the data in Chicago, and everyone still has to connect to Chicago to access the data. In countries where the network infrastructure is poor, availability groups provide no help with problematic access.
SCENARIO 2: High-Volume Reporting Needs Here is a possible case for using availability groups. Allowing reporting tools to connect to a specific secondary database could alleviate database contention, but it might impact that replica’s ability to meet specific RTO and RPO needs. If separate indexing strategies are needed for data retrieval, however, that would not be supported.
SCENARIO 3: Overnight Processing Jobs Another possible case for using availability groups. Backup procedures could be pointed at a secondary database for full (copy-only) and transaction log backup while processing continues to occur on the primary database. Differential backups on a secondary database are not supported. Find complete information on support for backups on a secondary replica here: http://msdn.microsoft.com/en-us/library/hh245119.aspx.
SCENARIO 4: Hardware Failure Availability groups can be used to failover in this situation. Much like mirroring, when an issue with the primary replica is detected, failover to one of the secondaries can take place. Unlike mirroring, no manual intervention is needed to redirect your application if you configure a listener name and your application uses the right client utilities. If you want the highest protection, you can combine availability groups with FCIs.
Failover Clustering
SQL Server can be installed as a clustered instance that runs on top of a Windows Server Failover Cluster (shown in Figure 11-5). It provides instance-level protection and automatic failover to another node due to how the underlying Windows clustering feature works. An FCI is not a solution that provides a redundant copy of the data; there is only one copy of the data for databases in an FCI. The databases are then stored on a shared-storage solution such as a storage area network (SAN).
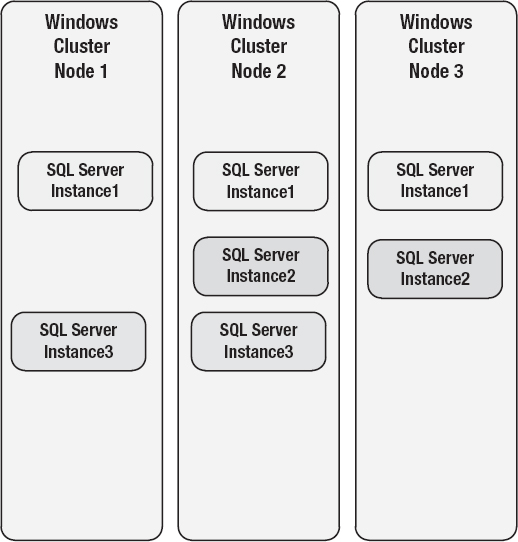
Figure 11-5. AlwaysOn failover clustering.
Failover can happen in a variety of circumstances, but the two most common scenarios are service or hardware failures and loss of quorum. Failures in services and issues with hardware are fairly obvious: the service or the hardware experiences a fatal failure and cannot recover. Loss of quorum can be a bit more confusing, but it boils down to answering this question: Are a majority of the servers in the cluster actually functioning? If the answer is yes, the cluster continues to run. If the answer is no, the entire cluster can go offline. This is certainly not a preferred state, and the configuration of your cluster should consider a loss of quorum situation.
The benefits from failover clustering include the following:
- For high-availability, failover clustering is one of the best features SQL Server has to offer.
- Failover clustering in SQL Server 2012 supports the multisubnet feature of WSFC and does not require a virtual local area network (VLAN) like in previous versions.
- The entire SQL Server instance is protected in event of a hardware or service failure.
- You get fast and automatic failover from the use of shared storage.
The imitations are as follows:
- Additional hardware resources are needed for multiple nodes.
- You need to work closely with other teams—such as teams working with storage, security, and network—to configure and support the Windows Server Failover Cluster.
- Loss of quorum in a WSFC can result in everything going down, which would then require manual intervention.
And following are some examples of how failover clustering might be applied in our four scenarios:
SCENARIO 1: Global Organization An FCI is intended for recovery from a hardware failure, so it will not cover a globally dispersed scenario. Although you can span multiple data centers with an FCI configuration, it still does not provide the data redundancy. The data redundancy needed to be able to switch between data centers underneath the cluster is provided by a storage-based solution.
SCENARIO 2: High-Volume Reporting Needs An FCI is intended for recovery from a hardware failure. It provides no redundancy of data. An FCI can house a reporting database, but typical methods to make it scale need to be employed.
SCENARIO 3: Overnight Processing Jobs Similar to Scenario 2, an FCI can be used for batch processing, but it would be a database in an instance—nothing more, nothing less.
SCENARIO 4: Hardware Failure Install SQL Server on a Windows Server Failover Cluster to provide immediate failover in this situation.
Custom ETL Using SQL Server Integration Services
SQL Server Integration Services (SSIS) is an incredibly powerful tool in the SQL Server stack, allowing for the utmost flexibility in creating processes for moving or copying data from one source to another. Commonly called ETL processing (Extract, Transform, Load), SSIS is most often used for loading data warehouses. Through the use of custom control-flow and data-flow tasks, any data source can be copied or moved to another location. Business logic can also be used to limit or change the data in any way needed.
If you have ever used the Data Import/Export Wizard in SQL Server Management Studio and saved the package at the end, you have created an SSIS package. The interface for working with SSIS is either Microsoft Visual Studio or Business Intelligence Development Studio (BIDS), a lighter weight version of Visual Studio. By using a single control flow that can branch out into multiple data-flow tasks, you take a dataset from its original format and location, massage the data to get it to look the way it needs to, and then save it in a new location.
The benefits are that Integration Services does the following:
- Provides for the highest level of customization
- Incorporates business logic if needed
- Allows secondary databases to be made available for use
Its limitations are these:
- You must rely on manual scheduling for execution.
- Integration Services might require extended development resources for design, coding, and testing.
- No troubleshooting or maintenance tools are included.
Following are ways you can apply custom ETL solutions developed using Integration Services to our four scenarios:
SCENARIO 1: Global Organization Creating a customized ETL for global distribution can be a tedious project. If your satellite offices require only copies of the data, or subsets of the data, replication is likely a better option. However, if your offices need data that is based on the data at the primary location, but not the raw data itself, an SSIS project might be worthwhile.
SCENARIO 2: High-Volume Reporting Needs Depending on the types of reports being run, you might want to create aggregate tables in a separate data store to support those. A custom ETL can be created to build a set of aggregations on a secondary server. Moving this data manipulation to a server with its own storage and memory capacity could make tedious reports much more accessible.
SCENARIO 3: Overnight Processing Jobs Custom ETL will not alleviate resource contention in this case.
SCENARIO 4: Hardware Failure Custom ETL would not be of any use in the event of a service or hardware failure.
Bulk Copy Process
Bulk Copy Process (BCP) is a utility that enables data to be copied from a data source to or from a file. Run at the command line, simple parameters are enabled to state the source and destination locations for the data. Optional use of a format file can be added to map the source and target more easily.
Let’s say you have a table with a million rows and 200 columns and you need to move that data somewhere or share it with multiple users rather quickly. Or maybe you have 50 tables that need to be shared and their combined data size is in the hundreds of Gigabytes. How will you get that data distributed? For initial loads, BCP is often a viable option when dealing with large amounts of data.
Using BCP is simple. You create and execute a BCP command at either the target or the source, depending on whether you are creating a data file for export or importing a data file. A host of options are available to customize the processing, including the ability to indicate a query for a subset of data from a table.
The benefits of using BCP include
- Simple, command-line execution
- Provision for reading and generating XML and text formats for ease in mapping data fields
Its limitations are
- A BCP command applies to a single table only.
- Manual mapping is required if you’re not using a format file.
- No troubleshooting or maintenance tools are included.
Following are ways in which to apply BCP in our four scenarios:
SCENARIO 1: Global Organization If satellite offices require subsets of the data only on an occasional basis, BCP might be an option for transferring those limited datasets. Data files for export could be created on a scheduled basis (ex: weekly) and offices could import those files as needed. BCP is used under the covers for applying snapshots in replication.
SCENARIO 2: High-Volume Reporting Needs BCP would not help in this scenario.
SCENARIO 3: Overnight Processing Jobs BCP would not help in this scenario.
SCENARIO 4: Hardware Failure Although BCP would not provide any help in the event of a service or hardware failure, it could be used to create files for all tables in a database. Those files could be used to “restore” the data for any table, but a format file for each table would also need to be used.
Choosing the Right Deployment
There will be times when one solution seems to be the perfect fit for the needs of your company or process, and you have the resources at hand to implement it easily. Treasure those times! More often, there will be compromises and concessions that need to be made along the way. I have seen it happen that management decides it needs one implementation, but in reality, once all of the requirements and resources have been laid out, it turns out a different implementation is needed.
Tables 11-1a and 11-1b—actually, one table split into two in order to fit onto the page—can help you decide which approach to take in a situation in which data needs to be replicated to or from another database. Choose your database edition and the features you need in the left column. Look for occurrences of “Yes” in the other columns to help you identify which of the solutions talked about in this chapter will cover your needs.
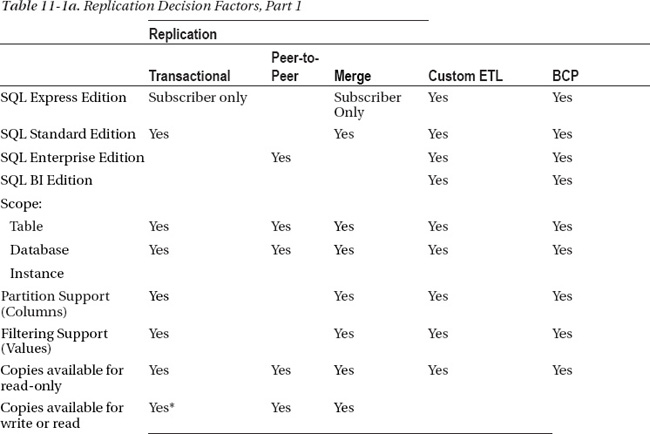
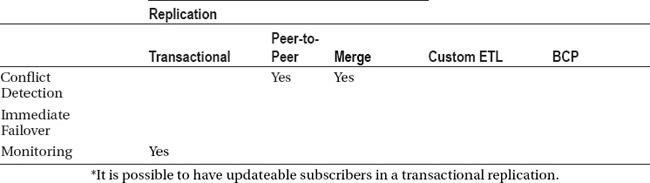
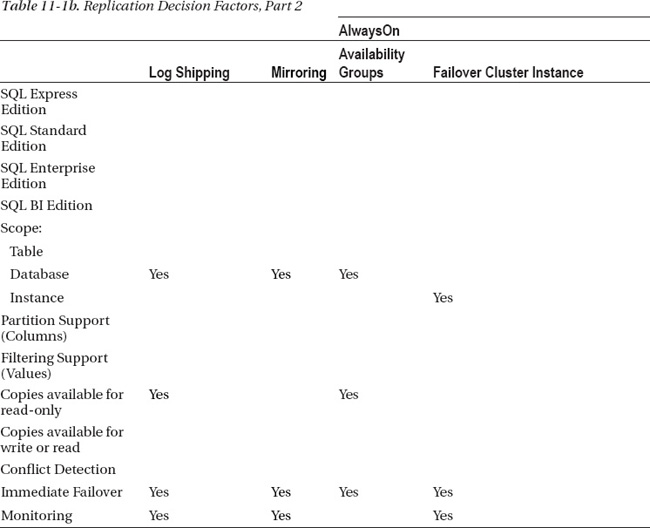
The key to a successful deployment is to ensure all parties involved have bought in and signed off on the requirements and the process to be used to achieve the goal. Problems arise when managers or executives are expecting one thing and they end up with something different. Managing those individual expectations will go a long way toward a successful deployment. Additionally, verify that all key personnel understand what the process implemented will actually be doing. If you have spent a considerable sum of money setting up a Windows Failover Cluster with SQL, and management expects to have a second copy of the data ready for reporting, you are going to have a lot of explaining to do later.
Keep in mind the following:
Edition of SQL Server Several features are available only with the Enterprise edition, which incurs greater licensing costs than the Standard edition.
Latency Determine whether or not latency will negatively impact your system. In many cases, a copy of the data that is 15-minutes to 1-hour old might be more than sufficient for the business needs.
Overall goal When the needs of data redundancy are for high availability or disaster recovery, log shipping, mirroring, and failover clustering are more likely the place to begin building your implementation plan. When searching for load-balancing, reporting, or distributed systems solutions, replication or AlwaysOn availability groups might be better places to start.
Keep in mind that there are always situations in which management might choose to go with a choice you don’t fully agree with or that you feel is suboptimal. Often, that is due to cost considerations, resource considerations, or both. For example, management might prefer to avoid the high cost of the Enterprise edition. Don’t dig in your heels in these cases. Work with what you have.
Keeping the Data Consistent
We’ve now created a picture of what each technology can do and have created a roadmap to help determine the best course of action. It’s time to talk about keeping the resulting solution running smoothly.
First and foremost, you need to monitor your systems. Some features, such as replication, come with built-in monitoring tools. These can be a starting place for troubleshooting in the event of failures. Other features, however, have nothing unless you build it yourself—BCP, for example.
If you build an automated system, remember to include error-handling and notification mechanisms too. The worst thing that can happen to your environment is to discover hours or days later that your data was not in sync!
If you discover inconsistencies in your data, you need to be prepared to fix them quickly. Notifying your superiors and users is crucial to keeping the situation from spiraling out of control. Have a plan for communication in the event of failures. Timing is very important. Plan for fast communication ahead of time.
Let’s go through our list once again and look at what is offered in terms of monitoring and recovery for each data-redundancy technology.
Monitoring and recovery options for replication include
- Monitoring
- Replication Monitor
- Custom Errors
- Recovery:
- Re-apply failed transactions
- Manually edit the data at the subscriber
- Reinitialize
Also helpful are the articles “Monitoring Replication with System Monitor” and “Monitoring Replication,” which you can read for information about using system tools in replication solutions. You’ll find these on the Microsoft Developer Network website (http://www.msdn.com). Just search for their titles.
Options for log shipping are as follows:
- Monitoring
- Notification upon failure of the Transaction Log backup
- Notification upon failure of the Copy job
- Notification upon failure of the Restore
- Recovery
- Restart failed jobs
- Manually apply log backups at the secondary
- Reinitialize
Again, MSDN is your friend. See the MSDN article “Monitor Log Shipping” for a list of system tables and stored procedures you can use to help stay on top of log-shipping solutions.
For database mirroring, your options are the following:
- Monitoring
- Notification upon failover
- Performance counters (see http://technet.microsoft.com/en-us/library/ms189931.aspx)
- Recovery
- GUI interface for failback
- Reinitialize
The list is very short for AlwaysOn availability groups:
- Monitoring
- The AlwaysOn dashboard in SQL Server Management Studio (SSMS)
- Extended events
- Windows PowerShell
- Recovery
- Failover and failback of the primary replica
Custom ETL using SQL Server Integration Services offers the following options for monitoring and recovery:
And finally, for Bulk Copy Process (BCP), you have the following options:
- Monitoring
- Scheduled BCP jobs can be configured to notify on failure.
- More robust scripting can include some error handling.
- Recovery
- When BCP fails on importing data, the entire batch is rolled back so that no data inconsistency can come from a partial load.
Keep in mind that you can take advantage of Extended Events and PowerShell to create your own custom monitoring. These two tools can actually be applied to any of the data-replication techniques described in this chapter.
Conclusion
You might end up using one or more of the methods described in this chapter, or a combination of two or more. They all have their strengths. They all have drawbacks, too. If you plan well and communicate that plan to the right team members, you are well on your way to successful deployment. Make sure your senior managers also are aware of what the technology you choose can and cannot do. With their understanding, you are less likely to be asked later, “Why doesn’t it do X? We thought it would do X.”
![]() NOTE Don’t forget to use all of the valuable resources available to you, most are available for free on YouTube, Twitter, and many SQL Server support sites.
NOTE Don’t forget to use all of the valuable resources available to you, most are available for free on YouTube, Twitter, and many SQL Server support sites.
As with everything related to SQL Server, your mileage might vary because your experiences can be vastly different from mine. The examples provided here have all come from real-life scenarios I have had to support. They are not intended to be all encompassing, and even though my company went in one direction for a solution, yours might choose another. A few things are certain, though: the technology will continue to advance, and database administrators and developers will continue to find creative solutions using those tools.