Making Sense of Unstructured Natural Language Information
Abstract
Making sense of the vast mountains of data that are being increased by tremendous quantities each day is a significant challenge. Whereas much of these data are produced by devices (sensors, cameras, global positioning systems, etc.), the volume of information produced by humans in the form of natural language is also growing dramatically. Making sense of text-based information is of particular importance in many communities including security, intelligence, and crisis management, where the focus is on the actors who may be involved in illicit or threatening activities or who may be caught up in disaster situations in which human communications have an important role in protecting life and property. However, dealing with unstructured natural language information has specific challenges not present in device-generated data. Current technologies for text analytics offer some limited partial solutions for intelligence purposes, but many problems remain unsolved or are only in the early stages. In this chapter we examine a number of issues involved in dealing with unstructured natural language data, discuss briefly the strengths and weaknesses of some widely used technologies for text analytics, and look at a flexible alternative solution to fill some of the gaps.
Keywords
Intelligence; Natural language; Sense making; Unstructured dataIntroduction
Information is of great value when a deduction of some sort can be drawn from it. This may occur as a result of its association with some other information already received.
AJP 2.0 Allied Joint Intelligence, Counter Intelligence and Security Doctrine (NATO, 2003)
Big Data and Unstructured Data
Aspects of Uncertainty in Sense Making
Situation Awareness and Intelligence
Situation Awareness: Short Timelines, Small Footprint
Intelligence: Long(er) Timelines, Larger Footprint
Processing Natural Language Data
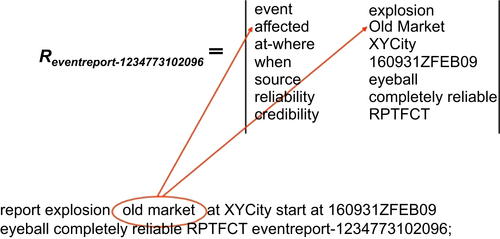
Structuring Natural Language Data
Two Significant Weaknesses
Ignoring Lexical Clues on Credibility and Reliability
Out of Context, Out of Mind
An Alternative Representation for Flexibility