
5.7 Layered Depth Video (LDV)
Although MVD can synthesize any infinitely dense intermediate views with high fidelity from a limited number of sparse views transmitted through the network, the overall required bandwidth to convey all the color and depth information of the N views (including central and side views) is still comparatively large, even bringing in the MVC coding for color and depth information. To further reduce the bit rate, one could deploy conventional video coding on the central view only; apply view synthesis technologies on the decoded and reconstructed central view to generate other N − 1 side views; and take the difference between the projection and the neighboring camera result as residual information. The residual consists of disoccluded information and is therefore mainly concentrated along depth discontinuities of foreground objects as well as image boundary data in both side views. The overall bit stream consists of three major components: (1) complete color and depth information from the central view; (2) parameters for view synthesis, such as geometry parameters for camera and real-world depth range; and (3) residual of color and depth information in the side views. At the decoder side, as shown in Figure 5.21, the decoder will first reconstruct the central view once having received the bit stream. Then, the decoder projects the central camera view into the other neighboring views using the view synthesis parameters to synthesize side views. The residual is added back to the synthesized side views to reconstruct all N views. Having those N views available, the rest of the intermediate views can be synthesized via techniques used in MVD.
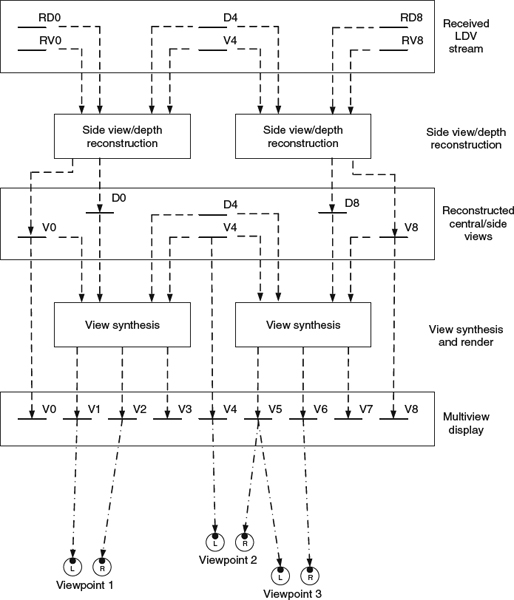
Figure 5.21 Decoding and rendering process in layered depth video.
It has been observed that the aforementioned straightforward method could introduce corona artifacts in the intermediate synthesized views. To remedy this problem, layered depth video (LDV) [56] is proposed. The basic idea of LDV is to identify the reliability of each depth pixel, especially the ones along the object boundaries, since those boundary pixels are often mixed with foreground and background, degraded by lossy compression artifacts, and may contain potential errors from imperfect depth estimation. The unreliable depth pixels are detected via the Canny edge detector, marked by a seven-pixel-wide area along depth discontinuities, and classified as the background boundary layer. A layer extraction procedure is conducted to preserve reliable pixels and to remove pixels in the background boundary layer. Then, the layer projection is performed during view synthesis by synthesizing pixels in the extracted layer to ensure the reliability of projected view. The projected side view will be further filtered to remove invalid disoccluded areas to reduce the synthesis error. The residual information will be taken from the original side view and the filtered projected side view.