
Chapter 5. OpenCL C Built-In Functions
The OpenCL C programming language provides a rich set of built-in functions for scalar and vector argument types. These can be categorized as
• Async copy and prefetch functions
• Vector data load and store functions
• Miscellaneous vector functions
• Image functions
Many of these built-in functions are similar to the functions available in common C libraries (such as the functions defined in math.h). The OpenCL C functions support scalar and vector argument types. It is recommended that you use these functions for your applications instead of writing your own.
In this chapter, we describe these built-in functions with examples that show how to use them. Additional information that provides special insight into these functions, wherever applicable and helpful, is also provided.
Work-Item Functions
Applications queue data-parallel and task-parallel kernels in OpenCL using the clEnqueueNDRangeKernel and clEnqueueTask APIs. For a data-parallel kernel that is queued for execution using clEnqueueNDRangeKernel, an application specifies the global work size—the total number of work-items that can execute this kernel in parallel—and local work size—the number of work-items to be grouped together in a work-group. Table 5.1 describes the built-in functions that can be called by an OpenCL kernel to obtain information about work-items and work-groups such as the work-item’s global and local ID or the global and local work size.
Table 5.1 Built-In Work-Item Functions
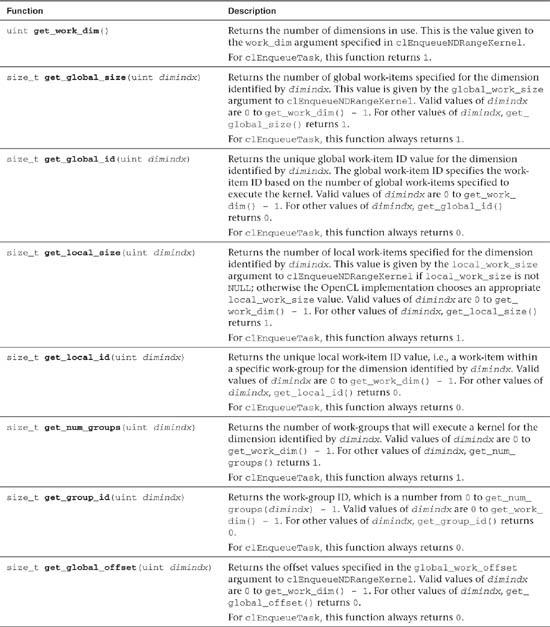
Figure 5.1 gives an example of how the global and local work sizes specified in clEnqueueNDRangeKernel can be accessed by a kernel executing on the device. In this example, a kernel is executed over a global work size of 16 items and a work-group size of 8 items per group.
Figure 5.1 Example of the work-item functions
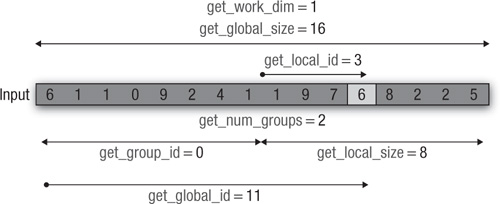
OpenCL does not describe how the global and local IDs map to work-items and work-groups. An application, for example, cannot assume that a work-group whose group ID is 0 will contain work-items with global IDs 0 ... get_local_size(0) - 1. This mapping is determined by the OpenCL implementation and the device on which the kernel is executing.
Math Functions
OpenCL C implements the math functions described in the C99 specification. Applications that want to use these math functions include the math.h header in their codes. These math functions are available as built-ins to OpenCL kernels.1
We use the generic type name gentype to indicate that the math functions in Tables 5.2 and 5.3 take float, float2, float3, float4, float8, float16, and, if the double-precision extension is supported, double, double2, double3, double4, double8, or double16 as the type for the arguments. The generic type name gentypei refers to the int, int2, int3, int4, int8, or int16 data types. The generic type name gentypef refers to the float, float2, float3, float4, float8, or float16 data types. The generic type name gentyped refers to the double, double2, double3, double4, double8, or double16 data types.
Table 5.2 Built-In Math Functions
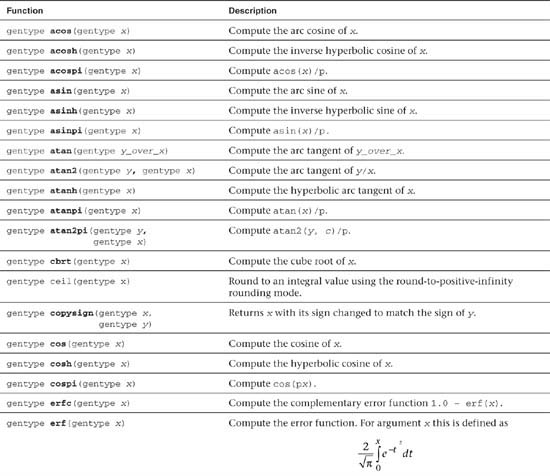

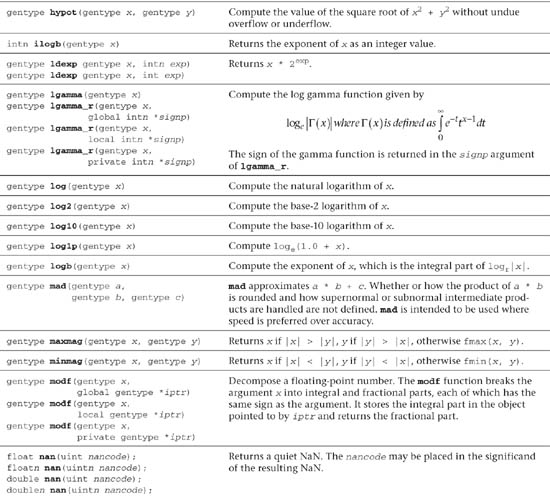
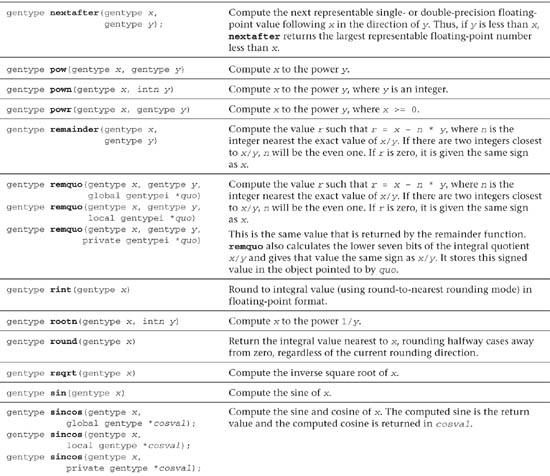

In addition to the math functions listed in Table 5.2, OpenCL C also implements two additional variants of the most commonly used math functions for single-precision floating-point scalar and vector data types. These additional math functions (described in Table 5.3) trade accuracy for performance and provide developers with options to make appropriate choices. These math functions can be categorized as
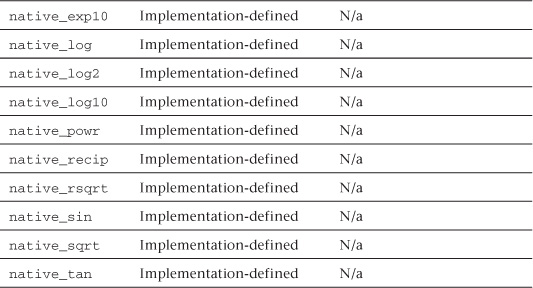
Table 5.3 Built-In half_ and native_ Math Functions
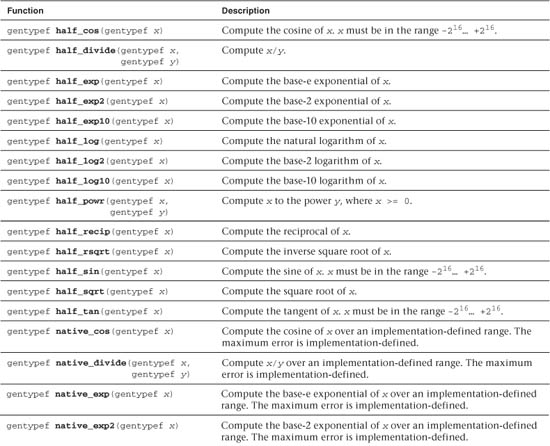
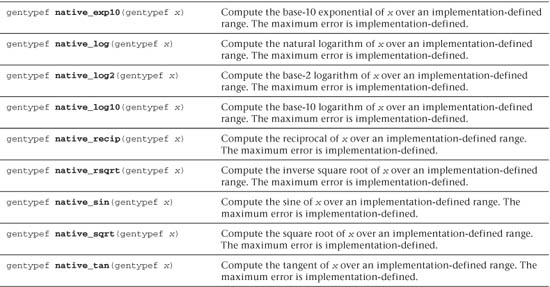
• A subset of functions from Table 5.2 defined with the half_ prefix. These functions are implemented with a minimum of 10 bits of accuracy, that is, a ulp value <= 8192 ulp.
• A subset of functions from Table 5.2 defined with the native_ prefix. These functions typically have the best performance compared to the corresponding functions without the native_ prefix or with the half_ prefix. The accuracy (and in some cases the input ranges) of these functions is implementation-defined.
• half_ and native_ functions for the following basic operations: divide and reciprocal.
Floating-Point Pragmas
The only pragma supported by OpenCL C is the FP_CONTRACT pragma. The FP_CONTRACT pragma provides a way to disallow contracted expressions and is defined to be
#pragma OPENCL FP_CONTRACT on-off-switch
on-off-switch is ON, OFF, or DEFAULT. The DEFAULT value is ON.
The FP_CONTRACT pragma can be used to allow (if the state is ON) or disallow (if the state is OFF) the implementation to contract expressions. If FP_CONTRACT is ON, a floating-point expression may be contracted, that is, evaluated as though it were an atomic operation. For example, the expression a * b + c can be replaced with an FMA (fused multiply-add) instruction.
Each FP_CONTRACT pragma can occur either outside external declarations or preceding all explicit declarations and statements inside a compound statement. When outside external declarations, the pragma takes effect from its occurrence until another FP_CONTRACT pragma is encountered, or until the end of the translation unit. When inside a compound statement, the pragma takes effect from its occurrence until another FP_CONTRACT pragma is encountered (including within a nested compound statement), or until the end of the compound statement; at the end of a compound statement the state for the pragma is restored to its condition just before the compound statement. If this pragma is used in any other context, the behavior is undefined.
Floating-Point Constants
The constants described in Table 5.4 are available. The constants with the _F suffix are of type float and are accurate within the precision of the float type. The constants without the _F suffix are of type double, are accurate within the precision of the double type, and are available only if the double-precision extension is supported by the OpenCL implementation.
Table 5.4 Single- and Double-Precision Floating-Point Constants

Relative Error as ulps
Table 5.5 describes the maximum relative error defined as ulp (units in the last place) for single-precision and double-precision floating-point basic operations and functions. The ulp2 is defined thus:
If x is a real number that lies between two finite consecutive floating-point numbers a and b, without being equal to one of them, then ulp(x) = |b − a|, otherwise ulp(x) is the distance between the two non-equal finite floating-point numbers nearest x. Moreover, ulp(NaN) is NaN.
Table 5.5 ulp Values for Basic Operations and Built-In Math Functions
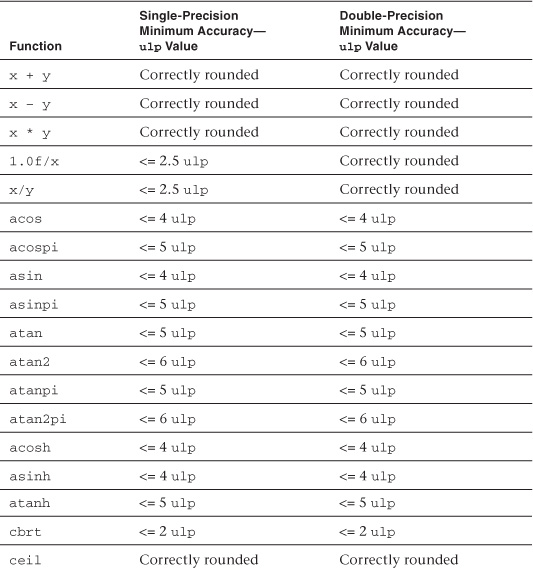
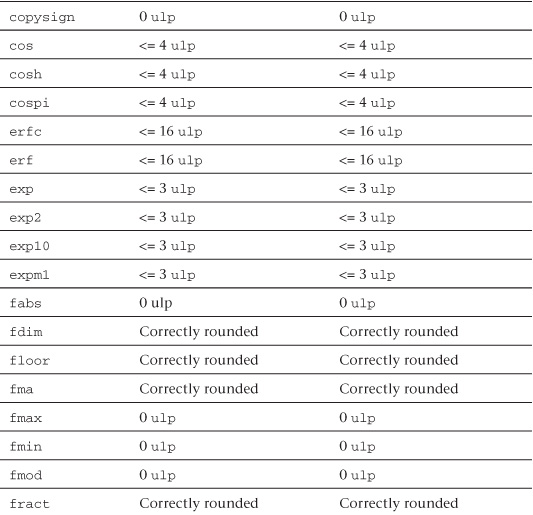
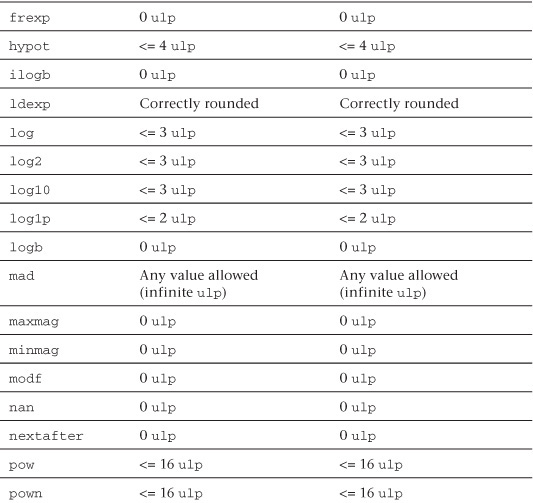
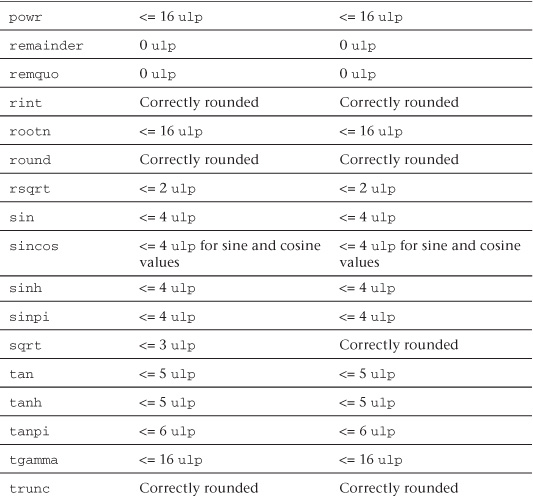
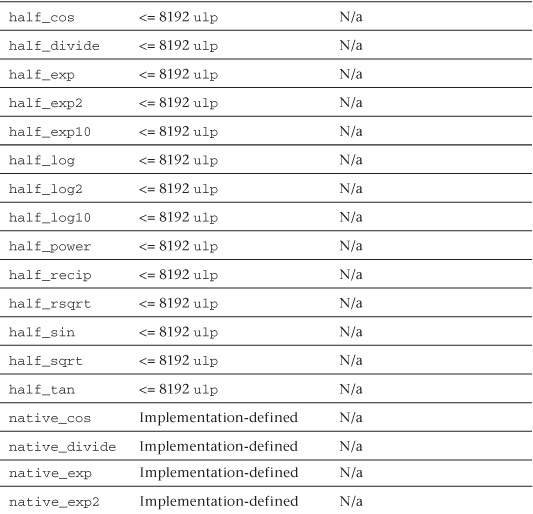
The following list provides additional clarification of ulp values and rounding mode behavior:
• The round-to-nearest rounding mode is the default rounding mode for the full profile. For the embedded profile, the default rounding mode can be either round to zero or round to nearest. If CL_FP_ROUND_TO_NEAREST is supported in CL_DEVICE_SINGLE_FP_CONFIG (refer to Table 4.3 of the OpenCL 1.1 specification), then the embedded profile supports round to nearest as the default rounding mode; otherwise the default rounding mode is round to zero.
• 0 ulp is used for math functions that do not require rounding.
• The ulp values for the built-in math functions lgamma and lgamma_r are currently undefined.
Integer Functions
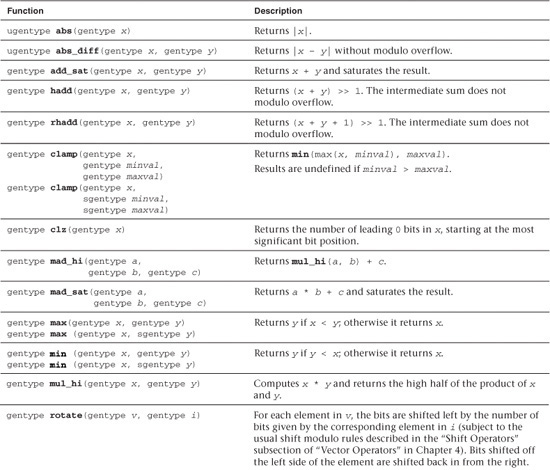
Table 5.6 describes the built-in integer functions available in OpenCL C. These functions all operate component-wise. The description is per component.
Table 5.6 Built-In Integer Functions

We use the generic type name gentype to indicate that the function can take char, char2, char3, char4, char8, char16, uchar, uchar2, uchar3, uchar4, uchar8, uchar16, short, short2, short3, short4, short8, short16, ushort, ushort2, ushort3, ushort4, ushort8, ushort16, int, int2, int3, int4, int8, int16, uint, uint2, uint3, uint4, uint8, uint16, long, long2, long3, long4, long8, long16, ulong, ulong2, ulong3, ulong4, ulong8, or ulong16 as the type for the arguments.
We use the generic type name ugentype to refer to unsigned versions of gentype. For example, if gentype is char4, ugentype is uchar4. We use the generic type name sgentype to refer to signed versions of gentype.
We use the generic type name sgentype to indicate that the function can take a scalar data type, that is, char, uchar, short, ushort, int, uint, long, or ulong, as the argument type. For built-in integer functions that take gentype and sgentype arguments, the gentype argument must be a vector or scalar of the sgentype argument. For example, if sgentype is uchar, gentype must be uchar, uchar2, uchar3, uchar4, uchar8, or uchar16.
The following macro names are available. The values are constant expressions suitable for use in #if processing directives.
#define CHAR_BIT 8
#define CHAR_MAX SCHAR_MAX
#define CHAR_MIN SCHAR_MIN
#define INT_MAX 2147483647
#define INT_MIN (-2147483647 – 1)
#define LONG_MAX 0x7fffffffffffffffL
#define LONG_MIN (-0x7fffffffffffffffL – 1)
#define SCHAR_MAX 127
#define SCHAR_MIN (-127 – 1)
#define SHRT_MAX 32767
#define SHRT_MIN (-32767 – 1)
#define UCHAR_MAX 255
#define USHRT_MAX 65535
#define UINT_MAX 0xffffffff
#define ULONG_MAX 0xffffffffffffffffUL
Common Functions
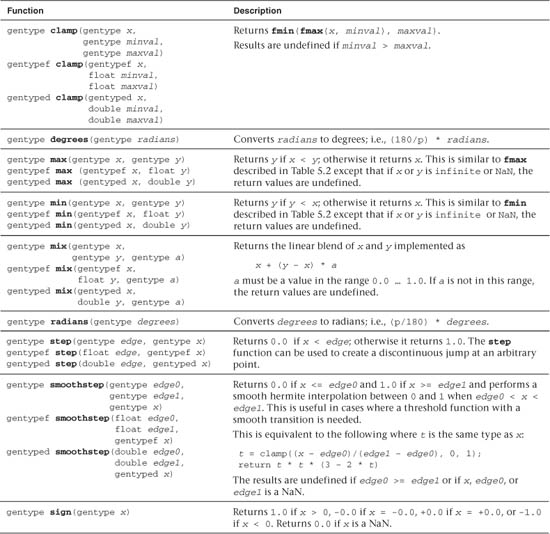
Table 5.7 describes the built-in common functions available in OpenCL C. These functions all operate component-wise. The description is per component.
Table 5.7 Built-In Common Functions
We use the generic type name gentype to indicate that the function can take float, float2, float3, float4, float8, or float16 and, if the double-precision extension is supported, double, double2, double3, double4, double8, or double16 as the type for the arguments.
We use the generic type name gentypef to indicate that the function can take float, float2, float3, float4, float8, or float16 as the type for the arguments and the generic type name gentyped to indicate that the function can take double, double2, double3, double4, double8, or double16 as the type for the arguments.
Geometric Functions
Table 5.8 describes the built-in geometric functions available in OpenCL C. These functions all operate component-wise. The description is per component.
Table 5.8 Built-In Geometric Functions


We use the generic type name gentypef to indicate that the function can take float, float2, float3, float4, float8, or float16 arguments. If the double-precision extension is supported, the generic type name gentyped indicates that the function can take double, double2, double3, double4, double8, or double16 as the type for the arguments.
Information on how these geometric functions may be implemented and additional clarification of the behavior of some of the geometric functions is given here:
• The geometric functions can be implemented using contractions such as mad or fma.
• The fast_ variants provide developers with an option to choose performance over accuracy.
• The distance, length, and normalize functions compute the results without overflow or extraordinary precision loss due to underflow.
Relational Functions
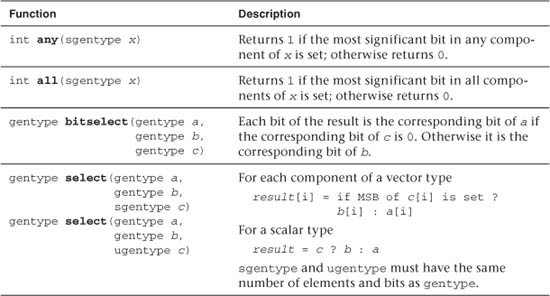
Table 5.9 describes the built-in relational functions available in OpenCL C. These functions all operate component-wise. The description is per component.
Table 5.9 Built-In Relational Functions


The functions isequal, isnotequal, isgreater, isgreaterequal, isless, islessequal, islessgreater, isfinite, isinf, isnan, isnormal, isordered, isunordered, and signbit in Table 5.9 return a 0 if the specified relation is false and a 1 if the specified relation is true for scalar argument types. These functions return a 0 if the specified relation is false and a -1 (i.e., all bits set) if the specified relation is true for vector argument types.
The functions isequal, isgreater, isgreaterequal, isless, islessequal, and islessgreater return 0 if either argument is not a number (NaN). isnotequal returns 1 if one or both arguments are NaN and the argument type is a scalar and returns -1 if one or both arguments are NaN and the argument type is a vector.
Table 5.10 describes additional relational functions supported by OpenCL C. We use the generic type name gentype to indicate that the function can take char, char2, char3, char4, char8, char16, uchar, uchar2, uchar3, uchar4, uchar8, uchar16, short, short2, short3, short4, short8, short16, ushort, ushort2, ushort3, ushort4, ushort8, ushort16, int, int2, int3, int4, int8, int16, uint, uint2, uint3, uint4, uint8, uint16, long, long2, long3, long4, long8, long16, ulong, ulong2, ulong3, ulong4, ulong8, ulong16, float, float2, float3, float4, float8, float16, and, if the double-precision extension is supported, double, double2, double3, double4, double8, or double16 as the type for the arguments.
Table 5.10 Additional Built-In Relational Functions
We use the generic type name sgentype to refer to the unsigned integer types char, char2, char3, char4, char8, char16, short, short2, short3, short4, short8, short16, int, int2, int3, int4, int8, int16, long, long2, long3, long4, long8, or long16.
We use the generic type name ugentype to refer to the signed integer types uchar, uchar2, uchar3, uchar4, uchar8, uchar16, ushort, ushort2, ushort3, ushort4, ushort8, ushort16, uint, uint2, uint3, uint4, uint8, uint16, ulong, ulong2, ulong3, ulong4, ulong8, or ulong16.
Vector Data Load and Store Functions
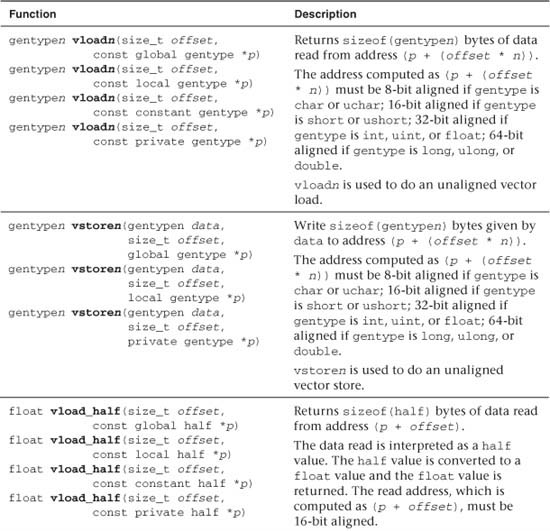
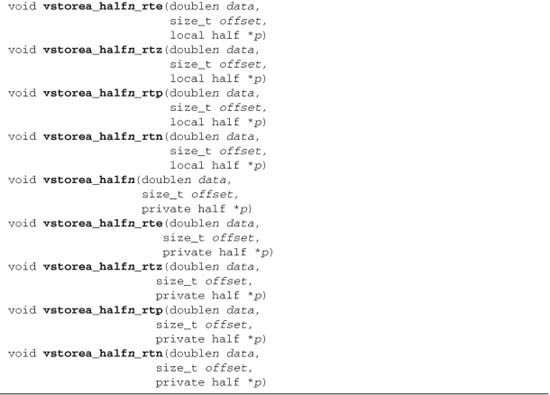
Table 5.11 describes the built-in functions that allow you to read and write vector types from a pointer to memory. We use the generic type name gentype to indicate the scalar built-in data types char, uchar, short, ushort, int, uint, long, ulong, float, or double. We use the generic type name gentypen to indicate the n-element vectors of gentype elements. We use the type name floatn, doublen, and halfn to represent n-element vectors of float, double, and half elements, respectively. The suffix n is also used in the function names (such as vloadn, vstoren), where n = 2, 3, 4, 8, or 16.
Table 5.11 Built-In Vector Data Load and Store Functions







Synchronization Functions
OpenCL C implements a synchronization function called barrier. The barrier synchronization function is used to enforce memory consistency between work-items in a work-group. This is described in Table 5.12.
Table 5.12 Built-In Synchronization Functions

If all work-items in a work-group do not encounter the barrier, then the behavior is undefined. On some devices, especially GPUs, this will most likely result in a deadlock in hardware. The following is an example that shows this incorrect usage of the barrier function:
kernel void
read(global int *g, local int *shared)
{
if (get_global_id(0) < 5)
barrier(CLK_GLOBAL_MEM_FENCE); ← illegal since not all work-
items encounter barrier.
else
k = array[0];
}
Note that the memory consistency is enforced only between work-items in a work-group, not across work-groups. Here is an example that demonstrates this:
kernel void
smooth(global float *io)
{
float temp;
int id = get_global_id(0);
temp = (io[id – 1] + io[id] + io[id + 1]) / 3.0f;
barrier(CLK_GLOBAL_MEM_FENCE);
io[id] = temp;
}
If kernel smooth is executed over a global work size of 16 items with 2 work-groups of 8 work-items each, then the value that will get stored in io[7] and/or io[8] is undetermined. This is because work-items in both work-groups use io[7] and io[8] to compute temp. Work-group 0 uses it to calculate temp for io[7], and work-group 1 uses it to calculate temp for io[8]. Because there are no guarantees when work-groups execute or which compute units they execute on, and because barrier only enforces memory consistency for work-items in a work-group, we are unable to say what values will be computed and stored in io[7] and io[8].
Async Copy and Prefetch Functions
Table 5.13 describes the built-in functions in OpenCL C that provide a portable and performant method for copying between global and local memory and do a prefetch from global memory. The functions that copy between global and local memory are defined to be an asynchronous copy.
Table 5.13 Built-In Async Copy and Prefetch Functions

We use the generic type name gentype to indicate that the function can take char, char2, char3, char4, char8, char16, uchar, uchar2, uchar3, uchar4, uchar8, uchar16, short, short2, short3, short4, short8, short16, ushort, ushort2, ushort3, ushort4, ushort8, ushort16, int, int2, int3, int4, int8, int16, uint, uint2, uint3, uint4, uint8, uint16, long, long2, long3, long4, long8, long16, ulong, ulong2, ulong3, ulong4, ulong8, ulong16, float, float2, float3, float4, float8, float16, and, if the double-precision extension is supported, double, double2, double3, double4, double8, or double16 as the type for the arguments.
The following example shows how async_work_group_strided_copy can be used to do a strided copy from global to local memory and back. Consider a buffer of elements where each element represents a vertex of a 3D geometric object. Each vertex is a structure that stores the position, normal, texture coordinates, and other information about the vertex. An OpenCL kernel may want to read the vertex position, apply some computations, and store the updated position values. This requires a strided copy to move the vertex position data from global to local memory, apply computations, and then move the update vertex position data by doing a strided copy from local to global memory.
typedef struct {
float4 position;
float3 normal;
float2 texcoord;
...
} vertex_t;
kernel void
update_position_kernel(global vertex_t *vertices,
local float4 *pos_array)
{
event_t evt = async_work_group_strided_copy(
(local float *)pos_array,
(global float *)vertices,
4, sizeof(vertex_t)/sizeof(float),
NULL);
wait_group_events(evt);
// do computations
. . .
evt = async_work_group_strided_copy((global float *)vertices,
(local float *)pos_array,
4, sizeof(vertex_t)/sizeof(float),
NULL);
wait_group_events(evt);
}
The kernel must wait for the completion of all async copies using the wait_group_events built-in function before exiting; otherwise the behavior is undefined.
Atomic Functions
Table 5.14 describes the built-in functions in OpenCL C that provide atomic operations on 32-bit signed and unsigned integers and single-precision floating-point to locations in global or local memory.
Table 5.14 Built-In Atomic Functions




Note
atom_xchg is the only atomic function that takes floating-point argument types.
Miscellaneous Vector Functions
OpenCL C implements the additional built-in vector functions described in Table 5.15. We use the generic type name gentype to indicate that the function can take char, uchar, short, ushort, int, uint, long, ulong, float, and, if the double-precision extension is supported, double as the type for the arguments.
Table 5.15 Built-In Miscellaneous Vector Functions

We use the generic type name gentypen (or gentypem) to indicate that the function can take char2, char3, char4, char8, char16, uchar2, uchar3, uchar4, uchar8, uchar16, short2, short3, short4, short8, short16, ushort2, ushort3, ushort4, ushort8, ushort16, int2, int3, int4, int8, int16, uint2, uint3, uint4, uint8, uint16, long2, long3, long4, long8, long16, ulong2, ulong3, ulong4, ulong8, ulong16, float2, float3, float4, float8, float16, and, if the double-precision extension is supported, double2, double3, double4, double8, or double16 as the type for the arguments.
We use the generic type ugentypen to refer to the built-in unsigned integer vector data types.
Here are a couple of examples showing how shuffle and shuffle2 can be used:
uint mask = (uint4)(3, 2, 1, 0);
float4 a;
float4 r = shuffle(a, mask); // r.s0123 = a.wzyx
uint8 mask = (uint8)(0, 1, 2, 3, 4, 5, 6, 7);
float4 a, b;
float8 r = shuffle2(a, b, mask); // r.s0123 = a.xyzw,
// r.s4567 = b.xyzw
A few examples showing illegal usage of shuffle and shuffle2 follow. These should result in a compilation error.
uint8 mask;
short16 a;
short8 b;
b = shuffle(a, mask); // not valid
We recommend using shuffle and shuffle2 to do permute operations instead of rolling your own code as the compiler can very easily map these built-in functions to the appropriate underlying hardware ISA.
Image Read and Write Functions
In this section, we describe the built-in functions that allow you to read from an image, write to an image, and query image information such as dimensions and format.
OpenCL GPU devices have dedicated hardware for reading from and writing to images. The OpenCL C image read and write functions allow developers to take advantage of this dedicated hardware. Image support in OpenCL is optional. To find out if a device supports images, query the CL_DEVICE_IMAGE_SUPPORT property using the clGetDeviceInfo API.
Reading from an Image
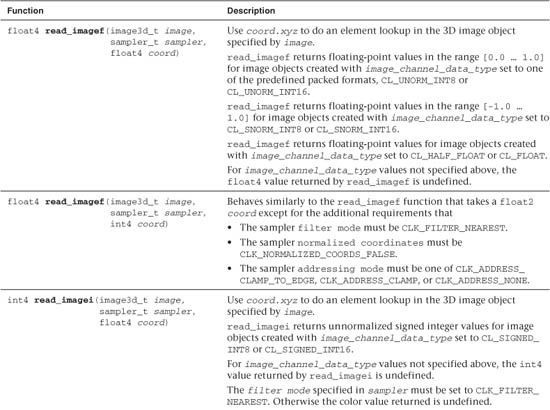
Tables 5.16 and 5.17 describe built-in functions that read from a 2D and 3D image, respectively.
Table 5.16 Built-In Image 2D Read Functions
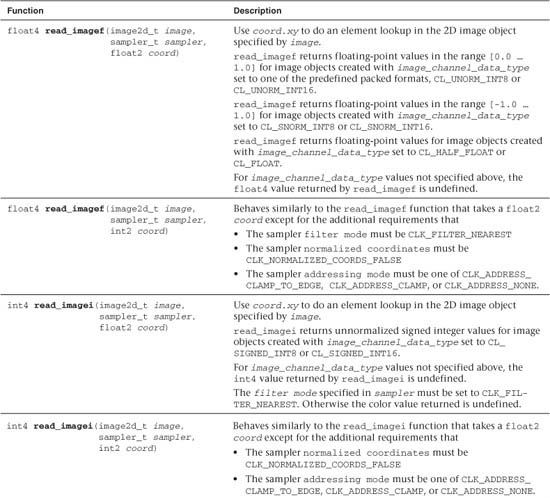
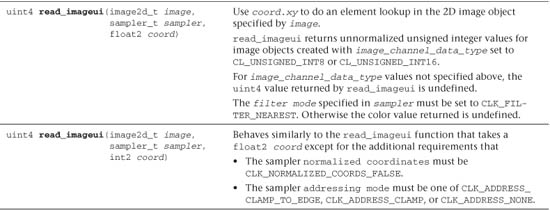
Table 5.17 Built-In Image 3D Read Functions

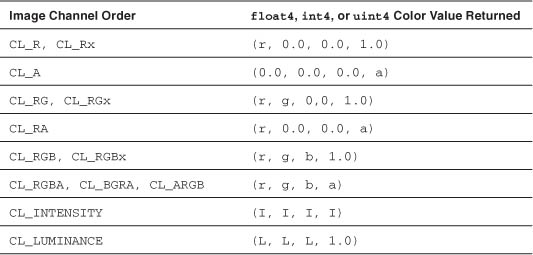
Note that read_imagef, read_imagei, and read_imageui return a float4, int4, or uint4 color value, respectively. This is because the color value can have up to four components. Table 5.18 lists the values used for the components that are not in the image.
Table 5.18 Image Channel Order and Values for Missing Components
Samplers
The image read functions take a sampler as an argument. The sampler specifies how to sample pixels from the image. A sampler can be passed as an argument to a kernel using the clSetKernelArg API, or it can be a constant variable of type sampler_t that is declared in the program source.
Sampler variables passed as arguments or declared in the program source must be of type sampler_t. The sampler_t type is a 32-bit unsigned integer constant and is interpreted as a bit field. The sampler describes the following information:
• Normalized coordinates: Specifies whether the coord.xy or coord.xyz values are normalized or unnormalized values. This can be set to CLK_NORMALIZED_COORDS_TRUE or CLK_NORMALIZED_COORDS_FALSE.
• Addressing mode: This specifies how the coord.xy or coord.xyz image coordinates get mapped to appropriate pixel locations inside the image and how out-of-range image coordinates are handled. Table 5.19 describes the supported addressing modes.
Table 5.19 Sampler Addressing Mode

• Filter mode: This specifies the filtering mode to use. This can be set to CLK_FILTER_NEAREST (i.e., the nearest filter) or CLK_FILTER_LINEAR (i.e., a bilinear filter).
The following is an example of a sampler passed as an argument to a kernel:
kernel void
my_kernel(read_only image2d_t imgA, sampler_t sampler,
write_only image2d imgB)
{
int2 coord = (int2)(get_global_id(0), get_global_id(1));
float4 clr = read_imagef(imgA, sampler, coord);
write_imagef(imgB, coord, color);
}
The following is an example of samplers declared inside a program source:
const sampler_t samplerA = CLK_NORMALIZED_COORDS_FALSE |
CLK_ADDRESS_CLAMP |
CLK_FILTER_LINEAR;
kernel void
my_kernel(read_only image2d_t imgA, read_only image2d_t imgB,
write_only image2d imgB)
{
int2 coord = (int2)(get_global_id(0), get_global_id(1));
float4 clr = read_imagef(imgA, samplerA, coord);
clr *= read_imagef(imgA,
(CLK_NORMALIZED_COORDS_FALSE |
CLK_ADDRESS_CLAMP | CLK_FILTER_NEAREST),
imgB);
}
The maximum number of samplers that can be used in a kernel can be obtained by querying the CL_DEVICE_MAX_SAMPLERS property using the clGetDeviceInfo API.
Limitations
The samplers specified to read_imagef, read_imagei, or read_imageui must use the same value for normalized coordinates when reading from the same image. The following example illustrates this (different normalized coordinate values used by samplers are highlighted). This will result in undefined behavior; that is, the color values returned may not be correct.
const sampler_t samplerA = CLK_NORMALIZED_COORDS_FALSE |
CLK_ADDRESS_CLAMP |
CLK_FILTER_LINEAR;
kernel void
my_kernel(read_only image2d_t imgA, write_only image2d imgB)
{
float4 clr;
int2 coord = (int2)(get_global_id(0), get_global_id(1));
float2 normalized_coords;
float w = get_image_width(imgA);
float h = get_image_height(imgA);
clr = read_imagef(imgA, samplerA, coord);
normalized_coords = convert_float2(coord) *
(float2)(1.0f / w, 1.0f / h);
clr *= read_imagef(imgA,
(CLK_NORMALIZED_COORDS_TRUE |
CLK_ADDRESS_CLAMP | CLK_FILTER_NEAREST),
normalized_coords);
}
Also, samplers cannot be declared as arrays or pointers or be used as the type for local variables inside a function or as the return value of a function defined in a program. Sampler arguments to a function cannot be modified. The invalid cases shown in the following example will result in a compile-time error:
sampler_t ← error. return type cannot be sampler_t
internal_proc(read_only image2d_t imgA, write_only image2d imgB)
{
...
}
kernel void
my_kernel(read_only image2d_t imgA, sampler_t sampler,
write_only image2d imgB)
{
sampler_t *ptr_sampler; ← error. pointer to sampler not allowed
my_func(imgA, &sampler); ← error passing a pointer to a sampler
...
}
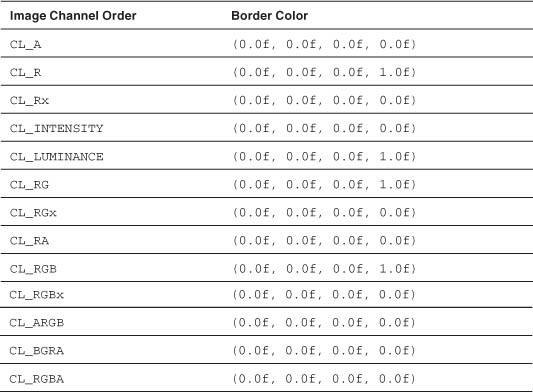
Determining the Border Color
If the sampler addressing mode is CLK_ADDRESS_CLAMP, out-of-range image coordinates return the border color. The border color returned depends on the image channel order and is described in Table 5.20.
Table 5.20 Image Channel Order and Corresponding Border Color Value
Writing to an Image
Tables 5.21 and 5.22 describe built-in functions that write to a 2D and 3D image, respectively.
Table 5.21 Built-In Image 2D Write Functions
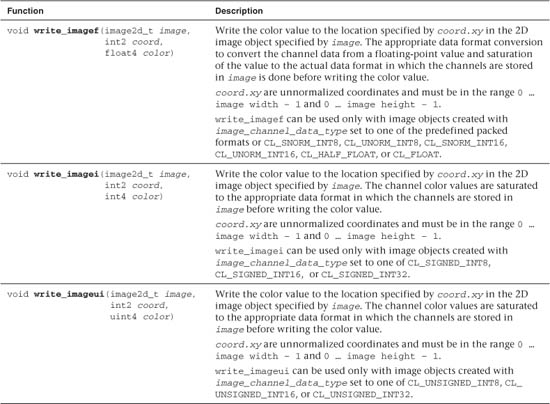
Table 5.22 Built-In Image 3D Write Functions
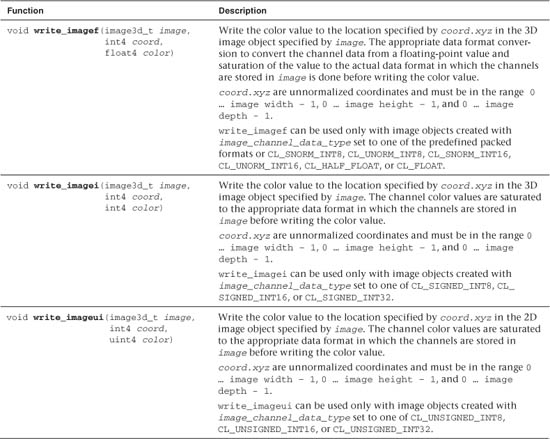
If the x coordinate is not in the range (0 ... image width – 1), or the y coordinate is not in the range (0 ... image height – 1), the behavior of write_imagef, write_imagei, or write_imageui for a 2D image is considered to be undefined.
If the x coordinate is not in the range (0 ... image width – 1), or the y coordinate is not in the range (0 ... image height – 1), or the z coordinate is not in the range (0 ... image depth – 1), the behavior of write_imagef, write_imagei, or write_imageui for a 3D image is considered to be undefined.
Querying Image Information
Table 5.23 describes the image query functions.
Table 5.23 Built-In Image Query Functions
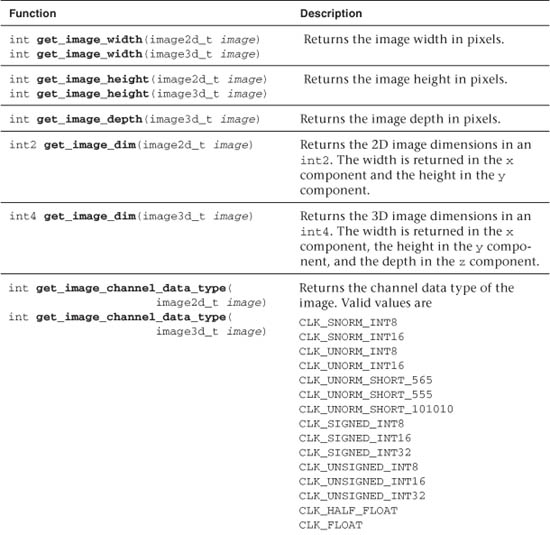

The values returned by get_image_channel_data_type and get_image_channel_order use a CLK_ prefix. There is a one-to-one mapping of the values with the CLK_ prefix to the corresponding CL_ prefixes specified in the image_channel_order and image_channel_data_type fields of the cl_image_format argument to clCreateImage2D and clCreateImage3D.