
Chapter 11
Blob Detection and Labelling
Segmentation divides an image into regions which have a common property. One common approach to segmentation is to enhance the common property through filtering, followed by thresholding to detect the pixels which have the enhanced property. Filtering has been covered in Chapter 8 and various forms of thresholding in Sections 6.1.2, 6.2.3, 7.2.3 and 8.7. However, these operations have processed the pixels individually (using local context in the case of filters). To analyse the image it is necessary to associate groups of related pixels to one another. This enables data on complete objects to be extracted from the groups of pixels.
Image processing operations that transform the image from individual pixels to objects are, therefore, intermediate level operations. Since the input data is still in terms of pixels, it is desirable where possible to use stream-based processing. The output consists of a set of blobs or blob descriptions, and may not necessarily be in the form of pixels.
Of the many approaches for blob detection and labelling, only the bounding box, run-length coding, chain coding and connected components analysis are considered here. FPGA implementation of other region-based analysis techniques, such as the distance transform, watershed transform and Hough transform, are considered at the end of this chapter.
The bounding box of a set of pixels is the smallest rectangular box aligned with the pixel axes that contains all of the detected points. It is assumed that the input pixel stream has been thresholded or segmented by preprocessing operations. Let ![]() be the set of pixels associated with object i. Then the bounding box of
be the set of pixels associated with object i. Then the bounding box of ![]() is:
is:
(11.1) 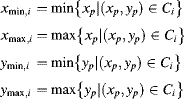
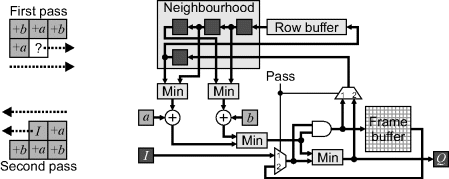
Initially assume that the input image is binary; the case of multiple labels is considered after presenting the basic circuit. Figure 11.1 shows the basic stream processing implementation. In the frame blanking period before the image is processed, init is set to one. The shaded block is only clocked for detected pixels, so that background pixels are effectively ignored. The init register provides initialisation when the first pixel is detected, by forcing the address of that pixel to be loaded into the ![]() ,
, ![]() ,
, ![]() and
and ![]() registers. Since the image is scanned in raster order, the first pixel detected will provide the
registers. Since the image is scanned in raster order, the first pixel detected will provide the ![]() value. The y value of every detected pixel is clocked into the
value. The y value of every detected pixel is clocked into the ![]() register because the last pixel detected in the frame will have the largest y. After the first pixel detected, the x value is compared with
register because the last pixel detected in the frame will have the largest y. After the first pixel detected, the x value is compared with ![]() and
and ![]() with the corresponding value adjusted if extended. At the end of the frame, the four registers indicate the extent of the object pixels within the image.
with the corresponding value adjusted if extended. At the end of the frame, the four registers indicate the extent of the object pixels within the image.
Figure 11.1 Basic bounding box implementation.
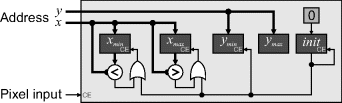
The basic implementation can be readily extended to process multiple input pixels per clock cycle (Figure 11.2). It is easiest if the number of pixels processed simultaneously is a power of two. The x address then contains only the most significant bits of the address, and two decoders are required to determine the least significant bits of the leftmost and rightmost of the pixels coming in simultaneously. These decoders can easily be built from the lookup tables within the FPGA. A similar approach can be used if multiple rows are processed simultaneously.
Figure 11.2 Processing multiple horizontal pixels simultaneously.
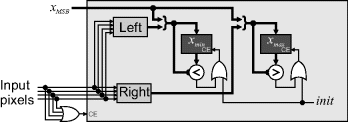
If there are multiple input classes, they can all be processed in parallel. Rather than build separate hardware for each class, the fact that each input pixel can only have one label implies that the update logic can be reused. The registers can then be multiplexed by the label of the incoming pixel. Unfortunately, the multiplexers will use more resources than the actual update logic. The alternative is to replace the registers with RAM and use the built-in RAM addressing to perform the multiplexing. The RAMs for ![]() and
and ![]() need to be dual-port, because the value needs to be read for the comparison. Since there is typically only a small number of labels, using fabric RAM gives a resource efficient implementation. Figure 11.3 assumes that a late write is not available, so the label and x value need to be buffered for writing in the following clock cycle. Otherwise, the hardware follows much the same form as the basic implementation in Figure 11.1.
need to be dual-port, because the value needs to be read for the comparison. Since there is typically only a small number of labels, using fabric RAM gives a resource efficient implementation. Figure 11.3 assumes that a late write is not available, so the label and x value need to be buffered for writing in the following clock cycle. Otherwise, the hardware follows much the same form as the basic implementation in Figure 11.1.
Figure 11.3 Bounding box of multiple labels in parallel.
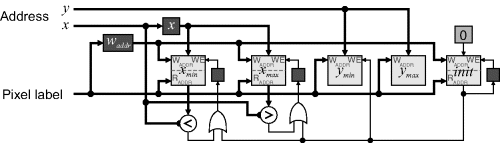
Using memory-based processing makes it difficult to process multiple input pixels simultaneously, because only one label can be read or written in each clock cycle. Therefore, to process multiple pixels per clock cycle it is necessary to have multiple copies of the hardware and to combine the results at the end of the frame.
From the bounding box, it is easy to derive the centre position, size and aspect ratio of the object:
(11.3) ![]()
(11.4) ![]()
However, the basic bounding box is unable to distinguish the orientation of long thin objects, as demonstrated in Figure 11.4. The basic system of Figure 11.1 can be extended to give orientation if required. Consider an object orientated top-right to bottom-left. The register ![]() is adjusted on most rows, whereas
is adjusted on most rows, whereas ![]() is only adjusted on the few rows at the top. The converse is true for an object orientated top-left to bottom-right. One method of discriminating between the two is to maintain an accumulator, acc, and increment it whenever
is only adjusted on the few rows at the top. The converse is true for an object orientated top-left to bottom-right. One method of discriminating between the two is to maintain an accumulator, acc, and increment it whenever ![]() is adjusted and decrement it whenever
is adjusted and decrement it whenever ![]() is adjusted. At the end of the frame, the sign of the accumulator indicates the orientation of the object. For long thin objects, this enables the angle to be estimated as:
is adjusted. At the end of the frame, the sign of the accumulator indicates the orientation of the object. For long thin objects, this enables the angle to be estimated as:
Figure 11.4 The bounding box cannot directly distinguish the orientation of long thin objects.

The main limitation of simply using the bounding box to extract the extent of an object is that the measurements are sensitive to noise. Any noise on the boundary at the extreme points will affect the limits and, consequently, the measurements derived in Equations 11.2 to 11.5. An isolated noise point away from the object can result in a spurious bounding box, giving meaningless results. Therefore, it is essential to apply appropriate filtering to remove noise before using the bounding box. Note that if a morphological opening with a circular or rectangular structuring element is used to remove isolated points, it is sufficient to just perform the erosion, because the effects of the dilation can be taken into account by adjusting Equations 11.2 to 11.5.
The biggest advantage of a simple bounding box is the low processing cost. Therefore, if the noise can be successfully filtered, it provides an efficient method of extracting some basic object parameters.
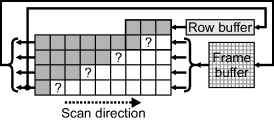
Many intermediate level image processing algorithms require more than one pass through the image. In this case, memory bandwidth is often the bottleneck on the speed of the processing. For some image processing operations, this may be overcome by processing runs of pixels as a unit, rather than processing individual pixels. In all but a few pathological cases, there are significantly fewer runs than there are pixels, allowing a significant acceleration of processing.
There are a number of different ways in which the runs can be encoded, as demonstrated in Figure 11.5. The standard approach used with image compression is to record each run as a (class, length) pair. However, if subsequent processing considers the connectivity between adjacent rows, then the absolute position is only implicit with this representation. An alternative is to record the absolute position of the transitions with a (class, start) pair, with the length given implicitly by the difference between adjacent starts. In the case that the input image is binary, it is only necessary to record the start and end of each run of object pixels and not code the background. In this case, it is also necessary to have an additional symbol to indicate the end of a line when it is a background pixel. This helps to identify blank lines and is necessary to prevent the second and third lines from Figure 11.5 from being considered as part of the same line.
Figure 11.5 Different schemes for run-length encoding.

Since each row is coded independently, multiple rows may be processed in parallel by building multiple processors.
The application of run-length coding for blob detection and labelling is considered briefly in the following two sections. Run-length coding can also be used for texture characterisation; in particular the distribution of run-lengths can be used to discriminate different textures. Directly run-length encoding a grey-level image is not as powerful as other texture analysis methods (Conners and Harlow, 1980). However, when applied to a binary image, it can be useful for providing statistical information on object sizes.
Another common application of run-length coding is for image compression (Brown and Shepherd, 1995). When an image has only a few distinct greyscale values or colours, it may be applied directly on the pixels. For general images, run-length coding is not usually effective on its own because adjacent pixels seldom have identical values. However, when the image is transformed, many of the coefficients are truncated to zero. Here run-length coding of the zeros can significantly reduce the number of coefficients that need to be stored.
One common intermediate level representation of image regions is to encode each region by its boundary. This reduces each two-dimensional shape to a one-dimensional boundary encoded within the two-dimensional space. This has advantages over a conventional image representation. The volume of data is significantly reduced in many applications, especially where the regions are large and have relatively smooth boundaries. This reduction in data can lead to efficient processing algorithms for extracting region features.
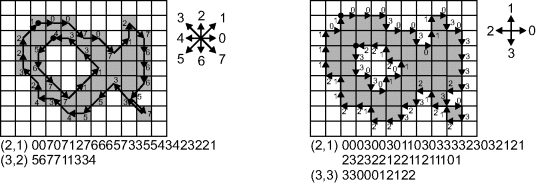
There are several different boundary representations (Wilson, 1997), of which the most common is the Freeman chain code (Freeman, 1961). Each pixel is coded with the direction of the next pixel in the sequence, as demonstrated in Figure 11.6. The chain code follows the object pixels on the boundary, keeping the background on the left. Consequently, the outside boundary is traversed clockwise and holes are coded anti-clockwise. A main alternative code is the crack code, which follows the cracks between the object and background pixels, as shown on the right in Figure 11.6.
Figure 11.6 Boundary representations. Left: chain code; right: crack code. The filled circle represents the start point of the boundary.
11.3.1 Sequential Implementation
A standard software algorithm for chain coding is to perform a raster scan of the image until an unprocessed boundary is encountered. Then scanning is suspended while the object boundary is traced and the chain code for the object built. This proceeds from a current boundary pixel looking at the neighbours sequentially in a clockwise order to find the next boundary pixel, and adding the corresponding link to the chain code. The traced pixels are also marked as processed to prevent them from being detected again later. Boundary following continues until the first pixel is reached and the complete boundary has been traced. At this point, the raster scan is resumed looking for another unmarked boundary pixel.
Such an algorithm does not fit within a stream processing implementation because it requires random access to the image. Although part of the algorithm involves a raster scan through the image, this is suspended whenever an object is encountered. The time taken to process the image also depends on image complexity; each pixel is loaded once during the raster scan, while approximately two pixels are read and one pixel is written for each boundary pixel detected during the boundary scan. An approach similar to this was implemented on an FPGA by Hedberg et al. (2007). Note that in some applications, the chain code does not actually have to be saved; features such as area, perimeter, centre of gravity and the bounding box can be calculated directly as the boundary is scanned.
The scanning process may be accelerated by using run-length codes as an intermediary (Kim et al., 1988). In the first pass, the image is run-length encoded and the run adjacency determined. The boundary scan can then be deferred to a second pass, where it is now potentially faster because runs can be processed rather than individual pixels.
11.3.2 Single Pass Algorithms
Even better is to perform the whole process in one pass during the raster scan. The basic principle is to maintain a set of chain code fragments and grow both ends of each chain fragment as each row is scanned. In this way, all of the chains are built up in parallel as the image is streamed in.
This has significant implications in terms of memory requirements. When only one chain is encoded at a time and the chain is built in one direction only (by tracking around the edge of the blob), the chain links can simply be stored sequentially in an array. Linking from one chain link to the next is implicit in the sequential addressing. However, when multiple fragments are being built simultaneously, with both the start and the end being extended, it is necessary to use some form of linked list. The storage space required for the linking is often significantly larger than the storage required for the chain code itself.
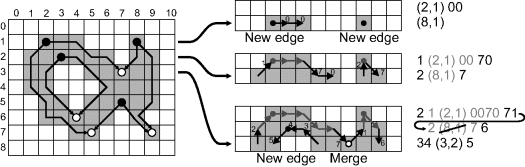
The basic principle is illustrated in Figure 11.7. As the image is scanned, each edge is detected and the chain code built within the context of the previous row. Consider the scan of the second line in this example. Two separate objects are encountered and chains begun. Even though these belong to the same object, this is not known at this stage. In general, there may be multiple starts for each boundary, occurring at the local tops of the object and background (Cederberg, 1979). As the next line is scanned, the chains are extended on both the left and right ends. On the third line, a new edge is started for the concavity that will eventually become the hole. The two fragments from the original two chains also merge and the corresponding chains linked. If the two fragments belong to two different start points, one of the start points must be deleted.
Figure 11.7 Growing a chain code with stream processing. Left: solid circles represent the starting points of new edges, with the lines showing the direction that the fragments are extended from these starting points, until the paths merge at the hollow circles. Right: how the boundary is built for the first three rows of the object.
Several software approaches using this basic technique are described in the literature. Cederberg (1979) scanned a 3 × 3 window through the image to generate the chain links and only coded the left and right fragments, as illustrated by the arrows on the left in Figure 11.7. He did not consider linking the fragments. Chakravarty (1981) also scanned a 3 × 3 window through the image and added segments built to a list. The algorithm involved a search to match corresponding segments as they are constructed. Shih and Wong (1992) used a similar approach to extend mid-crack codes, using a lookup table of the pixels within a 3 × 3 window to derive the segments to be added. Mandler and Oberlander (1990) used a 2 × 2 window to detect the corners in a crack code, which were then linked together in a single scan through the image. Their technique did not require thresholding the image first and derived the boundaries of each connected region of the same pixel value. This meant that each boundary is coded twice: once for the pixel value on each side of the crack. Zingaretti et al. (1998) performed a similar encoding of greyscale images. Their technique used a form of run length coding, looking up a 3 × 2 block of run lengths to create temporary chain fragments and linking these together as the image was scanned.
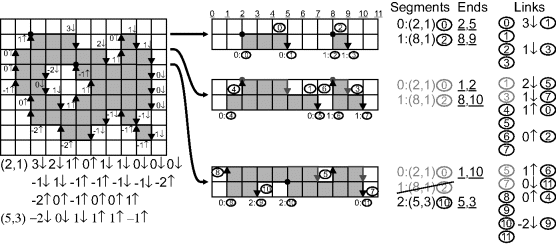
In a stream processing environment, it is unnecessary to actually perform the run-length coding first. This can be achieved by performing run-length coding of the cracks between pixels rather than the pixels themselves, with a simple linking mechanism from one row to the next (Bailey, 2010a). Since the linking primarily takes place at corners, this can be considered as a variation of the method described by Mandler and Oberlander, (1990). This hybrid crack run-length code is demonstrated on the left in Figure 11.8. It consists of the length of a horizontal run, plus one bit indicating whether the crack at the end of the run links up to the previous row, or down to the next row.
Figure 11.8 Raster-based crack run-length coding. Left: the coding of the regions. Right: building the linked lists representing the boundary, showing the first three lines of cracks.
The crack run-length chain can be built by scanning a 2 × 2 window through the image, as shown on the left in Figure 11.9. The pattern of pixels within the window provides the control signals for the linking circuitry on the right. With a binary image, the four bits within the window can conveniently be decoded from an arbitrary combination of patterns to produce each control signal with a single LUT.
Figure 11.9 Block diagram of raster-based crack code follower.
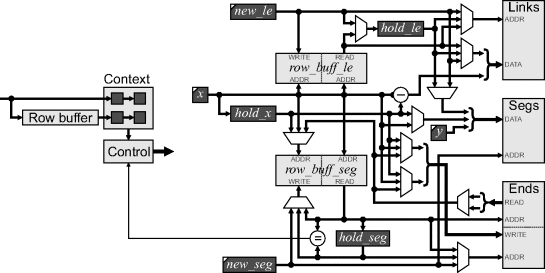
In addition to the row buffer required to form the input window, two other row buffers are also required to record the segment and link numbers at the ends of each fragment formed, as indicated along the bottom of each scan in Figure 11.8. The link entry row buffer (![]() ) holds the ends of the links from the previous row and the segment row buffer (
) holds the ends of the links from the previous row and the segment row buffer (![]() ) allows the mergers to be detected and processed appropriately.
) allows the mergers to be detected and processed appropriately.
Looking at the linking first, at the start of a crack run-length, the x position is latched into ![]() . If the link comes from the previous row, the le from the row buffer is held, otherwise a new link entry is allocated and saved in the row buffer and held in
. If the link comes from the previous row, the le from the row buffer is held, otherwise a new link entry is allocated and saved in the row buffer and held in ![]() . At the end of the run, either the link from the previous line is read from the row buffer or another new link is created, and the run-length data written to the Links table.
. At the end of the run, either the link from the previous line is read from the row buffer or another new link is created, and the run-length data written to the Links table.
If a new segment was created (both ends of the run link down to the next row) it is also necessary to allocate a new start pointer and save the position (either x or ![]() depending on the direction) and link entry into the Segments table. If a merge occurs (both ends of the run link to the previous row) it is necessary to check if the segments that are linked belong to the same segment or different segments. At the start of the run, the segment number is read from the row buffer and held in
depending on the direction) and link entry into the Segments table. If a merge occurs (both ends of the run link to the previous row) it is necessary to check if the segments that are linked belong to the same segment or different segments. At the start of the run, the segment number is read from the row buffer and held in ![]() . This is compared with the segment number at the end of the run. If they are the same, the boundary is completed, otherwise the segments are merged and one of the segment pointers is discarded. This requires updating the segment number in the row buffer corresponding to the opposite end of the discarded segment. The Ends table, indexed by the segment number, is used to keep track of the column numbers of the current ends of each segment.
. This is compared with the segment number at the end of the run. If they are the same, the boundary is completed, otherwise the segments are merged and one of the segment pointers is discarded. This requires updating the segment number in the row buffer corresponding to the opposite end of the discarded segment. The Ends table, indexed by the segment number, is used to keep track of the column numbers of the current ends of each segment.
With an early read (the memory is read in the middle of the clock cycle) and late write, the whole process can operate at one pixel per clock cycle (Bailey, 2010a). With a little extra logic, the segment entries that are discarded through merging can be recycled reducing the size of the Segments and Ends tables. The Links table requires one entry for each vertical crack within each object (the horizontal cracks are represented by the run lengths). In the worst case, this is the same as the number of pixels in the image (for alternating black and white lines), although for most realistic images of interest, the size of the table can be considerably smaller.
If necessary, the crack run-length code can be converted to a conventional crack code or Freeman chain code for subsequent processing. However, much of the processing may be able to be performed directly on the crack run-length code.
An image of the region may be reconstructed from the boundary code by drawing the boundary within an empty image and filling between the boundary pixels using a raster scan, producing a streamed output image.
11.3.3 Feature Extraction
Since the boundary contains information about the shape of a region, many features or parameters may be derived directly from the chain code (or other boundary code). The most obvious measurement from the chain code is the perimeter of the object. Unfortunately, simply counting the number of steps within the chain or crack code will overestimate the perimeter length because of quantisation effects. The error in the estimate also depends on the angle of the boundary within the image. To overcome this problem, it is necessary to smooth the boundary by measuring the distance between points k steps on either side, and assigning the average as the step size at each link (Proffitt and Rosen, 1979):
(11.6) ![]()
For long straight boundaries, increasing k can reduce the error in the estimate of the perimeter to an arbitrarily low level. However, this will result in cutting corners. Consequently, making k too large will underestimate the perimeter. For objects with rough boundaries, the perimeter will depend on the scale of the measurement, enabling a fractal dimension to be calculated as a feature.
Corners can be defined as regions of extreme curvature. Again, the quantisation effects on the boundary mean that the local curvature is quite noisy and can be smoothed by considering points k links apart. A simple corner measure at a point is the difference in angle between the points k links before the current point and k links after the current point (Figure 11.10).
(11.7) ![]()
Since k is a small integer and the steps are integers, the angles may be determined by table lookup. (For example, with ![]() ,
, ![]() ,
, ![]() , requiring only four bits from each of
, requiring only four bits from each of ![]() and
and ![]() , or eight input bits total for the lookup table to implement
, or eight input bits total for the lookup table to implement ![]() .) The peaks in
.) The peaks in ![]() that are over a predefined angle are defined as corners. A more sophisticated corner measure that takes into account the length over which the angle changes is given by Freeman and Davis (1977).
that are over a predefined angle are defined as corners. A more sophisticated corner measure that takes into account the length over which the angle changes is given by Freeman and Davis (1977).
Figure 11.10 Measuring curvature for detecting corners.
Measuring the area of a region consists of counting the number of pixels within the boundary. This may be obtained directly from the boundary by using contour integration (Freeman, 1961). It is important to note that the chain code is on one side of the boundary, so it will underestimate the area of regions and overestimate the area of holes unless the part pixels outside the chain are taken into account. The crack code does not have the same problem. Expressing it in terms of the crack codes:
(11.8) ![]()
This is amenable to direct calculation from the crack run-length codes. The area is generally much less sensitive than the perimeter to digitisation errors and noise.
Note that blobs will have a positive area, while holes will have a negative area. This enables external and internal boundaries to be distinguished, enabling the number of holes, and the Euler number to be calculated.
The centre of gravity may be determined from the contour integral for the first moment:
(11.9) 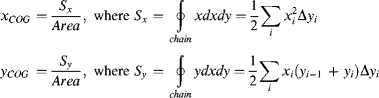
Higher order moments may be calculated in a similar way.
The convex hull may also be determined from the boundary code. Consider each link consisting of an arbitrary offset, ![]() . Point i on the boundary is concave if:
. Point i on the boundary is concave if:
The point may then be eliminated by combining it with the previous point:
(11.11) ![]()
If this is performed for every pair of adjacent points until no further points can be eliminated, then the remaining points are the vertices of the minimum convex polygon containing the region. (Note that holes will reduce to nothing since they are concave. To obtain the convex hull of a hole, the left and right hand sides of Equation 11.10 need to be swapped.)
From the convex hull, the depth of the bays may be determined, enabling a concavity analysis approach to separating touching convex objects (Bailey, 1992). The principle is that a convex object should have no significant concavities, so a concavity indicates multiple touching objects. From the deepest concavity, an opposite concavity is found and the object separated along the line connecting them. This is repeated until no significant concavities remain.
From the convex hull, the minimum area enclosing rectangle may be determined (Freeman and Shapira, 1975). The minimum area enclosing rectangle has one side coincident with the minimum convex polygon, so each edge can be tested in turn to find the extent of the region both parallel to and perpendicular to that edge. The extents that give the smallest area correspond to the minimum area enclosing rectangle.
The bounding box (aligned with the pixel axes) can be found from a simple scan around the boundary, finding the extreme points in each direction.
Chain codes may also be used for boundary or shape matching (Freeman, 1974). Although a full description is beyond the scope of this work, the basic principles are briefly outlined. If the complete boundary is being compared, a series of shape features may be extracted from the boundary and also the boundaries of candidate matches. Those with wildly different feature vectors can be eliminated. Those with similar feature vectors may be compared in more detail using correlation to determine the quality of fit. If the match is on partial boundaries, a chain code can be broken into multiple segments based on prior knowledge of the problem. For example, in a jigsaw-type problem, appropriate segmentation points would be sharp corners (Freeman, 1974). These fragments are then matched as before, using simple features to eliminate obvious mismatches and to find approximate matches that can be investigated further.
One set of shape features that may be extracted from boundary codes are Fourier descriptors. For a closed boundary, the shape is periodic, enabling analysis by Fourier series (Zhang and Lu, 2002). While any function of the boundary points could be used, the simplest is the radius from the centre of gravity as a function of angle. The main limitation of this is that the shape must be fairly simple for the function to be single-valued. A arbitrary shape can be represented directly by its x and y coordinates, as a complex number: ![]() , as a function of length along the perimeter, t. Alternatively, the angle of the tangent as a function of length can be used, normalised to make it periodic (Zahn and Roskies, 1972). Whichever features are used, the shape may be represented by the low order Fourier series coefficients. The method is also relatively insensitive to quantisation noise and with normalisation can be used for rotation and scale invariant matching. The simple and complex number-based Fourier descriptors also allow the smoothed boundary to be reconstructed from a few coefficients.
, as a function of length along the perimeter, t. Alternatively, the angle of the tangent as a function of length can be used, normalised to make it periodic (Zahn and Roskies, 1972). Whichever features are used, the shape may be represented by the low order Fourier series coefficients. The method is also relatively insensitive to quantisation noise and with normalisation can be used for rotation and scale invariant matching. The simple and complex number-based Fourier descriptors also allow the smoothed boundary to be reconstructed from a few coefficients.
11.4 Connected Component Labelling
While chain coding concentrates on the boundaries, an alternative approach labels the pixels within the connected components. Each set of connected pixels is assigned a unique label, enabling the pixels associated with a region to be isolated and features of that region to be extracted.
11.4.1 Random Access Algorithms
There are several distinct approaches to connected components labelling. One is based on boundary scanning (Chang et al., 2004), effectively determining the boundary and then filling in the object pixels inside the boundary with a unique label. In this approach, like chain coding, the image is scanned in a raster fashion until an unlabelled object pixel is encountered. A new label is assigned to this object and the boundary is scanned. Rather than extract chain codes of the boundary, the boundary pixels are assigned the new label. When the raster scan is resumed, these boundary labels are propagated internally to label the pixels associated with the object. Hedberg et al. (2007) implemented this algorithm on an FPGA. The main limitation of this approach is that the boundary scan requires random access to the image, requiring the complete image to be available in a frame buffer. The advantage of such an implementation is that the memory required by the labelling process is smaller than conventional connected components labelling because fewer bits are required to store the labels. In a typical case, the processing is also faster than standard two-pass algorithms (described shortly) because all of the processing is performed in a single pass plus the time associated with the boundary scanning. Some features can also be extracted directly during the boundary scan phase (for example any features that may be extracted from the boundary codes can be extracted at this stage).
An alternative to scanning around the boundary of an object is to perform a flood–fill operation when an unlabelled pixel is encountered during the raster scan (AbuBaker et al., 2007). A flood fill suspends the raster scan and defines the unlabelled pixel as a seed pixel for the new region. It then fills all pixels connected to the seed pixel with the allocated label. A row can be filled easily, with connected pixels in the rows immediately above and below added to a stack. Then, when no more unlabelled pixels are found adjacent to the current row, the seed is replaced by the top of stack and flooding continues. By carefully choosing which pixels are pushed onto the stack, an efficient algorithm can be obtained (AbuBaker et al., 2007). Again, the limitation is that the flood–fill phase requires random access to the image, requiring the complete image to be available in a frame buffer.
11.4.2 Multiple-Pass Algorithms
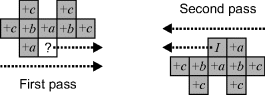
To avoid the need for random access processing, the alternative is to propagate labels from previously labelled connected pixels. The basic idea is illustrated in Figure 11.11. When an object pixel is encountered during the initial raster scan, its neighbours to the left and above are examined. If all are background pixels, a new label is assigned. Otherwise, the minimum non-zero (non-background) label is propagated to the current pixel. This is accomplished by having the input multiplexer select the Label during the first pass. If Label is the minimum non-zero value, then the new label is used and Label is incremented. For U shaped objects, multiple labels are assigned to a single connected component. At the bottom of the U, the minimum of the two labels is selected and propagated. However, the pixels that have already been labelled with the non-minimum label must be relabelled. The simplest method of accomplishing this is to perform a second, reverse raster scan through the image, this time from the bottom-right corner back up through the image. In the second pass (and subsequent passes) the input multiplexer is switched to the input pixel, effectively including it within the neighbourhood. The second pass propagates the minimum non-zero label back up the branch, replacing the larger initial label. For W shaped objects and spirals, additional forward and reverse passes through the image may be required to propagate the minimum label to all pixels within the connected component. Therefore, the process is iterated until there are no further changes within the image.
Figure 11.11 Multipass connected components labelling. Left: neighbourhood context, with the dotted lines showing the scan direction; right: label propagation.

This iterative, multipass approach to connected component labelling has been implemented on an FPGA (Crookes and Benkrid, 1999; Benkrid et al., 2003b). The main advantage of this approach is that the circuitry is very simple and quite small. It also requires no intermediate storage (apart from the frame buffer) – all necessary information is stored in the intermediate images. However, the main problem is that the number of passes through the image depends on the complexity of the connected components and is indeterminate at the start of processing. Therefore, there is potentially a large latency as a result of processing. The image must also be stored in a frame buffer, although the second and subsequent passes may be performed in place.
11.4.3 Two-Pass Algorithms
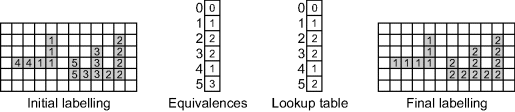
This label propagation may be reduced to two passes by explicitly keeping track of the pairs of equivalent labels whenever two parts of a component with a single label merge. The classic software algorithm (Rosenfeld and Pfaltz, 1966) does just this and is illustrated with a simple example in Figure 11.12. The first pass is similar to the first pass of the multipass algorithm as described above: as the image is scanned, if none of the previously processed neighbours has a label, a new label is assigned as before. If the neighbourhood contains only one label, that label is propagated to the current pixel. At the bottom of U shaped regions, however, there will be two different labels within the neighbourhood. These labels are equivalent in that they are associated with the same connected component. One of the labels (usually the smaller) will be retained and all instances of the redundant label must be converted to the current label. Rather than use multiple additional passes to propagate the change through the image, the fact that the two labels are equivalent is recorded in an equivalence table. At the end of the first pass, all of the equivalences are resolved and a lookup table created which maps the initial temporary labels to the final label. The issue of equivalence resolution has received much attention in the literature and is the main area of difference between many related algorithms (Wu et al., 2005; He et al., 2007). A wide range of techniques has been used to reduce the memory requirements of the data structures used to represent the equivalence table and to speed the search for equivalent labels. A second raster scan through the image then uses the lookup table to assign the final label to each object within the image.
Figure 11.12 Connected component labelling process. From the left: the initial labelling after the first pass; the equivalence or merger table; the lookup table after resolving equivalences; the final labelling after the second pass.
An early implementation of the standard two-pass algorithm (Rachakonda et al., 1995) used a bank-switched algorithm structure to enable every frame to be processed. As the initial labelling pass was performed on one image, the relabelling pass was performed on the previous image. An implementation of the standard two-pass algorithm using Handel-C is described by Jablonski and Gorgon (2004), where they show how the software algorithm is ported and refined to exploit parallelism.
The key to an efficient implementation is to have an efficient approach to resolving equivalences. When a new label is created, its entry in the equivalence table is set to point to itself. Then whenever a merger occurs, the larger label is set to point to the smaller label. While this is adequate in the simple example shown in Figure 11.12, the one label may merge with several others, making it necessary to store the labels as sets. One approach is to scan through the table every time two regions merge to update the labels to the new equivalent label. However, this cannot be accomplished in a single clock cycle, preventing its use within a streamed implementation.
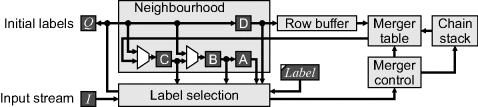
One approach is to partially resolve the mergers with each row (Bailey and Johnston, 2007). This is outlined in Figure 11.13. The basic idea is to prevent the redundant label from propagating further and resulting in additional mergers. To accomplish this, it is necessary to use the merger table to replace any instances of the redundant label that have been saved into the row buffer with the current label being used for that region. The merger control block initialises the entry in the merger table when a new label is allocated. A merger can only occur when pixel B is background and C has a different label to A or D. In this case, the merger table is updated so that the larger label is translated to the smaller label which is propagated. (The merger table must be dual-port to allow this update while the row buffer output is being translated.) The multiplexers on the input of B and C ensure that the redundant label within the neighbourhood is replaced by the minimum label.
Figure 11.13 First-pass logic required to efficiently implement merging.
One minor problem remains – if there is a sequence of mergers with the larger label on the left, as shown in the second region in Figure 11.12, then the merger table contains a chain of links from one label to the next. In this case, a single lookup in the merger table is insufficient to return the current label. (It can be shown that if the smaller label is on the left, this problem does not occur; Bailey and Johnston, 2007). The links may be unchained by a second backwards scan along each row. However, the data stored in the row buffer does not need to be changed as long as the entries in the merger table are unchained to all point to the smallest label for each region. This may also be accomplished by scanning through the merger table to unchain the links. The affected links may be accessed quickly by pushing the pair of merged labels onto a stack whenever the larger label is on the left (Bailey and Johnston, 2007). Then, at the end of the row, during the horizontal blanking period, the pairs are popped off the stack (effectively jumping to the key locations back along the row) and the merger table updated. With pipelining, unchaining requires one clock cycle per stack entry (Bailey and Johnston, 2007).
At the end of the first pass, it is necessary to reconcile chains of mergers that have taken place on different rows. A single pass through the table from the smallest label through to the largest is sufficient. If the entry in the table is not pointing to itself, only a single additional read is required to obtain the final label. If desired, the labels may also be renumbered consecutively during this pass. Each initial label will therefore require one or two reads and one write to the merger table.
The second pass through the image simply uses the merger table as a lookup table to translate the initial labels to the final label used for each connected component.
In software, the second pass can be accelerated by using run-length coding (He et al., 2008), because in general there will be fewer runs than pixels. In hardware though, little is gained unless the image is already run-length encoded by a previous operation. Otherwise the pixels still have to be read one by one, and all of the processing for each pixel takes place in a single clock cycle (although several rows can be run-length encoded in parallel; Trein et al., 2007). If a streamed output image is required, the only advantage of run-length encoding is to reduce the size of the intermediate frame buffer. However, if the output is an image in a frame buffer rather than streamed, then run-length coding can provide additional acceleration (Appiah and Hunter, 2005). During the first pass, in addition to storing the temporary labels in a frame buffer, the image is run-length coded. Then, during the second relabelling pass, only the runs with labels that need to be changed need processing. All of the background pixels and runs with the correct label can be skipped.
The algorithms considered so far are largely sequential. This is because labelling is not a local operation – distant pixels could potentially be connected, requiring the same label. This has led to a range of parallel architectures to speed up the label propagation (Alnuweiri and Prasanna, 1992). The major limitation of many of these approaches is that they require a large number of processors, making their implementation on an FPGA very resource intensive. It is also usually assumed that the image data has been preloaded onto the processors. When processing streamed images, much of the system must remain idle while the image is loaded in. The bandwidth bottleneck destroys the gains obtained by exploiting parallelism. One technique that may be exploited by an FPGA implementation is to divide the image into non-overlapping blocks. A separate processor is then used to label each of the blocks in parallel. In the merger resolution step, it is also necessary to consider links between adjacent blocks. This requires local communication between the processors for adjacent blocks. The second pass, relabelling each block with the final label can also be performed on each block in parallel.
11.4.4 Single-Pass Algorithms
The global nature of connected components labelling requires a minimum of two passes through the image to produce a labelled image. Frequently, connected components labelling is followed by feature extraction from each region, with the labelling operation used to distinguish between separate regions. In such cases, it is not actually necessary to produce the labelled image as long as the correct feature data for each region can be determined.
The basic principle behind single-pass approaches is to extract the data required to calculate the features during the first pass (Bailey, 1991). This requires a set of data tables to accumulate the data. When two regions merge, the data associated with each of the regions is also merged. Therefore, at the end of the image scan feature data has been accumulated for each of the connected component.
The data that needs to be maintained depends on the features that are being extracted from each connected component. The restriction on which features can be accumulated on-the-fly is governed by the fact that there must be a simple way to combine the raw data for each region when a merger occurs.
- If only the number of regions is required, this can be determined with a single global counter. Each time a new label is assigned, the counter is incremented, and when two regions merge the counter is decremented.
- For measuring the area of each region, a separate counter is maintained for each label. When two regions are merged, the corresponding counts are combined.
- For determining the centre of gravity of the region, or any other moment-based feature, the sums of the x and y coordinates are maintained. (For higher order moments, sums of powers of x and y coordinates are kept.) The corresponding sums are simply added on merging to give the new sum for the combined region. At the end of the image, centre of gravity may be obtained by normalising the sums by the blob area:
(11.12)
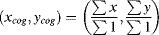
- Similarly, higher order moments may be obtained by appropriately combining the accumulated sums. This includes features such as the orientation and size of the best fit ellipse.
- To obtain the bounding box of each region, the extreme coordinates of the pixels added are recorded. On merging, the combined bounds may be obtained by using the minimum or maximum as necessary of the subcomponents.
- The average colour or pixel value may be calculated by adding the pixel values associated with each region into an accumulator and normalising by the area at the end of the scan. Similarly higher order statistics, such as variance (or covariance for colour images), skew and kurtosis, may be accumulated by summing powers of each pixel value and deriving the feature value from the accumulated data at the end of the image.
- Other, more complex, features such as perimeter may require additional operations (such as edge detection) prior to accumulating data.
Obviously, some features are not able to be calculated incrementally. In this case, it is necessary derive the labelled image prior to feature extraction.
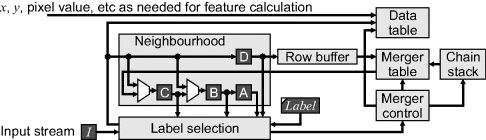
When single-pass processing is possible, the architecture of Figure 11.13 can be extended to give Figure 11.14 (Bailey and Johnston, 2007; Bailey et al., 2008). The data table can be implemented with single-port memory by reading the data associated with a label into a register and performing the updates in the register. On a merger, the merged entry can be read from the data table and combined with the data in the register. Then, on the first background pixel after the blob, the data may be written back to the data table (Bailey and Johnston, 2007). The object data is then available from the data table at the end of the frame.
Figure 11.14 Single-pass connected components analysis.
The main limitation with this approach is that the size of the data and merger tables depends on the number of initial labels within the image. In the worst case, this is proportional to the area of the image, where the maximum number of labels is one quarter of the number of pixels.
Since the initial labels are not actually being saved (apart from the previous row in the row buffer), the number of labels in active use at any one time is proportional to the width of the image not the area. Therefore, the memory used by the data table and merger tables is being used ineffectively. The memory requirements of the system can be optimised by recycling labels that are no longer used (Lumia et al., 1983; Khanna et al., 2002).
The approach taken in Bailey et al. (2008) and Ma et al. (2008) is to completely relabel each row. Several changes are required to the architecture of Figure 11.14. The equivalence table is split into two tables (Figure 11.15), with the merger table reflecting equivalences between labels on the same row and a translation table to convert the labels used in previous row to those used in the current row. Two merger and data tables are also required, for reasons that will be outlined shortly. There are also some significant changes to the logic and operation of the system.
Figure 11.15 Single-pass connected components analysis with label reuse.
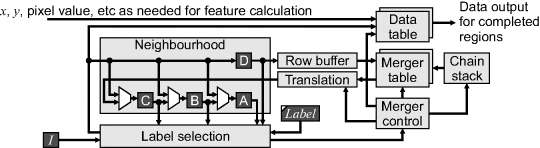
Firstly, the label selection code is a little more complex. A new label is assigned each time a region is first encountered on a row. Pixels from the previous row (in registers A, B and C) all need to be updated with the current label and the translation is recorded in the translation table. Secondly, the merger table is only updated when two regions which have different current row labels merge; many region mergers result in translations rather than requiring the merger table to be updated. It can be shown that the larger label will always be on the left for those mergers that require updating the merger table (Ma et al., 2008). Therefore, all mergers must be pushed onto the chain stack for resolution at the end of the row. Thirdly, the merger table is only applicable for a row, rather than the whole image. Two tables are therefore required: one for mapping mergers from the previous row (out of the row buffer) and one for recording mergers on the current row. At the end of the row (after unchaining), these tables are then swapped. The translation table, since it is specific to the row being translated, is discarded and rebuilt each row. Fourthly, two sets of data tables are required because the indexes change with every row. Whenever an entry is made within the translation table, the corresponding data is taken from the previous row's data table and combined with the data for the current row. Any data not transferred has no pixels on the current row and therefore represents a completed objects. Such data is available for subsequent feature processing at the end of each row.
Trein et al. (2007; 2008) took a slightly different approach. On the input, they run-length code up to 32 pixels in parallel, enabling a slower clock speed to be used to sequentially process the run-length encoded data. When regions merge, a pointer from the redundant label is linked to the label that is kept; however, chaining is not discussed. To keep the data table small, a garbage collector detects when a region has been completely scanned, outputs the resulting region data and adds the released label to a queue for reuse.
11.4.5 Multiple Input Labels
In all of the discussion above, it has been assumed that the input image is binary. If, instead, the input was a labelled image, for example from multilevel thresholding or colour segmentation, then the processing outlined above needs to be extended. A naïve approach would be to build a separate processor for each label. However, since each incoming pixel can only have one label, the hardware of a single processor may be augmented to handle multiple input labels.
The main change is that the labelling process should only propagate labels within regions with the same input label. Any different input label is considered as background. This requires that the input label must also be cached in the row buffer. Equality comparisons with the input label are required to create a foreground and background based on the incoming pixel. Since both foreground and background are being labelled, potentially twice as many labels are required. Consequently, the merger table and data tables need to be twice as large. Otherwise, the processing is the same as the single label case.
11.4.6 Further Optimisations
If the regions being labelled or extracted are convex, then further simplifications are possible. Since there are no U shapes (this would be non-convex), a relatively simple label propagation is sufficient to completely label the image in a single pass. The merger logic associated with the previous techniques is no longer required. The only slight complication arises with ⌟ shaped regions, such as the left hand object in Figure 11.12. This can occur along the top left edge of convex objects and it is necessary to prevent a new label from being assigned. One solution to overcoming this problem is to defer labelling the pixels in a row until the first background pixel is encountered. A simple approach is to run-length encode the pixels stored in the row buffer and output the streamed labelled image as it is being reconstructed from the row buffer.
Another form of labelling object pixels is provided by the distance transform. This labels each object pixel with its distance to the nearest background pixel. Different distance metrics result in different distance transforms. The Euclidean distance corresponds with how distances are measured in the real world. It is based on the L2 norm and is given by:
One difficulty with using the Euclidean distance is that it is difficult to determine which pixel is actually the closest background pixel without testing them all. This is complicated by the fact that images are sampled with a rectangular sampling grid. Two other distance metrics which are easier to calculate are the city block or Manhattan distance metric and the chessboard metric. The city block distance is based on the L1 norm:
(11.14) ![]()
This counts the number of horizontal and vertical pixel steps, considering neighbouring pixels which are four-connected. As a result, diagonal distances are overestimated because a diagonal step counts as two pixels. The chessboard metric is based on the L∞ norm:
(11.15) ![]()
This is so called because it counts the number of steps a king would take on a chessboard. This considers pixels to be eight-connected, so underestimates diagonal distances because a diagonal connection only counts as one step.
These three metrics are compared in Figure 11.16. It can be clearly seen that the non-Euclidean metrics are anisotropic. This has led to a wide range of other metrics that give better approximation to the Euclidean distance, while retaining the ease of calculation of the other distance metrics.
Figure 11.16 Comparison of distance metrics (contour lines have been added for illustration). Left: Euclidean, L2; centre: city block, L1; right: chessboard, L∞.

Obviously, direct calculation of the distance transform by measuring the distance of every object pixel from every background pixel and selecting the minimum is impractical. Therefore, several different methods have been developed to efficiently calculate the distance transform of a binary image.
11.5.1 Morphological Approaches
One approach is to successively erode the object using a series of morphological filters. If each pass removes one layer of pixels, then the distance of a pixel from the boundary is the number of passes required for an object pixel to become part of the background. The chessboard distance is obtained by eroding with a 3 × 3 square structuring element, whereas the city block distance is obtained by eroding with a five element + shaped structuring element. A closer approximation to Euclidean distance may be obtained by alternating the square and cross elements with successive iterations (Russ, 2002), which results in an octagonal shaped pattern. The main limitation of such algorithms is that many iterations are required to completely label an image. On an FPGA, the iterations may be implemented as a pipeline up to a certain distance (determined by the number of processors which are constructed). Beyond that distance, it is necessary to save the result as an intermediate image and feed the image back through.
To improve the approximation to a Euclidean distance, a larger structuring element needs to be used. This may be accomplished by having a series of different sized circular structuring elements applied in parallel (Waltz and Garnaoui, 1994b). Such a stack of structuring elements is equivalent to using greyscale morphology with a conical shaped structuring element. While using a conical structuring element directly is expensive, by decomposing it into a sequence of smaller structuring elements, it can be made computationally more feasible (Huang and Mitchell, 1994). However, for arbitrary sized objects, it is still necessary to iterate using finite sized structuring element.
11.5.2 Chamfer Distance
The iterative approach of morphological filters may be simplified by making the observation that successive layers will be adjacent. This allows the distance to be calculated through local propagations using stream processing (Borgefors, 1986; Butt and Maragos, 1998). The result is the chamfer distance transform.
Two raster scanned passes through the image are required. The first pass is a normal raster scan and propagates the distances from the top and left boundaries into the object.
(11.16) 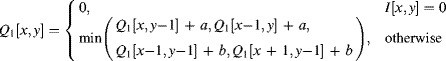
The second pass is a reverse raster scan, propagating the distance from the bottom and right boundaries.
(11.17) ![]()
An implementation of the chamfer distance transform is given in Figure 11.17. A frame buffer is required to hold the distances between passes. Note that the streamed output is in a reverse raster scan format. An FPGA-based implementation of such a distance transform is given in (Hezel et al., 2002). Higher throughput can be obtained by using separate hardware for each pass, with a bank switched frame buffer in between.
Figure 11.17 3 × 3 chamfer distance transform. Left: propagation increments with each pass; right: hardware implementation reusing the circuitry between the passes.
Different values of a and b will result in different distance metrics. The chessboard distance results when ![]() . Using only four-connected points (
. Using only four-connected points (![]() ,
, ![]() ) gives the city block distance. Closer approximation to the Euclidean distance is given with
) gives the city block distance. Closer approximation to the Euclidean distance is given with ![]() and
and ![]() . To maintain integer arithmetic, the best approximation for small integers is given with
. To maintain integer arithmetic, the best approximation for small integers is given with ![]() and
and ![]() , and dividing the result by three. Since the division by three is not easy in hardware, the result can either be left undivided, or using
, and dividing the result by three. Since the division by three is not easy in hardware, the result can either be left undivided, or using ![]() and
and ![]() , dividing the result by two (a right shift by one bit). The chamfer distance metric is given by:
, dividing the result by two (a right shift by one bit). The chamfer distance metric is given by:
(11.18) ![]()
A closer approximation to the Euclidean distance may be obtained by using a larger window size. A 5 × 5 window, with weights as shown in Figure 11.18, with ![]() ,
, ![]() and
and ![]() , gives the best approximation with small integer weights (Borgefors, 1986; Butt and Maragos, 1998). (Weights are not required for the blank spaces because these are multiples of smaller increments.)
, gives the best approximation with small integer weights (Borgefors, 1986; Butt and Maragos, 1998). (Weights are not required for the blank spaces because these are multiples of smaller increments.)
Figure 11.18 Masks for a 5 × 5 chamfer distance transform.
The two-pass chamfer distance algorithm may be adapted to measure Euclidean distance by propagating vectors ![]() instead of scalar distances. However, to correctly propagate the distance to all points requires three passes through the image (Danielsson, 1980; Ragnemalm, 1993; Bailey, 2004). The intermediate frame buffer also needs to be wider because it needs to store the vector. A further limitation is that because of the discrete nature of images, local propagation of vectors can leave some points with a small error relative (less than one pixel) to the Euclidean distance (Cuisenaire and Macq, 1999).
instead of scalar distances. However, to correctly propagate the distance to all points requires three passes through the image (Danielsson, 1980; Ragnemalm, 1993; Bailey, 2004). The intermediate frame buffer also needs to be wider because it needs to store the vector. A further limitation is that because of the discrete nature of images, local propagation of vectors can leave some points with a small error relative (less than one pixel) to the Euclidean distance (Cuisenaire and Macq, 1999).
The chamfer distance transform may be further accelerated by processing multiple lines in parallel (Trieu and Maruyama, 2006). This requires sufficient memory bandwidth to read data for several lines simultaneously. (Horizontal data packing is more usual, but by staggering the horizontal accesses and using short FIFOs, the same effect can be achieved.) The processor for each successive line must be offset, as shown in Figure 11.19, so that it is working with available data on the previous line. Depending on the frame buffer access pattern, short FIFOs may be required to delay the data for successive rows and to assemble the processed data for saving back to memory. Only the single row that overlaps between the strips needs to be cached in a row buffer. The same approach can also be applied to the reverse scan through the image.
Figure 11.19 Processing multiple lines in parallel with the chamfer distance.
11.5.3 Separable Transform
In most applications, the chamfer distance is sufficiently close to the Euclidean distance to be acceptable. If, however, the true Euclidean distance transform is required, it may be obtained by using a separable algorithm (Hirata, 1996; Maurer et al., 2003; Bailey, 2004). This relies on the fact that squaring Equation 11.13 gives:
which is separable. This allows the one-dimensional distance squared transform to be obtained of each row first, and then of each column of the result. The processing also only requires integer arithmetic, since ![]() and
and ![]() are integers. If the actual distance is required (rather than distance squared), then a square root operation may be pipelined on the output of the column processing. Since each row (and then column) is processed independently, the algorithm is readily parallelisable, and is also easily extendable to three or higher dimensional images.
are integers. If the actual distance is required (rather than distance squared), then a square root operation may be pipelined on the output of the column processing. Since each row (and then column) is processed independently, the algorithm is readily parallelisable, and is also easily extendable to three or higher dimensional images.
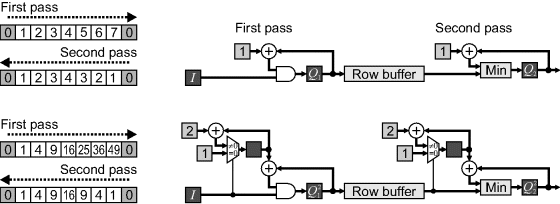
The first stage, processing along the rows, requires two passes, one in the forward direction and once in the reverse direction. The pass in the forward direction determines the distance from the left edge of the object and the reverse pass updates with the distance from the right edge. The processing for each of the two passes is:
(11.20) 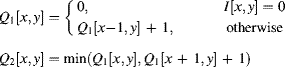
At the start of each pass ![]() and
and ![]() need to be initialised based on the boundary condition. If it is assumed that outside the image is background, they need to be initialised to zero, otherwise they need to be initialised to the maximum value. The circuit for implementing the scanning is given in Figure 11.20. Since the input, I, is binary, the multiplexer reduces to a set of AND gates. The addition of one in the feedback loop needs to be performed with saturation, especially if the outside of the image is considered to be object. Note that the data is read from the row buffer in reverse order during the second pass. Therefore, if directly processing streamed data, the row buffer needs to be able to hold two rows, or a pair of row buffers with bank switching can be used. Since the column processing stage requires the distances squared, these can be calculated directly using incremental processing techniques to avoid the multiplication (Section 5) as shown in the bottom of Figure 11.20.
need to be initialised based on the boundary condition. If it is assumed that outside the image is background, they need to be initialised to zero, otherwise they need to be initialised to the maximum value. The circuit for implementing the scanning is given in Figure 11.20. Since the input, I, is binary, the multiplexer reduces to a set of AND gates. The addition of one in the feedback loop needs to be performed with saturation, especially if the outside of the image is considered to be object. Note that the data is read from the row buffer in reverse order during the second pass. Therefore, if directly processing streamed data, the row buffer needs to be able to hold two rows, or a pair of row buffers with bank switching can be used. Since the column processing stage requires the distances squared, these can be calculated directly using incremental processing techniques to avoid the multiplication (Section 5) as shown in the bottom of Figure 11.20.
Figure 11.20 Row transform for the separable Euclidean distance transform. Top: performing the distance transform on each row; bottom: the distance squared transform using incremental update; left: example showing the result for a simple example.
The column processing is a little more complex. Finding the minimum distance at a point requires evaluating Equation 11.19 for each row and determining the minimum:
(11.21) ![]()
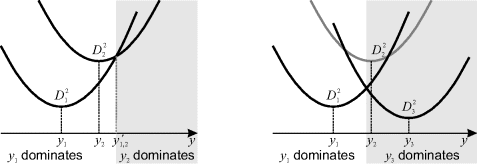
Rather than test every possible row within the column to find the minimum, it can be observed that the contributions from any two rows (say ![]() and
and ![]() ) are ordered. Let
) are ordered. Let ![]() and
and ![]() . Then, as shown in Figure 11.21, the distances from these two points divide the column into two at
. Then, as shown in Figure 11.21, the distances from these two points divide the column into two at ![]() where:
where:
(11.22) ![]()
Solving for the boundary of influence gives:
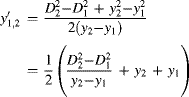
Figure 11.21 Regions of influence. Left: two rows on a column; (from Bailey, 2004) right: adding a third row that results in row y2 having no influence. (With kind permission from Springer Science+Business Media: Lecture Notes in Computer Science, “An efficient Euclidean distance transform”, 3322, © 2004, 394–408, D.G. Bailey, Figure 7).
The logic for implementing the column process calculating the distance transform is shown in Figure 11.22. The row number is used to read the row distance squared from the frame buffer. These are combined with the Previous values to give the boundary of influence using Equation 11.23. Note that the division only needs to be an integer division because the row numbers are only integers and it is only necessary to determine which two rows the boundary falls between. If the boundary is greater than that on the top of the stack (cached in the ![]() register) then the Previous values are pushed onto the stack, y is incremented and the next value read from memory. If less than or equal, then the Previous values have no influence, so the top of the stack is popped off into the Previous and
register) then the Previous values are pushed onto the stack, y is incremented and the next value read from memory. If less than or equal, then the Previous values have no influence, so the top of the stack is popped off into the Previous and ![]() registers and the comparison repeated.
registers and the comparison repeated.
Figure 11.22 Column transform for the separable Euclidean distance transform. Left: first pass determining the regions of influence; right: second pass, expanding the regions of influence to give the distance.
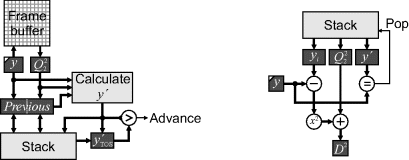
Although y is not necessarily incremented with every clock cycle, the number of clock cycles required for the first pass through the column is at most twice the number of rows. Therefore, to process one pixel per clock cycle, two such units must operate in parallel. The sporadic nature of frame buffer reads can be smoothed by reading from the frame buffer into a FIFO and accessing the distance values from the FIFO as necessary.
At the end of the first pass down the column, the stack contains a list of all of the regions of influence in order. It is then simply a case of treating the stack as a queue, with each section used to directly calculate the distance. When the end of the region of influence is reached, the next section is simply pulled from the queue until the bottom of the column is reached. The result is a streamed output image, with a vertical scan pattern rather than the conventional raster scan.
Row processing is actually the same operation as column processing. The simpler algorithm results from the prior distances all being zero for the background and infinite for the object. Therefore, the only pixels that have influence are the background points at each end of the groups of object pixels on a row, with the boundary of influence at the midpoint of each connected sets of pixels.
As described here, the row processing has a latency of two row lengths as a result of the combination of the forward and reverse pass. The latency may be reduced to one half a row time by also performing the second pass in the forward direction. During the first pass, the correct distance is generated for pixels up to the midpoint. Therefore, these do not need to be tested again. However, the midpoint is not determined until the first background pixel is reached at the end of the object. At this point, the second pass can go back to the midpoint and relabel the last half of the object, counting down rather than up.
The latency of processing a column, as described above, is two column times (the worst case time it takes for the first pass down the column). This may be reduced slightly by beginning the second pass through the image before the first pass has been completed.
The separability of the transform implies that all of the rows must be processed before beginning any of the columns. However, this is not necessarily the case. As with separable warping (Section 1), the two stages can be combined. Rather than process each column separately, they can be processed in parallel, with the stacks built in parallel as the data is streamed from the row processing. This is more complex with the distance transform because the volume of data required to hold the stacks would almost certainly require use of external memory. If the outside of the image can be considered background, the worst case latency would be just over half a frame, with conventional raster scanned input and output streams. The improved latency comes at the cost of more complex memory management. However, if outside the image is considered object, then it is necessary to process the complete frame in the worst case before any pixels can be output (for example if the only background pixel is in the bottom right corner in the image).
Since each row and each column are processed independently, an approach to accelerating the algorithm is by operating several processors in parallel. The main limitation to processing speed is governed by memory bandwidth for the input, intermediate storage and output streams.
11.5.4 Applications
The distance transform has a number of applications in image processing (Fabbri et al., 2008). One use is to derive features or shape descriptors of objects. Statistics of the distances within an object, such as mean and standard deviation, are effective size and shape measures. Ridges within the distance transform correspond to the medial axis or skeleton of the object (Arcelli and Di Baja, 1985). The distance to the medial axis is therefore half the width or thickness of the object at that point. Extending this further, local maxima correspond to centres of largest inscribed ‘circles’.
If objects within the image each have only a single local maximum in their distance transform, then the distance transform can be used to provide a count of the number of objects within the image even if adjacent objects are touching. This concept may be extended to the separation of touching objects through the watershed transform (see the next section).
Fast binary morphological filtering can be accomplished by thresholding the distance transformed image. Rather than perform several iterations with a small structuring element, the distance transform effectively performs these all in one step, with the thresholding selecting the particular iteration.
The distance transform can be used for robust template matching (Hezel et al., 2002) or shape matching (Arias-Estrada and Rodriguez-Palacios, 2002). The basic principle here is to compare the distance transformed images rather than simple binary images. This makes the matching less sensitive to small differences in shape, resulting for example from minor errors in segmentation.
11.5.5 Geodesic Distance Transform
A variation on the distance transform is the geodesic distance. The geodesic distance between two points within a region is defined as the shortest path between those two points that lies completely within the region. Any of the previously defined distance metrics may be used, but rather than measure the distance from the boundary, the distance from an arbitrary set of points is used. The previously described methods need to be modified to measure the geodesic distance.
Morphological methods use a series of constrained dilations beginning with the starting or seed pixels. The input is dilated from the seed pixels, with each iteration ANDed with the shape of the region to constrain the path to lie within the object. The distance from a seed point to an arbitrary point is the number of dilations required to include that point within the growing region.
Using larger conical structuring elements to perform multiple iterations in a single step does not work with this approach because a larger step may violate the constraint of remaining within the region.
The chamfer distance transform can also be used to calculate the geodesic distance. In general, two passes will not be sufficient for the distances to propagate around concavities in the region. The back and forth passes must be iterated until there is no further change.
Unfortunately, the constrained distance propagation cannot be easily achieved using stream processing. An approach that requires random access to the image can be built on a variation of Dijkstra's shortest path algorithm (Dijkstra, 1959). The seed pixels are marked within the image and are inserted into a FIFO queue. Then, pixels are extracted from the queue and their unmarked neighbours determined. These neighbours are marked with the incremented distance and their locations added to the end of the FIFO queue. The queue therefore implements a breadth-first search, which ensures that all pixels of one distance are processed and labelled before any of a greater distance. A Euclidean distance transform may be approximated by selecting four-neighbour or eight-neighbour propagation depending on the level. A potentially large FIFO queue is required to correctly process an arbitrary image. During the second phase, pixels are accessed in a random order. Searching for the unmarked neighbours requires multiple accesses to memory. An FPGA implementation of this algorithm was described by Trieu and Maruyama (2008).
Rather than use a FIFO queue, it is also possible to use chain codes as an intermediate step (Vincent, 1991). Propagating chain codes reduces the number of memory accesses because the location of unmarked pixels can come directly from the chain code, and only a single access is required to verify that the pixel is unmarked and apply the distance label.
One application of the geodesic distance is for navigation and path planning for robotics (Sudha and Mohan, 2008). The geodesic distance transform enables both obstacle avoidance and determining the shortest or lowest cost path from source to destination.
The watershed transform is closely related to connected components labelling. It considers the pixel values of an image as a topographical map and segments an image based on the topographical watersheds. There are two main approaches to determining the watersheds. The first is to consider a droplet of water falling on each pixel within the image. The droplet will flow downhill until it reaches a basin where it will stop. The image is segmented based on grouping together all of the pixels that flow into the same basin. The second approach reverses this process and starts with the basins, gradually raising the water level creating lakes of pixels associated with each basin. When two separate lakes meet, a barrier is built between them; this barrier is the watershed (Vincent and Soille, 1991).
11.6.1 Flow Algorithms
The first approach can be implemented in much the same way as connected components analysis (Bailey, 1991). The structure of the implementation is illustrated in Figure 11.23. The input stream of pixel values is augmented with an initial label of zero (unlabelled). With eight-connectivity, the neighbourhood must be extended to a 3 × 3 window to enable the direction of the minimum neighbour to be determined. If ambiguous, one of the neighbours can be chosen arbitrarily (or the gradient within the neighbourhood could be used to resolve the ambiguity; Bailey, 1991). If no pixels are less than the central pixel, it is a new local minimum (basin) and is assigned a label if it does not already have one. Otherwise a pixel is connected to its neighbourhood minimum. If neither is labelled, a new label is assigned to both pixels. If one is labelled, the label is propagated to the other pixel. If both are labelled, then a merger occurs; this is recorded in a merger table, in the same way as with connected components labelling.
Figure 11.23 Stream-based implementation of watershed segmentation.
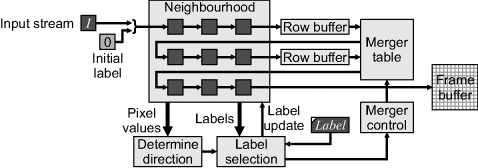
The merger table is a little more complicated than with connected component labelling, because potentially two accesses need to be made to update the labels emerging from the row buffer. This can be handled by running the merger table at twice the clock speed, or by using two parallel merger tables with identical entries. A further possibility is a lazy caching arrangement, where a label is translated only if necessary (if it is the centre pixel or the neighbourhood minimum).
If a labelled image is required, then two passes through the image are necessary. The first pass performs an initial labelling and determines the connectivity. The initial labels are then saved in a frame buffer, as shown in Figure 11.23, and the merger table used to provide a final consistently labelled image in the second pass. Alternatively, if the data for each region can be extracted in the first pass (as with single pass connected components analysis in Section 11.4), then the frame buffer is not required but can be replaced with a data table (Bailey, 1991).
One limitation of the above algorithm is that it does not divide plateaus which lie on a watershed evenly. Usually the whole of a plateau is assigned to a single label. Generally it is better to divide plateaus down the ‘middle’ with half being assigned to each watershed. This can be accomplished by distance transforming any plateaus, assigning pixels to the minimum that is the closest. This is a geodesic distance transform, which requires two or more passes through the image. This approach was taken by Trieu and Maruyama (Trieu and Maruyama, 2006; 2007), where multiple backward and forward scans are taken to calculate the geodesic distance transform of the plateaus where necessary. Because of the large volume of data that needs to be maintained, all of the data structures were kept in external memory. To accelerate their algorithm, they had multiple memory banks and processed multiple rows in parallel using the scheme introduced in Figure 11.19. This approach also has its own limitations; in particular, the number of back and forward scans through the image.
Trieu and Maruyama (Trieu and Maruyama, 2008) adapted the distance transform described in the previous section. The new scheme requires four processing phases. The first phase is a raster scan to identify the plateau boundaries with smaller pixel values. The locations of these boundary pixels are placed in a FIFO queue. In the second phase, the FIFO is used to propagate the boundary pixels distance transforming the plateaus. The third phase is another raster scan, which locates local minima and unlabelled plateaus, which must correspond to the basins. When a basin is found, the raster scan is suspended and the FIFO queue is used again to propagate the labels for each region (this is the fourth phase). Once the region is completed, the all pixels which drain into that basin have been segmented, so the raster scan of phase three is resumed.
11.6.2 Immersion Algorithms
The ‘traditional’ immersion approach to determining the watershed begins with the basins and increases the water level sequentially throughout the whole image, adding pixels to adjacent connected regions. This process considers the pixels within the image in strict pixel value order. Approached naïvely, this would require one pass through the image for each pixel value (requiring ![]() passes for an N-bit image). Since these successive passes through the image are in the same order, they can be pipelined, although this comes at the cost of one processor for each different pixel value within the image.
passes for an N-bit image). Since these successive passes through the image are in the same order, they can be pipelined, although this comes at the cost of one processor for each different pixel value within the image.
The alternative is to sort the pixels in the image into increasing order. Traditional sorting algorithms do not scale well with the size of the image, but, since the pixel values are discrete, fast methods that are linear with the number of pixels are possible. A bin sort can sort all of the pixels in a single pass through the image. This requires having ![]() bins. As the image is scanned, the coordinates of each pixel are added to the corresponding bin. Potentially, each bin could be the size of the image, although the total number in all of the bins is, of course, identical to the size of the image. The standard approach to avoid this overhead is to obtain a histogram of the image first, so that it is known in advance how many pixels occupy each bin. The cumulative histogram then gives the address in bin memory of the end of each bin. If the cumulative histogram is offset by one pixel value, so the count for pixel 0 is address 1, and so on, then the cumulative histogram will act as address translation for the incoming pixel values. As shown in Figure 11.24, the incoming pixel value is looked up in the cumulative histogram and used to store the pixel address in the bin memory. The bin memory address is incremented and written back to the cumulative histogram so that it will point to the next location. At the end of the image, the cumulative translation memory again contains the cumulative histogram and all of the pixels are sorted.
bins. As the image is scanned, the coordinates of each pixel are added to the corresponding bin. Potentially, each bin could be the size of the image, although the total number in all of the bins is, of course, identical to the size of the image. The standard approach to avoid this overhead is to obtain a histogram of the image first, so that it is known in advance how many pixels occupy each bin. The cumulative histogram then gives the address in bin memory of the end of each bin. If the cumulative histogram is offset by one pixel value, so the count for pixel 0 is address 1, and so on, then the cumulative histogram will act as address translation for the incoming pixel values. As shown in Figure 11.24, the incoming pixel value is looked up in the cumulative histogram and used to store the pixel address in the bin memory. The bin memory address is incremented and written back to the cumulative histogram so that it will point to the next location. At the end of the image, the cumulative translation memory again contains the cumulative histogram and all of the pixels are sorted.
Figure 11.24 Bin sort, using the cumulative histogram for bin addressing.
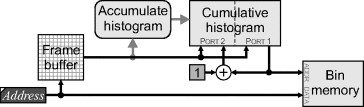
While the histogram-based bin sort is memory efficient, a disadvantage is that it requires two passes through the image. The first pass is to accumulate the histogram, which can be performed in parallel with the data being streamed into the frame buffer. The second pass does the actual pixel sorting. An alternative approach that avoids the need to pre-allocate the bin memory is to use an array of linked lists, one for each bin (De Smet, 2010). With a linked list, it is not necessary to know the bin size in advance.
A circuit for the construction of the linked lists is shown in Figure 11.25. Prior to processing the input stream, the entries in the Tail array need to be set to zero. (If the size of the input stream is not a power of two, they could be set to an invalid address after the end of the stream, for example all ones.) When the first pixel value of a particular value comes in, the corresponding Tail entry will be zero, so the pixel address stored in the corresponding Head entry. Otherwise the address is stored in the linked list at the entry pointed to by the Tail. In both cases, Tail is updated with the new address. If the Tail is initialised to zero, a little bit of additional logic is required to distinguish the case when a true zero address is written into the Tail register. This may be done as illustrated in Figure 11.25, or alternatively an additional bit could be added to the width of Tail to indicate this.
Figure 11.25 Bin sort using an array of linked lists.
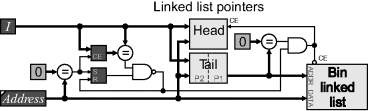
Since only one Head or Tail register is accessed at a time, they can be stored in either fabric RAM or block RAM. Head only needs to be single port, while Tail will need to be dual-port. The image addresses do not need to be stored explicitly because the linked list is structured such that the bin address corresponds to the image address. The pixel values also do not need to be saved within the bins because this is implicit with the linked list structure as each different pixel value has a separate linked list. However, since the neighbours need to be examined, this will require storing the image within a frame buffer. Construction of the linked list is easily parallelisable if memory bandwidth allows. Since bin addressing corresponds to image addressing, the image may be split vertically into a number of blocks, which are processed in parallel. At the end, it is then necessary to add the links between the blocks for each pixel value.
When performing the immersion, pixels are accessed in the order of pixel value from the sorted list or queue. Pixels are taken from the queue and added to the existing boundaries if an adjacent pixel has a lower level. The label is propagated from adjacent labelled pixels. If no smaller labelled pixels are in the neighbourhood, the pixels are added to a second queue to perform the geodesic distance transform of the plateau. Any unlabelled pixels remaining after this process are new basins, so are assigned a new label. An FPGA implementation of this process is described by Rambabu et al. (2002; Rambabu and Chakrabarti, 2007).
11.6.3 Applications
The primary use of the watershed transform is in segmentation. After applying an edge detection operator, the edges become ridges in the image which become the watersheds separating the regions. The watershed will tend to divide the image along the edges between regions. One limitation is that any noise within the image will create false edges, with consequent over-segmentation. This can be partially addressed by smoothing before segmentation and ignoring edges below a threshold height. When using the immersion method, the threshold may be implemented by allowing adjacent regions to join if the basin depth is less than the threshold below the current immersion level. This process is illustrated for a noisy image in Figure 11.26.
Figure 11.26 Watershed segmentation. Images from the left: original input image; Gaussian filtered with ![]() ; edge detection using the range within a 3 × 3 window; watershed segmentation merging adjacent regions with a threshold of five.
; edge detection using the range within a 3 × 3 window; watershed segmentation merging adjacent regions with a threshold of five.
Another application of the watershed transform is to separate touching objects, as illustrated in Figure 11.27. The basic principle is that convex objects (and some non-convex objects) will have a single peak when distance transformed. Therefore, if multiple objects are touching, then a blob will have multiple peaks within its distance transform. Inverting the distance transform will convert the peaks to basins, where the watershed transform will associate each pixel within a blob with the basin into which it flows. The one failure in Figure 11.27 is for the non-convex object, which has two peaks in its distance transform. Again, it is necessary to use a small threshold because with discrete images the distance transform can have small peaks along a diagonal ridge. However, when applying the watershed transform after a distance transform, there will be no plateaus. This can simplify the algorithm considerably.
Figure 11.27 Watershed segmentation for separating touching objects. Left: original image; centre: applying the 3,4 chamfer distance transform; right: original with watershed boundaries overlaid.

The watershed transform can be used in other applications where detecting peaks is of interest. One example of this is detecting the peaks following a Hough transform, described in the following section. Inverting the image will convert peaks to basins, allowing them to be individually labelled.
The Hough transform is a technique for detecting objects or features from detected edges within an image (Illingworth and Kittler, 1988; Leavers, 1993). While originally proposed for lines (Hough, 1962), it can readily be extended to any shape that can be parameterised. The basic idea behind the Hough transform is represented in Figure 11.28. Firstly, the image is processed to detect edges within the image. Each edge pixel then votes for all of the sets of parameters with which it is compatible, that is an object with those parameters would have an edge pixel at that point. This voting process is effectively accumulating a multidimensional histogram within parameter space. Sets of parameters which have a large number of votes have significant support for the corresponding objects within the image. Therefore, detecting peaks within parameter space determines potential objects within the image. Candidate objects can then be reconstructed from their parameters, and verified.
Figure 11.28 The principle behind using the Hough transform to detect objects.
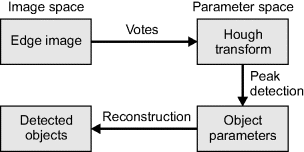
The idea of voting means that the complete object does not need to be present within the image. There only needs to be enough of the object to create a significant peak. The Hough transform therefore copes well with occlusion. Noise and other false edges with the image will vote for random sets of parameters, which will overall receive relatively little support. Therefore, the Hough transform is also insensitive to noise. This makes it a powerful technique for object or feature detection.
11.7.1 Line Hough Transform
Lines are arguably the simplest image feature, being described by only two parameters. The standard equation for a line is:
(11.24) ![]()
with parameters m and c. A detected edge point, ![]() will, therefore, vote for points along the line:
will, therefore, vote for points along the line:
in ![]() parameter space. Such a parameterisation is suitable for lines which are approximately horizontal, but vertical lines have large (potentially infinite) values of m and c. Such non-uniformity makes both vote recording and peak detection expensive and impractical. A more usual parameterisation of lines (Duda and Hart, 1972) is:
parameter space. Such a parameterisation is suitable for lines which are approximately horizontal, but vertical lines have large (potentially infinite) values of m and c. Such non-uniformity makes both vote recording and peak detection expensive and impractical. A more usual parameterisation of lines (Duda and Hart, 1972) is:
where ![]() is the angle of the line and
is the angle of the line and ![]() represents the closest distance between the line and the image origin. A point
represents the closest distance between the line and the image origin. A point ![]() votes for points along sinusoids in
votes for points along sinusoids in ![]() parameter space. This process is illustrated with an example in Figure 11.29.
parameter space. This process is illustrated with an example in Figure 11.29.
Figure 11.29 Using the Hough transform to detect the gridlines of a graph. From the left: input image; after thresholding and thinning the lines; Hough transform; detected gridlines overlaid on the original image.
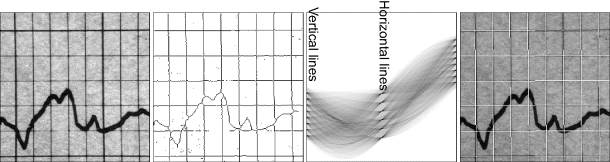
11.7.1.1 Parameter Calculation
The main problem with the Hough transform is its computational expense. This comes from two sources. The first is the calculation of the sine and cosine to determine the sets of parameters where each point votes. Normally ![]() is incremented from 0 to
is incremented from 0 to ![]() and the corresponding
and the corresponding ![]() calculated from Equation 11.26. Since the values of
calculated from Equation 11.26. Since the values of ![]() are fixed by the bin spacing, the values of
are fixed by the bin spacing, the values of ![]() and
and ![]() can be obtained from a lookup table. These then need to be multiplied by the detected pixel location, as shown in Figure 11.30. The size of the lookup tables can be reduced by a factor of four (for
can be obtained from a lookup table. These then need to be multiplied by the detected pixel location, as shown in Figure 11.30. The size of the lookup tables can be reduced by a factor of four (for ![]() in the range from 0 to
in the range from 0 to ![]() ) with a little extra logic and exploiting trigonometric identities (Cucchiara et al., 1998).
) with a little extra logic and exploiting trigonometric identities (Cucchiara et al., 1998).
Figure 11.30 Vote accumulator for line Hough transform.
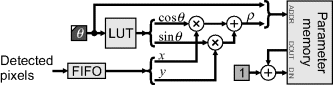
Mayasandra et al. (2005) used a bit-serial distributed arithmetic implementation that enabled the addition to be combined with the lookup table, with a shift and add accumulator to perform the multiplication. This significantly reduces the hardware at the cost of taking several clock cycles to calculate each point. (This was addressed by having multiple processors to calculate all angles in parallel.)
Lee and Evagelos (2008) used the architecture of Figure 11.30 using the logarithmic number system to avoid multiplications. They then converted from the logarithmic to standard binary for performing the final addition.
Alternatively, a CORDIC rotator of Equation 5.35 could be used to perform the whole computation of Equation 11.26. This option was used by Karabernou et al. (2005).
The parameter space could also be modified to simplify the calculation of the accumulator points. This is one of the advantages of the linear parameterisation of Equation 11.25, as incremental update can be used to calculate the intercepts for successive slopes. Tagzout et al. (2001) used a modified version of Equation 11.26 and used the small angle approximation of sine and cosine to enable incremental calculations to calculate the parameters for a series of angles. However, they still needed to reinitialise the calculation periodically, about every 10 degrees, to prevent accumulation of errors.
11.7.1.2 Vote Accumulation
The second problem with the Hough transform is the memory access bandwidth associated with incrementing the bins in parameter space as the votes are accumulated. Each detected pixel in the image votes for many bins within parameter space, with each vote requiring two accesses to memory (a read and a write). The parameter memory will usually be off-chip, which contributes to the bandwidth problem. If parameter space is coarsely quantised, then it may fit within distributed on-chip block RAMs. This would allow multiple bins to be updated in parallel, at the expense of multiple processors to calculate the line parameters.
The adaptive Hough transform reduces the memory requirements by performing the Hough transform in two or more passes (Illingworth and Kittler, 1987). The first pass uses a relatively coarse quantisation to find the significant peaks, but gives the parameters but with low accuracy. A second pass uses a higher resolution quantisation within those specific detected areas to refine the parameters. The adaptive approach significantly reduces both the total computational burden and the memory requirements, enabling it to be implemented with on-chip memory. Obviously the edge data needs to be buffered between passes.
The memory bandwidth issue may be addressed by not accumulating votes for every angle. Edge pixels are usually detected using an edge detection scheme that can also give the edge orientation. Knowing the edge orientation restricts the accumulation to a single angle (or small range of angles). Not only does this reduce the number of calculations, but it also reduces the clutter within parameter space, making peak detection more reliable. This approach has been used to accelerate FPGA implementations (Cucchiara et al., 1998; Karabernou et al., 2005).
Figure 11.30 also shows a FIFO buffer on the incoming detected pixel locations. Although the proportion of detected pixels is relatively low for normal images, these pixels tend to be clustered rather than evenly distributed. A FIFO buffer allows the Hough transform accumulation to run relatively independently of the pixel detection process.
11.7.1.3 Finding Peaks and Object Features
A single scan through the parameter space with a window is suitable for finding the peaks. A peak detection filter can be implemented with a small (3 × 3) window. If necessary, adjacent counts can be combined to give the centre of gravity of the peak with increased resolution. During the peak scan pass, it is also useful to clear the accumulator memory to prepare it for the next image. This is easy to do with dual-port on-chip memory, but is a little harder with off-chip memory.
While the location of a peak gives the parameters of the corresponding line, often this corresponds with only a line segment within the image. It is therefore necessary to search along the length of each line detected to find the start and end points. These extended operations are not discussed in many FPGA implementations. One exception is that of Nagata and Maruyama (2004). To give good processing throughput, the stages of edge detection, parameter accumulation, peak detection and line endpoint detection were pipelined.
11.7.2 Circle Hough Transform
Detecting circles (or circular arcs) within an image requires a parameterisation of the circle (Yuen et al., 1990). The commonly used parameterisation is in terms of the circle centre and radius ![]() :
:
(11.27) ![]()
With three parameters, the parameter space needs to be three-dimensional, with each detected point in the image voting for parameters on the surface of a cone. The increased dimensionality exacerbates the computational and bandwidth problems of the Hough transform.
Since two of the parameters relate directly to the position of the circle, the three-dimensional Hough transform may be recast as a three-dimensional convolution (Hollitt, 2009). The conventional approach of accumulating votes is equivalent to convolving the two-dimensional image of detected points with a three-dimensional conical surface. The convolution may be implemented in the frequency domain by taking the two-dimensional Fourier transform of the input image, multiplying it by the precalculated three-dimensional Fourier transform of the cone, and then calculating the inverse Fourier transform.
As with the line Hough transform, detecting the orientation of the edge helps to reduce the computational dimensionality. The direction of steepest gradient will point either towards or away from the centre of the circle. Rather than accumulate on the surface of a cone, this reduces to accumulating points along a ray in three-dimensional space. Incremental update can be used to simplify the calculation of successive points along this ray. The reduction in number of spurious points accumulated will also reduce the clutter within parameter space. However, small errors in estimating the edge orientation will mean that the peak is a little less focussed, particularly with larger radii.
However, the reduction in clutter allows a further reduction in dimensionality. Rather than draw the rays in three-dimensional space, the parameter space can be reduced to two dimensions by projecting along the radius axis (Bailey, 1992). A two-step process can then be used to determine the three parameters (Illingworth and Kittler, 1987; Davies, 1988); this is illustrated with an example in Figure 11.31. The first step is the two-dimensional projected Hough transform accumulating the rays towards the circle centre. These will reinforce at the circle centre, enabling two of the parameters to be determined. The radius may then be determined from a one-dimensional Hough transform (histogram) of the distances of each point from the detected centres.
Figure 11.31 Two-step circle Hough transform. Left: original image; centre top: two-dimensional transform to detect circle centres; right: radius histograms about the detected centres; centre bottom: detected circles overlaid on the original image.
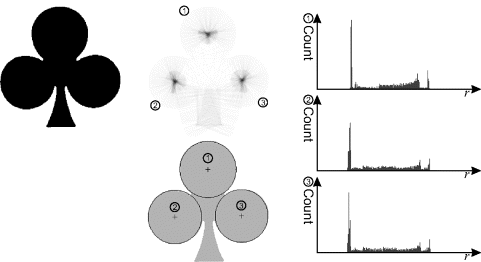
The two-pass approach requires that the list of detected points be buffered between passes. However, this is typically only a small fraction of the whole image, so may be stored efficiently (using chain codes is one possibility). Projecting the lines results in a fuzzy blob around the circle centres. When the peaks are found, these need to be smoothed (for example by calculating the centre of gravity) to obtain a better estimate of the peak location. In the second pass, several radius histograms may be accumulated in parallel, with the peak and the few radii on either side averaged to obtain the circle radius.
11.7.3 Generalised Hough Transform
The techniques described above can be generalised to arbitrarily shaped objects (Ballard, 1981). The object being detected is represented by a template, which is then parameterised by position and maybe also by scale and orientation. The generalised Hough transform is, therefore, a form of edge-based template matching.
Maruyama (2004) describes an FPGA implementation of a generalised Hough transform. The system was able to detect over 100 shapes per image using a two-stage process. The first stage uses reduced resolution (by a factor of 16 × 16) to locate and identify a shape approximately. The second stage uses full resolution, but focussed on the particular area and shape. This enabled frame rates between 13 and 26 frames per second for VGA resolution images (640 × 480).
Geninatti et al. (2009) used a variation of the generalised Hough transform to estimate the relative rotation between successive frames within a video sequence. To reduce the processing, only the DC components of MPEG compressed images were used, making the effective resolution 44 × 36 pixels.
The processing required for blob detection and labelling falls within the intermediate processing level within the image processing pyramid. The input is all in the form of image data, with the output in terms of segmented regions or even data extracted from those regions. While there are many possible algorithms for all of these operations, the primary focus in this chapter has been on stream processing. However, the non-local nature of labelling means that stream processing is not always possible.
The bounding box focuses purely on extracting size and shape information from each object based on simple pixel labelling. Consequently non-connected pixels are considered to belong to the same object if they have the same label. Full connected components labelling is required to take into consideration the connectivity. Producing a labelled image requires at least two passes, although if all of the required region data can be extracted in the first pass then the second pass is unnecessary.
Chain coding is an alternative region labelling approach, which defines regions by their boundaries, rather than explicitly associating pixels with regions. Chain coding can be accomplished in a single streamed pass, although this requires some quite complex memory management. Subsequent data extraction then works with the one-dimensional chains rather than the two-dimensional image.
Related intermediate level operations developed in this chapter were the distance transform, the watershed transform and the Hough transform. All can be used as part of segmentation or to extract data from an image. These require either multiple streamed passes through the image, or random access. (With the Hough transform, the random access is within parameter space.)
While other intermediate and high level image processing operations can also be implemented in hardware on an FPGA, these operations were selected as representative operations where significant benefits can be gained by exploiting parallelism. This does not mean that other image processing operations cannot be implemented in hardware. However, with many higher level operations, the processing often becomes data dependent. If implemented in hardware, separate hardware must be developed to handle each of the cases. As a result, the hardware is often sitting idle, waiting for the specific cases required to trigger its operation. There comes a point when the acceleration of the algorithm through hardware implementation becomes too expensive and complex relative to a software implementation.