
Chapter 7. Buffers and Sub-Buffers
In Chapter 2, we created a simple example that executed a trivial parallel OpenCL kernel on a device, and in Chapter 3, we developed a simple convolution example. In both of these examples, memory objects, in these cases buffer objects, were created in order to facilitate the movement of data in and out of the compute device’s memory, from the host’s memory. Memory objects are fundamental in working with OpenCL and include the following types:
• Buffers: one-dimensional arrays of bytes
• Sub-buffers: one-dimensional views into buffers
• Images: two-dimensional or three-dimensional data structured arrays, which have limited access operators and a selection of different formats, sampling, and clamping features
In this chapter we cover buffer and sub-buffer objects in more detail. Specifically, this chapter covers
• Buffer and sub-buffer objects overview
• Creating buffer and sub-buffer objects
• Reading and writing buffers and sub-buffer objects
• Mapping buffer and sub-buffer objects
• Querying buffer and sub-buffer objects
Memory Objects, Buffers, and Sub-Buffers Overview
Memory objects are a fundamental concept in OpenCL. As mentioned previously, buffers and sub-buffers are instances of OpenCL memory objects, and this is also true for image objects, described in Chapter 8. In general, the operations on buffers and sub-buffers are disjoint from those of images, but there are some cases where generalized operations on memory objects are enough. For completeness we describe these operations here, too.
As introduced in Chapter 1, OpenCL memory objects are allocated against a context, which may have one or more associated devices. Memory objects are globally visible to all devices within the context. However, as OpenCL defines a relaxed memory model, it is not the case that all writes to a memory object are visible to all following reads of the same buffer. This is highlighted by the observation that, like other device commands, memory objects are read and written by enqueuing commands to a particular device. Memory object read/writes can be marked as blocking, causing the command-to-host thread to block until the enqueued command has completed and memory written to a particular device is visible by all devices associated with the particular context, or the memory read has been completely read back into host memory. If the read/write command is not blocking, then the host thread may return before the enqueued command has completed, and the application cannot assume that the memory being written or read is ready to consume from. In this case the host application must use one of the following OpenCL synchronization primitives to ensure that the command has completed:
• cl_int clFinish(cl_command_queue queue), where queue is the particular command-queue for which the read/write command was enqueued. clFinish will block until all pending commands, for queue, have completed.
• cl_int clWaitForEvents(cl_uint num_events, const cl_event * event_list), where event_list will contain at least the event returned from the enqueue command associated with the particular read/write. clWaitForEvents will block until all commands associated with corresponding events in event_list have completed.
OpenCL memory objects associated with different contexts must be used only with other objects created within the same context. For example, it is not possible to perform read/write operations with command-queues created with a different context. Because a context is created with respect to a particular platform, it is not possible to create memory objects that are shared across different platform devices. In the case that an application will use all OpenCL devices within the system, in general, data will need to be managed via the host memory space to copy data in and out of a given context and across contexts.
Creating Buffers and Sub-Buffers
Buffer objects are a one-dimensional memory resource that can hold scalar, vector, or user-defined data types. They are created using the following function:

Table 7.1 Supported Values for cl_mem_flags


Like other kernel parameters, buffers are passed as arguments to kernels using the function clSetKernelArg and are defined in the kernel itself by defining a pointer to the expected data type, in the global address space. The following code shows simple examples of how you might create a buffer and use it to set an argument to a kernel:
#define NUM_BUFFER_ELEMENTS 100
cl_int errNum;
cl_context;
cl_kernel kernel;
cl_command_queue queue;
float inputOutput[NUM_BUFFER_ELEMENTS];
cl_mem buffer;
// place code to create context, kernel, and command-queue here
// initialize inputOutput;
buffer = clCreateBuffer(
context,
CL_MEM_READ_WRITE | CL_MEM_COPY_HOST_PTR,
sizeof(float) * NUM_BUFFER_ELEMENTS,
&errNum);
// check for errors
errNum = setKernelArg(kernel, 0, sizeof(buffer), &buffer);
The following kernel definition shows a simple example of how you might specify it to take, as an argument, the buffer defined in the preceding example:
__kernel void square(__global float * buffer)
{
size_t id = get_global_id(0);
buffer[id] = buffer[id] * buffer[id];
}
Generalizing this to divide the work performed by the kernel square to all the devices associated with a particular context, the offset argument to clEnqueueNDRangeKernel can be used to calculate the offset into the buffers. The following code shows how this might be performed:
#define NUM_BUFFER_ELEMENTS 100
cl_int errNum;
cl_uint numDevices;
cl_device_id * deviceIDs;
cl_context;
cl_kernel kernel;
std::vector<cl_command_queue> queues;
float * inputOutput;
cl_mem buffer;
// place code to create context, kernel, and command-queue here
// initialize inputOutput;
buffer = clCreateBuffer(
context,
CL_MEM_READ_WRITE | CL_MEM_COPY_HOST_PTR,
sizeof(float) * NUM_BUFFER_ELEMENTS,
inputOutput,
&errNum);
// check for errors
errNum = setKernelArg(kernel, 0, sizeof(buffer), &buffer);
// Create a command-queue for each device
for (int i = 0; i < numDevices; i++)
{
cl_command_queue queue =
clCreateCommandQueue(
context,
deviceIDs[i],
0,
&errNum);
queues.push_back(queue);
}
// Submit kernel enqueue to each queue
for (int i = 0; i < queues.size(); i++)
{
cl_event event;
size_t gWI = NUM_BUFFER_ELEMENTS;
size_t offset = i * NUM_BUFFER_ELEMENTS * sizeof(int);
errNum = clEnqueueNDRangeKernel(
queues[i],
kernel,
1,
(const size_t*)&offset,
(const size_t*)&gWI,
(const size_t*)NULL,
0,
0,
&event);
events.push_back(event);
}
// wait for commands to complete
clWaitForEvents(events.size(), events.data());
An alternative, more general approach to subdividing the work performed on buffers is to use sub-buffers. Sub-buffers provide a view into a particular buffer, for example, enabling the developer to divide a single buffer into chunks that can be worked on independently. Sub-buffers are purely a software abstraction; anything that can be done with a sub-buffer can be done using buffers, explicit offsets, and so on. Sub-buffers provide a layer of additional modality not easily expressed using just buffers. The advantage of sub-buffers over the approach demonstrated previously is that they work with interfaces that expect buffers and require no additional knowledge such as offset values. Consider a library interface, for example, that is designed to expect an OpenCL buffer object but always assumes the first element is an offset zero. In this case it is not possible to use the previous approach without modifying the library source. Sub-buffers provide a solution to this problem.
Sub-buffers cannot be built from other sub-buffers.1 They are created using the following function:

Table 7.2 Supported Names and Values for clCreateSubBuffer

Returning to our previous example of dividing a buffer across multiple devices, the following code shows how this might be performed:
#define NUM_BUFFER_ELEMENTS 100
cl_int errNum;
cl_uint numDevices;
cl_device_id * deviceIDs;
cl_context;
cl_kernel kernel;
std::vector<cl_command_queue> queues;
std::vector<cl_mem> buffers;
float * inputOutput;
cl_mem buffer;
// place code to create context, kernel, and command-queue here
// initialize inputOutput;
buffer = clCreate(
context,
CL_MEM_READ_WRITE | CL_MEM_COPY_HOST_PTR,
sizeof(float) * NUM_BUFFER_ELEMENTS,
inputOutput,
&errNum);
buffers.push_back(buffer);
// Create command-queues
for (int i = 0; i < numDevices; i++)
{
cl_command_queue queue =
clCreateCommandQueue(
context,
deviceIDs[i],
0,
&errNum);
queues.push_back(queue);
cl_kernel kernel = clCreateKernel(
program,
"square",
&errNum);
errNum = clSetKernelArg(
kernel,
0,
sizeof(cl_mem),
(void *)&buffers[i]);
kernels.push_back(kernel);
}
std::vector<cl_event> events;
// call kernel for each device
for (int i = 0; i < queues.size(); i++)
{
cl_event event;
size_t gWI = NUM_BUFFER_ELEMENTS;
errNum = clEnqueueNDRangeKernel(
queues[i],
kernels[i],
1,
NULL,
(const size_t*)&gWI,
(const size_t*)NULL,
0,
0,
&event);
events.push_back(event);
}
// Wait for commands submitted to complete
clWaitForEvents(events.size(), events.data());
As is the case with other OpenCL objects, buffers and sub-buffer objects are reference-counted and the following two operations increment and decrement the reference count.
The following example increments the reference count for a buffer:

The next example decrements the reference count for a buffer:

When the reference count reaches 0, the OpenCL implementation is expected to release any associated memory with the buffer or sub-buffer. Once an implementation has freed resources for a buffer or sub-buffer, the object should not be referenced again in the program.
For example, to correctly release the OpenCL buffer resources in the previous sub-buffer example the following code could be used:
for (int i = 0; i < buffers.size(); i++)
{
buffers.clReleaseMemObject(buffers[i]);
}
Querying Buffers and Sub-Buffers
Like other OpenCL objects, buffers and sub-buffers can be queried to return information regarding how they were constructed, current status (e.g., reference count), and so on. The following command is used for buffer and sub-buffer queries:

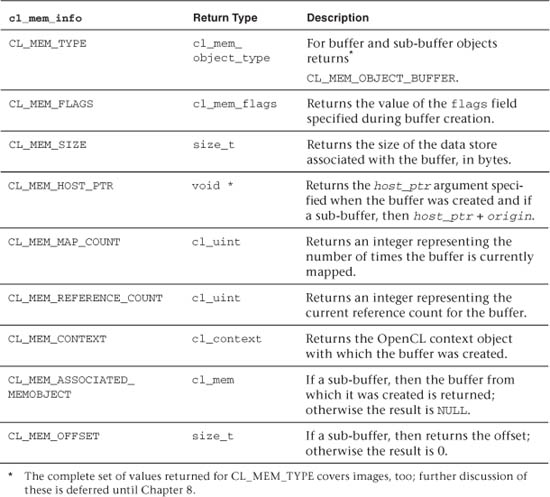
Table 7.3 OpenCL Buffer and Sub-Buffer Queries
The following code is a simple example of how you might query a memory object to determine if it is a buffer or some other kind of OpenCL memory object type:
cl_int errNum;
cl_mem memory;
cl_mem_object_type type;
// initialize memory object and so on
errNum = clGetMemObjectInfo(
memory,
CL_MEM_TYPE,
sizeof(cl_mem_object_type),
&type,
NULL);
switch(type)
{
case CL_MEM_OBJECT_BUFFER:
{
// handle case when object is buffer or sub-buffer
break;
}
case CL_MEM_OBJECT_IMAGE2D:
case CL_MEM_OBJECT_IMAGE3D:
{
// handle case when object is a 2D or 3D image
break;
}
default
// something very bad has happened
break;
}
Reading, Writing, and Copying Buffers and Sub-Buffers
Buffers and sub-buffers can be read and written by the host application, moving data to and from host memory. The following command enqueues a write command, to copy the contents of host memory into a buffer region:

Continuing with our previous buffer example, instead of copying the data in from the host pointer at buffer creation, the following code achieves the same behavior:
cl_mem buffer = clCreateBuffer(
context,
CL_MEM_READ_WRITE,
sizeof(int) * NUM_BUFFER_ELEMENTS * numDevices,
NULL,
&errNum);
// code to create sub-buffers, command-queues, and so on
// write data to buffer zero using command-queue zero
clEnqueueWriteBuffer(
queues[0],
buffers[0],
CL_TRUE,
0,
sizeof(int) * NUM_BUFFER_ELEMENTS * numDevices,
(void*)inputOutput,
0,
NULL,
NULL);
The following command enqueues a read command, to copy the contents of a buffer object into host memory:

Again continuing with our buffer example, the following example code reads back and displays the results of running the square kernel:
// Read back computed dat
clEnqueueReadBuffer(
queues[0],
buffers[0],
CL_TRUE,
0,
sizeof(int) * NUM_BUFFER_ELEMENTS * numDevices,
(void*)inputOutput,
0,
NULL,
NULL);
// Display output in rows
for (unsigned i = 0; i < numDevices; i++)
{
for (unsigned elems = i * NUM_BUFFER_ELEMENTS;
elems < ((i+1) * NUM_BUFFER_ELEMENTS);
elems++)
{
std::cout << " " << inputOutput[elems];
}
std::cout << std::endl;
}
Listings 7.1 and 7.2 put this all together, demonstrating creating, writing, and reading buffers to square an input vector.
Listing 7.1 Creating, Writing, and Reading Buffers and Sub-Buffers Example Kernel Code
simple.cl
__kernel void square(
__global int * buffer)
{
const size_t id = get_global_id(0);
buffer[id] = buffer[id] * buffer[id];
}
Listing 7.2 Creating, Writing, and Reading Buffers and Sub-Buffers Example Host Code
simple.cpp
#include <iostream>
#include <fstream>
#include <sstream>
#include <string>
#include <vector>
#include "info.hpp"
// If more than one platform installed then set this to pick which
// one to use
#define PLATFORM_INDEX 0
#define NUM_BUFFER_ELEMENTS 10
// Function to check and handle OpenCL errors inline void
checkErr(cl_int err, const char * name)
{
if (err != CL_SUCCESS) {
std::cerr << "ERROR: "
<< name << " (" << err << ")" << std::endl;
exit(EXIT_FAILURE);
}
}
///
// main() for simple buffer and sub-buffer example
//
int main(int argc, char** argv)
{
cl_int errNum;
cl_uint numPlatforms;
cl_uint numDevices;
cl_platform_id * platformIDs;
cl_device_id * deviceIDs;
cl_context context;
cl_program program;
std::vector<cl_kernel> kernels;
std::vector<cl_command_queue> queues;
std::vector<cl_mem> buffers;
int * inputOutput;
std::cout << "Simple buffer and sub-buffer Example"
<< std::endl;
// First, select an OpenCL platform to run on.
errNum = clGetPlatformIDs(0, NULL, &numPlatforms);
checkErr(
(errNum != CL_SUCCESS) ?
errNum : (numPlatforms <= 0 ? -1 : CL_SUCCESS),
"clGetPlatformIDs");
platformIDs = (cl_platform_id *)alloca(
sizeof(cl_platform_id) * numPlatforms);
std::cout << "Number of platforms: "
<< numPlatforms
<< std::endl;
errNum = clGetPlatformIDs(numPlatforms, platformIDs, NULL);
checkErr(
(errNum != CL_SUCCESS) ?
errNum : (numPlatforms <= 0 ? -1 : CL_SUCCESS),
"clGetPlatformIDs");
std::ifstream srcFile("simple.cl");
checkErr(srcFile.is_open() ?
CL_SUCCESS : -1,
"reading simple.cl");
std::string srcProg(
std::istreambuf_iterator<char>(srcFile),
(std::istreambuf_iterator<char>()));
const char * src = srcProg.c_str();
size_t length = srcProg.length();
deviceIDs = NULL;
DisplayPlatformInfo(
platformIDs[PLATFORM_INDEX],
CL_PLATFORM_VENDOR,
"CL_PLATFORM_VENDOR");
errNum = clGetDeviceIDs(
platformIDs[PLATFORM_INDEX],
CL_DEVICE_TYPE_ALL,
0,
NULL,
&numDevices);
if (errNum != CL_SUCCESS && errNum != CL_DEVICE_NOT_FOUND)
{
checkErr(errNum, "clGetDeviceIDs");
}
deviceIDs = (cl_device_id *)alloca(
sizeof(cl_device_id) * numDevices);
errNum = clGetDeviceIDs(
platformIDs[PLATFORM_INDEX],
CL_DEVICE_TYPE_ALL,
numDevices,
&deviceIDs[0],
NULL);
checkErr(errNum, "clGetDeviceIDs");
cl_context_properties contextProperties[] =
{
CL_CONTEXT_PLATFORM,
(cl_context_properties)platformIDs[PLATFORM_INDEX],
0
};
context = clCreateContext(
contextProperties,
numDevices,
deviceIDs,
NULL,
NULL,
&errNum);
checkErr(errNum, "clCreateContext");
// Create program from source
program = clCreateProgramWithSource(
context,
1,
&src,
&length,
&errNum);
checkErr(errNum, "clCreateProgramWithSource");
// Build program
errNum = clBuildProgram(
program,
numDevices,
deviceIDs,
"-I.",
NULL,
NULL);
if (errNum != CL_SUCCESS)
{
// Determine the reason for the error
char buildLog[16384];
clGetProgramBuildInfo(
program,
deviceIDs[0],
CL_PROGRAM_BUILD_LOG,
sizeof(buildLog),
buildLog,
NULL);
std::cerr << "Error in OpenCL C source: " << std::endl;
std::cerr << buildLog;
checkErr(errNum, "clBuildProgram");
}
// create buffers and sub-buffers
inputOutput = new int[NUM_BUFFER_ELEMENTS * numDevices];
for (unsigned int i = 0;
i < NUM_BUFFER_ELEMENTS * numDevices;
i++)
{
inputOutput[i] = i;
}
// create a single buffer to cover all the input data
cl_mem buffer = clCreateBuffer(
context,
CL_MEM_READ_WRITE,
sizeof(int) * NUM_BUFFER_ELEMENTS * numDevices,
NULL,
&errNum);
checkErr(errNum, "clCreateBuffer");
buffers.push_back(buffer);
// now for all devices other than the first create a sub-buffer
for (unsigned int i = 1; i < numDevices; i++)
{
cl_buffer_region region =
{
NUM_BUFFER_ELEMENTS * i * sizeof(int),
NUM_BUFFER_ELEMENTS * sizeof(int)
};
buffer = clCreateSubBuffer(
buffers[0],
CL_MEM_READ_WRITE,
CL_BUFFER_CREATE_TYPE_REGION,
®ion,
&errNum);
checkErr(errNum, "clCreateSubBuffer");
buffers.push_back(buffer);
}
// Create command-queues
for (int i = 0; i < numDevices; i++)
{
InfoDevice<cl_device_type>::display(
deviceIDs[i],
CL_DEVICE_TYPE,
"CL_DEVICE_TYPE");
cl_command_queue queue =
clCreateCommandQueue(
context,
deviceIDs[i],
0,
&errNum);
checkErr(errNum, "clCreateCommandQueue");
queues.push_back(queue);
cl_kernel kernel = clCreateKernel(
program,
"square",
&errNum);
checkErr(errNum, "clCreateKernel(square)");
errNum = clSetKernelArg(
kernel,
0,
sizeof(cl_mem), (void *)&buffers[i]);
checkErr(errNum, "clSetKernelArg(square)");
kernels.push_back(kernel);
}
// Write input data
clEnqueueWriteBuffer(
queues[0],
buffers[0],
CL_TRUE,
0,
sizeof(int) * NUM_BUFFER_ELEMENTS * numDevices,
(void*)inputOutput,
0,
NULL,
NULL);
std::vector<cl_event> events;
// call kernel for each device
for (int i = 0; i < queues.size(); i++)
{
cl_event event;
size_t gWI = NUM_BUFFER_ELEMENTS;
errNum = clEnqueueNDRangeKernel(
queues[i],
kernels[i],
1,
NULL,
(const size_t*)&gWI,
(const size_t*)NULL,
0,
0,
&event);
events.push_back(event);
}
// Technically don't need this as we are doing a blocking read
// with in-order queue.
clWaitForEvents(events.size(), events.data());
// Read back computed data
clEnqueueReadBuffer(
queues[0],
buffers[0],
CL_TRUE,
0,
sizeof(int) * NUM_BUFFER_ELEMENTS * numDevices,
(void*)inputOutput,
0,
NULL,
NULL);
// Display output in rows
for (unsigned i = 0; i < numDevices; i++)
{
for (unsigned elems = i * NUM_BUFFER_ELEMENTS;
elems < ((i+1) * NUM_BUFFER_ELEMENTS);
elems++)
{
std::cout << " " << inputOutput[elems];
}
std::cout << std::endl;
}
std::cout << "Program completed successfully" << std::endl;
return 0;
}
OpenCL 1.1 introduced the ability to read and write rectangular segments of a buffer in two or three dimensions. This can be particularly useful when working on data that, conceptually at least, is of a dimension greater than 1, which is how OpenCL sees all buffer objects. A simple example showing a two-dimensional array is given in Figure 7.1(a) and a corresponding segment, often referred to as a slice, in Figure 7.1(b).
Figure 7.1 (a) 2D array represented as an OpenCL buffer; (b) 2D slice into the same buffer
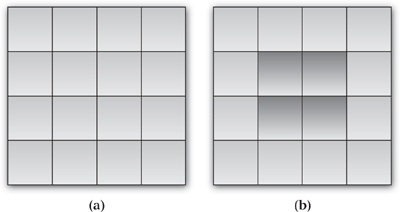
Segments are limited to contiguous regions of memory within the buffer, although they can have a row and slice pitch to handle corner cases such as alignment constraints. These can be different for the host memory being addressed as well as the buffer being read or written.
A two-dimensional or three-dimensional region of a buffer can be read into host memory with the following function:


There are rules that an implementation of clEnqueueReadBufferRect will use to calculate the region into the buffer and the region into the host memory, which are summarized as follows:
• The offset into the memory region associated with the buffer is calculated by
buffer_origin[2] * buffer_slice_pitch +
buffer_origin[1] * buffer_row_pitch +
buffer_origin[0]
In the case of a 2D rectangle region, buffer_origin[2] must be 0.
• The offset into the memory region associated with the host memory is calculated by
host_origin[2] * host_slice_pitch +
host_origin[1] * host_row_pitch +
host_origin[0]
In the case of a 2D rectangle region, buffer_origin[2] must be 0.
As a simple example, like that shown in Figure 7.1, the following code demonstrates how one might read a 2×2 region from a buffer into host memory, displaying the result:
#define NUM_BUFFER_ELEMENTS 16
cl_int errNum;
cl_command_queue queue;
cl_context context;
cl_mem buffer;
// initialize context, queue, and so on
cl_int hostBuffer[NUM_BUFFER_ELEMENTS] =
{
0, 1, 2, 3, 4, 5, 6, 7,
8, 9, 10, 11, 12, 13, 14, 15
};
buffer = clCreateBuffer(
context,
CL_MEM_READ | CL_MEM_COPY_HOST_PTR,
sizeof(int) * NUM_BUFFER_ELEMENTS,
hostBuffer,
&errNum);
int ptr[4] = {-1, -1, -1, -1};
size_t buffer_origin[3] = {1*sizeof(int), 1, 0};
size_t host_origin[3] = {0,0, 0};
size_t region[3] = {2* sizeof(int), 2,1};
errNum = clEnqueueReadBufferRect(
queue,
buffer,
CL_TRUE,
buffer_origin,
host_origin,
region,
(NUM_BUFFER_ELEMENTS / 4) * sizeof(int),
0,
0,
2*sizeof(int),
static_cast<void*>(ptr),
0,
NULL,
NULL);
std::cout << " " << ptr[0];
std::cout << " " << ptr[1] << std::endl;
std::cout << " " << ptr[2];
std::cout << " " << ptr[3] << std::endl;
Placing this code in a full program and running it results in the following output, as shown in Figure 7.1:
5 6
9 10
A two- or three-dimensional region of a buffer can be written into a buffer from host memory with the following function:


There are often times when an application needs to copy data between two buffers; OpenCL provides the following command for this:

While not required, as this functionality can easily be emulated by reading the data back to the host and then writing to the destination buffer, it is recommended that an application call clEnqueueCopyBuffer as it allows the OpenCL implementation to manage placement of data and transfers. As with reading and writing a buffer, it is possible to copy a 2D or 3D region of a buffer to another buffer using the following command:


Mapping Buffers and Sub-Buffers
OpenCL provides the ability to map a region of a buffer directly into host memory, allowing the memory to be copied in and out using standard C/C++ code. Mapping buffers and sub-buffers has the advantage that the returned host pointer can be passed into libraries and other function abstractions that may be unaware that the memory being accessed is managed and used by OpenCL. The following function enqueues a command to map a region of a particular buffer object into the host address space, returning a pointer to this mapped region:


Table 7.4 Supported Values for cl_map_flags

To release any additional resources and to tell the OpenCL runtime that buffer mapping is no longer required, the following command can be used:

We now return to the example given in Listings 7.1 and 7.2. The following code shows how clEnqueueMapBuffer and clEnqueueUnmapMemObject could have been used to move data to and from the buffer being processed rather than clEnqueueReadBuffer and clEnqueueWriteBuffer. The following code initializes the buffer:
cl_int * mapPtr = (cl_int*) clEnqueueMapBuffer(
queues[0],
buffers[0],
CL_TRUE,
CL_MAP_WRITE,
0,
sizeof(cl_int) * NUM_BUFFER_ELEMENTS * numDevices,
0,
NULL,
NULL,
&errNum);
checkErr(errNum, "clEnqueueMapBuffer(..)");
for (unsigned int i = 0;
i < NUM_BUFFER_ELEMENTS * numDevices;
i++)
{
mapPtr[i] = inputOutput[i];
}
errNum = clEnqueueUnmapMemObject(
queues[0],
buffers[0],
mapPtr,
0,
NULL,
NULL);
clFinish(queues[0]);
The following reads the final data back:
cl_int * mapPtr = (cl_int*) clEnqueueMapBuffer(
queues[0],
buffers[0],
CL_TRUE,
CL_MAP_READ,
0,
sizeof(cl_int) * NUM_BUFFER_ELEMENTS * numDevices,
0,
NULL,
NULL,
&errNum);
checkErr(errNum, "clEnqueueMapBuffer(..)");
for (unsigned int i = 0;
i < NUM_BUFFER_ELEMENTS * numDevices;
i++)
{
inputOutput[i] = mapPtr[i];
}
errNum = clEnqueueUnmapMemObject(
queues[0],
buffers[0],
mapPtr,
0,
NULL,
NULL);
clFinish(queues[0]);