
The DDL and Database Objects
The DDL is used to create, modify, and destroy database objects. Four types of DDL statements correspond to the following types of tasks:
CREATE is used to create database objects.
DROP is used to delete database objects or remove constraint definitions from them.
ALTER is used to modify an existing database object.
DECLARE is used for creating temporary objects.
We will discuss how DDL is used to manage the following types of objects:
Tables
Indexes
Views
Schemas
Tables
A table is an unordered set of data records that consists of columns and rows. Each row is commonly known as a record, and consists of one or more columns. Each column is a piece of data with a data type. There are three types of tables:
Permanent (base) tables
Temporary (declared) tables
Temporary (derived) tables
Only permanent tables are discussed in this chapter because these are the only ones relevant for the Fundamentals Exam. Permanent tables are created using the CREATE TABLE statement, which specifies a logical representation of how table data is physically stored. There are two major ways this can be achieved. If you have an existing database table, you can create an identical table with the same columns, keys, and constraints using the following statement:
CREATE TABLE t2 LIKE t1
This statement creates a new table called t2 using the data definitions of a table called t1. Of course, this assumes that t1 already exists. So, how do you create t1, defining all aspects of its data definition? To create t1 or any other table, you need to understand what constitutes the data definitions of a table. The three elements to this discussion, data types, constraints, and keys are covered in the following sections.
Data Types
Based on the contents of each row of your data, you need to assign a data type to each column. The data type of a column indicates the length of the values in it and the kind of data that is valid for it. There are two major categories of data types in DB2:
Built-in data types
User-defined data types
There are three types of user-defined types:
User-defined distinct types
User-defined structured types
User-defined reference types
For the Fundamentals Exam, you need to understand the concepts behind the built-in data types and the user-defined distinct types. Each user-defined distinct type is based on a built-in data type (or on another user-defined type), so to learn more about them, you first need to understand DB2's built-in data types.
In doing so, you should focus on understanding which type would be used in a given situation. There might be cases when multiple types are possible for the given data, but there is always a best choice. For example, if you are storing whole numbers, then an integer-based data type would be more suitable than a string type.
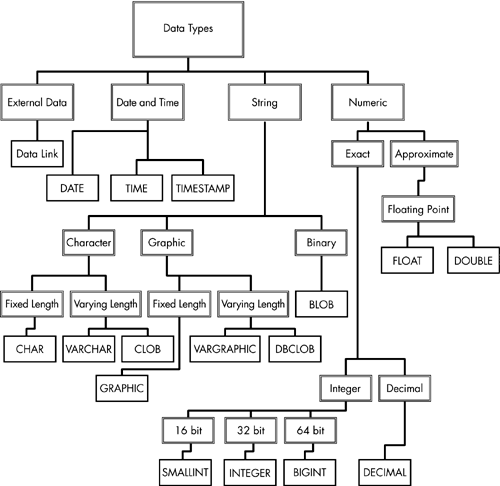
There are four main categories of data types in DB2:
Numeric
String
Date and Time
External File (Datalink)
Figure 3.1 shows all data types contained in a tree representation.
Figure 3.1. DB2 Data Types.
Numeric Data Types
Numeric data types are used to store integer, decimal, and floating point values. Integer data types don't allow any digits to the right of the decimal. There are six types of numeric data types:
SMALLINT
INTEGER
BIGINT
DECIMAL/NUMERIC
REAL/FLOAT
DOUBLE/FLOAT
Small Integer (SMALLINT)
SMALLINT uses the least amount of storage in the database for each value. The data value range for a SMALLINT is –32768 to 32767. The precision for a SMALLINT is five digits (to the left of the decimal). Two bytes of database storage are used for each SMALLINT column value.
Integer (INTEGER)
INTEGER takes twice as much as a SMALLINT, but has a range between –2,147,483,648 and 2,147,483,647. The precision for an INTEGER value is 10 digits to the left of the decimal. Four bytes of database storage are used for each column value.
To create a table T1 with a single INTEGER column C1, use the following CREATE TABLE statement:
CREATE TABLE T1(C1 INTEGER);
The short form INT also can be used in place of INTEGER. Notice that in SQL the name of the column precedes the data type when the table is defined. This is the opposite of some programming languages such as C and Java.
Big Integer (BIGINT)
BIGINT is available for supporting 64-bit integers, which means you have a whopping range of –9,223,372,036,854,775,808 to 9,223,372,036,854,775,807. As platforms include native support for 64-bit integers, the processing of large numbers with BIGINT is more efficient than processing with DECIMAL and more precise than DOUBLE or REAL.
Decimal (DECIMAL/NUMERIC)
The DECIMAL or NUMERIC type is used for numbers with fractional and whole parts. The DECIMAL data is stored in a packed format. When a DECIMAL data type is used, the precision and scale must both be provided. The maximum precision is 31 digits. The scale must be less than or equal to the precision. The terms NUMERIC, NUM, DECIMAL, and DEC can all be used to create a DECIMAL data type. To add a column to our table T1, we can use the ALTER TABLE ADD COLUMN command as follows:
ALTER TABLE T1 ADD COLUMN C2 DECIMAL(13,3)
This adds a column called C2 to T1 with a DECIMAL data type that allows 13 digits of total precision and its scale is 3 digits to the right of the decimal. Thus, the general form of a DECIMAL data type is DECIMAL(precision, scale). To create a DECIMAL data type to store currency amounts for up to $50 million, you would use DECIMAL(10,2) to capture the dollars and cents, respectively.
If the precision and scale values are not supplied for a DECIMAL data type, then the default is (5,0). DECIMAL data types require p/2 + 1 bytes of storage, where p is the precision used. For example, a DECIMAL(10,2) number would take up 10/2 + 1 = 6 bytes of storage.
Single-precision floating point (REAL/FLOAT)
A REAL data type is an approximation of a number. The approximation requires 32 bits or 4 bytes of storage. To specify a single-precision number using the REAL data type, its length must be defined between 1 and 24 (especially if the FLOAT data type is used, as it can represent both single- and double-precision and is determined by the integer value specified).
Double-precision floating point (DOUBLE/FLOAT)
A DOUBLE or FLOAT data type is an approximation of a number that requires 64 bits or 8 bytes of storage. To specify a double-precision number using the FLOAT data type, its length must be defined between 25 and 53.
NOTE
Both single- and double-floating point numbers are represented using exponential notation.
String Data Types
String data types include character strings and binary strings. Character strings can either be single-byte character strings or double-byte character strings. All possible string data types are discussed in the following section.
Fixed-Length Character String (CHAR)
Fixed-length character strings are stored in the database using the entire defined amount of storage. If the data being stored always has the same length, a CHAR data type should be used. For example, if you are storing employee information for a corporation where the employee identifier is always a nine-digit alphanumeric value, a CHAR data type with length 9 would be most appropriate:
CREATE TABLE employee(employee_id CHAR(9));
This example alters an existing table called EMPLOYEE by adding the EMPLOYEE_ID column.
The synonym CHARACTER can be used in place of CHAR. Fixed-length character types potentially waste a lot of disk space within the database if the data is not using the defined amount of storage. However, overhead is involved in storing varying-length character strings, as you will see. The length of a fixed-length string must be between 1 and 254 characters. If you do not supply a value for the length, a value of 1 is assumed.
Varying-Length Character String (VARCHAR)
Varying-length character strings are stored in the database using only the amount of space required to store the data. The term CHAR VARYING or CHARACTER VARYING can be used as a synonym for VARCHAR. If a varying-length character string is updated and the resulting value is larger than the original, the record will be moved to another page on the table. The original data record is then known as a tombstone record or pointer record. Too many pointer records can cause significant performance degradation because multiple pages are required to return a single data record. The maximum length of a VARCHAR column is 32,672 bytes.
It would be appropriate to use the last name for each employees as a VARCHAR because this will vary from each employee:
ALTER TABLE employee ADD COLUMN last_name VARCHAR(30);
Varying-Length Long Character String (LONG VARCHAR)
In DB2 v7.x, the VARCHAR type's upper limit increased to 32,672 bytes, virtually the same as the LONG VARCHAR type, which allows up to 32,700 bytes. The LONG VARCHAR type is not used as often as a result. If you need more than 32,672 bytes, it is recommended to use the CLOB data type.
NOTE
The FOR BIT DATA clause can be used following a character string column definition. During data exchange, code page conversions are not performed. Rather, data is treated and compared as a binary (bit) data.
Character Large Object (CLOB)
Character large objects are varying-length SBCS (single-byte character set) or MBCS (multibyte character set) character strings that are stored in the database. A code page is associated with each CLOB. CLOB columns are used to store strings greater than 32 KB in length, up to a maximum of 2 GB. Because this data type is varying-length, the amount of disk space allocated is determined by the amount of data in each record. Therefore, you should create the column specifying the length of the longest string.
Double-Byte Character Strings (GRAPHIC)
The GRAPHIC data types represent a single character using 2 bytes of storage. The GRAPHIC data types include:
GRAPHIC (fixed length—maximum 127 characters)
VARGRAPHIC (varying-length—maximum 16,336 characters)
LONG VARGRAPHIC (varying-length—maximum 16,350 characters)
Double-Byte Character Large Objects (DBCLOB)
Double-byte character large objects are varying-length character strings that are stored in the database using 2 bytes to represent each character. A code page is associated with each column. DBCLOB columns are used for large amounts (>32 KB) of double-byte text data such as Japanese text.
The maximum length should be specified during the column definition because each data record will be variable in length.
Binary Large Object (BLOB)
Binary large objects are variable-length binary strings. The data is stored in a binary format in the database. There are restrictions when using this data type including the inability to sort using this type of column. The BLOB data type is useful for storing nontraditional relational database information such as audio files or images. The maximum size of each BLOB is 2 GB. Since each binary string is varying-length, the amount of allocated disk space is determined by the amount of data in each record, not by the defined maximum size of the column in the table definition.
Date and Time Data Types
Three DB2 data types are specifically used to represent dates and times:
DATE— This data type is stored internally as a (packed) string of 4 bytes. Externally, the string has a length of 10 bytes (MM-DD-YYYY—this representation can vary and is dependent on the country code).
TIME— This data type is stored internally as a (packed) string of 3 bytes. Externally, the string has a length of 8 bytes (HH-MM-SS—this representation can vary).
TIMESTAMP— This data type is stored internally as a packed string of 10 bytes. Externally, the string has a length of 26 bytes (YYYY-MM-DD-HH-MM-SS-NNNNNN).
From the user perspective, these data types can be treated as character or string data types. Every time you need to use a datetime attribute, you will need to enclose it in quotation marks. However, datetime data types are not stored in the database as fixed-length character strings.
DB2 provides special functions that allow you to manipulate these data types. These functions allow you to extract the month, hour, or year of a datetime column.
The date and time formats correspond to the country code of the database or a specified format (because the representation of dates and times varies in different countries). Therefore, the string that represents a date value will change depending on the country code (or format specified). In some countries, the date format is DD/MM/YYYY, whereas in other countries, it is YYYY-MM-DD. You should be aware of the country code/format used by your applications to use the correct date string format. If an incorrect format is used, an SQL error will be reported.
As a general recommendation, if you are interested in a single element of a date string, say month or year, always use the SQL functions provided by DB2 to interpret the column value. By using the SQL functions, your application will be more portable.
Date String (DATE)
There are a number of valid methods of representing a DATE as a string. Any of the string formats shown in Table 3.1 can be used to store dates in a DB2 database.
| Format Name | Abbreviation | Date Format |
|---|---|---|
| International Standards Organization | ISO | YYYY-MM-DD |
| IBM USA Standard | USA | MM/DD/YYYY |
| IBM European Standard | EUR | DD.MM.YYYY |
| Japanese Industrial Standard | JIS | YYYY-MM-DD |
| Site Defined | LOC | Depends on database country code |
When data is retrieved using a SELECT statement (discussed in Chapter 4), the output string will be in one of these formats. There is an option of the BIND command called DATETIME, which allows you to define the external format of the date and time values. The abbreviation column in Table 3.1 contains some possible values for the DATETIME option of the BIND command.
Time String (TIME)
There are a number of valid methods for representing a TIME as a string. Any of the string formats in Table 3.2 can be used to store times in a DB2 database. When data is retrieved, the external format of the time will be one of the formats shown in Table 3.2.
| Format Name | Abbreviation | Date Format |
|---|---|---|
| International Standards Organization | ISO | HH.MM.SS |
| IBM USA Standard | USA | HH:MM AM or PM |
| IBM European Standard | EUR | HH.MM.SS |
| Japanese Industrial Standard | JIS | HH:MM:SS |
| Site Defined | LOC | Depends on database country code |
A BIND option, called DATETIME, allows you to define the external format of the date and time values. The abbreviation column in Table 3.2 contains some possible values for the DATETIME BIND option.
Timestamp String (TIMESTAMP)
The TIMESTAMP data type has a single external format. Therefore, the DATETIME BIND option does not affect the external format of timestamps. Time-stamps have an external representation as YYYY-MM-DD-HH.MM.SS.NNNNNN (Year-Month-Day-Hour.Minute.Seconds.Microseconds).
External File Data Types (DATALINK)
DATALINK is an encapsulated value that contains a logical reference from the database to a file stored in a Data Links Manager Server, which is outside the database. A DATALINK is an alternative to using data types such as binary strings to store the file itself. For the purposes of the Fundamentals Exam, understand these basic concepts. You can find details about DATALINK data types in the DB2 v8 SQL Reference.
User-Defined Data Types
User-defined data types (UDTs) can be created on an existing data type or on other UDTs. UDTs are used to define further types of data being represented in the database. If columns are defined using different UDTs based on the same base data type, these UDTs cannot be directly compared. This is known as strong typing. DB2 provides this strong data typing to avoid end-user mistakes during the assignment or comparison of different types of real-world data.
For example, if you have a table that will be used to store different measures of weight such as pounds and kilograms, you should use a numeric data type for these columns because arithmetic operations are appropriate. You use the INTEGER data type as the base DB2 data type for the UDTs, KILOGRAM and POUND. The values represent different units and should not be directly compared.
NOTE
UDTs can be based on other UDTs or existing DB2 data types.
To create a UDT for pound and kilogram, respectively, you use the following DDL statements:
CREATE DISTINCT TYPE pound AS INTEGER WITH COMPARISONS; CREATE DISTINCT TYPE kilogram AS INTEGER WITH COMPARISONS;
The keyword DISTINCT is mandatory for all UDTs. The WITH COMPARISONS clause is also mandatory except for LOB, LONG, and DATALINK data types. When the UDTs are defined, system-generated SQL functions are created. These functions are known as casting functions. The casting functions allow comparison between the UDT and its base type. In the real world, you cannot directly compare pounds and kilograms without converting one of the values into the other type. In DB2, a user-defined function is required to achieve this. Creating user-defined functions is covered in the Application Development with DB2 section.
To drop a UDT, use the following syntax:
DROP DISTINCT TYPE pound;
Selecting Data Types
Knowledge of the possible data values and their usage is required to select the correct data type. Specifying an inappropriate data type when defining tables can result in:
Wasted disk space
Improper expression evaluation
Performance implications
A small checklist for data type selection is provided in Table 3.3.
When using character data types, the choice between CHAR and VARCHAR is determined by the range of lengths of the columns. For example, if the range of column length is relatively small, use a fixed CHAR with the maximum length. This will reduce the storage requirements and could improve performance.
| Question | Data Type(s) |
|---|---|
| Is the data variable in length? | VARCHAR |
| If the data is variable in length, then what is the maximum length? | VARCHAR |
| Do you need to sort (order) the data? | CHAR, VARCHAR, NUMERIC |
| Is the data going to be used in arithmetic operations? | DECIMAL, NUMERIC, REAL, DOUBLE, BIGINT, INTEGER, SMALLINT |
| Does the data element contain decimals? | DECIMAL, NUMERIC, REAL, DOUBLE |
| Is the data fixed in length? | CHAR |
| Does the data have a specific meaning (beyond DB2 base data types?) | USER DEFINED TYPE |
| Is the data larger than a character string can store, or do you need to store the nontraditional data? | CLOB, BLOB, DBCLOB |
Null Value Considerations
A null value represents an unknown state. Therefore, when columns containing null values are used in calculations, the result is unknown. All of the data types discussed in the previous section support the presence of null values. During the table definition, you can specify that a valid value must be provided. This is accomplished by adding a phrase to the column definition. The CREATE TABLE statement can contain the phrase NOT NULL following the definition of each column. This will ensure that the column contains a known data value. For example:
CREATE TABLE t1 (c1 INT NOT NULL);
Default Values
If a column is nullable and its value is not specified when a record is inserted, the value will be null. If it is a NOT NULL column, DB2 will return an error. It is also possible to specify a default value for a column, whether it is nullable or not. This is done as follows:
CREATE TABLE t1( c1 INT NOT NULL WITH DEFAULT 5, c2 INT WITH DEFAULT3 );
The DEFAULT value also can be specified directly in the VALUES clause of an INSERT statement as follows:
INSERT INTO t1 VALUES(DEFAULT, DEFAULT);
This will insert a row with the default value for both columns.
Identity Columns
In the majority of applications, a single column within a table represents a unique identifier for that row. Often this identifier is a number that gets sequentially updated as new records are added. In DB2, a feature exists that automatically generates this value on behalf of the user. For example, to automatically generate an employee_id as a sequence, the following definition is used:
CREATE TABLE employee( employee_id INT GENERATED ALWAYS AS IDENTITY(START WITH 100, INCREMENT BY 10) );
If GENERATED ALWAYS is specified, then an INSERT statement cannot specify a value for the field. If GENERATED BY DEFAULT is used, then an INSERT can specify the value. The starting and increment amount are optionally specified in the column definition. If they are not specified, then numbering begins at 1 and increments by 1.
Generated Columns
Other columns also can be generated using the GENERATED ALWAYS or BY DEFAULT clauses. For example:
CREATE TABLE employee( employee_id INT GENERATED ALWAYS AS IDENTITY, salary INT, bonus INT, pay GENERATED ALWAYS AS (salary + bonus) );
Table Constraints and Keys
Tables consist of columns and rows that store an unordered set of data records. Tables can have constraints to guarantee the uniqueness of data records, maintaining the relationship between and within tables, and so on. A constraint is a rule that the database manager enforces. There are three types of constraints:
Unique constraint— Ensures the unique values of a key in a table. Any changes to the columns that comprise the unique key are checked for uniqueness.
Referential integrity— Enforces referential constraints on insert, update, and delete operations. It is the state of a database in which all values of all foreign keys are valid.
Table check constraint— Verifies that changed data does not violate conditions specified when a table was created or altered.
Unique Constraints
A unique constraint is the rule that the values of a key are valid only if they are unique within the table. Each column making up the key in a unique constraint must be defined as NOT NULL. Unique constraints are defined in the CREATE TABLE statement or the ALTER TABLE statement using the PRIMARY KEY clause or the UNIQUE clause. A table can have any number of unique constraints; however, a table cannot have more than one unique constraint on the same set of columns.
When a unique constraint is defined, the database manager creates (if needed) a unique index and designates it as either a primary or unique system-required index. The enforcement of the constraint is through the unique index. After a unique constraint has been established on a column, the check for uniqueness during multiple row updates is deferred until the end of the update (deferred unique constraint). A unique constraint also can be used as the parent key in a referential constraint.
Referential Integrity
Referential integrity allows you to define required relationships between and within tables. The database manager maintains these relationships, which are expressed as referential constraints, and requires that all values of a given attribute or table column also exist in some other table column.
For example, you can create two tables, employee and department, as follows:
CREATE TABLE employee ( employee_id INTEGER NOT NULL, workdept INTEGER NOT NULL ); CREATE TABLE department(dept_id INTEGER NOT NULL);
To ensure that each employee belongs to a department that exists, you need to guarantee that the workdept in the employee table maps directly to a dept_id in the department table. To accomplish this, you use keys:
A unique key is a set of columns in which no two values are duplicated in any other row. Only one unique key can be defined as a primary key for each table. The unique key may also be known as the parent key when referenced by a foreign key.
A primary key is a special case of a unique key. Each table can only have one primary key.
A foreign key is a column or set of columns in a table that refer to a unique key or primary key of the same or another table. A foreign key is used to establish a relationship with a unique key or primary key and enforces referential integrity among tables.
The column workdept in the employee table should be defined as a foreign key to the dept_id column of the department table to ensure referential integrity. The parent table for the foreign key in this case is the department table, whereas the dependent table is the table containing one or more foreign keys, in this case the employee table. In addition, the dept_id of the department table and the employee_id of the employee table should be created as unique keys to uniquely identify each employee and each department.
To do this, you can specify the primary key either when you create each table or by using the ALTER TABLE statement as follows:
ALTER TABLE employee ADD PRIMARY KEY employee_id; ALTER TABLE department ADD PRIMARY KEY dept_id;
You can now assign the foreign key to the employee table:
ALTER TABLE employee ADD FOREIGN KEY(workdept) REFERENCES department(dept_id);
A referential constraint is an assertion that nonnull values of a designated foreign key are valid only if they also appear as values of a unique key of a designated parent table. The purpose of referential constraints is to guarantee that database relationships are maintained and data entry rules are followed.
Enforcement of referential constraints has special implications for some SQL operations that depend on whether the table is a parent or a dependent. The database manager enforces referential constraints across systems based on these referential integrity rules:
INSERT rule
DELETE rule
UPDATE rule
INSERT Rule
The INSERT rule is implicit when a foreign key is specified. You can insert a row at any time into a parent table without any action being taken in the dependent table. You cannot insert a row into a dependent table unless there is a row in the parent table with a parent key value equal to the foreign key value of the row that is being inserted (unless the foreign key value is null). If an INSERT operation fails for one row during an attempt to insert more than one row, all rows inserted by the statement are removed from the database.
DELETE Rule
When you delete a row from a parent table, the database manager determines whether there are any dependent rows in the dependent table with matching foreign key values. If any dependent rows are found, several actions can be taken. You determine which action will be taken by specifying a DELETE rule when you create the dependent table. There are four options that exist:
RESTRICT— This option prevents any row in the parent table from being deleted if any dependent rows are found. If you need to remove both parent and dependent rows, delete dependent rows first.
NO ACTION— This option enforces the presence of a parent row for every child after all the referential constraints are applied. This is the default. The difference between NO ACTION and RESTRICT is based on when the constraint is enforced. See the DB2 UDB v8.x SQL Reference for further details.
CASCADE— This option implies that deleting a row in the parent table automatically deletes any related rows in the dependent table.
SET NULL— This option ensures that deletion of a row in the parent table sets the values of the foreign key in any dependent row to null (if nullable). Other parts of the row are unchanged.
UPDATE Rule
The database manager prevents the update of a unique key of a parent row. When you update a foreign key in a dependent table and the foreign key is defined with the NOT NULL option, it must match some value of the parent key of the parent table. Two options exist:
RESTRICT— The update for the parent key will be rejected if a row in the dependent table matches the original values of the key.
NO ACTION— The update operation for the parent key will be rejected if any row in the dependent table does not have a corresponding parent key when the update statement is completed (excluding after triggers). This is the default.
Check Constraints
Table-check constraints enforce data integrity at the table level. After a table-check constraint has been defined for a table, every UPDATE and INSERT statement will involve checking the restriction or constraint. If the constraint is violated, the data record will not be inserted or updated, and an SQL error will be returned.
A table-check constraint can be defined at table creation time or later using the ALTER TABLE statement. The table-check constraints can help implement specific rules for the data values contained in the table by specifying the values allowed in one or more columns in every row of a table. This can save time for the application developer because the validation of each data value can be performed by the database and not by each of the applications accessing the database.
Adding Check Constraints
When you add a check constraint to a table that contains data, one of two things can happen:
All the rows meet the check constraint.
Some or all the rows do not meet the check constraint.
In the first case, when all the rows meet the check constraint, the check constraint is created successfully. Future attempts to insert or update data that does not meet the constraint business rule will be rejected.
When some rows do not meet the check constraint, the check constraint is not created (i.e., the ALTER TABLE statement fails). The ALTER TABLE statement, which adds a new constraint to the EMPLOYEE table, is shown following the next few paragraphs. The check constraint is named check_job. DB2 uses this name to inform you as to which constraint was violated if an INSERT or UPDATE statement fails. The CHECK clause is used to define a table-check constraint.
An ALTER TABLE statement was used because the table had already been defined. If values in the EMPLOYEE table conflict with the constraint being defined, the ALTER TABLE statement will not be completed successfully. It is possible to turn off constraint checking to let you add a new constraint. The SET INTEGRITY statement enables you to turn off check constraint and referential constraint checking for one or more tables.
When you turn off the constraint checking for a table, the table is put in a CHECK PENDING state, and only limited access to the table is allowed. For example, after a table is in a check-pending state, use of SELECT, INSERT, UPDATE, and DELETE is disallowed on a table. See the DB2UDB v8.1 SQL Reference for the complete syntax of the SET INTEGRITY statement.
ALTER TABLE employee ADD COLUMN job VARCHAR(30);
ALTER TABLE employee
ADD CONSTRAINT check_job
CHECK (job IN ('Engineer','Sales','Manager'));
Modifying Check Constraints
Because check constraints are used to implement business rules, you might need to change them from time to time. This could happen when the business rules change in your organization. No special command is used to change a check constraint. Whenever a check constraint needs to be changed, you must drop it and create a new one. Check constraints can be dropped at any time, and this action will not affect your table or the data within it. When you drop a check constraint, be aware that data validation performed by the constraint will no longer be in effect. The statement used to drop a constraint is the ALTER TABLE statement.
Modifying a Table
After creating a table, the ALTER TABLE statement enables you to modify existing tables. The ALTER TABLE statement modifies existing tables by:
Adding one or more columns to a table
Adding or dropping a primary key
Adding or dropping one or more unique or referential constraints
Adding or dropping one or more check constraint definitions
Altering the length of a VARCHAR column
Altering a reference type column to add a scope
Altering or dropping a partitioning key
Changing table attributes such as the DATA CAPTURE, PCTFREE, LOCKSIZE, or APPEND mode option
Activating the not logged initially attribute of the table
In this chapter, not all of these operations are discussed. Refer to the DB2 UDB v8.1 SQL Reference for each option of the ALTER TABLE statement.
Indexes
An index is a list of the locations of rows sorted by the contents of one or more specified columns. Indexes are typically used to improve query performance, however, they also can serve a logical design purpose. For example, a unique index does not allow the entry of duplicate values in columns. This guarantees that no rows of a table are the same. Indexes can be created to specify ascending or descending order by the values in a column. The indexes contain a pointer, known as a record id (RID) to the physical location of the rows in the table.
These are two of the many purposes for creating indexes:
To ensure uniqueness of values
To improve query performance
More than one index can be defined on a particular base table, which can have a beneficial effect on the performance of queries. However, the more indexes there are, the more the database manager must work to keep the indexes up-to-date during update, delete, and insert operations. Thus, creating a large number of indexes for a table that receives many updates can slow down processing.
Unique Index and Nonunique Index
A unique index guarantees the uniqueness of the data values in a table's columns. The unique index can be used during query processing to perform faster data retrieval. The uniqueness is enforced at the end of the SQL statement that updates rows or inserts new rows. The uniqueness is also checked during the execution CREATE INDEX statement. If the table already contains rows with duplicate key values, the index is not created.
A nonunique index also can improve query performance by maintaining a sorted order for the data.
For unique indexes, depending on how many columns are used to define a key, you can have one of the following types:
An atomic key is a single column key.
A composite key is composed of two or more columns.
The following are types of keys used to implement constraints:
A unique key is used to implement unique constraints. A unique constraint does not allow two different rows to have the same values on the key columns.
A primary key is used to implement entity integrity constraints. A primary key is a specially designated unique key. There can only be one primary key per table, and the primary key column must be defined with a NOT NULL option.
A foreign key is used to implement referential integrity constraints. Referential constraints can only reference a primary or unique constraint. The values within a foreign key can only have values contained in the primary key, unique constraint that they are referencing, or the NULL value. (A foreign key is not an index.)
Referential Integrity and Indexes
As discussed previously, defining a primary key will ensure uniqueness of a column value and that the primary key is maintained using an index. The index supporting a primary key is known as the primary index of the table. If a constraint name is not provided, DB2-generated indexes use the following naming convention: SYSIBM.SQL<timestamp>.
Indexes supporting primary or unique key constraints cannot be dropped explicitly. To remove primary or unique key constraints indexes, you need to use the ALTER TABLE statement. Primary key indexes are dropped with the DROP PRIMARY KEY option. Unique key indexes are dropped using the DROP UNIQUE (CONSTRAINT NAME) option.
Null Values and Indexes
It is important to understand the difference between a primary or unique key constraint and a unique index. DB2 uses two elements to implement the relational database concept of primary and unique keys: unique indexes and the NOT NULL constraint. Therefore, unique indexes do not enforce the primary key constraint by themselves because they can allow a null value. Null values are unknown, but when it comes to indexing, a null value is treated as equal to all other null values. However, you cannot insert a null value twice if the column is a key of a unique index because this violates the uniqueness rule for the index.
General Indexing Guidelines
Indexes consume disk space. The amount of disk space will vary depending on the length of the key columns. The size of the index will increase as more data is inserted into the base table. Therefore, consider the disk space required for indexes when planning the size of the database. Some of the indexing considerations include:
Primary and unique key constraints will always create a system-generated unique index.
It is usually beneficial to create indexes on foreign constraint columns.
NOTE
You can estimate the disk space consumed by an index with the Control Center using the Estimate Size button when you create an index.
Index Only Access (Unique Index Include)
The INCLUDE clause specifies additional columns to be appended to the set of index key columns. Any columns included with this clause are not used to enforce uniqueness. These included columns may improve the performance of some queries through index only access. This option may:
Eliminate the need to access data pages for more queries.
Eliminate redundant indexes.
Maintain the uniqueness of an index.
In the following example, if select empno, firstnme, job from empno is issued to the table on which this index resides, all of the required data can be retrieved from the index without reading data pages. It may improve performance.
CREATE UNIQUE INDEX EMP_IX ON EMPLOYEE(EMPNO) INCLUDE(FIRSTNME, JOB);
Bidirectional Index
The ALLOW REVERSE SCANS index creation clause enables both forward and reverse scans, that is, in the order defined at index creation time and in the opposite (or reverse) order. This option allows you to:
Facilitate MIN and MAX functions.
Fetch the previous key.
Eliminate the need for the optimizer to create a temporary table for the reverse scan.
Eliminate redundant reverse order index.
If the index is ordered in ascending order from left to right across its leaf pages, a bidirectional index contains leaf pointers pointing in both directions; that is, to left and right neighboring leaf pages. Therefore, a bidirectional index can be scanned or leaf-traversed from left to right (ascending) or right to left (descending). For example:
CREATE UNIQUE INDEX EMP_IX ON EMPLOYEE(EMPNO) INCLUDE(FIRSTNME, JOB) ALLOW REVERSE SCANS;
This allows a descending sort on the EMPNO to occur using the index without having to perform a sort operation.
Modifying an Index
Index attributes cannot be changed without recreating the index definition. For example, you cannot add a column to the list of key columns without dropping the previous definition and creating a new index. You can add a comment to describe the purpose of the index using the COMMENT ON statement.
If you want to modify your index, you have to drop it first and then create the index again. There is no ALTER INDEX statement.
Removing an Index
When you want to remove an index, issue the following statement:
DROP INDEX EMP_IX;
Note that packages having a dependency on an index or index specification are invalidated.
Views
Views are logical tables that are created using the CREATE VIEW statement. After a view is defined, it can be accessed using DML statements, such as SELECT, INSERT, UPDATE, and DELETE, as if it were a base table. A view is a temporary table and the data in the view is only available during query processing. A view definition is always created using a SELECT statement.
With a view, you can make a subset of table data available to an application program and validate data that is to be inserted or updated. A view can have column names that are different from the names of corresponding columns in the original tables. The use of views provides flexibility in the way the application programs and end-user queries look at the table data.
Following is a sample CREATE VIEW statement. The original table, EMPLOYEE, has columns named SALARY and COMM. For security reasons, this view is created from the ID, NAME, DEPT, JOB, and HIREDATE columns. In addition, we are restricting access on the column DEPT. This definition will only show the information of employees who belong to the department whose DEPTNO is 10.
CREATE VIEW EMP_VIEW1 (EMPID,EMPNAME,DEPTNO,JOBTITLE,HIREDATE) AS SELECT ID,NAME,DEPT,JOB,HIREDATE FROM EMPLOYEE WHERE DEPT=10;
After the view has been created, the access privileges can be specified. The last part of this chapter describes how to specify access privileges. This provides data security because a restricted view of the base table is accessible. As shown earlier, a view can contain a WHERE clause to restrict access to certain rows or can contain a subset of the columns to restrict access to certain columns of data.
The column names in the view do not have to match the column names of the base table. The table name has an associated schema as does the view name. After the view has been defined, it can be used in DML statements such as SELECT, INSERT, UPDATE, and DELETE (with restrictions). The database administrator can decide to provide a group of users with a higher level privilege on the view than the base table.
Views with Check Option
If the view definition includes conditions (such as a WHERE clause) and the intent is to ensure that any INSERT or UPDATE statement referencing the view will have the WHERE clause applied, the view must be defined using WITH CHECK OPTION. This option can ensure the integrity of the data being modified in the database. An SQL error will be returned if the condition is violated during an INSERT or UPDATE operation.
The following is an example of a view definition using the WITH CHECK OPTION. The WITH CHECK OPTION is required to ensure that the condition is always checked. You want to ensure that the DEPT is always 10. This will restrict the input values for the DEPT column. When a view is used to insert a new value, the WITH CHECK OPTION is always enforced.
CREATE VIEW EMP_VIEW2 (EMPNO,EMPNAME,DEPTNO,JOBTITLE,HIREDATE) AS SELECT ID,NAME,DEPT,JOB,HIREDATE FROM EMPLOYEE WHERE DEPT=10 WITH CHECK OPTION;
If this view is used in an INSERT statement, the row will be rejected if the DEPTNO column is not the value 10. It is important to remember that there is no data validation during modification if the WITH CHECK OPTION is not specified. If the view is used in a SELECT statement, the conditional (WHERE clause) would be invoked and the resulting table would only contain the matching rows of data. In other words, the WITH CHECK OPTION does not affect the result of a SELECT statement. The WITH CHECK OPTION must not be specified for the following views:
Views defined with the READ ONLY option (a read-only view)
Views that reference the NODENUMBER or PARTITION function, a nondeterministic function (e.g., RAND), or a function with external action
Typed views
Nested View Definitions
If a view is based on another view, the number of predicates that must be evaluated is based on the WITH CHECK OPTION specification. If a view is defined without WITH CHECK OPTION, the definition of the view is not used in the data validity checking of any insert or update operations. However, if the view directly or indirectly depends on another view defined with the WITH CHECK OPTION, the definition of that super view is used in the checking of any insert or update operation.
If a view is defined with the WITH CASCADED CHECK OPTION or just the WITH CHECK OPTION (CASCADED is the default value of the WITH CHECK OPTION), the definition of the view is used in the checking of any insert or update operations. In addition, the view inherits the search conditions from any updatable views on which the view depends.
These conditions are inherited even if those views do not include the WITH CHECK OPTION. Then, the inherited conditions are multiplied together to conform to a constraint that is applied for any insert or update operations for the view or any views depending on the view.
As an example, if a view V2 is based on a view V1, and the check option for V2 is defined with the WITH CASCADED CHECK OPTION, the predicates for both views are evaluated when INSERT and UPDATE statements are performed against the view V2. You also can specify the WITH LOCAL CHECK OPTION when creating a view. If a view is defined with the WITH LOCAL CHECK OPTION, the definition of the view is used in the checking of any insert or update operations. However, the view does not inherit the search conditions from any updatable views on which it depends.
Modifying a View
Views are temporary table definitions. Unlike some other DB2 objects, a view definition cannot be altered using the ALTER statement. If a view definition needs to be changed in any way, the original view must be dropped and recreated with the desired configuration. A view can become inoperative if any of the referenced database objects are dropped from the database.
Removing a View
When you want to remove a view named emp_view1, issue the statement:
DROP VIEW emp_view1;
Note that when the specified view is deleted, the definition of any view or trigger that is directly or indirectly dependent on that view is marked inoperative, and any packages dependent on a view that is dropped or marked inoperative will be invalidated.
View Classifications
Views can be classified by the operations they allow. Views can be deletable, updatable, insertable, and read only. Essentially, a view type is established according to its update capabilities, and the classification of the view indicates the kind of SQL operation that can be performed using the view.
Referential and check constraints are not taken into account when determining the classification of the view. The rules determining the classification of a view are numerous and are not listed here. For details on DB2 v7.1 on the classification of views, please refer to the CREATE VIEW statement description in the DB2 UDB v8.1 SQL Reference.
Schemas
Schemas are used to logically group database objects. Most database objects are named using a two-part naming convention that consists of schema_name.object_name. The first part of the name is a schema or qualifier, while the second part is the name of the object.
When you create an object and do not specify a schema name, the object will be created with an implicit schema name of your authorization ID. When an object is referenced in an SQL statement, it is also implicitly qualified with the authorization ID of the issuer (dynamic SQL) if no schema name is specified in the SQL statement.
The CURRENT SCHEMA special register contains the default qualifier to be used for unqualified objects referenced for dynamic SQL statements issued from within a specific DB2 connection. This value can be modified by the user with the SET CURRENT SCHEMA statement. Static SQL statements are qualified with the authorization ID of the person binding the application (by default). For example, if user steve connected to the database and created a table called steves_stuff, the complete name of the table as stored in the database would be steve.steves_stuff. You can use the QUALIFIER option of the BIND command to define the default qualifier at bind time.
If a schema is not specified in an SQL statement, then it is implied based on the authorization ID of the user. Thus, if the user was logged in as STEVE, his implicit schema would be STEVE. The implicit schema also can be set using the CURRENT SCHEMA register, which initially is the authorization ID of the user.
A schema can be created using the CREATE SCHEMA statement:
CREATE SCHEMA steve;
It can be dropped using the following syntax:
DROP SCHEMA steve RESTRICT;
The RESTRICT keyword is mandatory and specifies that the schema can only be dropped if there are no database objects within the schema.
Case-Sensitivity of Object Names
By convention, in our DDL statements we have specified all the names of column identifiers in lowercase. However, DB2 will always store names in uppercase unless the name of an identifier is surrounded by double quotes(""). For example, it is not possible to create a table with the following definition:
CREATE TABLE EMPLOYEE( employee_id CHAR(9), employee_id CHAR(9) );
Doing so will generate an error from DB2 (SQLCODE = SQL0601N) because a table cannot have two columns with duplicate names. However, the following statement will not yield any such error:
CREATE TABLE EMPLOYEE( employee_id CHAR(9), "employee_id" CHAR(9) );
This statement will create the EMPLOYEE table where the first column is named EMPLOYEE_ID and the second column is named employee_id. Note that case-sensitivity is thus important when defining column names and for all database objects. Thus, we can apply the same rule to tables and to other database objects that we will cover in the following sections:
CREATE TABLE "employee" like employee
Errors when Running SQL Statements
If an SQL statement fails, you receive an SQL error code as well as an SQLSTATE code. The SQLSTATE code is a standard code based on the ISO/ANSI SQL92 standard. It is unchanged across all the members of the DB2 Family, including RDBMSs on host systems. The SQL error codes may be unique to DB2 UDB for UNIX, Windows, and Linux.
The SQL codes can be in two formats: a negative code (or in the format SQLxxxxN) or positive code (or in the format SQLxxxxW). The negative codes signify SQL errors, and the positive codes signify SQL warnings (a zero SQL code means that the SQL completed successfully).
Sometimes the SQL codes contain reason codes within the error message text. These reason codes usually provide more detailed information to supplement the message text. Some examples of reason codes include operating system return codes and communications protocol return codes. The DB2 UDB v8.x Messages Reference provides some detail on common return codes. Sometimes, however, it might be necessary to consult other system documentation.