
Chapter 10. Interoperability with OpenGL
This chapter explores how to achieve interoperation between OpenCL and OpenGL (known as OpenGL interop). OpenGL interop is a powerful feature that allows programs to share data between OpenGL and OpenCL. Some possible applications for OpenGL include using OpenCL to postprocess images generated by OpenGL, or using OpenCL to compute effects displayed by OpenGL. This chapter covers the following concepts:
• Querying the OpenCL platform for GL sharing capabilities
• Creating contexts and associating devices for OpenGL sharing
• Creating buffers from GL memory and the corresponding synchronization and memory management defined by this implied environment
OpenCL/OpenGL Sharing Overview
We begin this chapter with a brief overview of OpenCL/OpenGL sharing. At a high level, OpenGL interoperability is achieved by creating an OpenGL context, then finding an OpenCL platform that supports OpenGL buffer sharing. The program then creates a context for that platform. Buffers are allocated in the OpenGL context and can be accessed in OpenCL by a few special OpenCL calls implemented in the OpenCL/OpenGL Sharing API.
When GL sharing is present, applications can use OpenGL buffer, texture, and renderbuffer objects as OpenCL memory objects. OpenCL memory objects can be created from OpenGL objects using the clCreateFromGL*() functions. This chapter will discuss these sharing functions as well as function calls that allow for acquiring, releasing, and synchronizing objects. Each step will be described in detail, and a full OpenCL/OpenGL interop example is included in the code for this chapter.
Querying for the OpenGL Sharing Extension
A device can be queried to determine if it supports OpenGL sharing via the presence of the cl_khr_gl_sharing extension name in the string for the CL_DEVICE_EXTENSIONS property returned by querying clGetDeviceInfo().
Recall from Table 3.3 that clGetDeviceInfo() can return the following information:

The string we are interested in seeing is cl_khr_gl_sharing. The query will return a string upon which we can do some basic string handling to detect the presence of cl_khr_gl_sharing. For some valid device cdDevices[i], we first query the size of the string that is to be returned:
size_t extensionSize;
ciErrNum = clGetDeviceInfo(cdDevices[i], CL_DEVICE_EXTENSIONS, 0,
NULL, &extensionSize );
Assuming this call succeeds, we can query again to get the actual extensions string:
char* extensions = (char*)malloc(extensionSize);
ciErrNum = clGetDeviceInfo(cdDevices[i], CL_DEVICE_EXTENSIONS,
extensionSize, extensions, &extensionSize);
Here we have simply allocated the character array extensions of the appropriate length to hold the returned string. We then repeated the query, giving it this time the pointer to the allocated memory that is filled with the extensions string when clGetDeviceInfo() returns.
Any familiar method of string comparsion that checks for the presence of the cl_khr_gl_sharing string inside the extensions character array will work. Note that the strings are delimited by spaces. One way of parsing the string and searching for cl_khr_gl_sharing using the std::string object is as follows:
#define GL_SHARING_EXTENSION "cl_khr_gl_sharing"
std::string stdDevString(extensions);
free(extensions);
size_t szOldPos = 0;
size_t szSpacePos = stdDevString.find(' ', szOldPos);
// extensions string is space delimited
while (szSpacePos != stdDevString.npos)
{
if( strcmp(GL_SHARING_EXTENSION, stdDevString.substr(szOldPos, szSpacePos - szOldPos).c_str()) == 0 )
{
// Device supports context sharing with OpenGL
uiDeviceUsed = i;
bSharingSupported = true;
break;
}
do {
szOldPos = szSpacePos + 1;
szSpacePos = stdDevString.find(' ', szOldPos);
}
while (szSpacePos == szOldPos);
}
Initializing an OpenCL Context for OpenGL Interoperability
Once a platform that will support OpenGL interoperability has been identified and confirmed, the OpenCL context can be created. The OpenGL context that is to be shared should be initialized and current. When creating the contexts, the cl_context_properties fields need to be set according to the GL context to be shared with. While the exact calls vary between operating systems, the concept remains the same.
On the Apple platform, the properties can be set as follows:
cl_context_properties props[] =
{
CL_CONTEXT_PROPERTY_USE_CGL_SHAREGROUP_APPLE,
(cl_context_properties)kCGLShareGroup,
0
};
cxGPUContext = clCreateContext(props, 0,0, NULL, NULL, &ciErrNum);
On Linux platforms, the properties can be set as follows:
cl_context_properties props[] =
{
CL_GL_CONTEXT_KHR,
(cl_context_properties)glXGetCurrentContext(),
CL_GLX_DISPLAY_KHR,
(cl_context_properties)glXGetCurrentDisplay(),
CL_CONTEXT_PLATFORM,
(cl_context_properties)cpPlatform,
0
};
cxGPUContext = clCreateContext(props, 1, &cdDevices[uiDeviceUsed],
NULL, NULL, &ciErrNum);
On the Windows platform, the properties can be set as follows:
cl_context_properties props[] =
{
CL_GL_CONTEXT_KHR,
(cl_context_properties)wglGetCurrentContext(),
CL_WGL_HDC_KHR,
(cl_context_properties)wglGetCurrentDC(),
CL_CONTEXT_PLATFORM,
(cl_context_properties)cpPlatform,
0
};
cxGPUContext = clCreateContext(props, 1, &cdDevices[uiDeviceUsed],
NULL, NULL, &ciErrNum);
In these examples both Linux and Windows have used operating-system-specific calls to retrieve the current display and contexts. To include these calls in your application you’ll need to include system-specific header files such as windows.h on the Windows platform. In all cases, the appropriately constructed cl_context_properties structure is passed to the clCreateContext(), which creates a context that is capable of sharing with the GL context.
The remaining tasks for creating an OpenCL program, such as creating the command-queue, loading and creating the program from source, and creating kernels, remain unchanged from previous chapters. However, now that we have a context that can share with OpenGL, instead of creating buffers in OpenCL, we can use buffers that have been created in OpenGL.
Creating OpenCL Buffers from OpenGL Buffers
Properly initialized, an OpenCL context can share memory with OpenGL. For example, instead of the memory being created by clCreateBuffer inside OpenCL, an OpenCL buffer object can be created from an existing OpenGL object. In this case, the OpenCL buffer can be initialized from an existing OpenGL buffer with the following command:
This command creates an OpenCL buffer object from an OpenGL buffer object.
The size of the GL buffer object data store at the time clCreateFromGLBuffer() is called will be used as the size of the buffer object returned by clCreateFromGLBuffer(). If the state of a GL buffer object is modified through the GL API (e.g., glBufferData()) while there exists a corresponding CL buffer object, subsequent use of the CL buffer object will result in undefined behavior.
The clRetainMemObject() and clReleaseMemObject() functions can be used to retain and release the buffer object.
To demonstrate how you might initialize a buffer in OpenGL and bind it in OpenCL using clCreateFromGLBuffer(), the following code creates a vertex buffer in OpenGL. A vertex buffer object (VBO) is a buffer of data that is designated to hold vertex data.
GLuint initVBO( int vbolen )
{
GLint bsize;
GLuint vbo_buffer;
glGenBuffers(1, &vbo_buffer);
glBindBuffer(GL_ARRAY_BUFFER, vbo_buffer);
// create the buffer; this basically sets/allocates the size
glBufferData(GL_ARRAY_BUFFER, vbolen *sizeof(float)*4,
NULL, GL_STREAM_DRAW);
// recheck the size of the created buffer to make sure
//it's what we requested
glGetBufferParameteriv(GL_ARRAY_BUFFER,
GL_BUFFER_SIZE, &bsize);
if ((GLuint)bsize != (vbolen*sizeof(float)*4)) {
printf(
"Vertex Buffer object (%d) has incorrect size (%d).
",
(unsigned)vbo_buffer, (unsigned)bsize);
}
// we're done, so unbind the buffers
glBindBuffer(GL_ARRAY_BUFFER, 0);
return vbo_buffer;
}
Then, we can simply call this function to create a vertex buffer object and get its GLuint handle as follows:
GLuint vbo = initVBO( 640, 480 );
This handle, vbo, can then be used in the clCreateFromGLBuffer() call:
cl_vbo_mem = clCreateFromGLBuffer(context,CL_MEM_READ_WRITE,
vbo,&err );
The resulting OpenCL memory object, vbo_cl_mem, is a memory object that references the memory allocated in the GL vertex buffer. In the preceding example call, we have marked that vbo_cl_mem is both readable and writable, giving read and write access to the OpenGL vertex buffer. OpenCL kernels that operate on vbo_cl_mem will be operating on the contents of the vertex buffer. Note that creating OpenCL memory objects from OpenGL objects using the functions clCreateFromGLBuffer(), clCreateFromGLTexture2D(), clCreateFromGLTexture3D(), or clCreateFromGLRenderbuffer() ensures that the underlying storage of that OpenGL object will not be deleted while the corresponding OpenCL memory object still exists.
Objects created from OpenGL objects need to be acquired before they can be used by OpenCL commands. They must be acquired by an OpenCL context and can then be used by all command-queues associated with that OpenCL context. The OpenCL command clEnqueueAcquireGLObjects() is used for this purpose:
These objects need to be acquired before they can be used by any OpenCL commands queued to a command-queue. The OpenGL objects are acquired by the OpenCL context associated with command_queue and can therefore be used by all command-queues associated with the OpenCL context.
A similar function, clEnqueueReleaseGLObjects(), exists for releasing objects acquired by OpenCL:
These objects need to be acquired before they can be used by any OpenCL commands queued to a command-queue. The OpenGL objects are acquired by the OpenCL context associated with command_queue and can therefore be used by all command-queues associated with the OpenCL context.
Note that before acquiring an OpenGL object, the program should ensure that any OpenGL commands that might affect the VBO have completed. One way of achieving this manually is to call glFinish() before clEnqueueAcquireGLObjects(). Similarly, when releasing the GL object, the program should ensure that all OpenCL commands that might affect the GL object are completed before it is used by OpenGL. This can be achieved by calling clFinish() on the command-queue associated with the acquire/process/release of the object, after the clEnqueueReleaseGLObjects() call.
In the case that the cl_khr_gl_event extension is enabled in OpenCL, then both clEnqueueAcquireGLObjects() and clEnqueueReleaseGLObjects() will perform implicit synchronization. More details on this and other synchronization methods are given in the “Synchronization between OpenGL and OpenCL” section later in this chapter.
Continuing our vertex buffer example, we can draw a sine wave by filling the vertex array with line endpoints. If we consider the array as holding start and end vertex positions, such as those used when drawing GL_LINES, then we can fill the array with this simple kernel:
__kernel void init_vbo_kernel(__global float4 *vbo,
int w, int h, int seq)
{
int gid = get_global_id(0);
float4 linepts;
float f = 1.0f;
float a = (float)h/4.0f;
float b = w/2.0f;
linepts.x = gid;
linepts.y = b + a*sin(3.14*2.0*((float)gid/(float)w*f +
(float)seq/(float)w));
linepts.z = gid+1.0f;
linepts.w = b + a*sin(3.14*2.0*((float)(gid+1.0f)/(float)w*f +
(float)seq/(float)w));
vbo[gid] = linepts;
}
Here we have taken into account the width and height of the viewing area given by w and h and filled in the buffer with coordinates that agree with a typical raster coordinate system within the window. Of course, with OpenGL we could work in another coordinate system (say, a normalized coordinate system) inside our kernel and set the viewing geometry appropriately as another option. Here we simply work within a 2D orthogonal pixel-based viewing system to simplify the projection matrices for the sake of discussion. The final parameter, seq, is a sequence number updated every frame that shifts the phase of the sine wave generated in order to create an animation effect.
The OpenCL buffer object returned by clCreateFromGLBuffer() is passed to the kernel as a typical OpenCL memory object:
clSetKernelArg(kernel, 0, sizeof(cl_mem), &cl_vbo_mem);
Note that we have chosen to index the buffer using a float4 type. In this case each work-item is responsible for processing a start/end pair of vertices and writing those to the OpenCL memory object associated with the VBO. With an appropriate work-group size this will result in efficient parallel writes of a segment of data into the VBO on a GPU. After setting the kernel arguments appropriately, we first finish the GL commands, then have OpenCL acquire the VBO. The kernel is then launched. We call clFinish() to ensure that it completes and finally releases the buffer for OpenGL to use as shown here:
glFinish();
errNum = clEnqueueAcquireGLObjects(commandQueue, 1, &cl_tex_mem,
0,NULL,NULL );
errNum = clEnqueueNDRangeKernel(commandQueue, tex_kernel, 2, NULL,
tex_globalWorkSize,
tex_localWorkSize,
0, NULL, NULL);
clFinish(commandQueue);
errNum = clEnqueueReleaseGLObjects(commandQueue, 1, &cl_tex_mem, 0,
NULL, NULL );
After this kernel completes, the vertex buffer object is filled with vertex positions for drawing our sine wave. The typical OpenGL rendering commands for a vertex buffer can then be used to draw the sine wave on screen:
glBindBufferARB(GL_ARRAY_BUFFER_ARB, vbo);
glEnableClientState(GL_VERTEX_ARRAY);
glVertexPointer( 2, GL_FLOAT, 0, 0 );
glDrawArrays(GL_LINES, 0, vbolen*2);
glDisableClientState(GL_VERTEX_ARRAY);
glBindBufferARB(GL_ARRAY_BUFFER_ARB, 0);
The example code performs these operations and the result is shown in Figure 10.1. The sine wave has been generated by OpenCL and rendered in OpenGL. Every frame, the seq kernel parameter shifts the sine wave to create an animation.
Figure 10.1 A program demonstrating OpenCL/OpenGL interop. The positions of the vertices in the sine wave and the background texture color values are computed by kernels in OpenCL and displayed using Direct3D.
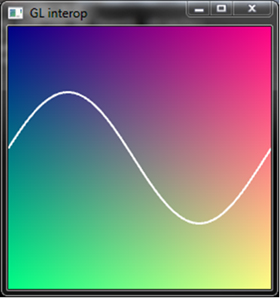
Creating OpenCL Image Objects from OpenGL Textures
In addition to sharing OpenGL buffers, OpenGL textures and renderbuffers can also be shared by similar mechanisms. In Figure 10.1, the background is a programmatically generated and animated texture computed in OpenCL. Sharing textures can be achieved using the glCreateFromGLTexture2D() and glCreateFromGLTexture3D() functions:
This creates an OpenCL 2D image object from an OpenGL 2D texture object, or a single face of an OpenGL cube map texture object.
The following creates an OpenCL 3D image object from an OpenGL 3D texture object:
For example, to share a four-element floating-point RGBA texture between OpenGL and OpenCL, a texture can be created with the following OpenGL commands:
glGenTextures(1, &tex);
glTexEnvi( GL_TEXTURE_ENV, GL_TEXTURE_ENV_MODE, GL_REPLACE );
glBindTexture(GL_TEXTURE_RECTANGLE_ARB, tex);
glTexImage2D(GL_TEXTURE_RECTANGLE_ARB, 0, GL_RGBA32F_ARB, width,
height, 0, GL_LUMINANCE, GL_FLOAT, NULL );
Note that when creating the texture, the code specifies GL_RGBA32F_ARB as the internal texture format to create the four-element RGBA floating-point texture, a functionality provided by the ARB_texture_float extension in OpenGL. Additionally, the texture created uses a non-power-of-2 width and height and uses the GL_TEXTURE_RECTANGLE_ARB argument supported by the GL_ARB_texture_rectangle extension. Alternatively, GL_TEXTURE_RECTANGLE may be used on platforms that support OpenGL 3.1. This allows natural indexing of integer pixel coordinates in the OpenCL kernel.
An OpenCL texture memory object can be created from the preceding OpenGL texture by passing it as an argument to clCreateFromGLTexture2D():
*p_cl_tex_mem = clCreateFromGLTexture2D(context,
CL_MEM_READ_WRITE, GL_TEXTURE_RECTANGLE_ARB,
0, tex, &errNum );
Again we have specified the texture target of GL_TEXTURE_RECTANGLE_ARB. The OpenCL memory object pointed to by p_cl_tex_mem can now be accessed as an image object in a kernel using functions such as read_image*() or write_image*() to read or write data. CL_MEM_READ_WRITE was specified so that the object can be passed as a read or write image memory object. For 3D textures, clCreateFromGLTexture3D() provides similar functionality.
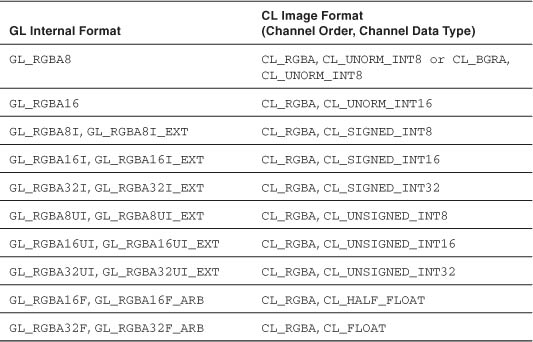
Note that only OpenGL textures that have an internal format that maps to an appropriate image channel order and data type in OpenCL may be used to create a 2D OpenCL image object. The list of supported OpenCL channel orders and data formats is given in the specification and is as shown in Table 10.1. Because the OpenCL image format is implicitly set from its corresponding OpenGL internal format, it is important to check what OpenCL image format is created in order to ensure that the correct read_image*() function in OpenCL is used when sampling from the texture. Implementations may have mappings for other OpenGL internal formats. In these cases the OpenCL image format preserves all color components, data types, and at least the number of bits per component allocated by OpenGL for that format.
Table 10.1 OpenGL Texture Format Mappings to OpenCL Image Formats
GL renderbuffers can also be shared with OpenCL via the clCreateFromGLRenderbuffer() call:
This creates an OpenCL 2D image object from an OpenGL renderbuffer object.
Attaching a renderbuffer to an OpenGL frame buffer object (FBO) opens up the possibility of computing postprocessing effects in OpenCL through this sharing function. For example, a scene can be rendered in OpenGL to a frame buffer object, and that data can be made available via the renderbuffer to OpenCL, which can postprocess the rendered image.
Querying Information about OpenGL Objects
OpenCL memory objects that were created from OpenGL memory objects can be queried to return information about their underlying OpenGL object type. This is done using the clGetGLObjectInfo() function:
The OpenGL object used to create the OpenCL memory object and information about the object type—whether it is a texture, renderbuffer, or buffer object—can be queried using this function.
After the function runs, the parameter gl_object_type will be set to an enumerated type for that object. The GL object name used to create the memobj is also returned, in gl_object_name. This corresponds to the object name given in OpenGL when the object was created, such as with a glGenBuffers() call in the case of an OpenGL buffer object.
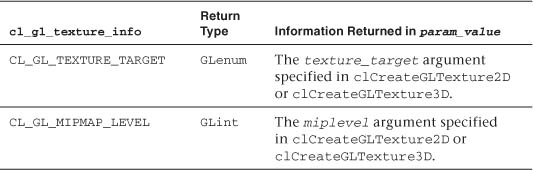
For texture objects, the corresponding call is clGetTextureObjectInfo():
This returns additional information about the GL texture object associated with a memory object.
When the function returns, the parameters param_value and param_value_size_ret will have been set by the function. param_value_size_ret is the size of the returned data, which is determined by the type of query requested, as set by the param_name parameter according to Table 10.2.
Table 10.2 Supported param_name Types and Information Returned
Synchronization between OpenGL and OpenCL
Thus far we have discussed the mechanics of creating and sharing an OpenGL object in OpenCL. In the preceding discussion we only briefly mentioned that when OpenGL objects are acquired and released, it is the program’s responsibility to ensure that all preceding OpenCL or OpenGL commands that affect the shared object (which of OpenCL or OpenGL is dependent on whether the object is being acquired or released) have completed beforehand. glFinish() and clFinish() are two commands that can be used for this purpose. glFinish(), however, requires that all pending commands be sent to the GPU and waits for their completion, which can take a long time, and empties the pipeline of commands. In this section, we’ll present a more fine-grained approach based on the sharing of event objects between OpenGL and OpenCL.
The cl_khr_gl_event OpenCL extension provides event-based synchronization and additional functionality to the clEnqueueAcquireGLObjects() and clEnqueueReleaseGLObjects() functions. The following pragma enables it:
#pragma OPENCL EXTENSION cl_khr_gl_event : enable
When enabled, this provides what is known as implicit synchronization whereby the clEnqueueAcquireGLObjects() and clEnqueueReleaseGLObjects() functions implicitly guarantee synchronization with an OpenGL context bound in the same thread as the OpenCL context. In this case, any OpenGL commands that affect or access the contents of a memory object listed in the mem_objects_list argument of clEnqueueAcquireGLObjects() and were issued on that context prior to the call to clEnqueueAcquireGLObjects() will complete before execution of any OpenCL commands following the clEnqueueAcquireGLObjects() call.
Another option for synchronization is explicit synchronization. When the cl_khr_gl_event extension is supported, and the OpenGL context supports fence sync objects, the completion of OpenGL commands can be determined by using an OpenGL fence sync object by creating a OpenCL event from it, by way of the clCreateEventFromGLsyncKHR() function:
An event object may be created by linking to an OpenGL sync object. Completion of such an event object is equivalent to waiting for completion of the fence command associated with the linked GL sync object.
In explicit synchronization, completion of OpenCL commands can be determined by a glFenceSync command placed after the OpenGL commands. An OpenCL thread can then use the OpenCL event associated with the OpenGL fence by passing the OpenCL event to clEnqueueAcquireGLObjects() in its event_wait_list argument. Note that the event returned by clCreateEventFromGLsyncKHR() may be used only by clEnqueueAcquireGLObjects() and returns an error if passed to other OpenCL functions. Explicit synchronization is useful when an OpenGL thread separate from the OpenCL thread is accessing the same underlying memory object.
Thus far we have presented OpenCL functions that create objects from OpenGL objects. In OpenGL there is also a function that allows the creation of OpenGL sync objects from existing OpenCL event objects. This is enabled by the OpenGL extension ARB_cl_event. Similar to the explicit synchronization method discussed previously, this allows OpenGL to reflect the status of an OpenCL event object. Waiting on this sync object in OpenGL is equivalent to waiting on the linked OpenCL sync object. When the ARB_cl_event extension is supported by OpenGL, the glCreateSyncFromCLeventARB() function creates a GLsync linked to an OpenCL event object:
An OpenGL sync object created with this function can also be deleted with the glDeleteSync() function:
Once created, this GLsync object is linked to the state of the OpenCL event object, and the OpenGL sync object functions, such as glWaitSync(), glClientWaitSync(), and glFenceSync(), can be applied. Full details on the interactions of these calls with OpenGL can be found in the OpenGL ARB specification.
The following code fragment demonstrates how this can be applied to synchronize OpenGL with an OpenCL kernel call:
cl_event release_event;
GLsync sync = glFenceSync(GL_SYNC_GPU_COMMANDS_COMPLETE, 0);
gl_event = clCreateEventFromGLsyncKHR(context, sync, NULL );
errNum = clEnqueueAcquireGLObjects(commandQueue, 1,
&cl_tex_mem, 0, &gl_event, NULL );
errNum = clEnqueueNDRangeKernel(commandQueue, tex_kernel, 2, NULL,
tex_globalWorkSize, tex_localWorkSize,
0, NULL, 0);
errNum = clEnqueueReleaseGLObjects(commandQueue, 1,
&cl_tex_mem, 0, NULL, &release_event);
GLsync cl_sync = glCreateSyncFromCLeventARB(context,
release_event, 0);
glWaitSync( cl_sync, 0, GL_TIMEOUT_IGNORED );
This code uses fine-grained synchronization and proceeds as follows:
1. First, an OpenGL fence object is created. This creates and inserts a fence sync into the OpenGL command stream.
2. Then, clCreateEventFromGLsyncKHR() is called. This creates an OpenCL event linked to the fence. This OpenCL event is then used in the event list for clEnqueueAcquireGLObjects(), ensuring that the acquire call will proceed only after the fence has completed.
3. The OpenCL kernel is then queued for execution, followed by the clEnqueueReleaseGLObjects() call. The clEnqueueReleaseGLObjects() call returns an event, release_event, that can be used to sync upon its completion.
4. The glCreateSyncFromCLeventARB() call then creates an OpenGL sync object linked to the release_event.
5. A wait is then inserted into the OpenGL command stream with glWaitSync(), which will wait upon the completion of the release_event associated with clEnqueueReleaseGLObjects().
Using a method like this allows synchronization between OpenGL and OpenCL without the need for gl/clFinish() functions.