
Chapter 1
Image Processing
Vision is arguably the most important human sense. The processing and recording of visual data therefore has significant importance. The earliest images are from prehistoric drawings on cave walls or carved on stone monuments commonly associated with burial tombs. (It is not so much the medium that is important here – anything else would not have survived to today). Such images consist of a mixture of both pictorial and abstract representations. Improvements in technology enabled images to be recorded with more realism, such as paintings by the masters. Images recorded in this manner are indirect in the sense that the light intensity pattern is not used directly to produce the image. The development of chemical photography in the early 1800s enabled direct image recording. This trend has continued with electronic recording, first with analogue sensors, and subsequently with digital sensors, which include the analogue to digital (A/D) conversion on the sensor chip.
Imaging sensors have not been restricted to the portion of the electromagnetic spectrum visible to the human eye. Sensors have been developed to cover much of the electromagnetic spectrum from radio waves through to X-rays and gamma rays. Other imaging modalities have been developed, including ultrasound, and magnetic resonance imaging. In principle, any quantity that can be sensed can be used for imaging – even dust rays (Auer, 1982).
Since vision is such an important sense, the processing of images has become important too, to augment or enhance human vision. Images can be processed to enhance their subjective content, or to extract useful information. While it is possible to process the optical signals that produce the images directly by using lenses and optical filters, it is digital image processing – the processing of images by computer – that is the focus of this book.
One of the earliest applications of digital image processing was for transmitting digitised newspaper pictures across the Atlantic Ocean in the early 1920s (McFarlane, 1972). However, it was only with the advent of digital computers with sufficient memory and processing power that digital image processing became more widespread. The earliest recorded computer-based image processing was from 1957, when a scanner was added to a computer at the National Bureau of Standards in the USA (Kirsch, 1998). It was used for some of the early research on edge enhancement and pattern recognition. In the 1960s, the need for processing large numbers of large images obtained from satellites and space exploration stimulated image processing research at NASA's Jet Propulsion Laboratory (Castleman, 1979). In parallel with this, research in high energy particle physics led to a large number of cloud chamber photographs that had to be interpreted to detect interesting events (Duff, 2000). As computers grew in power and reduced in cost, there was an explosion in the range of applications for digital image processing, from industrial inspection, to medical imaging.
More formally, an image is a spatial representation of an object, scene or other phenomenon (Haralick and Shapiro, 1991). Examples of images include: a photograph, which is a pictorial record formed from the light intensity pattern on an optical sensor; a radiograph, which is a representation of density formed through exposure to X-rays transmitted through an object; a map, which is a spatial representation of physical or cultural features; a video, which is a sequence of two-dimensional images through time. More rigorously, an image is any continuous function of two or more variables defined on some bounded region of a plane.
Such a definition is not particularly useful in terms of computer manipulation. A digital image is an image in digital format, so that it is suitable for processing by computer. There are two important characteristics of digital images. The first is spatial quantisation. Computers are unable to easily represent arbitrary continuous functions, so the continuous function is sampled. The result is a series of discrete picture elements, or pixels, for two-dimensional images, or volume elements, voxels, for three-dimensional images. Sampling can result in an exact representation (in the sense that the underlying continuous function may be recovered exactly) given a band-limited image and a sufficiently high sample rate. The second characteristic of digital images is sample quantisation. This results in discrete values for each pixel, enabling an integer representation. Common bit widths per pixel are 1 (binary images), 8 (greyscale images), and 24 (3 × 8 bits for colour images). Unlike sampling, value quantisation will always result in an error between the representation and true value. In many circumstances, however, this quantisation error or quantisation noise may be made smaller than the uncertainty in the true value resulting from inevitable measurement noise.
In its basic form, a digital image is simply a two (or higher) dimensional array of numbers (usually integers) which represents an object, or scene. Once in this form, an image may be readily manipulated by a digital computer. It does not matter what the numbers represent, whether light intensity, reflectance, distance to a point (or range), temperature, population density, elevation, rainfall, or any other numerical quantity.
Image processing can therefore be defined as subjecting such an image to a series of mathematical operations in order to obtain a desired result. This may be an enhanced image; the detection of some critical feature or event; a measurement of an object or key feature within the image; a classification or grading of objects within the image into one of two or more categories; or a description of the scene.
Image processing techniques are used in a number of related fields. While the principle focus of the fields often differs, at the fundamental level many of the techniques remain the same. Some of the distinctive characteristics are briefly outlined here.
Digital image processing is the general term used for the processing of images by computer in some way or another.
Image enhancement involves improving the subjective quality of an image, or the detectability of objects within the image (Haralick and Shapiro, 1991). The information that is enhanced is usually apparent in the original image, but may not be clear. Examples of image enhancement include noise reduction, contrast enhancement, edge sharpening and colour correction.
Image restoration goes one step further than image enhancement. It uses knowledge of the causes of the degradation present in an image to create a model of the degradation process. This model is then used to derive an inverse process that is used to restore the image. In many cases, the information in the image has been degraded to the extent of being unrecognisable, for example severe blurring.
Image reconstruction involves restructuring the data that a available into a more useful form. Examples are image super-resolution (reconstructing a high resolution image from a series of low resolution images) and tomography (reconstructing a cross-section of an object from a series of projections).
Image analysis refers specifically to using computers to extract data from images. The result is usually some form of measurement. In the past, this was almost exclusively two-dimensional imaging, although with the advent of confocal microscopy and other advanced imaging techniques, this has extended to three dimensions.
Pattern recognition is concerned with the identification of objects based on patterns in the measurements (Haralick and Shapiro, 1991). There is a strong focus on statistical approaches, although syntactic and structural methods are also used.
Computer vision tends to use a model-based approach to image processing. Mathematical models of both the scene and the imaging process are used to derive a three-dimensional representation based on one or more two-dimensional images of a scene. The use of models implicitly provides an interpretation of the contents of the images obtained.
The fields are sometimes distinguished based on application:
Machine vision is using image processing as part of the control system for a machine (Schaffer, 1984). Images are captured and analysed, and the results are used directly for controlling the machine while performing a specific task. Real-time processing is often emphasised.
Remote sensing usually refers to the use of image analysis for obtaining geographical information, either using satellite images or aerial photography.
Medical imaging encompasses a wide range of imaging modalities (X-ray, ultrasound, magnetic resonance, etc.) concerned primarily with medical diagnosis and other medical applications. It involves both image reconstruction to create meaningful images from the raw data gathered from the sensors, and image analysis to extract useful information from the images.
Image and video coding focuses on the compression of an image or image sequence so that it occupies less storage space or takes less time to transmit from one location to another. Compression is possible because many images contain significant redundant information. In the reverse step, image decoding, the full image or video is reconstructed from the compressed data.
While there are many possible sensors that can be used for imaging, the focus in this section is on optical images, within the visible region of the electromagnetic spectrum. While the sensing technology may differ significantly for other types of imaging, many of the imaging principles will be similar.
The first requirement to obtaining an image is some form of sensor to detect and quantify the incoming light. In most applications, it is also necessary for the sensor to be directional, so that it responds primarily to light arriving at the sensor from a particular direction. Without this direction sensitivity, the sensor will effectively integrate the light arriving at the sensor from all directions. While such sensors do have their applications, the directionality of a sensor enables a spatial distribution to be captured more easily.
The classic approach to obtain directionality is through a pinhole as shown in Figure 1.1, where light coming through the pinhole at some angle maps to a position on the sensor. If the sensor is an array then a particular sensing element (a pixel) will collect light coming from a particular direction. The biggest limitation of a pinhole is that only limited light can pass through. This may be overcome using a lens, which focuses the light coming from a particular direction to a point on the sensor. A similar focussing effect may also be obtained by using an appropriately shaped concave mirror.
Figure 1.1 Different image formation mechanisms: pinhole, lens, collimator, scanning mirror.

Two other approaches for constraining the directionality are also shown in Figure 1.1. A collimator allows light from only one direction to pass through. Each channel through the collimator is effectively two pinholes, one at the entrance, and one at the exit. Only light aligned with both the entrance and the exit will pass through to the sensor. The collimator can be constructed mechanically, as illustrated in Figure 1.1, or through a combination of lenses. Mechanical collimation is particularly useful for imaging modalities such as X-rays, where diffraction through a lens is difficult or impossible. Another sensing arrangement is to have a single sensing element, rather than an array. To form a two-dimensional image, the single element must be mechanically scanned in the focal plane, or alternatively have light from a different direction reflected towards the sensor using a scanning mirror. This latter approach is commonly used with time-of-flight laser range scanners (Jarvis, 1983).
The sensor, or sensor array, converts the light intensity pattern into an electrical signal. The two most common solid state sensor technologies are charge coupled device (CCD) and complementary metal oxide semiconductor (CMOS) active pixel sensors (Fossum, 1993). The basic light sensing principle is the same: an incoming photon liberates an electron within the silicon semiconductor through the photoelectric effect. These photoelectrons are then accumulated during the exposure time before being converted into a voltage for reading out.
Within the CCD sensor (Figure 1.2) a bias voltage is applied to one of the three phases of gate, creating a potential well in the silicon substrate beneath the biased gates (MOS capacitors). These attract and store the photoelectrons until they are read out. By biasing the next phase and reducing the bias on the current phase, the charge is transferred to the next cell. This process is repeated, successively transferring the charge from each pixel to a readout amplifier where it is converted to a voltage signal. The nature of the readout process means that the pixels must be read out sequentially.
Figure 1.2 Sensor types. Left: the MOS capacitor sensor used by CCD cameras; right: a three-transistor active pixel sensor used by CMOS cameras.
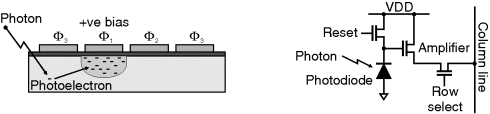
A CMOS sensor detects the light using a photodiode. However, rather than transferring the charge all the way to the output, each pixel has a built in amplifier that amplifies the signal locally. This means that the charge remains local to the sensing element, requiring a reset transistor to reset the accumulated charge at the start of each integration cycle. The amplified signal is connected to the output via a row select transistor and column lines. These make the pixels individually addressable, making it easier to read sections of the array, or even accessing the pixels randomly.
Although the active pixel sensor technology was developed before CCDs, the need for local transistors made early CMOS sensors impractical because the transistors consumed most of the area of the device (Fossum, 1993). Therefore, CCD sensors gained early dominance in the market. However, the continual reduction of feature sizes has meant that CMOS sensors became practical from the early 1990s. The early CMOS sensors had lower sensitivity and higher noise than a similar format CCD sensor, although with recent technological improvements there is now very little difference between the two families (Litwiller, 2005). Since they use the same process technology as standard CMOS devices, CMOS sensors also enable other functions, such as A/D conversion, to be directly integrated on the same chip.
Humans are able to see in colour. There are three different types of colour receptors (cones) in the human eye that respond differently to different wavelengths of light. If the wavelength dependence of a receptor is ![]() , and the light falling on the receptor contains a mix of light of different wavelengths,
, and the light falling on the receptor contains a mix of light of different wavelengths, ![]() , then the response of that receptor will be given by the combination of the responses of all different wavelengths:
, then the response of that receptor will be given by the combination of the responses of all different wavelengths:
What is perceived as colour is the particular combination of responses from the three different types of receptor. Many different wavelength distributions produce the same responses from the receptors, and therefore are perceived as the same colour. In practise, it is a little more complicated than this. The incoming light depends on the wavelength distribution of the source of the illumination, ![]() , and the wavelength dependent reflectivity,
, and the wavelength dependent reflectivity, ![]() , of the object being looked at. So Equation 1.1 becomes:
, of the object being looked at. So Equation 1.1 becomes:
(1.2) ![]()
To reproduce a colour, it is only necessary to reproduce the associated combination of receptor responses. This is accomplished in a television monitor by producing the corresponding mixture of red, green and blue light.
To capture a colour image for human viewing, it is necessary to have three different colour receptors in the sensor. Ideally, these should correspond to the spectral responses of the cones. However, since most of what is seen has broad spectral characteristics, a precise match is not critical except when the illumination source has a narrow spectral content (for example sodium vapour lamps or LED-based illumination sources). Silicon has a broad spectral response, with a peak in the near infrared. Therefore, to obtain a colour image, this response must be modified through appropriate colour filters.
Two approaches are commonly used to obtain a full colour image. The first is to separate the red, green and blue components of the image using a prism and with dichroic filters. These components are then captured using three separate sensor chips, one for each component. The need for three chips with precise alignment makes such cameras relatively expensive. An alternative approach is to use a single chip, with small filters integrated with each pixel. Since each pixel senses only one colour, the effective resolution of the sensor is decreased. A full colour image is created by interpolating between the pixels of a component. The most commonly used colour filter array is the Bayer pattern (Bayer, 1976), with filters to select the red, green and blue primary colours. Other patterns are also possible, for example filtering the yellow, magenta and cyan secondary colours (Parulski, 1985). Cameras using the secondary colours have better low light sensitivity because the filters absorb less of the incoming light. However, the processing required to produce the output gives a better signal-to-noise ratio from the primary filters than from secondary filters (Parulski, 1985; Baer et al., 1999).
One further possibility that has been considered is to stack the red, green and blue sensors one on top of the other (Lyon and Hubel, 2002; Gilblom et al., 2003). This relies on the fact that longer wavelengths of light penetrate further into the silicon before being absorbed. Thus, by using photodiodes at different depths, a full colour pixel may be obtained without explicit filtering.
Since most cameras produce video output signals, the most common format is the same as that of television signals. A two-dimensional representation of the timing is illustrated in Figure 1.3. The image is read out in raster format, with a horizontal blanking period at the end of each line. This was to turn off the cathode ray tube (CRT) electron beam while it retraced to the start of the next line. During the horizontal blanking, a horizontal synchronisation pulse controlled the timing. Similarly, after the last line is displayed there is a vertical blanking period to turn off the CRT beam while it is retraced vertically. Again, during the vertical blanking there is a vertical synchronisation pulse to control the vertical timing. While such timing is not strictly necessary for digital cameras, at the sensor level there can also be blanking periods at the end of each line and frame.
Figure 1.3 Regions within a scanned video image.

Television signals are interlaced. The scan lines for a frame are split into two fields, with the odd and even lines produced and displayed in alternate fields. This effectively reduces the bandwidth required by halving the frame rate without producing the associated annoying flicker. From an image processing perspective, if every field is processed separately, this doubles the frame rate, albeit with reduced vertical resolution. To process the whole frame, it is necessary to re-interlace the fields. This can produce artefacts; when objects are moving within the scene, their location will be different in each of the two fields. Cameras designed for imaging purposes (rather than consumer video) avoid this by producing a non-interlaced or progressive scan output.
Cameras producing an analogue video signal require a frame grabber to capture digital images. A frame grabber preprocesses the signal from the camera, amplifying it, separating the synchronisation signals, and if necessary decoding the composite colour signal into its components. The analogue video signal is digitised by an A/D converter (or three A/D converters for colour) and stored in memory for later processing.
Digital cameras do much of this processing internally, directly producing a digital output. A digital sensor chip will usually provide the video data and synchronisation signals in parallel. Cameras with a low level interface will often serialise these signals (for example the Camera@@@@@@@@ Link interface; AIA, 2004). Higher level interfaces will sometimes compress and will usually split the data into packets for transmission from the camera. The raw format is simply the digitised pixels; the colour filter array processing is not performed for single chip cameras. Another common format is RGB; for single chip sensors with a colour filter array, the pixels are interpolated to give a full colour value for each pixel. As the human eye has a higher spatial resolution to brightness than to colour, it is common to convert the image to YCbCr (Brown and Shepherd, 1995):
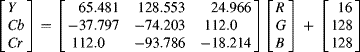
where the RGB components are normalised between 0 and 1, and the YCbCr components are 8-bit integer values. The luminance component, Y, is always provided at the full sample rate, with the colour difference signals, Cb and Cr provided at a reduced resolution. Several common subsampling formats are shown in Figure 1.4. These show the size or resolution of each Cb and Cr pixel in terms of the Y pixels. For example, in the 4:2:0 format, there is a single Cb and Cr value for each 2 × 2 block of Y values. To reproduce the colour signal, the lower resolution Cb and Cr values are combined with multiple luminance values. For image processing, it is usual to convert these back to RGB values using the inverse of Equation 1.3.
Figure 1.4 Common YCbCr subsampling formats.

1.3 Image Processing Operations
After capturing the image, the next step is to process the image to achieve the desired result.
The sequence of image processing operations used to process an image from one state to another is called an image processing algorithm. The term algorithm is sometimes a cause of confusion, since each operation is also implemented through an algorithm in some programming language. This distinction between application level algorithms and operation level algorithms is illustrated in Figure 1.5. Usually the context will indicate in which sense the term is used.
Figure 1.5 Algorithms at two levels: application level and operation level.
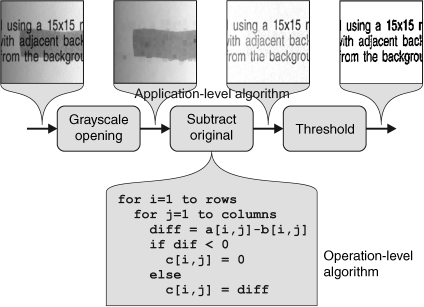
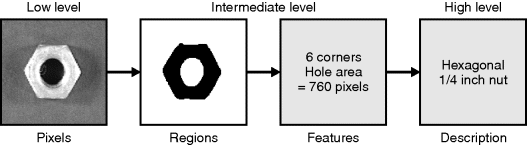
As the input image is processed by the application level algorithm, it undergoes a series of transformations. These are illustrated for a simple example in Figure 1.6. The input image consists of an array of pixels. Each pixel, on its own, carries very little information, but there are a large number of pixels. The individual pixel values represent high volume, but low value data. As the image is processed, collections of pixels are grouped together. At this intermediate level, the data may still be represented in terms of pixels, but the pixel values usually have more meaning; for example, they may represent a label associated with a region. At this intermediate level, the representation may depart from an explicit image representation, with the regions represented by their boundaries (for example as a chain code or a set of line segments) or their structure (for example as a quad tree). From each region, a set of features may be extracted that characterise the region. Generally, there are a small number of features (relative to the number of pixels within the region) and each feature contains significant information that can be used to distinguish it from other regions or other objects that may be encountered. At the intermediate level, the data becomes significantly lower in volume but higher in quality. Finally, at the high level, the feature data is used to classify the object or scene into one of several categories, or to derive a description of the object or scene.
Figure 1.6 Image transformations.
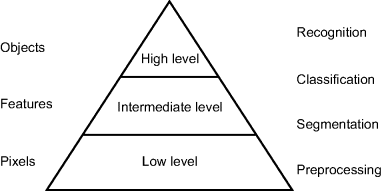
Rather than focussing on the data, it is also possible to focus on the image processing operations. The operations can be grouped according to the type of data that they process (Weems, 1991). This grouping is sometimes referred to as an image processing pyramid (Downton and Crookes, 1998; Ratha and Jain, 1999), as represented in Figure 1.7. At the lowest level of the pyramid are preprocessing operations. These are image-to-image transformations, with the purpose of enhancing the relevant information within the image, while suppressing any irrelevant information. Examples of preprocessing operations are distortion correction, contrast enhancement and filtering for noise reduction or edge detection. Segmentation operations such as thresholding, colour detection, region growing and connected components labelling occur at the boundary between the low and intermediate levels. The purpose of segmentation is to detect objects or regions in an image, which have some common property. Segmentation is therefore an image to region transformation. After segmentation comes classification. Features of each region are used to identify objects or parts of objects, or to classify an object into one of several predefined categories. Classification transforms the data from regions to features, and then to labels. The data is no longer image based, but position information may be contained within the features, or be associated with the labels. At the highest level is recognition, which derives a description or some other interpretation of the scene.
Figure 1.7 Image processing pyramid.
To illustrate the different stages of the processing, and how the different stages transform the image, the problem of detecting blemishes on the surface of kiwifruit will be considered (this example application is taken from Bailey, 1985). One of the problems frequently encountered with 100% grading is obtaining and training sufficient graders. This is made worse for the kiwifruit industry because the grading season is very short (typically only four to six weeks). Therefore, a pilot study was initiated to investigate the potential of using image processing techniques to grade kiwifruit.
There are two main types of kiwifruit defects. The first are shape defects, where the shape of the kiwifruit is distorted. With the exception of the Hayward protuberance, the fruit in this category are rejected purely for cosmetic reasons. They will not be considered further in this example. The second class of defects is that which involves surface blemishes or skin damage. With surface blemishes, there is a one square centimetre allowance, provided the blemish is not excessively dark. However, if the skin is cracked or broken or is infested with scale or mould, there is no size allowance and the fruit is reject. Since almost all of the surface defects appear as darker regions on the surface of the fruit, a single algorithm was used to detect both blemishes and damage.
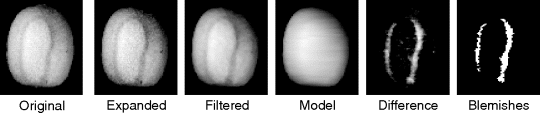
In the pilot study, only a single view of the fruit was considered; a practical application would have to inspect the complete surface of the fruit rather than just one view. Figure 1.8 shows the results of processing a typical kiwifruit with a water stain blemish. The image was captured with the fruit against a dark background to simplify segmentation, and diffuse lighting was used to reduce the visual texture caused by the hairs on the kiwifruit. Diffuse light from the direction of the camera also makes the centre of the fruit brighter than around the edges; this property is exploited in the algorithm.
Figure 1.8 Steps within the processing of kiwifruit images (Bailey, 1985).
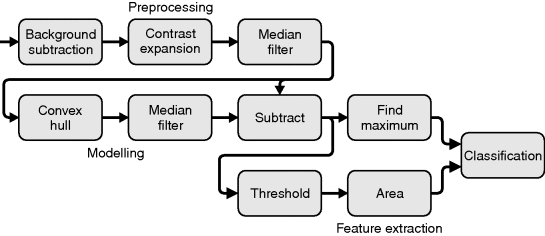
The dataflow for the image processing algorithm is represented in Figure 1.9. The first three operations preprocess the image to enhance the required information while suppressing the information that is irrelevant for the grading problem. In practise, it is not necessary to suppress all irrelevant information, but sufficient preprocessing is performed to ensure that subsequent operations perform reliably. Firstly, a constant is subtracted from the image to segment the fruit from the background; any pixel less than the constant is considered to be background and is set to zero. This simple segmentation is made possible by using a dark background. The next step is to normalise the intensity range to make the blemish measurements independent of fluctuations in illumination and the exact shade of a particular piece of fruit. This is accomplished by expanding the pixel values linearly to set the largest pixel value to 255. This effectively makes the blemish detection relative to the particular shade of the individual fruit. The third preprocessing step is to filter the image to remove the fine texture caused by the hairs on the surface of the fruit. A 3 × 3 median filter was used because it removes the local intensity variations without affecting the larger features that must be detected. It also makes the modelling stage more robust by significantly reducing the effects of noise on the model.
Figure 1.9 Image processing algorithm for detecting surface defects on kiwifruit (Bailey, 1985).
The next stage of the algorithm is to compare the preprocessed image with an ideal model of an unblemished fruit. The use of a standard fixed model is precluded by the normal variation in both the size and shape of kiwifruit. It would be relatively expensive to normalise the image of the fruit to conform to a standard model, or to transform a model to match the fruit. Instead, a dynamic model is created from the image of the fruit. This works on the principle of removing the defects, followed by subtraction to see what has been removed (Batchelor, 1979). Such a dynamic model has the advantage of always being perfectly aligned with the fruit being examined both in position and in shape and size. A simple model can be created efficiently by taking the convex hull of the non-zero pixels along each row within the image. It relies on the lighting arrangement that causes the pixel values to decrease towards the edges of the fruit because of the changing angle of the surface normal. Therefore, the expected profile of an unblemished kiwifruit is convex, apart from noise caused by the hairs on the fruit. The convex hull fills in the pixels associated with defects by setting their values based on the surrounding unblemished regions of the fruit. The accuracy of the model may be improved either by applying a median filter after the convex hull to smooth the minor discrepancies between the rows, or by applying a second pass of the convex hull to each column in the image (Bailey, 1985).
The preprocessed image is subtracted from the model to obtain the surface defects. (The contrast of this difference image has been expanded in Figure 1.8 to make the subtle variations clearer.) A pixel value in this defect image represents how much that pixel had to be filled to obtain the model, and is therefore a measure of how dark that pixel is compared with the surrounding area. Some minor variations can be seen resulting from noise remaining after the prefiltering. These minor variations are insignificant, and should be ignored. The defect image is thresholded to detect the significant changes resulting from any blemish.
Two features are extracted from the processed images. The first is the maximum value of the difference image. This is used to detect damage on the fruit, or to determine if a blemish is excessively dark. If the maximum difference is larger than a preset threshold, then the fruit is rejected. The second feature is the area of the blemish image after thresholding. For blemishes, an area less than one square centimetre is acceptable; larger than this, the fruit is rejected because the blemish is outside the allowance.
Three threshold levels must be determined within this algorithm. The first is the background level subtracted during preprocessing. This is set from looking at the maximum background level when processing several images. The remaining two thresholds relate directly to the classification. The point defect threshold determines how large the difference needs to be to reject the fruit. The second is the area defect threshold for detecting blemished pixels. These thresholds were determined by examining several fruit that spanned the range from acceptable, through marginal, to reject fruit. The thresholds were then set to minimise the classification errors (Bailey, 1985).
This example is typical of a real-time inspection application. It illustrates the different stages of the processing, and demonstrates how the image and information are transformed as the image is processed. This application has mainly low and intermediate level operations; the high level classification step is relatively trivial. As will be seen later, this makes such an algorithm a good candidate for hardware implementation on a FPGA (field programmable gate array).
1.5 Real-Time Image Processing
A real-time system is one in which the response to an event must occur within a specific time, otherwise the system is considered to have failed (Dougherty and Laplante, 1985). From an image processing perspective, a real-time imaging system is one that regularly captures images, analyses those images to obtain some data, and then uses that data to control some activity. All of the processing must occur within a predefined time (often, but not always, the image capture frame rate). Examples of real-time image processing systems abound. In machine vision systems, the image processing algorithm is used for either inspection or process control. Some robot vision systems use vision for path planning or to control the robot in some way where the timing is critical. Autonomous vehicle control requires vision or some other form of sensing for vehicle navigation or collision avoidance in a dynamic environment. In video transmission systems, successive frames must be transmitted and displayed in the right sequence and with minimum jitter to avoid a loss of quality of the resultant video.
Real-time systems are categorised into two types: hard and soft real time. A hard real-time system is one in which the complete system is considered to have failed if the output is not produced within the required time. An example is using vision for grading items on a conveyor belt. The grading decision must be made before the item reaches the actuation point, where the item is directed one way or another depending on the grading result. If the result is not available by this time, the system has failed. On the other hand, a soft real-time system is one in which the complete system does not fail if the deadline is not met, but the performance deteriorates. An example is video transmission via the internet. If the next frame is delayed or cannot be decoded in time, the quality of the resultant video deteriorates. Such a system is soft real time, because although the deadline was not met, an output could still be produced, and the complete system did not fail.
From a signal processing perspective, real time can mean that the processing of a sample must be completed before the next sample arrives (Kehtarnavaz and Gamadia, 2006). For video processing, this means that the total processing per pixel must be completed within a pixel sample time. Of course, not all of the processing for a single pixel can be completed before the next pixel arrives, because many image processing operations require data from many pixels for each output pixel. However, this provides a limit on the average processing rate, including any overhead associated with temporarily storing pixel values that will be used later (Kehtarnavaz and Gamadia, 2006).
A system that is not real time may have components that are real time. For instance, in interfacing to a camera, an imaging system must do something with each pixel as it is produced by the camera – either process it in some way, or store it into a frame buffer – before the next pixel arrives. If not, then the data for that pixel is lost. Whether this is a hard or soft real-time process depends on the context. While missing pixels would cause the quality of an image to deteriorate (implying soft real time), the loss of quality may have a significant negative impact on the performance of the imaging application (implying that image capture is a hard real-time task). Similarly, when providing pixels for display, if the required pixel data is not provided in time, that region of the display would appear blank. In the case of image capture and display, the deadlines are in the order of tens of nanoseconds, requiring such components to be implemented in hardware.
The requirement for the whole image processing algorithm to have a bounded execution time implies that each operation must also have a bounded execution time. This characteristic rules out certain classes of operation level algorithms from real-time processing. In particular, operations that are based on iterative or recursive algorithms can only be used if they can be guaranteed to converge satisfactorily within a predefined number of iterations, for the whole range of inputs that may be encountered.
One approach to guaranteeing a fixed response time is to make the imaging system synchronous. Such a system schedules each operation or step to execute at a particular time. This is suitable if the inputs occur at regular (or fixed) intervals, for example the successive frames from a video camera. However, synchronous systems cannot be used reliably when events occur randomly, especially when the minimum time between events is less than the processing time for each event.
The time between events may be significantly less than the required response time. A common example of this is a conveyor-based inspection system. The time between items on the conveyor may be significantly less than the time between the inspection point and the actuator. There are two ways of handling this situation. The first is to constrain all of the processing to take place during the time between successive items arriving at the inspection point, effectively providing a much tighter real-time constraint. If this new time constraint cannot be achieved then the alternative is to use distributed or parallel processing to maintain the original time constraint, but spread the execution over several processors. This can enable the time constraint to be met, by increasing the throughput to meet the desired event rate.
A common misconception of real-time systems, and real-time imaging systems in particular, is that they require high speed or high performance (Dougherty and Laplante, 1985). The required response time depends on the application and is primarily dependent on the underlying process to which the image processing is being applied. For example, a real-time coastal monitoring system looking at the movement of sand bars may require analysis times in the order of days or even weeks. Such an application would probably not require high speed! Whether or not real-time imaging requires high performance computing depends on the complexity of the algorithm. Conversely, an imaging application that requires high performance computing may not necessarily be real time (for example complex iterative reconstruction algorithms).
An embedded system is a computer system that is embedded within a product or component. Consequently, an embedded system is usually designed to perform one specific task, or a small range of specific tasks (Catsoulis, 2005), often with real-time constraints. An obvious example of an embedded image processing system is a digital camera. There the imaging functions include exposure and focus control, displaying a preview, and managing image compression and decompression.
Embedded vision is also useful for smart cameras, where the camera not only captures the image, but also processes it to extract information as required by the application. Examples of where this would be useful are “intelligent” surveillance systems, industrial inspection or control, robot vision, and so on.
A requirement of many embedded systems is that they need to be of small size, and light weight. Many run off batteries, and are therefore required to operate with low power. Even those that are not battery operated usually have limited power available.
Traditional image processing platforms are based on a serial computer architecture. In its basic form, such an architecture performs all of the computation serially by breaking the operation level algorithm down to a sequence of arithmetic or logic operations that are performed by the ALU (arithmetic logic unit). The rest of the CPU (central processing unit) is then designed to feed the ALU with the required data. The algorithm is compiled into a sequence of instructions, which are used to control the specific operation performed by the CPU and ALU during each clock cycle. The basic operation of the CPU is therefore to fetch an instruction from memory, decode the instruction to determine the operation to perform, and execute the instruction.
All of the advances in mainstream computer architecture have been developed to improve performance by squeezing more data through the narrow bottleneck between the memory and the ALU (the so-called von Neumann bottleneck; Backus 1978).
The obvious approach is to increase the clock speed, and hence the rate at which instructions are executed. Tremendous gains have been made in this area, with top clock speeds of several GHz being the norm for computing platforms. Such increases have come primarily as the result of reductions in propagation delay brought about through advances in semiconductor technology reducing both transistor feature sizes and the supply voltage. This is not without its problems, however, and one consequence of a higher clock speed is significantly increased power consumption by the CPU.
While the speeds of bulk memory have also increased, they have not kept pace with increasing CPU speeds. This has caused problems in reading both instructions and data from the system memory at the required rate. Caching techniques have been developed to buffer both instructions and data in a smaller high speed memory that can keep pace with the CPU. The problem then is how to maximise the likelihood that the required data will be in the cache memory rather than the slower main memory. Cache misses (where the data is not in cache memory) can result in a significant degradation in processor performance because the CPU is sitting idle waiting for the data to be retrieved.
Both instructions and data need to be accessed from the main memory. One obvious improvement is to use a Harvard architecture, which doubles the effective memory bandwidth by using separate memories for instructions and data. This can give a speed improvement by up to a factor of two. A similar improvement may be obtained with a single main memory, using separate caches for instructions and data.
Another approach is to increase the width of the ALU, so that more data is processed in each clock cycle. This gives obvious improvements for wider data word lengths (for example double precision floating-point numbers) because each number may be loaded and processed in a fewer clock cycles. However, when the natural word length is narrower, such is typically encountered in image processing, the performance improvement is not as great unless data memory bandwidth is the limiting factor. When the data path is wider than the word length, it is also possible to design the ALU to operate as a vector processor. Multiple data words are packed into a single processor word allowing the ALU to perform the same operation simultaneously on several data items (for example using the Intel MMX instructions; Peleg et al., 1997). This can be particularly effective for low level image processing operations where the same operation is performed on each pixel.
The speed of the fetch/decode/execute cycle may be improved by pipelining the separate phases. Thus, while one instruction is being executed, the next instruction is being decoded, and the instruction after that is being fetched. Depending on the complexity of the instructions, there may also be phases (and pipeline stages) for reading data from memory and writing the results to memory. Such pipelining is effective when executing long sequences of instructions without branches. However, instruction pipelining becomes more complex with loops or branches that break the regular sequence. This necessitates flushing the instruction pipeline to remove the successive instructions that have been incorrectly loaded and then loading the correct instructions. Techniques have been developed to attempt to minimise time lost through pipeline flushing. Branch prediction tries to anticipate which path will be taken at a branch, and increases the likelihood that the correct instructions will be loaded. Speculative execution, executes the instructions that have been loaded in the pipeline already, so that the time is not lost if the branch is predicted correctly. If the branch is incorrectly predicted, the results of the speculative execution are discarded.
Other instruction set architectures have been designed to increase the CPU throughput. RISC (reduced instruction set computer) architectures do this by simplifying the instructions, enabling a higher clock speed. VLIW (very large instruction word) architectures enable multiple independent instructions to execute in parallel, in an effort to maximise the utilisation of all parts of the CPU.
More recently, multiple core architectures have become mainstream. These enable multiple threads within an application to execute in parallel on separate processor cores (Geer, 2005). These can give some improvement for image processing applications, provided that the application has been developed carefully to support multiple threads. If care is not taken, the memory bandwidth in accessing the image can still be a bottleneck.
While impressive performance gains have been achieved, with serial processors, time is usually the critical resource. This is because serial processors can only do one thing at a time. VLIW and multicore processors are beginning to overcome this limitation, but, even so, they are still serially bound. Some problems do not fit well onto serial processors, for example, those for which the processing does not scale linearly with the number of inputs, or where the complexity of the problem is such that it remains intractable (or impractical) given current processor speeds.
Another recent development is the GPU (graphics processing unit), a processor customised primarily for graphics rendering, and initially driven by the high-end video game market. The primary function performed by a GPU is to take vertex data representing triangular patches within the scene and produce the corresponding output pixels, which are stored in a frame buffer. Native operations include texture mapping, pixel shading, z-buffering and blending, and anti-aliasing. Early GPUs had dedicated pipelines for each of these stages, which restricted their use for wider application. More recent devices are programmable, enabling them to be used for image processing (Cope et al., 2005) or other computationally intensive tasks (Manocha, 2005). The speed gain is achieved through a combination of data pipelining and lightweight multithreading (NVIDIA, 2006). Data pipelining reduces the need to write temporary results to memory only to read them in again to perform further processing. Instead, results are written to sets of local registers where they may be accessed in parallel. Multithreading splits the task into several small steps that can be implemented in parallel, which is easy to achieve for low level image processing operations where the independent processing of pixels maps well to the GPU architecture. Lightweight threads reduce the overhead of switching the context from one thread to the next. Therefore, when one thread stalls waiting for data, the context can be rapidly switched to another thread to keep the processing units fully used. GPUs can give significant improvements over CPUs for algorithms that are easily parallelised, especially where data access is not the bottleneck (Cope et al., 2005). However, power considerations rule them out for many embedded vision applications.
For low power, or embedded vision applications, the size and power requirements of a standard serial processor are impractical in many cases. Lowering the clock speed can reduce the power significantly, but on a serial processor will also limit the algorithms that can be implemented in real time. To retain the computing power while lowering the clock speed requires multiple parallel processors.
In principle, every step within any algorithm may be implemented on a separate processor, resulting in a fully parallel implementation. However, if the algorithm is predominantly sequential, with every step within the algorithm dependent on the data from the previous step, then little can be gained in terms of reducing the response time. To be practical for parallel implementation, an algorithm has to have a significant number of steps that may be implemented in parallel. This is referred to as Amdahl's law (Amdahl, 1967). Let s be the proportion of the algorithm that is constrained to run serially (the housekeeping and other sequential components) and p the proportion of the algorithm that may be implemented in parallel over N processors. The best possible speedup that can be obtained is then:
(1.4) ![]()
The equality will only be achieved if there is no additional overhead (for example communication or other housekeeping) introduced as a result of parallelisation. This speedup is always less than the number of parallel processors, and will be limited by the proportion of the algorithm that must be serially executed:
(1.5) ![]()
Therefore, to achieve any significant speedup, the proportion of the algorithm that can be implemented in parallel must also be significant. Fortunately, image processing is inherently parallel, especially at the low and intermediate levels of the processing pyramid. This parallelism shows in a number of ways.
Virtually all image processing algorithms consist of a sequence of image processing operations. This is a form of temporal parallelism. Such a structure suggests using a separate processor for each operation, as shown in Figure 1.10. This is a pipelined architecture. It works a little like a production line in that the data passes through each of the stages as it is processed. Each processor applies its operation and passes the result to the next stage. If each successive processor has to wait until the previous processor completes its processing, this arrangement will not reduce the total processing time, or the response time. However, the throughput can increase, because while the second processor is working on the output of operation 1, processor 1 can begin processing the next image. When processing images, data can usually begin to be output from an operation long before the complete image has been processed by that operation. The time between when data is first input to an operation and the corresponding output is available is the latency of that operation. The latency is lowest when each operation only uses input pixel values from a small, local neighbourhood because each output only requires data from a few input pixel values. Operations that require the whole image to calculate an output pixel value will have a higher latency. Operation pipelining can give significant performance improvements when all of the operations have low latency, because a downstream processor may begin performing its operation before the upstream processors have completed. This can give benefits, not only for multiprocessor systems, but also for software-based systems using a separate thread for each process (McLaughlin, 2000) because the user can begin to see the results before the whole image has been processed. Of course, in a software system using a single core, the total response time will not normally be decreased, although there may be some improvement resulting from switching to another thread while waiting for data from slower external memory when it is not available in the cache. In a hardware system, however, the total response time is given by the sum of the latencies of each of the stages plus the time to input in the whole image. If the individual latencies are small compared to the time required to load the image, then the speedup factor can be significant, approaching the number of processors in the pipeline.
Figure 1.10 Temporal parallelism exploited using a processor pipeline.

Two difficulties can be encountered with using pipelining for more complex image processing algorithms (Duff, 2000). The first is with multiple parallel paths. If, for example, Processor 4 in Figure 1.10 also takes as input the results output from processor 1 then the data must be properly synchronised to allow for the latencies of the other processors in the parallel path. For synchronous processing, this is simply a delay line, but synchronisation becomes considerably more complex when the latencies of the parallel operations are variable. A greater difficulty is handling feedback, either with explicitly iterative algorithms, or implicitly where the parameters of the earlier processors adapt to the results produced in later stages.
A lot of the parallelism within an operation level algorithm is in the form of loops. The outermost loop within each operation usually iterates over the pixels within the image, because many operations perform the same function independently on many pixels. This is spatial parallelism, which may be exploited by partitioning the image and using a separate processor to perform the operation on each partition. Common partitioning schemes split the image into blocks of rows, blocks of columns, or rectangular blocks, as illustrated in Figure 1.11. For video processing, the image sequence may also be partitioned in time, by assigning successive frames to separate processors (Downton and Crookes, 1998).
Figure 1.11 Spatial parallelism exploited by partitioning the image.

In the extreme case, a separate processor may be allocated to each pixel within the image (for example the MPP; Batcher, 1980). Dedicating a processor to each pixel can facilitate some very efficient algorithms. For example, image filtering may be performed in only a few clock cycles. However, one problem with such parallelism is the overhead required to distribute the image data to and from each of the processors. Many algorithms for massively parallel processors assume that the data is already available at the start.
The important consideration when partitioning the image is to minimise the communication between processors, which corresponds to minimising the communication between the different partitions. For low level image processing operations, the performance improvement approaches the number of processors. However, the performance will degrade as a result of any communication overheads or contention when accessing shared resources. Consequently, each processor must have some local memory to reduce any delays associated with contention for global memory. Partitioning is therefore most beneficial when the operations only require data from within a local region, where local is defined by the partition boundaries. If the operations performed within each region are identical, this leads to a SIMD (single instruction, multiple data) parallel processing architecture according to Flynn's taxonomy (Flynn, 1972).
With some intermediate level operations, the processing time for each partition may vary significantly depending on the content of the image within that region. A simple static, regular, partitioning strategy will be less efficient in this instance because the worst-case performance must be allowed for when allocating partitions to processors. As a result, many of the processors may be sitting idle for much of the time. In such cases, better performance may be achieved by having more partitions than processors, and using a processor farm approach (Downton and Crookes, 1998). Each partition is then allocated dynamically to the next available processor. Again, it is important to minimise the communications between processors.
For high level image processing operations, the data is no longer image based. However, data partitioning methods can still be exploited by assigning a separate data structure, region, or object to a separate processor. Such assignment generally requires the dynamic partitioning approach of a processor farm.
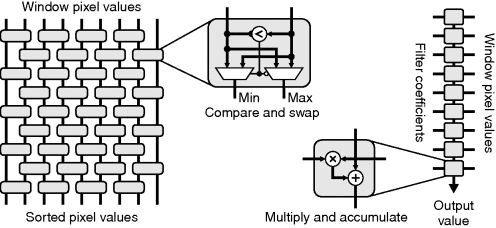
Logical parallelism reuses the same functional block many times within an operation. This often corresponds to inner loops within the algorithm implementing the operation. Logical parallelism is exploited by executing each instance of the function block in parallel, effectively unrolling the inner loops. Often the functions can be arranged in a regular structure, as illustrated in the examples in Figure 1.12. The odd–even transposition network within a bubble sort (for example to sort the pixel values within a rank window filter; Heygster, 1982; Hodgson et al., 1985) consists of a series of compare and swap function blocks. Implementing the blocks in parallel gives a considerable speed improvement over iterating with a single compare and swap block. A linear filter or convolution multiplies the pixel values within a window by a set of weights, or filter coefficients. The multiply and accumulate block is repeated many times, and is a classic example of logic parallelism.
Figure 1.12 Examples of logical parallelism. Left: compare and swap within a bubble sorting odd–even transposition network; right: multiply and accumulate within a linear filter.
Often the structure of the group of function blocks is quite regular, which, when combined with pipelining, results in a synchronous systolic architecture (Kung, 1985). When properly implemented, such architectures have a very low communication overhead, enabling significant speed improvements resulting from multiple copies of the function block.
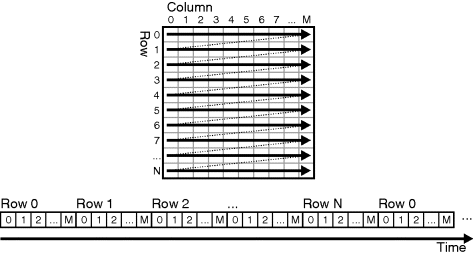
One of the common bottlenecks within image processing is the time, and bandwidth, required to read the image from memory and write the resultant image to memory. Stream processing exploits this to convert spatial parallelism into temporal parallelism. The image is read (and written) sequentially using a raster scan often at a rate of one pixel per clock cycle (Figure 1.13). It then performs all of its processing on the pixels on-the-fly as they are being read or written. The individual operations with the operation level algorithm are pipelined as necessary to maintain the required throughput. Data is cached locally to avoid the need for parallel external data accesses. This is most effective if each operation uses input from a small local neighbourhood, otherwise the caching requirements can be excessive. Stream processing also works best when the time taken to process each pixel is constant. If the processing time is data dependent, it may be necessary to insert FIFO (first-in, first-out) buffers on the input or output (or both) to maintain a constant data rate. With stream processing, the response time is given by the sum of the time required to read or write the image and the processing latency (the time between reading a pixel and producing its corresponding output). For most operations the latency is small compared with loading the whole image, so if the whole application level algorithm can be implemented using stream processing the response time is dominated by frame rate.
Figure 1.13 Stream processing converts spatial parallelism into temporal parallelism.
1.9 Hardware Image Processing Systems
In the previous section, it was not made explicit whether the processors that made up the parallel systems were a set of standard serial processors, or dedicated hardware implementing the parallel functions. In theory, it makes little difference, as long as the parallelism is implemented efficiently, and the communication overheads are kept low.
Early serial computer systems were too slow for processing images of any size or in any volume. The regular structure of images led to designs for hardware systems to exploit the parallelism because hardware systems are inherently parallel. Many of the earliest systems were based on having a relatively simple processing element (PE) at each pixel. Unger (Unger, 1958) proposed a system based on a 4-connected square grid for processing binary images. Although the hardware for each PE was relatively simple, he demonstrated that many useful low level image processing operations could be performed. Although this early system was not built (Duff, 2000), it inspired other similar architectures. Golay proposed a system based on a hexagonal grid (Landsman et al., 1965; Golay, 1969) with the image cycled through a single PE using stream processing. Such a system was ultimately built by Preston (Preston et al., 1979). The CLIP series of image processors used a parallel set of PEs. The CLIP2 (Duff et al., 1973) used a 16 × 12 hexagonal array, and although it was able to perform some basic processing it was not practical for real applications. The successor, CLIP4 (Duff, 2000) used a 96 × 96 array, and was able to operate on greyscale images in a bit serial manner. A similar 128 × 128 array (the massively parallel processor) was built by Batcher (Batcher, 1980); it also operated in a bit serial manner.
For capturing and display of video or images, even serial computers required a hardware system to interface with the camera or display. These frame grabbers interfaced with the host computer system either through direct memory access (DMA), or shared memory that was mapped within the address space of the host. A basic frame grabber consisted of an A/D converter, a bank of memory capable of holding at least one image frame, and a digital to analogue converter for image display. Many allowed basic point operations to be applied through lookup tables on the image being captured or displayed. This simple pipelining was extended to more sophisticated operations and completely pipelined image processing systems, the most notable of which was the Datacube. Pipelining is less suitable for high level image processing; hybrid systems were developed consisting of pipelined hardware for the preprocessing and an array of serial processors (often transputers) for high level processing, such as in the Kiwivision system (Clist and Valkenburg, 1994).
The early hardware systems were implemented with small and medium scale integrated circuits. The advent of VLSI (very large scale integration) lowered the cost of hardware and dramatically increased the speed and performance of the resulting systems. This led to a wider range of hardware architectures being used and image processing operations being implemented (Offen, 1985). It is interesting to note that, as technology has improved, the reducing feature sizes has meant that the cost of producing the masks has increased, significantly increasing the proportion of the one-off costs relative to the cost of individual devices. Consequently, the economics of VLSI production meant that only a limited range of circuits (those general enough to warrant large production runs) saw widespread commercial use.
Hardware-based image processing systems are very fast, but their biggest problem is their relative inflexibility. Once configured they perform their task very well, but it is difficult, if not impossible, to reconfigure these systems if the nature of the task changes. In the 1980s, the introduction of FPGA (field programmable gate array) technology opened new possibilities for digital logic design. FPGAs combine the inherent parallel nature of hardware with the flexibility of software in that their functionality can be reprogrammed or reconfigured. Early FPGAs were quite small in terms of the equivalent number of gates, so they tended to be used primarily for providing flexible interconnect and interface logic (sometimes called glue logic), and for implementing finite state machine-based controllers. Multiple FPGAs were required to implement any significant image processing system. As FPGAs grew in power, hybrid systems were developed where FPGAs were used as vision coprocessors or accelerators within a host computer (for example the Splash-2 system; Athanas and Abbot, 1995). Modern FPGAs now have sufficient resources to enable whole applications to be implemented on a single FPGA, making them an ideal choice for embedded real-time vision systems.