
Let’s ignore status values for the moment and concentrate on cities. So far, then, I’ve said that shaded entries in the CITY column (as shown in, e.g., Figure C-2) mean we don’t know the applicable supplier city—i.e., the supplier does have a city, but we don’t know what it is. But our not knowing is only one of many possible reasons why we might not be able to use a genuine city name as some entry in that column. For example, it might be that the notion of having a city simply doesn’t apply to some suppliers (perhaps they conduct their business entirely online). If so, we might say, very loosely, that table SC, with those shaded entries in the CITY column (i.e., table SC as shown in Figure C-2), has a predicate looking something like this:
Supplier SNO is located in city CITY OR we don’t know where supplier SNO is located OR supplier SNO isn’t located anywhere.
Note, therefore, that those shaded entries now potentially have two distinct interpretations: Some of them mean we don’t know the applicable city, others mean the property of having a city doesn’t apply. So, again, we apply horizontal decomposition, this time to obtain three tables: SC (suppliers with a known city), SUC (suppliers with an unknown city), and SNC (suppliers with no city). The predicates are:
SC: Supplier SNO is located in city CITY.
SUC: We don’t know where supplier SNO is located.
SNC: Supplier SNO doesn’t have a location.
If we assume for the sake of the example that supplier S2 has an unknown city and supplier S4 doesn’t have a city at all, the result of this decomposition is as shown in Figure C-6:
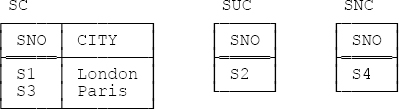
In other words, the decomposition approach allows us to represent as many different kinds of missing information as we like. To be specific, if there are n distinct reasons for supplier cities to be missing, there’ll be n+1 tables having to do with suppliers and cities. Two possible objections to the approach thus immediately spring to mind:
Aren’t some queries going to get awfully complex? For example, suppose we just want to retrieve everything in the database having to do with suppliers (the analog of SELECT * FROM S in SQL); aren’t we going to have to do a lot of joins, or (worse) outer joins?
Aren’t we going to wind up with an awful lot of tables?
I’ll come back to the first of these issues in the section QUERIES, later. As for the second, well, there are several points I want to make. Let C be an SQL column for which nulls are allowed. Then:
If the nulls in column C all represent the same kind of missing information, and if the same is true for all such columns C, then the number of tables resulting from the decomposition approach is exactly the same as the number resulting from a good relational design. (To paraphrase something I said earlier, the presence of such a column C in a table T means table T is certainly not a relational table. Proper relational design requires elimination of such columns.)
The situation is worse if the nulls in some such column C represent two or more distinct kinds of missing information but proper decomposition isn’t done. If it isn’t, there’ll certainly be fewer tables—but the apparent simplicity of such a design is spurious: Those tables aren’t relational, they don’t faithfully reflect the real world, they no longer have a clear predicate, and queries are more susceptible to errors of formulation or errors of interpretation or both.
There’s a tactic we might consider, if we want to reduce the number of tables, which I’ll illustrate with reference to Figure C-6. In terms of that example, the tactic would involve combining tables SUC and SNC into a single table with two columns, SNO and REASON, where REASON indicates the reason why the applicable supplier has no recorded city:
SNOREASONS2d/kS4n/aBut now we have to define appropriate values, and spell out their interpretations, for column REASON (in the example, I’ve used d/k for “don’t know” and n/a for “not applicable”). In fact, if the decomposition approach requires n missing information tables, the combination approach requires n missing information reasons. So the combination approach is in some respects no less complex than the decomposition approach.