
Chapter 14
Example Applications
In the earlier chapters, much of the focus in describing FPGA implementation was on individual image processing operations, rather than complete applications. This final chapter shows how the individual operations tie together within an application. Of particular interest are some of the optimisations used to reduce hardware or processing time.
In this application, it was desired to create a gesture-based user input. Rather than operate in a completely unstructured environment, it was decided to use coloured paddles to provide the input gestures (Johnston et al., 2005b). One of the goals was to minimise resource use to enable the remainder of the FPGA to be used for the application being controlled (Johnston et al., 2005a).
The basic structure of the algorithm is shown in Figure 14.1. The basic steps within the application were to use the distinctive colours of the paddles to segment them from the background. A simple bounding box was then used to determine the paddle locations. The remainder of this section details the algorithm and the optimisations made to reduce the size of the implementation.
Figure 14.1 Steps within a colour tracking algorithm.
This application was implemented on an RC100 board from Celoxica Ltd. The board uses a Xilinx XC2S200 Spartan II FPGA and has a number of peripheral devices on the board, including a video codec chip. The codec digitised the composite video signal from the camera and provided a stream of 16-bit colour (RGB565) pixels to the FPGA. The codec provided a 27 MHz pixel clock, with one pixel every two clock cycles.
Two counters were implemented to keep track of the input, one to count the pixels on the row, ![]() , and the other to count the row number,
, and the other to count the row number, ![]() . Both were reset at the end of the respective blanking intervals. The control signals for driving the rest of the application were derived from these counters.
. Both were reset at the end of the respective blanking intervals. The control signals for driving the rest of the application were derived from these counters.
The first stage is to identify the colour of the pixels in the incoming pixel stream. As described in Section 6.3.3, the RGB colour space is not the most suitable for colour segmentation. The RGB pixel values were therefore converted to a form of YCbCr to separate the luminance from the chrominance. Since the output is not intended for human viewing, the exact YCbCr matrix conversion is not necessary. Instead, the simplified YUV colour space of Equation 6.61 was used:
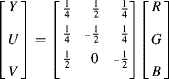
which can implement the conversion with four additions, as shown in Figure 6.35. The fact that ![]() has one more bit that
has one more bit that ![]() and
and ![]() does not matter as all three values are treated at binary fractions. The resultant YUV components each have seven bits. However, since the transformation is linear, scaling the intensity will scale all three RGB components and, consequently, also the YUV components. Therefore, dividing
does not matter as all three values are treated at binary fractions. The resultant YUV components each have seven bits. However, since the transformation is linear, scaling the intensity will scale all three RGB components and, consequently, also the YUV components. Therefore, dividing ![]() and
and ![]() by
by ![]() would provide true intensity normalisation:
would provide true intensity normalisation:
Unfortunately, with the definition in Equation 14.1, ![]() can exceed
can exceed ![]() for some colours, and
for some colours, and ![]() goes outside the range −1 to 1. Therefore, an alternative definition was used for the luminance:
goes outside the range −1 to 1. Therefore, an alternative definition was used for the luminance:
(14.3) ![]()
This normalises ![]() and
and ![]() to the range
to the range ![]() to
to ![]() . While such intensity scaling removes the intensity dependence, it also has a side effect of reducing colour specificity. After normalisation, all colours with a similar hue are mapped to the same range. Normalisation therefore introduces a trade-off between insensitivity to intensity and colour selectivity.
. While such intensity scaling removes the intensity dependence, it also has a side effect of reducing colour specificity. After normalisation, all colours with a similar hue are mapped to the same range. Normalisation therefore introduces a trade-off between insensitivity to intensity and colour selectivity.
The next step in the process is colour segmentation. This detects pixels within a box within ![]() colour space. Rather than build a set of comparators for each colour detected, a variation on the lookup table approach of Figure 6.42 is used. The divisions of Equation 14.2 are relatively expensive (although with the two-phase input clock, a single divider could be shared between the two channels, as shown in Figure 5.22). The divisions are avoided by using the lookup table to perform the division. This is accomplished by concatenating the
colour space. Rather than build a set of comparators for each colour detected, a variation on the lookup table approach of Figure 6.42 is used. The divisions of Equation 14.2 are relatively expensive (although with the two-phase input clock, a single divider could be shared between the two channels, as shown in Figure 5.22). The divisions are avoided by using the lookup table to perform the division. This is accomplished by concatenating the ![]() with the
with the ![]() and
and ![]() , respectively, as shown on the left in Figure 14.2, and setting the table contents based on Equation 14.2. Of course, during tuning when the colour thresholds are set, the division is required to initialise the LUTs.
, respectively, as shown on the left in Figure 14.2, and setting the table contents based on Equation 14.2. Of course, during tuning when the colour thresholds are set, the division is required to initialise the LUTs.
Figure 14.2 Colour segmentation and labelling. Left: basic idea of joint lookup tables; right: gaining an extra bit of precision for

To minimise the resource use, it was decided to fit both lookup tables in a single dual-port block RAM (Johnston et al., 2005a). On the target FPGA, each block RAM is 4 Kbits in size. To detect four colours in parallel, the memory needs to be four bits wide. Therefore, the 4 Kbit RAM allows 512 entries for each table, or nine address bits to be divided between the ![]() and
and ![]() components. Since colour resolution is more important than precise intensity normalisation, six bits were used for each of
components. Since colour resolution is more important than precise intensity normalisation, six bits were used for each of ![]() and
and ![]() and three bits were allocated to
and three bits were allocated to ![]() . While this gives only an approximate result, the three bits are sufficient to give some degree of intensity normalisation.
. While this gives only an approximate result, the three bits are sufficient to give some degree of intensity normalisation.
As the paddles are always lighter coloured, the minimum threshold for ![]() is always above the 50% level. This allows four bits to be used from
is always above the 50% level. This allows four bits to be used from ![]() , with the three least significant bits passed to the lookup table and the most significant by used directly to control the AND gate. This optimisation is shown on the right in Figure 14.2.
, with the three least significant bits passed to the lookup table and the most significant by used directly to control the AND gate. This optimisation is shown on the right in Figure 14.2.
Each coloured object was recognised by finding the bounding box of the corresponding label. However, since the bounding box is sensitive to noise, a 3 × 3 erosion filter was used to remove isolated noise pixels. These commonly occur on the boundaries between colours, or around specular highlights where the pixel values saturate. The 3 × 3 filter is separable, decomposing into a 3 × 1 horizontal filter followed by a 1 × 3 vertical filter. The row buffers are indexed directly by the pixel counter, ![]() , rather than needing an additional counter. Although erosion shrinks the size of each region, it is not necessary to dilate the image again – it does not affect the centre of the bounding box, and if necessary this can be taken into account when interpreting the bounding box dimensions.
, rather than needing an additional counter. Although erosion shrinks the size of each region, it is not necessary to dilate the image again – it does not affect the centre of the bounding box, and if necessary this can be taken into account when interpreting the bounding box dimensions.
The bounding box implementation of Figure 11.3 is used to determine the bounding box of all the labels in parallel. Fabric RAM is used to avoid the explicit need for a multiplexer. With a two-phase clock, only a single-port RAM is required, reducing the resource requirements. Each LUT gives a 16-bit deep RAM. With four bits used to represent the label, one bit for each colour, it is unnecessary to explicitly convert this to binary. The raw four-bit label is used to directly address the RAM. As described in Section 11.1, each bounding box is augmented with a counter to determine the orientation of long thin objects.
The timing for the coloured region tracking pipeline is shown in Figure 14.3. Signals from the codec are valid on the rising edge of the 27 MHz codec produced clock. The CREF signal produced by the codec is high when pixel data is available (every second cycle). The ![]() register is also incremented in this phase, so that it remains constant between phase 1 when the row buffer and bounding box are read and when they are written in phase 2.
register is also incremented in this phase, so that it remains constant between phase 1 when the row buffer and bounding box are read and when they are written in phase 2.
Figure 14.3 Pixel timing for coloured region tracking.
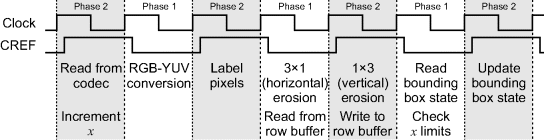
The pipeline timing shows the pixel processing. Additional processing is performed at the end of each line and frame. After each row, the pixel counter is reset and the row counter incremented. A state variable used for determining the orientation is also reset. At the end of each field, the data for each bounding box is transmitted to the main clock domain over a channel (all of the image processing is performed directly in the codec's clock domain). After transmission, the bounding box data is reset for the next field.
The tracking algorithm locates up to four programmed colours in each field at either 50 or 60 fields per second (depending on whether a PAL or NTSC camera is connected). All of the processing is performed on-the-fly as the data is streamed in. The only pixel buffering is two block RAMs used as row buffers for the vertical erosion filter. The complete tracking system used less than 10% of the logic resources of the FPGA (and 3/14 of the block RAMs), leaving the remainder of the system to be used for the application.
14.2 Lens Distortion Correction
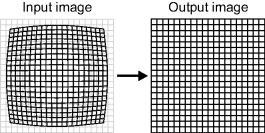
Many low cost lenses used in a lot of image processing applications suffer from lens distortion. Such distortion results from the magnification of the lens not being uniform across the field of view; this is particularly prevalent with wide angle lenses. In many imaging applications, inexpensive wide angle lenses are used because of space and cost constraints. An example of the form of distortion is shown in Figure 14.4 (it has been exaggerated here for effect). This next application looks at characterising and correcting the lens distortion in images being displayed.
Figure 14.4 Lens distortion correction.
Lens distortion is usually modelled using a radially dependent magnification:
where
(14.5) ![]()
is the radius about the centre of the distortion in the input image,
is the radius of the corresponding point in the output image and ![]() is the magnification of the forward mapping. The magnification function is often modelled as a generic radial Taylor series:
is the magnification of the forward mapping. The magnification function is often modelled as a generic radial Taylor series:
(14.7) ![]()
There are two points of note. Firstly, the centre of distortion (the origin in these equations) is not necessarily in the centre of the image (Willson and Shafer, 1994). Two parameters are therefore required to represent the distortion centre, ![]() . Secondly, for many lenses, a simple first order model is sufficient to account for much of the distortion (Li and Lavest, 1996) even when the distortion is quite severe. With the truncated series, the subscript will be dropped from the
. Secondly, for many lenses, a simple first order model is sufficient to account for much of the distortion (Li and Lavest, 1996) even when the distortion is quite severe. With the truncated series, the subscript will be dropped from the ![]() parameter.
parameter.
Equation 14.4 represents the forward mapping. From this equation, the inverse (the reverse mapping) may be obtained as another radially dependent magnification:
Lens distortion correction can be broken into two phases: the first is calibration, which determines the distortion parameters (![]() ,
, ![]() , and
, and ![]() ), and the second is to use the distortion model and calibration parameters to correct the distortion within an image.
), and the second is to use the distortion model and calibration parameters to correct the distortion within an image.
14.2.1 Characterising the Distortion
Since the calibration process is not time critical, it is best performed using a software-based system. However, out of interest, an FPGA implementation is presented here. Calibration can use a separate configuration file to distortion correction since both processes do not need to operate concurrently.
While there are a number of methods that can be used to calibrate lens distortion, a variation of the ‘plumb line’ originally proposed by (Brown, 1971) is used here. It is based on the premise that without lens distortion straight lines should be straight under projection. Any deviation from straightness is, therefore, an indication of distortion (Fryer et al., 1994; Devernay and Faugeras, 2001). Many algorithms for determining the distortion parameters are iterative. Here a direct, non-iterative method will be used.
The basic principle (Bailey, 2002) is to capture an image of a rectangular grid and fit a parabola to each of the gridlines. The quadratic term of the parabola indicates the degree of curvature. Lines through the centre of distortion will be straight, allowing the centre to be estimated from where the sign of the quadratic term changes. The distortion parameter is then derived to make the curved lines straight.
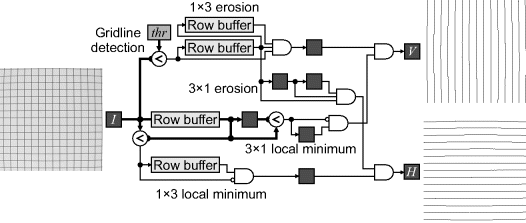
Assuming that the gridlines are approximately one pixel wide, the algorithm for detecting both sets of gridlines is outlined in Figure 14.5. While thresholding can detect the gridlines, the resulting lines are often thicker than a single pixel. Two sets of filters in parallel are used to solve this problem. The gridlines are separated by using two small one-dimensional erosion filters: a vertical 1 × 3 erosion will remove the horizontal gridlines and a horizontal 3 × 1 erosion will remove the vertical gridlines. A second pair of filters (one horizontal and one vertical) operates on the original image to detect the local minimum pixel positions. This is masked with the detected gridlines to select the best pixel. With both sets of filters, the horizontal filters follow the first row buffer to offset them by one line, giving correct temporal alignment of the outputs. Similarly, the output of the vertical filters is delayed by one clock cycle for alignment.
Figure 14.5 Algorithm for grid detection.
In the output, there may still be the occasional double pixel, or the occasional missing pixel where the gridlines cross. To correct for this, a small 3 × 3 cleaning filter is used. For horizontal lines, to bridge narrow gaps if there is a pixel detected in the left and right of the window, but not in the centre column, a linking pixel is added. To reduce the thickness of double wide lines, if two pixels are adjacent vertically then one is removed. A similar filter is used for cleaning vertical lines. The filters are given in Figure 14.6.
Figure 14.6 Filters for filling in small gaps and thinning double wide lines. Left: for horizontal gridlines; right: for vertical gridlines.

A version of connected components analysis is then used to label each gridline and extract the data required to determine the parabola coefficients. The single pass algorithm given in Section 11.4.4 can be simplified, because the number of labels is relatively small and unchaining is not necessary.
Firstly consider the horizontal gridlines. The parabola fitted to each gridline is:
Using a least squares fit to determine the coefficients requires solving:
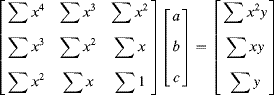
This poses a number of problems from an implementation perspective. Consider a 1024 × 1024 image with 1024 pixels across each row. The sum of ![]() requires 48 bits to represent. Defining the origin in the centre of the image improves this, reducing the representation to 44 bits. A second problem is the wide range in scales between the terms. Both problems may be solved by scaling
requires 48 bits to represent. Defining the origin in the centre of the image improves this, reducing the representation to 44 bits. A second problem is the wide range in scales between the terms. Both problems may be solved by scaling ![]() and
and ![]() by a power of two, so that the absolute value at the edges of the image is between one and two. In this case, scaling by 28 allows a 20-bit representation for all numbers (12 integer bits and eight fraction bits).
by a power of two, so that the absolute value at the edges of the image is between one and two. In this case, scaling by 28 allows a 20-bit representation for all numbers (12 integer bits and eight fraction bits).
If each horizontal line has a pixel in every column, then the matrix on the left of Equation 14.10 is actually a constant and does not need to be accumulated. The inverse can also be calculated off-line and hardwired into the implementation, enabling the coefficients to be calculated as a weighted combination of the terms on the right hand side. Incremental update can be used calculate ![]() ,
, ![]() , and
, and ![]() without multiplications.
without multiplications.
The centre of distortion is determined from where the quadratic term of the set of parabolas goes to zero. Therefore, the horizontal gridlines can be used to calculate ![]() and the vertical gridlines to calculate
and the vertical gridlines to calculate ![]() . Solving for where the curvature is zero from the horizontal gridlines gives:
. Solving for where the curvature is zero from the horizontal gridlines gives:
(14.11) ![]()
and similarly for the vertical gridlines. After determining the centre, each of the parabola coefficients needs to be adjusted to the new origin:
(14.12) ![]()
Substituting into Equation 14.9 for the horizontal gridlines adjusts the parabola coefficients for the new origin:
(14.13) ![]()
Each gridline can then be used to estimate the distortion parameter (Bailey, 2002):
(14.14) ![]()
Since each gridline (both horizontal and vertical) provides a separate estimate of the distortion parameter, the estimates can be combined by averaging. A weighted average should be used because the division by ![]() in the denominator makes the estimate less accurate near the centre of the image. Therefore:
in the denominator makes the estimate less accurate near the centre of the image. Therefore:
(14.15) ![]()
If necessary, additional steps can be taken to also calibrate the perspective distortion associated with the camera not being perpendicular to the grid (Bailey, 2002; Bailey and Sen Gupta, 2010).
Apart from the initial image processing and connected components labelling, much of the computation in this application is probably best performed in software, since it is largely sequential in nature. This could either be through an embedded processor or through a custom processor with an instruction set designed specifically for the types of computation used.
14.2.2 Correcting the Distortion
A number of papers have been written on the correction of radial distortion using FPGAs. Three different approaches have been taken to this problem. The first (Oh and Kim, 2008) transforms the incoming distorted image on-the-fly, resulting in a corrected image being stored in a frame buffer on the output. The second (Eadie et al., 2002; Gribbon et al., 2003) transforms the output image on-the-fly, taking the input from the frame buffer. The third approach transforms the image from one buffer to another. This allows the technique to exploit symmetry to reuse computation (Ngo and Asari, 2005) or divide the image into tiles to reuse pixel values for interpolation without running into memory bandwidth problems (Bellas et al., 2009).
A range of different distortion models have also been used, from a two-dimensional polynomial warp (Eadie et al., 2002), to a high order radial distortion model (Ngo and Asari, 2005; Oh and Kim, 2008), to the simple first order model described in the previous section (Gribbon et al., 2003) to a dedicated model of fish-eye distortion (Bellas et al., 2009). Most implementations used bilinear interpolation, although Bellas et al. (2009) used the more demanding bicubic interpolation.
The approach taken here is to correct a distorted image on-the-fly as it is being displayed from a frame buffer. This requires the reverse mapping to determine where each output pixel is to come from in the input image. Substituting Equations 14.4 and 14.7 into Equation 14.8 gives:
(14.16) 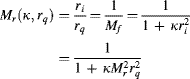
therefore
The reverse magnification function depends on the product ![]() rather than each of the terms separately. Therefore, a single magnification function can be implemented and used for different values of
rather than each of the terms separately. Therefore, a single magnification function can be implemented and used for different values of ![]() . Secondly, it is not necessary to take the square root to calculate
. Secondly, it is not necessary to take the square root to calculate ![]() as in Equation 14.6; this simplifies the computational requirements of determining the mapping.
as in Equation 14.6; this simplifies the computational requirements of determining the mapping.
Incremental calculation can be used to calculate ![]() . From Equation 14.6:
. From Equation 14.6:
(14.18) ![]()
Moving from one pixel to the next:
(14.19) ![]()
just requires a single addition (since the 1 can be placed in the least significant bit when ![]() is shifted). A similar calculation can be used when moving from one line to the next during the horizontal blanking interval.
is shifted). A similar calculation can be used when moving from one line to the next during the horizontal blanking interval.
Solving Equation 14.17 for the reverse magnification function gives:
(14.20) ![]()
where
(14.21) 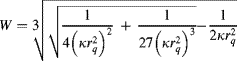
Clearly this is clearly impractical to calculate on-the-fly. This function is plotted in Figure 14.7. Since it is quite smooth, it may be implemented efficiently using either an interpolated lookup table or multipartite tables (Section 2).
Figure 14.7 Reverse magnification function.
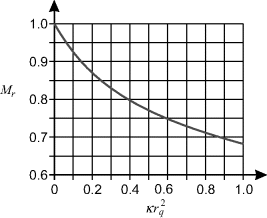
The accuracy of the representation depends on the desired accuracy in the corrected image. For a 1024 × 1024 image, the maximum radius is approximately 725 pixels in the corner of the image. Therefore, to achieve better than one pixel accuracy at the corners of the image, the magnification needs to have at least 10 bits accuracy. To maintain good accuracy, it is desired to represent the magnitude with at least 15 bits accuracy. For ![]() in the range of 0 to 1, direct lookup table implementation would require 215 entries. An interpolated lookup table only requires 28 entries, but needs a multiplication to perform the interpolation.
in the range of 0 to 1, direct lookup table implementation would require 215 entries. An interpolated lookup table only requires 28 entries, but needs a multiplication to perform the interpolation.
The next step is to use the magnification function to scale the radius. One approach for achieving this (Ngo and Asari, 2005) is to use a CORDIC engine to convert the output Cartesian coordinates to polar coordinates, scale the radius by the magnification function and then use a second CORDIC engine to convert polar coordinates back to Cartesian coordinates in the input image. However, such transformations are unnecessary because the angle does not change. From similar triangles, scaling the radius can be achieved simply by scaling the ![]() and
and ![]() components directly:
components directly:
(14.22) ![]()
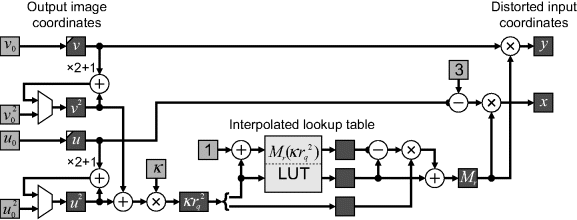
The resulting pipeline is shown in Figure 14.8. At the start of the frame, the ![]() and
and ![]() registers are initialised based on the location of the origin. Similarly,
registers are initialised based on the location of the origin. Similarly, ![]() and
and ![]() are initialised at the start of each line, with
are initialised at the start of each line, with ![]() and
and ![]() updated for the next line. The interpolated lookup table was implemented using a single 256 × 16 dual-port block RAM as described in Section 2. The −3 in the
updated for the next line. The interpolated lookup table was implemented using a single 256 × 16 dual-port block RAM as described in Section 2. The −3 in the ![]() line is to account for the pipeline latency;
line is to account for the pipeline latency; ![]() is incremented three times while determining the magnification factor. An alternative to the subtraction is to add three pipeline registers to the
is incremented three times while determining the magnification factor. An alternative to the subtraction is to add three pipeline registers to the ![]() line before multiplying by the magnification factor.
line before multiplying by the magnification factor.
Figure 14.8 Pipeline for correcting lens distortion.
The last stage is to use the calculated position in the input image to derive the corresponding output pixel value. For this, bilinear interpolation was used (Gribbon and Bailey, 2004). Any of the techniques described in Section 1 could be used. Caching is simplified by the fact that the magnification factor is less than one. This means that of the four pixel values required for bilinear interpolation, at least two (and usually three) will be in common with the previous position or previous row. Therefore, with appropriate caching, only one or two new pixel values will need to be loaded to calculate each output pixel value. This can be achieved using caching with preload, using the circuit in Figure 14.9. The operation is as follows.
Figure 14.9 Bilinear interpolation for lens distortion correction.
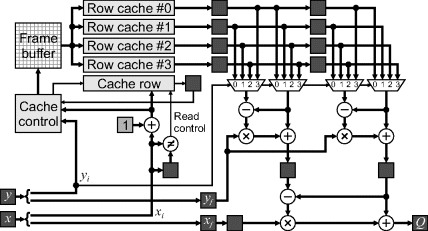
The row caches store data based on the two least significant bits of the corresponding row address (![]() ). The cache row records the two LSBs of the row that was most recently loaded for each column, to enable the preload to load the next free row. As each data is extracted from the cache, the cache control determines which new location to fetch from memory based on the current location, and next row to load.
). The cache row records the two LSBs of the row that was most recently loaded for each column, to enable the preload to load the next free row. As each data is extracted from the cache, the cache control determines which new location to fetch from memory based on the current location, and next row to load.
Having multiple parallel cache rows enables all the required pixels for the interpolation window to be accessed in parallel in a similar manner to window filters. Firstly, the incoming pixel coordinates are split into their integer and fractional components. To access the pixels from the cache, ![]() is compared with the previous value and, if different, the values from column
is compared with the previous value and, if different, the values from column ![]() are read from all four cache rows. Values from the previous column are shifted along, giving a 2 × 4 window into the input image. The two least significant bits of
are read from all four cache rows. Values from the previous column are shifted along, giving a 2 × 4 window into the input image. The two least significant bits of ![]() are used to select the required rows for the 2 × 2 window. These values are then weighted according to the fractional parts to produce the output pixel value. The pipeline from the input coordinates to the output pixel value has three stages.
are used to select the required rows for the 2 × 2 window. These values are then weighted according to the fractional parts to produce the output pixel value. The pipeline from the input coordinates to the output pixel value has three stages.
To prime the row caches will require the first row to be loaded three times. This may be accomplished during the vertical blanking period before the first row is output. Similarly, it is necessary to prime each row by loading the first pixel twice. The extra control logic required to achieve the priming is not shown here.
This application has shown how an image with lens distortion may be corrected on-the-fly as it is being displayed. To correct the image on-the-fly as it is being loaded from the camera will require quite a different transformation. A related example, that of introducing a predefined distortion into an image being captured is shown in the next section.
Low cost high resolution sensors (up to 10 megapixels and larger) are now becoming commonplace. This presents both a bonus and a problem for image processing. The increased resolution means that more accurate and higher quality results can be produced. However, there is also a significantly increased computational cost to achieve these results, especially when real-time constraints have to be met. Therefore, there is often a trade-off between quality of results and processing requirements.
Single high resolution images may be readily processed in real time on an FPGA if stream processing can be used. However, any algorithm that requires multiple frames will require significant off-chip memory and large associated memory bandwidth. Simply reducing the data volume by reducing the resolution can result in a critical loss of information. In many applications (for example tracking and pattern recognition), high resolution is only required in a small region of the image, although a wide field of view is important to maintain context. One solution to this dilemma is to use a foveated window. Inspired by the human visual system, this maintains high resolution in the fovea, with resolution decreasing in the periphery. It has been shown that such a variable spatial resolution can reduce the volume of data in tracking applications by a factor of 22 (Martinez and Altamirano, 2006) to 64 (Bailey and Bouganis, 2009b) without a severely affecting the tracking performance. Several researchers have investigated foveal mappings using FPGAs.
Traditionally, a log-polar mapping has been used for foveal vision in software to mimic the change of resolution within the human visual system (Wilson and Hodgson, 1992; Traver and Pla, 2003). The log-polar map is both rotation and scale invariant once the fovea is positioned on a common key point. Arribas and Macia (1999) implemented a log-polar mapping using an FPGA that was able to achieve real-time performance. They represented the mapping as a full lookup table from each input pixel to the corresponding output pixel. The image was mapped from a frame buffer rather than directly as it was streamed from the camera.
The complexities of processing a log-polar image have led many researchers to work with Cartesian approximations. Camacho et al. (1998) used a pyramidal-based fovea with each successive level decreasing the resolution by a factor of two towards the periphery, giving a form of stepped log-Cartesian topology. Ovod et al. (2005) implemented multiple fovea, allowing multiple objects to be tracked simultaneously, although their system only allowed two levels of resolution: fovea and periphery. Martinez and Altamirano (2006) used high resolution rectangular sampling within the fovea and approximated a log-polar mapping in the periphery by mapping multiple square rings to a rectangular output image using simple subsampling. Bailey and Bouganis (2008) introduced a family of Cartesian foveal mappings with continuously variable resolution. To minimise latency, the foveal image was mapped on-the-fly as the pixels were streamed from the camera.
An important part of foveal vision systems is the use of active vision techniques (mechanical or electronic-based systems) to ensure that the high resolution part of the sensor corresponds to the region of the scene where it can be most effective. Active vision requires minimising the latency between image capture and repositioning the fovea, because delays may degrade the performance of the application and limit the stability of this control loop. The lower resolution of the foveal images can significantly increase their processing rate, enabling real-time camera control.
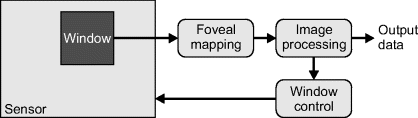
A CMOS sensor with a wide angle lens enables a wide field of view without a loss of resolution compared to that of a standard camera. CMOS sensors also allow an arbitrary rectangular window of the sensor to be selectively read out; this window may be positioned anywhere within the active area of the camera. Repositioning the window from one frame to the next provides the digital equivalent of pan and tilt, without the physical latency and motion blur associated with physically moving the camera. An active foveal vision system based on this mechanism (Bailey and Bouganis, 2008; 2009a; 2009c) is illustrated in Figure 14.10. The pixels within the window undergo a foveal mapping to give a reduced resolution image. This image is then processed to extract the required data and to determine the best position to relocate the window to within the CMOS sensor for the next frame.
Figure 14.10 Active vision architecture using a foveal mapping.
14.3.1 Foveal Mapping
A separable foveal mapping (Bailey and Bouganis, 2009a) will be used because it is easier to implement and it has been demonstrated through simulations (Bailey and Bouganis, 2009b) that its performance in tracking applications is similar to more complex radial mappings. The mapping here will map a 512 × 512 window to a 64 × 64 foveal image. An example of the foveal mapping for:
(14.23) 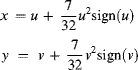
is illustrated in Figure 14.11. Note that due to the symmetry of the mapping, signed coordinates are used, with the origin in the centre of the images.
Figure 14.11 Example foveal mapping. Left: original 512 × 512 image; centre: after the foveal map to 64 × 64; right: reconstructed to the original size, showing the reduction in resolution in the periphery. (Reproduced with permission from D.G. Bailey and C.S. Bouganis, “Reconfigurable foveated active vision system,” International Conference on Sensing Technology, 162–169, 2008. © 2008 IEEE.)

In the previous section, a reverse mapping was used to correct for lens distortion. Here it is desirable to use a forward mapping for several reasons. Firstly, it saves the need for a frame buffer to hold the much larger input image. Secondly, the forward mapping enables the image to be transformed on-the-fly as it is streamed from the camera, significantly reducing the latency. Thirdly, the reduction in resolution in the periphery requires a spatially variant anti-aliasing filter. This can easily be incorporated into the forward mapping as described in Section 1.
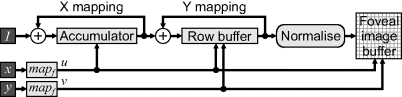
The basic architecture of the forward mapping is shown in Figure 14.12. In the first stage, the incoming pixels are mapped into their correct column and accumulated until the output pixel is completed horizontally. It is then passed to the Y mapping, which adds it to the appropriate column accumulator (stored in the row buffer). Once each row is completed vertically, the completed output pixels are normalised (the accumulated total is divided by the area) and saved to the foveal image buffer.
Figure 14.12 Architecture of the separable foveal mapping. (Reproduced with permission from D.G. Bailey and C.S. Bouganis, “Implementation of a foveal vision mapping,” International Conference on Field Programmable Technology, 22–29, 2009. © 2009 IEEE.)
Since each output pixel is contributed to by many input pixels, it is necessary for each pixel accumulator, ![]() , to consist of two component registers: one to accumulate the pixel value,
, to consist of two component registers: one to accumulate the pixel value, ![]() , and one to accumulate the area (or number of pixels),
, and one to accumulate the area (or number of pixels), ![]() . It can therefore be considered as a vector:
. It can therefore be considered as a vector:
(14.24) ![]()
For a continuously variable resolution function, some input pixels will need to be split between adjacent output pixels. Although Figure 14.12 indicates a forward mapping, it is actually more convenient to implement this by using a reverse mapping function. The index of the current output pixel being accumulated is looked up in a table to obtain the position of its edge in the input image (this is a reverse mapping). The input pixels can then be accumulated until this edge is reached, with the last fraction of a pixel added before the accumulated pixel is passed to the next stage. An advantage of using the reverse mapping function is that the output image has fewer pixels, so the table is significantly smaller. It also manages the splitting of the input pixel more naturally (Bailey and Bouganis, 2009a). The circuit for implementing the foveal mapping is shown in Figure 14.13.
Figure 14.13 Detailed foveal mapping circuit. (Adapted from Bailey and Bouganis, 2009a.)
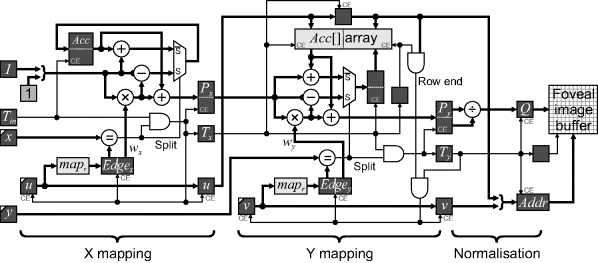
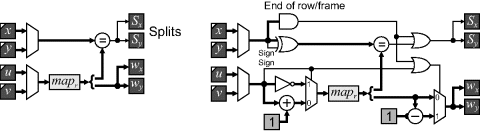
Consider firstly the X mapping. If an incoming pixel is not split, it is simply added to the accumulator. A split pixel is detected if the input pixel position matches the integer part of the edge of the output pixel. In that case the fractional part of the edge, ![]() , is used to weight the incoming pixel, which is combined with the accumulator and passed to the output register
, is used to weight the incoming pixel, which is combined with the accumulator and passed to the output register ![]() . The remainder of the pixel is used to update the accumulator:
. The remainder of the pixel is used to update the accumulator:
(14.25) 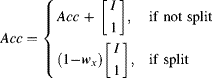
and
(14.26) ![]()
Since ![]() is typically only a few bits, it can be implemented efficiently in the FPGA fabric using adders rather than dedicated multipliers. The incoming pixel area is always one, so a multiplier for that is not required.
is typically only a few bits, it can be implemented efficiently in the FPGA fabric using adders rather than dedicated multipliers. The incoming pixel area is always one, so a multiplier for that is not required.
A token passing mechanism is used to indicate that valid data is available. Therefore, since a pixel is completed whenever a split occurs, ![]() is asserted and the current value of
is asserted and the current value of ![]() is registered with it.
is registered with it.
The Y mapping is very similar to the X mapping logic. The difference is that the pixels are accumulated in columns, although the data is still streamed horizontally. Therefore all columns are mapped in parallel, with the accumulators maintained in a memory-based array. The incoming ![]() selects the accumulator to add the new data to, with the accumulated data written back to the array in the following clock cycle:
selects the accumulator to add the new data to, with the accumulated data written back to the array in the following clock cycle:
(14.27) ![]()
and
(14.28) ![]()
with corresponding output valid token, ![]() . Since the mapping is separable, on a split row, all of the pixels will be split. The
. Since the mapping is separable, on a split row, all of the pixels will be split. The ![]() counter is only incremented at the end of split rows, with an AND gate over the bits of the u address used to detect the end of row.
counter is only incremented at the end of split rows, with an AND gate over the bits of the u address used to detect the end of row.
The final processing stage is to normalise the accumulated pixel value by the area to obtain the average input value within region spanned by each output pixel:
(14.29) ![]()
The division may be implemented efficiently using eight iterations (for eight 8 bits output) of a non-restoring division algorithm (Bailey, 2006). If necessary, the division can be pipelined to achieve the desired clock frequency.
If desired, the circuit can be optimised further (Bailey and Bouganis, 2009a). Since the Y mapping only uses the map lookup table at the end of each row, a single table can readily be shared between the X and Y mapping sections, as demonstrated on the left in Figure 14.14. The mapping is also symmetrical, therefore only one half needs to be stored in the table. This requires additional logic to mirror the input and foveal coordinates. The fraction also needs to be subtracted from one for the first half of the table to reflect this mirroring. With mirroring, the end of the row is no longer detected by the mapping, so this must be detected explicitly. The mirroring logic is shown on the right in Figure 14.14.
Figure 14.14 Sharing the mapping between the X and Y mapping sections. Left: simple sharing; right: reducing the map LUT size by mirroring.
These optimisations reduce the memory required by the lookup table by a factor of four. An additional benefit is that it the foveal mapping itself is changed dynamically, it only needs to be changed in one place.
14.3.2 Using the Sensor
The primary applications of a foveal sensor are in pattern recognition and tracking. In this section, the use of the sensor for object tracking is described briefly. When tracking an object, it is desired to centre the fovea on the target as it moves through the scene. The following stages are required within any tracking system (Bailey and Bouganis, 2009b):
1. The high resolution fovea is positioned on the expected position of the target within the image. Precise positioning is not essential because the lower resolution periphery enables a small image to be used while still maintaining a wide field of view.
2. The target is detected within the foveal image. Any standard object detection technique, such as filtering, thresholding, or colour detection can be used. Processing is relatively quick because of the small image size.
3. The true location of the target is estimated, based on the fact that the image is distorted. Note that standard correlation and registration-based techniques will give a biased result because of the distortion introduced in the mapping. However, for a given mapping, this bias may be estimated and compensated for. If using the centre of gravity, it is necessary to take into account the size and position of each pixel and weight accordingly (Bailey and Bouganis, 2009b).
4. The detected target is fed into a tracking system (for example a Kalman filter; Lee and Salcic, 1997; Liu et al., 2007) and the next location of the target is predicted. This is then used to reposition the window for the next image captured.
Using a foveal sensor has a number of advantages over a conventional sensor in this application. It allows a lower resolution image to be processed, which allows more complex processing with reduced latency. For tracking, the latency requirements make it important that the input image is converted to a foveal image on-the-fly. Multiple targets can be tracked by alternating the fovea between the targets with successive images captured (this reduces the effective frame rate for each target).
Standard imaging techniques only obtain two-dimensional data of a scene. To capture a three-dimensional image, it is also necessary to estimate the range of each pixel. Two commonly used techniques for obtaining the range are stereo imaging, which captures two images of the scene from slightly different viewpoints and uses the disparity between the views to estimate the range, and time of flight imaging, which transmits a light signal and measures the round trip propagation time of the light from the source to each point in the scene and back to the sensor. Time of flight sensing is considered in this example.
The distance to each point on an object is:
where ![]() is the round trip propagation time and
is the round trip propagation time and ![]() is the speed of light. Since it is difficult to measure the time of flight for a large number of pixels simultaneously, it is more usual to modulate the amplitude of the light source with a sinusoid and measure the phase shift of the envelope of the returned light (for example using synchronous detection). The distance from Equation 14.30 then becomes:
is the speed of light. Since it is difficult to measure the time of flight for a large number of pixels simultaneously, it is more usual to modulate the amplitude of the light source with a sinusoid and measure the phase shift of the envelope of the returned light (for example using synchronous detection). The distance from Equation 14.30 then becomes:
where ![]() is the modulation frequency,
is the modulation frequency, ![]() is the measured phase shift and
is the measured phase shift and ![]() is an integer number of complete cycles (to account for the phase ambiguity). Since
is an integer number of complete cycles (to account for the phase ambiguity). Since ![]() is unknown, it is usually assumed to be zero, with a maximum unambiguous range of:
is unknown, it is usually assumed to be zero, with a maximum unambiguous range of:
(14.32) ![]()
Two image capture modalities are commonly used. Heterodyne imaging (Jongenelen et al., 2008) uses slightly different modulation frequencies at the transmitter and sensor. The result is a beat frequency as the phase changes slowly with time. Capturing a sequence of images spaced exactly over one cycle of the beat waveform enables the phase at each pixel to be determined using a single bin Fourier transform. The alternative, homodyne imaging (Jongenelen et al., 2010), uses identical frequencies for the transmitter and sensor. The phase of the transmitter is offset from that of the receiver successively by a fixed amount each frame, again enabling a single bin Fourier transform to be used to measure the phase delay. In both cases, the frequency synthesis features of the FPGA can be used to provide phase locked clocks for both the light source and the sensor.
Given a sequence of images, ![]() , taking the temporal Fourier transform at each pixel:
, taking the temporal Fourier transform at each pixel:
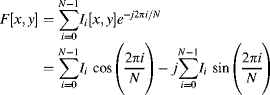
gives the phase shift:
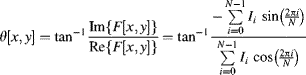
and amplitude:
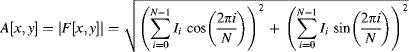
The phase shift is proportional to the range, and the amplitude provides a standard intensity image.
A direct implementation of this is given on the left in Figure 14.15. The sine and cosine values can be obtained from a small table (only ![]() entries are needed) or, since they are constant for each whole frame, may be loaded into registers at the start of each successive frame. Obviously, if
entries are needed) or, since they are constant for each whole frame, may be loaded into registers at the start of each successive frame. Obviously, if ![]() everything is simplified since the sine and cosine terms are −1, 0 or 1 and no multiplication is needed. However, the general case is considered here.
everything is simplified since the sine and cosine terms are −1, 0 or 1 and no multiplication is needed. However, the general case is considered here.
Figure 14.15 Calculating the phase shift at each pixel. Left: direct implementation of Equation 14.34; right: recursive implementation using CORDIC.

As each frame is streamed from the sensor, it is scaled by the sine and cosine terms and added into a complex accumulator image. For small images, the accumulator image may be held on-chip in block RAM. However, for larger images, it will need to be off-chip in a frame buffer. On the ![]() th frame, the imaginary component is divided by the real component and the arctangent taken. This can be through a suitable lookup table, which can also include the scale factor required to directly give the range. Additional logic is also required to obtain the amplitude from Equation 14.35. Alternatively, the division, arctangent and amplitude calculation may be performed by a single CORDIC unit.
th frame, the imaginary component is divided by the real component and the arctangent taken. This can be through a suitable lookup table, which can also include the scale factor required to directly give the range. Additional logic is also required to obtain the amplitude from Equation 14.35. Alternatively, the division, arctangent and amplitude calculation may be performed by a single CORDIC unit.
The processing may be simplified by rearranging Equation 14.33 into recursive form. Firstly define:
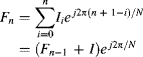
then
(14.37) ![]()
The recursive multiplication by ![]() corresponds to a rotation and may be implemented either using a complex multiplication (Figure 10.8) or by using a compensated CORDIC rotator operating in rotation mode (Section 5.4.3). Either way, since the multiplication is by a constant, it can be optimised to reduce the required logic. To calculate both the angle and magnitude, a second CORDIC rotator may be used, this time operating in vectoring mode. This does not need to use compensated CORDIC because scaling the amplitude will scale all pixels equally. The scale factor to convert the angle to a range can also be built into the CORDIC angle tables to avoid the need for an additional multiplication.
corresponds to a rotation and may be implemented either using a complex multiplication (Figure 10.8) or by using a compensated CORDIC rotator operating in rotation mode (Section 5.4.3). Either way, since the multiplication is by a constant, it can be optimised to reduce the required logic. To calculate both the angle and magnitude, a second CORDIC rotator may be used, this time operating in vectoring mode. This does not need to use compensated CORDIC because scaling the amplitude will scale all pixels equally. The scale factor to convert the angle to a range can also be built into the CORDIC angle tables to avoid the need for an additional multiplication.
If using a running Fourier transform to obtain an update every frame, the accumulation of Equation 14.33 should be used with ![]() as input. The recursive form of Equation 14.36 is only marginally stable (Duda, 2010) and any rounding or truncation errors may make it unstable with errors accumulating and growing exponentially.
as input. The recursive form of Equation 14.36 is only marginally stable (Duda, 2010) and any rounding or truncation errors may make it unstable with errors accumulating and growing exponentially.
14.4.1 Extending the Unambiguous Range
The unambiguous range is limited by assuming ![]() in Equation 14.31. While simply reducing the modulation frequency will extend the range, this comes at the cost of reduced accuracy. However, by making two measurements with different modulation frequencies, the unambiguous range can be extended (Jongenelen et al., 2010; 2011). Let
in Equation 14.31. While simply reducing the modulation frequency will extend the range, this comes at the cost of reduced accuracy. However, by making two measurements with different modulation frequencies, the unambiguous range can be extended (Jongenelen et al., 2010; 2011). Let ![]() be the phase represented as a binary fraction:
be the phase represented as a binary fraction:
(14.38) ![]()
then with two measurements, Equation 14.31 is extended to:
where ![]() and
and ![]() represent the number of times the phase terms
represent the number of times the phase terms ![]() and
and ![]() have wrapped respectively. Let the ratio between the two frequencies be expressed as a ratio of co-prime integers:
have wrapped respectively. Let the ratio between the two frequencies be expressed as a ratio of co-prime integers:
(14.40) ![]()
To determine the range, it is necessary to solve Equation 14.39 for ![]() and
and ![]() . Unfortunately, it is not as simple as this since, as a result of inevitable noise in the measurements, the two estimates may not match exactly.
. Unfortunately, it is not as simple as this since, as a result of inevitable noise in the measurements, the two estimates may not match exactly.
The naïve approach is to evaluate all combinations of ![]() and
and ![]() to find the combination that has the smallest absolute difference. While this will find the closest match, it involves significant unnecessary computation.
to find the combination that has the smallest absolute difference. While this will find the closest match, it involves significant unnecessary computation.
This problem is closely related to the conversion from a residue number system to standard binary. Given two residues, ![]() and
and ![]() in co-prime bases
in co-prime bases ![]() and
and ![]() , the goal is to calculate:
, the goal is to calculate:
where ![]() and
and ![]() are integers. The solution given by the modified Chinese remainder theorem (Wang, 1998) can be found directly as:
are integers. The solution given by the modified Chinese remainder theorem (Wang, 1998) can be found directly as:
where ![]() is an integer such that:
is an integer such that:
(14.43) ![]()
Comparing Equations 14.41 and 14.42, it can be seen that the right hand term is effectively calculating the unknown multiplier, ![]() , and
, and ![]() is the multiplicative inverse of
is the multiplicative inverse of ![]() . Since
. Since ![]() and
and ![]() are co-prime, such an inverse will always exist.
are co-prime, such an inverse will always exist.
The difference with range disambiguation is that ![]() and
and ![]() are not integers and that the result is not necessarily exactly equal. However, Equation 14.42 can be applied in several steps (Jongenelen et al., 2011). Firstly the difference term is calculated:
are not integers and that the result is not necessarily exactly equal. However, Equation 14.42 can be applied in several steps (Jongenelen et al., 2011). Firstly the difference term is calculated:
This should be an integer, but may not be because of noise. Forcing it to an integer by rounding enables ![]() to be calculated:
to be calculated:
Next, a weighted average of the two estimates is obtained:
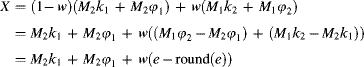
where ![]() is chosen to reduce the variance by taking a weighted average of the two estimates. The third line saves having to explicitly calculate
is chosen to reduce the variance by taking a weighted average of the two estimates. The third line saves having to explicitly calculate ![]() . Finally, the range may be calculated as:
. Finally, the range may be calculated as:
(14.47) ![]()
To simplify the calculation further, ![]() and
and ![]() can be chosen so that
can be chosen so that ![]() is a power of two (Jongenelen et al., 2010). For example, if
is a power of two (Jongenelen et al., 2010). For example, if ![]() or
or ![]() then
then ![]() . Furthermore,
. Furthermore, ![]() and
and ![]() are usually small integers; their size is limited by noise to ensure that Equation 14.45 gives the correct result for most pixels. Therefore, the multiplications in Equation 14.44 can be implemented directly as one or two additions. Alternatively, if the angles are produced by CORDIC units, the scale factor may be built in with the angle, giving
are usually small integers; their size is limited by noise to ensure that Equation 14.45 gives the correct result for most pixels. Therefore, the multiplications in Equation 14.44 can be implemented directly as one or two additions. Alternatively, if the angles are produced by CORDIC units, the scale factor may be built in with the angle, giving ![]() and
and ![]() directly.
directly.
Finally, the noise in the phase estimate will be approximately inversely proportional to the amplitude (Frank et al., 2009). Therefore, the weight, ![]() , in Equation 14.46 is derived to favour the signal with the stronger amplitude (Jongenelen et al., 2011):
, in Equation 14.46 is derived to favour the signal with the stronger amplitude (Jongenelen et al., 2011):
(14.48) ![]()
An implementation of the extended range processing is shown in Figure 14.16. In practise, the integration time can be divided between the two modulation frequencies (Jongenelen et al., 2011), with the phase offsets for each image set so that they fall in different frequency bins for the Fourier transform. The system therefore requires two phase decoder units operating in parallel. The output intensity image is formed from the weighted combination of the two component images.
Figure 14.16 Logic for range disambiguation using two modulation frequencies.
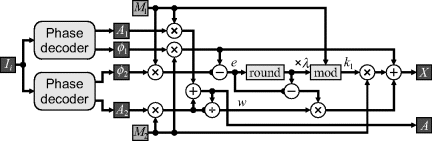
The two time consuming blocks within this circuit are the division to calculate ![]() and the following multiplication to weight the error term. These may be pipelined, if necessary, to achieve the required throughput. Best results (in terms of range accuracy) are obtained if the two frequencies are both high and with approximately the same integration time allocated to each frequency (Jongenelen et al., 2011). Under these circumstances,
and the following multiplication to weight the error term. These may be pipelined, if necessary, to achieve the required throughput. Best results (in terms of range accuracy) are obtained if the two frequencies are both high and with approximately the same integration time allocated to each frequency (Jongenelen et al., 2011). Under these circumstances, ![]() and both the division and multiplication can be removed (multiplication by 0.5 is just a right shift).
and both the division and multiplication can be removed (multiplication by 0.5 is just a right shift).
This example has shown the application of embedded image processing in enhancing a sensor. The use of an FPGA to perform the image processing has off-loaded the burden from the system using the data. Subsequent processing of the range image may be performed either by the host system or as downstream processing on the FPGA.
14.5 Real-Time Produce Grading
This final application describes a machine vision system for the grading of asparagus by weight. The goal was to estimate the weight of each spear and perform simple quality grading at up to 15 pieces per second. While the original algorithms (Bailey et al., 2004; Bailey, 2011a) were written in C and were able to execute sufficiently fast on a desktop machine for real-time operation, this application would be an ideal candidate for FPGA implementation within a smart camera.
While there is significantly more to a machine vision application than just the image processing, the mechanical handling, lighting and image capture arrangement are beyond the scope of the discussion here. The focus here will be solely on implementing the image processing algorithm on an FPGA. More details on other aspects of the project are given elsewhere (Bailey et al., 2001; 2004; Mercer et al., 2002; Bailey, 2011a). The basic principle behind estimating the weight of each asparagus spear is to treat each spear as a generalised cylinder and estimate its volume by measuring its projections in two perpendicular views. The weight is then estimated as:
where ![]() is the pixel position along the length of the spear, and
is the pixel position along the length of the spear, and ![]() and
and ![]() are the diameters of each view. The constant of proportionality is determined through calibration. The long, thin nature of asparagus enables multiple views to be captured in a single image by using a series of mirrors to divide the field of view.
are the diameters of each view. The constant of proportionality is determined through calibration. The long, thin nature of asparagus enables multiple views to be captured in a single image by using a series of mirrors to divide the field of view.
14.5.1 Software Algorithm
The structure of the software algorithm is shown in Figure 14.17 with images at various stages of the algorithm shown in Figure 14.18. Images are captured asynchronously, when triggered by the cups carrying the asparagus passing over a sensor. Cups are identified by counting them, with cup 0 causing an indicator LED to light up. Since images are buffered with variable latency before processing, it was necessary to use a visual indication to associate each image with a particular cup. The first processing step was to check for the presence of this indicator and for the presence of a spear on the cup. The spear was detected by calculating the mean and standard deviation within the one pixel wide window indicated in Figure 14.18. If no spear was present, processing was aborted for that image.
Figure 14.17 Machine vision application for grading asparagus.
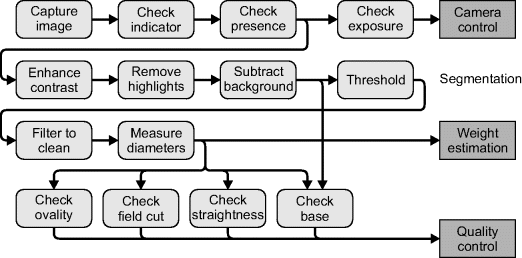
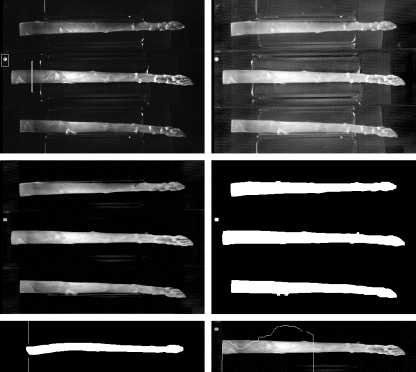
Figure 14.18 Images at various stages through the asparagus grading algorithm. Top left: captured image with indicator region and asparagus detection window overlaid; top right: after contrast enhancement; middle left: after background subtraction; middle right: after thresholding and cleaning; bottom left; side image showing field cut at base; bottom right: detecting white stalk.
If a spear was detected, the exposure was checked by building a histogram of the input image and determining the pixel value associated with the 99.6th percentile, essentially using the algorithm described in Section 7.1.3. This was used to automatically adjust the camera exposure by a small increment. The spear was segmented from the background by first performing a contrast enhancement using a lookup table, filtering to remove specular highlights with a 9 × 1 horizontal greyscale morphological closing. The background intensity was estimated by averaging the pixels in each column within each three views within the image. This background was subtracted and the contrast expanded using:
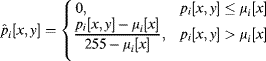
where ![]() is a pixel value in the
is a pixel value in the ![]() th view and
th view and ![]() is the corresponding column mean. This image was thresholded with a constant threshold level and then cleaned using a series of binary morphological filters: a vertical 1 × 9 opening was followed by a horizontal 5 × 1 opening and a 5 × 1 closing. The pixels in each column were counted for the two perpendicular views to enable the volume to be estimated using Equation 14.49.
is the corresponding column mean. This image was thresholded with a constant threshold level and then cleaned using a series of binary morphological filters: a vertical 1 × 9 opening was followed by a horizontal 5 × 1 opening and a 5 × 1 closing. The pixels in each column were counted for the two perpendicular views to enable the volume to be estimated using Equation 14.49.
Finally, a quality grading was performed using four simple tests. Firstly, the ovality of the spear was estimated by measuring the diameter at the base of the spear in each of the three views. The ovality ratio was the minimum diameter divided by the maximum diameter, after compensating for the change in magnification in the centre view. Secondly, the angle of the base was checked in each of the three views for the presence of a field cut, with the pixel position required to remove the cut determined. A diagonal field cut is clearly seen in the bottom left panel of Figure 14.18. Thirdly, the straightness of the spear is evaluated by measuring the variance of the spear centreline in the ![]() coordinate. Fourthly, the presence of a white base is detected in the central view. The greyscale image is filtered horizontally with an 11 × 1 minimum filter before reducing the intensity profile to one dimension by calculating the median of each row. This profile is then checked for a dip, indicating the presence of a white base, as illustrated in the bottom right panel of Figure 14.18.
coordinate. Fourthly, the presence of a white base is detected in the central view. The greyscale image is filtered horizontally with an 11 × 1 minimum filter before reducing the intensity profile to one dimension by calculating the median of each row. This profile is then checked for a dip, indicating the presence of a white base, as illustrated in the bottom right panel of Figure 14.18.
14.5.2 Hardware Implementation
In mapping the algorithm to hardware, there are a number of optimisations and simplifications that may be made to exploit parallelism. Only the image processing steps for the weight estimation and the filtering required for checking the base of the spear will be implemented in hardware. The output is a set of one-dimensional data, consisting of the edge positions of the spear in each view, along with the intensity profile from the central view. The quality control checks only need to be performed once per frame and are more control orientated, so can be implemented in software using the preprocessed one-dimensional data.
To minimise the memory requirements, as much as possible of the processing will be performed as the data is streamed in from the camera. However, since the processing consists of a mix of row orientated and column orientated processing, a frame buffer will be necessary. The detailed implementation of the algorithm is shown in Figure 14.19 and is described in the following paragraphs.
Figure 14.19 Schematic of the FPGA implementation.
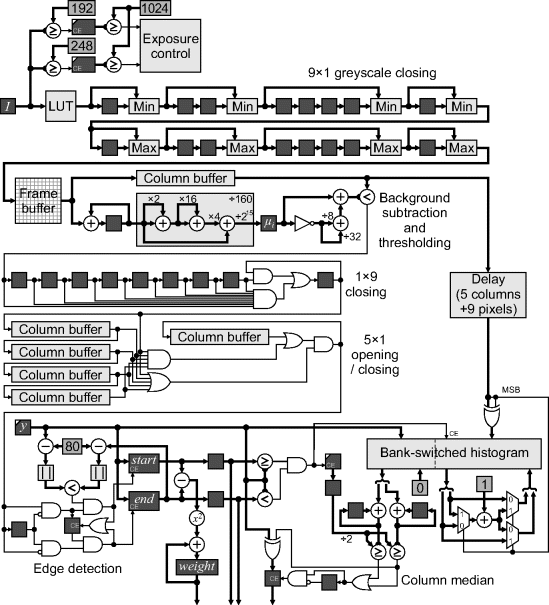
Of the initial processing checks, the check for the indicator LED is no longer necessary. Since the images are processed directly as they are streamed from the camera, this signal can be fed directly to the FPGA rather than capturing it via the image. The check for the presence of an asparagus spear will need to be deferred because it relies on the middle view. Processing will need to begin assuming that a spear is present; the results are discarded if it is later not found. For the exposure check, rather than build a histogram then determine the 99.6th percentile and check to see whether it is in range, the processing can be simplified by checking whether the incoming pixels are within range and accumulating them accordingly. In software the threshold levels were 192 and 250. By adjusting the upper threshold to 248 (binary 11111000) the comparison may be simply formed by ANDing the upper five bits. Similarly, comparing with 192 (binary 11000000) reduces to a two-input AND gate. These signals are used to enable the clocks of two counters, to count the pixels above the respective thresholds. The 99.6th percentile is somewhat arbitrary; it is equivalent to two lines of pixels in a 640 × 480 image. Adjusting this to 1024 simplifies the checking logic; at the end of the frame, if a spear is present, the counts are compared with 1024 (a simple check of the upper bits of the counter) for exposure control.
The contrast enhancement used a fixed lookup table in software. The incoming stream may be processed in exactly the same way, with a lookup table implemented using a block RAM. The 9 × 1 greyscale closing may be pipelined from the output of the lookup table. The erosion and dilation are implemented using the filter structure from Figure 8.39. Subsequent processing requires a column of data to remove the average. A bank of 160 row buffers could be used, but to fit this on-chip would require a large FPGA. Therefore, the image is streamed to an off-chip frame buffer. A ZBT RAM clocked at twice the pixel clock would avoid the need for a bank switched memory. Alternatively, two pixels could be packed into each memory location, although this would require a row buffer on the input or column buffer on the output.
After each image panel has been loaded into the frame buffer (160 columns) the column processing may begin. This streams the data out of the frame buffer by column for each third of the image. The first step is to calculate the column average, which is then subtracted from each pixel in that column. The pixel data is accumulated and also stored in a column buffer. At the end of each column, the total is divided by 160 and clocked into the mean register, ![]() . This division by a constant may be implemented efficiently with three adders (multiplying by 205/215 and eliminating a common subexpression) as shown in Figure 14.19. If only a binary image was required, the normalisation division of Equation 14.50 may be avoided by rearranging the threshold:
. This division by a constant may be implemented efficiently with three adders (multiplying by 205/215 and eliminating a common subexpression) as shown in Figure 14.19. If only a binary image was required, the normalisation division of Equation 14.50 may be avoided by rearranging the threshold:
(14.51) 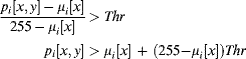
and since the threshold is constant (40/256) it may be implemented by a single addition (×32/256+× 8/256). The subtraction from 255 is simply a one's complement. Although the greyscale values are used to derive the profile for the quality grading, the pixel values without the background subtracted would be just as good, since the primary purpose of the background subtraction is to segment the spear. The background subtraction and thresholding is effectively implementing an adaptive threshold.
The presence check may be implemented by testing ![]() in the appropriate column of the central panel. If it is above a predefined threshold, then the presence of a spear is indicated (this is not shown in Figure 14.19).
in the appropriate column of the central panel. If it is above a predefined threshold, then the presence of a spear is indicated (this is not shown in Figure 14.19).
The binary morphological filters for cleaning the image may also be significantly simplified because they are one dimensional. The 1 × 9 vertical closing is normally implemented as an erosion followed by a dilation. The nine-input AND gate performs the erosion and sets the output register when nine consecutive ones are detected. The output is held at one until the zero propagates through to the end of the chain; this is effectively performing the dilation, using the same shift registers.
Rather than use another frame buffer to switch back to row processing, the 5 × 1 horizontal cleaning filters are implemented in parallel using column buffers to cache the previous columns along the row. Rather than perform the opening and closing as two separate operations, both operations are performed in parallel: a sequence of five consecutive ones will switch the output to a one, and a sequence of five zeros will switch the output to a zero. While this filter is not identical to that used in software, it has the same intent of removing sequences of fewer than five ones or zeros.
The next step is to determine the row numbers corresponding to the top and bottom edges of the asparagus spear in each column. A binary transition detector is used to clock the row counter, ![]() , into the
, into the ![]() and
and ![]() registers. This is complicated slightly by the fact that occasionally spears in adjacent cups are also detected near the edge of the image, as illustrated in Figure 14.20. The region detected near the centre of the panel corresponds to the correct region to be measured. A second detected region replaces the first only if it is nearer to the centre of the panel, that is if:
registers. This is complicated slightly by the fact that occasionally spears in adjacent cups are also detected near the edge of the image, as illustrated in Figure 14.20. The region detected near the centre of the panel corresponds to the correct region to be measured. A second detected region replaces the first only if it is nearer to the centre of the panel, that is if:
Figure 14.20 Spears visible and detected from adjacent cups.

(14.52) ![]()
At the end of the column, the edge values are transferred to a pair of output registers. The squared difference is also added to the weight accumulator only for the side images, evaluating Equation 14.49 for the current spear. If a hardware multiplier was not available, the squaring could be performed efficiently using a sequential algorithm since it only needs to be calculated once per column.
If desired, additional accumulators could be added to calculate the column variance for each view, used to evaluate the spear straightness. This would require two accumulators and a counter, and a squarer and a division.
(14.53) ![]()
Again, the squarer and division can use sequential algorithm over several clock cycles.
The final processing step is to calculate the median of the pixel values in each column of the central view. The greyscale values are delayed to compensate for the latency of the filters and the edge detection block. The most efficient way of calculating the median of a variable number of pixels is through accumulating a histogram and finding the 50th percentile. The row counter, ![]() , is compared against spear edges and only the pixels within the spear are accumulated by enabling the clock of the histogram accumulator. A counter also counts the pixels which are accumulated. When the column is complete, the histogram is summed to find the 50th percentile. This requires two histogram banks to be used, while the median is being found from one bank, the other bank is accumulating the histogram of the next column.
, is compared against spear edges and only the pixels within the spear are accumulated by enabling the clock of the histogram accumulator. A counter also counts the pixels which are accumulated. When the column is complete, the histogram is summed to find the 50th percentile. This requires two histogram banks to be used, while the median is being found from one bank, the other bank is accumulating the histogram of the next column.
The problem here is that there are only 160 clock cycles available for each column, requiring two bins to be summed every clock cycle. In the implementation in Figure 14.19, two histogram bins are stored in each memory location. Address ![]() holds the counts for histogram bins
holds the counts for histogram bins ![]() and
and ![]() . When accumulating the histogram, if the most significant bit of the pixel value is set, the least significant bits are inverted to get the address. The most significant bit is also used to control the multiplexers which determine which bin is incremented. When determining the median, the two bins are accumulated separately, using the
. When accumulating the histogram, if the most significant bit of the pixel value is set, the least significant bits are inverted to get the address. The most significant bit is also used to control the multiplexers which determine which bin is incremented. When determining the median, the two bins are accumulated separately, using the ![]() counter as the address until half the total count is reached. This is effectively scanning from both ends of the histogram in parallel until the 50th percentile is located. If the upper bin is reached first,
counter as the address until half the total count is reached. This is effectively scanning from both ends of the histogram in parallel until the 50th percentile is located. If the upper bin is reached first, ![]() is inverted to obtain the correct median value. While scanning for the median, the write port is used to reset the histogram count to zero to ready it for the next column.
is inverted to obtain the correct median value. While scanning for the median, the write port is used to reset the histogram count to zero to ready it for the next column.
Not shown in Figure 14.19 is much of the control logic. Various registers need to be reset at the start of the row (or column or image) and others are only latched at the end of a column. In controlling these, allowance must also be made for the latencies of the preceding stages within the pipeline. It is also necessary to account for the horizontal and vertical blanking periods when controlling the various modules and determining the latencies. Also not shown are how the outputs are sent to the serial processor. This depends on whether the processor is implemented on the FPGA or is external. However, because of the relatively low data rate (three numbers per column), this is not particularly difficult.
While quite a complex algorithm, it can still readily be implemented on an FPGA by successively designing each image processing component and piecing these together. A hardware implementation has allowed a number of optimisations that were not available in software, including the simplification of a number of the filters. This example demonstrates that even quite complex machine vision algorithms can be targeted to an FPGA implementation.
This chapter has illustrated the design of a number of embedded image processing systems implemented using FPGAs. They have varied from the relatively simple to the complex. There has not been sufficient space available to go through the complete design process, including the false starts and mistakes. What is presented here is an overview of some of the aspects of the completed design. It is hoped that these have demonstrated a range of the techniques covered in this book.
Overall, I trust that this book has provided both a solid foundation and will continue to provide a useful reference in your design. It is now over to you to build on this foundation, in the development of your own embedded image processing applications based on field programmable gate arrays.