
Like all lookup tables, direct-access tables replace more complicated logical control structures. They are "direct access" because you don't have to jump through any complicated hoops to find the information you want in the table. As Figure 18-1 suggests, you can pick out the entry you want directly.
Figure 18-1. As the name suggests, a direct-access table allows you to access the table element you're interested in directly
Suppose you need to determine the number of days per month (forgetting about leap year, for the sake of argument). A clumsy way to do it, of course, is to write a large if statement:
Example 18-3. Visual Basic Example of a Clumsy Way to Determine the Number of Days in a Month
If ( month = 1 ) Then days = 31 ElseIf ( month = 2 ) Then days = 28 ElseIf ( month = 3 ) Then days = 31 ElseIf ( month = 4 ) Then days = 30 ElseIf ( month = 5 ) Then days = 31 ElseIf ( month = 6 ) Then days = 30 ElseIf ( month = 7 ) Then days = 31 ElseIf ( month = 8 ) Then days = 31 ElseIf ( month = 9 ) Then days = 30 ElseIf ( month = 10 ) Then days = 31 ElseIf ( month = 11 ) Then days = 30 ElseIf ( month = 12 ) Then days = 31 End If
An easier and more modifiable way to perform the same function is to put the data in a table. In Microsoft Visual Basic, you'd first set up the table:
Now, instead of using the long if statement, you can just use a simple array access to find out the number of days in a month:
Example 18-5. Visual Basic Example of an Elegant Way to Determine the Number of Days in a Month (continued)
If you wanted to account for leap year in the table-lookup version, the code would still be simple, assuming LeapYearIndex() has a value of either 0 or 1:
Example 18-6. Visual Basic Example of an Elegant Way to Determine the Number of Days in a Month (continued)
In the if-statement version, the long string of ifs would grow even more complicated if leap year were considered.
Determining the number of days per month is a convenient example because you can use the month variable to look up an entry in the table. You can often use the data that would have controlled a lot of if statements to access a table directly.
Suppose you're writing a program to compute medical insurance rates and you have rates that vary by age, gender, marital status, and whether a person smokes. If you had to write a logical control structure for the rates, you'd get something like this:
Java Example of a Clumsy Way to Determine an Insurance Rate

Example 18-7.
if ( gender == Gender.Female ) {
if ( maritalStatus == MaritalStatus.Single ) {
if ( smokingStatus == SmokingStatus.NonSmoking ) {
if ( age < 18 ) {
rate = 200.00;
}
else if ( age == 18 ) {
rate = 250.00;
}
else if ( age == 19 ) {
rate = 300.00;
}
...
else if ( 65 < age ) {
rate = 450.00;
}
else {
if ( age < 18 ) {
rate = 250.00;
}
else if ( age == 18 ) {
rate = 300.00;
}
else if ( age == 19 ) {
rate = 350.00;
}
...
else if ( 65 < age ) {
rate = 575.00;
}
}
else if ( maritalStatus == MaritalStatus.Married )
...
}The abbreviated version of the logic structure should be enough to give you an idea of how complicated this kind of thing can get. It doesn't show married females, any males, or most of the ages between 18 and 65. You can imagine how complicated it would get when you programmed the whole rate table.
You might say, "Yeah, but why did you do a test for each age? Why don't you just put the rates in arrays for each age?" That's a good question, and one obvious improvement would be to put the rates into separate arrays for each age.
A better solution, however, is to put the rates into arrays for all the factors, not just age. Here's how you would declare the array in Visual Basic:
Example 18-8. Visual Basic Example of Declaring Data to Set Up an Insurance Rates Table
Public Enum SmokingStatus SmokingStatus_First = 0 SmokingStatus_Smoking = 0 SmokingStatus_NonSmoking = 1 SmokingStatus_Last = 1 End Enum Public Enum Gender Gender_First = 0 Gender_Male = 0 Gender_Female = 1 Gender_Last = 1 End Enum Public Enum MaritalStatus MaritalStatus_First = 0 MaritalStatus_Single = 0 MaritalStatus_Married = 1 MaritalStatus_Last = 1 End Enum Const MAX_AGE As Integer = 125 Dim rateTable ( SmokingStatus_Last, Gender_Last, MaritalStatus_Last, _ MAX_AGE ) As Double
Once you declare the array, you have to figure out some way of putting data into it. You can use assignment statements, read the data from a disk file, compute the data, or do whatever is appropriate. After you've set up the data, you've got it made when you need to calculate a rate. The complicated logic shown earlier is replaced with a simple statement like this one:
Cross-Reference
One advantage of a table-driven approach is that you can put the table's data in a file and read it at run time. That allows you to change something like an insurance rates table without changing the program itself. For more on the idea, see Binding Time.
This approach has the general advantages of replacing complicated logic with a table lookup. The table lookup is more readable and easier to change.
You can use a table to describe logic that's too dynamic to represent in code. With the character-classification example, the days-in-the-month example, and the insurance rates example, you at least knew that you could write a long string of if statements if you needed to. In some cases, however, the data is too complicated to describe with hard-coded if statements.
If you think you've got the idea of how direct-access tables work, you might want to skip the next example. It's a little more complicated than the earlier examples, though, and it further demonstrates the power of table-driven approaches.
Suppose you're writing a routine to print messages that are stored in a file. The file usually has about 500 messages, and each file has about 20 kinds of messages. The messages originally come from a buoy and give water temperature, the buoy's location, and so on.
Each of the messages has several fields, and each message starts with a header that has an ID to let you know which of the 20 or so kinds of messages you're dealing with. Figure 18-2 illustrates how the messages are stored.
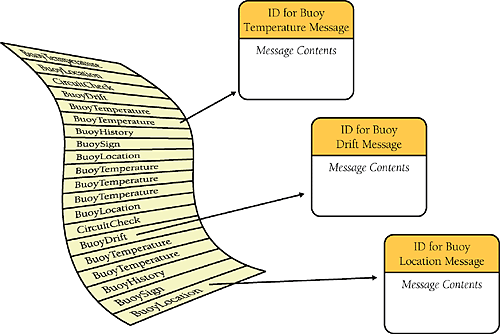
Figure 18-2. Messages are stored in no particular order, and each one is identified with a message ID
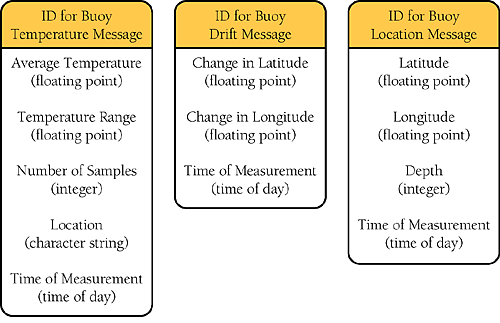
The format of the messages is volatile, determined by your customer, and you don't have enough control over your customer to stabilize it. Figure 18-3 shows what a few of the messages look like in detail.
If you used a logic-based approach, you'd probably read each message, check the ID, and then call a routine that's designed to read, interpret, and print each kind of message. If you had 20 kinds of messages, you'd have 20 routines. You'd also have who-knows-how-many lower-level routines to support them—for example, you'd have a PrintBuoyTemperatureMessage() routine to print the buoy temperature message. An object-oriented approach wouldn't be much better: you'd typically use an abstract message object with a subclass for each message type.
Each time the format of any message changed, you'd have to change the logic in the routine or class responsible for that message. In the detailed message earlier, if the average-temperature field changed from a floating point to something else, you'd have to change the logic of PrintBuoyTemperatureMessage(). (If the buoy itself changed from a "floating point" to something else, you'd have to get a new buoy!)
In the logic-based approach, the message-reading routine consists of a loop to read each message, decode the ID, and then call one of 20 routines based on the message ID. Here's the pseudocode for the logic-based approach:
While more messages to read
Read a message header
Decode the message ID from the message header
If the message header is type 1 then
Print a type 1 message
Else if the message header is type 2 then
Print a type 2 message
...
Else if the message header is type 19 then
Print a type 19 message
Else if the message header is type 20 then
Print a type 20 messageCross-Reference
This low-level pseudocode is used for a different purpose than the pseudocode you use for routine design. For details on designing in pseudocode, see Chapter 9.
The pseudocode is abbreviated because you can get the idea without seeing all 20 cases.
If you were using a rote object-oriented approach, the logic would be hidden in the object inheritance structure but the basic structure would be just as complicated:
While more messages to read
Read a message header
Decode the message ID from the message header
If the message header is type 1 then
Instantiate a type 1 message object
Else if the message header is type 2 then
Instantiate a type 2 message object
...
Else if the message header is type 19 then
Instantiate a type 19 message object
Else if the message header is type 20 then
Instantiate a type 20 message object
End if
End WhileRegardless of whether the logic is written directly or contained within specialized classes, each of the 20 kinds of messages will have its own routine for printing its message. Each routine could also be expressed in pseudocode. This is the pseudocode for the routine to read and print the buoy temperature message:
Print "Buoy Temperature Message" Read a floating-point value Print "Average Temperature" Print the floating-point value Read a floating-point value Print "Temperature Range" Print the floating-point value Read an integer value Print "Number of Samples" Print the integer value Read a character string Print "Location" Print the character string Read a time of day Print "Time of Measurement" Print the time of day
This is the code for just one kind of message. Each of the other 19 kinds of messages would require similar code. And if a 21st kind of message was added, either a 21st routine or a 21st subclass would need to be added—either way a new message type would require the code to be changed.
The table-driven approach is more economical than the previous approach. The message-reading routine consists of a loop that reads each message header, decodes the ID, looks up the message description in the Message array, and then calls the same routine every time to decode the message. With a table-driven approach, you can describe the format of each message in a table rather than hard-coding it in program logic. This makes it easier to code originally, generates less code, and makes it easier to maintain without changing code.
To use this approach, you start by listing the kinds of messages and the types of fields. In C++, you could define the types of all the possible fields this way:
Rather than hard-coding printing routines for each of the 20 kinds of messages, you can create a handful of routines that print each of the primary data types—floating point, integer, character string, and so on. You can describe the contents of each kind of message in a table (including the name of each field) and then decode each message based on the description in the table. A table entry to describe one kind of message might look like this:
This table could be hard-coded in the program (in which case, each of the elements shown would be assigned to variables), or it could be read from a file at program startup time or later.
Once message definitions are read into the program, instead of having all the information embedded in a program's logic, you have it embedded in data. Data tends to be more flexible than logic. Data is easy to change when a message format changes. If you have to add a new kind of message, you can just add another element to the data table.
Here's the pseudocode for the top-level loop in the table-driven approach:
Example 18-12.
While more messages to read <-- 1 Read a message header | Decode the message ID from the message header <-- 1 Look up the message description in the message-description table Read the message fields and print them based on the message description End While
(1)The first three lines here are the same as in the logic-based approach.
Unlike the pseudocode for the logic-based approach, the pseudocode in this case isn't abbreviated because the logic is so much less complicated. In the logic below this level, you'll find one routine that's capable of interpreting a message description from the message description table, reading message data, and printing a message. That routine is more general than any of the logic-based message-printing routines but not much more complicated, and it will be one routine instead of 20:
While more fields to print
Get the field type from the message description
case ( field type )
of ( floating point )
read a floating-point value
print the field label
print the floating-point value
of ( integer )
read an integer value
print the field label
print the integer value
of ( character string )
read a character string
print the field label
print the character string
of ( time of day )
read a time of day
print the field label
print the time of day
of ( boolean )
read a single flag
print the field label
print the single flag
of ( bit field )
read a bit field
print the field label
print the bit field
End Case
End WhileAdmittedly, this routine with its six cases is longer than the single routine needed to print the buoy temperature message. But this is the only routine you need. You don't need 19 other routines for the 19 other kinds of messages. This routine handles the six field types and takes care of all the kinds of messages.
This routine also shows the most complicated way of implementing this kind of table lookup because it uses a case statement. Another approach would be to create an abstract class AbstractField and then create subclasses for each field type. You won't need a case statement; you can call the member routine of the appropriate type of object.
Here's how you would set up the object types in C++:
This code fragment declares a member routine for each class that has a string parameter and a FileStatus parameter.
The next step is to declare an array to hold the set of objects. The array is the lookup table, and here's how it looks:
The final step required to set up the table of objects is to assign the names of specific objects to the Field array:
This code fragment assumes that FloatingPointField and the other identifiers on the right side of the assignment statements are names of objects of type AbstractField. Assigning the objects to array elements in the array means that you can call the correct ReadAndPrint() routine by referencing an array element instead of by using a specific kind of object directly.
Once the table of routines is set up, you can handle a field in the message simply by accessing the table of objects and calling one of the member routines in the table. The code looks like this:
Example 18-16. C++ Example of Looking Up Objects and Member Routines in a Table
fieldIdx = 1; <-- 1 while ( ( fieldIdx <= numFieldsInMessage ) && ( fileStatus == OK ) ) { <-- 1 fieldType = fieldDescription[ fieldIdx ].FieldType; fieldName = fieldDescription[ fieldIdx ].FieldName; field[ fieldType ].ReadAndPrint( fieldName, fileStatus ); <-- 2 fieldIdx++; }
(1)This stuff is just housekeeping for each field in a message.
(2)This is the table lookup that calls a routine depending on the type of the field—just by looking it up in a table of objects.
Remember the original 34 lines of table-lookup pseudocode containing the case statement? If you replace the case statement with a table of objects, this is all the code you'd need to provide the same functionality. Incredibly, it's also all the code needed to replace all 20 of the individual routines in the logic-based approach. Moreover, if the message descriptions are read from a file, new message types won't require code changes unless there's a new field type.
You can use this approach in any object-oriented language. It's less error-prone, more maintainable, and more efficient than lengthy if statements, case statements, or copious subclasses.
The fact that a design uses inheritance and polymorphism doesn't make it a good design. The rote object-oriented design described earlier in the "Object-Oriented Approach" section would require as much code as a rote functional design—or more. That approach made the solution space more complicated, rather than less. The key design insight in this case is neither object orientation nor functional orientation—it's the use of a well thought out lookup table.
In each of the three previous examples, you could use the data to key into the table directly. That is, you could use messageID as a key without alteration, as you could use month in the days-per-month example and gender, maritalStatus, and smokingStatus in the insurance rates example.
You'd always like to key into a table directly because it's simple and fast. Sometimes, however, the data isn't cooperative. In the insurance rates example, age wasn't well behaved. The original logic had one rate for people under 18, individual rates for ages 18 through 65, and one rate for people over 65. This meant that for ages 0 through 17 and 66 and over, you couldn't use the age to key directly into a table that stored only one set of rates for several ages.
This leads to the topic of fudging table-lookup keys. You can fudge keys in several ways:
Duplicate information to make the key work directly. One straightforward way to make age work as a key into the rates table is to duplicate the under-18 rates for each of the ages 0 through 17 and then use the age to key directly into the table. You can do the same thing for ages 66 and over. The benefits of this approach are that the table structure itself is straightforward and the table accesses are also straightforward. If you needed to add age-specific rates for ages 17 and below, you could just change the table. The drawbacks are that the duplication would waste space for redundant information and increase the possibility of errors in the table—if only because the table would contain redundant data.
Transform the key to make it work directly. A second way to make Age work as a direct key is to apply a function to Age so that it works well. In this case, the function would have to change all ages 0 through 17 to one key, say 17, and all ages above 66 to another key, say 66. This particular range is well behaved enough that you could use min() and max() functions to make the transformation. For example, you could use the expression
max( min( 66, Age ), 17 )
to create a table key that ranges from 17 to 66.
Creating the transformation function requires that you recognize a pattern in the data you want to use as a key, and that's not always as simple as using the min() and max() routines. Suppose that in this example the rates were for five-year age bands instead of one-year bands. Unless you wanted to duplicate all your data five times, you'd have to come up with a function that divided Age by 5 properly and used the min() and max() routines.
Isolate the key transformation in its own routine. If you have to fudge data to make it work as a table key, put the operation that changes the data to a key into its own routine. A routine eliminates the possibility of using different transformations in different places. It makes modifications easier when the transformation changes. A good name for the routine, like KeyFromAge(), also clarifies and documents the purpose of the mathematical machinations.
If your environment provides ready-made key transformations, use them. For example, Java provides HashMap, which can be used to associate key/value pairs.