
Chapter 9
Requirements and Challenges for Big Data Architectures
John Panneerselvam, Lu Liu, and Richard Hill
Abstract
Big data analytics encompass the integration of a range of techniques while deploying and using this technology in practice. The processing requirements of big data span across multiple machines with the seamless integration of a large range of subsystems functioning in a distributed fashion. Because we witness the processing requirements of big data exceeding the capabilities of most current machines, building up such a huge processing architecture involves several challenges in terms of both the hardware and software deployments. Understanding the analytics assets across the underpinning core technologies will add additional values, while driving innovation and insights with big data. This chapter is structured to showcase the challenges and requirements of a big data processing infrastructure and also gives an overview of the core technologies and considerations involved in the concept of big data processing.
Keywords
Acquisition; Analysis; Deployment; Extract; Integration; OrganizationWhat Are the Challenges Involved in Big Data Processing?
Data generated across the society is very much in a raw state and must be processed to transform it into valuable and meaningful information. Raw data always includes dirty data, i.e., data with potential errors, incompleteness, and differential precision, which must be refined. Usually, data reach their most significant value when they are in their refined state. Architectures for processing big data must be scalable to answer the following questions (Fisher et al., 2012):
• How do we capture, store, manage, distribute, secure, govern, and exploit the data?
• How do we create links across the data stored in different locations? The data value explodes when it is interlinked, leading to better data integration.
• How do we develop trust in the data?
• What advanced tools are available for rapid analysis and to derive new insights?
Real-time analytics of all formats of data and of any volume is the ultimate goal of big data analytics. In other words, Big Data solutions require the analysis against the volume, velocity, and variety of data, while the data are still in motion. To facilitate this, the architectural structure requires integrated data, actionable information, insightful knowledge, and real-time wisdom in its processing model (Begoli and Horey, 2012). This is best achieved with a complete hardware and software integrated framework for big data processing.
Deployment Concept
It is appropriate to consider the deployment process in accordance with the three major phases (data acquisition, data organization, and data analysis) of the big data infrastructure. Generally speaking, deployment constitutes the way of thinking about the minutia involved in the acquisition, organization, and analysis phases. Usually, enterprises will participate in a predeployment analysis phase to identify the architectural requirements based on the nature of the data, the estimated processing time, the expected confidentiality of the generated results, and the affordability for a particular project. The major challenges to be considered in the deployment process are heterogeneity, timeliness, security, scale in terms of volume, complexity of the data, the expected accuracy of the results, and more importantly the way of enabling human interaction with the data. According to the five-phase process model (Barlow, 2013), real-time processing includes data distillation, model development, validation and deployment, real-time scoring, and model refreshing. In simple terms, a big data solution is the art of merging the problem with the platform to achieve productivity.
Table 9.1
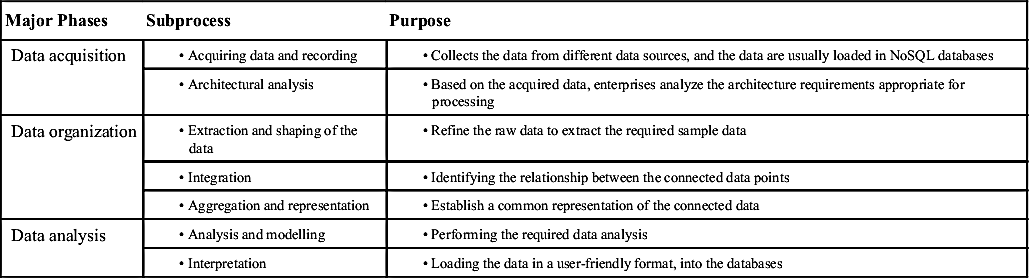
The deployment pipeline of big data may start from acquiring and recording the data and then move to the analysis of the architecture; extraction of the data; shaping of the data; their integration, aggregation, analysis, and modelling; representation; and finally their interpretation. All of these processes are complex, because a multitude of options and optimization techniques are available in every phase of the deployment pipeline. Choosing and handling the appropriate techniques for every phase depends on the nature of the data and the outcome expected. For ease of understanding, these subprocesses are grouped under the major three phases of the infrastructure. Table 9.1 explains the subprocesses and their respective purposes involved in the deployment pipeline.
Technological Underpinning
No single technology can form a complete big data platform. It is the integration of many core technologies that build the big data platform, thus creating a broader enterprise big data model. Yet, rather than viewing the big data solution as an entirely new technology, it is appropriate to see the big data platform as the integrated extension of existing business intelligence (BI) tools. The orchestration of these technologies (Byun et al., 2012), such as real-stream analytics, MapReduce frameworks, and massively parallel processing (MPP) processors, with massive databases scalable for big data, forms an integrative big data solution.
The Core Technologies
MapReduce frameworks
The massive parallel processing of big data in a distributed fashion is enabled by MapReduce frameworks. MapReduce (Raden, 2012) is a programming strategy applied to big data for analytics, which usually divides the workload into subworkloads and separately processes each block of the subunit to generate the output. MapReduce frameworks often depend on Hadoop-like technologies (Shangy et al., 2013), which allows the processing and analysis of data, while the data reside in their original storage location. Hadoop allows the users to load and process the data without the need for any transformation before loading the data into the MapReduce platform.
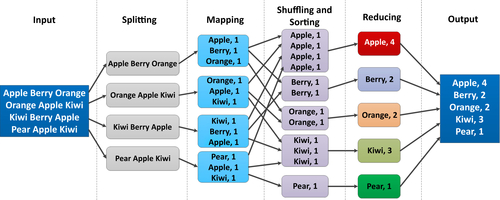
As its name suggests, the MapReduce process involves two phases, the map phase and the reduce phase. The map phase divides (splits) the workload into subworkloads and assigns tasks to the mapper. The mapper processes each unit of the sub-block and generates a sorted list of key-value pairs that are passed on to the next phase, reduce. The reduce phase merges and analyzes the key-value pairs to produce the final output. MapReduce applications can be programmed in Java or with other higher-level languages like Hive and Pig. A simple MapReduce operation for counting the number of objects from raw data is illustrated in Figure 9.1.
Hadoop distributed file systems
Hadoop distributed file system (HDFS) is a long-term storage option of the Hadoop platform, which is used to capture, store, and retrieve data for later analysis. HDFS is usually configured as direct attached storage (DAS) to Hadoop and facilitates moving data blocks to different distributed servers for processing. HDFS is focused on NoSQL databases, capable of capturing and storing all formats of data without any categorization. The output generated by the Hadoop platform is usually written on the HDFS, which operates in master–slave architecture, with two types of nodes, the name node and the data node. It uses a single name node per cluster, acting as a master, and a number of data nodes performing the read and write requests of the clients. The data nodes store the data blocks in the HDFS, while the name node holds the metadata with the enumeration of the blocks and the list of data nodes in the HDFS cluster. HDFS has the capability of storing data of all formats and of massive sizes. They thus outperform the capabilities of traditional RDBMS, which are limited only to structured data.
HBase
HDFS may include the implementation of HBase, which usually sits on top of the HDFS architecture. HBase is a column-oriented database management system, which provides additional capabilities to HDFS and makes working with HDFS much easier. HBase configuration can be carried out in Java, and its programming functionalities are similar to MapReduce and HDFS. HBase requires the predetermination of the table schema and the column families. However, it provides the advantage that new columns to the families can be added at any time, thus enabling scalability for supporting changes in the application requirements.
Data warehouse and data mart
A data warehouse is a relational database system used to store, query, and analyze the data and to report functions. The data warehousing structure is ideal for analyzing structured data with advanced in-database analytics techniques. In addition to its primary functionalities, data warehouses also include extract-transform-load (ETL) solutions and online analytical processing (OLAP) services. OLAP-based data warehouses have powerful analytical capabilities that can be integrated to generate significant results. Data warehouses are nonvolatile, which means that the data, once entered, cannot be changed, allowing the analysis of what has actually occurred.
There are two approaches to store the data in data warehouses, dimensional and normalized. In the dimensional approach, transaction data is partitioned into either facts, which are the transaction data, or dimensions, which are the reference information providing contexts to the facts. The dimensional approach provides an understanding of the data warehouse and facilitates retrieval of the information. Yet, it has complications in loading the data into the data warehouse from different sources and also in the modification of the stored data. In the normalized approach, the tables are grouped together by subject areas under defined data categories. This structure divides the data into entities and creates several tables in the form of relational databases. The process of loading information into the data warehouse is thus straightforward, but merging of data from different sources is not an easy task due to the number of tables involved. Also, users may experience difficulties in accessing information in the tables, if they lack precise understanding of the data structure.
The data warehouse architecture may include a data mart, which is an additional layer used to access the data warehouse. Data marts are important for many data warehouses, because they customize various groups within an organization. The data within the data mart is generally tailored according to the specific requirements of an organization.
Planning for a Big Data Platform
Infrastructure Requirements
Typically, big data analytics work with the principle of ETL. It is the act of pulling the data from the database to an environment where it can be dealt with for further processing. The data value chain defines the processing of any kind of data, flowing from data discovery, integration, and then to data exploitation. It is important to keep in mind that our ultimate target is to achieve easy integration, thereby conducting deeper analytics of the data. In this case, the infrastructure requirements (Dijcks, 2012; Forsyth, 2012) for the framework to process big data span across three main phases: data acquisition, data organization, and data analysis (Miller and Mork, 2013).
Data acquisition
Trends and policies in acquiring data have changed drastically over the years, and the dynamic nature of big data is forcing enterprises to adapt changes in their infrastructure, mainly in the collection of big data. The infrastructure must show low, predictable latency, not only in capturing the data, but also in executing the process in quick succession. Handling high volumes of transaction data is one of the key characteristics that create the need for infrastructures that are scalable, supporting flexible and dynamic data structures.
In recent years, there has been a transition from SQL databases to NoSQL databases (Kraska, 2013), to capture and store big data. Unlike traditional SQL databases, NoSQL databases show the advantage of capturing the data without any categorization of the collected data. This keeps the storage structure simple and flexible, and thus scalable for dynamic data structures. NoSQL databases do not follow any specific patterns or schemas with respect to relationships between the data. Instead they contain a key to locate the container holding the relevant data. This simple storage strategy avoids costly reorganization of the data for later processing in the data value chain.
Data organization
Data organization is also referred to as data integration. Data integration allows the analysis and the manipulation of the data with data residing (Cleary et al., 2012) in their original storage location. This avoids the complex process of moving huge bulks of data to various places, not only saving processing time, but also costs. Data organization should be managed in such a way that the infrastructure offers higher throughput in handling various formats of data (i.e., from structured to unstructured).
Integrating data is a means of identifying the cross-links between connected data, thereby establishing a common representation of the data. Integration constitutes mapping by defining how the data are related in a common representation. This common representation often depends on the data’s syntax, structure, and data semantics and makes the information available usually from a metadata repository. Data integration can be either virtual, through a federated model or physical, usually through a data warehouse. Organizing the data provides ease of storage and facilitates more effective analytics not only in the present, but also in the future.
Data analysis
Data analysis is an important phase in the data management, which leads the way for assisted decision-making in enterprises. From an analysis perspective, the infrastructure must support both statistical analysis and also deeper data mining. Because we are talking about processing the data in its original storage location, a high degree of parallelization is an important criterion that makes the infrastructure scalable. Faster response times, low latency, tolerance to extreme conditions, adaptability to frequent changes, and automated decisions are other important features that make a big data infrastructure more effective.
The purpose of data analysis is to produce a statistically significant result that can be further used by enterprises to make important decisions. Along with the analysis of current data, a combined analysis with older data is important, because this older data could play a vital role in decision making. The interpreted results generated by the analysis phase must be available to the decision maker in a simple and understandable format, usually by providing visualization of the metadata to the interpreter.
Network considerations
Because we process big data in a distributed fashion, the interconnections of the operating nodes within a cluster are crucial, particularly during both the read and write functionalities of the HDFS (Bakshi, 2012) and also the MapReduce metadata communications between the nodes. Every node in HDFS and MapReduce needs low latency and high throughput. In the HDFS framework, the name node should be in a highly connected fashion with the data nodes, to avoid the name node de-listing any data node belonging to its cluster. In a typical Hadoop cluster, the nodes are arranged in racks, and so network traffic from the same rack is more desirable than across the racks. Replication of the name nodes is advantageous because it provides improved fault tolerance.
The network should demonstrate redundancy and should be scalable as the cluster grows. To overcome drawbacks such as single point failure and node block-outs, multiple redundant paths are useful for the operating nodes. At times, the read–write functionalities may involve bottlenecks, leading to packet drops, which in turn forces retransmission of the dropped packets. This leads to longer than usual processing times causing unnecessary delays. Higher network oversubscription may cause packet drops and lower performance, and conversely, lower network oversubscriptions are usually costly to implement. Maintaining lower network latency is always beneficial, and application developers need to consider this when designing solutions. Network bandwidth is another important parameter that has a direct impact on the analytics performance. Because we are moving massive volumes of information from the storage repositories, subscribing to the optimum level of bandwidth is essential.
Performance considerations
When considering performance, the following criteria are relevant:
• Scalable cluster sizing of the Hadoop platform allows the cluster to expand as new nodes arrive. Generally speaking, the best way of decreasing the time required for job completion and to offer faster response times is to increase the number of active nodes participating in the cluster.
• Suitable algorithms increase the efficiency of the entire data model. The algorithm should be designed in accordance with the input datasets and the expected results. Offloading the computational complexities towards the map phase than that of the reduce phase or vice versa may make the algorithm inefficient. In this sense, the design of the algorithm should be in balance between the two phases of the MapReduce framework.
• The pipeline defines how the job task flows from capturing the data until the interpretation of the output. A pipeline with the integration of smaller jobs proves to be more efficient than single larger jobs. This strategy helps in avoiding issues like network bottlenecks, overloading, etc., and thus helps optimization.
• Parallel processing allows MapReduce to process jobs concurrently, e.g., in the form of ETL.
• Service discovery helps the master node to identify the required resources for newly submitted jobs. Less sharing of the node clusters ensures node availability for processing the newly submitted jobs, thus achieving better performance.
Capacity Planning Considerations
Hadoop manages data storage and analytics under the software tier rather than relying on storage options such as SAN and server blades. A typical Hadoop element includes CPU, memory, disk, and the network. The platform requires a partition of the MapReduce intermediate files and the HDFS files, implying that both must be stored in separate locations. Swapping these two memories often degrades the system performance. In-database analytics techniques are essential, which takes the processing to the data rather than moving the data to the processing environment. In-memory computing should be enabled in relationship with the in-database analytics by providing high-speed analytics for online transaction processing (OLTP) and BI applications. In-memory computing stores the processed data in a memory storage, which is directly addressable using the memory bus of the CPU.
Data stack requirements
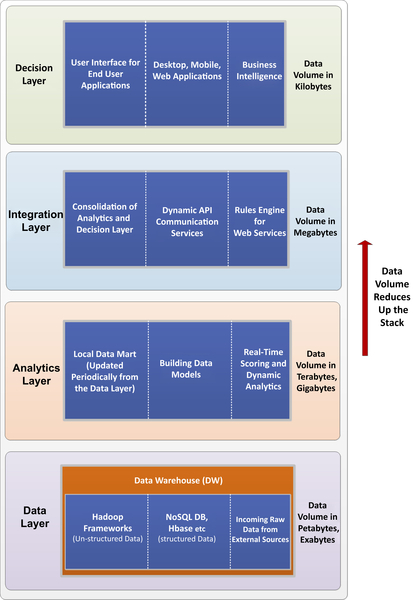
Organizations dealing with big data are still faced with significant challenges, both in the way they extract significant value out of the data and the decision, whether it is appropriate to retain the data or not. In some cases, most or all of the data must be processed to extract a valuable sample of data. The “bigness” of the data is determined according to their location in the data stack. The higher the data move up in the stack, the less of the data needs to be actively managed (Barlow, 2013). Often we see data quantities of petabytes and exabytes in the data layer, where it is usually collected. The analytics layer can reduce this data volume to terabytes and gigabytes after refining the raw and dirty data. It is feasible that this data volume is even reduced to megabytes in the integration layer. This architecture manages to reduce data into just kilobytes in the decision layer. Thus the architecture reduces the size of the data by a considerable volume at the top of the data stack. The data stack architecture is illustrated in Figure 9.2.
Cloud Computing Considerations
Processing big data with cloud computing resources involves the transmission of large volumes of data to the cloud through a network. This highlights the importance of network bandwidth allocation, network congestion, and other network-related issues such as overloading and bottlenecks (KDnuggets, 2012). Enterprises prefer to process their data in an environment that computes the units of data close together rather than distributing them geographically. It is important for enterprises to identify the correct cloud services for their requirements. Another issue in processing big data in clouds is the level of trust in processing the data with the cloud providers. Enterprises should assess the trust level offered by the cloud providers as they are ready to process their confidential data in an environment that is beyond their reach. Before going to the cloud, enterprises should conduct an assessment to evaluate the cloud provider’s capacity in satisfying their architectural needs and the application requirements within their inevitable financial constraints.
Conclusions
Big data analytics illustrates a significant and compelling value, but they also encompass the complexity in every processing step of the analytics platform. The success of the big data concept lies in the potential integration of the supporting technologies that can facilitate the infrastructure requirements of collecting, storing, and analyzing the data. Undoubtedly, the big data implementations require extension or even replacement of the traditional data processing systems. Knowing the significance of big data in the next solid set of years, enterprises have started to adopt big data solutions at a quicker time scale. On the other hand, we see the size of the datasets increasing constantly, and therefore, we need new technologies and new strategies to deal with these data. Thus in the near future, we might need systems of systems, techniques of techniques, and strategies of strategies to solve the big data queries. Cloud computing directly underpins big data implementations. On the whole, the dependability of big data requires the incorporation, integration, and matching of suitable techniques and technologies to sustain the promises and potential of big data solutions.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.