
Chapter 3. Platforms, Contexts, and Devices
Chapter 2 described an OpenCL program that included the basic API calls to create a context, device, program, kernel, and memory buffers; write and read the buffers; and finally execute the kernel on the chosen device. This chapter looks, in more detail, at OpenCL contexts (i.e., environments) and devices and covers the following concepts:
• Enumerating and querying OpenCL platforms
• Enumerating and querying OpenCL devices
• Creating contexts, associating devices, and the corresponding synchronization and memory management defined by this implied environment
OpenCL Platforms
As discussed in Chapter 2, the first step of an OpenCL application is to query the set of OpenCL platforms and choose one or more of them to use in the application. Associated with a platform is a profile, which describes the capabilities of the particular OpenCL version supported. A profile can be either the full profile, which covers functionality defined as part of the core specification, or the embedded profile, defined as a subset of the full profile which in particular drops some of the requirements of floating conformance to the IEEE 754 standard. For the most part this book covers the full profile, and Chapter 13 covers the differences with the embedded profile in detail.
The set of platforms can be queried with the command
This command obtains the list of available OpenCL platforms. In the case that the argument platforms is NULL, then clGetPlatformIDs returns the number of available platforms. The number of platforms returned can be limited with num_entries, which can be greater than 0 and less than or equal to the number of available platforms.
You can query the number of available platforms by setting the arguments num_entries and platforms to 0 and NULL, respectively. In the case of Apple’s implementation this step is not necessary, and rather than passing a queried platform to other API calls, such as clGetDeviceIds(), the value NULL is passed instead.
As a simple example of how you might query and select a platform, we use clGetPlatformIDs() to obtain a list of platform IDs:
cl_int errNum;
cl_uint numPlatforms;
cl_platform_id * platformIds;
cl_context context = NULL;
errNum = clGetPlatformIDs(0, NULL, &numPlatforms);
platformIds = (cl_platform_id *)alloca(
sizeof(cl_platform_id) * numPlatforms);
errNum = clGetPlatformIDs(numPlatforms, platformIds, NULL);
Given a platform, you can query a variety of properties with the command
This command returns specific information about the OpenCL platform. The allowable values for param_name are described in Table 3.1.
Table 3.1 OpenCL Platform Queries
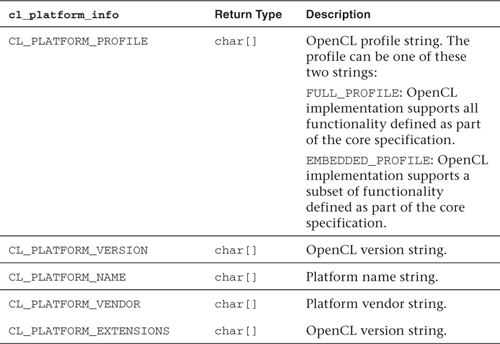
The set of valid queries is given in Table 3.1, and you can query the size of a returned value by setting the values of param_value_size and param_value to 0 and NULL, respectively.
As a simple example of how you might query and select a platform, we use clGetPlatformInfo() to obtain the associated platform name and vendor strings:
cl_int err;
size_t size;
err = clGetPlatformInfo(id, CL_PLATFORM_NAME, 0, NULL, &size);
char * name = (char *)alloca(sizeof(char) * size);
err = clGetPlatformInfo(id, CL_PLATFORM_NAME, size, info, NULL);
err = clGetPlatformInfo(id, CL_PLATFORM_VENDOR, 0, NULL, &size);
char * vname = (char *)alloca(sizeof(char) * size);
err = clGetPlatformInfo(id, CL_PLATFORM_VENDOR, size, info, NULL);
std::cout << "Platform name: " << name << std::endl
<< "Vendor name : " << vname << std::endl;
On ATI Stream SDK this code displays
Platform name: ATI Stream
Vendor name : Advanced Micro Devices, Inc.
Putting this all together, Listing 3.1 enumerates the set of available platforms, and Listing 3.2 queries and outputs the information associated with a particular platform.
Listing 3.1 Enumerating the List of Platforms
void displayInfo(void)
{
cl_int errNum;
cl_uint numPlatforms;
cl_platform_id * platformIds;
cl_context context = NULL;
// First, query the total number of platforms
errNum = clGetPlatformIDs(0, NULL, &numPlatforms);
if (errNum != CL_SUCCESS || numPlatforms <= 0)
{
std::cerr << "Failed to find any OpenCL platform." << std::endl;
return;
}
// Next, allocate memory for the installed platforms, and query
// to get the list.
platformIds = (cl_platform_id *)alloca(
sizeof(cl_platform_id) * numPlatforms);
// Query the platform IDs
errNum = clGetPlatformIDs(numPlatforms, platformIds, NULL);
if (errNum != CL_SUCCESS)
{
std::cerr << "Failed to find any OpenCL platforms."
<< std::endl;
return;
}
std::cout << "Number of platforms: "
<< numPlatforms
<< std::endl;
// Iterate through the list of platforms displaying associated
// information
for (cl_uint i = 0; i < numPlatforms; i++) {
// First we display information associated with the platform
DisplayPlatformInfo(
platformIds[i], CL_PLATFORM_PROFILE, "CL_PLATFORM_PROFILE");
DisplayPlatformInfo(
platformIds[i], CL_PLATFORM_VERSION, "CL_PLATFORM_VERSION");
DisplayPlatformInfo(
platformIds[i], CL_PLATFORM_VENDOR, "CL_PLATFORM_VENDOR");
DisplayPlatformInfo(
platformIds[i],
CL_PLATFORM_EXTENSIONS,
"CL_PLATFORM_EXTENSIONS");
}
}
Listing 3.2 Querying and Displaying Platform-Specific Information
void DisplayPlatformInfo(
cl_platform_id id,
cl_platform_info name,
std::string str)
{
cl_int errNum;
std::size_t paramValueSize;
errNum = clGetPlatformInfo(
id,
name,
0,
NULL,
¶mValueSize);
if (errNum != CL_SUCCESS)
{
std::cerr << "Failed to find OpenCL platform "
<< str << "." << std::endl;
return;
}
char * info = (char *)alloca(sizeof(char) * paramValueSize);
errNum = clGetPlatformInfo(
id,
name,
paramValueSize,
info,
NULL);
if (errNum != CL_SUCCESS)
{
std::cerr << "Failed to find OpenCL platform "
<< str << "." << std::endl;
return;
}
std::cout << " " << str << ": " << info << std::endl;
}
OpenCL Devices
Associated with each platform is a set of compute devices that an application uses to execute code. Given a platform, a list of supported devices can be queried with the command
This command obtains the list of available OpenCL devices associated with platform. In the case that the argument devices is NULL, then clGetDeviceIDs returns the number of devices. The number of devices returned can be limited with num_entries, where 0 < num_entries <= number of devices.
The type of compute device is specified by the argument device_type and can be one of the values given in Table 3.2. Each device shares the same execution and memory model as described in Chapter 1 and captured in Figures 1.6, 1.7, and 1.8.
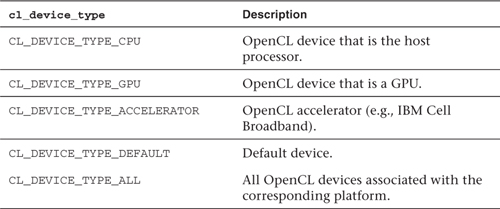
The CPU device is a single homogeneous device that maps across the set of available cores or some subset thereof. They are often optimized, using large caches, for latency hiding; examples include AMD’s Opteron series and Intel’s Core i7 family.
The GPU device corresponds to the class of throughput-optimized devices marketed toward both graphics and general-purpose computing. Well-known examples include ATI’s Radeon family and NVIDIA’s GTX series.
The accelerator device is intended to cover a broad range of devices ranging from IBM’s Cell Broadband architecture to less well-known DSP-style devices.
The default device and all device options allow the OpenCL runtime to assign a “preferred” device and all the available devices, respectively.
For the CPU, GPU, and accelerator devices there is no limit on the number that are exposed by a particular platform, and the application is responsible for querying to determine the actual number. The following example shows how you can query and select a single GPU device given a platform, using clGetDeviceIDs and first checking that there is at least one such device available:
cl_int errNum;
cl_uint numDevices;
cl_device_id deviceIds[1];
errNum = clGetDeviceIDs(
platform,
CL_DEVICE_TYPE_GPU,
0,
NULL,
&numDevices);
if (numDevices < 1)
{
std::cout << "No GPU device found for platform "
<< platform << std::endl;
exit(1);
}
errNum = clGetDeviceIDs(
platform,
CL_DEVICE_TYPE_GPU,
1,
&deviceIds[0],
NULL);
Given a device, you can query a variety of properties with the command
This command returns specific information about the OpenCL platform. The allowable values for param_name are described in Table 3.3. The size of a returned value can be queried by setting the values of param_value_size and param_value to 0 and NULL, respectively.1
Table 3.3 OpenCL Device Queries
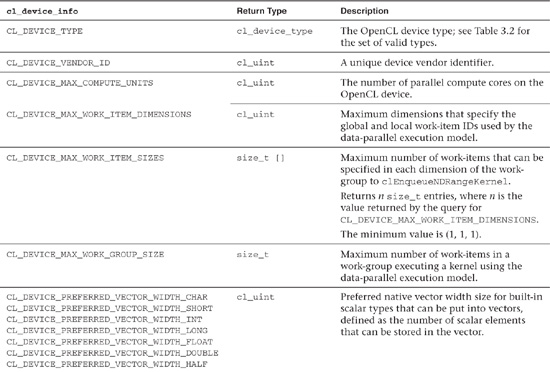
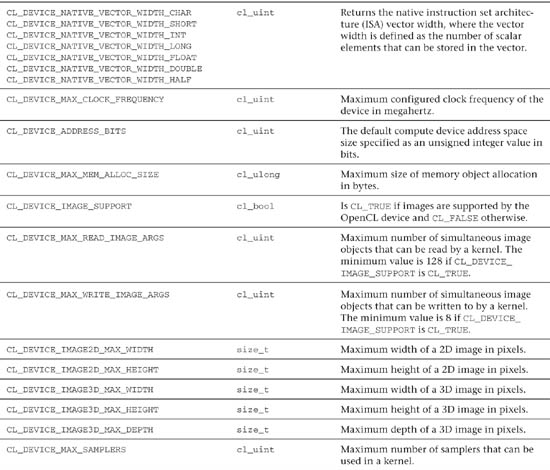
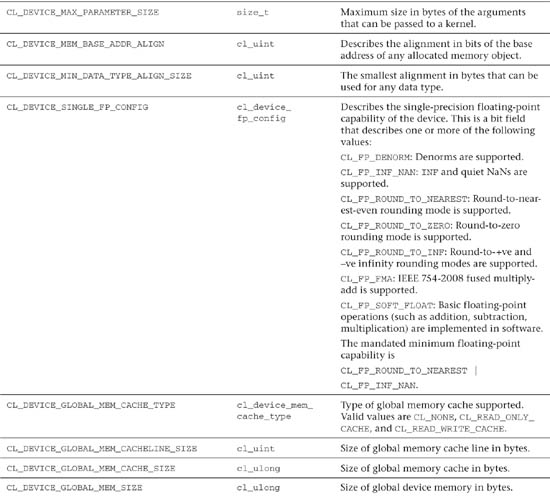
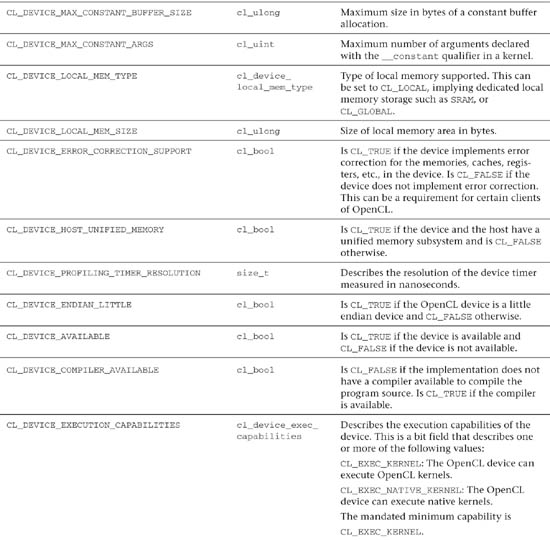
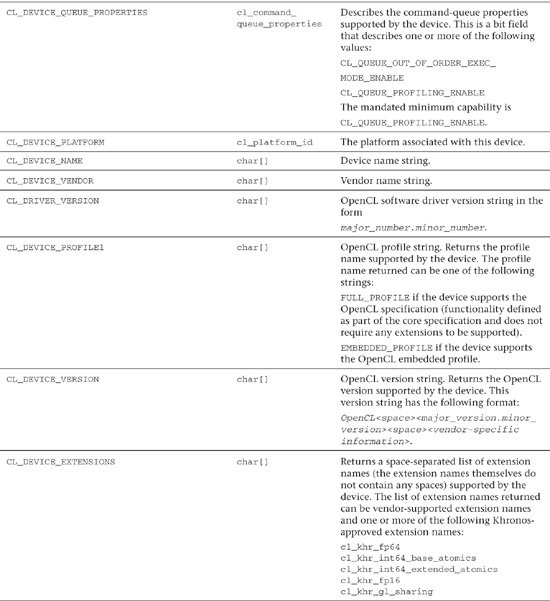
Following is a simple example of how you can query a device, using clGetDeviceInfo(), to obtain the maximum number of compute units:
cl_int err;
size_t size;
err = clGetDeviceInfo(
deviceID,
CL_DEVICE_MAX_COMPUTE_UNITS,
sizeof(cl_uint),
&maxComputeUnits,
&size);
std::cout << "Device has max compute units: "
<< maxComputeUnits << std::endl;
On ATI Stream SDK this code displays the following for an Intel i7 CPU device:
Device 4098 has max compute units: 8
Putting this all together, Listing 3.3 demonstrates a method for wrapping the query capabilities of a device in a straightforward, single call interface.2
Listing 3.3 Example of Querying and Displaying Platform-Specific Information
template<typename T>
void appendBitfield(
T info, T value, std::string name, std::string & str)
{
if (info & value)
{
if (str.length() > 0)
{
str.append(" | ");
}
str.append(name);
}
}
template <typename T>
class InfoDevice
{
public:
static void display(
cl_device_id id, cl_device_info name, std::string str)
{
cl_int errNum;
std::size_t paramValueSize;
errNum = clGetDeviceInfo(id, name, 0, NULL, ¶mValueSize);
if (errNum != CL_SUCCESS)
{
std::cerr << "Failed to find OpenCL device info "
<< str << "." << std::endl;
return;
}
T * info = (T *)alloca(sizeof(T) * paramValueSize);
errNum = clGetDeviceInfo(id,name,paramValueSize,info,NULL);
if (errNum != CL_SUCCESS)
{
std::cerr << "Failed to find OpenCL device info "
<< str << "." << std::endl;
return;
}
switch (name)
{
case CL_DEVICE_TYPE:
{
std::string deviceType;
appendBitfield<cl_device_type>(
*(reinterpret_cast<cl_device_type*>(info)),
CL_DEVICE_TYPE_CPU, "CL_DEVICE_TYPE_CPU", deviceType);
appendBitfield<cl_device_type>(
*(reinterpret_cast<cl_device_type*>(info)),
CL_DEVICE_TYPE_GPU, "CL_DEVICE_TYPE_GPU", deviceType);
appendBitfield<cl_device_type>(
*(reinterpret_cast<cl_device_type*>(info)),
CL_DEVICE_TYPE_ACCELERATOR,
"CL_DEVICE_TYPE_ACCELERATOR",
deviceType);
appendBitfield<cl_device_type>(
*(reinterpret_cast<cl_device_type*>(info)),
CL_DEVICE_TYPE_DEFAULT,
"CL_DEVICE_TYPE_DEFAULT",
deviceType);
std::cout << " " << str << ": "
<< deviceType << std::endl;
}
break;
case CL_DEVICE_SINGLE_FP_CONFIG:
{
std::string fpType;
appendBitfield<cl_device_fp_config>(
*(reinterpret_cast<cl_device_fp_config*>(info)),
CL_FP_DENORM, "CL_FP_DENORM", fpType);
appendBitfield<cl_device_fp_config>(
*(reinterpret_cast<cl_device_fp_config*>(info)),
CL_FP_INF_NAN, "CL_FP_INF_NAN", fpType);
appendBitfield<cl_device_fp_config>(
*(reinterpret_cast<cl_device_fp_config*>(info)),
CL_FP_ROUND_TO_NEAREST,
"CL_FP_ROUND_TO_NEAREST",
fpType);
appendBitfield<cl_device_fp_config>(
*(reinterpret_cast<cl_device_fp_config*>(info)),
CL_FP_ROUND_TO_ZERO, "CL_FP_ROUND_TO_ZERO", fpType);
appendBitfield<cl_device_fp_config>(
*(reinterpret_cast<cl_device_fp_config*>(info)),
CL_FP_ROUND_TO_INF, "CL_FP_ROUND_TO_INF", fpType);
appendBitfield<cl_device_fp_config>(
*(reinterpret_cast<cl_device_fp_config*>(info)),
CL_FP_FMA, "CL_FP_FMA", fpType);
appendBitfield<cl_device_fp_config>(
*(reinterpret_cast<cl_device_fp_config*>(info)),
CL_FP_SOFT_FLOAT, "CL_FP_SOFT_FLOAT", fpType);
std::cout << " " << str << ": " << fpType << std::endl;
}
break;
case CL_DEVICE_GLOBAL_MEM_CACHE_TYPE:
{
std::string memType;
appendBitfield<cl_device_mem_cache_type>(
*(reinterpret_cast<cl_device_mem_cache_type*>(info)),
CL_NONE, "CL_NONE", memType);
appendBitfield<cl_device_mem_cache_type>(
*(reinterpret_cast<cl_device_mem_cache_type*>(info)),
CL_READ_ONLY_CACHE, "CL_READ_ONLY_CACHE", memType);
appendBitfield<cl_device_mem_cache_type>(
*(reinterpret_cast<cl_device_mem_cache_type*>(info)),
CL_READ_WRITE_CACHE, "CL_READ_WRITE_CACHE", memType);
std::cout << " " << str << ": " << memType << std::endl;
}
break;
case CL_DEVICE_LOCAL_MEM_TYPE:
{
std::string memType;
appendBitfield<cl_device_local_mem_type>(
*(reinterpret_cast<cl_device_local_mem_type*>(info)),
CL_GLOBAL, "CL_LOCAL", memType);
appendBitfield<cl_device_local_mem_type>(
*(reinterpret_cast<cl_device_local_mem_type*>(info)),
CL_GLOBAL, "CL_GLOBAL", memType);
std::cout << " " << str << ": " << memType << std::endl;
}
break;
case CL_DEVICE_EXECUTION_CAPABILITIES:
{
std::string memType;
appendBitfield<cl_device_exec_capabilities>(
*(reinterpret_cast<cl_device_exec_capabilities*>(info)),
CL_EXEC_KERNEL, "CL_EXEC_KERNEL", memType);
appendBitfield<cl_device_exec_capabilities>(
*(reinterpret_cast<cl_device_exec_capabilities*>(info)),
CL_EXEC_NATIVE_KERNEL, "CL_EXEC_NATIVE_KERNEL", memType);
std::cout << " " << str << ": " << memType << std::endl;
}
break;
case CL_DEVICE_QUEUE_PROPERTIES:
{
std::string memType;
appendBitfield<cl_device_exec_capabilities>(
*(reinterpret_cast<cl_device_exec_capabilities*>(info)),
CL_QUEUE_OUT_OF_ORDER_EXEC_MODE_ENABLE,
"CL_QUEUE_OUT_OF_ORDER_EXEC_MODE_ENABLE", memType);
appendBitfield<cl_device_exec_capabilities>(
*(reinterpret_cast<cl_device_exec_capabilities*>(info)),
CL_QUEUE_PROFILING_ENABLE, "CL_QUEUE_PROFILING_ENABLE",
memType);
std::cout << " " << str << ": " << memType << std::endl;
}
break;
default:
std::cout << " " << str << ": " << *info << std::endl;
break;
}
}
};
The template class InfoDevice does the hard work, proving the single public method, display(), to retrieve and display the requested information. The earlier example, querying a device’s maximum compute units, can be recast as follows:
InfoDevice<cl_uint>::display(
deviceID,
CL_DEVICE_MAX_COMPUTE_UNITS,
"DEVICE has max compute units");
OpenCL Contexts
Contexts are the heart of any OpenCL application. Contexts provide a container for associated devices, memory objects (e.g., buffers and images), and command-queues (providing an interface between the context and an individual device). It is the context that drives communication with, and between, specific devices, and OpenCL defines its memory model in terms of these. For example, a memory object is allocated with a context but can be updated by a particular device, and OpenCL’s memory guarantees that all devices, within the same context, will see these updates at well-defined synchronization points.
It is important to realize that while these stages often form the foundation of any OpenCL program, there is no reason not to use multiple contexts, each created from a different platform, and distribute work across the contexts and associated devices. The difference is that OpenCL’s memory model is not lifted across devices, and this means that corresponding memory objects cannot be shared by different contexts, created either from the same or from different platforms. The implication of this is that any data that is to be shared across contexts must be manually moved between contexts. This concept is captured in Figure 3.1.
Figure 3.1 Platform, devices, and contexts
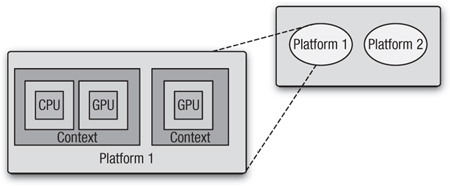
Unlike platforms and devices, often queried at the beginning of the program or library, a context is something you may want to update as the program progresses, allocating or deleting memory objects and so on. In general, an application’s OpenCL usage looks similar to this:
1. Query which platforms are present.
2. Query the set of devices supported by each platform:
a. Choose to select devices, using clGetDeviceInfo(), on specific capabilities.
3. Create contexts from a selection of devices (each context must be created with devices from a single platform); then with a context you can
a. Create one or more command-queues
b. Create programs to run on one or more associated devices
c. Create a kernel from those programs
d. Allocate memory buffers and images, either on the host or on the device(s)
e. Write or copy data to and from a particular device
f. Submit kernels (setting the appropriate arguments) to a command-queue for execution
Given a platform and a list of associated devices, an OpenCL context is created with the command clCreateContext(), and with a platform and device type, clCreateContextFromType() can be used. These two functions are declared as
This creates an OpenCL context. The allowable values for the argument properties are described in Table 3.4.
Table 3.4 Properties Supported by clCreateContext

The list of properties is limited to the platform with which the context is associated. Other context properties are defined with certain OpenCL extensions. See Chapters 10 and 11 on sharing with graphics APIs, for examples. The arguments devices and device_type allow the set of devices to be specified explicitly or restricted to a certain type of device, respectively. The arguments pfn_notify and user_data are used together to define a callback that is called to report information on errors that occur during the lifetime of the context, with user_data being passed as the last argument to the callback.
The following example shows that given a platform, you can query for the set of GPU devices and create a context, if one or more devices are available:
cl_platform pform;
size_t num;
cl_device_id * devices;
cl_context context;
size_t size;
clGetDeviceIDs(platform, CL_DEVICE_TYPE_GPU, 0, NULL, &num);
if (num > 0)
{
devices = (cl_device_id *)alloca(num * sizeof(cl_device_id));
clGetDeviceIDs(
platform,
CL_DEVICE_TYPE_GPU,
num,
devices[0],
NULL);
}
cl_context_properties properties [] =
{
CL_CONTEXT_PLATFORM, (cl_context_properties)platform, 0
};
context = clCreateContext(
properties,
size / sizeof(cl_device_id),
devices,
NULL,
NULL,
NULL);
Given a context, you can query a variety of properties with the command
This command returns specific information about the OpenCL context. The allowable values for param_name, defining the set of valid queries, are described in Table 3.5.
Table 3.5 Context Information Queries

Following is an example of how you can query a context, using clGetContextInfo(), to obtain the list of associated devices:
cl_uint numPlatforms;
cl_platform_id * platformIDs;
cl_context context = NULL;
size_t size;
clGetPlatformIDs(0, NULL, &numPlatforms);
platformIDs = (cl_platform_id *)alloca(
sizeof(cl_platform_id) * numPlatforms);
clGetPlatformIDs(numPlatforms, platformIDs, NULL);
cl_context_properties properties[] =
{
CL_CONTEXT_PLATFORM, (cl_context_properties)platformIDs[0], 0
};
context = clCreateContextFromType(
properties, CL_DEVICE_TYPE_ALL, NULL, NULL, NULL);
clGetContextInfo(context, CL_CONTEXT_DEVICES, 0, NULL, &size);
cl_device_id * devices = (cl_device_id*)alloca(
sizeof(cl_device_id) * size);
clGetContextInfo(context,CL_CONTEXT_DEVICES, size, devices, NULL);
for (size_t i = 0; i < size / sizeof(cl_device_id); i++)
{
cl_device_type type;
clGetDeviceInfo(
devices[i],CL_DEVICE_TYPE, sizeof(cl_device_type), &type, NULL);
switch (type)
{
case CL_DEVICE_TYPE_GPU:
std::cout << "CL_DEVICE_TYPE_GPU" << std::endl;
break;
case CL_DEVICE_TYPE_CPU:
std::cout << "CL_DEVICE_TYPE_CPU" << std::endl;
break;
case CL_DEVICE_TYPE_ACCELERATOR:
std::cout << "CL_DEVICE_TYPE_ACCELERATOR" << std::endl;
break;
}
}
On ATI Stream SDK this code displays as follows for a machine with an Intel i7 CPU device and ATI Radeon 5780:
CL_DEVICE_TYPE_CPU
CL_DEVICE_TYPE_GPU
Like all OpenCL objects, contexts are reference-counted and the number of references can be incremented and decremented with the following two commands:3
These increment and decrement, respectively, a context’s reference count.
To conclude this chapter, we build a simple example that performs a convolution of an input signal. Convolution is a common operation that appears in many signal-processing applications and in its simplest form combines one signal (input signal) with another (mask) to produce a final output (output signal). Convolution is an excellent application for OpenCL; it shows a good amount of data parallelism for large inputs and has good data locality that enables use of OpenCL’s sharing constructs.
Figure 3.2 shows the process of applying a 3×3 mask to an 8×8 input signal, resulting in a 6×6 output signal.4 The algorithm is straightforward; each sample of the final signal is generated by
1. Placing the mask over the input signal, centered at the corresponding input location
2. Multiplying the input values by the corresponding element in the mask
3. Accumulating the results of step 2 into a single sum, which is written to the corresponding output location
Figure 3.2 Convolution of an 8×8 signal with a 3×3 filter, resulting in a 6×6 signal
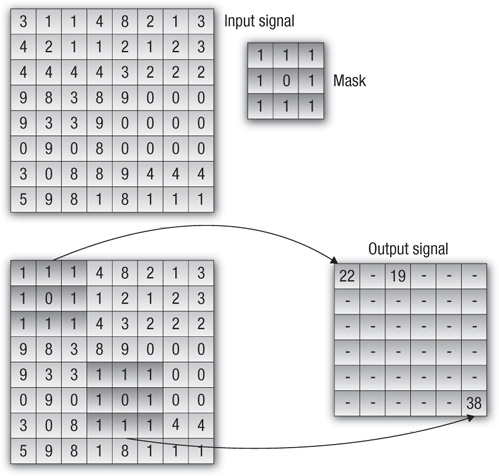
For each location in the output signal the kernel convolve, given in Listing 3.4, performs the preceding steps; that is, each output result can be computed in parallel.
Listing 3.4 Using Platform, Devices, and Contexts—Simple Convolution Kernel
Convolution.cl
__kernel void convolve(
const __global uint * const input,
__constant uint * const mask,
__global uint * const output,
const int inputWidth,
const int maskWidth)
{
const int x = get_global_id(0);
const int y = get_global_id(1);
uint sum = 0;
for (int r = 0; r < maskWidth; r++)
{
const int idxIntmp = (y + r) * inputWidth + x;
for (int c = 0; c < maskWidth; c++)
{
sum += mask[(r * maskWidth) + c] * input[idxIntmp + c];
}
}
output[y * get_global_size(0) + x] = sum;
}
Listing 3.5 contains the host code for our simple example. The start of the main function queries the list of available platforms, then it iterates through the list of platforms using clGetDeviceIDs() to request the set of CPU device types supported by the platform, and in the case that it finds at least one, the loop is terminated. In the case that no CPU device is found, the program simply exits; otherwise a context is created with the list of devices, and then the kernel source is loaded from disk and compiled and a kernel object is created. The input/output buffers are then created, and finally the kernel arguments are set and the kernel is executed. The program completes by reading the outputted signal and outputting the result to stdout.
Listing 3.5 Example of Using Platform, Devices, and Contexts—Simple Convolution
Convolution.cpp
#include <iostream>
#include <fstream>
#include <sstream>
#include <string>
#ifdef __APPLE__
#include <OpenCL/cl.h>
#else
#include <CL/cl.h>
#endif
// Constants
const unsigned int inputSignalWidth = 8;
const unsigned int inputSignalHeight = 8;
cl_uint inputSignal[inputSignalWidth][inputSignalHeight] =
{
{3, 1, 1, 4, 8, 2, 1, 3},
{4, 2, 1, 1, 2, 1, 2, 3},
{4, 4, 4, 4, 3, 2, 2, 2},
{9, 8, 3, 8, 9, 0, 0, 0},
{9, 3, 3, 9, 0, 0, 0, 0},
{0, 9, 0, 8, 0, 0, 0, 0},
{3, 0, 8, 8, 9, 4, 4, 4},
{5, 9, 8, 1, 8, 1, 1, 1}
};
const unsigned int outputSignalWidth = 6;
const unsigned int outputSignalHeight = 6;
cl_uint outputSignal[outputSignalWidth][outputSignalHeight];
const unsigned int maskWidth = 3;
const unsigned int maskHeight = 3;
cl_uint mask[maskWidth][maskHeight] =
{
{1, 1, 1}, {1, 0, 1}, {1, 1, 1},
};
inline void checkErr(cl_int err, const char * name)
{
if (err != CL_SUCCESS)
{
std::cerr << "ERROR: " << name
<< " (" << err << ")" << std::endl;
exit(EXIT_FAILURE);
}
}
void CL_CALLBACK contextCallback(
const char * errInfo,
const void * private_info,
size_t cb,
void * user_data)
{
std::cout << "Error occurred during context use: "
<< errInfo << std::endl;
exit(EXIT_FAILURE);
}
int main(int argc, char** argv)
{
cl_int errNum;
cl_uint numPlatforms;
cl_uint numDevices;
cl_platform_id * platformIDs;
cl_device_id * deviceIDs;
cl_context context = NULL;
cl_command_queue queue;
cl_program program;
cl_kernel kernel;
cl_mem inputSignalBuffer;
cl_mem outputSignalBuffer;
cl_mem maskBuffer;
errNum = clGetPlatformIDs(0, NULL, &numPlatforms);
checkErr(
(errNum != CL_SUCCESS) ? errNum :
(numPlatforms <= 0 ? -1 : CL_SUCCESS),
"clGetPlatformIDs");
platformIDs = (cl_platform_id *)alloca(
sizeof(cl_platform_id) * numPlatforms);
errNum = clGetPlatformIDs(numPlatforms, platformIDs, NULL);
checkErr(
(errNum != CL_SUCCESS) ? errNum :
(numPlatforms <= 0 ? -1 : CL_SUCCESS), "clGetPlatformIDs");
deviceIDs = NULL;
cl_uint i;
for (i = 0; i < numPlatforms; i++)
{
errNum = clGetDeviceIDs(
platformIDs[i],
CL_DEVICE_TYPE_CPU,
0,
NULL,
&numDevices);
if (errNum != CL_SUCCESS && errNum != CL_DEVICE_NOT_FOUND)
{
checkErr(errNum, "clGetDeviceIDs");
}
else if (numDevices > 0)
{
deviceIDs = (cl_device_id *)alloca(
sizeof(cl_device_id) * numDevices);
errNum = clGetDeviceIDs(
platformIDs[i], CL_DEVICE_TYPE_CPU, numDevices,
&deviceIDs[0], NULL);
checkErr(errNum, "clGetDeviceIDs");
break;
}
}
if (deviceIDs == NULL) {
std::cout << "No CPU device found" << std::endl;
exit(-1);
}
cl_context_properties contextProperties[] =
{
CL_CONTEXT_PLATFORM,(cl_context_properties)platformIDs[i], 0
};
context = clCreateContext(
contextProperties, numDevices, deviceIDs,
&contextCallback, NULL, &errNum);
checkErr(errNum, "clCreateContext");
std::ifstream srcFile("Convolution.cl");
checkErr(srcFile.is_open() ? CL_SUCCESS : -1,
"reading Convolution.cl");
std::string srcProg(
std::istreambuf_iterator<char>(srcFile),
(std::istreambuf_iterator<char>()));
const char * src = srcProg.c_str();
size_t length = srcProg.length();
program = clCreateProgramWithSource(
context, 1, &src, &length, &errNum);
checkErr(errNum, "clCreateProgramWithSource");
errNum = clBuildProgram(
program, numDevices, deviceIDs, NULL, NULL, NULL);
checkErr(errNum, "clBuildProgram");
kernel = clCreateKernel(program, "convolve", &errNum);
checkErr(errNum, "clCreateKernel");
inputSignalBuffer = clCreateBuffer(
context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR,
sizeof(cl_uint) * inputSignalHeight * inputSignalWidth,
static_cast<void *>(inputSignal), &errNum);
checkErr(errNum, "clCreateBuffer(inputSignal)");
maskBuffer = clCreateBuffer(
context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR,
sizeof(cl_uint) * maskHeight * maskWidth,
static_cast<void *>(mask), &errNum);
checkErr(errNum, "clCreateBuffer(mask)");
outputSignalBuffer = clCreateBuffer(
context, CL_MEM_WRITE_ONLY,
sizeof(cl_uint) * outputSignalHeight * outputSignalWidth,
NULL, &errNum);
checkErr(errNum, "clCreateBuffer(outputSignal)");
queue = clCreateCommandQueue(
context, deviceIDs[0], 0, &errNum);
checkErr(errNum, "clCreateCommandQueue");
errNum = clSetKernelArg(
kernel, 0, sizeof(cl_mem), &inputSignalBuffer);
errNum |= clSetKernelArg(
kernel, 1, sizeof(cl_mem), &maskBuffer);
errNum |= clSetKernelArg(
kernel, 2, sizeof(cl_mem), &outputSignalBuffer);
errNum |= clSetKernelArg(
kernel, 3, sizeof(cl_uint), &inputSignalWidth);
errNum |= clSetKernelArg(
kernel, 4, sizeof(cl_uint), &maskWidth);
checkErr(errNum, "clSetKernelArg");
const size_t globalWorkSize[1] =
{ outputSignalWidth * outputSignalHeight };
const size_t localWorkSize[1] = { 1 };
errNum = clEnqueueNDRangeKernel(
queue,
kernel,
1,
NULL,
globalWorkSize,
localWorkSize,
0,
NULL,
NULL);
checkErr(errNum, "clEnqueueNDRangeKernel");
errNum = clEnqueueReadBuffer(
queue, outputSignalBuffer, CL_TRUE, 0,
sizeof(cl_uint) * outputSignalHeight * outputSignalHeight,
outputSignal, 0, NULL, NULL);
checkErr(errNum, "clEnqueueReadBuffer");
for (int y = 0; y < outputSignalHeight; y++)
{
for (int x = 0; x < outputSignalWidth; x++)
{
std::cout << outputSignal[x][y] << " ";
}
std::cout << std::endl;
}
return 0;
}