
8.4 Cracking the Substitution Cipher
The substitution cipher is much more difficult to crack than the rail fence cipher. As we mentioned previously, 26! or roughly 4 × 1026 different possible arrangements of the alphabet could be used as a key. Clearly, the brute-force strategy for finding the key would take an extremely long time. However, the substitution cipher does have a fatal flaw that we can exploit.
The flaw in the substitution cipher allows us to take advantage of patterns in the English language that can help us deduce letters in the key. The first pattern we will exploit is that some letters in the English language are used more frequently than others. If we count the number of times each letter occurs in a document such as this text, or any English-language text, we would find that the letters e, t, a, o, and i occur much more frequently than any other letters in the alphabet.
8.4.1 Letter Frequency
We can write our own program to calculate the frequency of letters in a text. To report the letter frequency, we might simply count the total number of occurrences of each letter. However, that total would change depending on the size of the document. A better approach is to report each letter’s percentage—that is, the total count for each letter divided by the total number of letters. We will keep our analysis simple. FIGURE 8.1 shows a graph of the results we are seeking from our letter frequency program.
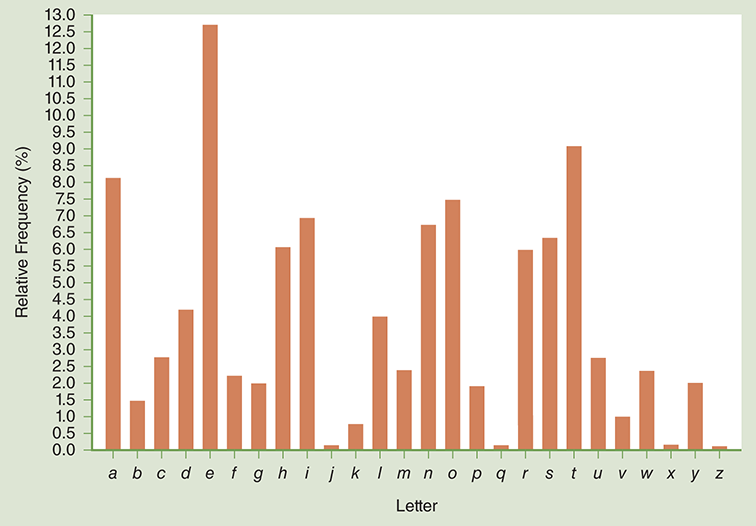
FIGURE 8.1 Relative letter frequencies.
To generate the data for the graph in Figure 8.1, we will write a Python function that takes a string, text, as a parameter. For each letter in the alphabet, the function prints the number of times each letter occurred in text and the percentage of the total characters in text that the count represents. Counting the letters is easy, because we can use the count method of the string class. The trickier part of this exercise is that to get an accurate percentage, we need to ignore nonletter characters such as spaces, punctuation marks, and numbers.
One effective way to ignore nonletter characters is to remove them from the string before we start counting. Thus, we need a way to remove all the nonletter characters from text. Earlier, we wrote a function that can remove characters from a string, called removeMatches. Although we do not have a handy string full of all the nonletter characters, we can certainly create one. SESSION 8.3 repeats the removeMatches function and shows how we can make a string of nonLetters by first removing all the letters from the string we want to count. Then we call removeMatches again with all the nonletter characters we removed. The text string at the end of the session is ready for analysis by our counting function.
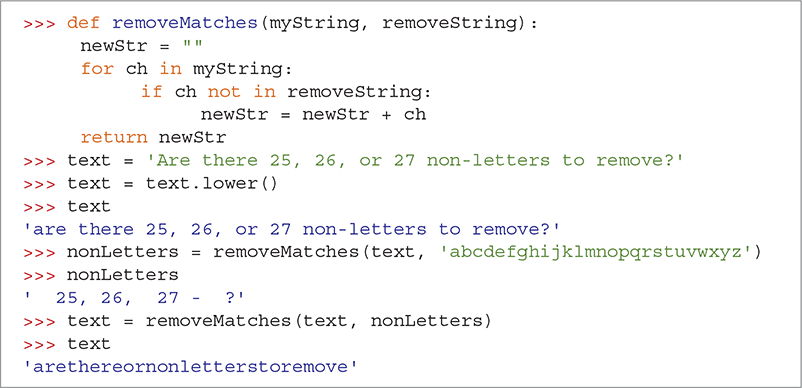
SESSION 8.3 Demonstrating removeMatches
To count all the letters of the alphabet, we will use the dictionary technique we introduced in the Introducing the Python Collections chapter to keep track of the frequency of numbers. The key for each entry in the dictionary is the letter. To build our dictionary, we will simply iterate over all the characters in a string. The dictionary will initially keep track of the number of times each character occurs in the string. After all the counts have been tallied, we will make a second pass through the dictionary and convert the counts into percentages. LISTING 8.4 shows the Python code for the letter-counting function.

LISTING 8.4 Counting the frequency of each letter in the alphabet
Let’s look at a session where we calculate the text frequencies of the letters in H. G. Wells’s War of the Worlds, a novel that is free from copyright and freely downloadable from Project Gutenberg (http://www.gutenberg.org). Project Gutenberg asks that we print this notice with the mention of its book:
This eBook is for the use of anyone anywhere in the United States and most other parts of the world at no cost and with almost no restrictions whatsoever. You may copy it, give it away, or reuse it under the terms of the Project Gutenberg License included with this eBook or online at www.gutenberg.org. If you are not located in the United States, you’ll have to check the laws of the country where you are located before using this eBook.
We will save the .txt version of the book as wells.txt. You may note when you download this book that the .txt file is in UTF-8 format. Thus, to read this file, we need to specify the encoding format in the open function using the encoding keyword parameter. We use the value 'utf-8' for the text format.
After opening the file, we use the read method to read in the entire file from disk as one string. We then use our letterFrequency function to compute the relative frequencies of each letter. SESSION 8.4 demonstrates the use of letterFrequency.
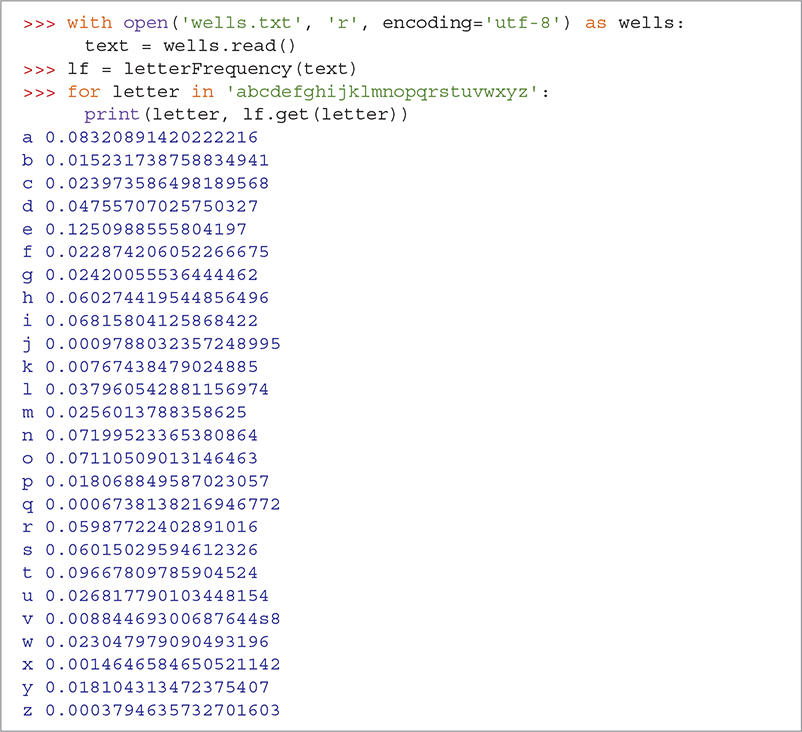
SESSION 8.4 Letter frequency for War of the Worlds
Of course, it would be much more interesting to see the information sorted from most frequent letter to least frequent. To do this, we will first extract the information from the dictionary into a list, and then sort the list. We can extract all the key–value pairs from a dictionary using the items method along with the list function. For example, the first three elements in the list returned by items in our letter frequency dictionary are as follows:

Note that the order of the items in the dictionary is the same as the order in which the keys were entered. As you can see, the first three letters of the book are “the.”
The sort function for lists, as shown in TABLE 8.4, is extremely powerful. Let’s see how we can use it to sort this list from most to least frequently used letter. The first question you might ask is, How does the sort function know which value to use when it sorts this list? Remember, a list can contain any Python object, so the sort function must be able to sort any kind of object. In this case, the elements on our list are tuples, so the sort function defaults to using the first element of the tuple. Fortunately, the sort function takes some optional keyword parameters that make it more flexible.
TABLE 8.4 The |
||
|---|---|---|
| Method | Use | Explanation |
sort(key = None, reverse = False) |
list.sort(key = sortKey, reverse = True) |
Performs an in-place sort of the list—that is, the list is modified. Keyword Parameters: key: specifies a function to use for comparing items; default is None, which means to sort on the first elementreverse: specifies whether the list should be sorted in reverse (high to low); default is low to high (False) |
Two keyword parameters for the sort method are key and reverse, as explained in Table 8.4. If we call sort with the keyword parameter reverse set to True, the sort function will sort the list from largest to smallest value, instead of the other way around. SESSION 8.5 demonstrates a reverse sort on a simple list of integers.

SESSION 8.5 Sorting a list in reverse
The keyword parameter, key, enables us to write a function that takes one object as a parameter and returns a value from that object that we should use as the sort key for that object. For example, suppose we had a list of turtles that we wanted to sort according to the x coordinate of each turtle. In this scenario, our function would return the x value for the turtle. In the case of our dictionary, we want to write a function that can return the frequency number from a tuple. This is a very short two-line function, as shown in LISTING 8.5.

LISTING 8.5 Returning the second value in a tuple
Using the getFreq method along with the key and reverse parameters, we can now sort our letter frequency dictionary from highest frequency to lowest (see SESSION 8.6). The sort method implements an in-place sort—that is, it modifies the list it is sorting. It does not create a new list, nor does it return any value. A common mistake is to write a statement such as myList = myList.sort(). Try this for yourself, and you will see that unfortunately myList has been set to None rather than being sorted.


SESSION 8.6 Sorted letter frequency from War of the Worlds
8.4.2 Ciphertext Frequency Analysis
Letter popularity is critical for breaking a substitution cipher. Because a substitution cipher makes a one-for-one letter substitution from the plaintext to the ciphertext, the most popular letter in the plaintext will also be the most popular letter in the ciphertext. This small amount of information is enough to begin breaking the encryption through frequency analysis.
Let’s do a bit of cryptanalysis on the following paragraph:
ul ilahvble jkhbevbt hk kul letl cs kul dvk kuhk kul kuvbt uhe ahel sci vkjlzs jkhivbt hk vkj jkihbtl hddlhihbwl hjkcbvjule wuvlszq hk vkj mbmjmhz juhdl hbe wczcmi hbe evazq dliwlvnvbt lnlb kulb jcal lnvelbwl cseljvtb vb vkj hiivnhz kul lhizq acibvbt ohj ocbelismzzq jkvzz hbe kul jmb xmjk wzlhivbt kul dvbl killj kcohiej olqgivetl ohj hzilheq ohia ul eve bck ilalagli ulhivbt hbq gviej kuhk acibvbt kulil ohj wlikhvbzq bc gillrl jkviivbt hbe kul cbzq jcmbej olil kul shvbk acnlalbkj sica ovkuvb kul wvbeliq wqzvbeli ul ohj hzz hzcbl cb kul wcaacb
The first step in breaking this code is to apply our letter frequency analysis to the encrypted text. TABLE 8.5 shows the results.
TABLE 8.5 Relative Frequency of Letters in the Ciphertext |
|---|
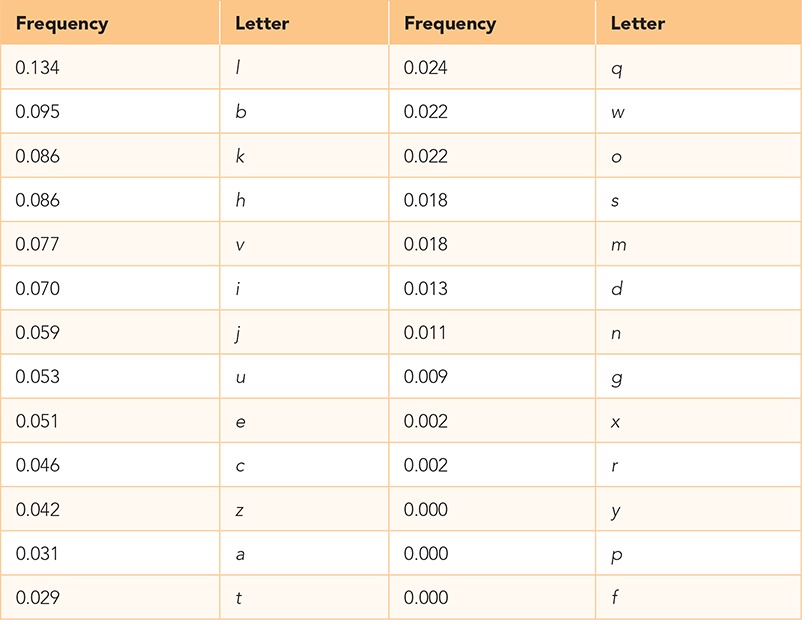
|
One approach would be to hope that we find an exact match in the frequencies of letters between the plaintext sample and the ciphertext. If this were the case, we could figure out the key by matching the letters in order of their popularity: e ↔ l, t ↔ b, a ↔ k, n ↔ h, and so on. Using these letter substitutions, the first line of ciphertext would be decrypted as follows: “se ieunoter hantrotm na ase erme df ase yoa asna ase asotm snr unre fdi oahelf haniotm na oah haintme.” Clearly, a blind mapping is not the answer.
8.4.3 Letter Pair Analysis
Because the frequency of letters is bound to vary to some extent (particularly in smaller samples), we need to try to match the letters with a bit more flexibility. Let’s begin by assuming that the four most popular plaintext letters will match the four most popular ciphertext letters in some order. For example, a ciphertext 'l' will be either 'e', 't', 'n', or 'a'. Likewise, the ciphertext letters 'b', 'k', and 'h' will match one of 'e', 't', 'n', or 'a'.
Notice that two of the four most popular plaintext letters are vowels and two are consonants. One way that we can statistically tell the difference between a vowel and a consonant is to notice that vowels frequently appear before or after almost any other letter in the alphabet. Consonants typically have a small number of letters that they appear next to. This suggests that we can write a variation of our letter frequency function to figure out how frequently each letter appears next to another letter.
Although this may seem like a daunting task, it is important to understand that if we start with our basic letter frequency function, we have already made a great deal of progress toward our goal. Let’s look at the additional problems we need to solve:
Rather than count the number of times each letter occurs, we want to keep a list of neighboring letters. This list will contain all the letters that appear before or after the letter in question.
The output of the function will be a dictionary that contains a key for each letter of the alphabet and a list of neighboring letters.
We need to be careful about how we account for nonletters in our counting. If we simply delete nonletters as we did previously, we will end up creating false neighbors.
Once again, we want to keep track of some information that is indexed by a letter—which again suggests that we will use a dictionary. The difference is that we need to keep track of something more complicated than a simple number. The good news is that dictionaries can store any Python object as a value. To keep track of a character’s neighbors, we use that character as the key and store a list of neighboring characters as the value. For example, if our dictionary is called myNeighbors, then myNeighbors['q'] will evaluate to the list of letters that occur next to 'q'. For example, in one large text, the letter 'q' appears next to the letters ['u', 'e', 'o', 's', 'n', 'd', 'i', 'h', 'a', 'c'].
Once we know that we will use a list for keeping track of the neighbors, the next problem is easy to solve. We can use the len function to find the length of our list of neighbors after we have processed all the characters in the string.
Thus, our new function will include the following steps:
Create an empty dictionary
nbDict.Loop over all the characters in a string.
If the current character is not in
nbDict, add an empty list. Otherwise, retrieve the list of neighbors already stored.Add the next character as a neighbor of the current character.
If the next character is not in
nbDict, add an empty list. Otherwise, retrieve the list of neighbors already stored.Add the current character as a neighbor of the next character.
Loop over all the keys of the dictionary, and replace the list with the length of the list.
Return the dictionary.
A couple of ideas in this overview of the new function are worth considering. First, notice that when we are looking at the character at index i in the character string, we add the character at index i+1 as a neighbor. At the same time, we add the character at index i as a neighbor of the character at index i+1. In this way, we can ensure that as we move through the list we are getting the neighboring characters that occur both before and after each character.
Second, we need to be careful about which characters we add to the list of neighbors. If a letter is already on the neighbor list, we do not want to add it again. In addition, since we do not wish to count spaces, punctuation marks, numbers, or any other nonletter as neighbors, we will ignore those characters. The easiest way to make sure that we are counting only letters is to check whether the character is one of the 26 letters of the alphabet. To do this, we write a little function that takes two parameters: a character and a list. Let’s call this function maybeAdd. LISTING 8.6 shows the complete function to add a character to a list under the conditions just described.

LISTING 8.6 Conditionally adding a character to a list
The maybeAdd function is a good example of a function that modifies one of its parameters. Notice that we pass a list as a parameter, but instead of returning the list, the function appends the character directly to the list. This simplifies the process of adding characters to the list item in the dictionary.
SESSION 8.7 shows the maybeAdd function in action.

SESSION 8.7 Testing the maybeAdd function
LISTING 8.7 shows the complete neighborCount function. There are several interesting things to think about in regard to this function. First, we use the statement
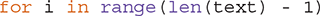
rather than iterating over each character in the string, because we need to index the current character as well as the next character. If we simply used len(text), we would eventually get an “index out of range” error.

LISTING 8.7 Creating a dictionary of neighbors
Another statement to look at carefully is
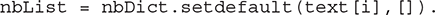
The setdefault method first checks whether the key is in the dictionary. If it is not, it adds the default value and returns a reference to the default value, which is then assigned to the list of neighbors. The setdefault method is described in TABLE 8.6.
TABLE 8.6 The |
||
|---|---|---|
| Method | Use | Explanation |
setdefault(key, default) |
value = nDict.setdefault(dict[i], defaultValue) |
If the key is not in the dictionary, insert key with a value of default and return default. If the key is in the dictionary, return the value for the key. |
The statement given in the preceding paragraph is a shortcut for the Python code shown in LISTING 8.8.

LISTING 8.8 Adding a new default value to a dictionary
This pattern is quite common when using dictionaries. Using the setdefault method is a good idea because it reduces the amount of code you need to write and reduces your chances of making an error.
Now we will use the neighborCount function to continue our analysis of the ciphertext. SESSION 8.8 shows the neighborCount function in action. After building the dictionary freqDict, we print the number of neighbors for the commonly used letters 'e', 'n', and 't'.

SESSION 8.8 Number of neighbors for e, n, and t
As we can see in Session 8.8, e appears next to 26 different letters, n appears next to 25 different letters, and t appears next to 21 different letters. We were hoping for a result that would allow us to easily differentiate between vowels and consonants. Unfortunately, this is not it. For these counts to be more useful, we need a bit more detail. For example, e probably appears frequently next to many different letters, whereas n and t may appear next to some letters very frequently and next to other letters infrequently. We need to see the frequency with which different letters appear next to each other. What we need to build is a table like that shown in TABLE 8.7.
TABLE 8.7 Letter-Pair Frequency Analysis |
|---|

|
Let’s improve neighborCount so we can produce a table of letter-pair frequency counts. This may allow us to learn enough to make better guesses about which letters are vowels and which are consonants. The most important change we will make is to replace the list of letters with a dictionary so that we can keep a count for each neighboring letter. In doing so, we will create a dictionary of dictionaries. As an example, d['a']['x'] tells us the number of times that the letters 'a' and 'x' appear next to each other.
The necessary modifications are actually quite simple. In the neighborCount function, we need to change only the calls to setdefault to create a dictionary instead of an empty list. We do this by changing [] to {} for the default value and removing the second for loop that replaces the letters with a count.
Another change occurs in the maybeAdd function, which now updates a count of each neighboring letter in a dictionary rather than simply appending a letter to a list. LISTING 8.9 shows the new version of neighborCount and maybeAdd. Once again, the setdefault function simplifies the implementation of the maybeAdd function.

LISTING 8.9 New addMaybe and neighborCount functions
SESSION 8.9 shows the result of calling the neighborCount function on the entire book. Let’s look at what we can learn about the letters e, n, and t. It seems that e appears more frequently next to a very large number of letters. In addition, although both n and t appear next to many different letters, they do so much less frequently. Also note that e appears least frequently next to other vowels and several consonants such as z and q.

SESSION 8.9 Testing the new neighborCount function
As shown in Session 8.9, the data is quite difficult to interpret. Although we can present the data as shown in Table 8.7, a better way to get an idea of how the letter pairs work out is to create a histogram. FIGURE 8.2 shows a histogram that compares the frequencies with which letters a, e, n, and t occur with the frequencies for all the other letters of the alphabet. This plot was produced with the matplotlib module of Python. This histogram readily shows us that e and a appear more frequently with more other letters.
FIGURE 8.2 Letter-pair frequencies for a, e, n, and t.
The histogram in FIGURE 8.3 is for the ciphertext paragraph presented earlier in this chapter and corresponds to TABLE 8.8. You can see that l and h are vowels because they appear more frequently with more letters. The letters k and b are consonants. But which of these ciphertext characters is a and which is e?
FIGURE 8.3 Letter frequency in the ciphertext example.
TABLE 8.8 Frequency Pairs for the Four Most Common Ciphertext Letters |
|---|
|
We have three pieces of evidence that help us make a good guess about the letter l. First, it was the most common letter in the ciphertext paragraph. Second, our letter-pair analysis indicates that l is a vowel because it appears relatively frequently with many other letters. Finally, we can see that the letter l appears next to itself four times but the letter h never appears next to itself. Since it is much more common for e to appear next to itself than the letter a does (unless you are writing a thesis about aardvarks), we can probably conclude that l maps to e and h maps to a.
Now that we have two letter mappings in place, let’s plug them into the ciphertext and see if that gives us any clues that will help decrypt the letters b and k. We can use the Python string replace method to help us replace the ciphertext letters with the plaintext letters we have figured out. SESSION 8.10 shows how to replace the ciphertext l with E and h with A. We will use uppercase for the decoded plaintext letters to make it clear which letters we have decoded and which we still need to work on.

SESSION 8.10 First character replacement
8.4.4 Word Frequency Analysis
We have made some progress, but we still have more work to do. Let’s employ another cryptanalysis technique to help with the next step. This technique will look at the short words—namely, the words that are one, two, or three letters long.
An easy way to do this is to reorder the words in the ciphertext and sort them by their length. Recall that the sort function can accept a key function as a parameter. LISTING 8.10 shows a Python function that accepts one word as a parameter and returns the length of the word. SESSION 8.11 illustrates the use of our sortByLen function and provides us with some interesting new clues.

LISTING 8.10 Function to compare two words by length

SESSION 8.11 Sorting ciphertext words by length
The new clues from Session 8.11 are that the word Ak appears three times, uE appears three times, Abe appears four times, and kuE appears 10 times. So we might ask these questions:
What are some popular three-letter words?
Which three-letter words end in “e” since the E in kuE is in place?
Which three-letter words begin with “a” since the A in Abe is in place?
Try It Out exercise 8.15 at the end of this section asks you to write a function that reads a string and prints a list of words that are of a given length, ordered from most popular to least. If you run such a function on the text of War of the Worlds, you would produce TABLE 8.9. Now the choices for the letters k and u become clear. Since the most popular three-letter word is the and it is the only such word in the top 10 that ends in e, it is a pretty safe assumption that kuE corresponds to the word THE. In addition, since and is the second most popular three-letter word, we can also make the assumption that b maps to N and e maps to D. SESSION 8.12 shows what happens when we make these four additional substitutions.
TABLE 8.9 Three-Letter Word Frequency Counts |
|
|---|---|
| Word | Count |
| the | 4959 |
| and | 2555 |
| was | 851 |
| had | 579 |
| for | 369 |
| but | 295 |
| his | 250 |
| out | 231 |
| all | 225 |
| not | 212 |

SESSION 8.12 Second replacement, using word frequency
As a bonus, in addition to and and the, other words such as that, at, had, and then also now appear. Considering that we have mapped only six letters, this result is promising. In fact, you can probably make some additional guesses based on what you see.
Referring back to the three-letter frequency counts in Table 8.9, let’s try to decrypt a few more letters. First, we might notice that another popular three-letter word appearing in the partially decrypted ciphertext is the word oAj. Looking at our list of popular three-letter words, we see that was is the third most popular word. In addition, was has an a in the middle position. Scanning through the rest of the ciphertext, we notice that many words end in j. Of course, s is a very popular letter at the end of words because it makes a word plural. Once again, you can write a function to find out which letters appear most frequently at the end of a word. It is highly likely you would find that s appears most frequently at the end of a word. If we use the new mappings, o maps to W and j maps to S, we now find that our ciphertext looks like the following:
HE iEaAvNED STANDvNt AT THE EDtE cs THE dvT THAT THE THvNt HAD aADE sci vTSEzs STAivNt AT vTS STiANtE AddEAiANwE ASTcNvSHED wHvEszq AT vTS mNmSmAz SHAdE AND wczcmi AND Dvazq dEiwEvnvNt EnEN THEN ScaE EnvDENwE cs DESvtN vN vTS AiivnAz THE EAizq aciNvNt WAS WcNDEismzzq STvzz AND THE SmN xmST wzEAivNt THE dvNE TiEES TcWAiDS WEqgivDtE WAS AziEADq WAiaHE DvD NcT iEaEagEi HEAivNt ANq gviDS THAT aciNvNt THEiE WAS wEiTAvNzq Nc giEErE STviivNt AND THE cNzq ScmNDS WEiE THE sAvNT acnEaENTS sica WvTHvN THE wvNDEiq wqzvNDEi HE WAS Azz AzcNE cN THE wcaacN
We can get two more letters with another observation. Look at the last three letters of each word and notice that several end in vNt. In fact, ten words end in the pattern vNt. A common English language suffix for words is ing. This gives us the vowel i, which means that we now know the mappings for the vowels a, e, and i.
At this point, we can also make an educated guess that the word cs in the ciphertext is probably of. The pair frequency profile of c fits that of a vowel, and the word of makes the most sense in the context of the phrase “STANDING AT THE EDGE cs THE dIT.”
Finally, let’s make one more substitution before looking at the whole text again. There is another common letter in the ciphertext that we have not decoded yet: “z”. Notice that we have partially decoded the three-letter word Azz. The only three-letter word in our top 10 that has a double letter is the word all, so it is a good bet that z maps to L.
HE iEaAINED STANDING AT THE EDGE OF THE dIT THAT THE THING HAD aADE FOi ITSELF STAiING AT ITS STiANGE AddEAiANwE ASTONISHED wHIEFLq AT ITS mNmSmAL SHAdE AND wOLOmi AND DIaLq dEiwEInING EnEN THEN SOaE EnIDENwE OF DESIGN IN ITS AiiInAL THE EAiLq aOiNING WAS WONDEiFmLLq STILL AND THE SmN xmST wLEAiING THE dINE TiEES TOWAiDS WEqgiIDGE WAS ALiEADq WAiaHE DID NOT iEaEagEi HEAiING ANq gIiDS THAT aOiNING THEiE WAS wEiTAINLq NO giEErE STIiiING AND THE ONLq SOmNDS WEiE THE FAINT aOnEaENTS FiOa WITHIN THE wINDEiq wqLINDEi HE WAS ALL ALONE ON THE wOaaON
We have made good progress, finding the mappings for 12 letters with only 14 more letters to fill in. TABLE 8.10 shows the letters we have identified and those letters we have yet to decode. We could continue to make some deductions about which letters go where. But let’s look at another way we can use Python to help us by doing some automated pattern matching—a common application for computers.
TABLE 8.10 Progress on Mapping the Letters |
|---|

|
8.4.5 Pattern Matching with Partial Words
We would like to be able to select a word from the partially decoded ciphertext and ask the program to find a word from the dictionary that is the same length and matches the letters that we have decoded so far. It turns out that humans are pretty good at the task of pattern matching. For example, given the template aADE, you can probably come up with the words MADE, FADE, and WADE. Some of those would work for us; others would not. For example, FADE would not work for us because F has already been decoded. Ideally, we would like to give the function the set of letters that are legal to use when matching the coded parts of the words. If the computer finds only one match, we can then be fairly confident that we have decoded some additional letters.
Most modern programming languages provide a pattern-matching library that uses regular expressions. In Python, regular expressions are available through the re module, which we need to import to use regular expressions. Regular expressions are extremely useful and powerful programming tools. We will just barely scratch the surface of their application in this section, but we will see how even a simple use of regular expressions can make the final decryption step easier.
Regular expressions allow us to see if two strings match, much as when we use the == operator, except that in regular expressions we can use wildcard characters as part of the match. For example, we can test whether the string .ADE matched FADE. When using regular expressions, the . character is a wildcard that matches any character. The regular expression function that we use to test whether two strings match is called match. The match function takes two parameters: a regular expression and the string we want to match against. SESSION 8.13 illustrates the use of the match function, as well as some simple pattern matching.

SESSION 8.13 Trying regular expression matches
If two strings match, the match function returns a match object. At this point, we can just think of that object as being our indication of success. As you learn to use more advanced regular expressions, you will use the match object for more interesting purposes. If the two strings do not match, the match function returns None. This allows us to use re.match as a condition in an if statement.
Because we want to be more specific in our matches at this point, we should learn some additional regular expression syntax. Within a regular expression, the square brackets ([]) allow us to define a set of characters, any one of which may match. For example, [abc] will match a or b or c, but not any other character. In addition, we can use the + character to match multiple instances of a character. For example, [abc]+ will match a or b or c or abc or aaaaaaa or bbbb or aaabbbccc or any other combination of the letters abc. You read the + character to mean “one or more,” so we say that the regular expression [abc]+ means “match one or more instances of the characters a, b, or c.”
You may also have noticed that ('.ADE', 'FADER') matched 'FADE'. This is because FADE appears enclosed within FADER. The regular expression matcher starts at the beginning and tries to match the whole regular expression. If we want the pattern to come at the end of the string, we end our pattern with a $. In the third example in Session 8.13, the $ in the pattern means that ADE must come at the end of the string to be a match.
Table 8.10 showed that we have not decoded B, C, J, K, M, P, Q, R, U, V, W, X, Y, or Z. When we check for matches in the dictionary, we can use the regular expression [BCJKMPQRUVWXYZ] to limit our choices for a particular letter position to match only those characters. The call to match for the example we have been using would be

Because F is not one of the characters inside the square brackets, this call would fail and return None. However,

would be successful and return a match object because M is one of the characters in the brackets.
Let’s write a Python function that uses the regular expression module to create a list of all the words in the dictionary file that match a given regular expression. The basic form of our function is really quite simple: We use a loop to read through all the words in the dictionary, trying to match each word against the regular expression. If a word matches, we add it to the list. If the word does not match, we ignore it. When we have tested all the words, we return the list that we constructed. The code for this matching function, called checkWord, is shown in LISTING 8.11.

LISTING 8.11 Matching words from the dictionary against patterns
SESSION 8.14 uses the checkWord function to see if we can identify more letters. Our partially decoded message includes the string aOiNING. Using the pattern '.o.ning', the checkWord function matches the word morning from the dictionary. The second example uses a pattern that explicitly restricts the possible matches to our list of unmapped characters. The rest of Session 8.14 finds matches for some additional words.
SESSION 8.14 Using checkWord to find matches
Constructing the pattern string for the checkWord parameter is quite tedious, but we can reduce the amount of work necessary by making the checkWord function more intelligent. To do so, let’s pass two parameters to the checkWord function: a string of unused letters and the word from the partially decoded ciphertext. As a consequence, letters to keep in place will (initially) be capitalized, and letters that we can match from the unused group will be in lowercase.
We can use the re module’s replace function (called re.sub) to substitute for all of the lowercase characters using the group of letters we want to match. Line 5 of LISTING 8.12 shows the use of the re.sub function. Notice that we can use a simplified pattern to represent all the lowercase characters. The pattern [a-z] is the same as typing [abcdefghijklmnopqrstuvwxyz].

LISTING 8.12 checkWord construction of a regular expression
The syntax for the re.sub function is as follows:
The re.sub function finds each instance of pattern in target string and replaces it with replacement string. We have added a print statement to the checkWord function so that you can see the final version of the regular expression constructed by checkWord.
SESSION 8.15 illustrates the new checkWord function in action. But as you can see, we could make one more improvement: checkWord could tell us the ciphertext to plaintext mapping for the letters that complete the match. In fact, regular expressions allow us to do this very nicely by using match objects and capture groups, which help us learn which characters in the target word matched letters in different parts of our pattern. To create a capture group, you surround some part of the regular expression with left and right parentheses. For the example, the regular expression 'F(..)L(..)$' will match any word that starts with an F followed by any two letters, followed by an L followed by two more letters. Thus, words like FUELED, FOILED, and FOOLER would all match.

SESSION 8.15 Using the new checkWord to find matches
SESSION 8.16 illustrates the use of capture groups in regular expressions. Let’s suppose that we matched the word FOILED. The first capture group corresponds to the first set of parentheses, so the letters in the capture group would be OI. The second capture group would contain the letters ED. The match object allows us to get capture groups by number, using the group method, or to get all the capture groups as a list using the groups method.

SESSION 8.16 Demonstrating capture groups
Now that you have some idea of how capture groups work with regular expressions, we will use capture groups to create a list of character maps that show us which characters we can substitute for the ciphertext characters. We begin with the checkWord function and add this new feature. There are three key differences between the new version and the old one:
We create a list of the lowercase ciphertext letters in our original pattern.
We add capture groups to the regular expression.
When we get a matching word, we save the matching letters from the capture groups along with their ciphertext equivalents.
LISTING 8.13 shows the entire new version of checkWord, now called findLetters. Let’s look at the lines that differ significantly from the old checkWord function. First, we want to create a list of all the lowercase ciphertext letters in the partially decrypted word (pattern). You could write a loop to do this and build this list yourself by checking one letter at a time. However, the re module has a findall function that does exactly this job for us. It returns a list of all the substrings of a string that match a particular regular expression. SESSION 8.17 demonstrates the findall function in action. Line 4 in Listing 8.13 uses the findall function to create the list of ciphertext letters.

LISTING 8.13 Showing the matching letters

SESSION 8.17 Finding all occurrences of a regular expression
We next make a very minor change to line 6 so as to add parentheses around our regular expression that matches the undecoded ciphertext letters. This change ensures that each instance of a lowercase letter in the pattern will end up in its own capture group.
Finally, lines 11–17 make use of the match object and the groups function. When a match is made against a word from the word list file, the call myMatch.groups() gives us the letters that were used to make the matching word. At this point, we have two lists that contain important information: The ctLetters list contains the original ciphertext letters and the matchingLetters list contains the plaintext letters that complete the word.
We must now match the letters from ctLetters with the corresponding letters from matchingLetters. It is easy to know which letter from ctLetters corresponds to a letter in matchingLetters because they are parallel lists. The first letter in ctLetters corresponds to the first letter in matchingLetters, and so on. Although we could write our own function that accepts two lists and puts the letters together into a new list by moving through the lists one item at a time, Python has a handy zip function that takes care of this step for us. The zip function takes two lists and “zips” them together, matching the first item from list1 with the first item from list2, and so on. TABLE 8.11 explains the zip built-in function, and SESSION 8.18 illustrates how zip works.
TABLE 8.11 The |
||
|---|---|---|
| Method | Use | Explanation |
zip(list1, list2, …) |
tList = list(zip(listA, listB)) |
Iterator that returns tuples composed of parallel elements of each list |

SESSION 8.18 Using the zip function to create a list of tuples
SESSION 8.19 shows how the findLetters function can help us finish decoding the ciphertext. On the first line, findLetters searches for the mappings that use the partially decrypted word 'AiiInAL'. We discover that 'arrival' is a good match for 'AiiInAL'. The third line of the session shows us that the ciphertext letter i maps to the plaintext letter R and that n maps to the plaintext letter V.
SESSION 8.19 Demonstrating the findLetters function
Additional calls to findLetters give us the mappings for m, g, i, r, q, and n. Now a message is really starting to show. With just a few more substitutions we will have the entire message decoded.
HE REaAINED STANDING AT THE EDGE OF THE dIT THAT THE THING HAD aADE FOR ITSELF STARING AT ITS STRANGE AddEARANwE ASTONISHED wHIEFLY AT ITS UNUSUAL SHAdE AND wOLOUR AND DIaLY dERwEIVING EVEN THEN SOaE EVIDENwE OF DESIGN IN ITS ARRIVAL THE EARLY aORNING WAS WONDERFULLY STILL AND THE SUN xUST wLEARING THE dINE TREES TOWARDS WEYBRIDGE WAS ALREADY WARaHE DID NOT REaEaBER HEARING ANY BIRDS THAT aORNING THERE WAS wERTAINLY NO BREEZE STIRRING AND THE ONLY SOUNDS WERE THE FAINT aOVEaENTS FROa WITHIN THE wINDERY wYLINDER HE WAS ALL ALONE ON THE wOaaON
From here we need only a few more substitutions to complete the message, as shown in SESSION 8.20. In the first call to findLetters, we find matches in common and pompon. Since common is more likely to be a word in the ciphertext, we choose to substitute C for w. If we later find this is not correct, we could substitute P for w. In both words, we find that a maps to M. This makes for a high confidence level for that substitution.
SESSION 8.20 The last substitutions
HE REMAINED STANDING AT THE EDGE OF THE PIT THAT THE THING HAD MADE FOR ITSELF STARING AT ITS STRANGE APPEARANCE ASTONISHED CHIEFLY AT ITS UNUSUAL SHAPE AND COLOUR AND DIMLY PERCEIVING EVEN THEN SOME EVIDENCE OF DESIGN IN ITS ARRIVAL THE EARLY MORNING WAS WONDERFULLY STILL AND THE SUN JUST CLEARING THE PINE TREES TOWARDS WEYBRIDGE WAS ALREADY WARM HE DID NOT REMEMBER HEARING ANY BIRDS THAT MORNING THERE WAS CERTAINLY NO BREEZE STIRRING AND THE ONLY SOUNDS WERE THE FAINT MOVEMENTS FROM WITHIN THE CINDERY CYLINDER HE WAS ALL ALONE ON THE COMMON
TABLE 8.12 shows the final key that maps the ciphertext letters to the plaintext letters. Notice that the keyGen function we wrote earlier was used to create the key from the password hgwells.
TABLE 8.12 Final Mapping of the Letters |
|---|

|
8.4.6 Regular Expression Summary
We conclude this section with a summary of the regular expression syntax (TABLE 8.13) and the functions we used from the re module (TABLE 8.14).
TABLE 8.13 Simple Regular Expression Syntax |
|
|---|---|
| Expression | Meaning |
. |
Match any character. |
[abc] |
Match a or b or c. |
[^abc] |
Match any character other than a or b or c at the beginning of the string. |
[abc]+ |
Match one or more occurrences of the characters abc—for example, b or aba or ccba. |
[abc]* |
Match zero or more occurrences of the characters abc—for example, b or aba or ccba. |
| (regex ) | Create a capture group. |
$ |
Match at the end of the string. |
TABLE 8.14 Regular Expression Module Functions |
||
|---|---|---|
| Method | Use | Explanation |
match(pattern,string) |
re.match( '[abc]XY.', 'myString') |
Matches any string in myString that starts with a, b, or c followed by XY followed by any character. Returns a Match object on success or None. |
sub(pattern, replacement, string) |
re.sub('[tv]', 'X', 'vxyzbgtt') |
Returns 'XxyzbgXX'. Like replace, except uses regular expression matching. |
findall(pattern,string) |
re.findall('[bc]+','abcdefedcba') |
Returns ['bc','cb']. Returns a list of all substrings matching the regular expression. |
groups() |
matchObj.groups() |
Returns a tuple of all capture groups matched. matchObj is created by a call to match. |
group(i) |
matchObj.group(2) |
Returns a single capture group at index i. matchObj is created by a call to match. |