
All of the above is not to say we won’t continue to make progress or there isn’t still work to be done in this important field. In fact, I see at least four areas, somewhat interrelated, where developments are either under way or are needed: implementation, foundations, higher level abstractions, and higher level interfaces.
In some ways the message of this book can be summed up very simply:
Let’s implement the relational model!
To elaborate: First of all, I think it’s clear from the body of the book that it’s being extremely charitable to SQL to describe it as a relational language. It follows that SQL products can be considered relational only to a first approximation. The truth is, the relational model has never been properly implemented in commercial form (at least, not in any mainstream product), and users have never really enjoyed the benefits that a truly relational product would bring. Indeed, that’s one of the reasons why I wrote this book, and it’s also one of the reasons why Hugh Darwen and I have been working for so long on The Third Manifesto. The Third Manifesto—the Manifesto for short—is a formal proposal for a solid foundation for future DBMSs. And it goes without saying that what it really does, in as careful and precise a manner as the authors are capable of, is define the relational model and spell out some of the implications of that definition. (It also goes into a great deal of detail on the impact of type theory on that model; in particular, it proposes a comprehensive model of type inheritance as a logical consequence of that type theory.)
So we’d really like to see the ideas of the Manifesto implemented properly in commercial form (“we” here meaning, primarily, Hugh Darwen and myself).[186] We believe such an implementation would serve as a solid basis on which to build so many other things—for example, “object/relational” DBMSs; spatiotemporal DBMSs; DBMSs used in connection with the World Wide Web; and “rule engines” (also known as “business logic servers”), which some see as the next generation of general purpose DBMS products. We further believe we would then have the right framework for supporting the other items that are suggested below as also being desirable. Personally, in fact, I would go further; I would suggest that trying to implement those items in any other kind of framework is likely to prove more difficult than doing it right. To quote the well known mathematician Gregory Chudnovsky: “If you do it the stupid way, you will have to do it again” (from an article in The New York Times, December 24th, 1997).
There’s still much interesting work to be done on theoretical foundations (in other words, it’s certainly not the case that all of the foundation problems have been solved). Here are three examples:
Let rx be some relational expression. By definition, the relation r denoted by rx satisfies a constraint rc that’s derived from the constraints satisfied by the relations in terms of which rx is expressed. To what extent can the process of determining that constraint rc be mechanized?
Can we inject more science into the database design process? In particular, can we come up with a precise and operationally useful characterization of the notion of redundancy? Note: The book Normal Forms and All That Jazz: A Database Professional’s Guide to Database Design Theory (see Appendix G) offers some proposals in this connection.
Can we come up with a good way—that is, a way that’s robust, logically sound, and ergonomically satisfactory—of dealing with the “missing information” problem? Note: Appendix C of the present book offers some suggestions in this regard.
One way we make progress in computer languages and applications is by raising the level of abstraction. For example, I pointed out in Chapter 5 that the familiar KEY and FOREIGN KEY specifications are really just shorthand for constraints that can be expressed more longwindedly using the general integrity features of any relationally complete language like Tutorial D. But those shorthands are useful: Quite apart from the fact that they save us some writing, they also serve to raise the level of abstraction, by allowing us to talk in terms of certain bundles of concepts that belong naturally together. In a sense, they make it easier to see the forest as well as the trees.
By way of another illustration, consider the relational algebra. I showed in Chapter 6 and Chapter 7 that many of the operators of the algebra—including ones we use all the time, even if we don’t realize it, like semijoin—are really shorthand for certain combinations of other operators.[187] In other words, what’s really going on here is again a raising of the level of abstraction (rather as macros raise the level of abstraction in a conventional programming language).
Raising the level of abstraction in the relational world can be regarded as building on top of the relational model; it doesn’t change the model, but it does make it more directly useful for certain tasks. And one area where this approach looks as if it’s going to prove really fruitful is temporal databases. In our book Temporal Data and the Relational Model (see Appendix G), Hugh Darwen, Nikos Lorentzos, and I—building on original work by Lorentzos—introduce interval types as a basis for supporting temporal data in a relational framework. For example, consider the “temporal relation” in Figure A-1 opposite, which shows that certain suppliers supplied certain parts during certain intervals of time (you can read d04 as “day 4,” d06 as “day 6,” and so on; likewise, you can read [d04:d06] as “the interval from day 4 to day 6 inclusive,” and so on). Attribute DURING in that relation is interval valued.
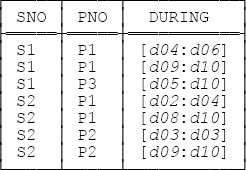
Support for interval attributes, and hence for temporal databases, involves among other things support for generalized versions of the regular algebraic operators. For reasons that aren’t important here, we call those generalized operators “U_ operators”; thus, there’s a U_restrict operator, a U_join operator, a U_union operator, and so on. But—and here comes the point—those U_ operators are all, in the last analysis, nothing but shorthand for certain combinations of regular (i.e., conventional) algebraic operators, as described in this book. Once again, then, what’s fundamentally going on is a raising of the level of abstraction.
Two further points on this topic: First, our approach to temporal data involves not just “U_” versions of the algebraic operators but also (a) “U_” keys and foreign keys, (b) “U_” comparison operators, and (c) “U_” versions of INSERT, DELETE, and UPDATE—but, again, all of these constructs turn out to be essentially just shorthand. Second, it also turns out that the Manifesto’s type inheritance model has a crucial role to play in that temporal support—and so once again we see an example of the interconnectedness of all of these issues.
There’s another way in which we can build on the relational model, and that’s by means of various kinds of applications that run on top of the relational interface and provide various specialized services. One example might be decision support; another might be data mining; another might be a natural language front end. For the users of such applications, the relational model will disappear under the covers, at least to some degree. (Though even if it does, and even if most users interact with the database only through some such front end, it seems to me that database design and the like will still necessarily be based on solid relational principles. At least, I certainly hope so.)
By the way: Suppose it’s your job to implement one of those front end applications. Which would you prefer as a target?—a relational DBMS, or some other kind (an object oriented DBMS, say)? And if you opt for the former, as I obviously think you should, which would you prefer?—a DBMS that supports the relational model as such, or one that supports SQL?
In case it’s not clear, my point is this: We’ve come a long way from the early days when SQL was being touted as a language that end users could use for themselves,[188] and I know many people will dismiss my numerous criticisms of SQL as mere carping for that very reason. Real users don’t use it anyway, right? Only programmers use it. And in any case, much of the SQL code that’s actually executed is never written by a human programmer at all but is generated by some kind of front end application. However, it seems to me that SQL is bad as a target language for all of the same reasons that it’s bad as a source language. And it further seems to me, therefore, that my criticisms are still germane.
SQL is incapable of providing the kind of firm foundation we need for future growth and development. Instead, it’s the relational model that has to provide that foundation. In The Third Manifesto, therefore, Darwen and I reject SQL as such; in its place, we argue that some truly relational language like Tutorial D should be implemented as soon as possible. Of course, we aren’t so naïve as to think that SQL will ever disappear. Rather, we hope that Tutorial D, or some other true relational language, will be sufficiently superior that it will become the database language of choice (by a process of natural selection), and SQL will become “the database language of last resort.” In fact, we see a parallel with the world of programming languages, where COBOL has never disappeared (and never will); but COBOL has become “the programming language of last resort” for developing applications, because better alternatives exist. We see SQL as a kind of database COBOL, and we would like to see some other language become available as a better alternative to it.
To say it again, we do realize that SQL databases and applications are going to be with us for quite a long time—to think otherwise would be quite unrealistic—and so we do have to pay some attention to the question of what to do about today’s SQL legacy. The Manifesto therefore does include some specific proposals in this regard. In particular, it offers some suggestions for implementing SQL on top of a true relational language, so that existing SQL applications can continue to work. Detailed discussion of those proposals would be out of place here; suffice it to say, however, that we believe we can simulate various nonrelational features of SQL—even things like duplicates and nulls—without having to support such concepts directly in the underlying relational language.
[186] In this connection, we’d also like to see an implementation that’s more sophisticated in certain respects than most current SQL implementations typically are. More specifically, we’d like to see an implementation based on what’s called The TransRelational™ Model (see Appendix G).
[187] As a matter of fact, Darwen and I show in our Manifesto book that every algebraic operator discussed in this book—with the sole exception of TCLOSE—can be expressed in terms of just two primitives, remove (which is basically “project over all attributes but one”) and either nand or nor (which are basically algebraic analogs of the logical operators with the same names—see the answer to Exercise 10.4 in Appendix F).
[188] Yes, it really was thought of in such terms. Here’s a quote from the very first paper on the language we now know as SQL (see Appendix G): “Examples of such users are accountants, engineers, architects, and urban planners. It is for this class of users that [SQL] is intended.”