
Chapter 11
Mining Social Media
Architecture, Tools, and Approaches to Detecting Criminal Activity
Marcello Trovati
Abstract
Social media have been increasingly used as a means of information gathering and sharing in criminal activities. The ability to expose and analyze any such activity is at the core of crime detection, providing a variety of techniques and platforms that facilitate the decision-making process in this field.
Keywords
Bayesian networks; Data mining; Information retrieval; Social media; Text miningIntroduction
In his famous article, “Computing Machinery and Intelligence,” Turing (1950) begins by introducing the question, “Can machines think?”
Since the dawn of artificial intelligence research, the possibility of creating machines able to interact and ultimately contribute to our society has been at its core. Despite the enormous progress made in several aspects within this ambitious goal, language acquisition and its understanding has proved to be probably the most complex task of all. The act of making sense of the complicated and often ambiguous information captured by language comes naturally to us humans, but its intrinsic and inexplicable complexity is extremely hard to assess and manage digitally.
The development of the Internet has created a wide variety of new opportunities as well as challenges for our societies. Since their introduction, social media have increasingly become an extension of the way human beings interact with each other, providing a multitude of platforms on which individuals can communicate, exchange information, and create business revenue without geographical and temporal constraints. As a consequence, this new technology is very much part of the fabric of our societies, shaping our needs and ambitions as well as our personality (McKenna, 2004). In particular, social media have redefined and shifted our ways of manipulating and generating information, collaborating, and deciding what personal details to share and how.
It is not difficult to imagine that social media are extremely complex systems based on interwoven connections that are continuously changing and evolving. To harness their power, there has been much research to scientifically describe their properties in a rigorous yet efficient manner. Owing to their multidisciplinary nature, researchers from a variety of fields have united their efforts to produce mathematical models to capture, predict, and analyze how information spreads and its perception and management as it travels across social media. When we think of Facebook, LinkedIn, or Twitter, we tend to picture a huge tapestry of relations linking individuals, companies, entities, and countries, to name but a few. A specific representation of such systems is social networks, a concept with which most of us are familiar, and which many people associate with social media. The formal definition of social networks is intuitive. They consist of nodes (such as individuals) and edges, representing the mutual relationships (for an example, see Figure 11.1).
Although it appears to be an overly simple definition, it has a powerful modeling ability to describe the behavior of social networks. They are, in fact, not about individuality. They are about mass information interpretation and perception. They are about collective intelligence, the cognitive process created by collective interactive systems (Schoder et al., 2013); in other words:

Figure 11.1 One of many examples of a social network freely available online. http://www.digitaltrainingacademy.com/socialmedia/2009/06/social_networking_map.php.
It is a form of universally distributed intelligence, constantly enhanced, coordinated in real time, and resulting in the effective mobilization of skills.
Lévy, 1994, p. 13
Mining of Social Networks for Crime
The introduction of social media and social networks in particular has changed not only the opportunities available to us, but also the type of threats of which we need to be aware. The wealth of information available within any social networking scenario is valuable to criminals, who use individuals’ personal details and information to their advantage. There has been a worrying upward trend of alleged crimes linked to the use of social networks, which poses a new challenge to identify and prioritize social networking crimes linked to genuine harm without restricting freedom of speech. For example, police forces around the United Kingdom (UK) have seen a 780% increase in 4 years of potential criminal activity linked to Facebook and Twitter (The Guardian, 2012).
A dramatic surge in terrorist attacks has caused drastic and long-lasting effects on many aspects of our society. Furthermore, there has been exponential growth in the number of large-scale cybercrimes, which cause considerable financial loss to organizations and businesses. Cybercriminals tend to collaborate, exchange data and information, and create new tools via the dark markets available on online social media (Lau et al., 2014). On the other hand, it offers the possibility of obtaining relevant information about these criminal networks to create new methods and tools to obtain intelligence on cybercrime activities.
Experts from a variety of fields have increasingly contributed to improving the techniques and methods for enhancing the ability to fight criminal activity. In particular, data mining techniques can be applied to assessing information sharing and collaboration as well as their classification and clustering both in spatial and temporal terms (Chen, 2008).
One of the most dangerous and insidious aspects of cybercrime is related to the concept of social engineering. It refers to the ability of obtaining information from systems and data by exploiting human psychology rather than by using a direct approach. A social engineer would find, assess, and combine information to obtain the crucial insight that would lead to getting inside the system. For example, rather than finding software vulnerabilities, a social engineer would obtain sensitive information by deceit, such as obtaining the trust of one or more individuals who might have valuable information. As a consequence, there is an increasing emphasis on specific penetration test techniques, which analyze information available on social network sites to assess several types of related criminal activity.
In work by Jakobsson (2005), an investigation on spear phishing, or context aware phishing, is discussed, detailing a network-based model in which the ability to linking e-mail addresses to potential victims is shown to increase the phishing outcome, urging more sophisticated and effective tools (Dhamija and Tygar, 2005; Dhamija et al., 2006). In April 2011, a variety of companies including Citibank, Disney, JPMorgan Chase, The Home Shopping Network, and Hilton were affected by a security breach into the Internet company Epsilon, which exposed e-mail details of millions of users (Schwartz, 2011). This was one example of collaborative phishing, in which multiple data sources are analyzed to identify specific patterns that will be used to infer statistical information via sophisticated algorithms (Shashidhar and Chen, 2011). As a consequence, criminal network analysis based on social network techniques has been shown to provide effective tools for the investigation, prediction, and management of crime. In fact, the amount of information flowing and propagating across social networks is astonishing. Such information contains a wealth of data encapsulating human activity, individual and general emotions and opinions, as well as intentions to plan or pursue specific activities.
Therefore, social network mining provides an important tool for discovering, analyzing, and visualizing networked criminal activity. Because of the complexity of the task, the numerous research efforts that have been carried out and implemented have achieved only partial success. Therefore, the collective goal is to improve state-of-the-art technology to produce a comprehensive approach to extracting relevant and accurate information to provide criminal network analysis intelligence.
Most information embedded in social networks is in the form of unstructured textual data such as e-mails, chat messages and text documents. The manual extraction of relevant information from textual sources, which can be subsequently turned into a suitable structured database for further analysis, is certainly inefficient and error prone especially when big, if not huge, textual datasets need to be addressed. Therefore, the automation of this process would enable a more efficient approach to social network (and media) mining for criminal activity as well as hypothesis generation to identify potential relationships among the members of specified networks.
Text Mining
Text mining, often referred to as natural language processing (NLP), consists of a range of computational techniques to analyze human language using linguistic analysis for a range of tasks or applications. In particular, such techniques have been shown to have a crucial role in how we can represent knowledge described by the interactions between computers and human (natural) languages. The main goal of NLP is to extend its methods to incorporate any language, mode, or genre used by humans to interact with one another, to achieve a better understanding of the information captured by human communication (Liddy, 2001).
Language is based on grammatical and syntactic rules that fall into patterns or templates that sentences with similar structure follow. Such language formats allow us to construct complex sentences as well as frame the complexity of language. For example, the ability to determine the subject and the object of a particular action described by a sentence has heavily contributed to human evolution and the flourishing of all civilizations (see also Chapter 13).
Natural Language Methods
NLP methods have been developed to embrace a variety of techniques that can be grouped into four categories: symbolic, statistical, connectionist, and hybrid. In this section we will briefly discuss these approaches in terms of their main features and suitability with respect to the tasks requiring implementation.
Symbolic Approach
In this method, linguistic phenomena are investigated that consist of explicit representations of facts about language via precise and well-understood knowledge representations (Laporte, 2005). Symbolic systems evolve from human-developed rules and lexicons, which generate the relevant information on which this approach is based. Once the rules have been defined and identified, a document is analyzed to pinpoint the exact conditions, which validates them. All such rules associated with semantic objects generate networks describing their hierarchical structure. In fact, highly associated concepts exhibit directly linked properties, whereas moderately or weakly related concepts are linked through other semantic objects. Symbolic methods have been widely exploited in a variety of research contexts such as information extraction, text categorization, ambiguity resolution, explanation-based learning, decision trees, and conceptual clustering.
Statistical Approach
This approach is based on observable data and large documents to develop generalized models based on smaller knowledge datasets and significant linguistic or world knowledge (Manning and Schütze, 1999). The set of states is associated with probabilities. Several techniques can be used to investigate their structures, such as the hidden Markov model, in which the set of status is regarded as not directly observable. The techniques have many applications such as parsing rule analysis, statistical grammar learning, and statistical machine translation, to name but a few.
Connectionist Approach
This approach combines statistical learning with representation techniques to allow an integration of statistical tools with logic-based rule manipulation, generating a network of interconnected simple processing units (often associated with concepts) with edge weights representing knowledge. This typically creates a rich system with an interesting dynamical global behavior induced by the semantic propagation rules. In Troussov et al. (2010), a connectionist distributed model is investigated pointing toward a dynamical generalization of syntactic parsing, limited domain translation tasks, and associative retrieval.
General Architecture and Various Components of Text Mining
In linguistics, a (formal) grammar is a set of determined rules that govern how words and sentences are combined according to a specific syntax. A grammar does not describe the meaning of a set of words or sentences; it only addresses the construction of sentences according to the syntactic structure of words. Semantics, on the other hand, refers to the meaning of a sentence (Manning and Schütze, 1999). In computational linguistics, semantic analysis is a much more complex task because it is based on the unique identification of the meaning of sentences.
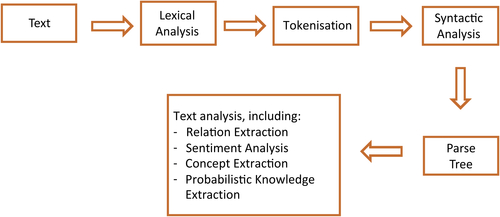
Any text mining process consists of a number of steps to identify and classify sentences according to specific patterns, to analyze a textual source (see Figure 11.2). Broadly speaking, to achieve this, we need to follow these general steps:
1. Fragments of text are divided into manageable components, usually words, that can be subsequently syntactically analyzed.
2. The above components, forming a tokenized text fragment, are then analyzed according to the rules of a formal grammar. The output is a parsing tree—in other words, an ordered tree representing the hierarchical syntactic structure of a sentence.
3. Once we have isolated the syntactic structure of a text fragment, we are in the position of extracting relevant information, such as specific relationships and sentiment analysis.
More specifically, the main components of text mining are as follows:
Lexical Analysis
The most basic level in an NLP system is based on lexical analysis, which deals with words regarded as the atomic structure of text documents; in particular, it is the process that takes place when the basic components of a text are analyzed and grouped into tokens, which are sequences of characters with a collective meaning (Dale et al., 2000). In other words, lexical analysis techniques identify the meaning of individual words, which are assigned to a single part-of-speech (POS) tag. Lexical analysis may require a lexicon, which is usually determined by the particular approach used in a suitably defined NLP system as well as the nature and extent of information inherent in the lexicon. Mainly, lexicons may vary in terms of their complexity because they can contain information about the semantic information related to a word. Moreover accurate and comprehensive sub-categorization lexicons are extremely important for the development of parsing technology as well as for any NLP application that relies on the structure of information related to predicate-argument structure. More research is currently being carried out to provide better tools for analyzing words in semantic contexts (see Korhonen et al., 2006 for an overview).
POS Tagging
POS tagging is one of the first steps in text analysis because it allows us to attach a specific syntactic definition (noun, verb, adjective, etc.) to the words that are part of a sentence. This task tends to be accurate because it relies on a set of rules that are usually unambiguously defined. Consider the word “book.” Depending on the sentence to which it belongs, it might be a verb or a noun. Consider “a book on a chair” and “I will book a table at the restaurant.” The presence of specific keywords such as “a” in the former and “I will” in the latter provides important clues as to the syntactic role that “book” has in the two sentences. One of the main reasons for the overall accuracy of POS tagging is that a semantic analysis is often not required. It is based only on the position of the word and its neighboring words.
Parsing
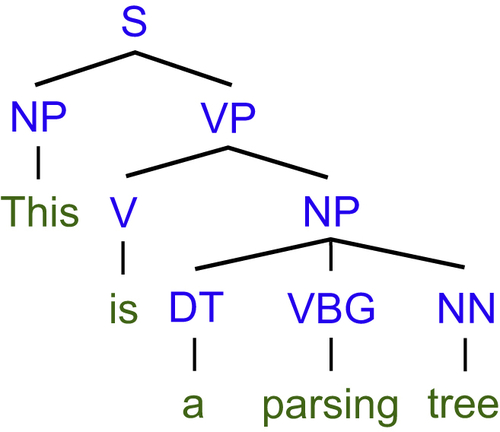
Once the POS tagging of a sentence has identified the syntactic roles of each word, we can consider such a sentence in its entirety. The main difference with POS tagging is that parsing enables the identification of the hierarchical syntactic structure of a sentence. Consider, for example, the parsing tree structure of the sentence “This is a parsing tree,” depicted in Figure 11.3. Each word is associated with a POS symbol that corresponds to its syntactic role (Manning and Schütze, 1999).
Named Entity Recognition
An important aspect of text analysis is the ability to determine the type of the entities within a text fragment. More specifically, determining whether a noun refers to a person, an organization, or a geographical location (to name but a few) substantially contributes to the extraction of accurate information and provides the tools for a deeper understanding. For example, the analysis of “Dogs and cats are the most popular pets in the UK” would identify that dogs and cats are animals and the UK is a country. Clearly, there are many instances where this depends on the context. Think of “India lives in Manchester.” Anyone reading such a sentence would interpret India as the name of a specific person, and rightly so. However, a computer might not be able to do so and may decide that it is a country. We know that a country would not be able to “live” in a city. It is just common sense. Unfortunately, computers do not have the ability to discern what common sense is. They might be able to guess according to the structure of a sentence or the presence of specific keywords. Nevertheless, it is precisely that—a guess. This is an effective example of semantic understanding, which comes naturally to humans but is a complex, if impossible, task for computers.
Co-reference Resolution
Co-reference resolution is the task of determining, which words refer to the same objects. An example is anaphora resolution, which is specifically concerned with the nouns or names to which words refer. Another instance of co-reference resolution is relation resolution, which attempts to identify to which individual entities or objects a relation refers. Consider the following sentence: “We are looking for a corrupted member of the panel.” Here, we are not looking for just any corrupted member of the panel, but for a specific individual.
Relation Extraction
The identification of relations among different entities within a text provides useful information that can be used to disambiguate subcomponents of the text fragment as well as determine quantitative and qualitative information linking such entities. For example, consider the sentence “Smoking potentially causes lung cancer.” Here, the act of smoking is linked to lung cancer by a causal relationship.
Concept Extraction
A crucial task in information extraction from textual sources is concept identification, which is typically defined as one or more keywords or textual definitions. The two main approaches in this task are supervised and unsupervised concept identification, depending on the level of human intervention in the system.
In particular, formal concept analysis (FCA) provides a set of robust data and text mining tools to facilitate the identification of key concepts relevant to a specific topical area (Stumme, 2002). Broadly speaking, unstructured textual datasets are analyzed to isolate clusters of terms and definitions referring to the same concepts, which can be grouped together. One of the main features of FCA is that it is human-centered, so that user(s) can actively interact with the system to determine the most appropriate parameters and starting points of such classifications.
In work by Poelmans et al. (2010), a case study describing the extraction of domestic violence intelligence from a dataset of unstructured Dutch police reports is analyzed by applying FCA. The aim is to determine the concepts defined by terms, which are clustered together. Figure 11.4 depicts the main architecture of this approach. As this figure demonstrates, FCA provides a useful and powerful platform to visualize and capture the main factors in crime detection.
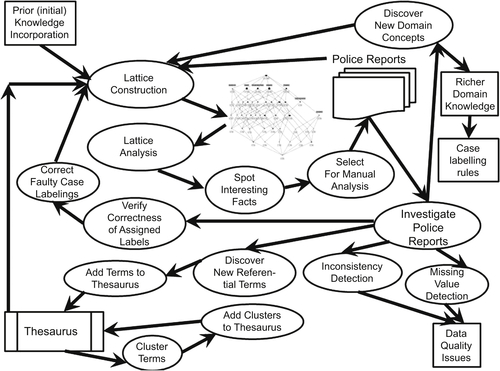
Figure 11.4 Example of a detailed human-centered knowledge discovery process for crime detection using formal concept analysis (FCA) (as described in Chen, 2008).
Topic Recognition
This procedure attempts to identify the general topic of a text by grouping a set of keywords that appear frequently in the documents. These are then associated with one or more concepts to determine the general concept trend.
Sentiment Analysis
This is a particular example of information extraction from text, which focuses on identifying trends of opinions across a population in social media. Broadly speaking, its aim is to determine the polarity of a given text, which identifies whether the opinion expressed is positive, negative, or neutral. This includes emotional states such as anger, sadness, and happiness, as well as intent: for example, planning and researching. Sentiment analysis can be an important tool in obtaining insight into criminal activity because it can detect a general state of mind shared by a group of individuals via their blog entries and social network discussions. A variety of tools are used in crime detection as well as prosecution that can automate law enforcement across several social media, including Web sites, e-mails, personal blogs, and video uploaded onto social platforms (Dale et al., 2000).
Semantic Analysis
Semantic analysis determines the possible meanings of a sentence by investigating interactions among word-level meanings in the sentence. This approach can also incorporate the semantic disambiguation of words with multiple senses. Semantic disambiguation allows selection of the sense of ambiguous words, so that they can be included in the appropriate semantic representation of the sentence (Wilks and Stevenson, 1998). This is particularly relevant in any information retrieval and processing system based on ambiguous and partially known knowledge. Disambiguation techniques usually require specific information about the frequency with which each sense occurs in a particular document, as well as an analysis of the local context and the use of pragmatic knowledge of the domain of the document. An interesting aspect of this research field is concerned with the purposeful use of language in which the use of a context within the text is exploited to explain how extra meaning is part of some documents without actually being constructed in them. Clearly this is still being developed, because it requires an incredibly wide knowledge dealing with intentions, plans, and objectives (Manning and Schütze, 1999). Extremely useful applications in NLP can be seen in inferencing techniques, in which extra information derived from a wider context successfully addresses statistical properties (Kuipers, 1984).
Machine Translation
The automatic translation of a text from one language into another one provides users with the ability to read texts quickly and fairly accurately in a variety of languages. This is a complex task involving several challenges, from mapping different syntactic structures to semantic interpretation and disambiguation.
Bayesian Networks
Bayesian networks (BNs) are graphical models that capture independence relationships among random variables, based on a basic law of probability called Bayes’ rule (Pearl, 1998). They are a popular modeling framework in risk and decision analysis and have been used in a variety of applications such as safety assessment of nuclear power plants, risk evaluation of a supply chain, and medical decision support tools (Nielsen and Verner Jensen, 2009). More specifically, BNs are composed of a graph whose nodes represent objects based on a level of uncertainty, also called random variables, and whose edges indicate interdependence among them. In addition to this graphical representation, BNs contain quantitative information that represents a factorization of the joint probability distribution of all variables in the network. In fact, each node has an associated conditional probability table that captures the probability distribution associated with the node conditional for each possibility.
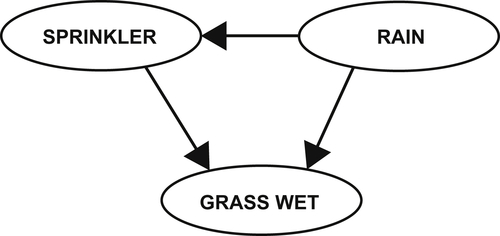
Suppose, for example, we want to explore the chance of finding wet grass on any given day. In particular, assume the following:
1. A cloudy sky is associated with a higher chance of rain.
2. A cloudy sky affects whether the sprinkler system is triggered.
3. Both the sprinkler system and rain have an effect on the chance of finding wet grass.
In this particular example, no probabilistic information is given. The resulting BN is depicted in Figure 11.5.
Such graphical representations provide an intuitive way to depict the dependence relations among variables.
In BN modeling, the strong statements are not about dependencies, but rather about independences (i.e., absence of edges at the graph level), because it is always possible to capture them through the conditional probability tables when an edge is present, even though the reverse is not true.
The construction of a BN can be done either through data or, when unavailable, through literature review or expert elicitation. Whereas the first approach can be automated, the other two require a significant amount of manual work, which can make them impractical on a large scale. There is extensive research on BNs, and in particular their extraction from text corpora is increasingly gaining attention. For example, Sanchez-Graillet and Poesio (2004) suggested a domain-independent method for acquiring text causal knowledge to generate BNs. Their approach is based on a classification of lexico-syntactic patterns, which refer to causation, in which automatic detection of causal patterns and semi-validation of their ambiguity is carried out. Similarly, in work by Kuipers (1984), a supervised method for the detection and extraction of causal relations from open domain texts is presented. The authors provide an in-depth analysis of verbs and cue phrases that encode causality and, to a lesser extent, influence.
Automatic Extraction of BNs from Text
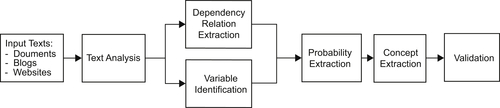
Because of the mathematical constraints posed by Bayes’ rule and general probability theory, identification of suitable BNs is often carried out by human intervention in the form of a modeler who identifies the relevant information. However, this can be time-consuming and may use only specific, often limited, sources depending on the modeler’s expertise. On the other hand, it is enormously valuable to be able to extract the relevant data automatically, in terms of increased efficiency and scalability to the process of defining and populating BNs. However, extracting both explicit and implicit information and making sense of partial or contradictory data can be demanding challenges. More specifically, elements of the quantitative layer depend on the graphical layer; in other words, the structure of the conditional probability tables depends on the parents of each node. Therefore, it is necessary to determine the structure of the BN before populating it with quantitative information. Figure 11.6 depicts the most important components of the general architecture in the automatic extraction of BNs from text.
Dependence Relation Extraction from Text
Nodes in BNs, which are connected by edges, imply that the corresponding random variables are dependent. Such dependence relations must therefore be extracted from textual information when they are present. The conditional dependencies in a BN are often based on known statistical and computational techniques. One of their strengths is the combination of methods from graph theory, probability theory, computer science, and statistics. Linguistically speaking, a dependence relation contains specific keywords that indicate that two concepts are related to a certain degree. Consider the sentence “Lung cancer is more common among smokers.” There is little doubt that we would interpret this as a clear relation linking lung cancer with smoking. However, there is not a precise linguistic definition to determine a relationship between two concepts from the text. The reason is that it depends on the context.
When full automation of the process of textual information extraction is carried out, a clear and unambiguous set of rules ensures a reasonably good level of accuracy. As a consequence, it is usually advisable to consider causal relationships. Causal inference is one stage of a crucial reasoning process (Pearl, 1998) that has a fundamental role in any question-answering technique with interesting artifical intelligence applications such as decision making in BNs. Despite this, they convey a much stronger statement, because causal relations are often regarded as a subgroup of dependence relations; they are more easily spotted owing to a more limited set of linguistic rules that characterize them. Going back to the above example, saying that smoking causes lung cancer assumes a direct link between them. We cannot arguably say the contrary, but there are other cases in which there is a less marked cutoff. If we are looking only for causal relationships when populating a BN, we might miss several dependence relations. However, accuracy is much more preferable. In fact, integrating an automatic BN extraction with human intervention usually addresses this issue. Therefore, the identification of causal relationships between concepts is an essential stage of the extraction of BNs from text.
Causal learning often focuses on long-run predictions through estimating the parameters of causal BN structural learning. An interesting approach is described in Danks et al. (2002), in which people’s short-term behavior is modeled through a dynamic version of the current approaches. Moreover, the limitation of a merely static investigation is addressed by a dynamical approach based on BN methods. Their result applies only to a particular scenario, but it offers a new perspective and shows huge research potential in this area.
Variables Identification
Mapping a representative to a specific variable is closely linked to the task of relations extraction. However, this is partially a modeling choice by the user based on the set of concepts in which she or he is interested. Consider again the sentence “Smoking causes lung cancer.” If this were rephrased as “Smokers are more likely to develop lung cancer,” we would need to ensure that “smoking” and “smokers” are identified as a single variable associated with the act of smoking. In a variety of cases, this can be addressed by considering synonymy. However, as in our example, it might also happen that they refer to the same concept, rather than being the same concept. FCA is a computational technique that can be successfully applied in this particular context.
BN Structure Definition
This step aggregates the information gathered in the previous two steps to output the structure of the BN. This includes evaluating the credibility of each dependence relation, determining whether the dependence stated is direct or indirect, and ensuring that no cycles are created in the process of orienting the edges.
Probability Information Extraction
This step involves processing the textual sources to extract information about the probability of variables. This includes the search for both numerical information and quantitative statements such as “Smoking increases the chances of lung cancer” and “Nonsmokers are less likely to get lung cancer.”
Aggregation of Structural and Probabilistic Data
BNs and Crime Detection
As discussed above, BN modeling is an efficient and powerful tool for defining and investigating systems consisting of phenomena with a level of uncertainty. Because BNs combine expert knowledge with observational and empirical data, they provide a platform that can facilitate decision making. As a consequence, BNs have been successfully applied to crime detection, prevention, and management (Ghazi et al., 2006). In particular, the extraction of BNs from textual sources associated with social networks, and social media in general, can improve the overall modeling power of BNs by enabling the acquisition of large amounts of information and its management with limited human intervention.
An example of BN modeling applied to crime activity detection includes fraudulent transaction identification. In fact, BNs have the distinct advantage of adapting in real time, which enables probabilistic data to be updated while fraud analysts determine whether specific transactions are either fraudulent or legitimate. Furthermore, the process of assessing the quantitative information from each transaction is facilitated by the relative approachability of Bayesian probability evaluation.
Psychological and social profiling of criminal suspects can also benefit from the use of BNs (Stahlschmidt and Tausendteufel, 2013). More specifically, known characteristics of an offender can identify the number of potential suspects by removing individuals who are not likely to have those features, with obvious advantages in terms of time and cost efficiency. Using specific BN modeling can be applied to understanding the structure of an unknown domain as well as for profile prediction. Profilers could, for example, obtain a prediction of the offender’s age and thereby reduce the number of suspects substantially by adding evidence found in the crime scene to an appropriate BN. As part of their investigation, they ascertain that offenders are likely to meet their victims in unfamiliar surroundings, preferring to travel a long distance to avoid obvious exposure of their crime and showing a high level of forensic awareness. On the other hand, more impulsive offenders are likely to commit a crime closer to their familiar environment. The use of BNs in this research field has also facilitated the creation of a probabilistic model to visualize the main factors and parameters in sex-related homicides. Figure 11.7 depicts an example which provides a user-friendly yet rigorous platform to support and facilitate the decision-making progress.
General Architecture
The general architecture of the extraction of BNs from social media for detecting and assessing criminal activity typically consists of the following components (see also Figure 11.8):
1. Existing and predefined information about criminal activity would be incorporated into a database or knowledge database (KDB) consisting of:
a. Historical data from structured databases
b. BNs built on existing data
c. Data entered by modeler(s) and manually validated
The KDB is an important component because it is based on information that is deemed reliable. In a variety of cases, the KDB is maintained by modeling experts to ensure that the data are regularly updated to prevent inconsistency and ambiguity.
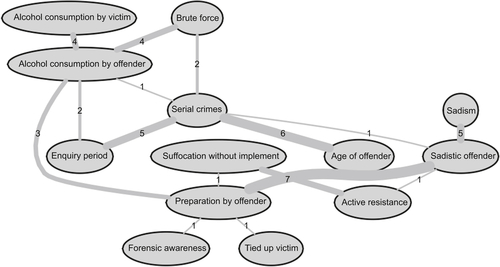
Figure 11.7 Main variables identifying the difference between an offender and situation-driven crime.
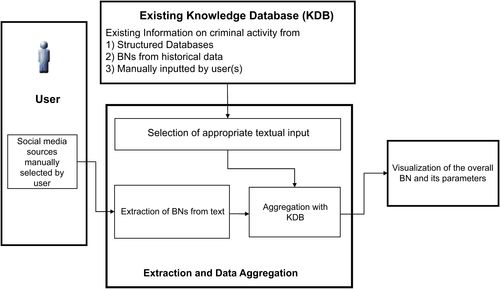
3. The extraction and data aggregation stage consists of identifying appropriate textual data associated with the social media sources and standardization of their format. For example, if a Web page contains multimedia data along with some text, only the latter would be considered. This would enable the extraction of a BN both as an unsupervised and semi-supervised process. This would be integrated with a combination of different information from the KDB with extraction of the sources identified by the user and the removal of any data duplication. An essential part of this process is to address data inconsistency at both a qualitative and quantitative level. As discussed above, BNs have strict mathematical constraints that make any fully unsupervised automatic extraction prone to inaccuracies and inconsistencies. As a consequence, human intervention is often advisable to minimize error.
4. Finally, the BN is visualized, providing:
a. Relevant information on the structure of the BN
b. Description of the different parameters
c. Any required action to address inconsistency that could not be resolved automatically. This is typically an interactive step in which the result can be updated by the user and focused on a specific part of the BN.
Example of BN Application to Crime Detection: Covert Networks
Automatic extraction of relevant information to define and populate BNs has a variety of applications in crime detection and management. Furthermore, the huge potential offered by the investigation of Big Data can provide critical insight into criminal activities. However, the extraction, assessment, and management of datasets that are continuously created poses challenges that have to be addressed to provide a valuable platform.
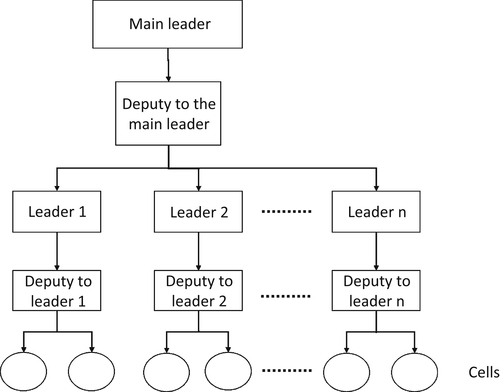
A relevant scenario in which BNs provide a useful tool in criminal detection is described in Smith et al. (2013), who discuss criminal detection within covert communities. A well-known example is the terrorist network that carried out the 9/11 attack in the United States. In fact, it exhibited the property that members of the different cells were kept unconnected, which ensured that the structure of the network was unknown by its components (Krebs, 2002). These types of networks tend to be defined by a tree, as shown in Figure 11.9.
Despite the difficulties in the assessment and criminal detection of such networks, covert communities tend to be discoverable during any activity they may carry out, even for a short amount of time. In particular, this allows the different components and their interconnections to be fully observable, which suggests that BNs can successfully model such scenarios correlating a priori information regarding the observed network connections. All relevant information can be gathered from both structured and unstructured Big Datasets, including surveillance and reconnaissance sensors such as wide-area motion imagery, and textual information from the Web (Smith et al., 2013).
Conclusions
The ability to mine social media to extract relevant information provides a crucial tool in crime detection. A wealth of emerging techniques has been successfully applied in this field and has led to increased multidisciplinary collaboration among academics and practitioners. In particular, because a great proportion of relevant information contained in social media is in the form of unstructured data, there is a common effort to provide state-of-the-art tools and techniques to automatically collect and assess intelligence on criminal activity.
Furthermore, since the birth of Big Data, the availability of increasingly large datasets has introduced huge potential in crime detection. However, this raises several difficulties in identifying relevant and accurate information and its assessment. In fact, any information extraction from Big Data sets is highly inefficient and error prone when it is addressed manually. Therefore, the creation of specific approaches to automated mining of social media for criminal activity and the assessment of complex systems with a level of uncertainty allow the retrieval, management, and analysis of Big Datasets with small human intervention (see Chapter 3). This facilitates the decision-making process supported by both observed and inferred knowledge, which is of paramount importance when determining and isolating criminal activity.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.