
Appendix
A.1 Notation
Notation |
Explanation |
Chapter |
≻, ≺ |
preference relations |
|
~ |
equivalence relation |
|
Z |
set of outcomes, rewards |
|
z |
outcome, generic element of Z |
|
z0 |
best outcome |
|
z0 |
worst outcome |
|
Zi1i2...is0k |
outcome from actions |
|
Zi1i2...iSk |
outcome from actions |
|
Θ |
set of states of nature, parameter space |
|
θ |
event, state of nature, parameter, generic element of Θ, scalar |
|
θ |
state of nature, parameter, generic element of Θ, vector |
|
|
generic state of nature upon taking stopping action |
|
|
generic state of nature at last stage S upon taking action |
|
π |
subjective probability |
|
πθ |
price, relative to stake S, for a bet on θ |
|
πθ1|θ2 |
price of a bet on θ1 called off if θ2 does not occur |
|
|
current probability assessment of θ |
|
|
future probability assessment of θ |
|
πM |
least favorable prior |
|
Sθ |
stake associated with event θ |
|
gθ |
net gains if event θ occurs |
|
A |
action space |
|
a |
action, generic element of A |
|
a(θ) |
VNM action, function from states to outcomes |
|
|
expected value of the rewards for a lottery a |
|
z*(a) |
certainty equivalent of lottery a |
|
λ(z) |
Arrow–Pratt (local) measure of risk aversion at z |
|
P |
set of probability functions on Z |
|
a |
AA action, horse lottery, list of VNM lotteries a(θ) in P for θ ∊ Θ |
|
a(θ, z) |
probability that lottery a(θ) assigns to outcome z |
|
aS,θ |
action of betting stake S on event θ |
|
aθ |
action that would maximize decision maker’s utility if θ was known |
|
a |
action, vector |
|
|
generic action, indexed by is, at stage s of a multistage decision problem |
|
|
stopping action at stage s of a multistage decision problem |
|
aM |
minimax action |
|
a* |
Bayes action |
|
p(z) |
probability of outcome z |
|
p |
lottery or gamble, probability distribution over Z |
|
χz |
degenerate action with mass 1 at reward z |
|
u |
utility |
|
u(z) |
utility of outcome z |
|
u(a(θ)) |
utility of outcome a(θ) |
|
uθ(z) |
state-dependent utility of outcome z |
|
S(q) |
expected score of the forecast probability q |
|
s(θ, q) |
scoring rule for the distribution q and event θ |
|
RP(a) |
risk premium associated with action a |
|
X |
sample space |
|
x |
random variable or observed outcome |
|
xn |
random sample (x1, ..., xn) |
|
x |
multivariate random sample |
|
|
random variable with possible values xi1, ..., xiJs observed at stage s, upon taking continuation action |
|
f (x|θ) |
probability density function of x or likelihood function |
|
m(x) |
marginal density function of x |
|
F(x|θ) |
distribution function of x |
|
π(θ) |
prior probability of θ; may indicate a density if θ is continuous |
|
π(θ|x), πx |
posterior density of θ given x |
|
Ex[g(x)] |
expectation of the function g(x) with respect to m(x) |
|
Ex|θ[g(x)], E[g(x)|θ] |
expectation of the function g(x) with respect to f (x|θ) |
|
uπ(a) |
expected utility of action a, using prior π |
|
uπ(d) |
expected utility of the sequential decision procedure d |
|
δ |
decision rule, function with domain X and range A |
|
δ |
multivariate decision rule |
|
δM |
minimax decision rule |
|
δ* |
Bayes decision rule |
|
δR(x, ·) |
randomized decision rule for a given x |
|
δn |
terminal decision rule after n observations xn |
|
δ |
sequence of decision rules δ1(x1), δ2(x2), ... |
|
ζn |
stopping rule after n observations xn |
|
ζ |
sequence of stopping rules ζ0, ζ1(x1), ... |
|
d |
sequential decision rule: pair (δ, ζ) |
|
L(θ, a) |
loss function (in regret form) |
|
Lu(θ, a) |
loss function as the negative of the utility function |
|
L(θ, a, n) |
loss function for n observations |
|
u(θ, a, n) |
utility function for n observations |
|
L(θ, δR(x)) |
loss function for randomized decision rule δR |
|
Lπ(a) |
prior expected loss for action a |
|
Lπx(a) |
posterior expected loss for action a |
|
U(θ, d) |
average utility of the sequential procedure d for given θ |
|
R(θ, δ) |
risk function of decision rule δ |
|
V(π) |
maximum expected utility with respect to prior π |
|
W0(πxn, n) |
posterior expected utility, at time n, of colleting 0 additional observations |
|
Wk–n(πxn, n) |
posterior expected utility, at time n, of continuing for at most an additional k – n steps |
|
r(π, δ) |
Bayes risk associated with prior π and decision δ |
|
r(π, n) |
Bayes risk adopting the optimal terminal decision with n observations |
|
D |
class of decision rules |
|
DR |
class of all (including randomized) decision rules |
|
ɛ∞ |
perfect experiment |
|
ɛ |
generic statistical experiment |
|
ɛ12 |
statistical experiment consisting of observing both variables x1 and x2 |
|
ɛ(n) |
statistical experiment consisting of experiments ɛ1, ɛ2, ..., ɛn where ɛ2, ..., ɛn are conditionally i.i.d. repetitions of ɛ1 |
|
Vθ(ɛ∞) |
conditional value of perfect information for a given θ |
|
V(ɛ∞) |
expected value of perfect information |
|
Vx(ɛ) |
observed value of information for a given x in experiment ɛ |
|
V(ɛ) |
expected value of information in the experiment ɛ |
|
V(ɛ12 |
expected value of information in the experiment ɛ12 |
|
V(ɛ2|ɛ1) |
expected information of x2 conditional on observed x1 |
|
Ix(ɛ) |
observed (Lindley) information provided by observing x in experiment ɛ |
|
I(ɛ) |
expected (Lindley) information provided by the experiment ɛ |
|
Ix(ɛ12) |
expected (Lindley) information provided by the experiment ɛ12 |
|
I(ɛ2|ɛ1) |
expected (Lindley) information provided by E2 conditional on E1 |
|
c |
cost per observation |
|
C(n) |
cost function |
|
|
Bayes rule based on n observations |
|
Uπ (n) |
expected utility of making n observations and adopting the optimal terminal decision |
|
n* |
Bayesian optimal sample size |
|
nM |
Minimax optimal sample size |
|
η |
nuisance parameter |
|
Φ(.) |
cumulative distribution function of the N(0,1) |
|
M |
class of parametric models in a decision problem |
|
M |
generic model within M |
|
Hs |
history set at stage s of a multistage decision problem |
A.2 Relations
p(z) |
= |
|
(3.3) |
|
= |
|
(4.4) |
z*(a) |
= |
|
(4.9) |
RP(a) |
= |
|
(4.10) |
λ(z) |
= |
–u″ (z)/u′ (z) = –(d/dz)(log u′ (z)) |
(4.13) |
Lu(θ, a) |
= |
–u(a(θ)) |
(7.1) |
L(θ, a) |
= |
Lu(θ, a) – infa∈A Lu(θ, a) |
(7.2) |
|
= |
supa′(θ) u(a′ (θ)) – u(a(θ)) |
(7.3) |
Lπ(a) |
= |
|
(7.6) |
Lπx(a) |
= |
|
(7.13) |
Uπ(a) |
= |
|
(3.4) |
|
= |
|
(3.5) |
S(q) |
= |
|
(10.1) |
V(π) |
= |
supa Uπ(a) |
(13.2) |
aM |
= |
argmin maxθ L(θ, a) |
(7.4) |
a* |
= |
argmax Uπ(a) |
(3.6) |
|
= |
argmin ∫Θ L(θ, a)π(θ)dθ |
(7.5) |
aθ |
= |
arg supa∈A u(a(θ)) |
(13.4) |
m(x) |
= |
∫Θ π(θ)f (x|θ)dθ |
(7.12) |
π(θ|x) |
= |
π(θ)f (x|θ)/m(x) |
(7.11) |
L(θ, δR(x)) |
= |
|
(7.16) |
R(θ, δ) |
= |
|
(7.7) |
r(π, δ) |
= |
|
(7.9) |
δM |
s.t. supθ R(θ, δM) = infδ supθ R(θ, δ) |
(7.8) |
|
δ* |
s.t. r(π, δ*) = infδ r(π, δ) |
(7.10) |
|
Vθ(ɛ∞) |
= |
u(aθ(θ)) – u(a*(θ)) |
(13.5) |
V(ɛ∞) |
= |
Eθ[Vθ(ɛ∞)] |
(13.6) |
|
= |
Eθ [supa u(a(θ))] – V(π) |
(13.7) |
Vx(ɛ) |
= |
V(πx) – Uπx(a*) |
(13.9) |
V(ɛ) |
= |
Ex[Vx(ɛ)] = Ex[V(πx) – Uπx(a*)] |
(13.10) |
|
= |
E[Vx(ɛ)] = Ex[V(πx)] – V(π) |
(13.12) |
|
= |
Ex[V(πx)] – V(Ex[πx]) |
(13.13) |
V(ɛ2|ɛ1) |
= |
Ex1x2[V(πx1x2)] – Ex1[V(πx1)] |
(13.17) |
V(ɛ12 |
= |
Ex1x2[V(πx1x2)] – V(π) |
(13.16) |
|
= |
V(ɛ1) + V(ɛ2|ɛ1) |
(13.18) |
I(ɛ) |
= |
∫X ∫Σ log (πx(θ)/π(θ)) πx(θ)m(x)dθdx |
(13.27) |
|
= |
∫Σ ∫X log (f (x|θ)/m(x)) f (x|θ)π(θ)dxdθ |
(13.28) |
|
= |
Ex [Eθ|x [log (f (x|θ)/m(x))]] |
(13.29) |
|
= |
Ex [Eθ|x[log (fx(θ)/m(x))]] |
(13.30) |
I(ɛ2|ɛ1) |
= |
Ex1Ex2|x1Eθ|x1,x2 [log (f (x2|θ, x1)/m(x2|x1))] |
(13.33) |
I(ɛ12 |
= |
I(ɛ1) + I(ɛ2|ɛ1) |
(13.31) |
Ix(ɛ) |
= |
∫Σ πx(θ)log (πx(θ)/π(θ)) dθ |
(13.26) |
u(a, θ, n) |
= |
u(a(θ)) – C(n) |
(14.1) |
L(θ, a, n) |
= |
L(θ, a) + C(n) |
(14.2) |
r(π, n) |
= |
|
(14.3) |
|
= |
|
(14.4) |
Uπ(n) |
= |
|
(14.5) |
A.3 Probability (density) functions of some distributions
If x ~ Bin(n, θ) then

If x ~ N(θ, σ2) then

If x ~ Gamma(α, β) then

If x ~ Exp(θ) then
f (x|θ) = θe–θx.
If x ~ Beta – Binomial(n, α, β) then

If x ~ Beta(α, β) then

A.4 Conjugate updating
In the following description, prior hyperparameters have subscript 0, while parameters of the posterior distributions have subscript x.
Sampling model: binomial
Data: x|θ ~ Bin(n, θ).
Prior: θ ~ Beta(α0, β0).
Posterior: θ|x ~ Beta(αx, βx) where
αx = α0 + x and βx = β0 + n – x.
Marginal: x ~ BetaBinomial(n, α0, β0).
Sampling model: normal
Data: x ~ N(θ, σ2)(σ2 known).
Prior:
 .
.Posterior:
 where
where
Marginal:
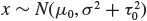 .
.