
DATABASES (STUDY OBJECTIVE 4)
A database is a collection of data stored on the computer in a form that allows the data to be easily accessed, retrieved, manipulated, and stored. The term “database” usually implies a shared database within the organization. Rather than each computer application having its own file, a database implies a single set of data that is shared by each application that uses the data. Exhibit 13-3 illustrates this data sharing concept.
The top half of the exhibit shows the traditional file-oriented approach to data storage. Each application owns the data file that it uses, and there is no sharing of data even though these applications do in fact use some of the same type of data (such as inventory part numbers and descriptions). This lack of sharing leads to data redundancy. Data redundancy occurs when the same data are stored in more than one file. In this case, inventory part numbers and descriptions may exist in all three files. Data redundancy causes concurrency problems. Concurrency means that all of the multiple instances of the same data are exactly alike. If the same records are stored in many different locations, it is difficult to make sure that they all are updated at the same time (concurrently). For example, changing the address of a customer may mean changing it in three different places. In such cases of data redundancy, errors in updating the data are much more likely to occur. Thus, the data are more likely to have errors. Due to this data redundancy, adding records, deleting records, and editing or changing records are more likely to cause errors in the data.
The lower half of Exhibit 13-3 illustrates a shared database approach. All data are stored once in a shared database, and those data are available to all applications that use the data. Notice that this eliminates data redundancy and concurrency problems. Since the data are stored only once, any and all changes to a record are immediately available to those who share the data. Adding records, deleting records, and editing records are less likely to cause erroneous data when those data are stored only once.

Exhibit 13-3 Traditional File-Oriented Approach and the Database Approach
The DBMS symbol in Exhibit 13-3 represents the database management system. The database management system (DBMS) is software that manages the database and controls the access and use of data by individual users and applications. The DBMS determines which parts of the database can be read or modified by individuals or processes. Before beginning the technical discussion of databases, it is useful to define database terms and to examine a brief history of databases. This history is useful in understanding the current environment and database use in organizations.
Data reveal relationships between records. These relationships can be thought of as parent–child relationships. One parent can be related to one or more children. The types of relationships in data are one-to-one, one-to-many, and many-to-many. One-to-one relationships are those where one entity in the data is related to only one other entity. An example of one-to-one would be employees and Social Security numbers. Each employee has only one Social Security number, and each Social Security number belongs to only one person. One-to-many relationships are those where one entity in the data is related to more than one other entity. Each individual employee can have several time cards in a given year. Notice, however, that this one-to-many relationship is in one direction only. That is, while an employee is related to several time cards, each time card belongs to only one employee. Most data in accounting transactions exhibit one-to-many relationships. Examples are a vendor to many invoices, a customer to many orders, a customer to many payments, and an order to many items in the order. Many-to-many relationships are those in which one entity is related to many other entities, and the reverse is also true. An example of a many-to-many relationship is vendors to items and items to vendors. That is, a single vendor can supply several items, and any single item can be supplied by many vendors.
THE HISTORY OF DATABASES
Flat File Database Model
The earliest databases, from the period of the 1950s and 1960s, are called flat file databases. The term flat file comes from the idea that data are stored in two-dimensional tables with rows and columns. In a flat file table, each row is a record and each column is a characteristic related to the records. For example, each employee has the characteristic of a certain hire date. In database terminology, columns are called attributes. Therefore, attributes are characteristics of a related record. Exhibit 13-4 illustrates such a table.
Flat file records are stored in text format in sequential order, and all processing must occur sequentially. No relationships are defined between records. These systems must use batch processing only, and batches must be processed in sequence. The system makes the processing of large volumes of similar transactions very efficient. However, it does not allow a single record to be quickly and easily retrieved or stored. Therefore, interactive, real-time processing is not possible with sequential, flat file databases.
Each table in a database must meet the following conditions:
- Items in a column must all be of the same type of data. The column in Exhibit 13-4 titled “Last Name” must have only last names from each record.
- Each column must be uniquely named.
- Each row must be unique in at least one attribute (one column). If there were no differences in any column, the rows would be identical and one row could be deleted since it is a duplicate of another row.
- Each cell at the intersection of a row and column must contain only one data item. In this example, each employee can have only one hire date.

The flat file database and each database model described next are based on tables with the four characteristics just listed.
Hierarchical Database Model As computer processing power increased, databases evolved into the hierarchical model. Hierarchical databases define relationships between records by an inverted tree structure. These relationships are called parent–child, and they represent one-to-many relationships. Therefore, the hierarchical model of a database could incorporate one-to-one and one-to-many relationships in the data. These relationships are permanently and explicitly defined in the database by data linkages. The data are linked by these explicit relationships in a record linkage structure such as record pointers. A record pointer is a column value in the table that points to the next address with the linked attribute. This linkage allows quick retrieval of records in that linkage chain. For example, a payroll database could have linkages from plant location to department to employee. Exhibit 13-5 illustrates a hierarchical relationship linkage.
If the desire is to quickly retrieve records for employees in Plant 1, the record access can be quick because of the built-in linkage. However, if we desired to retrieve only records of all employees who work in Department 1, there is no single set of linkages that make the retrieval easy. Each record would be read in sequence to see whether that employee worked in Department 1. Hierarchical databases are efficient in processing large volumes of transactions, but they do not allow for easy retrieval of records except for those within an explicit linkage. This means that hierarchical databases are not flexible enough to allow various kinds of inquiries of the data.
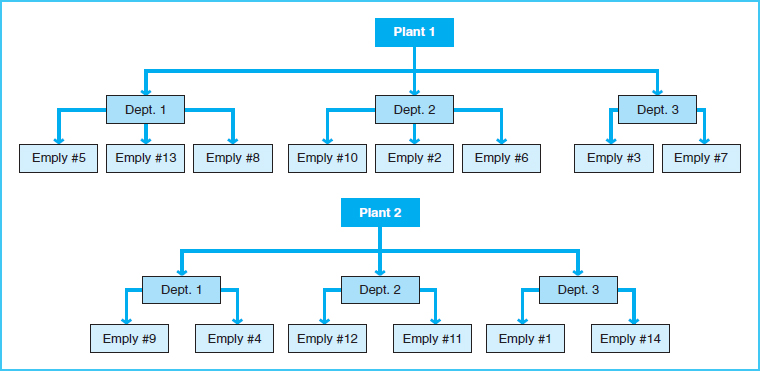
Exhibit 13-5 Linkages in a Hierarchical Database
Network Database Model
To slightly improve the recognition of relationships in databases, the network model of databases was developed next. Network databases are also built on the inverted tree structure, but they allow more complex relationship linkages by the use of shared branches. This essentially means that there is more than one set of inverted tree branches into the data. However, the network model has not been very popular, and it is rarely used today. Both the hierarchical and network models have many disadvantages. In both models it is impossible to add new data unless all related information is known. A new vendor cannot be added to a database until it is known which items will be purchased from that vendor. In addition, deleting any parent record will also delete all child records.
Relational Database Model
In 1969, a mathematician named E.F. Codd developed a model of databases that allows the inclusion of more complex data relationships. He termed this model the relational database. A relational database stores data in two-dimensional tables that are joined in many ways to represent many different kinds of relationships in the data. Although it took many years for the computing technology to be available to implement his ideas broadly, the relational database structure is the most widely used database structure today. IBM DB2, Oracle Database, and Microsoft Access® are all examples of relational databases.