
The GROUP BY Clause
A Brief Overview
Use the GROUP BY clause to group your
data for summarization. You can use the GROUP BY clause to do the
following:
-
classify the data into groups based on the values of one or more columns.
-
group multiple columns, or separate the column names with commas within the GROUP BY clause. You can use aggregate functions with any of the columns that you select.
Note: If you specify a GROUP BY
clause in a query that does not contain a summary function, your clause
is changed to an ORDER BY clause, and a message is written to the
SAS log.
To summarize data, you can use the following summary
functions with PROC SQL. Notice that some functions have more than
one name to accommodate both SAS and SQL conventions. Where multiple
names are listed, the first name is the SQL name.
Note: The summary functions listed
below are limited for the purposes of this book.
|
AVG, MEAN
|
mean or average of values
|
|
COUNT, FREQ, N
|
number of nonmissing
values
|
|
CSS
|
corrected sum of squares
|
|
CV
|
coefficient of variation
(percent)
|
|
MAX
|
largest value
|
|
MIN
|
smallest value
|
|
NMISS
|
number of missing values
|
|
PRT
|
probability of a greater
absolute value of student's t
|
|
RANGE
|
range of values
|
|
STD
|
standard deviation
|
|
STDERR
|
standard error of the
mean
|
|
SUM
|
sum of values
|
|
T
|
student's t value
for testing the hypothesis that the population mean is zero
|
|
USS
|
uncorrected sum of squares
|
|
VAR
|
variance
|
PROC SQL calculates
summary functions and writes output results in different ways, depending
on a combination of factors. Here are four key factors:
-
whether the summary function specifies one or multiple columns as arguments
-
whether the query contains a GROUP BY clause
-
if the summary function is specified in a SELECT clause, whether there are additional columns listed that are outside a summary function
-
whether the WHERE clause, if there is one, contains only columns that are specified in the SELECT clause
GROUP BY Clause Syntax
|
Syntax, GROUP BY clause:
PROC SQL <options>;
SELECT column-1 <,...column-n>
FROM input-tables
WHERE expression
GROUP
BY column-name <,column-name>;
QUIT;
|
Example: Determine Total Number of Miles Using the SUM Function
Suppose you want to
determine the total number of miles traveled by frequent-flyer program
members in each of three membership classes (Gold, Silver, and Bronze).
Frequent-flyer program information is stored in the table Certadv.Frequentflyers.
To summarize your data, you can submit the following PROC SQL step:
proc sql; select membertype, sum(milestraveled) as TotalMiles /*1*/ from certadv.frequentflyers group by membertype; /*2*/ quit;
| 1 | The SUM function totals the values of the MilesTraveled column to create the TotalMiles column. |
| 2 | The GROUP BY clause groups the data by the values of MemberType. |
The results show total
miles by membership class (MemberType).
Output 1.11 PROC SQL Query Result: Total Number of Miles by MemberType

Number of Argument and Summary Function Processing
Summary
functions specify one or more arguments in parentheses. In the examples
shown in this chapter, the arguments are always columns in the table
being queried.
Note: The ANSI-standard summary
functions, such as AVG and COUNT, can be used only with a single argument.
The SAS summary functions, such as MEAN and N, can be used with either
single or multiple arguments.
The following table
shows how the number of columns that are specified as arguments affects
the way that PROC SQL calculates a summary function.
Summary
Function Processing
|
Summary Function Behavior
|
Calculation
|
Sample Code and Result
|
|
|---|---|---|---|
|
specifies one column
as argument
|
performed down the column
|
proc sql;
select sum(boarded), sum(transferred),sum(nonrevenue)
as Total
from certadv.marchflights;
quit;
 |
|
|
specifies multiple columns
as arguments
|
performed across columns
for each row
|
proc sql;
select sum(boarded,transferred,nonrevenue)
as Total
from certadv.marchflights;
quit;
 |
|
Groups and Summary Function Processing
Summary functions perform calculations on groups of
data. When PROC SQL processes a summary function, it looks for a GROUP
BY clause:
|
GROUP BY Clause Presence
|
PROC SQL Behavior
|
Example
|
|---|---|---|
|
is not present in the
query
|
applies the function
to the entire table
|
proc sql;
select jobcode, avg(salary)
as AvgSalary
from certadv.payrollmaster;
quit;
|
|
is present in the query
|
applies the function
to each group specified in the GROUP BY clause
|
proc sql;
select jobcode, avg(salary)
as AvgSalary
from certadv.payrollmaster
group by jobcode;
quit;
If a query contains
a GROUP BY clause, all columns in the SELECT clause that do not contain
a summary function should typically be listed in the GROUP BY clause.
Otherwise, unexpected results might be returned.
|
SELECT Clause Columns and Summary Function Processing
A
SELECT clause that contains a summary function can also list additional
columns that are not specified in the summary function. The presence
of these additional columns in the SELECT clause list causes PROC
SQL to display the output differently.
|
SELECT Clause Contents
|
PROC SQL Behavior
|
Example
|
|---|---|---|
|
contains summary functions
and no columns outside summary functions
|
calculates a single
value by using the summary function for the entire table. However,
if groups are specified in the GROUP BY clause, for each group it
combines the information into a single row of output for the entire
table.
|
proc sql;
select avg(salary)
as AvgSalary
from certadv.payrollmaster;
quit;
|
|
contains summary functions
and additional columns outside summary functions
|
calculates a single
value for the entire table. However, if groups are specified, for
each group it displays all rows of output within the single grouped
value. If the data in the table is grouped by more than one value,
then grouped values are repeated.
|
proc sql;
select EmpId,
jobcode,
dateofhire,
avg(salary)
as AvgSalary
from certadv.payrollmaster
group by jobcode;
quit;
|
Example: Using a Summary Function with a Single Argument (Column)
The following example illustrates
a PROC SQL query that calculates the average salary for all employees
who are listed in Certadv.Payrollmaster.
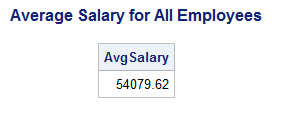
title 'Average Salary for All Employees';
proc sql;
select avg(salary) as AvgSalary
from certadv.payrollmaster;
quit;
The SELECT statement
contains the summary function AVG with Salary as its argument. Because
there is only one column as an argument, the function calculates the
statistic down the Salary column to display a single value: the average
salary for all employees.
Output 1.12 PROC SQL Query Result: Calculating Average Salary for All Employees
Example: Using a Summary Function with Multiple Arguments (Columns)
Consider a PROC SQL query
that contains a summary function with multiple columns as arguments.
This query calculates the total number of passengers for each flight
in March by adding the number of boarded, transferred, and nonrevenue
passengers:
proc sql;
select sum(boarded, transferred, nonrevenue) as Total
from certadv.marchflights;
quit;
The SELECT clause contains
the summary function SUM with three columns as arguments. Because
the function contains multiple arguments, the statistic is calculated
across the three columns for each row to produce the following output.
Output 1.13 PROC SQL Query Result: Calculating Total for 3 Arguments (partial
output)

Example: Using a Summary Function with Columns outside the Function
The following example
illustrates calculating an average for each job group. The result
is grouped by JobCode. Your first step is to add an existing code,
Jobcode, to the SELECT clause list.
proc sql;
select jobcode, avg(salary) as AvgSalary
from certadv.payrollmaster;
quit;
As this result shows,
adding a column to the SELECT clause that is not within a summary
function causes PROC SQL to display all rows instead of a single value.
To generate this output:
-
PROC SQL calculated the average salary down the column as a single value (
54079.62). -
PROC SQL displayed all rows in the output, because JobCode is not specified in a summary function.
Therefore, the single
value for AvgSalary is repeated for each row. When you submit the
query, SAS remerges the summary information with the JobCode values.
Note: The SAS log displays a message
indicating that data remerging has occurred.
Output 1.14 PROC SQL Query Result: Summary Function with Jobcode (partial
output)

Log 1.2 SAS Log
NOTE: The query requires remerging summary statistics back with the original data.
Example: Using a Summary Function with a GROUP BY Clause
Using the query from the previous example, add a GROUP
BY clause. The GROUP BY clause groups rows by JobCode, which results
in one row per JobCode value. For example, you might have multiple
JobCode values for FA2 but only one value of FA2 displayed in the
output. In the SELECT clause, JobCode is specified but is not used
as a summary function argument. Other changes to the query include
specifying a format for the AvgSalary column.
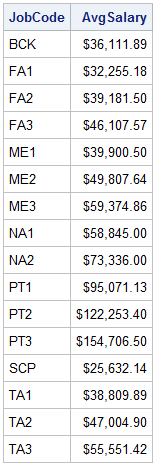
proc sql;
select jobcode, avg(salary) as AvgSalary format=dollar11.2
from certadv.payrollmaster
group by jobcode;
quit;
The summary function
has been calculated for each JobCode group, and the results are grouped
by JobCode.
Output 1.15 PROC SQL Query Result Grouped by JobCode
Counting Values by Using the COUNT Summary Function
Sometimes you want to count the number
of rows in an entire table or in groups of rows. There are three main
ways to use the COUNT function.
|
Form for COUNT
|
Result
|
Example
|
|---|---|---|
|
COUNT(*)
|
the total number of
rows in a group or in a table
|
select count(*) as Count |
|
COUNT(column)
|
the total number of
rows in a group or in a table for which there is a nonmissing value
in the selected column
|
select count(jobcode) as Count |
|
COUNT(DISTINCT column)
|
the total number of
unique values in a column
|
select count(distinct jobcode)
as Count
|
Note: When given
a column entry, the COUNT summary function counts only the nonmissing
values. Missing values are ignored. Many other summary functions also
ignore missing values. When you use a summary function with data that
contains missing values, the results might not provide the information
that you expect.
Tip
To count
the number of missing values, use the NMISS function. Example: Counting All Rows in a Table
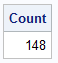
Suppose you want to know how many employees are listed
in the table Certadv. Payrollmaster. This table contains a separate
row for each employee, so counting the number of rows in the table
gives you the number of employees.
proc sql;
select count(*) as Count
from certadv.payrollmaster;
quit;
Note: The COUNT summary function
is the only function that enables you to use an asterisk (*) as an
argument.
Output 1.16 PROC SQL Query Result: Counting All Rows in Certadv.Payrollmaster
Example: Counting Rows within Groups of Data
You can also use COUNT(*)
to count rows within groups of data. To do this, you specify the groups
in the GROUP BY clause. Consider a more complex PROC SQL query that
uses COUNT(*) with grouping. This time, the goal is to find the total
number of employees within each job category, using the same table
that was used previously.
proc sql; select substr(jobcode,1,2) /*1*/ label='Job Category', count(*) as Count /*2*/ from certadv.payrollmaster group by 1; /*3*/ quit;
This query defines two new columns in the SELECT clause.
| 1 | The first column, which is labeled JobCategory, is created by using the SAS function SUBSTR. The SUBSTR function extracts the two-character job category from the existing JobCode field. |
| 2 | The second column, Count, is created by using the COUNT function. |
| 3 | The GROUP BY clause specifies that the results are to be grouped by the first defined column, which is referenced by 1 because the column was not assigned a name. |
Output 1.17 PROC SQL Query Result: Count Rows within Groups of Data

CAUTION:
Columns
should not contain missing values.
When a column contains
missing values, PROC SQL treats the missing values as a single group.
This can produce unexpected results.
Counting All Nonmissing Values in a Column
Suppose
you want to count all of the nonmissing values in a specific column
instead of in the entire table. To do this, you specify the name of
the column as an argument of the COUNT function.
If the table has no
missing data, you get the same output as you would by using COUNT(*).
However, if the variable column contained missing values, the query
would produce a lower value of Count than the number of values in
a column.
Example: Counting All Unique Values in a Column
To count all unique values
in a column, add the keyword DISTINCT before the name of the column
that is used as an argument.
proc sql;
select count(distinct jobcode) as Count
from certadv.payrollmaster;
quit;
This query counts 16
unique values for JobCode.
Output 1.18 PROC SQL Query Result: Counting Unique Values

Example: Listing All Unique Values in a Column
To display the unique
JobCode values, you can apply the method of eliminating duplicates,
which was discussed earlier. The following query lists only the unique
values for JobCode.
proc sql;
select distinct jobcode
from certadv.payrollmaster;
quit;
There are 16 job codes,
so the output contains 16 rows.
Output 1.19 PROC SQL Query Result: Displaying Distinct Values

Last updated: October 16, 2019
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.