
Chapter 10. Working with stored procedures
- Mapping stored procedures in the EDM
- Retrieving data using stored procedures
- Embedding SQL commands in the EDM
- Updating data using stored procedures
Now that you’ve mastered Entity SQL, we can move forward and take a closer look at another advanced feature of Entity Framework: the use of stored procedures.
Because LINQ to Entities makes it so easy to write queries, leaving the burden of creating SQL code to the framework, you may think that stored procedures are no longer needed. From a developer’s point of view, writing queries against the domain model with LINQ to Entities is more natural than writing a stored procedure that returns raw data. But there is another side to this coin: the DBA.
Often, DBAs want full control over the commands that are executed against the database. Furthermore, they want only authorized users to have read and write permissions on the tables, views, and so on. A well-defined set of stored procedures gives the DBA this control over the database and guarantees that the SQL is highly optimized.
Another situation where stored procedures are useful is when you want to put some logic in them. In OrderIT, when an order is placed, you have to update the quantity of in-stock products by subtracting the items sold. A stored procedure is the ideal place to put such logic.
The first half of this chapter discusses stored procedures that read data. You may encounter several different situations when using such stored procedures, and each one deserves attention. We’ll cover this topic in great detail. After that, we’ll look at how to use stored procedures to persist data instead of using dynamically generated SQL.
Before digging into querying with stored procedures, let’s start with the basics: how to make stored procedures available to Entity Framework.
10.1. Mapping stored procedures
Entity Framework doesn’t allow a stored procedure to be queried until it’s mapped in the EDM. As usual, this is a three-step affair: import the stored procedure into the storage schema, create its counterpart in the conceptual schema, and finally map everything in the MSL.
The designer is powerful enough to let you perform all these operations graphically without touching the EDMX file manually. But you’ll learn as you read this chapter that you need a deep knowledge of the EDM to use its stored procedure–related features. Such knowledge is necessary because the designer doesn’t cover all EDM capabilities; to use specific features, you’ll have to manually modify the EDMX file.
In this section, we’ll map the following stored procedure, which returns all the details of an order, given its ID:
CREATE PROCEDURE GetOrderDetails @OrderId as int As SELECT OrderDetailId, Quantity, UnitPrice, Discount, ProductId, OrderId FROM OrderDetail WHERE OrderId = @OrderId
Let’s see how to make it available to the code. You’ll use the designer to accomplish this task. When that’s done, you’ll see how the steps made using the designer modify the EDMX file.
10.1.1. Importing a stored procedure using the designer
The designer doesn’t allow you to write stored procedures and bring them into the database. That means it doesn’t matter whether you opt for the model-first or database-first approach; you always have to create your stored procedures in the database and later import them into the EDM.
Here you’ll import the stored procedure mentioned at the end of the previous section into the EDM, but these general steps can be used to import any stored procedure. Follow these steps:
1. Right-click the designer, and select the Update Model from Database option.
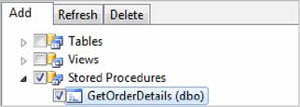
2. In the wizard, expand the Stored Procedures node, and check the GetOrder-Details stored procedure, as shown in figure 10.1.
Figure 10.1. The GetOrderDetails stored procedure in the wizard
3. Click Finish to import the stored procedure.
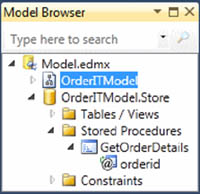
4. In the Model Browser, open the OrderITModel.Store node, open its Stored Procedures child folder, and right-click GetOrderDetails, as shown in figure 10.2. In the context menu, select Add Function Import.
Figure 10.2. The GetOrderDetails stored procedure in the Model Browser window
5. In the Returns a Collection Of section of the wizard, click the Entities radio button and select the OrderDetail entity from the dropdown list, as shown in figure 10.3.
Figure 10.3. The wizard makes the stored procedure available on the conceptual side and maps its result to the OrderDetail class.

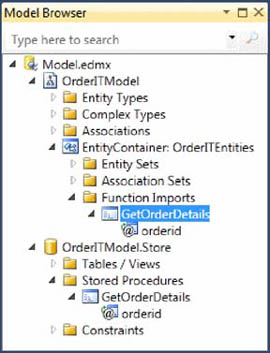
Now the EDM contains all the information needed to invoke the stored procedure. In the Model Browser window (shown in figure 10.4) you can see that the stored procedure has been imported into the conceptual side of the EDM.
Figure 10.4. Once imported, the GetOrderDetails stored procedure is visible in the Model.
That was easy—with a bunch of clicks, everything is ready.
But what happened under the covers? What does the EDM look like now that the stored procedure has been imported and mapped? We’ll look at that next.
10.1.2. Importing stored procedures manually
The wizard steps in the previous section can be performed manually by modifying the EDM. As you’ll discover, it’s not a difficult task. There are three main steps:
1. Declare the stored procedure in the storage schema.
2. Declare the function in the conceptual schema (so that it becomes available to the code).
3. Create the mapping between the stored procedure in the storage schema and the function in the conceptual schema.
We’ll look at these steps in turn.
Defining a Stored Procedure in the Storage Schema
The first EDM schema involved is the storage schema. Here you define the shape of the stored procedure via the Function node inside the Schema element, as in the next snippet:
<Function Name="GetOrderDetails" IsComposable="False" ParameterTypeSemantics="AllowImplicitConversion" Schema="dbo"> <Parameter Name="OrderId" Type="int" Mode="In" /> </Function>
The Name attribute contains the logical name of the function inside the EDM, and StoreFunctionName specifies the name of the stored procedure in the database. If StoreFunctionName isn’t specified, Name must be set to the name of the stored procedure. The ability to specify a name that is different from the stored procedure name turns out to be useful when procedures have meaningless names and you want to use more friendly ones.
The ParameterTypeSemantics attribute is an enumeration that specifies how the .NET parameter types are converted to the equivalent SQL types. The default value is AllowImplicitConversion, which instructs the runtime to take care of the conversion so you don’t have to worry about it.
The IsComposable attribute specifies whether the stored command can be used to create other commands or not. Its default value is true, but for stored procedures it must be set to false because stored procedures can’t be queried on the server. (You can’t write SELECT * FROM StoredProcName.)
Finally, the Schema attribute identifies the owner of the stored procedure (it has nothing to do with EDM schemas).
If the stored procedure has parameters, you have to nest a Parameter element for each one. In this element, the Name attribute contains the name of the parameter, Type specifies the database type of the parameter, and Mode identifies the direction. Mode is an enumeration that contains one of three values: In (input-only), Out (output-only), and InOut (input-output).
The preceding attributes of the Parameter element are mandatory, but Parameter has other optional attributes. The first is MaxLength, which is used when the parameter is a string and you need to specify the maximum length for its value. If you have decimal parameters, you can also use Precision and Scale to specify how much data the number can contain.
At this point, you’ve imported the stored procedure in the EDM. This is the same thing you achieve when completing step 3 of the wizard we discussed in section 10.1.1. Now you need to declare the function in the conceptual schema so that it becomes available to the code.
Defining a Function in the Conceptual Schema
In the conceptual schema, a stored procedure is referred to as function. When you create a function in the conceptual schema, you’re actually importing a stored procedure from the storage schema. This is why, in the conceptual layer, the element responsible for declaring the function is called FunctionImport and is nested in the Entity-Container node.
In the next snippet, you can see that not only does FunctionImport declare the function, it also describes the function’s parameters and results:
<FunctionImport Name="GetOrderDetails" EntitySet="OrderDetails" ReturnType="Collection(OrderITModel.OrderDetail)"> <Parameter Name="orderid" Mode="In" Type="Int32" /> </FunctionImport>
The Name attribute represents the name of the function in the conceptual layer and is the only mandatory attribute. This name is decoupled from the stored-procedure name in the storage schema because it’s the mapping schema that binds the function to the stored procedure. EntitySet specifies the entity set returned by the stored procedure, and ReturnType declares the type returned. The Collection keyword is mandatory because even if the function returns only a single record, it’s included in a list.
Note
When the function returns an entity, specifying the entity set and the type may seem to be a duplication. But when you deal with objects that are part of an inheritance hierarchy, you may have different types for the same entity set, so you have to specify both to clearly identify the result of the function. What’s more, in situations where you don’t retrieve an entity but a custom type, you can omit EntitySet and declare only the ReturnType attribute.
Not all stored procedures are used for querying—many are used to update data in tables and don’t return any results. In this case, you don’t include the EntitySet and ReturnType attributes.
The Parameter element is used to specify function parameters (which match the stored-procedure parameters). Its attributes are exactly the same as those for the Parameter element in the storage file, with the only difference being that here Type is expressed as a .NET type: Int32, String, DateTime, and so on.
The last step is creating the mapping between the stored procedure in the storage schema and the function in the conceptual schema. Not surprisingly, this is done in the mapping file.
Binding a Stored Procedure to a Function in the Mapping Schema
Mapping a stored procedure to a function is trivial. The following mapping fragment shows that you just need to add a FunctionMapping element inside EntityContainer-Mapping:
<FunctionImportMapping FunctionImportName="GetOrderDetails" FunctionName="OrderITModel.Store.GetOrderDetails" />
FunctionImportName is the name of the function in the conceptual schema, and FunctionName is the name of the stored procedure in the storage schema.
The EDM is now ready. It contains everything needed to invoke the stored procedure on the database and have the results returned as objects. It’s time to talk about the code.
10.2. Returning data with stored procedures
Retrieving data with stored procedures is a common task in any data-centric application. What’s different when using an O/RM tool is that the results must be poured into objects that are then returned to the application. What’s more, the results of the stored procedures are just resultsets with columns, and these columns may be anything. The columns may match the properties of an entity, they may come from multiple joined tables, they may contain a single scalar value, or they can be anything else.
We’ll discuss the following scenarios in the upcoming sections:
- Stored procedures whose columns match the properties of an entity
- Stored procedures whose columns don’t match the properties an entity
- Stored procedures that return scalar values
- Stored procedures that return objects in an inheritance hierarchy
Note
Stored procedures can return output parameters too. You must keep this in mind in any of the preceding scenarios.
Each of these cases has a different solution and has its particular needs. The first three cases are the easiest to deal with. Thanks to the designer’s capabilities, you can handle them visually without getting your hands dirty in the EDM. The fourth case is a little more complicated, but it’s not too difficult.
Let’s start with the first and analyze how a stored procedure’s results become an entity.
10.2.1. Stored procedures whose results match an entity
Executing a stored procedure is pretty easy. Once it’s imported into the conceptual side of the EDM, you can use the ExecuteFunction<T> method, whose signature is shown in the following snippet:
C#
public ObjectResult<TElement> ExecuteFunction<TElement>(string functionName,
MergeOption mergeOption, params ObjectParameter[] parameters)
Public Function ExecuteFunction(Of TElement) _ (ByVal functionName As String, ByVal mergeOption As MergeOption, _ ByVal ParamArray parameters As ObjectParameter()) _ As ObjectResult(Of TElement) parameters)
The generic parameter is the class returned by the query. The arguments represent the function name as imported in the CSDL, the MergeOption for the returned entities, and the parameters passed to the stored procedure.
The following snippet shows how to use the ExecuteFunction<T> method to invoke the stored procedure:
C#
ObjectParameter orderidParameter = new ObjectParameter("orderid", 1);
var result = ctx.ExecuteFunction<OrderDetail>("GetOrderDetails",
orderidParameter);
VB
Dim orderidParameter As New ObjectParameter("orderid", 1)
Dim result = ctx.ExecuteFunction(Of OrderDetail)("GetOrderDetails",
orderidParameter)
The POCO template that generates code automatically generates a convenient wrapper method for each function. The stored-procedure parameters are exposed as method arguments, so the invocation code is simplified. Due to this simplicity, we strongly recommend using these autogenerated methods, as shown in listing 10.1, instead of directly invoking ExecuteFunction<T>.
Listing 10.1. The autogenerated method to invoke a stored procedure
C#
public virtual ObjectResult<OrderDetail> GetOrderDetails(
Nullable<int> orderid)
{
ObjectParameter orderidParameter;
if (orderid.HasValue)
orderidParameter = new ObjectParameter("orderid", orderid);
else
orderidParameter = new ObjectParameter("orderid", typeof(int));
return base.ExecuteFunction<OrderDetail>("GetOrderDetails",
orderidParameter);
}
VB
Public Overridable Function GetOrderDetails _
(ByVal orderid As Nullable(Of Integer)) As ObjectResult(Of OrderDetail)
Dim orderidParameter As ObjectParameter
If orderid.HasValue Then
orderidParameter = New ObjectParameter("orderid", orderid)
Else
orderidParameter = New ObjectParameter("orderid", GetType(Integer))
End If
Return MyBase.ExecuteFunction(Of OrderDetail)
("GetOrderDetails", orderidParameter)
End Function
Notice that parameters are passed as nullable. The database allows you to pass a null value to any stored procedure parameter, so this possibility is left open in the code.
The last piece of background you need to know is how the result of the stored procedure becomes an entity. In the world of mapping, you would expect the stored procedure result to be explicitly mapped against a class. Well, it’s not like that.
How a Stored Procedure’s Results are Mapped to a Class
An object is materialized from each row of the result based on the column and scalar property names. It’s almost the same materialization mechanism used by the ObjectContext class’s ExecuteStoreQuery<T> method.
Note
We said almost because later you’ll see that you can slightly tweak the materialization process using the EDM.
Let’s look at the GetOrderDetails stored procedure. The OrderDetail entity that the GetOrderDetails stored procedure result is mapped to has the following scalar properties: OrderDetailId, Quantity, UnitPrice, Discount, ProductId, and OrderId. To map the stored procedure result to the entity, the stored procedure must return a resultset containing the columns OrderDetailId, Quantity, UnitPrice, Discount, ProductId, and OrderId. The order in which they’re returned isn’t important, but the names of the class properties and the resultset column names must match exactly or you’ll get an InvalidOperationException with the message, “The data reader is incompatible with the specified ‘TypeName’. A member of the type, ‘PropertyName’, does not have a corresponding column in the data reader with the same name.”
Figure 10.5 illustrates how the mapping works.
Figure 10.5. The mapping between the function result and the class is based on the match between column and property names.

Navigation properties are ignored by the materialization process. They are handled by class code. If they aren’t initialized within the constructor, they’re null; otherwise they’re set to whatever value the constructor gives them. This is true even if the foreign-key properties are set.
If the query returns more columns than there are entity properties, the extra columns are ignored. If the query doesn’t return enough columns to match the entity properties, the materialization process fails, and you get the runtime exception mentioned earlier.
The example shown here is the easiest case: the stored procedure results line up perfectly with an entity. In the next section, we’ll discuss how to handle resultsets that don’t match up with an entity.
10.2.2. Stored procedures whose results don’t match an entity
When a stored procedure’s results don’t match up with an entity, you can resort to complex types. You can create a new complex type in the designer (as you learned how to do in chapter 2) and map the stored procedure’s results to it. The materialization mechanism is the same as is used for entities; there are no differences.
There are three possible situations where the stored procedure’s results don’t align with an entity:
- The resultset is an aggregation or contains columns that don’t match with any entity.
- The resultset columns contain data that match up with an entity but that have different names.
- The entity has complex properties.
Let’s start with the first case, where the result of the stored procedure isn’t an entity but is something else: a set of columns plus other aggregated columns, a set of columns that partially fill an entity, or perhaps a set of columns coming from a query that joins multiple tables and that don’t fit any entity.
Stored Procedures Whose Results Have Columns that Don’t Line Up with an Entity
In OrderIT, the GetTopOrders stored procedure returns the top ten orders sorted by their total amount. Its code is as follows:
CREATE PROCEDURE GetTopOrders
AS
SELECT TOP 10 c.Name, o.OrderId, o.OrderDate,
SUM(od.UnitPrice * (Quantity - Discount)) as Total
FROM [order] o
JOIN company c ON o.CustomerId = c.CompanyId
JOIN orderdetail od ON od.OrderId = o.OrderId
GROUP BY c.Name, o.OrderId, o.OrderDate
ORDER BY Total DESC
This stored procedure returns a resultset that doesn’t match the Order class or any other entity in OrderIT. You can see the result in figure 10.6.
Figure 10.6. The result of the GetTopOrders stored procedure

In figure 10.7, you can see a class that matches the result of the stored procedure.
Figure 10.7. The class that matches the results of the GetTopOrders stored procedure

There’s no entity like this in OrderIT, so how do you map the result of the stored procedure, and to which class? The solution is simple: you map the results to an ad hoc class; more precisely, you map the results to a complex type (the TopOrder class in this case).
Note
Because the results of the stored procedure are specified in the EDM, the class must be in the EDM. You can’t use a class that isn’t in the EDM.
Once again, the designer comes to the rescue by simplifying the plumbing. After you’ve imported the stored procedure from the database, you can import it into the conceptual side by using the form you saw earlier in figure 10.3.
What’s different in this case is that instead of mapping the result to an entity, you map it to a complex type. If there are no complex types that match the stored procedure’s results, you can let the form inspect the stored procedure and create the complex type for you. Your productivity will increase to an incredible extent thanks to this feature.
Follow these steps to import the stored procedure into the conceptual schema of the EDM:
1. Right-click the designer, and choose Update Model from Database.
2. In the wizard (shown earlier in figure 10.1), expand the Stored Procedures node, and check the GetTopOrders item.
3. Click Finish to import the stored procedure.
4. In the Model Browser, open the OrderITModel.Store node, open its Stored Procedures child, and then right-click the GetTopOrders item. In the context menu, select the Add Function Import option.
5. In the Returns a Collection Of section of the Add Function Import dialog box, click the Complex radio button.
6. In the Stored Procedure Column Information section of the dialog box, click the Get Column Information button. The stored procedure’s results structure will be displayed in a grid, as shown in figure 10.8.
Figure 10.8. The structure of the stored procedure’s results
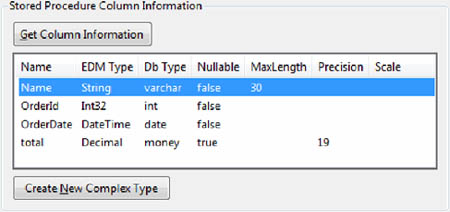
7. Click the Create New Complex Type button to create a complex type from the results’ structure.
8. A new item is added in the Complex drop-down list, and you can change its name. By default, the name follows the pattern FunctionName_Result, but you can change the name to whatever you want. (We opted for TopOrder.)
9. Click OK to finish the import.
10. Right-click the POCO templates that generate the context and entities’ code. Click the Run Custom Tool item in the context menu that pops up. At the end of the process, you’ll have the GetTopOrders method (which invokes the stored procedure) in the context class, and the TopOrder class that the result of the stored procedure is mapped to.
It’s that easy. Now you have the EDM, the code to invoke the stored procedure in the context, and the code for the class that holds the results. All that with just a few clicks.
Invoking the stored procedure is simple. You can call the ExecuteFunction<T> method directly (not recommended):
C#
var orders = ctx.ExecuteFunction<TopOrder>("GetTopOrders");
VB
Dim orders = ctx.ExecuteFunction(Of TopOrder)("GetTopOrders")
Or you can use the autogenerated GetTopOrders context method (recommended):
C#
var orders = ctx.GetTopOrders();
VB
Dim orders = ctx.GetTopOrders()
Naturally, stored procedures are mutable, meaning that you can add, remove, and rename columns in the results. In such cases, you need to realign the complex type with these changes. Once again, the designer lets you do this visually by following these steps:
1. In the Model Browser window, expand the OrderITModel > Entity Container: OrderITEntities > FunctionImport nodes, and double-click the GetTopOrders item.
2. Click the Update button next to the Complex drop-down list. Doing so triggers the stored procedure inspection and automatically updates the complex type structure.
3. In the Explorer Solution window, right-click the template that generates code for entities, and select Run Custom Tool to regenerate the class’s code. The class that the stored procedure maps to is updated to reflect the changes in the stored-procedure results). There’s no need to update the context because its code doesn’t change.
Again, the designer spares you a lot of work. It’s fantastic being able to use stored procedures and simply configure everything from the designer.
Another scenario where the stored procedure’s results don’t fit an entity is when the results don’t contain all of an entity’s data. For instance, a stored procedure may return the ID and the name of all customers, and ignore all other properties. In this case, one possible way to go would be to modify the stored procedure to return all columns. This approach has two problems: you may not be able to modify the stored procedure, and returning unused data is a waste of resources. Once again, complex types are the best solution.
So far, we’ve assumed that the stored procedure’s column names match the properties of the entity. But sometimes entity properties are named differently from database columns, or the stored procedure may rename the result columns for some reason.
Stored Procedures Whose Result Columns’ Names are Different from - Entity Properties
A typical case where column names in a stored procedure’s results differ from entity property names is when you have a legacy database with meaningless table and column names. For example, some legacy databases still have table and column names that are limited to eight characters. Due to this limitation, columns names are almost or totally meaningless (such as USISAPPM standing for USer IS APPlication Manager). In such a situation, it’s best to rename all the classes and properties in the model so they’re clearer for developers.
When a stored procedure is run, and the column names in the results don’t match property names in the entity, the materialization fails. To solve this problem, you can use the FunctionImportMapping section in the mapping schema to manually specify how a column maps to a property. Once again, the designer spares you from the manual work by adding a new window to visually perform this task.
In the following steps, you’ll modify the GetOrderDetails stored procedure to return a result with column names that don’t line up with the OrderDetail entity, and you’ll see how to make the mapping work:
1. Modify the GetOrderDetails stored procedure by changing the name of the Quantity column as shown in the following code:
SELECT orderDetailId, Quantity as q, UnitPrice, Discount, orderid
FROM orderdetail
WHERE orderid = @orderid
2. In the Model Browser window, expand the OrderITModel > Entity Container: OrderITEntities > FunctionImport nodes, right-click the GetOrderDetails item, and select the Function Import Mapping item.
3. In the mapping window, the properties are displayed on the left and the columns on the right. Change the name of the Quantity column to q (as shown in figure 10.9), and you’re done.
Figure 10.9. Mapping a column to a property with a different name

It’s that easy. This approach is better than using a complex type just because a property name doesn’t match, isn’t it?
Before moving on to the next subject, take a look at this snippet to see what the EDM’s MSL schema looks like after this modification:
<FunctionImportMapping FunctionImportName="GetOrderDetails"
FunctionName="OrderITModel.Store.GetOrderDetails" >
<ResultMapping>
<EntityTypeMapping TypeName="OrderITModel.OrderDetail">
<ScalarProperty Name="Quantity" ColumnName="q" />
</EntityTypeMapping>
</ResultMapping>
</FunctionImportMapping>
This code is saying that the return type is OrderDetail and that the property Quantity maps to the column q. Only the differently named columns must be included; by default, the other ones are matched by name. What’s good is that only the mapping schema changes; the conceptual and storage schemas are untouched.
We’ve now talked about entities with scalar and navigation properties. The situation gets more challenging when complex properties come into play.
Stored Procedures that Return Resultsets of an Entity With Complex Types
Mapping a function to an entity or a complex type with a complex property is tricky. The flat nature of a stored procedure’s results and the complex nature of objects make the materialization impossible, as you see in figure 10.10.
Figure 10.10. Mapping function result to a class with a complex property is impossible due to the names mismatch.
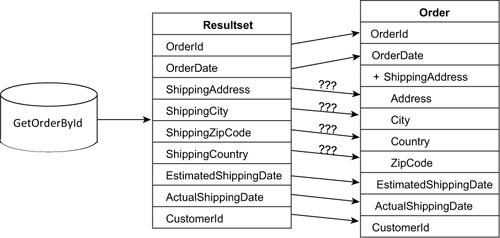
The only way to go is to use a defining query, but as you’ll discover in chapter 11, this requires the database to be adapted and that’s not always possible.
Stored procedures, and queries in general, return not only entities, but also scalar values. Using a class to contain a single value is pointless; other approaches are preferable.
10.2.3. Stored procedures that return scalar values
In OrderIT, the GetTotalOrdersAmount stored procedure returns the amount of all orders placed. This stored procedure returns a single decimal value; neither complex types nor entities are involved:
CREATE PROCEDURE GetTotalOrdersAmount AS SELECT sum(Quantity * (UnitPrice - Discount)) FROM orderdetail
Let’s see how to import this stored procedure in the EDM and how to use it.
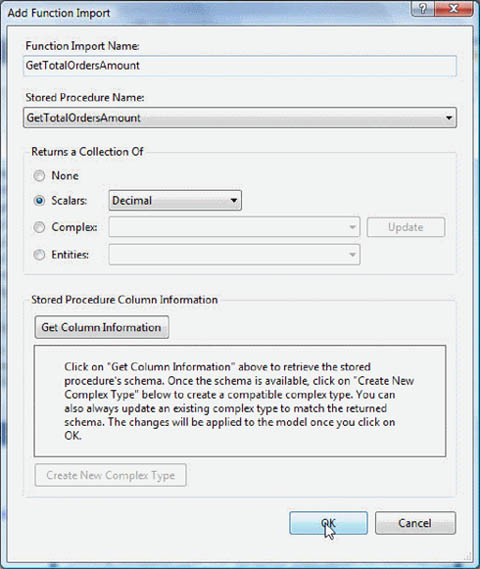
With the designer you import the stored procedure from the database and then import it in the conceptual side. In the wizard form (shown in figure 10.11), select the Scalar option, and select the Decimal type from the dropdown list.
Figure 10.11. The wizard imports into the conceptual schema a stored procedure that returns a single decimal value.
Finally, you need to update the context code using the POCO template, and you’re done.
The autogenerated method in the context returns an ObjectResult<Int32> object. Because it implements the IEnumerable<T> interface, and you already know that only one item is returned, you can call the LINQ First method to retrieve the value. Remember that everything is generated as nullable; the result is no exception, as the following code demonstrates:
C#
decimal? amount = ctx.GetTotalOrdersAmount().First();
VB
Nullable(Of Decimal) amount = ctx.GetTotalOrdersAmount().First()
If, instead of using the designer, you want to manually modify the EDM, you’ll have to declare the stored procedure in the SSDL and map it to the MSL as you’ve seen before. In the CSDL, the situation is slightly different.
First of all, because you aren’t retrieving an entity, you don’t have an entity set, and consequently an entity, to associate the result to. This means the EntitySet attribute in the FunctionImport element isn’t needed.
Second, even if the function returns a single value, Entity Framework can’t know in advance whether the stored procedure returns more than one result, so it’s always mapped as a collection. This is clearly indicated by the use of the Collection keyword in the next mapping fragment:
<FunctionImport Name="GetTotalOrdersAmount" ReturnType="Collection(Decimal)" />
Naturally, it’s possible that a stored procedure returns a collection of scalar values. For instance, you may need to retrieve a list of order IDs. In that case, you can simply loop over the results of the function, and you’re finished.
So far, we haven’t talked about polymorphic stored procedures. You know that you can query a hierarchy using LINQ to Entities and Entity SQL to obtain only a specified type or an entire hierarchy, regardless of the mapping strategy you choose. Stored procedures allow you to do this too, but the implementation is a bit more complex.
10.2.4. Stored procedures that return an inheritance hierarchy
When the stored procedure returns data about classes involved in an inheritance hierarchy, two very different scenarios are possible:
- The resultset maps to a specified type of the hierarchy.
- The resultset returns data about different types in the hierarchy.
In the first case, the stored procedure’s results are mapped to a single entity. That’s not any different from what you’ve seen already. The materialization process doesn’t care whether the class is part of an inheritance hierarchy or not. It simply creates an instance and populates it. As usual, the only important thing is that column and property names match.
Things get more complicated when the stored procedure returns data about different types in the hierarchy. Suppose you have a stored procedure that returns all customers and suppliers. Because the materialization process doesn’t care about mapping information, how can it know whether a row is about a customer or a supplier?
Returning a Hierarchy Mapped with the TPH Strategy
To map a result to all types of an inheritance hierarchy, the stored procedure must return a resultset that includes all columns for the involved types. Because the result-set is mapped on a column basis, you must include a discriminator column that identifies which class must be generated from each row. This is the same concept you’ve seen for the TPH mapping strategy.
Note
For this section, we’ll assume that there aren’t any complex properties but just scalar ones; otherwise, the following code won’t work. This section just explains how to use stored procedures to query an inheritance graph persisted with TPH. In chapter 11, you’ll see how to make complex properties, inheritance, and stored procedures work together.
Let’s start by analyzing the customer/supplier scenario. In the model, the Get-Companies stored procedure returns all the companies without worrying whether they’re customers or suppliers. In this situation, the return type can’t be Customer or Supplier but must be Company.
Company is abstract,, and mapping the stored procedure as described in the preceding paragraph generates an exception at runtime. What’s worse, because the use of stored procedures bypasses any inheritance configuration, if Company isn’t abstract, all the objects returned by the invocation of the stored procedure are of Company type, even if the result contains rows about customers and suppliers.
To solve the previous problems, you still use Company as the return type, but you also have to manipulate the mapping file of the EDM, specifying a discriminator column and what concrete type corresponds to each value of that column.
The node responsible for this configuration is FunctionImportMapping. Inside it, you nest a ResultMapping node containing as many EntityTypeMapping elements as there are possible return types. Each EntityTypeMapping element specifies the full name of the mapped type, and inside that you add a Condition node for each column of the function that acts as a discriminator. The result of this configuration is shown here.
Listing 10.2. Mapping resultset rows to types with a discriminator
<FunctionImportMapping FunctionImportName="GetCompanies"
FunctionName="OrderITModel.Store.GetCompanies">
<ResultMapping>
<EntityTypeMapping TypeName="OrderITModel.Supplier">
<Condition ColumnName="Type" Value="S"/>
</EntityTypeMapping>
<EntityTypeMapping TypeName="OrderITModel.Customer">
<Condition ColumnName="Type" Value="C"/>
</EntityTypeMapping>
</ResultMapping>
</FunctionImportMapping>
The conceptual file and storage file don’t specify any additional information other than what you’ve seen previously.
Finally, here’s the code for the stored procedure. As you can see, it’s trivial:
CREATE PROCEDURE GetTotalOrdersAmount AS SELECT * FROM company
Now you can invoke the stored procedure. Thanks to the inheritance mapping settings and the correct names of the columns, everything works fine.
Note
We haven’t used the designer here because it doesn’t support this feature. You have to change the EDM manually.
Using stored procedures to retrieve entities mapped using the TPH strategy is pretty easy. Mapping classes using a discriminator is something you’re familiar with. But what about the TPT approach? You don’t have a discriminator in this situation, so how do you map inheritance?
Returning a Hierarchy Mapped with the TPT Strategy
The product scenario uses the TPT approach. Even if the data organization is different from the TPH strategy, the way inheritance is mapped with stored procedures doesn’t change at all. You still have to use a discriminator. You can’t rely on the relationship between tables, because here you’re dealing only with the resultset. This is why the only thing that changes in the TPT approach is the stored procedure code—it must perform the join between the tables and create a discriminator column on the fly.
In OrderIT, the GetProducts stored procedure returns all the products in the database. As you’ll see, this stored procedure is more complicated than you may think, because there are columns with the same names in different tables, and they must be handled carefully, as the following stored procedure demonstrates:
ALTER PROCEDURE GetProducts
AS
SELECT p.*, isnull(sho.Color, shi.color) Color,
isnull(sho.Size, shi.Size) Size,
isnull(sho.Gender, shi.gender) Gender,
sho.Sport, shi.SleeveType, shi.Material,
case isnull(sho.gender, '0')
when '0' then 'SHIRT' else 'SHOE' end as type
FROM Product p
LEFT JOIN Shoes sho ON (p.ProductId = sho.ProductId)
LEFT JOIN Shirt shi ON (p.ProductId = shi.ProductId)
This SQL takes the Product table and joins it to the tables that contain product-specific data. Naturally, it’s a left join, so you’re sure that all products are returned. Additional columns for shoes are left null when the row belongs to a shirt and vice versa. In addition to joining data, this query creates a column that’s used in the mapping file to identify the row type: Type.
As you can see, there are many ISNULL statements in this T-SQL command. In T-SQL, ISNULL returns the value of the first parameter unless it’s null. If it’s null, the second value is returned. You do this because the Shirt and Shoe tables share the same column names. If you extract them twice, the materializer will always use the first column, ignoring the second one.
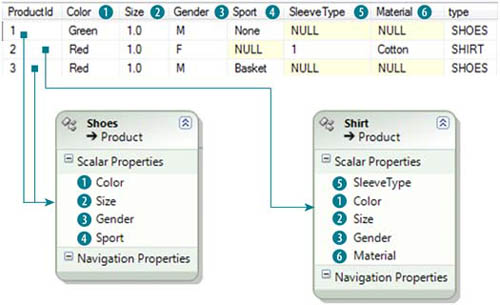
This means that if you extract shoe size and then shirt size as different columns, only the first one will be used to populate the property of both objects. If the object to be created is Shoe, everything works fine; but when the object is Shirt, it receives a null value, leading to exceptions or bugs due to erroneous data. Figure 10.12 illustrates this problem.
Figure 10.12. Mapping between the function result and the objects. Values in the first Color column are used to set both Shirt and Shoe entity properties. The second Color column is ignored.

Using the ISNULL function allows you to have a single column that contains data for both records. This way, the value of the column will be used to populate both classes. In figure 10.13 you can see that the problem is solved.
Figure 10.13. Mapping between the function result and the objects. The Color, Size, and Gender columns are used to fill properties of both classes.
The type column acts as a discriminator, letting you map the results as if they were coming from a TPH strategy. Here’s the mapping code.
Listing 10.3. Mapping resultset rows to types via a discriminator with TPT hierarchies
<FunctionImportMapping FunctionImportName="GetProducts"
FunctionName="OrderITModel.Store.GetProducts">
<ResultMapping>
<EntityTypeMapping TypeName="OrderITModel.Store.Shirt">
<Condition ColumnName="Type" Value="SHIRT"/>
</EntityTypeMapping>
<EntityTypeMapping TypeName="OrderITModel.Store.Shoe">
<Condition ColumnName="Type" Value="SHOES"/>
</EntityTypeMapping>
</ResultMapping>
</FunctionImportMapping>
Stored procedures return resultsets, but in some cases you may want them to return additional information. The best way to do this is to use output or input-output parameters.
10.2.5. Stored procedures with output parameters
A typical example where you need an output parameter is when creating a stored procedure that returns paged data. To build an efficient paging system, you must retrieve only the data that needs to be bound to a control (such as a grid) and the number of records to create a pager. In OrderIT, the GetPagedOrderDetails stored procedure retrieves the order details based on paging information and sets an output parameter with the total number of details. Its code is as follows.
Listing 10.4. Stored procedure that returns a resultset plus an output parameter
CREATE PROCEDURE GetPagedDetails
@pageIndex int,
@rowsPerPage int,
@count int output
AS
BEGIN
WITH PageRows
AS (
SELECT TOP(@pageIndex * @rowsPerPage)
RowNumber = ROW_NUMBER() OVER (ORDER BY orderdetailid), *
FROM orderdetail
)
SELECT *
FROM PageRows
WHERE RowNumber > ((@pageIndex - 1) * @rowsPerPage);
select @count = COUNT(*) from orderdetail
END
Entity Framework natively supports output parameters for stored procedures. When you import a stored procedure by the designer, Entity Framework automatically inspects the stored procedure looking for output parameters and marking them in the EDM.
If you modify the EDM manually, you need to set the Mode attribute of the Parameter element to Out for output parameters or InOut for both input and output, as in the next fragment:
<Parameter Name="count" Type="int" Mode="Out" />
The context code autogenerated by the POCO template is more complicated than it may seem. So far, you’ve used the automatically generated methods, passing in a value for each input parameter of the function. Output parameters are a bit different. They must still be passed to the method, but as ObjectParameter objects instead of simple values. This is due to the way Entity Framework retrieves the output parameter’s value after execution.
The fetching of stored procedure results is lazy. First the resultset is processed, and only after that are the output parameters retrieved. This means you can’t get the output parameter values until you’ve fetched all the resultset records. To avoid this, the template code generates the method parameter related to the stored procedure output parameter as an object of ObjectParameter type. If you pass an out value for C# or ref for VB, you will always have an empty value because the results have not been iterated yet. The following listing contains the correct code.
Listing 10.5. Output parameters returned as ObjectParameter objects

What’s bad about this approach is that the invoking code needs to know the names of the output parameters. This makes it impossible to encapsulate the logic of the function call.
An alternative is shown in the following listing. Here you iterate over the results directly into the context function, so that inside it you have both the results and the values of the parameters.
Listing 10.6. Output parameters returned as simple values

The function result is no longer an ObjectResult<T> instance but a List<T> ![]() , because the data is fetched inside it. The method no longer accepts an Object-Parameter parameter but a simple value
, because the data is fetched inside it. The method no longer accepts an Object-Parameter parameter but a simple value ![]() . Inside the method, you execute the function and immediately iterate its result using the ToList method
. Inside the method, you execute the function and immediately iterate its result using the ToList method ![]() . Finally, you set the simple output parameter value
. Finally, you set the simple output parameter value ![]() .
.
Remember that returning results as a List<T> is different from returning them as an ObjectResult<T>. Choose each option on a one-by-one basis.
Sometimes, instead of using output parameters, data is returned in a second result-set. Let’s see what you can do in this case.
Output Parameters in a Second Resultset
If you opt for a solution where the additional data is returned as a second resultset instead of in output parameters, you must keep in mind that ExecuteFunction<T> doesn’t support multiple resultsets. It doesn’t fail if more than one resultset is returned from the stored procedure; it takes the first and ignores the others. The workaround is to use the Entity Client and its internal physical connection to manually invoke the stored procedure and iterate over its results. This goes beyond Entity Framework, so you’re better off directly using ADO.NET.
Now you know everything about reading data using stored procedures. But sometimes you don’t have a stored procedure, and you’d like to. If you can’t create one because you don’t have permissions (or for any other reason) you can create one inside the EDM.
10.3. Embedding functions in the storage model
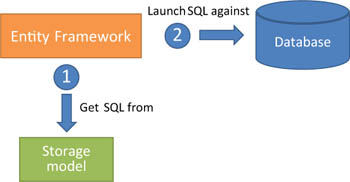
Although the storage file describes the database, you can add information to it that isn’t related to the real database structure. More precisely, you can create functions that don’t exist in the database but that are still seen as functions by the engine. Figure 10.14 shows the flow of a storage model function’s execution.
Figure 10.14. The function-execution process: Entity Framework gets the SQL from the SSDL and then executes it against the database.
Naturally, you have to define the SQL code for such functions, and you have to do it using the database-specific SQL code (for instance, T-SQL for SQL Server or PL-SQL for Oracle).
This feature turns out to be useful when you want to optimize a query and you don’t have an appropriate stored procedure. Another situation where it’s useful is when you must use a particular database feature that neither LINQ to Entities nor Entity SQL allows you to use. The power of this feature really shines when you have to update data using stored procedures; we’ll cover this subject in section 10.4.
Defining a function in the storage model is similar to defining a stored procedure. The only difference is that the Function element has a nested CommandText element, inside which you put the SQL code. Should the function need any parameters, you use the Parameter element. (The CommandText element must be put before Parameter elements.) The following snippet shows the definition of a function:
<Function Name="GetOrderDetailsByIdUsingEmbeddedFunction"
IsComposable="false" Schema="dbo">
<CommandText>
select * from [orderdetail] where orderid = @orderid
</CommandText>
<Parameter Mode="In" Name="orderid" Type="int"/>
</Function>
Note
If the SQL code contains the < or > sign, you must use its escaped versions: > or <. This is necessary to avoid any conflict with the XML format of the mapping files.
The conceptual and mapping schemas aren’t even aware that the function is embedded in the storage schema. As a result, the declaration of the function in the CSDL, and the mapping between the function and the stored procedure in the MSL, don’t change. The code generated by the POCO template and the way you use the code isn’t affected either. You can invoke the function exactly as you do for stored procedures.
Note
This feature isn’t supported by the Visual Studio Designer. What’s worse, every time you update the model from the database, it re-creates the storage schema from scratch, and the function is lost. Despite these limitations, this feature is a great example of mapping flexibility in Entity Framework and a great example of the advantages of EDM decoupling.
The SQL embedded in the function can contain more than one command. It can contain any SQL command you need. Potentially, you could avoid writing stored procedures in the database and put all of them into the storage schema. But naturally, we wouldn’t recommend this practice to our worst enemies, let alone to you.
So far, you’ve learned how to query data using stored procedures and storage-model functions, but that’s only half of the story. Stored procedures can perform any operation on the database, including making modifications. In the next section, we’ll investigate how to make Entity Framework interact with this type of stored procedure.
10.4. Updating data with stored procedures
Updating data using stored procedures is a common way of hiding SQL and database complexity from the code. Sometimes such complexity can be difficult to manage in code, and a stored procedure may be a good place to put the logic.
For instance, using a stored procedure is useful when an operation on one entity requires updating another entity. In OrderIT, adding an order requires updating the stock of the ordered products. You’ve seen how to update the number of items in stock via code, but using a stored procedure would probably have been simpler.
Sometimes, handling the update via Object Services isn’t convenient because of concurrency or other reasons. In OrderIT, this was the case with updating the number of items in stock when new items are added to the available ones. You learned in chapter 8 that if you update the number of items in stock, you risk concurrency check problems even if you don’t need the check to be performed. In such a case, a stored procedure is a good way to avoid concurrency checks.
These are the possible scenarios when updating entities using stored procedures:
- A stored procedure persists a standalone entity.
- A stored procedure persists an entity in an inheritance hierarchy.
- A stored procedure upgrades and downgrades an entity in an inheritance hierarchy.
- A stored procedure performs an arbitrary operation not connected to any entities.
The first two cases are straightforward and are almost identical in terms of how you handle them. The third case is a bit more complex and deserves particular handling. The last one covers launching commands other than those executed by Entity Framework for persistence.
Let’s start by analyzing the simplest scenario, where a standalone entity is updated using stored procedures.
10.4.1. Using stored procedures to persist an entity
Persisting an entity using stored procedures is an all-or-nothing affair. You can’t use a stored procedure that inserts data into the database and leave Entity Framework to generate the SQL for UPDATE and DELETE operations. That isn’t supported, and if you try it you’ll get a runtime exception.
To demonstrate using a stored procedure to persist an entity, you’ll persist an Order. This is probably the most complex entity in the model, and it uses all the function-mapping features. It has foreign keys and complex properties, and it’s the parent of a relationship, which means its database-generated ID is necessary for inserting the details.
The following steps will show you specifically how to map the stored procedure to insert an order, but the same process applies to updates and deletions:
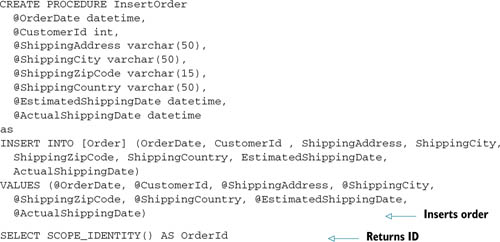
1. Create the stored procedure as in the following listing.
Listing 10.7. A stored procedure that inserts an order
2. Import the stored procedure the same way as before. (You don’t need to create the function in the conceptual schema.)
3. Right-click the Order entity, and select the Stored Procedure Mapping item.
4. In the Mapping Details window, associate each operation to the related stored procedure, as shown in figure 10.15.
Figure 10.15. Mapping a stored procedure to persist a new order. The same process applies for modifications and deletions.
5. Map the stored procedure’s parameters to the Order class’s properties. The designer automatically maps columns and properties whose names match. Complex properties must be mapped manually.
6. In the Result Column Bindings section (shown in figure 10.16), write OrderId in Parameter/Column column, and associate it to the OrderId property. This way, the column containing the autogenerated ID returned by the stored procedure (see the last line of listing 10.7) is used to set the OrderId property of the order after the stored procedure has been executed. Naturally, this is only needed for database-generated values; if you generate primary keys on your own, it’s not necessary.
Figure 10.16. Mapping the stored procedure’s parameters to the entity’s properties

The preceding steps can also be used to map stored procedures that perform updates and deletions. The only difference is that step 6 isn’t required because UPDATE and DELETE commands don’t generate the ID of the row.
That’s it. You don’t need to invoke these stored procedures manually. Because Entity Framework knows how they’re mapped to the properties, it invokes the stored procedures when it needs to persist the entity, instead of generating SQL code.
To demonstrate this, suppose that you added an order and two details to the context. When you call the SaveChanges method, the SQL Profiler would look like figure 10.17.
Figure 10.17. The order is inserted using a stored procedure; details are stored using Entity Framework–generated code.

What’s great about this technique is that if you decide to switch from using Entity Framework–generated SQL code to stored procedures, it’s completely transparent to you. What’s dangerous is that although the Entity Framework code updates only the modified properties of the entity, the stored procedures you write generally update all the properties. Always remember that, because if you persist a partially loaded entity (an entity where not all properties are set), you may end up losing your data.
Before passing on to the next subject, let’s take a quick look at how the EDM is affected when you map stored procedures to persist an entity, as in the previous series of steps.
Stored Procedures that Persist an Entity and the EDM
From the SSDL point of view, the stored procedures are declared as usual; there’s nothing new about that. The same thing happens for the CSDL. Because the stored procedures are invoked automatically by Entity Framework, there’s no need to import them to the conceptual schema: you’ll never use them.
What really changes is the mapping schema, as you see here.
Listing 10.8. Mapping an entity to persistence stored procedures in the MSL
<EntityTypeMapping TypeName="OrderITModel.Order">
<ModificationFunctionMapping>
<InsertFunction FunctionName="OrderITModel.Store.InsertOrder">
<ScalarProperty Name="ActualShippingDate"
ParameterName="ActualShippingDate" />
<ScalarProperty Name="EstimatedShippingDate"
ParameterName="EstimatedShippingDate" />
<ScalarProperty Name="CustomerId" ParameterName="CustomerId" />
<ScalarProperty Name="OrderDate" ParameterName="OrderDate" />
<ComplexProperty Name="ShippingAddress"
TypeName="OrderITModel.AddressInfo">
<ScalarProperty Name="Country" ParameterName="ShippingCountry" />
<ScalarProperty Name="ZipCode" ParameterName="ShippingZipCode" />
<ScalarProperty Name="City" ParameterName="ShippingCity" />
<ScalarProperty Name="Address" ParameterName="ShippingAddress" />
</ComplexProperty>
<ResultBinding Name="OrderId" ColumnName="OrderId" />
</InsertFunction>
<UpdateFunction ...> ... </UpdateFunction>
<DeleteFunction ...> ... </DeleteFunction>
</ModificationFunctionMapping>
</EntityTypeMapping>
In the EntityTypeMapping element related to the Order type, you include a ModificationFunctionMapping element. It instructs Entity Framework that the persistence of the entity is delegated to the stored procedure defined in this element. Inside EntityTypeMapping, you define three nodes that correspond to the insert, update, and delete stored procedures: InsertFunction, UpdateFunction, DeleteFunction (the order isn’t important).
We’ll focus on the mapping information for the insert function here, but this information is valid for the other elements too. The InsertFunction element contains the FunctionName attribute, which defines the full name of the stored procedure as declared in the storage schema. Inside it, you declare a set of ScalarProperty nodes to map scalar-entity properties to stored-procedure parameters; complex properties are mapped using the ComplexProperty node. Furthermore, using the Result-Binding element, you define the mapping for data returned by the function. It’s particularly important for insert functions that can return the ID of the row just added to the database.
After you’ve mapped all the parameters for the insert function, you have to map the update and delete ones too, and then you’re ready to go.
What about concurrencies? You know that the automatically generated SQL reflects the concurrency settings. Because with stored procedures you have to manage everything manually, you have to handle concurrency too.
10.4.2. Using stored procedures to update an entity with concurrency
Entity Framework natively supports optimistic concurrency. With stored procedures, this support is totally up to you, but the infrastructure and the designer help a lot. Because the state manager keeps track of the original values, you can pass them to the stored procedure along with the current ones. When you have both, you can perform the concurrency check in the stored procedure.
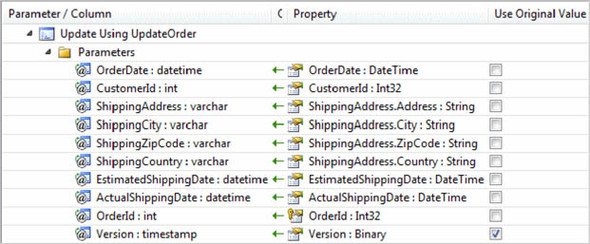
What’s absolutely great is that the retrieval of the original values is hidden from the code. You specify it directly in the mapping using the designer. In the Mapping Details window (shown in figure 10.18), next to the Property column is a Use Original Value column containing check boxes. If Use Original Value is checked, the original value of the property is used; otherwise, the current value is used.
Figure 10.18. The original value of the Version field is passed to the stored procedure. The other parameters take the property’s current value.
Manually mapping the version in the EDM is simple. Just add the Version attribute of the ScalarProperty element, and set it to Original to pass the original value, as in the following fragment:
<ScalarProperty Name="Version" ParameterName="Version" Version="Original" />
Or set ScalarProperty to Current to use the current value.
Note
Remember that even if you don’t need concurrency, the Version attribute is mandatory for the parameters declared in an Update-Function.
A standalone entity is easy to map. The situation gets more complicated when the entity is part of an inheritance hierarchy. In the next section, we’ll investigate such a scenario.
10.4.3. Persisting an entity that’s in an inheritance hierarchy
When inheritance comes into play, there are some additional considerations. Once again, all or nothing is the main rule: if you want to use stored procedures to persist an entity that’s part of an inheritance hierarchy, all of the concrete (non-abstract) entities that belong to the same hierarchy must be persisted using stored procedures.
In the customer/supplier scenario, you have to create three stored procedures for the customer and three stored procedures for the supplier. It works like a charm without you needing to learn anything new.
But the difference between the customer and supplier stored procedures is just a few fields. It would be nice to create a stored procedure that manages one operation for both entities. For instance, you could create a stored procedure that handles the insert for both customers and suppliers, and do the same for updates and deletions. This would spare some lines of code and keep the set of stored procedures smaller.
Using One Stored Procedure to Persist a Hierarchy
The idea behind this technique is to create a single stored procedure to perform a type of update for both classes. (Potentially, you could write a single stored procedure that performs all CUD operations for all classes, but it would be a mess.)
After the stored procedure is created, you can create two functions in the SSDL and personalize the command to invoke the real stored procedure with different parameters. This can be done using the CommandText element, as you saw in section 10.3. This technique is shown in listing 10.9. (For the sake of clarity, we have hidden the parameter declarations.)
Listing 10.9. Declaring functions and letting them invoke stored procedures

The last step is mapping the stored procedures to the InsertFunction node of the customer and the supplier classes. That’s done the same way as before, so we won’t show it again here. Naturally, the same technique applies to update and deletion stored procedures.
Note
We didn’t use the designer because this feature isn’t supported. Everything must be done manually. And remember that the storage schema is rewritten each time you update the model from the database, so you’ll lose any changes when that happens.
We have now analyzed the customer/supplier (TPH) scenario, but everything we have done is perfectly valid for the product (TPT) scenario. In both mapping strategies, you can encounter a case where you need to upgrade or downgrade an entity. Let’s see what that means.
10.4.4. Upgrading and downgrading an entity that’s in an inheritance hierarchy
In OrderIT, you can’t persist a company or a product. You have to use the specialized classes (Customer, Supplier, Shoe, and Shirt) because the base classes have no meaning in the business (in fact, they’re abstract). In other situations, the base classes may have meaning as well as the inheriting classes. Think about a contact list where a simple contact can become a customer. You can model this situation using the TPH strategy: Contact is the base class, and Customer inherits from it.
When you create a new contact, it’s persisted in the table with a discriminator value of CO. At a certain point, the contact decides to buy something and becomes a customer. Lots of additional data is required, and the discriminator column must be changed to CU. We’ll call this process upgrade. If for some reason you need to delete the customer but keep the person or company as a contact, you perform a downgrade.
Entity Framework doesn’t support this functionality. This means you have to perform all the updates manually using stored procedures or custom SQL commands. If you aren’t comfortable with this approach, you can use the classic ADO.NET approach to modify data in the table. If you use the TPH strategy, you just have to modify the discriminator column to change the type. If you use the TPT strategy, you have to delete the record from the specialized table, leaving the data only in the main table.
It’s important to highlight that the domain-driven design rules state that the type of an entity must always be the same during its lifetime. What we have described here is a situation where we’re changing the type of an entity. This is a situation we have encountered several times and have solved using stored procedures without any problems, but you could also achieve the same goal in other ways. Because there are many variables involved, every case must be evaluated on its own.
Sometimes you need to perform an update on the database that’s not connected to the persistence of an entity. For instance, you may want to log each time a user signs in. In this case, you don’t have a Log entity; what you need to do is add a record in a table. Using a stored procedure to do this is pretty simple. Let’s see how to do that.
10.4.5. Executing stored procedures not connected to an entity
In chapter 7 you saw that a custom command can be executed using the Execute-StoreCommand method, but this has the disadvantage of breaking the database-independence model, because it accepts a SQL string. A stored procedure is definitely a better way to go; it encapsulates the logic, makes the application database-agnostic, and keeps the DBA happy. You kill three birds with one stone.
Having said that, to invoke a stored procedure that doesn’t return data, you have to use the ExecuteFunction method. It’s different from ExecuteStoreCommand because it doesn’t accept a generic parameter and returns only an Int32 containing the number of affected rows. The only arguments it accepts are the stored procedure name plus an array of ObjectParameter objects representing the parameters.
Naturally, to be invoked via the context class, the stored procedure must be imported to the conceptual schema. Even if you import the stored procedure in the conceptual schema, the POCO template you’ve been using so far to generate code doesn’t generate a context method to invoke these types of stored procedures. Fortunately, with a little bit of work on the POCO template, you can change that. You’ll learn how to do that in chapter 13.
10.5. Summary
Stored procedures are a key feature of any database, and they’re used in almost every project we have developed. It’s very important that you understand how to best use them in any situation.
This chapter has given you some great insight into what you can do with Entity Framework and stored procedures. In this version of Entity Framework, native support for stored procedures has been greatly improved, but there’s still a lot to do to make them work seamlessly.
The designer offers great productivity improvements and the template-generated context class offers better integration, but the ability to map stored procedure to entities with complex types and support for eager loading are still missing. We’ll probably see these features in the next release, but for the moment we have to live without them.
We’re now finished with stored procedures, but there’s another similar feature that’s key in Entity Framework: database and model functions, which are discussed in the next chapter, together with defining queries.