
3.1 See the body of the chapter.
3.2 Two values of any kind are equal if and only if they’re the very same value (meaning they must be of the same type, a fortiori). In particular, therefore, (a) two tuples t and t′ are equal if and only if they have the same attributes A1, A2, ..., An and for all i (i = 1, 2, ..., n), the value v of Ai in t is equal to the value v′ of Ai in t′; (b) two relations r and r′ are equal if and only if they have the same heading and the same body (i.e., their headings are equal and their bodies are equal).
3.3 Tutorial D tuple selector invocations (actually literals):
TUPLE { PNO 'P1' , PNAME 'Nut' ,
COLOR 'Red' , WEIGHT 12.0 , CITY 'London' }
TUPLE { SNO 'S1' , PNO 'P1' , QTY 300 }SQL analogs (“row value constructor” invocations):
ROW ( 'P1' , 'Nut' , 'Red' , 12.0 , 'London' )
ROW ( 'S1' , 'P1' , 300 )Observe the lack of column names (or field names, to use the SQL term) and the reliance on left to right ordering in these SQL expressions. The keyword ROW can be omitted without changing the meanings.
3.4 The following selector invocation (actually a literal) denotes a relation of two tuples:
RELATION { TUPLE { SNO 'S1' , PNO 'P1' , QTY 300 } ,
TUPLE { SNO 'S1' , PNO 'P2' , QTY 200 } }SQL analog (a “table value constructor” invocation, involving two “row value constructor” invocations):
VALUES ROW ( 'S1' , 'P1' , 300 ) ,
ROW ( 'S1' , 'P2' , 200 )Either or both of the two row value constructor invocations here can omit the ROW keyword if desired. By the way, the fact that there are no parentheses enclosing that commalist of row value constructor invocations isn’t an error. In fact, the following SQL expression—
VALUES ( ROW ( 'S1' , 'P1' , 300 ) ,
ROW ( 'S1' , 'P2' , 200 ) )(which is certainly legal, syntactically speaking)—denotes something entirely different! See the answer to Exercise 3.10 later.
3.5 The list that follows is based on one in my book An Introduction to Database Systems (see Appendix G).
Each attribute in the heading of a relation involves a type name, but those type names are usually omitted from tables (where by tables I mean tabular pictures of relations).
Each component of each tuple in the body of a relation involves a type name and an attribute name, but those type and attribute names are usually omitted from tabular pictures.
Each attribute value in each tuple in the body of a relation is a value of the applicable type, but those values (or literals denoting those values, rather) are usually shown in some abbreviated form—for example, S1 instead of ‘S1’—in tabular pictures.
The columns of a table have a left to right ordering, but the attributes of a relation don’t. One implication of this point is that (unlike attributes) columns can have duplicate names, or even no names at all. For example, consider the SQL expression
SELECT DISTINCT S.CITY , S.STATUS * 2 , P.CITY FROM S, PWhat are the column names in the result of this expression?
The rows of a table have a top to bottom ordering, but the tuples of a relation don’t.
A table might contain duplicate rows, but a relation never contains duplicate tuples.
Tables (at least in SQL) always have at least one column, while relations are allowed to have no attributes at all (see the section TABLE_DUM AND TABLE_DEE in the body of the chapter).
Tables (at least in SQL) are allowed to include nulls, but relations certainly aren’t.
Tables (in the sense of tabular pictures) are “flat” or two-dimensional, but relations are n-dimensional.
3.6 One exception is as follows: Since no database relation can have an attribute of any pointer type, no tuple in such a relation can have an attribute of any pointer type either. The other exception is a little harder to state, but what it boils down to is that if tuple t has heading {H}, then no attribute of t can be defined in terms of any tuple or relation type with that same heading {H}, at any level of nesting.
Here are Tutorial D expressions denoting (a) a tuple with a tuple valued attribute and (b) a tuple with a relation valued attribute:
TUPLE { NAME 'Superman' ,
ADDR TUPLE { STREET '1600 Pennsylvania Ave.' ,
CITY 'Washington' , STATE 'DC' , ZIP '20500' } }
TUPLE { SNO 'S2' , PNO_REL RELATION { TUPLE { PNO 'P1' } ,
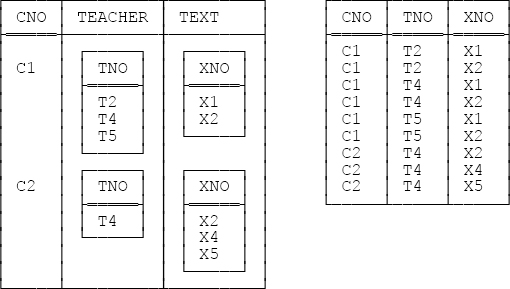
TUPLE { PNO 'P2' } } }3.7 For a relation with one RVA, see relation R4 in Figure 2-2 in Chapter 2; for an equivalent relation with no RVA, see relation R1 in Figure 2-1 in Chapter 2. As for one with two RVAs, consider the table on the left below. The intended meaning is:
Course CNO can be taught by every teacher TNO in TEACHER (and no other teachers) and uses every textbook XNO in TEXT (and no other textbooks).
The table on the right represents a relation without RVAs that conveys the same information.
As for a relation with an RVA such that there’s no relation without an RVA that represents precisely the same information, one simple example can be obtained from Figure 2-2 in Chapter 2 by just replacing the PNO_REL value for (say) supplier S2 by an empty relation:

Subsidiary exercise: Why exactly is there no relation without an RVA that represents the same information as the relation just shown?
However, it isn’t necessary to invoke the notion of an empty relation in order to come up with an example of a relation with an RVA such that there’s no relation without an RVA that represents precisely the same information. (Subsidiary exercise: Justify this remark! If you give up, refer to the discussion of the SIBLING example in Chapter 7.)
Perhaps I should elaborate on what it means for two relations to represent the same information. Basically, relations r1 and r2 represent the same information if and only if it’s possible to map r1 into r2 and vice versa by means of operations of the relational algebra.[197] With reference to relations R4 in Figure 2-2 in Chapter 2 and R1 in Figure 2-1 in Chapter 2, for example, we have:
R4 = R1 GROUP ( { PNO } AS PNO_REL )
R1 = R4 UNGROUP ( PNO_REL )Each relation can thus be defined in terms of the other, and the two therefore do represent the same information. See Chapter 7 for further discussion of the GROUP and UNGROUP operators.
3.8 TABLE_DEE and TABLE_DUM (DEE and DUM for short) are the only relations with no attributes; DEE contains exactly one tuple (the 0-tuple), DUM contains no tuples at all. SQL doesn’t support them because tables in SQL are always required to have at least one column. (In other words, SQL’s version of the relational algebra is like an arithmetic that has no zero.) As for why this is so, your guess is as good as mine.
3.9 (Note: You might want to come back and take another look at this answer after reading Chapter 10.) We need the concept of relations in general before we can have the concept of relations of degree zero in particular. The concept of relations in general depends on predicate logic. Predicate logic depends on propositional logic.
Propositional logic depends on the truth values TRUE and FALSE. So if we tried to replace TRUE and FALSE by DEE and DUM, we would be going round in circles!
Also, it would be a little odd (to say the least) if all boolean expressions suddenly became relational expressions, and host languages thus suddenly all had to support relational data types.
Would it make sense to define a relvar of degree zero? It’s hard but not impossible to imagine a situation in which such a relvar might be useful—but that’s not the point. Rather, the point is that the system shouldn’t include a prohibition against defining such a relvar. If it did, then that fact would constitute a violation of orthogonality, and such violations always come back to bite us eventually.
3.10 The first denotes an SQL table of four rows (three distinct ones, plus a duplicate of one of those three). The second denotes an SQL table of one row, that row consisting of four “field” values all of which are rows in turn. Note that none of the fields involved (in either case) is named.
3.11 The given expression is semantically equivalent to this one:
SELECT SNO
FROM S
WHERE STATUS > 20
OR ( STATUS = 20 AND SNO > 'S4' )
OR STATUS IS NULL
OR SNO IS NULL3.12 See the body of the chapter.
3.13 See the body of the chapter.
3.14 EXISTS (t), where t is the SQL analog of the relational expression r. Note: Another possibility is (SELECT COUNT(*) FROM (t)) > 0; however, this possibility is slightly deprecated, for reasons to be explained in Chapter 10.
3.15 The complete syntax for a relation selector invocation in Tutorial D is as follows:
RELATION [<heading>] {<tuple exp commalist>}
Simplifying slightly, a <heading> is a commalist of attribute-name/type-name pairs enclosed in braces; it must be specified if the <tuple exp commalist> is empty, but can be omitted otherwise. By way of example, therefore, the empty suppliers relation can be specified as follows:
RELATION { SNO CHAR , SNAME CHAR , STATUS INTEGER , CITY CHAR } { }As an aside, I note that TABLE_DEE and TABLE_DUM can be thought of as shorthand for the relation selector invocations RELATION {} {TUPLE {}} and RELATION {} {}, respectively.
As for SQL: The SQL analog of a relation selector invocation is (an important special case of) a VALUES expression. The syntax is:
VALUES <row exp commalist>As you can see, there’s nothing here analogous to the optional <heading> component of a Tutorial D selector invocation. As a consequence, the <row exp commalist> mustn’t be empty, and SQL has no direct way of specifying an empty table. Thus, workarounds are needed. For example, the empty suppliers table might be specified as follows:
SELECT * FROM S WHERE FALSE
3.16 Yes! However, we would of course want such operators always to produce a valid tuple as a result (i.e., we would want closure for such operations, just as we have closure for relational operations). For tuple union, for example, we would want the input tuples to be such that attributes with the same name have the same value (and are therefore of the same type, a fortiori). By way of example, let t1 and t2 be a supplier tuple and a shipment tuple, respectively, and let t1 and t2 have the same SNO value. Then the union of t1 and t2, t1 UNION t2, is a tuple of type TUPLE {SNO CHAR, SNAME CHAR, STATUS INTEGER, CITY CHAR, PNO CHAR, QTY INTEGER}, with components as in t1 or t2 or both (as applicable). E.g., if t1 is (S1,Smith, 20,London) and t2 is (S1,P1,300)—to adopt an obvious shorthand notation for tuples—then their union is the tuple (S1,Smith,20,London,P1,300). Note: This operation might not unreasonably be called tuple join instead of tuple union.
Of course, it’s not just the usual set operators that might reasonably be adapted to tuples specifically—the same goes for certain of the well known relational operators, too. A particularly important example is provided by the tuple projection operator, which is a straightforward adaptation of the relational projection operator. For example, let t be a supplier tuple; then the projection t{SNO,CITY} of t on attributes {SNO,CITY} is that subtuple of t that contains just the SNO and CITY components from t. Likewise, t{CITY} is that subtuple of t that contains just the CITY component from t, and t{} is that subtuple of t that contains no components at all (in other words, it’s the 0-tuple). In fact, it’s worth noting explicitly that every tuple has a projection on the empty set of attributes whose value is, precisely, the 0-tuple.
3.17 See the body of the chapter.
3.18 AS is used in SELECT clauses (to introduce column names); CREATE VIEW (ditto); FROM clauses (to introduce range variable names—by contrast, the syntax used to introduce column names in this context doesn’t use AS); WITH specifications; and other contexts not discussed in this book.
You were also asked (a) in which cases the keyword was optional; (b) in which cases the AS clause took the form “<something> AS name”; and (c) in which cases it took the form “name AS <something>“: No answer provided.
[197] Another useful informal characterization is this: Relations r1 and r2 represent the same information if and only if, for any query q1 that can be addressed to r1, there’s a corresponding query q2 that can be addressed to r2 that produces the same result (and vice versa).