
The first step in the process of getting rid of those shaded entries is to apply vertical decomposition to produce a set of tables with the property that no table ever has more than one column with any such entries. (Note: Vertical decomposition—vertical because the dividing lines in the decomposition are between columns, so to speak—is essentially what we do when we do classical normalization.) For the table in Figure C-1, the result of this step is tables SN, ST, and SC as shown in Figure C-2. (For obvious reasons I use T, not S, as an abbreviation for STATUS throughout this appendix.)
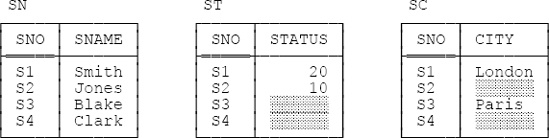
The “obvious” (?) predicates for the tables in Figure C-2 are as follows:
SN: Supplier SNO is named SNAME.
ST: Supplier SNO has status STATUS.
SC: Supplier SNO is located in city CITY.
However, the predicates for ST and SC here are still only approximate, because of those shaded entries—and that’s why we need horizontal decomposition, which I’ll get to in the next section. Note first, however, that each of tables SN, ST, and SC has just two columns. But this state of affairs is a fluke, in a way; it’s a direct result of my choice of example. If the example were different—e.g., if we knew that column STATUS, as well as columns SNO and SNAME, will never contain any shaded entries—then the appropriate vertical decomposition would be as shown in Figure C-3 below. Note: I’ve assumed in Figure C-3, just for the sake of the revised example (but in accordance with our usual sample values), that suppliers S3 and S4 have status 30 and 20, respectively.
