
Chapter 9. Events
OpenCL commands move through queues executing kernels, manipulating memory objects, and moving them between devices and the host. A particularly simple style of OpenCL programming is to consider the program as a single queue of commands executing in order, with one command finishing before the next begins.
Often, however, a problem is best solved in terms of multiple queues. Or individual commands need to run concurrently, either to expose more concurrency or to overlap communication and computation. Or you just need to keep track of the timing of how the commands execute to understand the performance of your program. In each of these cases, a more detailed way to interact with OpenCL is needed. We address this issue within OpenCL through event objects.
In this chapter, we will explain OpenCL events and how to use them. We will discuss
• The basic event model in OpenCL
• The APIs to work with events
• User-defined events
• Profiling commands with events
Commands, Queues, and Events Overview
Command-queues are the core of OpenCL. A platform defines a context that contains one or more compute devices. For each compute device there is one or more command-queues. Commands submitted to these queues carry out the work of an OpenCL program.
In simple OpenCL programs, the commands submitted to a command-queue execute in order. One command completes before the next one begins, and the program unfolds as a strictly ordered sequence of commands. When individual commands contain large amounts of concurrency, this in-order approach delivers the performance an application requires.
Realistic applications, however, are usually not that simple. In most cases, applications do not require strict in-order execution of commands. Memory objects can move between a device and the host while other commands execute. Commands operating on disjoint memory objects can execute concurrently. In a typical application there is ample concurrency present from running commands at the same time. This concurrency can be exploited by the runtime system to increase the amount of parallelism that can be realized, resulting in significant performance improvements.
Another common situation is when the dependencies between commands can be expressed as a directed acyclic graph (DAG). Such graphs may include branches that are independent and can safely run concurrently. Forcing these commands to run in a serial order overconstrains the system. An out-of-order command-queue lets a system exploit concurrency between such commands, but there is much more concurrency that can be exploited. By running independent branches of the DAG on different command-queues potentially associated with different compute devices, large amounts of additional concurrency can be exploited.
The common theme in these examples is that the application has more opportunities for concurrency than the command-queues can expose. Relaxing these ordering constraints has potentially large performance advantages. These advantages, however, come at a cost. If the ordering semantics of the command-queue are not used to ensure a safe order of execution for commands, then the programmer must take on this responsibility. This is done with events in OpenCL.
An event is an object that communicates the status of commands in OpenCL. Commands in a command-queue generate events, and other commands can wait on these events before they execute. Users can create custom events to provide additional levels of control between the host and the compute devices. The event mechanism can be used to control the interaction between OpenCL and graphics standards such as OpenGL. And finally, inside kernels, events can be used to let programmers overlap data movement with operations on that data.
Events and Command-Queues
An OpenCL event is an object that conveys information about a command in OpenCL. The state of an event describes the status of the associated command. It can take one of the following values:
• CL_QUEUED: The command has been enqueued in the command-queue.
• CL_SUBMITTED: The enqueued command has been submitted by the host to the device associated with the command-queue.
• CL_RUNNING: The compute device is executing the command.
• CL_COMPLETE: The command has completed.
• ERROR_CODE: A negative value that indicates that some error condition has occurred. The actual values are the ones returned by the platform or runtime API that generated the event.
There are a number of ways to create events. The most common source of events is the commands themselves. Any command enqueued to a command-queue generates or waits for events. They appear in the API in the same way from one command to the next; hence we can use a single example to explain how events work. Consider the command to enqueue kernels for execution on a compute device:
cl_int clEnqueueNDRangeKernel (
cl_command_queue command_queue,
cl_kernel kernel,
cl_uint work_dim,
const size_t *global_work_offset,
const size_t *global_work_size,
const size_t *local_work_size,
cl_uint num_events_in_wait_list,
const cl_event *event_wait_list,
cl_event *event)
This should look familiar from earlier chapters in the book. For now, we are interested in only the last three arguments to this function:
• cl_uint num_events_in_wait_list: the number of events this command is waiting to complete before executing.
• const cl_event *event_wait_list: an array of pointers defining the list of num_events_in_wait_list events this command is waiting on. The context associated with events in event_wait_list and the command_queue must be the same.
• cl_event *event: a pointer to an event object generated by this command. This can be used by subsequent commands or the host to follow the status of this command.
When legitimate values are provided by the arguments num_events_in_wait_list and *event_wait_list, the command will not run until every event in the list has either a status of CL_COMPLETE or a negative value indicating an error condition.
The event is used to define a sequence point where two commands are brought to a known state within a program and hence serves as a synchronization point within OpenCL. As with any synchronization point in OpenCL, memory objects are brought to a well-defined state with respect to the execution of multiple kernels according to the OpenCL memory model. Memory objects are associated with a context, so this holds even when multiple command-queues within a single context are involved in a computation.
For example, consider the following simple example:
cl_event k_events[2];
// enqueue two kernels exposing events
err = clEnqueueNDRangeKernel(commands, kernel1, 1,
NULL, &global, &local, 0, NULL, &k_events[0]);
err = clEnqueueNDRangeKernel(commands, kernel2, 1,
NULL, &global, &local, 0, NULL, &k_events[1]);
// enqueue the next kernel .. which waits for two prior
// events before launching the kernel
err = clEnqueueNDRangeKernel(commands, kernel3, 1,
NULL, &global, &local, 2, k_events, NULL);
Three kernels are enqueued for execution. The first two clEnqueueNDRangeKernel commands enqueue kernel1 and kernel2. The final arguments for these commands generate events that are placed in the corresponding elements of the array k_events[]. The third clEnqueueNDRangeKernel command enqueues kernel3. As shown in the seventh and eighth arguments to clEnqueueNDRangeKernel, kernel3 will wait until both of the events in the array k_events[] have completed before the kernel will run. Note, however, that the final argument to enqueue kernel3 is NULL. This indicates that we don’t wish to generate an event for later commands to access.
When detailed control over the order in which commands execute is needed, events are critical. When such control is not needed, however, it is convenient for commands to ignore events (both use of events and generation of events). We can tell a command to ignore events using the following procedure:
1. Set the number of events the command is waiting for (num_events_in_wait_list) to 0.
2. Set the pointer to the array of events (*event_wait_list) to NULL. Note that if this is done, num_events_in_wait_list must be 0.
3. Set the pointer to the generated event (*event) to NULL.
This procedure ensures that no events will be waited on, and that no event will be generated, which of course means that it will not be possible for the application to query or queue a wait for this particular kernel execution instance.
When enqueuing commands, you often need to indicate a synchronization point where all commands prior to that point complete before any of the following commands start. You can do this for commands within a single queue using the clBarrier() function:
The single argument defines the queue to which the barrier applies. The command returns CL_SUCCESS if the function was executed successfully; otherwise it returns one of the following error conditions:
• CL_INVALID_COMMAND_QUEUE: The command-queue is not a valid command-queue.
• CL_OUT_OF_RESOURCES: There is a failure to allocate resources required by the OpenCL implementation on the device.
• CL_OUT_OF_HOST_MEMORY: There is a failure to allocate resources required by the OpenCL implementation on the host.
The clEnqueueBarrier command defines a synchronization point. This is important for understanding ordering constraints between commands. But more important, in the OpenCL memory model described in Chapter 1, consistency of memory objects is defined with respect to synchronization points. In particular, at a synchronization point, updates to memory objects visible across commands must be complete so that subsequent commands see the new values.
To define more general synchronization points, OpenCL uses events and markers. A marker is set with the following command:

The marker command is not completed until all commands enqueued before it have completed. For a single in-order queue, the effect of the clEnqueueMarker command is similar to a barrier. Unlike the barrier, however, the marker command returns an event. The host or other commands can wait on this event to ensure that all commands queued before the marker command have completed. clEnqueueMarker returns CL_SUCCESS if the function is successfully executed. Otherwise, it returns one of the following errors:
• CL_INVALID_COMMAND_QUEUE: The command_queue is not a valid command-queue.
• CL_INVALID_VALUE: The event is a NULL value.
• CL_OUT_OF_RESOURCES: There is a failure to allocate resources required by the OpenCL implementation on the device.
• CL_OUT_OF_HOST_MEMORY: There is a failure to allocate resources required by the OpenCL implementation on the host.
The following function enqueues a wait for a specific event or a list of events to complete before any future commands queued in the command-queue are executed:

These events define synchronization points. This means that when the clEnqueueWaitForEvents completes, updates to memory objects as defined in the memory model must complete, and subsequent commands can depend on a consistent state for the memory objects. The context associated with events in event_list and command_queue must be the same.
clEnqueueWaitForEvents returns CL_SUCCESS if the function was successfully executed. Otherwise, it returns one of the following errors:
• CL_INVALID_COMMAND_QUEUE: The command_queue is not a valid command-queue.
• CL_INVALID_CONTEXT: The context associated with command_queue and the events in event_list are not the same.
• CL_INVALID_VALUE: num_events is 0 or event_list is NULL.
• CL_INVALID_EVENT: The event objects specified in event_list are not valid events.
• CL_OUT_OF_RESOURCES: There is a failure to allocate resources required by the OpenCL implementation on the device.
• CL_OUT_OF_HOST_MEMORY: There is a failure to allocate resources required by the command.
The three commands clEnqueueBarrier, clEnqueueMarker, and clEnqueueWaitForEvents impose order constraints on commands in a queue and synchronization points that impact the consistency of the OpenCL memory. Together they provide essential building blocks for synchronization protocols in OpenCL.
For example, consider a pair of queues that share a context but direct commands to different compute devices. Memory objects can be shared between these two devices (because they share a context), but with OpenCL’s relaxed consistency memory model, at any given point shared memory objects may be in an ambiguous state relative to commands in one queue or the other. A barrier placed at a strategic point would address this problem and a programmer might attempt to do so with the clEnqueueBarrier() command, as shown in Figure 9.1.
Figure 9.1 A failed attempt to use the clEnqueueBarrier() command to establish a barrier between two command-queues. This doesn’t work because the barrier command in OpenCL applies only to the queue within which it is placed.
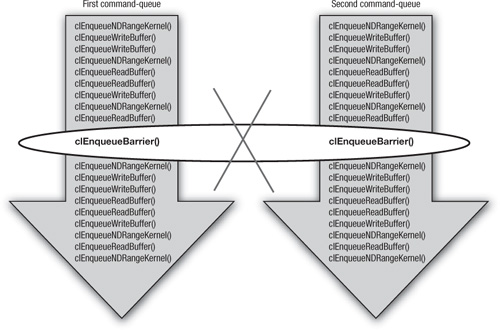
The barrier command in OpenCL, however, constrains the order of commands only for the command-queue to which it was enqueued. How does a programmer define a barrier that stretches across two command-queues? This is shown in Figure 9.2.
Figure 9.2 Creating a barrier between queues using clEnqueueMarker() to post the barrier in one queue with its exported event to connect to a clEnqueueWaitForEvent() function in the other queue. Because clEnqueueWaitForEvents() does not imply a barrier, it must be preceded by an explicit clEnqueueBarrier().
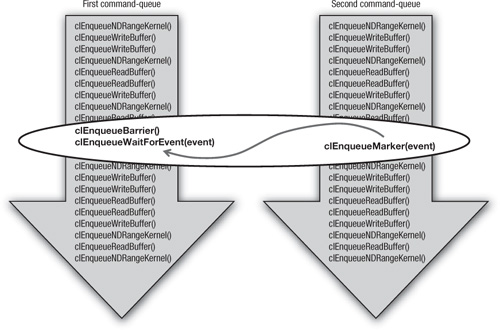
In one of the queues, a clEnqueueMarker() command is enqueued, returning a valid event object. The marker acts as a barrier to its own queue, but it also returns an event that can be waited on by other commands. In the second queue, we place a barrier in the desired location and follow the barrier with a call to clEnqueueWaitForEvents. The clEnqueueBarrier command will cause the desired behavior within its queue; that is, all commands prior to clEnqueueBarrier() must finish before any subsequent commands execute. The call to clEnqueueWaitForEvents() defines the connection to the marker from the other queue. The end result is a synchronization protocol that defines barrier functionality between a pair of queues.
Event Objects
Let’s take a closer look at the events themselves. Events are objects. As with any other objects in OpenCL, we define three functions to manage them:
• clGetEventInfo
• clRetainEvent
• clReleaseEvent
The following function increments the reference count for the indicated event object:
Note that any OpenCL command that returns an event implicitly invokes a retain function on the event.
clRetainEvent() returns CL_SUCCESS if the function is executed successfully. Otherwise, it returns one of the following errors:
• CL_INVALID_EVENT: The event is not a valid event object.
• CL_OUT_OF_RESOURCES: There is a failure to allocate resources required by the OpenCL implementation on the device.
• CL_OUT_OF_HOST_MEMORY: There is a failure to allocate resources required by the OpenCL implementation on the host.
To release an event, use the following function:
This function decrements the event reference count. clReleaseEvent returns CL_SUCCESS if the function is executed successfully. Otherwise, it returns one of the following errors:
• CL_INVALID_EVENT: The event is not a valid event object.
• CL_OUT_OF_RESOURCES: There is a failure to allocate resources required by the OpenCL implementation on the device.
• CL_OUT_OF_HOST_MEMORY: There is a failure to allocate resources required by the OpenCL implementation on the host.
Information about an event can be queried using the following function:

The clGetEventInfo function does not define a synchronization point. In other words, even if the function determines that a command identified by an event has finished execution (i.e., CL_EVENT_COMMAND_EXECUTION_STATUS returns CL_COMPLETE), there are no guarantees that memory objects modified by a command associated with the event will be visible to other enqueued commands.
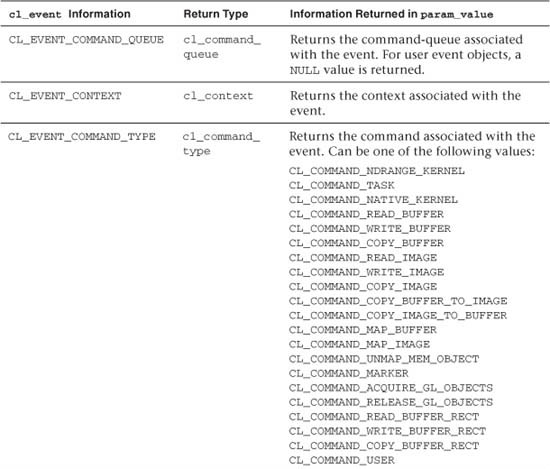
Table 9.1 Queries on Events Supported in clGetEventInfo()

Generating Events on the Host
Up to this point, events were generated by commands on a queue to influence other commands on queues within the same context. We can also use events to coordinate the interaction between commands running within an event queue and functions executing on the host. We begin by considering how events can be generated on the host. This is done by creating user events on the host:

The returned object is an event object with a value of CL_SUBMITTED. It is the same as the events generated by OpenCL commands, the only difference being that the user event is generated by and manipulated on the host.
The errcode_ret variable is set to CL_SUCCESS if the function completes and creates the user event without encountering an error. When an error is encountered, one of the following values is returned within errcode_ret:
• CL_INVALID_CONTEXT: The context is not a valid context.
• CL_OUT_OF_RESOURCES: There is a failure to allocate resources required by the OpenCL implementation on the device.
• CL_OUT_OF_HOST_MEMORY: There is a failure to allocate resources required by the OpenCL implementation on the host.
If clCreateUserEvent is called with the value of the variable errcode_ret set to NULL, error code information will not be returned.
With events generated on the command-queue, the status of the events is controlled by the command-queue. In the case of user events, however, the status of the events must be explicitly controlled through functions called on the host. This is done using the following function:

clSetUserEventStatus can be called only once to change the execution status of a user event to either CL_COMPLETE or to a negative integer value to indicate an error. A negative integer value causes all enqueued commands that wait on this user event to be terminated.
The function clSetUserEventStatus returns CL_SUCCESS if the function was executed successfully. Otherwise, it returns one of the following errors:
• CL_INVALID_EVENT: The event is not a valid user event object.
• CL_INVALID_VALUE: The execution_status is not CL_COMPLETE or a negative integer value.
• CL_INVALID_OPERATION: The execution_status for the event has already been changed by a previous call to clSetUserEventStatus.
• CL_OUT_OF_RESOURCES: There is a failure to allocate resources required by the OpenCL implementation on the device.
• CL_OUT_OF_HOST_MEMORY: There is a failure to allocate resources required by the OpenCL implementation on the host.
An example of how to use the clCreateUserEvent and clSetUserEventStatus functions will be provided later in this chapter, after a few additional concepts are introduced.
Events Impacting Execution on the Host
In the previous section, we discussed how the host can interact with the execution of commands through user-generated events. The converse is also needed, that is, execution on the host constrained by events generated by commands on the queue. This is done with the following function:

The function clWaitForEvents() does not return until the num_events event objects in event_list complete. By “complete” we mean each event has an execution status of CL_COMPLETE or an error occurred, in which case the execution status would have a negative value. Note that with respect to the OpenCL memory model, the events specified in event_list define synchronization points. This means that the status of memory objects relative to these synchronization points is well defined.
clWaitForEvents() returns CL_SUCCESS if the execution status of all events in event_list is CL_COMPLETE. Otherwise, it returns one of the following errors:
• CL_INVALID_VALUE: num_events is 0 or the event_list is NULL.
• CL_INVALID_CONTEXT: Events specified in event_list do not belong to the same context.
• CL_INVALID_EVENT: Event objects specified in event_list are not valid event objects.
• CL_EXEC_STATUS_ERROR_FOR_EVENTS_IN_WAIT_LIST: The execution status of any of the events in event_list is a negative integer value.
• CL_OUT_OF_RESOURCES: There is a failure to allocate resources required by the OpenCL implementation on the device.
• CL_OUT_OF_HOST_MEMORY: There is a failure to allocate resources required by the OpenCL implementation on the host.
Following is an excerpt from a program that demonstrates how to use the clWaitForEvents(), clCreateUserEvent(), and clSetUserEventStatus() functions:
cl_event k_events[2];
// Set up platform(s), two contexts, devices and two command-queues.
Comm1 = clCreateCommandQueue(context1, device_id1,
CL_QUEUE_OUT_OF_ORDER_EXEC_MODE_ENABLE, &err);
Comm2 = clCreateCommandQueue(context2, device_id2,
CL_QUEUE_OUT_OF_ORDER_EXEC_MODE_ENABLE, &err);
// Set up user event to be used as an execution trigger
cl_event uevent = clCreateUserEvent(context2, &err);
// Set up memory objs, programs, kernels and enqueue a DAG spanning
// two command-queues (only the last few "enqueues" are shown).
err = clEnqueueNDRangeKernel(Comm1, kernel1, 1, NULL, &global,
&local,0, NULL, &k_events[1]);
err = clEnqueueNDRangeKernel(Comm1, kernel2, 1, NULL, &global,
&local, 0, NULL, &k_events[2]);
// this command depends on commands in a different context so
// the host must mitigate between queues with a user event
err = clEnqueueNDRangeKernel(Comm2, kernel3, 1, NULL, &global,
&local, 1, uevent, NULL);
// Host waits for commands to complete from Comm1 before triggering
// the command in queue Comm2
err = clWaitForEvents(2, &k_events);
err = clSetUserEventStatus(uevent, CL_SUCCESS);
Events are the mechanism in OpenCL to specify explicit order constraints on commands. Events, however, cannot cross between contexts. When crossing context boundaries, the only option is for the host program to wait on events from one context and then use a user event to trigger the execution of commands in the second context. This is the situation found in this example code excerpt. The host program enqueues commands to two queues, each of which resides in a different context. For the command in the second context (context2) the host sets up a user event as a trigger; that is, the command will wait on the user event before it will execute. The host waits on events from the first context (in queue Comm1) using clWaitForEvents(). Once those events have completed, the host uses a call to the function clSetUserEventStatus() to set the user event status to CL_COMPLETE and the command in Comm2 executes. In other words, because events cannot cross between contexts, the host must manage events between the two contexts on behalf of the two command-queues.
Events can also interact with functions on the host through the callback mechanism defined in OpenCL 1.1. Callbacks are functions invoked asynchronously on behalf of the application. A programmer can associate a callback with an arbitrary event using this function:


The clSetEventCallback function registers a user callback function that will be called when a specific event switches to the event state defined by command_exec_callback_type (currently restricted to CL_COMPLETE). It is important to understand that the order of callback function execution is not defined. In other words, if multiple callbacks have been registered for a single event, once the event switches its status to CL_COMPLETE, the registered callback functions can execute in any order.
clSetEventCallback returns CL_SUCCESS if the function is executed successfully. Otherwise, it returns one of the following errors:
• CL_INVALID_EVENT: The event is not a valid event object.
• CL_INVALID_VALUE: The pfn_event_notify is NULL or the command_exec_callback_type is not CL_COMPLETE.
• CL_OUT_OF_RESOURCES: The system is unable to allocate resources required by the OpenCL implementation on the device.
• CL_OUT_OF_HOST_MEMORY: The system is unable to allocate resources required by the OpenCL implementation on the host.
A programmer must be careful when designing the functions used with the callback mechanism. The OpenCL specification asserts that all callbacks registered for an event object must be called before an event object can be destroyed. The ideal callback function should return promptly and must not call any functions that could cause a blocking condition. The behavior of calling expensive system routines, calling OpenCL API to create contexts or command-queues, or blocking OpenCL operations from the following list is undefined in a callback:
• clFinish
• clWaitForEvents
• Blocking calls to
• clEnqueueReadBuffer
• clEnqueueReadBufferRect
• clEnqueueWriteBuffer
• clEnqueueWriteBufferRect
• clEnqueueReadImage
• clEnqueueWriteImage
• clEnqueueMapBuffer
• clBuildProgram
Rather than calling these functions inside a callback, an application should use the non-blocking forms of the function and assign a completion callback to it to do the remainder of the work. Note that when a callback (or other code) enqueues commands to a command-queue, the commands are not required to begin execution until the queue is flushed. In standard usage, blocking enqueue calls serve this role by implicitly flushing the queue. Because blocking calls are not permitted in callbacks, those callbacks that enqueue commands on a command-queue should either call clFlush on the queue before returning or arrange for clFlush to be called later on another thread.
An example of using callbacks with events will be provided later in this chapter, after the event profiling interface has been described.
Using Events for Profiling
Performance analysis is part of any serious programming effort. This is a challenge when a wide range of platforms are supported by a body of software. Each system is likely to have its own performance analysis tools or, worse, may lack them all together. Hence, the OpenCL specification defines a mechanism to use events to collect profiling data on commands as they move through a command-queue. The specific functions that can be profiled are
• clEnqueue{Read|Write|Map}Buffer
• clEnqueue{Read|Write}BufferRect
• clEnqueue{Read|Write|Map}Image
• clEnqueueUnmapMemObject
• clEnqueueCopyBuffer
• clEnqueueCopyBufferRect
• clEnqueueCopyImage
• clEnqueueCopyImageToBuffer
• clEnqueueCopyBufferToImage
• clEnqueueNDRangeKernel
• clEnqueueNativeKernel
• clEnqueueAcquireGLObjects
• clEnqueueReleaseGLObjects
Profiling turns the event into an opaque object to hold timing data. This functionality is enabled when a queue is created when the CL_QUEUE_PROFILING_ENABLE flag is set. If profiling is enabled, the following function is used to extract the timing data:

The profiling data (as unsigned 64-bit values) provides time in nanoseconds since some fixed point (relative to the execution of a single application). By comparing differences between ordered events, elapsed times can be measured. The timers essentially expose incremental counters on compute devices. These are converted to nanoseconds by an OpenCL implementation that is required to correctly account for changes in device frequency. The resolution of a timer can be found as the value of the constant CL_DEVICE_PROFILING_TIMER_RESOLUTION, which essentially defines how many nanoseconds elapse between updates to a device counter.
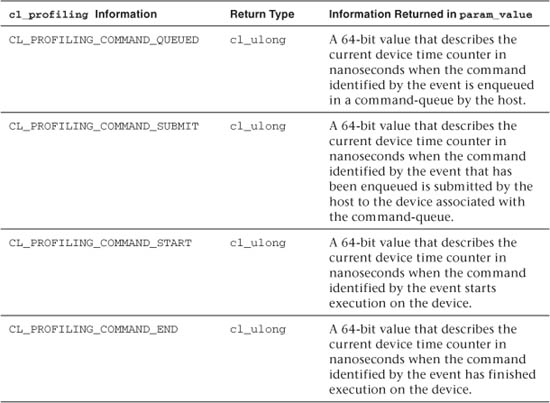
Table 9.2 Profiling Information and Return Types
The clGetEventProfilingInfo() function returns CL_SUCCESS if the function is executed successfully and the profiling information has been recorded. Otherwise, it returns one of the following errors:
• CL_PROFILING_INFO_NOT_AVAILABLE: This value indicates one of three conditions: the CL_QUEUE_PROFILING_ENABLE flag is not set for the command-queue, the execution status of the command identified by the event is not CL_COMPLETE, or the event is a user event object and hence not enabled for profiling.
• CL_INVALID_VALUE: The param_name is not valid, or the size in bytes specified by param_value_size is less than the size of the return type as described in Table 9.2 and param_value is not NULL.
• CL_INVALID_EVENT: The event is a not a valid event object.
• CL_OUT_OF_RESOURCES: There is a failure to allocate resources required by the OpenCL implementation on the device.
• CL_OUT_OF_HOST_MEMORY: There is a failure to allocate resources required by the OpenCL implementation on the host.
An example of the profiling interface is shown here:
// set up platform, context, and devices (not shown)
// Create a command-queue with profiling enabled
cl_command_queue commands = clCreateCommandQueue(context,
device_id, CL_QUEUE_PROFILING_ENABLE, &err);
// set up program, kernel, memory objects (not shown)
cl_event prof_event;
err = clEnqueueNDRangeKernel(commands, kernel, nd,
NULL, global, NULL, 0, NULL, prof_event);
clFinish(commands);
err = clWaitForEvents(1, &prof_event );
cl_ulong ev_start_time=(cl_ulong)0;
cl_ulong ev_end_time=(cl_ulong)0;
size_t return_bytes;
err = clGetEventProfilingInfo(prof_event,
CL_PROFILING_COMMAND_QUEUED,sizeof(cl_ulong),
&ev_start_time, &return_bytes);
err = clGetEventProfilingInfo(prof_event,
CL_PROFILING_COMMAND_END, sizeof(cl_ulong),
&ev_end_time, &return_bytes);
run_time =(double)(ev_end_time - ev_start_time);
printf("
profile data %f secs
",run_time*1.0e-9);
We have omitted the details of setting up the platform, context, devices, memory objects, and other parts of the program other than code associated with the profiling interface. First, note how we created the command-queue with the profiling interface enabled. No changes were made to how the kernel was run. After the kernel was finished (as verified with the call to clFinish()), we waited for the event to complete before probing the events for profiling data. We made two calls to clGetEventProfilingInfo(): the first to note the time the kernel was enqueued, and the second to note the time the kernel completed execution. The difference between these two values defined the time for the kernel’s execution in nanoseconds, which for convenience we converted to seconds before printing.
When multiple kernels are profiled, the host code can become seriously cluttered with the calls to the profiling functions. One way to reduce the clutter and create cleaner code is to place the profiling functions inside a callback function. This approach is shown here in a host program fragment:
#include "mult.h"
#include "kernels.h"
void CL_CALLBACK eventCallback(cl_event ev, cl_int event_status,
void * user_data)
{
int err, evID = (int)user_data;
cl_ulong ev_start_time=(cl_ulong)0;
cl_ulong ev_end_time=(cl_ulong)0;
size_t return_bytes; double run_time;
printf(" Event callback %d %d ",(int)event_status, evID);
err = clGetEventProfilingInfo( ev, CL_PROFILING_COMMAND_QUEUED,
sizeof(cl_ulong), &ev_start_time, &return_bytes);
err = clGetEventProfilingInfo( ev, CL_PROFILING_COMMAND_END,
sizeof(cl_ulong), &ev_end_time, &return_bytes);
run_time = (double)(ev_end_time - ev_start_time);
printf("
kernel runtime %f secs
",run_time*1.0e-9);
}
//------------------------------------------------------------------
int main(int argc, char **argv)
{
// Declarations and platform definitions that are not shown.
commands = clCreateCommandQueue(context, device_id,
CL_QUEUE_PROFILING_ENABLE, &err);
cl_event prof_event;
//event to trigger the DAG
cl_event uevent = clCreateUserEvent(context, &err);
// Set up the DAG of commands and profiling callbacks
err = clEnqueueNDRangeKernel(commands, kernel, nd, NULL, global,
NULL, 1, &uevent, &prof_event);
int ID=0;
err = clSetEventCallback (prof_event, CL_COMPLETE,
&eventCallback,(void *)ID);
// Once the DAG of commands is set up (we showed only one)
// trigger the DAG using prof_event to profile execution
// of the DAG
err = clSetUserEventStatus(uevent, CL_SUCCESS);
The first argument to the callback function is the associated event. Assuming the command-queue is created with profiling enabled (by using CL_PROFILING_COMMAND_QUEUED in the call to clGetEventProfilingInfo()), the events can be queried to generate profiling data. The user data argument provides an integer tag that can be used to match profiling output to the associated kernels.
Events Inside Kernels
Up to this point, events were associated with commands on a command-queue. They synchronize commands and help provide fine-grained control over the interaction between commands and the host. Events also appear inside a kernel. As described in Chapter 5, events are used inside kernels to support asynchronous copying of data between global and local memory. The functions that support this functionality are listed here:
• event_t async_work_group_copy()
• event_t async_work_group_strided_copy()
• void wait_group_events()
The details of these functions are left to Chapter 5. Here we are interested in how they interact with events inside a kernel.
To understand this functionality, consider the following example:
event_t ev_cp = async_work_group_copy(
(__local float*) Bwrk, (__global float*) B,
(size_t) Pdim, (event_t) 0);
for(k=0;k<Pdim;k++)
Awrk[k] = A[i*Ndim+k];
wait_group_events(1, &ev_cp);
for(k=0, tmp= 0.0;k<Pdim;k++)
tmp += Awrk[k] * Bwrk[k];
C[i*Ndim+j] = tmp;
This code is taken from a kernel that multiplies two matrices, A and B, to produce a third matrix, C. Each work-item generates a full row of the C matrix. To minimize data movement between global memory and local or private memory, we copy rows and columns of B out of global memory before proceeding. It might be possible for some systems to carry out these data movement operations concurrently. So we post an asynchronous copy of a column of B from global into local memory (so all work times can use the same column) followed by a copy of a row of A into private memory (where a single work-item will use it over and over again as each element of the product matrix C is computed).
For this approach to work, the for loop that multiplies rows of A with columns of B must wait until the asynchronous copy has completed. This is accomplished through events. The async_work_group_copy() function returns an event. The kernel then waits until that event is complete, using the call to wait_group_events() before proceeding with the multiplication itself.
Events from Outside OpenCL
As we have seen in this chapter, OpenCL supports detailed control of how commands execute through events. OpenCL events let a programmer define custom synchronization protocols that go beyond global synchronization operations (such as barriers). Therefore, anything that can be represented as commands in a queue should ideally expose an events interface.
The OpenCL specification includes an interface between OpenCL and OpenGL. A programmer can construct a system with OpenCL and then turn it over to OpenGL to create and display the final image. Synchronization between the two APIs is typically handled implicitly. In other words, the commands that connect OpenCL and OpenGL are defined so that in the most common situations where synchronization is needed, it happens automatically.
There are cases, however, when more detailed control over synchronization between OpenGL and OpenCL is needed. This is handled through an optional extension to OpenCL that defines ways to connect OpenCL events to OpenGL synchronization objects. This extension is discussed in detail in Chapter 10.