
Chapter 1. Data access reloaded: Entity Framework
- DataSet and classic ADO.NET approach
- Object model approach
- Object/relational mismatch
- Entity Framework as a solution
When you design an application, you have to decide how to access and represent data. This decision is likely the most important one you’ll make in terms of application performance and ease of development and maintainability. In every project we’ve worked on, the persistence mechanism was a relational database. Despite some attempts to introduce object databases, the relational database is still, and will be for many years, the main persistence mechanism.
Nowadays, relational databases offer all the features you need to persist and retrieve data. You have tables to maintain data, views to logically organize them so that they’re easier to consume, stored procedures to abstract the application from the database structure and improve performance, foreign keys to relate records in different tables, security checks to avoid unauthorized access to sensitive data, the ability to transparently encrypt and decrypt data, and so on. There’s a lot more under the surface, but these features are ones most useful to developers.
When you must store data persistently, relational databases are your best option. On the other hand, when you must temporarily represent data in an application, objects are the best way to go. Features like inheritance, encapsulation, and method overriding allow a better coding style that simplifies development compared with the legacy DataSet approach.
Before we delve into the details of Entity Framework, we’ll take the first three sections of this chapter to discuss how moving from the DataSet approach to the object-based approach eases development, and how this different way of working leads to the adoption of an object/relational mapping (O/RM) tool like Entity Framework.
When you opt for using objects, keep in mind that there are differences between the relational and object-oriented paradigms, and the role of Entity Framework is to deal with them. It lets the developer focus on the business problems and ignore, to a certain extent, the persistence side. Such object/relational differences are hard to overcome. In section 1.4, you’ll discover that there is a lot of work involved in accommodating them. Then, the last sections of the chapter will show how Entity Framework comes to our aid in solving the mismatch between the paradigms and offering a convenient way of accessing data.
By the end of this chapter, you’ll have a good understanding of what an O/RM tool is, what it’s used for, and why you should always think about using one when creating an application that works with a database.
1.1. Getting started with data access
Data in tables is stored as a list of rows, and every row is made of columns. This efficient tabular format has driven how developers represent data in applications for many years. Classic ASP and VB6 developers use recordsets to retrieve data from data-bases—the recordset is a generic container that organizes the data retrieved in the same way it’s physically stored: in rows and columns. When .NET made its appearance, developers had a brand new object to maintain in-memory data: the dataset. Although this control is completely different from the recordset we used before the .NET age, it has similar purposes and, more important, has data organized in the same manner: in rows and columns.
Although this representation is efficient in some scenarios, it lacks a lot of features like type safety, performance, and manageability. We’ll discuss this in more detail when we talk about datasets in the next section.
In the Java world, a structure like the dataset has always existed, but its use is now discouraged except for the simplest applications. In the .NET world, we’re facing the beginning of this trend too. You may be wondering, “If I don’t use general-purpose containers, what do I use to represent data?” The answer is easy: objects.
Objects are superior to datasets in every situation because they don’t suffer from the limitations that general-purpose structures do. They offer type safety, autocompletion in Visual Studio, compile-time checking, better performance, and more. We’ll talk more about objects in section 1.2.
The benefits you gain from using objects come at a cost, resulting from the differences between the object-oriented paradigm and the relational model used by databases. There are three notable differences:
- Relationships— In a tabular structure, you use foreign keys on columns; with classes, you use references to other classes.
- Equality— In a database, the data always distinguishes one row from another, whereas in the object world you may have two objects of the same type with the same data that are still different.
- Inheritance— The use of inheritance is common in object-oriented languages, but in the database world it isn’t supported.
This just touches the surface of a problem known as the object/relational mismatch, which will be covered in section 1.4.
In this big picture, O/RM takes care of object persistence. The O/RM tool sits between the application code and the database and takes care of retrieving data and transforming it into objects efficiently, tracks objects’ changes, and reflects them to the database. This ensures that you don’t have to write almost 80 percent of the data-access code (that’s a rough estimate based on our experience).
1.2. Developing applications using database-like structures
Over the last decade, we have been developing applications using VB6, Classic ASP, Delphi, and .NET, and all of these technologies use external components or objects to access databases and maintain data internally. Both tasks are similar in each language, but they’re especially similar for internal data representation: data is organized in structures built on the concept of rows and columns. The result is that applications manage data the same way it’s organized in the database.
Why do different vendors offer developers the same programming model? The answer is simple: developers are accustomed to tabular representation, and they don’t need to learn anything else to be productive. Furthermore, these generic structures can contain any data as long as it can be represented in rows and columns. Potentially, even data coming from XML files, web services, or rest calls can be organized this way.
As a result, vendors have developed a subset of objects that can represent any information without us having to write a single line of code. These objects are called data containers.
1.2.1. Using datasets and data readers as data containers
At the beginning of our .NET experience, many of us used datasets and data readers. With a few lines of code, we had an object that could be bound to any data-driven control and that, in case of the data reader, provided impressive performance. By using a data adapter in combination with a dataset, we had a fully featured framework for reading and updating data. We had never been so productive. Visual Studio played its role, too. Its wizards and tight integration with these objects gave us the feeling that everything could be created by dragging and dropping and writing a few lines of code.
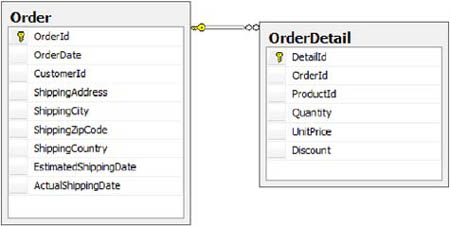
Let’s look at an example. Suppose you have a database with Order and Order-Detail tables (as shown in figure 1.1), and you have to create a simple web page where all orders are shown.
Figure 1.1. The Order table has a related OrderDetail table that contains its details.
The first step is creating a connection to the database. Then, you need to create an adapter and finally execute the query, pouring data into a data table that you bind to a list control. These steps are shown in the following listing.
Listing 1.1. Displaying a list of orders
C#
using (SqlConnection conn = new SqlConnection(connString))
{
using (SqlDataAdapter da = new SqlDataAdapter("Select * from order",
conn))
{
DataTable dt = new DataTable();
da.Fill(dt);
ListView1.DataSource = dt;
ListView1.DataBind();
}
}
VB
Using conn As New SqlConnection(connString)
Using da As New SqlDataAdapter("Select * from order", conn)
Dim dt As New DataTable()
da.Fill(dt)
ListView1.DataSource = dt
ListView1.DataBind()
End Using
End Using
By doing a bit of refactoring, you get the connection and the adapter in a single method call, so the amount of code is further reduced. That’s all you need to do to display the orders.
After playing with the prototype, your customer changes the specifications and wants to see the details under each order in the list. The solution becomes more challenging, because you can choose different approaches:
- Retrieve data from the Order table and then query the details for each order. This approach is by far the easiest to code. By intercepting when an order is bound to the ListView, you can query its details and show them.
- Retrieve data joining the Order and OrderDetail tables. The result is a Cartesian product of the join between the tables, and it contains as many rows as are in the OrderDetail table. This means the resultset can’t be passed to a control as is, but must be processed locally first.
- Retrieve all orders and all details in two distinct queries. This is by far the best approach, because it performs only two queries against the database. You can bind orders to a control, intercept when each order is bound, and filter the in-memory details to show only those related to the current order.
Whichever path you choose, there is an important point to consider: you’re bound to the database structure. Your code is determined by the database structure and the way you retrieve data; each choice leads to different code, and changing tactics would be painful.
Let’s move on. Your customer now needs a page to display data about a single order so it can be printed. The page must contain labels for the order data and a ListView for the details. Supposing you retrieve the data in two distinct commands, the code would look like this.
Listing 1.2. Displaying data for a single order
C#
using (SqlConnection conn = new SqlConnection(connString))
{
using (SqlCommand cm = new SqlCommand("Select * from order where orderid = 1", conn))
{
conn.Open();
using (SqlDataReader rd = cm.ExecuteReader())
{
rd.Read();
date.Text = ((DateTime)rd["OrderDate"]).ToString();
shippingAddress.Text = rd["ShippingAddress"].ToString();
shippingCity.Text = rd["ShippingCity"].ToString();
}
using (SqlDataReader rd = cm.ExecuteReader())
{
details.DataSource = rd;
details.DataBind();
}
}
}
VB
Using conn As New SqlConnection(connString)
Using cm As New SqlCommand("Select * from order where orderid = 1", conn)
conn.Open()
Using rd As SqlDataReader = cm.ExecuteReader()
rd.Read()
[date].Text = DirectCast(rd("OrderDate"), DateTime).ToString()
shippingAddress.Text = rd("ShippingAddress").ToString()
shippingCity.Text = rd("ShippingCity").ToString()
End Using
Using rd As SqlDataReader = cm.ExecuteReader()
details.DataSource = rd
details.DataBind()
End Using
End Using
End Using
The way you access data is completely unsafe and generic. On the one hand, you have great flexibility, because you can easily write generic code to implement functions that are unaware of the table field names and rely on configuration. On the other hand, you lose type safety. You identify a field specifying its name using a string; if the name isn’t correct, you get an exception only at runtime.
You lose control not only on field names, but even on datatypes. Data readers and data tables (which are the items that contain data in a dataset) return column values as Object types (the .NET base type), so you need to cast them to the correct type (or invoke the ToString method as well). This is an example of the object/relational mismatch we mentioned before.
Now that you’ve seen the big picture of the generic data-container world, let’s investigate its limitations and look at why this approach is gradually being discontinued in enterprise applications.
1.2.2. The strong coupling problem
In the previous example, you were asked to determine the best way to display orders and details in a grid. What you need is a list of orders, where every order has a list of details associated with it.
Data readers and data tables don’t allow you to transparently retrieve data without affecting the user interface code. This means your application is strongly coupled to the database structure, and any change to that structure requires your code to do some heavy lifting. This is likely the most important reason why the use of these objects is discouraged. Even if you have the same data in memory, how it’s retrieved affects how it’s internally represented. This is clearly a fetching problem, and it’s something that should be handled in the data-access code, and not in the user interface.
In many projects we have worked on, the database serves just one application, so the data is organized so the code can consume it easily. This isn’t always the case. Sometimes applications are built on top of an existing database, and nothing can be modified because other applications are using the database. In such situations, you’re even more coupled to the database and its data organization, which might be extremely different from how you would expect. For instance, orders might be stored in one table and shipping addresses in another. The data access code could reduce the impact, but the fetching problem would remain.
And what happens when the name of a column changes? This happens frequently when an application is under development. The result is that interface code needs to be adapted to reflect this change; your code is very fragile because a search and replace is the only way to achieve this goal. You can mitigate the problem by modifying the SQL and adding an alias to maintain the old name in the resultset, but this causes more confusion and soon turns into a new problem.
1.2.3. The loose typing problem
To retrieve the value of a column stored in a data reader or a data table, you usually refer to it using a constant string. Code that uses a data table typically looks something like this:
C#
object shippingAddress = orders.Rows[0]["ShippingAddress"];
VB
Dim shippingAddress As Object = orders.Rows(0)("ShippingAddress")
The variable shippingAddress is of type System.Object, so it can contain potentially any type of data. You may know it contains a string value, but to use it like a string, you have to explicitly perform a casting or conversion operation:
C#
string shippingAddress = (string)orders.Rows[0]["ShippingAddress"]; string shippingAddress = orders.Rows[0]["ShippingAddress"].ToString();
VB
Dim shippingAddress As String = _
DirectCast(orders.Rows(0)("ShippingAddress"), String)
Dim shippingAddress As String = _
orders.Rows(0)("ShippingAddress").ToString()
Casting and converting cost, both in terms of performance and memory usage, because casting from a value type to a reference type and vice versa causes boxing and unboxing to occur. In some cases, conversion can require the use of the IConvertible interface, which causes an internal cast.
Data readers have an advantage over data tables. They offer typed methods to access fields without needing explicit casts. Such methods accept an integer parameter that stands for the index of the column in the row. Data readers also have a method that returns the index of a column, given its name, but its use tends to clutter the code and is subject to typing errors:
C#
string address = rd.GetString(rd.GetOrdinal("ShippingAddress"));
string address = rd.GetString(rd.GetOrdinal("ShipingAdres")); //exception
VB
Dim address As String = _
rd.GetString(rd.GetOrdinal("ShippingAddress"))
Dim address As String = _
rd.GetString(rd.GetOrdinal("ShipingAdres")) 'exception
The problem resulting from column name changes, discussed in the previous section, involves even the loss of control at compile time. It’s not desirable to discover at runtime that a column name has changed or that you have mistyped a column name. Compilers can’t help avoid such problems because they have no knowledge of what the name of the column is.
1.2.4. The performance problem
DataSet is likely one of the most complex structures in the .NET class library. It contains one or more DataTable instances, and each of these has a list of DataRow objects made of a set of DataColumn objects. A DataTable can have a primary key consisting of one or more columns and can declare that certain columns have a foreign key relationship with columns in another DataTable. Columns support versioning, meaning that if you change the value, both the old and the new value are stored in the column to perform concurrency checks. To send updates to the database, you have to use a DbDataAdapter class (or, more precisely, one of its derived classes), which is yet another object.
Although these features are often completely useless and are ignored by developers, DataSet internally creates an empty collection of these objects. This might be a negligible waste of resources for a standalone application, but in a multiuser environment with thousands of requests, like a web application, this becomes unacceptable. It’s useless to optimize database performance, tweaking indexes, modifying SQL, adding hints, and so on, if you waste resources creating structures you don’t need.
In contrast, DataReader is built for different scenarios. A DataTable downloads all data read from the database into memory, but often you don’t need all the data in memory and could instead fetch it record by record from the database. Another situation is in data updates; you often need to read data but don’t need to update it. In such cases, some features, like row versioning, are useless. DataReader is the best choice in such situations, because it retrieves data in a read-only (faster) way. Although it boosts performance, DataReader can still suffer from the casting and conversion problems of DataSet, but this loss of time is less than the gain you get from its use.
All of these problems may seem overwhelming, but many applications out there benefit from the use of database-like structures. Even more will be developed in the future using these objects without problems. Nonetheless, in enterprise-class projects, where the code base is large and you need more control and flexibility, you can leverage the power of object-oriented programming and use classes to organize your data.
1.3. Using classes to organize data
We’re living in the object-oriented era. Procedural languages still exist, but they’re restricted to particular environments. For instance, COBOL is still required for applications that run on mainframe architectures.
Using classes is a natural choice for most applications today. Classes are the foundation of object-oriented programming. They easily represent data, perform actions, publish events, and so on. From a data organization point of view, classes express data through methods and properties (which, in the end, are special methods).
By using classes, you can choose your internal representation of data without worrying about how it’s persisted—you need to know nothing about the storage mechanism. It could be a database, a web service, an XML file, or something else. Representing data without having any knowledge of the storage mechanism is referred to as persistence ignorance, and the classes used in this scenario are called POCOs (plain old CLR objects).
The use of classes offers several benefits that are particularly important in enterprise applications:
- Strong typing— You no longer need to cast or convert every column in a row to get its value in the correct type (or, at least, you don’t have to do it in the interface code).
- Compile-time checking— Classes expose properties to access data; they don’t use a generic method or indexer. If you incorrectly enter the name of a property, you immediately get a compilation error. You no longer need to run the application to find typos.
- Ease of development— Editors like Visual Studio offer IntelliSense to speed up development. IntelliSense offers the developer hints about the properties, events, and methods exposed by a class. But if you use DataSet, editors can’t help you in any way, because columns are retrieved using strings, which aren’t subject to IntelliSense.
- Storage-agnostic interface— You don’t have to shape classes to accommodate the structure of the database, which gives you maximum flexibility. Classes have their own structure, and although it’s often similar to that of the table they’re related to, it doesn’t need to be. You no longer have to worry about database organization and data retrieval, because you code against classes. Data-retrieval details are delegated to a specific part of the application, and the interface code always remains the same.
To get a look at these concepts in practice, let’s refactor the example from the previous section.
1.3.1. Using classes to represent data
Let’s start from scratch again. The customer wants to display orders in a grid. The first step is to create an Order class to contain order data, as shown in figure 1.2.
Figure 1.2. The Order class contains data from the Order table.
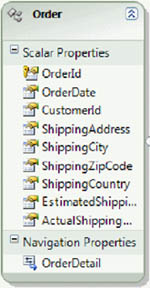
The Order class has the same structure as the related database table. The only obvious difference here is that you have .NET types (String, Int32, DateTime) instead of database types (int, varchar, date).
The second step is to create a class with a method that reads data from the database and transforms it into objects, as in the following listing. The container class is often in a separate assembly, known as data layer.
Listing 1.3. Creating a list of orders
C#
public List<Order> GetOrders()
{
using (SqlConnection conn = new SqlConnection(connString))
{
using (SqlCommand comm = new SqlCommand("select * from orders", conn))
{
conn.Open();
using(SqlDataReader r = comm.ExecuteReader())
{
List<Order> orders = new List<Order>();
while (rd.Read())
{
orders.Add(
new Order
{
CustomerCode = (string)rd["CustomerCode"],
OrderDate = (DateTime)rd["OrderDate"],
OrderCode = (string)rd["OrderCode"],
ShippingAddress = (string)rd["ShippingAddress"],
ShippingCity = (string)rd["ShippingCity"],
ShippingZipCode = (string)rd["ShippingZipCode"],
ShippingCountry = (string)rd["ShippingCountry"]
}
);
}
return orders;
}
}
}
}
...
ListView1.DataSource = new OrderManager().GetOrders();
ListView1.DataBind();
VB
Public Function GetOrders() As List(Of Order)
Using conn As New SqlConnection(connString)
Using comm As New SqlCommand("select * from orders", conn)
conn.Open()
Using r As SqlDataReader = comm.ExecuteReader()
Dim orders As New List(Of Order)()
While rd.Read()
orders.Add(New Order() With {
.CustomerCode = DirectCast(rd("CustomerCode"), String),
.OrderDate = DirectCast(rd("OrderDate"), DateTime),
.OrderCode = DirectCast(rd("OrderCode"), String),
.ShippingAddress = DirectCast(rd("ShippingAddress"), String),
.ShippingCity = DirectCast(rd("ShippingCity"), String),
.ShippingZipCode = DirectCast(rd("ShippingZipCode"), String),
.ShippingCountry = DirectCast(rd("ShippingCountry"), String)
})
End While
Return orders
End Using
End Using
End Using
End Function
...
ListView1.DataSource = New OrderManager().GetOrders()
ListView1.DataBind()
“What a huge amount of code!” That’s often people’s first reaction to the code in listing 1.3. And they’re right; that’s a lot of code, particularly if you compare it with listing 1.1, which uses a dataset. If your application has to show simple data like this, the data-set approach is more desirable. But when things get complex, classes help a lot more.
Let’s take a look at the next required feature: displaying a single order in a form. After the order is retrieved, displaying its properties using classes is far more straightforward:
C#
shippingAddress.Text = order.ShippingAddress; shippingCity.Text = order.ShippingCity;
VB
shippingAddress.Text = order.ShippingAddress shippingCity.Text = order.ShippingCity
The final step is showing the orders and related details in a grid. Doing this requires in-depth knowledge because it introduces the concept of models. You can’t represent orders and details in a single class—you have to use two separate classes the same way you do with tables. In the next section, we’ll discuss this technique.
1.3.2. From a single class to the object model
You have now seen how to develop a single standalone class and how to instantiate it using data from a database, but the real power comes when you create more classes and begin to link them to each other (for instance, when you create an OrderDetail class that contains data from the OrderDetail table).
In a database, the relationship between an order and its detail lines is described using a foreign key constraint between the OrderId column in the Order table and the OrderId column in the OrderDetail table. From a database design point of view, this is the correct approach.
In the object-oriented world, you have to follow another path. There’s no point in creating an OrderDetail class and giving it an OrderId property. The best solution is to take advantage of a peculiar feature of classes: they can have properties whose type is a user-defined class. This means the Order class can hold a reference to a list of OrderDetail objects, and the OrderDetail class can have a reference to Order.
When you create these relationships, you’re beginning to create an object model. An object model is a set of classes related to each other that describe the data consumed by an application.
The real power of the object model emerges when you need to show orders and their related details in a single grid. In section 1.2.1, there was a fetching problem with a spectrum of solutions. Every one was different, but what’s worse is that every one required a different coding style on the interface.
Using classes, your interface code is completely isolated from fetching problems because it no longer cares about the database. A specific part of the application will fetch data and return objects. This is where the storage-agnostic interface feature of using classes comes into play.
The Object Model and Domain Model patterns are often considered to refer to the same thing. They may initially look exactly the same, because both carry data extracted from storage. But after digging a bit, you’ll find that they have differences: the object model contains only the data, whereas the domain model contains data and exposes behavior.
The Order class that we’ve been looking at is a perfect expression of an object model. It has properties that hold data and nothing more. You could add a computed property that reports the full address by combining the values of other properties, but this would be a helper method. It wouldn’t add any behavior to the class.
If you want to move on from an object model to a domain model, you have to add behavior to the class. To better understand the concept of behavior, suppose you need to know if an order exceeds the allowed total amount. With an object model, you have to build a method on another class. In this method, you call the database to retrieve the maximum amount allowed, and then compare it with the amount of the order. If you opt for a domain model, on the other hand, you can add an IsCorrect method to the Order class and perform the check there. This way you’re adding behavior and expressiveness to the Order class.
Creating and maintaining a domain model isn’t at all easy. It forces the software architect to make choices about the design of the application. In particular, classes must be responsible for their own validation and must always be in a valid state. (For instance, an order must always have a related customer.) These checks may contribute to code bloating in the classes; so, to avoid confusion, you may have to create other classes that are responsible for validation, and keep those classes in the domain model.
The details of the Object Model and Domain Model patterns are beyond the scope of this book and won’t be covered, but plenty of books focus on this subject and all its implications. We recommend Domain Driven Design by Eric Evans (Addison-Wesley Professional, 2004). We’ll discuss the Domain Model pattern and Entity Framework in chapter 14.
The example we’ve looked at so far is oversimplified. You’ll have noticed that the Order class has a CustomerId property and the OrderDetail class has a ProductId property. In a complete design, you’d have Customer and Product classes too. Likely, a customer has a list of applicable discounts based on some condition, and a product belongs to one or more categories. Creating a strong object model requires a high degree of knowledge, discipline, and a good amount of practice.
At first sight, it may seem that a one-to-one mapping between classes and database tables is enough. Going deeper, though, the object-oriented paradigm has much more expressiveness and a different set of features compared with the database structure. Inheritance, many-to-many-relationships, and logical groups of data are all features that influence how you design a model. More importantly, such features create a mismatch between the relational representation and the model; in literature, this problem is known as the object/relational mismatch, and it’s discussed in the next section.
1.4. Delving deep into object/relational differences
Understanding the differences between the object-oriented and relational worlds is important, because they affect the way you design an object or domain model and the database.
The mismatch can be broken down into different parts relating to datatypes, associations, granularity, inheritance, and identity, and in the following sections we’ll look at them in turn. To better illustrate this mismatch, we’ll make use of the example introduced in previous sections.
1.4.1. The datatype mismatch
The datatype mismatch refers to the different data representations and constraints that are used in the object and relational worlds. When you add a column to a table in a database, you have to decide what datatype to assign to it. Any modern database supports char, varchar, int, decimal, date, and so on. When it comes to classes, the situation is different. Database int and bigint types fit naturally into .NET Int32 and Int64 types, but other database types don’t have an exact match in .NET.
In the database, when you know that the value of a column has a maximum length, you set this constraint into the column to enforce the business rule. This is particularly desirable when the database serves several applications, and yours isn’t the only one that updates data. In .NET, varchar doesn’t exist. The nearest type to varchar is String, but it doesn’t support any declarative limitations on its length (it can contain 2 GB of data). If you want to check that the value of the String isn’t longer than expected, you have to implement this check in the setter of the property, or call a check method before sending the data back to the database.
Another example of this mismatch involves binary data. Every database accepts binary data, but the column that contains the data doesn’t know anything about what the data represents. It might be a text or PDF file, an image, and so on. In .NET, you could represent such a column using an Object, but it would be nonsense, because you know perfectly well what kind of data you have stored in the binary column. If the value is a file, you can use a Stream property, whereas the Image type is your best choice for images.
One last example of the datatype difference emerges when you use dates. Depending on the database vendor and version, you have lots of datatypes you can use to store a date. For instance, until version 2005 of SQL Server, you had DateTime and Small-DateTime. SQL Server 2008 has introduced two more datatypes: Date and Time. As you can imagine, the first contains only a date and the second only a time. In .NET, you have only a DateTime class that represents both date and time. Handling this mismatch isn’t difficult, but it requires a bit of discipline when instantiating the object from database data and vice versa.
As you can see, the datatype mismatch is trivial and doesn’t cause developers to lose sleep at night. But it does exist, and it’s something you must take care of.
The second difference, which already emerged in section 1.2, is the association between classes. Databases use foreign keys to represent relationships, whereas object-oriented applications use references to other objects. In the next section, we’ll go deeper into this subject.
1.4.2. The association mismatch
When talking about associations, the biggest mismatch between the relational and object worlds is how relationships are maintained. Database tables are related using a mechanism that is different from the one used by classes. Let’s examine how the cardinality of relationships is handled in both worlds.
One-to-One Relationships
The Order table contains all the data about orders. But suppose the application needs to be improved, and an additional column has to be added to the Order table. This may initially seem like a minor improvement, because adding a column isn’t too dangerous. But it’s more serious than that. There may be lots of applications that rely on that table, and you don’t want to risk introducing bugs. The alternative is to create a new table that has OrderId as the primary key and contains the new columns.
On the database side, that’s a reasonable tradeoff, but repeating such a design in the object model would be nonsense. The best way to go is to add properties to the Order class, as shown in figure 1.3.
Figure 1.3. The Order2 table contains columns for the new data and is related to the Order table. In the object model, there’s no new class—just a new property on the Order class.
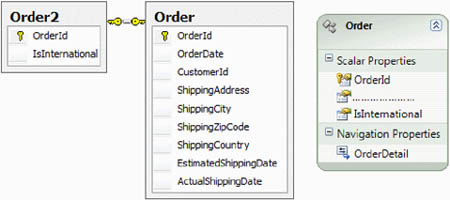
The method that interacts with the database will handle the differences between the two schemas. Such a method isn’t complicated at all; it performs a join between the two tables and updates data in both to handle the mismatch: Select a.*, b.* from Orders a join Order2 on (a.orderid = b.orderid)
This association difference leads to the granularity mismatch, which will be discussed later in this section.
One-to-Many Relationships
You’ve already seen a one-to-many relationship when we linked details to an order. In a database, the table that represent the “many” side of the relationship contains the primary key of the master table. For example, the OrderDetail table contains an OrderId column that links the detail to its order. In database jargon, this column is called a foreign key.
By nature, database associations are unique and bidirectional. By unique, we mean that you have to define the relationship only on one side (the OrderDetail side); you don’t need to define anything in the Order table. Bidirectional means that even if you modify only one side, you have automatically related the master record to its details and a detail to its master. This is possible because SQL allows you to perform joins between tables to get the order related to a detail and all details related to an order.
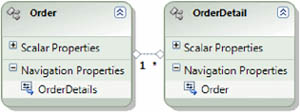
In the object-oriented world, such automatism doesn’t exist because everything must be explicitly declared. The OrderDetail class contains a reference to the order via its Order property, and this behavior is similar to the database. The real difference is that you also need to modify the Order class, adding a property (OrderDetails) that contains a list of OrderDetail objects that represent the details of the order. In figure 1.4, you can see this relationship.
Figure 1.4. The relationship between Order and OrderDetail in the object model is expressed with properties.
So far, you have handled orders and their details. Now, let’s move on to handle products and their suppliers. A product can be bought from more than one supplier, and a single supplier can sell many products. This leads to a many-to-many association.
Many-to-Many Relationships
The many-to-many relationship represents an association where each of the endpoints has a multiple relationship with the other. This means there’s no master-detail relationship between tables—both of them are at the same level.
For example, if you have Product and Supplier tables, you can’t express the relationship between them simply by creating a foreign key in one of the tables. The only way to link them is to not link them at all. Instead, you create a middle table, known as a link table, that contains the primary key of both tables. The Product and Supplier tables contain only their own data, whereas the link table contains the relationship between them. This way, the two main tables aren’t directly connected, but rely on a third one that has foreign keys.
In an object model, the concept of a link table doesn’t exist because the relationship is represented as a list of references to the other class on both sides. Because you have Product and Supplier tables in the database, you create Product and Supplier classes in the model. In the Product class, you add a Suppliers property that contains a list of Supplier objects representing those who sell the product. Similarly, in the Supplier class you add a Products property that contains a list of Product objects that represent the products sold by the supplier. Figure 1.5 shows such associations.
Figure 1.5. In the database, the Product and Supplier tables are related via the ProductSupplier table. In the model, the Product and Supplier classes are directly related using properties.
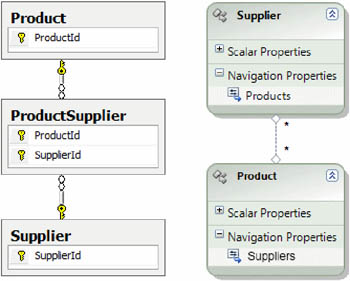
Like one-to-one relationships, many-to-many relationships are one of the causes of the granularity problem that appears in the object model. The other cause of the granularity problem is covered in the next section.
1.4.3. The granularity mismatch
The granularity problem refers to the difference in the number of classes compared with the number of tables in the database. You’ve already seen that depending on the types of relationships, you might end up with fewer classes than tables. Now we’re going to explore another cause for the granularity mismatch: value types.
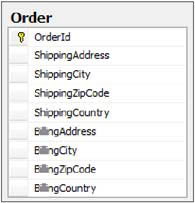
Let’s get back to our example. The Order table has a shipping address that’s split into four columns: address, city, zip code, and country. Suppose you need to handle another address, say the billing address, and you decide to add four more columns to the Order table, so it looks like the one shown in figure 1.6.
Figure 1.6. An excerpt of the new Order table with the new billing address field
The Order class already has four properties for the shipping address, so adding further properties won’t be a problem. But although it works smoothly, these new properties let the class grow, making it harder to understand. What’s more, customers and suppliers have an address, the product store has an address, and maybe other classes have addresses too. Classes are reusable, so wouldn’t it be good to create an AddressInfo class and reuse it across the entire model?
With a bit of refactoring, you can modify the Order class to remove the address-related properties and add two more: ShippingAddress and BillingAddress. The code after refactoring looks like this.
Listing 1.4. The AddressInfo and Order classes
C#
public class AddressInfo
{
public string Address { get; set; }
public string City { get; set; }
public string ZipCode { get; set; }
public string Country { get; set; }
}
public class Order
{
public Address ShippingAddress { get; set; }
public Address BillingAddress { get; set; }
}
VB
Public Class AddressInfo Public Property Address() As String Public Property City() As String Public Property ZipCode() As String Public Property Country() As String End Class Public Class Order Public Property ShippingAddress() As Address Public Property BillingAddress() As Address End Class
As you see, the code after the refactoring is easy to understand.
We have seen solutions where the database has been overnormalized. The addresses were moved into a different table with its own identity, and foreign keys were used to link the customer table to the address. From a purist database designer point of view, this approach might be correct, but in practice it doesn’t perform as well as if the columns were stored in the customer table. It’s very likely that you’ll need address information each time you retrieve an order, so every access will require a join with the address table.
This design might or might not have optimized the overall database design, but from a developer’s perspective it was a painful choice. This design affected the design of the object model too. The AddressInfo class was originally a mere container of data, but it was turned into an entity that has its own correspondence with a database table. The consequences were a higher number of lines of code to maintain the new database table, and slower performance because SQL commands increased (updating a customer meant updating its personal data and address). Forewarned is forearmed.
Another cause of the different levels of granularity is the inheritance feature of OOP. In a model, it’s common to create a base class and let other classes inherit from it. In relational databases, though, the concept of inheritance doesn’t exist, so you have to use some workaround to handle such scenarios, as we’ll see next.
1.4.4. The inheritance mismatch
The inheritance mismatch refers to the impossibility of representing inheritance graphs in a database. Let’s go back to the example to see why this difference represents a problem.
Let’s refine the object model to add the Customer class, and we’ll let it and the Supplier class inherit from Company. It’s highly likely that these entities share columns, such as address, VAT number, name, and so on, so using inheritance is the most natural way to design such classes. Figure 1.7 shows these classes.
Figure 1.7. The Supplier and Customer classes inherit from Company.
![]()
In a relational database, you can’t simply declare a Customer table and say that it inherits from another table. That isn’t how relational organization works. You can create a single table that contains both customer and supplier data, or create one for each type. Whatever your decision is, there will be a mismatch between database and model.
In the model, you have a Product class. A store can sell different types of products such as shoes, shirts, golf equipment, swimming equipment, and so on. All these products share some basic types of data, like price and color, and they’ll also have other information that’s specific to each product.
Even in this case, inheritance comes to your aid. To reflect this situation, you write a Product class, and then you create a class for each specific product. The biggest problem emerges when you design the OrderDetail class. In that class, you’ll need a property indicating what product the detail refers to; this property is of type Product even if at runtime the concrete instance of the object might be of type Shoes, Shirts, or any type that inherits from Product. Figure 1.8 shows this inheritance hierarchy in the model.
Figure 1.8. Shirt and Shoes inherit from Product, which is referenced by OrderDetail.

This type of association is referred to as polymorphic, and it’s absolutely impossible to natively represent in a database. Furthermore, to retrieve the product related to an order detail, you need a polymorphic query, which isn’t supported in a database.
Fortunately, after years of experience, developers have found a way to use a combination of database design, SQL statements, and code to simulate the effect of a polymorphic query. This means that you can write a query and get instances of objects of the correct type based on the data in the OrderDetail table. Naturally, you don’t just need polymorphic queries; you need polymorphic inserts, updates, and deletes too. Indeed, the code that interacts with the database has to both retrieve and update data, so you need to solve both sides of the mismatch.
The last difference we’ll talk about is identity. Databases and objects have different concepts of equality. Databases base identity on the primary key column, whereas objects use a pointer comparison.
1.4.5. The identity mismatch
The identity mismatch refers to the different ways that objects and databases determine equality.
The identity of a row in a table is represented by the value of its primary key columns. As a result, you have to pay attention when choosing a primary key for a table. Sometimes you may want to use a natural key, such as a product code, but this choice can introduce troubles instead of simplifying things.
For example, suppose you need to change a product code because you entered an incorrect one. The product code is a foreign key column in the OrderDetail table, so you have to update it too. The problem is that you can’t update the product code column in the OrderDetail table, because if you change it to a value that doesn’t yet exist in the Product table, you’ll receive an error. On the other hand, you can’t change the value in the Product table because it would violate the foreign key constraint. Lots of steps are necessary to solve this problem; what seems to be a simple update turns out to be a nightmare.
That’s likely the most annoying problem, but there’s another reason to avoid the use of natural keys. A product code might be a relatively long string, and almost all databases are optimized for storing and searching integer values, so the most effective primary key is a surrogate key that’s a meaningless value to the business. By using a surrogate key, you leave the burden of creating it to the database, and you can concentrate on the data. The use of surrogate keys allows you to change data in any column in the table without affecting any other table; you don’t have to perform a complicated series of steps to change the product code.
Note
We have opted for an integer key, but GUID keys are good too. In many scenarios, GUIDs are a better choice than integers. There’s no absolute rule about this; it must be considered on a case-by-case basis.
So far, we can state that an object is the object-oriented representation of a table row, and that the primary key property is what links the object to the row. The problem is that if you compare two different objects of the same type, they turn out to be different even if they contain the same data.
Why are objects with the same data different? Because, by default, two variables that point to different objects representing the same row of a table are different. If the two variables point to the same instance, then they are equal. This is called equality by reference.
An approach that changes this default behavior is certainly more desirable. If two different objects contain the same data, their comparison should return true. In .NET, such equality can be achieved by overriding the Equals and GetHashCode methods, and stating the equality rules in these methods. The most natural way to represent equality is to compare properties that represent the primary key on the table, but there are complex cases where this approach can’t be followed.
1.4.6. Handling the mismatches
Now that you’ve seen all of the differences between the relational and object worlds, you’ll have an idea of what writing code that accesses the database in object-model–based applications involves. We haven’t talked about the techniques for handling the mismatches, but you may easily guess that a flexible system requires a lot of lines of code. Naturally, if you focus on solving the problems for an individual application, the solution is simpler; but if you want to create something reusable, complexity increases.
In our experience, one of the most difficult features to implement is polymorphic queries. You need to accommodate the design of the database to create (sometimes very complex) ad hoc SQL queries and to write a huge amount of code to correctly transform the data extracted by the query into objects.
Relationships come at a cost too. As stated before, it’s easy to write code that retrieves the orders. If you need to retrieve orders and details, it requires a bit more work, but nothing too difficult. Whichever path you choose, you’ll have to write a lot of code to handle fetching features. Even if this code isn’t too complicated to write, you still have to write it.
Fortunately, the datatype and granularity mismatches are trivial to solve. Handling the datatype differences just requires a bit of discipline to check that database constraints aren’t violated when data is sent back for updates. The granularity problem is even simpler to handle and doesn’t need particular attention.
Sometimes the way you shape classes can’t be represented in a database, or it results in a poor database design. Even if databases and models represent the same data, the way they’re organized can be so different that some compromise is required.
In our experience, designing an application so it works as well as it can often involves bending and twisting both database and object model (mainly the latter) so that they might look tricky in places. Someone looking at them could say that the application isn’t well designed. These are words often spoken by purists of one of the two models who only consider their side. Always remember: the best design is the one that accommodates both models without losing too much of their benefits.
As you can see, an application that uses a model has many intricacies when dealing with a database. The next question is who has to deal with this complexity. The answer is that if you’re crazy, you can reinvent the wheel on your own. Otherwise, you can adopt an O/RM tool. More precisely, you can use Entity Framework.
1.5. Letting Entity Framework ease your life
The key to delivering an application that’s maintainable and easy to evolve is to separate the concerns into different logical layers and sometimes into different physical layers (tiers). You can gain many benefits from adopting such a technique.
First of all, there is the separation of concerns. Each layer has its own responsibilities: the interface layer is responsible for the GUI; the business layer maintains business rules and coordinates the communication between the GUI and the data layer; and the data layer is responsible for the interaction with the database.
After the interface between the layers is defined, they can evolve independently, allowing parallel development, which always speeds things up.
Another great advantage of using different logical layers is the ease of maintaining and deploying the application. If you need to change how you access the database, you only have to modify the data layer. When deploying the new packages, you deploy only the modified assemblies, leaving the others untouched.
Obviously, the data layer is the one affected by the adoption of an O/RM tool. In a well-designed application, the GUI and the business layer don’t need to know that an O/RM tool is in use. It’s completely buried in the data-layer code.
Let’s move on and look at what an O/RM tool can do for us.
1.5.1. What is O/RM?
O/RM is an acronym that stands for object/relational mapping. In a nutshell, an O/RM framework is used to persist model objects in a relational database and retrieve them. It uses metadata information to interface with the database. This way, your data-layer code knows nothing about the database structure; the O/RM tool becomes middleware that completely hides the complexity.
The heart of O/RM is the mapping—the mapping technique is what binds the object and relational worlds. By mapping, you express how a class and its properties are related to one or more tables in the database. This information is used by the O/RM tool’s engine to dynamically build SQL code that retrieves data and transforms it into objects. Similarly, by tracking changes to objects’ properties, it can use mapping data to send updates back to the database. The mapping information is generally expressed as an XML file. As an alternative, some O/RM tools use attributes on the classes and their properties to maintain mapping data.
An O/RM tool is a complex piece of software that saves the developer from the burden of managing the interaction with the database. It handles the collision between object and relational worlds, it transforms query data into objects, it tracks updates to objects to reflect changes in the database, and a lot more. The idea of coding these features manually is absurd when you have a tool that does it for you.
There are plenty of O/RM tools on the market, both free and commercial. So far, NHibernate has been the most powerful and stable one. The stability was inherited from its parent (NHibernate is the .NET port of Hibernate, which is an O/RM tool written in Java, available since 2001), and the fact that it’s an open source project has encouraged its adoption. Now, its leadership is being threatened by the new version of Entity Framework.
In the next section, we’ll look at why Entity Framework is a valid alternative.
1.5.2. The benefits of using Entity Framework
“Why should I adopt an O/RM tool, and more specifically Entity Framework? What benefits will I gain from its use? Is it a stable technology? Why should I add another complex framework to my application?”
These are the most common questions we’re asked by people who approach this technology for the first time. If you’ve read the whole chapter so far, you should be convinced that O/RM technology is worth a chance (if you have a model in your application). To get the complete answers to the preceding questions, you’ll have to read at least the first two parts of this book. But here are some quick answers, in case you can’t wait:
- Productivity— In our experience, persistence code that doesn’t rely on an O/RM tool can take up to 35 percent of the entire application code. The use of an O/RM tool can cut that percentage down to 5 percent in some edge cases, and to 15–20 percent in a normal situation. The API that Entity Framework introduces make the developer’s life easier than ever. In spite of its limitations, the designer integrated into Visual Studio dramatically simplifies the mapping process.
- Maintainability— The fewer lines of code you have, the fewer lines of code you have to maintain. This is particularly true in the long run, when refactoring comes into play and a smaller code base is easier to inspect. Furthermore, the ability of an O/RM tool to bridge the gap between the object and relational models opens interesting scenarios. You can refactor the database structure or model definition without affecting the application code, and only changing the mapping. If you think about the code needed to manually handle persistence and to refactor a database or classes, you’ll immediately understand that maintainability increases if you adopt an O/RM tool.
- Performance— This is one of the most-discussed subjects relating to O/RM. The complexity of O/RM introduces an obvious slowdown in performance. In most cases, though, this is an acceptable trade-off because the slowdown is almost irrelevant. We have seen only one edge case where the performance decrease was unbearable.
The preceding features are shared by all O/RM tools available. Now let’s look at the benefits that Entity Framework adds to your development phase.
- It’s included in the .NET Framework. Microsoft fully supports Entity Framework and guarantees bug fixes, documentation, and improvements at a pace its competitors can’t keep up with. Often, customers choose Entity Framework instead of NHibernate because Entity Framework’s presence in the .NET Framework reassures them about the overall quality of the project. What’s more, because the .NET Framework is free, Entity Framework is free as well.
- It’s integrated into Visual Studio. When you install Visual Studio 2010, you have wizards and a designer to manage the mapping phase visually, without worrying about the implementation details. As you’ll see throughout the rest of the book, Visual Studio allows you to reverse-engineer existing databases to automatically create object model classes and mapping files and keep them updated when the database design changes. It allows even the reverse process: creating the object model and then creating the database to persist it. Should you make any modifications to the object model, you can immediately re-create the database.
- The current version solves most of the problems of the past. Microsoft has listened attentively to community feedback. Since the release of Entity Framework v1.0, Microsoft has engaged a board of experts, including Jimmy Nilsson, Eric Evans, Martin Fowler, and others, to make Entity Framework a great competitor. The first release of Entity Framework was struck by a vote of no confidence on the web, but the current version solves all of the problems raised at that time. Although its version number is 4.0, this is the second version of Entity Framework. In the past, Microsoft has confused developers with version numbers. The company shipped .NET Framework 3.0, which was not a new version but a set of classes including WCF, WPF, and WF; but the CLR was still at version 2.0. When .NET Framework 3.5 shipped, the CLR was again version 2.0. Old assemblies remained in version 2.0, whereas those shipped in version 3.0 and the new ones were upgraded to version 3.5. This versioning policy introduced so much confusion that with .NET Framework 4.0, Microsoft realigned everything to version 4.0. This is why we have Entity Framework 4.0 instead of 2.0.
- It’s independent from the type of database you use. The persistence layer uses the Entity Framework API to interact with the database. Entity Framework is responsible for translating method calls to SQL statements that are understood by the database. But even if all modern databases support standard SQL, lots of features differ between vendors. Sometimes there are subtle differences even between different versions of the same product. SQL Server 2005 introduced a huge number of improvements, and a good O/RM tool has to generate optimized SQL for both SQL Server 2005/2008 and SQL Server 7/2000 platforms. Entity Framework guarantees that the correct SQL code is (almost) always generated, and it relieves the developer of checking which database is in use at every command. This helps a lot, but it doesn’t mean you can forget about SQL code—you always have to check the SQL code produced by Entity Framework to be sure it respects your performance prerequisites.
- It uses LINQ as a query language. You can express your queries using LINQ, and Entity Framework will take care of translating your LINQ query into SQL code. This means you can write queries with IntelliSense, strong typing, and compile-time checking! At the moment, no other O/RM tool on the market (apart from the ghost of the LINQ to SQL project) allows that.
- Entity Framework is recommended for data access by Microsoft. Microsoft clearly states that the future of data access for the .NET platform is Entity Framework. This is why the company is working so hard to make Entity Framework so powerful. Microsoft is also working on other products to make them rely on Entity Framework for accessing the database.
An O/RM tool is useful, but it isn’t going to save your life. There are many cases where its use isn’t feasible. In the next section, we’ll delve into this subject.
1.5.3. When isn’t O/RM needed?
In the last couple of years, the thrust toward O/RM has dramatically increased. Now, many developers think that an O/RM tool is the silver-bullet solution to all problems, and they tend to use it in every project. Sometimes its use isn’t the right choice.
Despite the huge improvement in productivity it offers, O/RM is just a framework. It’s something you have to study and test in several situations, and it takes time to correctly use it. In projects with a limited budget or where the delivery date is relatively soon, time is something you don’t have, and you’ll have to resort to hand-coding the data access layer.
The type of application you’re developing is another thing you have to take into account when choosing whether to adopt an O/RM tool. If you’re developing a web application that’s mainly focused on displaying data, an O/RM tool may be a waste, because you get the best out of it when you have to both retrieve and persist objects. Even if it gives great flexibility in retrieving data, you may not need it if you know exactly what the fetching level is. For instance, applications that generate statistical reports won’t get any benefit from O/RM. They probably wouldn’t benefit from a model either.
If your application must perform bulk inserts, O/RM isn’t what you need. Databases have internal features that allow bulk inserts, so you’re better off relying on those features.
In short, you should always plan ahead before adopting an O/RM tool. This isn’t news; in our field, everything must be planned for in advance.
So far, you’ve seen that working with objects improves application stability and makes them easier to maintain. You’ve also learned that there is a mismatch between data organized in objects and data organized in relational databases, and that this mismatch can easily be handled by O/RM tools like Entity Framework. In the next section, we’ll look at the components Entity Framework is made up of, and how those components interact with each other to solve data-access problems.
1.6. How Entity Framework performs data access
Entity Framework is a complex piece of software. Its overall architecture consists of several components, each fulfilling a specific task. Figure 1.9 illustrates Entity Framework’s key components and gives an idea of where each fits in.
Figure 1.9. The overall architecture of Entity Framework: The query languages lie on top of Object Services, which relies on Entity Client to interact with the database. Entity Client uses the standard ADO.NET providers to physically communicate with the database. The EDM is a layer that’s referenced by all the others and is used by them to obtain metadata about classes.
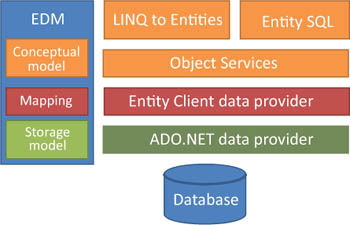
The Entity Data Model (EDM) is the layer where the mapping between the classes and the database is expressed. This component consists of the three mapping files shown in figure 1.9.
LINQ to Entities and Entity SQL are the languages used to write queries against the object model. Entity SQL was the first language to be developed, because when Entity Framework first appeared, LINQ was still in a prototype phase and a dedicated language for querying was necessary. During development, LINQ reached stability, so the team decided to include a LINQ dialect for Entity Framework. That’s why we now have two query languages in Entity Framework.
The Object Services layer is the gateway to accessing data from the database and sending it back. As a result, this component is the most important for developers. Object Services is responsible for materialization—the process of transforming the data obtained from the Entity Client data provider, which has a tabular structure, into objects. Another important part of this layer is the ObjectStateManager object, or state manager, which tracks any changes made to the objects.
The Entity Client data provider, which we’ll refer to as the Entity Client from now on, is responsible for communication with the ADO.NET data providers, which in turn communicate with the database. The main task of this layer is to convert Entity SQL and LINQ to Entities queries into SQL statements that are understood by the underlying database. Furthermore, it converts the results of queries from database tabular structure into a model tabular structure that’s then passed to Object Services.
Now that you have a general idea of what the parts of the software do, let’s discuss them in greater detail, starting with the EDM.
1.6.1. The Entity Data Model
The EDM is the link between the model and the database. Here you describe the database and the model structure and how to map them. The great thing about the EDM is that it decouples your application from the underlying store. Database and model can have completely different structures, but they’re always related by the EDM.
The EDM consists of three XML files, each with a precise task. These files are summarized in table 1.1.
Table 1.1. The mapping files of the EDM
|
Filename |
Description |
Alternative name |
Extension |
|---|---|---|---|
| Conceptual model | Describes the model classes and their relationships | Conceptual schema, conceptual side | CSDL |
| Storage model | Describes the database tables, views, and stored procedures, and their keys and relationships | Storage schema, storage side | SSDL |
| Mapping model | Maps the conceptual and storage models | Mapping schema, mapping side | MSL |
At runtime, these files are parsed and their data is stored in classes that can be queried to obtain metadata about the classes, the database, and their mapping. The main application that uses the data in these classes is Entity Framework itself. When it materializes objects from a query, it asks the EDM for metadata. We’ll discuss mapping in detail in chapter 12.
Note
One of the most despised features of Entity Framework is the extreme verbosity of the EDM. Creating the classes and describing them in the model is a useless duplication. The same objection is made against the storage model, because the engine could analyze the database structure and retrieve the schema on its own. If it did, the only task the user would need to do is create the mapping file, as is the case in other frameworks. There are several reasons why the team included all the files in the EDM; the main reasons are for performance and maximum decoupling from the physical structures.
The Conceptual Model
The conceptual model is where you describe the model classes. This file is split into two main sections: the first is a container that lists all the entities and the relationships that are managed by Entity Framework, and the second contains a detailed description of their structure.
One important peculiarity of this file is that it can be separated into several files. This may become helpful when your model gets too large and the performance of the Visual Studio designer becomes unacceptable. We’ll return to this subject in chapter 19, which is dedicated to performance.
The Storage Model
The storage model is the equivalent of the conceptual model, but it describes the database organization. Not only is this file conceptually similar to the previous one, but it also uses the same XML nodes. Unlike the conceptual model, it isn’t possible to split this model into several physical files.
The first section of this file lists all the tables, views, stored procedures, and foreign keys that are affected. The second section describes the items listed in the first node. Regarding tables and views, the columns and primary keys are described. When it comes to stored procedures, input and output parameters are described. The description of a foreign key contains information about the table involved, the cardinality, and the delete and update rules.
The Mapping Model
The mapping file is completely different. Its job isn’t to describe something but to compensate for the differences that exist between the two previous models. This is where the real magic of mapping happens: you map a class to one or multiple tables, map one table to one or multiple classes, define inheritance mapping, and map stored procedures for both updates and object retrieval.
There is only one important node in this file: it associates the class to a table and can be repeated more than once to ensure that a class can be mapped against multiple tables, and vice versa.
Like the storage description file and unlike the conceptual file, the mapping file can’t be split into multiple files.
The Visual Studio Mapping File
As you’ll see in the next section, Visual Studio has a wizard that automatically generates the mapping information from the database, and a designer that allows you to modify the mappings visually, without worrying about the underlying files.
To easily integrate the mapping requirements and the designer in Visual Studio, there is a new file with the EDMX extension. The EDMX file merges the three EDM files into one, adding designer-required information. The Entity Framework designer team invented the EDMX file to allow visual modifications to be made to object model classes and their mappings against the database, whereas the EDM is the real mapping layer. At compile time, the EDMX file is split up, and the three mapping files are generated.
In terms of the object/relational mismatch, the mapping layer is where all the problems enumerated in section 1.4 are resolved. But mapping only provides metadata to solve the problem—the code lies in the Object Services and Entity Client layers. In the next section, we’ll discuss the former.
1.6.2. Object Services
Object Services is the layer responsible for managing objects in Entity Framework. Entity Framework is mostly interested in handling the mismatch between database and objects, so there are lots of tasks to be performed against objects.
The first key feature of Object Services is that it exposes the API to generate the objects that queries are written against. Fortunately, the Visual Studio wizard helps a lot in generating the code necessary to write queries, so you only have to worry about the query and not about the plumbing.
When a query is executed, the Object Services layer translates it into a command tree that’s then passed on to the underlying Entity Client. The process is slightly different depending on which query technology you use. If you use LINQ to Entities, the LINQ provider generates an expression tree that’s then parsed and transformed in the command tree. If the query was developed using Entity SQL, Object Services parses the string and generates another command tree. This process is known as query transformation.
When the query against the database has been executed and the underlying layer has reorganized the data using the mapping, Object Services is responsible for creating objects using the input structure. The input data is organized as rows and columns, but in a conceptual-model way and not in a database manner. This means each row represents an object, and if it has a property that references another class, the column contains the overall row for the class. Figure 1.10 illustrates how the data is organized.
Figure 1.10. How data is received by the Object Services layer

Due to this organization of data, the process of creating objects is fairly simple. This process is object materialization.
When the objects are ready to be consumed, the context comes into play. By context we mean the lifetime of the communication between the application and Entity Framework. It’s established using a well-known class (ObjectContext, or context), and it’s active as long as the class is referenced in the code or it isn’t disposed of. The context class is used from the beginning because this class creates the entry point for querying the object model.
After the objects are materialized, they’re automatically added to the context memory, but this behavior can be overridden for performance reasons. During the materialization process, if the object that’s going to be created already exists in the context memory, it’s skipped by the engine, and a reference to the in-memory object is returned to the code executing the query. This means the context acts as a sort of local cache.
The objects that are attached to the context are automatically tracked by the state manager component. This mechanism ensures that any modifications made to objects are correctly managed and recorded in the database. To do this, the state manager stores the original data of every object that’s loaded so it can compare them and perform an optimized update. This component gives you many options to customize its behavior.
Finally, the Object Services layer coordinates the updates to the data store, querying the state manager for modifications, and it controls the creation of the plumbing code needed to execute the commands.
Each of the preceding steps will be discussed in detail in chapters 4, 6, 7, and 8. But now that you know how objects are handled, it’s time to investigate the layer that interacts with the database.
1.6.3. Entity Client data provider
The Entity Client is responsible for communicating with the database. To simplify its architecture, this layer isn’t physically connected to the database, but relies on the well-known ADO.NET data-provider infrastructure.
Whereas Object Services manages objects using the conceptual model of the EDM, the Entity Client uses all the EDM files. It needs the mapping and storage model files to convert the command tree into SQL commands to execute against the database. It then needs the conceptual model file to convert the tabular database results into conceptual shaped data, as shown in figure 1.9, which is later moved into objects by Object Services.
At this point, you should have a clear understanding of how the system handles queries, uses them to hit the database, and converts the resulting data to objects. In particular situations, where maximum performance is required, you may query this layer directly, ignoring Object Services. The great boost in performance is obtained not only by jumping one layer in the chain, but also by avoiding the materialization process, which is the slowest task of query execution. For obvious reasons, LINQ to Entities can’t be used when you directly query Entity Client, because LINQ manipulates objects, and this layer knows nothing about them. Entity SQL is the only language you can use in such a scenario.
Let’s now move on to the first querying option: LINQ to Entities.
1.6.4. LINQ to Entities
LINQ to Entities is the LINQ dialect that enables typed queries against the model. Thanks to the LINQ syntax, you can write a typed query against the model and have an object returned with compile-time checking.
Even though LINQ to Entities operates on objects, it must still be translated into the SQL that’s finally launched against the database. Many of the LINQ methods or overloads can’t be represented in SQL. For instance, the ElementAt method isn’t supported but is still syntactically valid. A call to this method won’t cause a compile-time error but will produce a NotSupportedException at runtime. Similarly, the overload of the Where method that accepts an integer as the second parameter can’t be translated to SQL, so its use causes only a runtime exception. Apart from unsupported methods, you’ll encounter other cases where the compile-time checking isn’t enough, but they’re pretty rare and are well documented in MSDN.
Note
It’s important to emphasize that LINQ to Entities isn’t Entity Framework. Many developers tend to see LINQ to Entities as a technology opposed to LINQ to SQL, but that’s a mistake. LINQ to SQL is a full-featured O/RM tool that shipped with .NET Framework 3.5, whereas LINQ to Entities is only a query language inside Entity Framework. LINQ to Entities is the main querying language in Entity Framework, but Entity SQL is still a great tool to have in your toolbox.
1.6.5. Entity SQL
Entity SQL is the second way of querying the object model. Like LINQ to Entities queries, Entity SQL queries are always expressed against the model. The difference is that Entity SQL is string-based, so it may be preferable in some scenarios.
Entity SQL is one of the most complicated languages we have ever met. When the Entity Framework team had to create a query language for Entity Framework (before LINQ was available), they wanted to create a language that was easy for developers to understand and opted for a SQL-like syntax (which is why it was called Entity SQL). As Entity Framework evolved, and more and more features were added, the spectrum of query capabilities widened, and new functions in the language were required. It currently includes over 150 functions and has maintained only a little compatibility with the original SQL syntax.
Although it’s complex, Entity SQL is ahead of LINQ to Entities in some situations. First, it’s string-based, so it’s easier to create queries at runtime based on conditions. Second, Entity SQL is the only language that can be used to retrieve data at low level, directly using the Entity Client. Finally, there are functions that can’t be invoked using LINQ to Entities but can using Entity SQL. You’ll learn more about that in chapter 9.
1.7. Summary
In this chapter, you’ve seen what O/RM is, what problems it solves, and how it fits into application design.
You’ve learned the basics of data access using ready-to-use structures like datasets and data readers, and why they’re used in some environments and discouraged in others. In scenarios where tabular structures aren’t applicable, an object/domain model is the obvious replacement, because the use of classes lets you take advantage of the power of object-oriented programming.
Naturally, the introduction of a domain model carries a new set of problems with it, due to the many differences that exist between object and relational representations of data. Handling such differences is sometimes easy for small to medium-sized business applications, but it may result in overwhelming code as the applications grow.
This is where O/RM tools like Entity Framework come into play. As you’ve seen, O/RM tools make database-interaction code easier to develop and maintain. Although O/RM tools aren’t the silver bullet for any application, a wide spectrum of applications can benefit from the adoption of O/RM.
Finally, you’ve learned about the core components of Entity Framework and how they interact to solve the object/relational mismatches.
You haven’t seen Entity Framework in action yet, but in the next chapter we’ll start tackling its complexity and learning how to work with it.