
Chapter 14. Integration Testing Databases with DbUnit[12]
Introduction
The JUnit family provides the basic framework for unit testing for Java applications. On top of JUnit, there are many additional tools and frameworks for specialized areas of testing. In this chapter, we take a look at DbUnit,[*] an important tool for database integration testing.
We describe database testing as “integration testing” to distinguish it from ordinary “unit testing.” Integration tests involve infrastructure beyond your own code. In the case of database integration testing, the additional infrastructure is a real database.
DbUnit is often referred to as a “JUnit extension.” It is true that DbUnit provides TestCase subclasses, which you may extend in your own test classes. But DbUnit may be used in other ways independently of JUnit, too. For example, you can invoke DbUnit from within Ant to perform certain tasks.
In this chapter, we will describe the main purpose of DbUnit, give some simple examples of typical usage, and then proceed with several additional related topics.
Overview
Purpose of DbUnit
DbUnit has two main purposes:
- To prime the database
DbUnit can set up tables with known contents before each test method.
- To verify the database
DbUnit makes it easier to verify tables’ contents after each test method.
If you were not using DbUnit, you would have several rather awkward alternatives to choose from. You could hand-code JDBC calls to prime and verify the database. This would usually be very awkward and a lot of work. Alternatively, if you are using object-relational mapping (ORM) in your main application, some people would advocate using that to populate your database with test data and to read values from the database for verification. This amounts to using your data access layer to test your data access layer, and may not be a good idea. ORM technology involves a fair amount of subtlety, such as caching for example, and we would prefer not to have this possibly confounding our tests.
DbUnit, by contrast, provides a relatively straighforward and flexible way to prime and verify the database independently of the code under test.
Setting Up DbUnit
The first thing you need to do to use DbUnit is to download the JAR file from http://dbunit.sourceforge.net. Place this JAR on the classpath of your IDE or your build script. You will also need the JDBC driver for your database on the classpath. There are no other dependencies for basic DbUnit usage.
You should also read the online documentation at http://dbunit.sourceforge.net. The documentation is not extensive, but it is short and relevant and definitely worth reading.
The next thing is to decide how you want to invoke DbUnit. For most testing scenarios, you will invoke DbUnit in your test classes, either directly or indirectly. You can also use DbUnit from Ant for some tasks, as we will see below.
Running with DbUnit
When you do database testing with DbUnit, you test against a real database. You need to have a connection to the real database at the time you run your tests.
Because DbUnit, and your code under test, will insert and modify data in this database, each developer needs to have more or less exclusive access to the database, or at least to a schema within it. Otherwise, if different developers run the tests at the same time, they may conflict with each other. The ideal setup is for each developer to have the database software installed on his machine. Machines these days are powerful enough to run virtually any database software with little overhead.
You don’t have to have a copy of your entire production database on your machine. The nature of DbUnit tests is that they work best with relatively small amounts of data. DbUnit tests typically test the system for correct function, rather than for performance.
Some people suggest to use a lightweight embedded database (such as HSQLDB or Apache Derby) for running integration tests. This has the advantage of not requiring you to install special database software on your machine. Also, embedded databases typically run tests much faster than real databases because most of it can be done in memory and there is less overhead in general.
However, for a serious application this is usually misguided. Your application will often contain database-specific code or make use of database-specific features. These cannot be tested properly unless you use the same database when running your tests. Also, even if you are using an ORM layer such as Hibernate or JPA, which appears to make your code database-independent, the actual SQL generated by the ORM may well be different from one database to another. The JDBC drivers will certainly be different.
So, there are significant functional differences between an embedded database and your production database. To make your tests as useful and effective as possible, you should endeavor to make the database environments identical. Of course, if your production system itself uses an embedded database, then you are fortunate!
DbUnit Structure
The easiest way to use DbUnit when starting out is to extend one of its provided base classes. We will see some examples below where this is not necessary, or always advisable. For starting out, let’s take a look at these base classes.
Like any good object-oriented framework or library, DbUnit contains a lot of interfaces. Most of the functionality of DbUnit is specified by interfaces. DbUnit adopts the convention that interfaces begin with a capital “I.”
DbUnit often provides several concrete implementations of an interface. Typically, there is an abstract base implementation, with multiple specific concrete subclasses.
DatabaseTestCase
The main base class in DbUnit is DatabaseTestCase.
Before DbUnit 2.2, you would extend DatabaseTestCase
to create your test classes. As of DbUnit 2.2, there is a new subclass that
you should extend instead, DBTestCase. The main
difference with DBTestCase is that it provides a
getConnection() method that delegates
to the IDatabaseTester. You provide or override the
default IDatabaseTester by overriding newDatabaseTester().
The IDatabaseTester is responsible for providing
several important features for testing:
The database connection
The setup test data set
The setup operation (usually
CLEAN_INSERT)The teardown operation (usually none)
DbUnit provides several standard
IDatabaseTester implementations, and you can
easily use one of these, extend one of them, or provide your own.
The DatabaseTestCase and
IDatabaseTester hierarchies are shown in Figure 14-1.
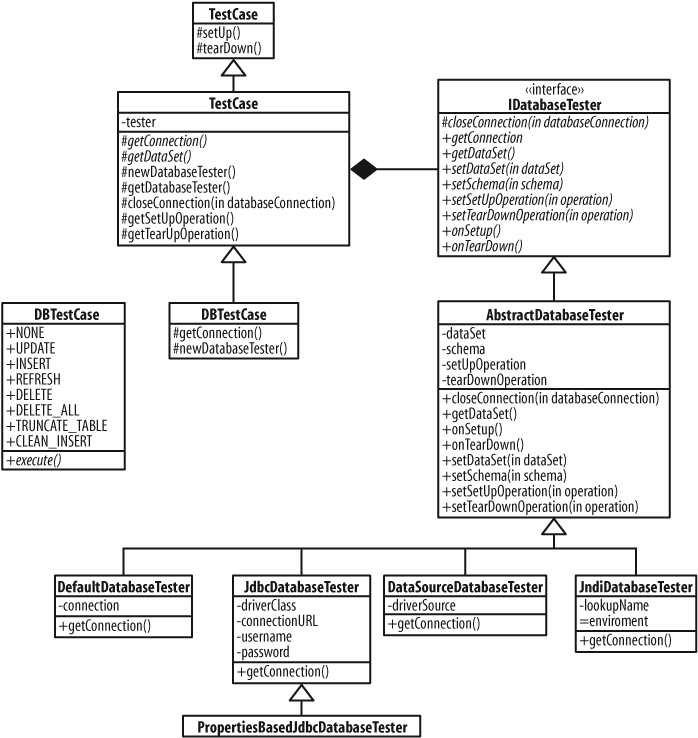
We’ll see how these classes work in some detail in our examples, and we will refer back to features from these diagrams as we explain them.
IDatabaseConnection
When a DatabaseTestCase or
IDatabaseTester needs to access the actual
database, it does so via an IDatabaseConnection. The
IDatabaseConnection is basically a wrapper or
adapter for a JDBC
Connection. You can customize an
IDatabaseConnection via its
DatabaseConfig, which is a collection of
name/value features and properties. These classes are shown in Figure 14-2.
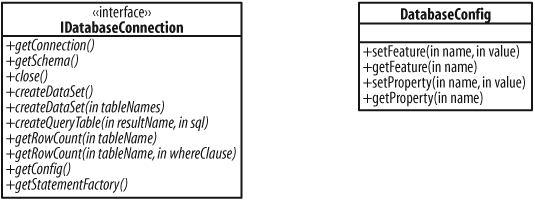
IDataSet
DbUnit represents the actual data for tests as an
IDataSet, which is an abstract representation of
the data in a collection of tables.
DbUnit provides several concrete implementations of
IDataSet, which you can use to obtain data sets
from different sources, and to decorate them with additional functionality.
Some of the implementations are shown in Figure 14-3. For example,
FlatXmlDataSet,
CsvDataSet, and XlsDataSet are
different ways of representing data in files. We’ll look at examples of
these next. You can find others by examining the source code.
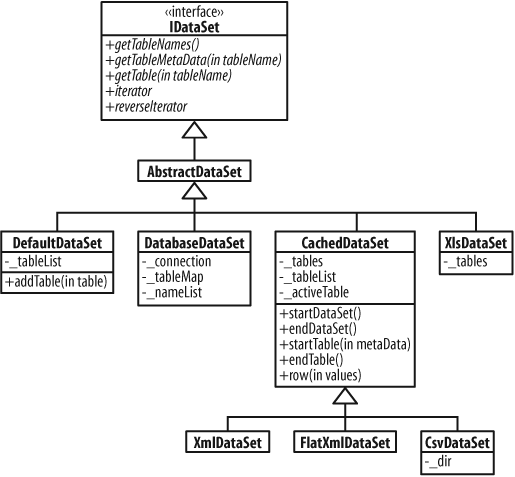
ITable
A table in turn is represented by an ITable, which
is basically a set of rows and columns. Figure 14-4 shows ITable,
along with some implementations.
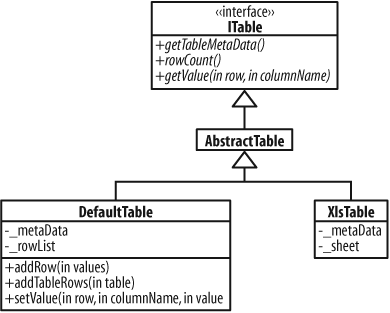
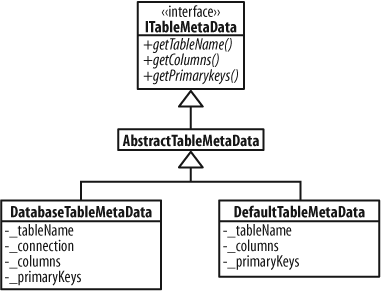
ITableMetaData
Finally, DbUnit uses an ITableMetaData object to
provide information about a table: its name and the characteristics of its
columns. Figure 14-5 shows
ITableMetaData and some implementations.
These interfaces represent the core functionality of DbUnit. Of course, DbUnit contains many more interfaces and classes than these. We will see some additional interfaces and classes in the examples that follow.
You don’t need to understand all of these classes to start using DbUnit.
Some of them, such as ITableMetaData, you will only
use when customizing or extending DbUnit. The examples should give you a
good idea of how the classes fit together, and how you can use them in your
own projects.
Example Application
We’ll explain various DbUnit features through a series of examples. The code for the examples is provided in the source code that accompanies this book. An Ant build script to set up and run the code is also provided.
For the examples, we’ll use a database schema adapted from the PetClinic application provided with the Spring Framework.[*] This application is one of the samples provided with the Spring framework. It is an implementation of the classic (infamous) Pet Store J2EE demo application. Most of our examples do not depend on Spring—we’re simply using this schema as a convenient sample application.
The PetClinic schema we’ll use is shown in Figure 14-6. It is slightly modified from the original, in that we’ve added a couple of extra columns to use in demonstrating certain DbUnit features.
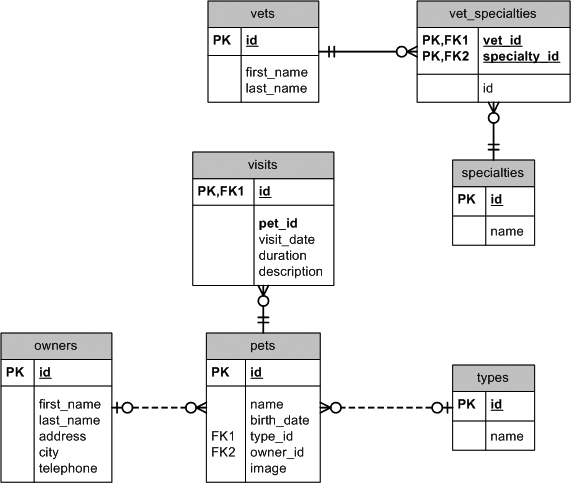
The Spring version of this application provides HSQLDB and MySQL variants of the database. For the examples in this book, I have adapted the schema to run on Oracle instead. (You can download Oracle Express Edition for free for Windows or GNU/Linux.) The Oracle SQL DDL to define this schema is provided in create_tables.sql.
Priming the Database
For the first examples, I’ll show how to use DbUnit to prime the
database with known test data before a test. The standard way to do this is via
the setUp() method of your test. Or rather,
the setUp() method of
DatabaseTestCase. The basic idea is that you provide
an IDataSet, containing the data you want, and DbUnit
loads the data.
In the first examples, we’ll use the FlatXmlDataSet,
which is probably the most commonly used implementation of
IDataSet. Later, we’ll show a couple of other alternatives.
Verifying Querying a Single Row
The simplest kind of database test is to test some code that retrieves one
single row from the database. Consider this interface for a Data Access
Object (DAO) for the owners table:
public interface OwnerDao {
Collection<Owner> findOwners(String lastName);
Owner loadOwner(int id);
void storeOwner(Owner owner);
void deleteOwner(Owner owner);
}
The DAO includes a method, loadOwner(), for retrieving a single
Owner by ID. The listing below shows a simple
JDBC implementation of the loadOwner() method:
public class JdbcOwnerDao extends AbstractJdbcDao implements OwnerDao {
// ...
public Owner loadOwner(int id) {
Connection conn = null;
PreparedStatement stmt = null;
PreparedStatement stmt2 = null;
ResultSet rs = null;
try {
conn = getConnection();
stmt = conn.prepareStatement(
"SELECT id, first_name, last_name, address, city, telephone "
+ "FROM owners WHERE id = ?");
stmt.setInt(1, id);
stmt2 = conn.prepareStatement(
"SELECT p.id p_id, p.name p_name, p.birth_date, t.id t_id,
t.name t_name "
+ "FROM pets p JOIN types t ON t.id = p.type_id WHERE owner_id
= ? ORDER BY 1");
stmt2.setInt(1, id);
rs = stmt.executeQuery();
if (rs.next()) {
Owner result = new Owner();
result.setId(id);
result.setFirstName(rs.getString("first_name"));
result.setLastName(rs.getString("last_name"));
result.setAddress(rs.getString("address"));
result.setCity(rs.getString("city"));
result.setTelephone(rs.getString("telephone"));
Collection<Pet> pets = new ArrayList<Pet>();
ResultSet rs2 = stmt2.executeQuery();
while (rs2.next()) {
Pet pet = new Pet();
pet.setId(rs2.getInt("p_id"));
pet.setName(rs2.getString("p_name"));
pet.setBirthDate(DateUtils.localDate(rs2.getDate("birth_date")));
Type type = new Type();
type.setId(rs2.getInt("t_id"));
type.setName(rs2.getString("t_name"));
pet.setType(type);
pets.add(pet);
}
result.setPets(pets);
return result;
}
else {
return null;
}
}
catch (SQLException ex) {
throw new RuntimeException(ex);
}
finally {
closeResultSet(rs);
closeStatement(stmt);
closeStatement(stmt2);
closeConnection(conn);
}
}
// ...
}This DAO implementation is intended only to illustrate how you would use DbUnit to test your own DAOs. We would not code a production DAO in a real system like this. There are many things wrong with it. For example:
The JDBC code is verbose, repetitive, and does not handle exceptions properly.
The code mixes low-level data access with connection management.
The DAO is inflexible about when to fetch dependent relationships (i.e., the “pets” collection).
The DAO has no capability for lazy-loading.
There is no transaction management.
In a real system, we would use an ORM framework for DAOs, or a JDBC framework such as iBATIS or Spring JDBC DAO support. However, for the purposes of giving a DbUnit example, it will suffice.
We won’t waste space including program listings of most of the DAO functions under test. The source code is included with the accompanying code, if you want to try running it for yourself. Remember that the DAO code is not to production standards—it is simply there to demonstrate DbUnit.
To test this DAO using DbUnit, we’ll create a subclass
of DBTestCase:
public class FlatXmlSelectOwnerTest extends DBTestCase {
// ...
}In this class, we override newDatabaseTester() to provide DbUnit with an IDatabaseTester:
protected IDatabaseTester newDatabaseTester() throws Exception {
return new DataSourceDatabaseTester(DataSourceUtils.getDataSource());
}In
this case, we use a DataSourceDatabaseTester. This is
a simple variant that uses a JDBC
DataSource to obtain a connection to the
database.
The several provided IDatabaseTester
implementations obtain the connection to the database in different ways:
DataSourceDatabaseTesterGets connection from a
DataSourceDefaultDatabaseTesterGets connection from one supplied in constructor
JdbcDatabaseTesterGets connection from JDBC via
DriverManagerJndiDatabaseTesterGets connection from JNDI
We provide a DataSource obtained via a static
utility method in our application: DataSourceUtils.getDataSource(). This
method is hardcoded to return an appropriate data source for our
application. Later in this chapter, we will see an alternative way to
specify the data source without hard-coding it.
The current implementation of DataSourceUtils looks
like this:
public class DataSourceUtils {
private static final DataSource dataSource = createBasicDataSource();
private static DataSource createBasicDataSource() {
BasicDataSource result = new BasicDataSource();
result.setDriverClassName("oracle.jdbc.OracleDriver");
result.setUrl("jdbc:oracle:thin:@localhost:1521:XE");
result.setUsername("jpt");
result.setPassword("jpt");
return result;
}
public static DataSource getDataSource() {
return dataSource;
}
}Here, we are using
org.apache.commons.dbcp.BasicDataSource to
provide a pooled data source. If we use a more
simplistic strategy for obtaining database connections, such as creating
them from the JDBC
DriverManager, we are likely to run into timing
problems due to connection limits on the server. This is because
DriverManager and similar approaches create a new
physical connection to the server for every connection request. Because
database tests request many connections in a short space of time, this can
result in problems, even if you are running the server on your own
machine.
Instead, the BasicDataSource uses a pool and in
fact may create only one physical connection throughout the entire test
suite. Not only does this eliminate resource and timing problems, it is also
much faster.
The next thing we need to do is to provide an
IDataSet containing the test data:
protected IDataSet getDataSet() throws Exception {
return new FlatXmlDataSet
(getClass().getResourceAsStream("FlatXmlSelectOwnerTest.xml"));
}This
method retrieves the file from an InputStream
obtained on the classpath, but the constructor accepts any
InputStream.
In this case, we’re using a FlatXmlDataSet. This is
an IDataSet that gets test data for tables from a
single XML file. The XML for our data set looks like this:
<dataset>
<owners id="1" first_name="Mandy" last_name="Smith" address="12 Oxford Street"
city="Southfield" telephone="555-1234567"/>
<owners id="2" first_name="Joe" last_name="Jeffries" address="25 Baywater Lane"
city="Northbrook" telephone="555-2345678"/>
<owners id="3" first_name="Herb" last_name="Dalton" address="2 Main St"
city="Southfield" telephone="555-3456789"/>
<owners id="4" first_name="Dave" last_name="Smith-Jones" address="12 Kent Way"
city="Southfield" telephone="555-4567890"/>
<pets/>
<visits/>
</dataset>The main document element is <dataset>. Within the document, there is an element for
each table row. The element is named for the table the row belongs in, and
there is an attribute for each column. You can also specify an empty table
with an empty element, e.g., <pets/>.
DbUnit also provides the older XmlDataSet, which uses a more verbose and
awkward XML format. We don’t look at XmlDataSet in
this book.
Providing this dataset via overriding the getDataSet() method is all we need to do to get DbUnit to
prime the database. Before each test method in FlatXmlSelectOwnerTest, DbUnit will
delete all rows in the tables in the data set, then repopulate them from the
data in the XML file.
An important consideration when using CLEAN_INSERT, the default setup operation, is the order in
which it processed the tables. The CLEAN_INSERT operation INSERTs data in the order it finds the tables in the data
set. Prior to inserting them, it DELETEs
from them, in the reverse order.
This sequence helps you to arrange the tables in your data set to avoid foreign key constraint violations when clearing and reloading tables. Generally, you put parent tables first and child tables after. Sometimes this isn’t enough, such as when you have circular referential integrity rules. We’ll consider how to deal with those later.
private OwnerDao getOwnerDao() {
return new JdbcOwnerDao(DataSourceUtils.getDataSource());
}
private static void assertOwner(Owner owner, int id, String firstName,
String lastName, String address,
String city, String telephone) {
assertEquals(id, owner.getId());
assertEquals(firstName, owner.getFirstName());
assertEquals(lastName, owner.getLastName());
assertEquals(address, owner.getAddress());
assertEquals(city, owner.getCity());
assertEquals(telephone, owner.getTelephone());
}
public void testLoadOwner() {
OwnerDao ownerDao = getOwnerDao();
Owner joe = ownerDao.loadOwner(2);
assertOwner(joe, 2, "Joe", "Jeffries", "25 Baywater Lane", "Northbrook",
"555-2345678");
}
// ... more tests ...In
the testLoadOwner() method, we obtain an
instance of the DAO. We use the DAO to
retrieve the Owner with ID 2, and we verify the
properties of the returned object.
If the returned object were different from what we expected, at least one of the assertions would fail, resulting in a failed test. These assertions have nothing to do with DbUnit, and can be anything you want them to be. We will now see how DbUnit can be used to make assertions about results in the database.
Verifying Querying Multiple Rows
We can easily extend the test case now to verify the findOwners() method, which returns a
collection of Owner objects:
public void testFindOwners() {
OwnerDao ownerDao = getOwnerDao();
Iterator<Owner> owners = ownerDao.findOwners("smith").iterator();
assertOwner(owners.next(), 1, "Mandy", "Smith", "12 Oxford Street", "Southfield",
"555-1234567");
assertOwner(owners.next(), 4, "Dave", "Smith-Jones", "12 Kent Way", "Southfield",
"555-4567890");
assertFalse(owners.hasNext());
} Specifying NULLs by Omission
So, what if we need to specify NULL for a data value? There are several ways to do this with
DbUnit. Probably the simplest way is to omit the column’s attribute in the
row.
Here’s an example of a FlatXmlDataSet with some
NULL column values:
<dataset>
<owners id="1" first_name="Mandy" last_name="Smith" address="12 Oxford Street"
city="Southfield" telephone="555-1234567"/>
<owners id="2" first_name="Joe" last_name="Jeffries" address="25 Baywater Lane"
telephone="555-2345678"/>
<owners id="3" first_name="Herb" last_name="Dalton" address="2 Main St"
city="Southfield"/>
<owners id="4" first_name="Dave" last_name="Smith-Jones" address="12 Kent Way"
city="Southfield" telephone="555-4567890"/>
<pets/>
<visits/>
</dataset> In
this example, there is no value specified for the city column in the second row, or for the telephone column in the third row.
Here’s a modified test method that verifies the null properties in the resulting objects:
public void testValues() {
OwnerDao ownerDao = getOwnerDao();
assertOwner(ownerDao.loadOwner(1), 1, "Mandy", "Smith", "12 Oxford Street",
"Southfield", "555-1234567");
assertOwner(ownerDao.loadOwner(2), 2, "Joe", "Jeffries", "25 Baywater Lane",
null, "555-2345678");
assertOwner(ownerDao.loadOwner(3), 3, "Herb", "Dalton", "2 Main St",
"Southfield", null);
assertOwner(ownerDao.loadOwner(4), 4, "Dave", "Smith-Jones", "12 Kent Way",
"Southfield", "555-4567890");
}It’s important to note that the order of the rows for the owners table in the
FlatXmlDataSet is important when using this
method. The attributes found on the first row for each table in the XML file
determine the columns that DbUnit will populate for that table. If you omit
an attribute for the first row, that column will be omitted (will be
NULL) for all
rows, whether or not you include the attribute for later rows. So, generally
you will need to include all columns of interest on the first row. This is
not usually a problem. It would be a problem if, for example, you had a pair
of columns such that one or the other of them could be nonnull but not
both.
Specifying NULLs by DTD
Another way to specify null columns is to use the DTD feature
FlatXmlDataSet. You can optionally associate a
DTD with a FlatXmlDataSet to specify the columns for
each table in it.
Here’s an example DTD for our test data set:
<!ELEMENT dataset (owners*, pets*, visits*)> <!ELEMENT owners EMPTY> <!ATTLIST owners id CDATA #REQUIRED first_name CDATA #IMPLIED last_name CDATA #IMPLIED address CDATA #IMPLIED city CDATA #IMPLIED telephone CDATA #IMPLIED > <!ELEMENT pets EMPTY> <!ATTLIST pets id CDATA #REQUIRED name CDATA #IMPLIED birth_date CDATA #IMPLIED type_id CDATA #IMPLIED owner_id CDATA #IMPLIED > <!ELEMENT visits EMPTY> <!ATTLIST visits id CDATA #REQUIRED pet_id CDATA #REQUIRED visit_date CDATA #IMPLIED description CDATA #IMPLIED >
With this DTD, we have specified the full set of columns for each table. We can now give an XML file where no row has every column included:
<!DOCTYPE dataset SYSTEM "FlatXmlSelectOwnerNullByDtdTest.dtd">
<dataset>
<owners id="1" first_name="Mandy" last_name="Smith" address="12 Oxford Street"
city="Southfield"/>
<owners id="2" first_name="Joe" last_name="Jeffries" address="25 Baywater Lane"
telephone="555-2345678"/>
<owners id="3" first_name="Herb" last_name="Dalton" address="2 Main St"
city="Southfield"/>
<owners id="4" first_name="Dave" last_name="Smith-Jones" address="12 Kent Way"
telephone="555-4567890"/>
<pets/>
<visits/>
</dataset>To instruct DbUnit to use the DTD, we use this alternative
FlatXmlDataSet constructor when creating the data
set:
protected IDataSet getDataSet() throws Exception {
return new FlatXmlDataSet(
getClass().getResourceAsStream("FlatXmlSelectOwnerNullByDtdTest.xml"),
getClass().getResourceAsStream("FlatXmlSelectOwnerNullByDtdTest.dtd")
);
}Again,
note that both arguments to the constructor are
InputStreams, in this case obtained from the
classpath.
With this in place, we can verify the properties of the returned objects in a modified test:
public void testValues() {
OwnerDao ownerDao = getOwnerDao();
assertOwner(ownerDao.loadOwner(1), 1, "Mandy", "Smith", "12 Oxford Street",
"Southfield", null);
assertOwner(ownerDao.loadOwner(2), 2, "Joe", "Jeffries", "25 Baywater Lane",
null, "555-2345678");
assertOwner(ownerDao.loadOwner(3), 3, "Herb", "Dalton", "2 Main St", "Southfield",
null);
assertOwner(ownerDao.loadOwner(4), 4, "Dave", "Smith-Jones", "12 Kent Way", null,
"555-4567890");
}This gives you some basic tools for populating your database using
FlatXmlDataSet. We’ll look at some alternative
data set formats shortly, and we’ll also show how to specify more exotic
data values. But first, let’s see how we can use DbUnit to verify data in
the database after a test case.
Verifying the Database
The second use you can put DbUnit to in your database tests is verifying the data in the database after (or during) a test case. In this section, we’ll see how to do that, and take a look at some of the issues involved.
Verifying an UPDATE
Let’s consider a test for the storeOwner() method of our DAO. The
storeOwner() method adds a new
Owner to the database, or updates an existing
Owner. We’ll start by testing updates to an
existing Owner. Here is the test code:
public void testUpdateOwner() throws Exception {
OwnerDao ownerDao = getOwnerDao();
Owner owner = ownerDao.loadOwner(1);
owner.setFirstName("Mandy-Jane");
owner.setLastName("Brown");
owner.setAddress("21 Ocean Parade");
owner.setCity("Westport");
owner.setTelephone("555-9876543");
ownerDao.storeOwner(owner);
IDataSet expectedDataSet
= new FlatXmlDataSet(getClass().getResourceAsStream
("FlatXmlUpdateOwnerTest.xml"));
ITable expectedTable = expectedDataSet.getTable("owners");
ITable actualTable = getConnection().createDataSet().getTable("owners");
Assertion.assertEquals(expectedTable, actualTable);
}In this test, we obtain an Owner object, change it,
then save the changed object back to the database with the storeOwner() method.
We specify the expected results in a new
FlatXmlDataSet, obtained from file FlatXmlUpdateOwnerTest.xml in the classpath. The contents of
the file look like this:
<dataset>
<owners id="1" first_name="Mandy-Jane" last_name="Brown" address="21 Ocean Parade"
city="Westport" telephone="555-9876543"/>
<owners id="2" first_name="Joe" last_name="Jeffries" address="25 Baywater Lane"
city="Northbrook" telephone="555-2345678"/>
<owners id="3" first_name="Herb" last_name="Dalton" address="2 Main St"
city="Southfield" telephone="555-3456789"/>
<owners id="4" first_name="Dave" last_name="Smith-Jones" address="12 Kent Way"
city="Southfield" telephone="555-4567890"/>
<pets/>
<visits/>
</dataset>As you can see, the result data set contains the same data as we primed
the database with, except that the first row of the owners table is changed.
To compare the actual database contents with the expected table data, we
retrieve an ITable instance via the createDataSet() and getTable() calls on the IDatabaseConnection. Finally, we use the assertEquals() from DbUnit’s
Assertion class, overloaded for
ITable.
This test passes. If the data was wrong, DbUnit would fail the test. For
example, suppose we omit the call to ownerDao.storeOwner(), to simulate the DAO
not saving the data. Then, when we run the test, we get an output such as:
junit.framework.AssertionFailedError: value (table=owners, row=0, col=address):
expected:<21 Ocean Parade>
but was:<12 Oxford Street>
at org.dbunit.Assertion.assertEquals(Assertion.java:147)
at com.ora.javapowertools.dao.test.FlatXmlUpdateOwnerTest.testUpdateOwner
(FlatXmlUpdateOwnerTest.java:46)
...Note that DbUnit counts rows from 0.
Verifying a DELETE
We can do a very similar test for the deleteOwner() method. In doing do, we notice that the work to
compare the database table to an expected result is the same for both tests,
so it’s better if we move that out to a separate method like this:
private void assertTable(String dataSetFilename, String tableName)
throws Exception {
IDataSet expectedDataSet = new FlatXmlDataSet(getClass().
getResourceAsStream(dataSetFilename));
ITable expectedTable = expectedDataSet.getTable(tableName);
ITable actualTable = getConnection().createDataSet().getTable(tableName);
Assertion.assertEquals(expectedTable, actualTable);
} Now we can proceed to write the test for deleteOwner():
public void testDeleteOwner() throws Exception {
OwnerDao ownerDao = getOwnerDao();
Owner owner = ownerDao.loadOwner(1);
ownerDao.deleteOwner(owner);
assertTable("FlatXmlDeleteOwnerTest.xml", "owners");
} In this test, we compare the table to the expected data in another
FlatXmlDataSet, stored in FlatXmlDeleteOwnerTest.xml:
<dataset>
<owners id="2" first_name="Joe" last_name="Jeffries" address="25 Baywater Lane"
city="Northbrook" telephone="555-2345678"/>
<owners id="3" first_name="Herb" last_name="Dalton" address="2 Main St"
city="Southfield" telephone="555-3456789"/>
<owners id="4" first_name="Dave" last_name="Smith-Jones" address="12 Kent Way"
city="Southfield" telephone="555-4567890"/>
<pets/>
<visits/>
</dataset>This time, the first row of the table has been deleted.
If the deleteOwner() method did not
work correctly, we would get a failed test with something like this:
junit.framework.AssertionFailedError: row count (table=owners) expected:<3> but was:<4>
at org.dbunit.Assertion.assertEquals(Assertion.java:128)
at com.ora.javapowertools.dao.test.FlatXmlDeleteOwnerTest.assertTable
(FlatXmlDeleteOwnerTest.java:38)
at com.ora.javapowertools.dao.test.FlatXmlDeleteOwnerTest.testDeleteOwner
(FlatXmlDeleteOwnerTest.java:45)
...This time DbUnit finds that the data set is short by a row.
Verifying an INSERT, Ignoring the Key
Verifying an UPDATE or DELETE is quite straightforward. INSERTs can be a little more tricky when using
surrogate keys such as those obtained from database SEQUENCEs. In this scenario, the generated key depends on the
current value of the sequence, and can be different from one run to the
next. DbUnit’s setUp() does not restore
database SEQUENCEs.
One approach to this is simply to ignore the generated key. We can do so with some test code like this:
public void testInsertOwner() throws Exception {
OwnerDao ownerDao = getOwnerDao();
Owner owner = new Owner();
owner.setFirstName("John");
owner.setLastName("Hudson");
owner.setAddress("15 Dorset Av");
owner.setCity("Easton");
owner.setTelephone("555-7654321");
ownerDao.storeOwner(owner);
assertTable("FlatXmlInsertOwnerIgnoreSequenceTest.xml", "owners");
}This code adds a new object, then compares the result against an expected table in FlatXmlInsertOwnerIgnoreSequenceTest.xml. The expected data look like this:
<dataset>
<owners first_name="Mandy" last_name="Smith" address="12 Oxford Street"
city="Southfield" telephone="555-1234567"/>
<owners first_name="Joe" last_name="Jeffries" address="25 Baywater Lane"
city="Northbrook" telephone="555-2345678"/>
<owners first_name="Herb" last_name="Dalton" address="2 Main St"
city="Southfield" telephone="555-3456789"/>
<owners first_name="Dave" last_name="Smith-Jones" address="12 Kent Way"
city="Southfield" telephone="555-4567890"/>
<owners first_name="John" last_name="Hudson" address="15 Dorset Av"
city="Easton" telephone="555-7654321"/>
<pets/>
<visits/>
</dataset>The
id column has been left out of the
data set. This test fails with this
output:
junit.framework.AssertionFailedError: column count (table=owners)
expected:<5> but was:<6>
at org.dbunit.Assertion.assertEquals(Assertion.java:112)
at com.ora.javapowertools.dao.test.FlatXmlInsertOwnerIgnoreSequenceTest.
assertTable
(FlatXmlInsertOwnerIgnoreSequenceTest.java:41)
at com.ora.javapowertools.dao.test.FlatXmlInsertOwnerIgnoreSequenceTest.
testInsertOwner
(FlatXmlInsertOwnerIgnoreSequenceTest.java:53)
...This is because DbUnit by default compares all columns in the expected
table to all columns in the actual table. Because the actual table contains
the id column and the existing table does
not, the test fails.
We can correct this by applying a decorator to the actual table to remove
the columns that are not in the expected table. We do this with this code in
our assertTable method:
private void assertTable(String dataSetFilename, String tableName) throws
Exception {
IDataSet expectedDataSet =
new FlatXmlDataSet(getClass().getResourceAsStream(dataSetFilename));
ITable expectedTable = expectedDataSet.getTable(tableName);
ITable actualTable = getConnection().createDataSet().getTable(tableName);
ITable actualToCompare = DefaultColumnFilter
.includedColumnsTable(actualTable,
expectedTable.getTableMetaData().
getColumns());
Assertion.assertEquals(expectedTable, actualToCompare);
}This technique is often handy for “system” columns such as sequence numbers and timestamps.
Verifying an INSERT, with the Key
There are often times when you do want to check the
value of a generated key. One way we can do this with our current test is to
reset the sequence to a known value. We add a new method, setSequence>setSequence():
private void setSequence(String sequence, int startValue) {
Connection conn = null;
Statement stmt = null;
try {
conn = DataSourceUtils.getDataSource().getConnection();
stmt = conn.createStatement();
stmt.execute("DROP SEQUENCE " + sequence);
stmt.execute("CREATE SEQUENCE " + sequence + " START WITH " + startValue);
}
catch (SQLException ex) {
throw new RuntimeException(ex);
}
finally {
JdbcUtils.closeStatement(stmt);
JdbcUtils.closeConnection(conn);
}
}Then, we change the test code to the following:
public void testInsertOwner() throws Exception {
setSequence("owners_seq", 5);
OwnerDao ownerDao = getOwnerDao();
Owner owner = new Owner();
owner.setFirstName("John");
owner.setLastName("Hudson");
owner.setAddress("15 Dorset Av");
owner.setCity("Easton");
owner.setTelephone("555-7654321");
ownerDao.storeOwner(owner);
assertTable("FlatXmlInsertOwnerWithSequenceTest.xml", "owners");
}This method uses the Oracle-specific technique for resetting a sequence: dropping and recreating it. Obviously, you would need to substitute something else for this if you are using a different database.
Another point to note about this technique is that DROP and CREATE are DDL operations. This means that they cannot be
contained within a transaction. Depending on how you are managing
transactions in both your production and test code, this can have
implications for the ways that you organize your code.
In the DbUnit tests that we’ve seen so far, the DbUnit setUp() and the code under test have been run
in their own transactions. Thus, the data being primed into the database is
COMMITted, and so are the data
changed by the test. In this scenario, there is no problem with DDL running
as part of the test.
Later, we’ll look at an example in which we update the database but roll back the update at the end of the test. In that variation, we need to be careful not to use DDL within the transaction we wish to roll back.
As well as dropping and recreating sequences, you can use DDL at select
points in your tests to achieve other things, too. For example, if you have
circular dependencies in your foreign keys, you cannot arrange a sequence of
tables such that they can be cleanly inserted or deleted. Instead, you could
simply use DDL to DROP
DISABLE the foreign key constraints
before the clean insert, and restore them afterward. This requires hacking
around in the set up operations, but it is a useful technique,
nonetheless.
Replacing Values
We saw earlier a couple of ways of placing NULL into a FlatXmlDataSet.
CsvDataSet also supports the literal null in a CSV file, and
InlineDataSet can similarly support null values inline. It turns out that there are
often times when you want to use custom replacement values in a data set.
DbUnit provides ReplacementDataSet, which can be used
to replace values in a data set, either with null or other values. We can also write some code of our own for
more advanced scenarios.
Using NULL with a ReplacementDataSet
DbUnit’s ReplacementDataSet offers a simple
replacement facility out of the box. Here’s how we could use it to
substitute NULLs into the database, in a
similar way to our earlier examples:
protected IDataSet getDataSet() throws Exception {
IDataSet result = dataSet(
table("owners",
col("id", "first_name", "last_name", "address", "city", "telephone"),
row("1", "Mandy", "Smith", "12 Oxford Street", "Southfield", "(NULL)"),
row("2", "Joe", "Jeffries", "25 Baywater Lane", "(NULL)", "555-2345678"),
row("3", "Herb", "Dalton", "2 Main St", "Southfield", "(NULL)"),
row("4", "Dave", "Smith-Jones", "12 Kent Way", "(NULL)", "555-4567890")
),
table("pets", col("id")),
table("visits", col("id"))
);
Map objectMap = new HashMap(1);
objectMap.put("(NULL)", null);
return new ReplacementDataSet(result, objectMap, null);
}In this example, we’ve used ReplacementDataSet with
an InlineDataSet. For this use it is rather pointless
because, as mentioned, we can simply use a literal null with that data set anyway.
But ReplacementDataSet can be used in this way with
any data set. ReplacementDataSet is a decorator
and wraps an existing data set.
ReplacementDataSet works with a
Map of replacement values. In our example, we
placed a single entry in the Map: the string "(NULL),"null. You can place any number of
key/value replacement pairs you like.
Using NULL with a ValueReplacer
DbUnit’s own ReplacementDataSet is somewhat limited
in that you can specify only literal values as replacements. Sometimes you
need more flexibility. For example, it would be nice to have DbUnit call
some arbitrary code to compute a replacement value.
We can add this functionality pretty easily. First, we define a
ValueReplacer interface:
public interface ValueReplacer {
Object replaceValue(Object value);
} This defines a callback, or strategy, that we can get DbUnit to call.
To replace values in an ITable, we’ll use a
ValueReplacerTable decorator:
public class ValueReplacerTable implements ITable {
private ITable target;
private ValueReplacer valueReplacer;
public ValueReplacerTable(ITable target, ValueReplacer valueReplacer) {
this.target = target;
this.valueReplacer = valueReplacer;
}
public ITableMetaData getTableMetaData() {
return target.getTableMetaData();
}
public int getRowCount() {
return target.getRowCount();
}
public Object getValue(int row, String column) throws DataSetException {
Object value = target.getValue(row, column);
return valueReplacer.replaceValue(value);
}
} This
ITable decorates an existing
ITable, replacing values in it according to the
ValueReplacer
strategy.
Let’s define a trivial example of a ValueReplacer
strategy, one that in effect does just the same as the existing
ReplacementDataSet:
public class LiteralValueReplacer implements ValueReplacer {
private String matchValue;
private Object replacementValue;
public LiteralValueReplacer() {
}
public LiteralValueReplacer(String matchValue, Object replacementValue) {
this.matchValue = matchValue;
this.replacementValue = replacementValue;
}
public void setMatchValue(String matchValue) {
this.matchValue = matchValue;
}
public void setReplacementValue(Object replacementValue) {
this.replacementValue = replacementValue;
}
public Object replaceValue(Object value) {
if (value instanceof String) {
String stringValue = (String) value;
if (stringValue.equals(matchValue)) {
return replacementValue;
}
}
return value;
}
}We can use this LiteralValueReplacer to replace the
string "(NULL)" with null as follows:
protected IDataSet getDataSet() throws Exception {
return dataSet(
new ValueReplacerTable(
table("owners",
col("id", "first_name", "last_name", "address", "city", "telephone"),
row("1", "Mandy", "Smith", "12 Oxford Street", "Southfield", "(NULL)"),
row("2", "Joe", "Jeffries", "25 Baywater Lane", "(NULL)", "555-2345678"),
row("3", "Herb", "Dalton", "2 Main St", "Southfield", "(NULL)"),
row("4", "Dave", "Smith-Jones", "12 Kent Way", "(NULL)", "555-4567890")
),
new LiteralValueReplacer("(NULL)", null)
),
table("pets", col("id")),
table("visits", col("id"))
);
} Using an Image ValueReplacer
Let’s now use ValueReplacerTable to do something
that we can’t do with the simplistic
ReplacementDataSet. This time we’ll use the
pets table for our test, instead of
the owners table.
The pets table includes a
BLOB column named image for the pet’s photo. We’ll specify a
BLOB value in a dataset by giving a resource name
from which to load the BLOB. We’ll indicate that the
value is a BLOB by prefixing the resource name with the
string "blob:," e.g., "blob:fido.jpg."
Because the idea of
prefixing a value is quite general and distinct from actually using
BLOBs, we’ll start with a
PrefixValueReplacer:
public abstract class PrefixValueReplacer implements ValueReplacer {
private String prefix;
protected PrefixValueReplacer(String prefix) {
this.prefix = prefix;
}
public void setPrefix(String prefix) {
this.prefix = prefix;
}
public Object replaceValue(Object value) {
if (value instanceof String) {
String stringValue = (String) value;
if (stringValue.startsWith(prefix)) {
String remainingString = stringValue.substring(prefix.length());
return doReplaceValue(remainingString);
}
}
return value;
}
protected abstract Object doReplaceValue(String remainingString);
} The PrefixValueReplacer class takes care of
recognizing the prefix and deciding when it applies. We can now extend this
class for the specific case of BLOBs:
public class BlobValueReplacer extends PrefixValueReplacer {
private static final String DEFAULT_PREFIX = "blob:";
public BlobValueReplacer() {
this(DEFAULT_PREFIX);
}
public BlobValueReplacer(String prefix) {
super(prefix);
}
protected Object doReplaceValue(String remainingString) {
InputStream inputStream = null;
try {
inputStream = getClass().getResourceAsStream(remainingString);
return IOUtils.bytesFromStream(inputStream);
}
finally {
IOUtils.closeInputStream(inputStream);
}
}
}The BlobValueReplacer loads the specified
BLOB as a resource from the classpath, and uses it as
the replacement value.
We can tie this together in a test case for the
PetDao
DAO. First, we apply our ValueReplacerTable in getDataSet():
protected IDataSet getDataSet() throws Exception {
ITable typesTable = table("types",
col("id", "name"),
row("1", "Cat"),
row("2", "Bird"),
row("3", "Fish"),
row("4", "Dog")
);
ITable ownersTable = table("owners",
col("id", "first_name", "last_name", "address", "city", "telephone"),
row("1", "Mandy", "Smith", "12 Oxford Street", "Southfield", "555-1234567"),
row("2", "Joe", "Jeffries", "25 Baywater Lane", "Northbrook", "555-2345678"),
row("3", "Herb", "Dalton", "2 Main St", "Southfield", "555-3456789"),
row("4", "Dave", "Smith-Jones", "12 Kent Way", "Southfield", "555-4567890")
);
ITable petsTable = table("pets",
col("id", "name", "birth_date", "type_id", "owner_id", "image"),
row("1", "Fido", "1999-10-22", "4", "1", "blob:fido.jpg"),
row("2", "Rex", "2001-01-20", "4", "4", "blob:rex.jpg"),
row("3", "Guppers", "2006-12-25", "3", "2", "(NULL)"),
row("4", "Bonnie", "2005-03-12", "1", "3", "(NULL)"),
row("5", "Ditzy", "2004-07-08", "1", "3", "(NULL)")
);
petsTable = new ValueReplacerTable(petsTable,
new LiteralValueReplacer("(NULL)", null));
petsTable = new ValueReplacerTable(petsTable, new BlobValueReplacer());
return dataSet(
typesTable,
ownersTable,
petsTable
);
} We’re
actually using two ValueReplacerTables: one for the
BLOBs, and another for NULLs. We can wrap as many decorators as we wish around a
given ITable.
The pets table has referential
integrity constraints to both the types
table and the owners table, so we need to
provide data for them, too. The returned data set includes all three
tables.
Now, we can write the test case, along with an assertion method for
Pet objects:
private static void assertEquals(byte[] expected, byte[] actual) {
if (expected == null) {
assertNull(actual);
return;
}
assertEquals(expected.length, actual.length);
for (int i = 0; i < expected.length; i++) {
assertEquals(expected[i], actual[i]);
}
}
private byte[] image(String resource) {
InputStream inputStream = null;
try {
inputStream = getClass().getResourceAsStream(resource);
return IOUtils.bytesFromStream(inputStream);
}
finally {
IOUtils.closeInputStream(inputStream);
}
}
private static void assertPet(Pet pet, int id, String name, LocalDate birthDate,
String typeName, String ownerFirstName, byte[] image) {
assertEquals(id, pet.getId());
assertEquals(name, pet.getName());
assertEquals(birthDate, pet.getBirthDate());
assertEquals(typeName, pet.getType().getName());
assertEquals(ownerFirstName, pet.getOwner().getFirstName());
assertEquals(image, pet.getImage());
}
public void testValues() {
PetDao petDao = getPetDao();
assertPet(petDao.loadPet(1), 1, "Fido", ld(1999, 10, 22), "Dog", "Mandy",
image("fido.jpg"));
assertPet(petDao.loadPet(2), 2, "Rex", ld(2001, 1, 20), "Dog", "Dave",
image("rex.jpg"));
assertPet(petDao.loadPet(3), 3, "Guppers", ld(2006, 12, 25), "Fish",
"Joe", null);
} In this test, as in our domain class, we’re treating the image as a
byte[] object. In a real domain
model, you would probably use a higher level of abstraction. Either way, we
need to verify that we got the correct set of bytes from the
database.
Hopefully, this example has given you some idea of how you can extend DbUnit’s data sets with decorators of your own to provide for quite flexible and elegant ways of loading data into your database, and verifying data.
Alternative Dataset Formats
The FlatXmlDataSet format for test data is the de facto
“standard” format for DbUnit testing. It is quite flexible, and easy to use, and
probably contains support for the most features. DbUnit does provide several
additional options however. Let’s take a look at a couple of them.
Using an XLS Dataset
One of the biggest drawbacks of the XML format is that it tends to lose the “tableness” of the data. The XML syntax, rather than highlighting the structure of the information, tends to obscure it. It would be nice if we could represent our test data in a format that looks more like a database table.
One commonly known tool that can represent data in a tabular form is a
spreadsheet. Thanks to the Apache POI library,[*] DbUnit can offer support for data sets in Microsoft Excel
(XLS) files via its XlsDataSet
class. To use Excel files with DbUnit, you need to download the
POI JAR and place it in your classpath.
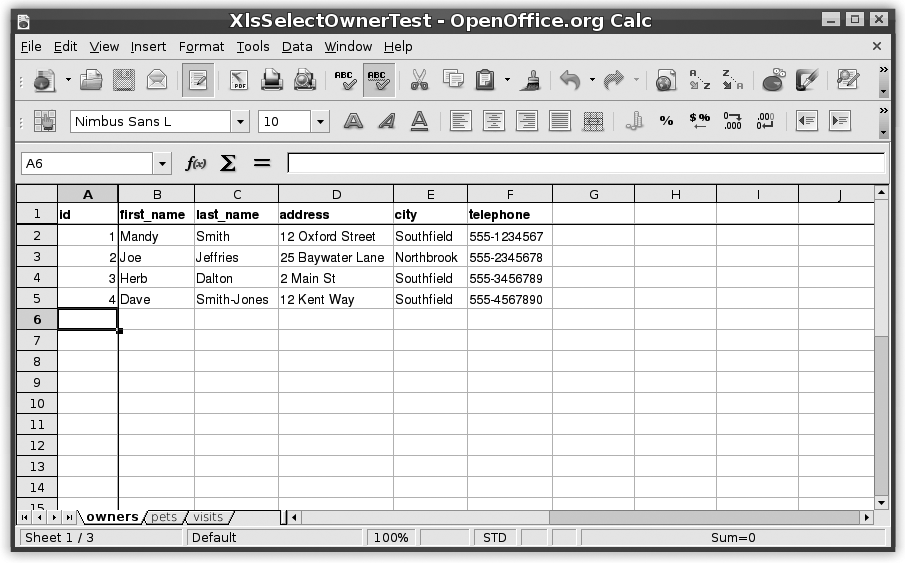
Let’s see how the data set looks using XLS files. We
make each table a tab in the spreadsheet file, named for the table. The
first row of tab contains the column names. The rest of the rows contain the
data. For our SELECT test on the owners table, an example is shown in Figure 14-7.
To use this data set in our test, all we need to do is change the
implementation of getDataSet() to use an
XlsDataSet:
protected IDataSet getDataSet() throws Exception {
return new XlsDataSet(getClass().getResourceAsStream("XlsSelectOwnerTest.xls"));
}Notice that again the constructor accepts any
InputStream, which is very convenient.
You can, of course, prepare your XLS files using Microsoft Excel. If you are using GNU/Linux, or even on Windows, you may prefer to use OpenOffice[13] instead. It’s free, and it appears to create files that are more XLS-compatible than Excel itself. (You may have less trouble reading OpenOffice-saved XLS files with POI.)
Using a CSV Dataset
Even though the XLS format is nice and tabular, it is still not ideal. The biggest problem with it, from a typical programmer’s perspective, is that the file format is essentially an opaque binary format. It doesn’t work well with standard development tools such as text editors and version control systems. It would be preferable to use some kind of plain text format.
A common plain text format that has a tabular layout is the venerable
“comma-separated values” or CSV file. DbUnit supports
CSV data sets via its
CsvDataSet class. Let’s adapt the
SelectOwner test to use a
CsvDataSet.
Again, the only change to our code is in getDataSet():
protected IDataSet getDataSet() throws Exception {
return new CsvDataSet(new File("src/test/com/ora/javapowertools/dao/test/csv/"));
}For CSV data sets, we provide the path to the directory
containing CSV files. Unfortunately, this must be
provided as a (relative) filesystem path, rather than an InputStream. In our example, the
CSV files are in src/test/com/ora/javapowertools/dao/test/csv, relative to
the project root directory.
DbUnit’s CsvDataSet first looks in this directory
for a file named table-ordering.txt.
This file names the data set’s tables in the order in which DbUnit is to
populate them. For our example, the file contains:
owners pets visits
Also in the directory, we place a CSV file for each table, with extension .csv. The owners.csv file contains these lines:
id,first_name,last_name,address,city,telephone 1,Mandy,Smith,12 Oxford Street,Southfield,555-1234567 2,Joe,Jeffries,25 Baywater Lane,Northbrook,555-2345678 3,Herb,Dalton,2 Main St,Southfield,555-3456789 4,Dave,Smith-Jones,12 Kent Way,Southfield,555-4567890
The CsvDataSet gives a nice text-based, tabular
representation of the test data. It plays friendly with version control and
other development tools. One disadvantage of CsvDataSet is that the test data is even more spread out
and removed from the test code than before.
Using an InlineDataSet
A common problem with all of the data sets we’ve looked at so far is that the data is separated from the test code. Much of the time, this is not a problem; in fact it is desirable. It is a common practice with DbUnit to put common “reference” data into a data set to be loaded by a common base class for all tests. That way, a certain “baseline” set of data is always available.
In many tests, however, it would be nicer to place the data that relates specifically to the test closer to the test code. It would be nice to put the data in the test code. That’s what we’ll do now with an inline data set.
Our InlineDataSet is very simple, though it does
make use of the varargs feature introduced in Java 5:
public class InlineDataSet {
public static IDataSet dataSet(ITable... tables) {
return new DefaultDataSet(tables);
}
public static ITable table(String name, String[] cols, String[]... data)
throws DataSetException {
Column[] columns = new Column[cols.length];
for (int i = 0; i < cols.length; i++) {
columns[i] = new Column(cols[i], DataType.UNKNOWN);
}
DefaultTable result = new DefaultTable(name, columns);
for (String[] row : data) {
result.addRow(row);
}
return result;
}
public static String[] col(String... columns) {
return columns;
}
public static String[] row(String... data) {
return data;
}
} The implementation is very brief, because it mostly uses preexisting
functionality provided with DbUnit, such as
DefaultDataSet and
DefaultTable.
The static methods are intended to be imported and used by test classes,
and the varargs argument lists allow test
classes to represent data quite elegantly, as in the new version of our
getDataSet() method:
protected IDataSet getDataSet() throws Exception {
return dataSet(
table("owners",
col("id", "first_name", "last_name", "address", "city", "telephone"),
row("1", "Mandy", "Smith" , "12 Oxford Street", "Southfield",
"555-1234567"),
row("2", "Joe" , "Jeffries" , "25 Baywater Lane", "Northbrook",
"555-2345678"),
row("3", "Herb" , "Dalton" , "2 Main St" , "Southfield",
"555-3456789"),
row("4", "Dave" , "Smith-Jones", "12 Kent Way" , "Southfield",
"555-4567890")
),
table("pets", col("id")),
table("visits", col("id"))
);
}
This time, there is no need to reference and
InputStream or other external file for the data
set. All of the data is included inline in the test code.
The rest of the code doesn’t change. Now we have the test code and the data for it together, so it’s easier to edit it and see what relates to what.
Again, we need to stress that this is appropriate only for data specific
to each test case. If you have common data you want to use for a set of
tests, or all your tests, you should load that data in a common setUp() routine, and you may find no advantage
to placing the data inline.
Dealing with Custom Data Types
You may have noticed that in all of the data sets we’ve looked at,
the data values are given simply as strings. How does DbUnit know what the type
of a column is supposed to be? How does DbUnit distinguish among the treatment
of a VARCHAR and a NUMBER and a DATE?
DbUnit uses DataTypes to do this. A
DataType is DbUnit’s abstraction for a
JDBC data type. DbUnit includes built-in
DataTypes for all of the standard
JDBC data types.
Some databases treat certain DataTypes differently. For
example, although JDBC distinguishes among DATE, TIME, and
TIMESTAMP, Oracle for a long time
supported only a single DATE type, which
served the purpose of all three.
DbUnit caters for variation of JDBC data types across
databases using a DataTypeFactory.
The DataTypeFactory determines the
DataType for a column. DbUnit provides a basic
DataTypeFactory for each of several popular databases
out of the box.
For example, the OracleDataTypeFactory causes columns
with JDBC type of either DATE or TIMESTAMP to be
treated as TIMESTAMPs within DbUnit. To use
the OracleDataTypeFactory in your
test, you set a property in the DatabaseConfig on the
IDatabaseConnection:
protected IDatabaseConnection getConnection() throws Exception {
IDatabaseConnection result = super.getConnection();
DatabaseConfig config = result.getConfig();
config.setProperty(DatabaseConfig.PROPERTY_DATATYPE_FACTORY,
new OracleDataTypeFactory());
return result;
}In this section, we’ll see how you can extend DbUnit’s
DataType and DataTypeFactory
framework and provide support for custom data types.
Specifying an INTERVALDS Data Type
Although the INTERVAL data types have
been part of the SQL standard for a long time (since ANSI SQL-92), they have
never been supported by JDBC. This is a pity, because
they are often an appropriate choice for columns in a well-considered data
model.
However, it is often possible to use INTERVAL types anyway, using vendor-specific
JDBC extensions. Let’s see how to use INTERVALs with DbUnit, using an addition to
the PetClinic schema.
I’ve added a duration column to the
original visits table. The DDL is shown
here:
CREATE TABLE visits ( id INTEGER NOT NULL, pet_id INTEGER NOT NULL, visit_date DATE, duration INTERVAL DAY TO SECOND, description VARCHAR(255) );
In the domain model, I’ve added a duration property, using the Duration
class from the Joda-Time date/time library.[*]
As already mentioned, DbUnit’s
OracleDataTypeFactory handles standard JDBC date
and time types. It also handles some variations of CLOBs
and binary large object (BLOBs). There are several
Oracle-specific data types that OracleDataTypeFactory
does not handle, however. These include the INTERVAL types, and also Oracle’s XMLType support, for example.
We’ll define our own DataType for Oracle’s INTERAL DAY TO SECOND. Before we do this, we
need to know a few things about how the type works:
What JDBC type does the driver return for an
INTERAL DAY TO SECONDcolumn?What Java class does the driver return for these objects?
How should comparisons be done for this type?
One way to answer these questions is to write some simple exploratory code. We can define a simple test table like this:
CREATE TABLE t (
c INTERVAL DAY TO SECOND
);
INSERT INTO t VALUES (INTERVAL '1' DAY);
INSERT INTO t VALUES (INTERVAL '1 2:03:04' DAY TO SECOND);
INSERT INTO t VALUES (INTERVAL '1' HOUR);
COMMIT WORK;
With this test table in place, we can investigate the JDBC properties of the column with some simple Java code:
public class PrintINTERVALDSMetaData {
public static void main(String[] args) throws SQLException {
Connection conn = DataSourceUtils.getDataSource().getConnection();
ResultSet rs = conn.createStatement().executeQuery("SELECT * FROM t ORDER BY 1");
ResultSetMetaData metaData = rs.getMetaData();
System.out.println("metaData.getColumnType(1) = " + metaData.getColumnType(1));
while (rs.next()) {
Object c = rs.getObject(1);
System.out.println("c.getClass() = " + c.getClass());
System.out.println("c.toString() = " + c.toString());
}
}
} This code prints the following output:
metaData.getColumnType(1) = -104 c.getClass() = class oracle.sql.INTERVALDS c.toString() = 0 1:0:0.0 c.getClass() = class oracle.sql.INTERVALDS c.toString() = 1 0:0:0.0 c.getClass() = class oracle.sql.INTERVALDS c.toString() = 1 2:3:4.0
From this, we can determine the answers to our questions:
The JDBC type for Oracle’s
INTERVAL DAY TO SECONDis –104. The constantoracle.jdbc.OracleTypes.INTERVALDSis defined to this value.The Java class is
oracle.sql.INTERVALDS.For comparison purposes, as long as we only care about value equality, we can compare the
toString()representation of the object.
With this information, we can define a
OracleINTERVALDSDataType data type:
public class OracleINTERVALDSDataType extends AbstractDataType {
public OracleINTERVALDSDataType() {
super("INTERVALDS", OracleTypes.INTERVALDS, INTERVALDS.class, false);
}
public Object typeCast(Object value) throws TypeCastException {
return value;
}
public int compare(Object o1, Object o2) throws TypeCastException {
return o1.toString().equals(o2.toString()) ? 0 : 1;
}
} There is not much work to do because most of it can be done by the base
class AbstractDataType, provided that we call its
constructor and give it the appropriate values. In other cases, you may need to implement more methods
of IDataType your self to get your custom data type
to work. See the source code for more details.
In order to use this data type in our test, we need to create a
DataTypeFactory that recognizes Oracle INTERVAL DAY TO SECOND columns and associates
them with this data type:
public class OracleINTERVALDSDataTypeFactory extends DefaultDataTypeFactory {
public static final DataType ORACLE_INTERVALDS = new OracleINTERVALDSDataType();
public DataType createDataType(int sqlType, String sqlTypeName)
throws DataTypeException {
if (sqlType == OracleTypes.INTERVALDS || "INTERVALDS".equals(sqlTypeName)) {
return ORACLE_INTERVALDS;
}
return super.createDataType(sqlType, sqlTypeName);
}
} Now we need to specify this data type factory on our
IDatabaseConnection when the test runs:
protected IDatabaseConnection getConnection() throws Exception {
IDatabaseConnection result = super.getConnection();
DatabaseConfig config = result.getConfig();
config.setProperty(DatabaseConfig.PROPERTY_DATATYPE_FACTORY,
new OracleINTERVALDSDataTypeFactory());
return result;
} Finally, to specify INTERVAL DAY TO
SECOND values in our test data set, we need a ValueReplacer that can create them.
We’ll use an extension of PrefixValueReplacer again,
this time with default prefix "INTERVALDS:":
public class INTERVALDSValueReplacer extends PrefixValueReplacer {
public static final String DEFAULT_PREFIX = "INTERVALDS:";
public INTERVALDSValueReplacer() {
this(DEFAULT_PREFIX);
}
public INTERVALDSValueReplacer(String prefix) {
super(prefix);
}
protected INTERVALDS doReplaceValue(String remainingString) {
return new INTERVALDS(remainingString);
}
} That is starting to seem like a lot of work, but we are almost done. We
can now write a test method that specifies an expected visits table with an INTERVAL DAY TO SECOND column:
public void testValues() throws Exception {
setSequence("visits_seq", 1);
Pet fido = getPetDao().loadPet(1);
Visit visit = new Visit();
visit.setPet(fido);
visit.setVisitDate(ld(2007, 11, 4));
visit.setDuration(dur(1, 6, 30, 0));
visit.setDescription("Upset tummy");
VisitDao visitDao = getVisitDao();
visitDao.storeVisit(visit);
ITable expectedTable = table("visits",
col("id", "pet_id", "visit_date", "duration", "description"),
row("1", "1", "2007-11-04", "INTERVALDS:1 06:30:00.0", "Upset tummy")
);
expectedTable = new ValueReplacerTable(expectedTable,
new INTERVALDSValueReplacer());
assertTable(expectedTable, "visits");
} Note again that although we’ve used the inline data set for the example,
this value replacement technique can be used just as easily with any other
DbUnit data set, including FlatXmlDataSet.
Other Applications
We have now looked in detail at many ways of specifying data sets and customizing their behavior. Let’s look at some different aspects of DbUnit and database testing.
Injecting the Test Fixture
In our tests so far we’ve used the DataSourceUtils.getDataSource() utility method to obtain a
DataSource. Real applications generally do
not-hard code their data source configuration, although it may be perfectly
acceptible for test code.
These days, it is popular to use dependency injection to obtain data sources and other external resources, and sometimes it may be an advantange to inject these dependencies into test code, too.
Probably the most popular dependency-injection framework today is Spring.[*] Spring provides a variety of useful services for JEE applications, and is very test-friendly. Spring even provides several base classes for integration testing, which can make set up much simpler for testing complex arrangements of components. Let’s see how we can use Spring to inject the data source for our tests.
Spring’s basic support for dependency injection in tests is the base class
AbstractDependencyInjectionSpringContextTests. By extending
this base class, and telling it where to find your configuration data, you
can get Spring to inject your test classes with resources such as
DataSources.
Let’s define a base class for our dependency-injected database tests:
public abstract class SpringDatabaseTestCase extends
AbstractDependencyInjectionSpringContextTests {
private DataSource dataSource;
private IDatabaseTester tester;
public DataSource getDataSource() {
return dataSource;
}
public void setDataSource(DataSource dataSource) {
this.dataSource = dataSource;
}
protected String[] getConfigLocations() {
return new String[] {
"classpath:/applicationContext.xml"
};
}
protected void onSetUp() throws Exception {
super.onSetUp();
tester = new DataSourceDatabaseTester(getDataSource());
tester.setDataSet(getDataSet());
tester.onSetup();
}
protected abstract IDataSet getDataSet() throws Exception;
protected IDatabaseConnection getConnection() throws Exception {
return tester.getConnection();
}
protected void closeConnection(IDatabaseConnection connection) throws Exception {
tester.closeConnection(connection);
}
}This class does not extend DatabaseTestCase. It
cannot because it extends Spring’s
AbstractDependencyInjectionSpringContextTests.
Instead, it instantiates an IDatabaseTester of its
own, and uses that to provide DbUnit functionality. The class provides
getDataSet(), getConnectionand (),
closeConnection() methods as does
IDatabaseTestCase, so the idea is it can be
similarly extended by concrete test subclasses.
This base class instructs Spring to load the configuration from a single application context file, applicationContext.xml, located in the root of the classpath. We put this configuration in the file:
<!DOCTYPE beans PUBLIC "-//SPRING//DTD BEAN//EN"
"http://www.springframework.org/dtd/spring-beans.dtd">
<beans>
<!-- DataSource -->
<bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource">
<!-- The first properties are standard required commons DBCP DataSource
configuration. -->
<property name="driverClassName" value="${db.driver}" />
<property name="url" value="${db.url}" />
<property name="username" value="${db.userid}" />
<property name="password" value="${db.password}" />
</bean>
<bean class="org.springframework.beans.factory.config.PropertyPlaceholderConfigurer">
<property name="location" value="classpath:/applicationContext.properties"/>
<property name="systemPropertiesModeName" value="SYSTEM_PROPERTIES_MODE_OVERRIDE"/>
</bean>
<bean id="transactionManager"
class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource"/>
</bean>
</beans> The configuration simply defines the dataSource bean as being a
org.apache.commons.dbcp.BasicDataSource instance,
as we had before. However, the class, URL, username, and password are now
controlled by system properties. Also, there is a Spring
DataSourceTransactionManager defined, which we
would be using if we wrote our DAOs using Spring JDBC
DAO support.
In a real application, you would also place configuration for your DAO themselves, your ORM configuration, and so forth, into the Spring application context file. To keep this example simple, we configure only the data source.
We can write a test class using this base class like this:
public class SpringInlineSelectOwnerTest extends SpringDatabaseTestCase {
protected IDataSet getDataSet() throws Exception {
return dataSet(
table("owners",
col("id", "first_name", "last_name", "address", "city", "telephone"),
row("1", "Mandy", "Smith" , "12 Oxford Street", "Southfield",
"555-1234567"),
row("2", "Joe" , "Jeffries" , "25 Baywater Lane", "Northbrook",
"555-2345678"),
row("3", "Herb" , "Dalton" , "2 Main St" , "Southfield",
"555-3456789"),
row("4", "Dave" , "Smith-Jones", "12 Kent Way" , "Southfield",
"555-4567890")
),
table("pets", col("id")),
table("visits", col("id"))
);
}
private OwnerDao getOwnerDao() {
return new SpringJdbcOwnerDao(getDataSource());
}
private static void assertOwner(Owner owner, int id, String firstName, String lastName,
String address, String city, String telephone) {
assertEquals(id, owner.getId());
assertEquals(firstName, owner.getFirstName());
assertEquals(lastName, owner.getLastName());
assertEquals(address, owner.getAddress());
assertEquals(city, owner.getCity());
assertEquals(telephone, owner.getTelephone());
}
public void testValues() {
OwnerDao ownerDao = getOwnerDao();
assertOwner(ownerDao.loadOwner(1), 1, "Mandy", "Smith", "12 Oxford Street",
"Southfield", "555-1234567");
assertOwner(ownerDao.loadOwner(2), 2, "Joe", "Jeffries", "25 Baywater Lane",
"Northbrook", "555-2345678");
assertOwner(ownerDao.loadOwner(3), 3, "Herb", "Dalton", "2 Main St",
"Southfield", "555-3456789");
assertOwner(ownerDao.loadOwner(4), 4, "Dave", "Smith-Jones", "12 Kent Way",
"Southfield", "555-4567890");
}
} Using Transaction Rollback Teardown
Another technique, or trick, that is often used in database
integration tests is called transaction rollback
teardown. This technique is to have the tearDown() method roll back changes made
during the test. This avoids the need to prime the database with all data
before every single test case. The sole advantage of this technique is in
performance, but the benefit is sometimes considerable. Tests using this
pattern can run much faster than tests without it.
Transaction rollback teardown requires careful management of database
connections. It is necessary that priming the database, the code under test,
and any verification code all use the same connection. It is also necessary
that none of the code commits a transaction on the connection. And, finally,
the tearDown() method needs to rollback
the connection at some point.
In typical use, you would prime your database with standard reference data before running your test suite. Between tests, the database is always returned to its initial state. Individual tests can prime the database with any additional data they need that is peculiar to specific tests.
Spring provides a convenient base class for tests wanting to use
transaction rollback teardown:
AbstractTransactionalSpringContextTests. When
using this base class, Spring manages all the transaction rollback for you.
You need to ensure that all database access by your code is via Spring’s
transaction-aware utility classes such as JdbcTemplate. You also need to ensure that you don’t
inadvertently commit any changes at the wrong point. This means, for
example, being careful where you execute any DDL.
Let’s define a base class for our Spring transaction rollback teardown tests:
public abstract class SpringTransactionalDatabaseTestCase
extends AbstractTransactionalSpringContextTests {
private DataSource dataSource;
private IDatabaseTester tester;
public DataSource getDataSource() {
return dataSource;
}
public void setDataSource(DataSource dataSource) {
this.dataSource = dataSource;
}
protected String[] getConfigLocations() {
return new String[] {
"classpath:/applicationContext.xml"
};
}
protected void onSetUpInTransaction() throws Exception {
super.onSetUpInTransaction();
new JdbcTemplate(dataSource).execute(new ConnectionCallback() {
public Object doInConnection(Connection con) throws DataAccessException {
try {
tester = new DefaultDatabaseTester(new DatabaseConnection(con));
tester.setDataSet(getDataSet());
tester.onSetup();
}
catch (Exception ex) {
throw new RuntimeException(ex);
}
return null;
}
});
}
protected abstract IDataSet getDataSet() throws Exception;
protected IDatabaseConnection getConnection() throws Exception {
return tester.getConnection();
}
protected void closeConnection(IDatabaseConnection connection) throws Exception {
tester.closeConnection(connection);
}
} This
class is pretty similar to the SpringDatabaseTestCase
class we defined earlier. The main difference is that we now prime the
database with the initial data set inside a Spring
JdbcTemplate method, which uses Spring’s
transaction-aware connection management.
Also, note that the setup method is now called onSetUpInTransaction(). Spring’s
AbstractTransactionalSpringContextTests provides
both onSetUpInTransaction() and onSetUpBeforeTransaction(), so that you can
place set up code inside or outside of the transaction as necessary. If we
needed to run DDL, for example to reset a sequence, we could do it in
onSetUpBeforeTransaction().
With this base class written, our test is just the same as before, except
that we extend the new base class. Note that the DAO
implementation is SpringJdbcOwnerDao, which is a
DAO class written using Spring’s transaction-aware
JdbcDaoSupport.
The transaction rollback teardown pattern does suffer from several potential pitfalls:
You lose some test isolation. Each test assumes the database is in a certain starting condition before
setUp()runs, and the rollback must revert it back to that condition. Each test is not responsible for priming the database with all the state that it needs.You can’t see what’s in the database when something goes wrong. If your test fails, you usually want to examine the database to see what happened. If you’ve rolled back the changes, it’s harder to see the bug.
You have to be careful not to inadvertently commit during your test. As mentioned already, any DDL must be run outside the transaction. However, it is easy to make a mistake with this, and the results can be very confusing.
Some tests do need to commit changes, and you cannot easily mix these into the same suite. For example, you may wish to test PL/SQL stored procedures. These generally do explicit
COMMITs. You cannot mix these in the same JUnit suite with tests that assume that the database always remains in a certain state between tests.
The verdict on transaction rollback teardown is: make you own decision. Be aware of the consequences, and use it if the performance benefit outweighs the potential pitfalls. If you are careful in your test design, you may find that switching between the two approaches is not too hard.
Testing a Stored Procedure
So far we’ve talked about testing Java code such as DAOs. DbUnit can be used for any tests that involve a real database. Some of these tests might be end-to-end integration tests of components of your application. You might also find it easy to use DbUnit to test your database code itself, such as stored procedures.
There are, of course, unit testing frameworks for stored procedures for some databases. In many cases, they may be the most sensible tool to use for stored procedure tests. However, priming the database with known data, and verifying tables after a test—what DbUnit is specifically designed for—are both rather awkward in straight SQL or PL/SQL code. It is much the same problem as we’d faced when trying to do it with straight JDBC code. For these jobs, it is often better to use DbUnit. In addition, it integrates very neatly into your Java tests, which are used by your continuous integration system and IDE and all the other cool stuff you have for Java.
We’ll use a rather contrived and simple example to test a stored
procedure. Suppose we have a table specialist_vets in which we wish to store copies of all the
vets rows that have more than one
specialty in the specialty table. The
vet_specialties table has the
identical structure to vets. The stored
procedure, in a PL/SQL package, looks like this:
CREATE OR REPLACE PACKAGE pkg_clinic AS
PROCEDURE reload_specialist_vets;
END;
/
CREATE OR REPLACE PACKAGE BODY pkg_clinic AS
PROCEDURE reload_specialist_vets IS
BEGIN
DELETE FROM specialist_vets;
INSERT INTO specialist_vets
SELECT id, first_name, last_name
FROM vets
WHERE EXISTS (
SELECT vet_id, COUNT(*)
FROM vet_specialties
WHERE vet_id = vets.id
GROUP BY vet_id
HAVING COUNT(*) > 1
);
COMMIT WORK;
END;
END;
/ It is surprisingly easy to use DbUnit to test this kind of code. We have a setup data set, just the same as before, which we won’t repeat here. Then we have the test code:
public void testReloadSpecialistVets() throws Exception {
ITable expectedBefore = table("specialist_vets",
col("id", "first_name", "last_name")
);
ITable expectedAfter = table("vw_specialist_vets",
col("id", "first_name", "last_name"),
row("1", "Harry", "Seuss"),
row("2", "Mary", "Watson")
);
assertTable(expectedBefore, "specialist_vets");
executeCallableStatement("{call pkg_clinic.reload_specialist_vets}");
assertTable(expectedAfter, "specialist_vets");
}
private void executeCallableStatement(String sql) throws SQLException {
Connection conn = null;
CallableStatement stmt = null;
try {
conn = DataSourceUtils.getDataSource().getConnection();
stmt = conn.prepareCall(sql);
stmt.executeUpdate();
conn.commit();
}
finally {
JdbcUtils.closeStatement(stmt);
JdbcUtils.closeConnection(conn);
}
} The code first verifies that no data is in the vet_specialties table at the beginning of the test. Then it
invokes the stored procedure. Finally, it verifies the vet_specialties table at the end.
Any time that you find yourself writing a nontrivial stored procedure, consider whether it would be worth adding a test for it to your test suite. Hopefully, this example shows that this is easy enough to do, once you have your DbUnit testing infrastructure set up.
Testing a View
Just as with stored procedures, we often find ourselves defining views that contain non-trivial logic. Again, these should be backed by tests, particularly the more complex ones. And again, DbUnit makes testing views remarkably easy.
Here is a view definition for vw_vet_specialties, a view that returns the vets rows having more than one specialty. This
is a better solution to the requirement solved above by a stored
procedure:
CREATE VIEW vw_specialist_vets AS SELECT id, first_name, last_name FROM vets WHERE EXISTS ( SELECT vet_id, COUNT(*) FROM vet_specialties WHERE vet_id = vets.id GROUP BY vet_id HAVING COUNT(*) > 1 );
private void assertView(ITable expectedView, String sql) throws Exception {
ITable actualView = getConnection().createQueryTable("actual", sql);
Assertion.assertEquals(expectedView, actualView);
}
public void testVwSpecialistVets() throws Exception {
ITable expected = table("vw_specialist_vets",
col("id", "first_name", "last_name"),
row("1", "Harry", "Seuss"),
row("2", "Mary", "Watson")
);
assertView(expected, "SELECT * FROM vw_specialist_vets ORDER BY 1");
}This example shows how you can use DbUnit to verify the results of an arbitrary SQL query, just as easily as verifying a table. Sometimes this form is useful for tables, too, if you want to control the columns or the order of the rows returned.
Exporting a Dataset with Ant
Sometimes it is useful to be able to create a DbUnit
FlatXmlDataSet file from data already existing in
a database. You can use the DbUnit Ant targets for this.
To define the DbUnit Ant tasks in Ant, include this entry in your build.xml script:
<taskdef name="dbunit" classname="org.dbunit.ant.DbUnitTask">
<classpath refid="classpath.lib"/>
</taskdef>You need to specify the classpath where your dbunit.jar is.
To export data from your database, use the <dbunit> target with the <export> option, like this:
<target name="export"
description="Export schema from database to ${dataset.export}">
<dbunit driver="${db.driver}" url="${db.url}" userid="${db.userid}"
password="${db.password}" schema="${db.schema}">
<classpath refid="classpath.lib"/>
<export dest="${dataset.export}"/>
</dbunit>
</target>You can also restrict the set of tables exported. See the DbUnit documentation online for more details.
Importing a Dataset with Ant
To import data from a FlatXmlDataSet file into the
database using the Ant task, use the <dbunit> target with the <operation> option, like this:
<target name="import"
description="Import schema from ${dataset.import} to database">
<dbunit driver="${db.driver}" url="${db.url}" userid="${db.userid}"
password="${db.password}" schema="${db.schema}">
<classpath refid="classpath.lib"/>
<operation type="CLEAN_INSERT" src="${dataset.import}"/>
</dbunit>
</target> This can be useful in combination with the transaction rollback teardown pattern, for setting the database into the initial state before running your test suite.