
Chapter 16. Entity Framework and n-tier development
You can solve many problems with a service-oriented application. Sometimes these types of applications are used by client applications (clients from now on) within a larger system. Other times, clients are developed by third-party organizations, and your duty is to build services. This means that you have no GUI to develop—just services.
Whatever the client is, the application must be separated into different physical tiers that are completely disconnected from each other and that communicate through a specific interface: the contract. In the context of Entity Framework, working in a disconnected way is the obvious pattern for these types of applications because the context can’t be propagated from the server to the client tier, which means modifications made on the client side can’t be tracked, and a new context for each request is required on the server side.
In chapter 6, you learned that a degree of discipline is required to work in a disconnected scenario. Although the code on the client side is simple (the client code isn’t even aware that Entity Framework is used by the server), persisting modifications on the service side requires a certain amount of code.
In this chapter, you’ll learn what problems services have to face and what techniques you can use to solve them. You’ll also learn that under some circumstances, Entity Framework can simplify n-tier applications so that you can stay more focused on the business code and not spend as much time on persistence problems.
16.1. n-Tier problems and solutions
Distributed applications introduce challenges that don’t exist for applications that are always connected (such as Windows applications), including client change-tracking and entity serialization. We’ll look at these n-tier problems and solutions in the next few sections, so we can spend the rest of the chapter looking at how to implement n-tier applications.
16.1.1. Tracking changes made on the client
The biggest challenge you face when developing n-tier applications is that the context exists only on the server side, so changes made to entities on the client aren’t tracked (this is a typical example of a disconnected scenario). Suppose you have a web service with one method that reads the customer and another that updates it (an example we’ve looked at previously). Figure 16.1 shows how such a web service handles the context.
Figure 16.1. The path of an update in a n-tier application. The context that’s used to read a customer is different from the one used to update it. Furthermore, client change-tracking isn’t available.
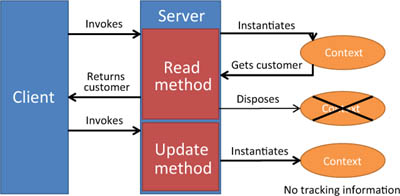
In the method that retrieves the customer, you create a context, retrieve the customer, return it to the caller, and then destroy the context. In the method that saves the customer, you create a context, but it has no knowledge of what has been modified on the client side. The result is that you have two ways to update the customer:
- Retrieve the customer from the database, compare it with the input version, update the database with the differences, and destroy the context.
- Attach the input customer to the context, mark it as Modified, persist all its data, and destroy the context.
Both solutions are simple because Customer is a single entity; but what happens with orders? Creating and deleting an order is pretty easy, but how do things change if you have to update one? You have to handle its relationships with the customer and with the details, which must in turn keep their relationships with the products. You have to know which details have been updated, added, or deleted.
A possible solution is to compare details from the database with the ones in the input order. Another option is adopting a convention where details with ID 0 are added, those with ID greater than 0 are updated, and those with ID greater than 0 and with all properties set to their default values are deleted. Whatever your choice is, you have to arrange a sort of logic contract between the client and the server, and the client must know how to let the service understand what happened. This logic contract requires lots of code on both the client and the server.
Another alternative is to use self-tracking entities(STEs). These are POCO entities that contain data plus logic that internally stores the modifications made to the properties. Thanks to this feature, the client can send the entities back to the server, which can read the internal state and save the modifications to the database. STEs aren’t bulletproof. They’re perfect in some scenarios, but in others they’re unusable. Later in this chapter, we’ll discuss when and why you can use them.
In addition to the change-tracking problem, another problem that arises when working in n-tier scenarios is the contract between the client and server. Usually you won’t want to send full entities to the client because they could contain sensitive information.
16.1.2. Choosing data to be exchanged between server and client
In OrderIT, each customer has a username/password combination that grants access to the web service they can use to modify personal data and to create and modify orders. You should never let the password flow through the web service. You can let the customer reset the password, send it to the customer via mail, or let the system administrator change it, but you shouldn’t let the password flow to the customer through the service (especially if the channel isn’t secured by HTTPS).
What’s more, it’s the system administrator who decides whether a customer can access the web service and what username is assigned, so the customer can’t change web service–related information through the web service.
Now, suppose that you’re realizing the web service methods that let customers read and modify their personal data. The first thing you have to decide is how to exchange data with the client. Because the Customer entity has the WSPassword, WSUsername, and WSEnabled properties (which we’ll refer to collectively as the WS* properties), and you don’t want to send them to the web service client, you have two choices:
- Send the Customer entity to the client, emptying the WS* properties. This approach works. You just need to pay attention to not filling the WS* properties when sending data to the client and to not using the WS* properties’ values to update the database when data comes back from the client. The obvious drawback is that because you’re ignoring the WS* properties, there’s not much point in sending them back and forth. The next option is better than this one.
- Create a CustomerDTO class, a data transfer object (DTO) class, containing only the data needed for communication, and expose it to the client. This approach works really well. You just need to create an ad hoc class (a DTO), pour data into it when reading the Customer entity, and pour data from it to the Customer entity when updating the database (not updating the WS* properties). This way, you have a much cleaner design, with the only drawback being that you need to maintain one more class. But remember that T4 templates can help you generate such classes. Just create a custom property (as you did in the Add/Attach example in chapter 13) that states whether the entity property must be included in the DTO, and then create a template that generates the DTO for you. If this doesn’t make you fall in love with T4, nothing will.
The class you expose to the client is known as the contract. Choosing what type of contract to expose to the client isn’t strictly related to Entity Framework; it’s more related to application design. Nonetheless, choosing whether to send the full entity or a DTO to the client has an impact on how you work with Entity Framework.
Let’s now look at another common problem. Generally speaking, to let data flow over the wire, the data must be serialized. You know that when an entity is returned by a query, the real type is a proxy (unless you disable proxy generation). This creates a problem, because Windows Communication Foundation (WCF), which is the framework we’ll use to create the web service, isn’t able to serialize a proxy instance.
16.1.3. The serialization problem
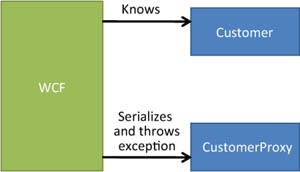
By default, when you query for a customer, you get an instance of an object that inherits from Customer (such as CustomerProxy). WCF can serialize only types it knows about (referred to as known types), and CustomerProxy, although it inherits from Customer, isn’t a known type. The consequence is that serializing it throws an exception, as illustrated in figure 16.2.
Figure 16.2. WCF knows Customer but not CustomerProxy, so it throws an exception when serializing CustomerProxy.
The problem isn’t only on the server side, but on the client side also. The client can be an application that uses Entity Framework for its own purposes. Suppose the client reads customer data from its own database and then calls the service to synchronize local database data with server data. In this case, the client could have a proxy instance that would need to be serialized by WCF: different layers, but the same problem.
Often you don’t need a proxy. If you only need to read an entity from the database and send this entity over the wire, you don’t need either change-tracking or lazy-loading behavior. In such cases, you can disable proxy generation.
Note
If you have a proxy instance, remember to disable lazy loading before serializing, or you’ll end up sending unwanted data to the client. This happens because the WCF serializer extracts all properties, including navigation properties, and this causes them to be lazily loaded.
In some cases, though, you may need to have a proxy instance and to serialize it. The Entity Framework team considered this possibility and used a new WCF 4.0 feature to serialize proxies: the contract resolver. WCF’s DataContractResolver class allows you to dynamically map one type to another type.
The Entity Framework team created the ProxyDataContractResolver class, which inherits from DataContractResolver, to map the proxy type to the POCO type that the proxy wraps (for example, from CustomerProxy to Customer). To resolve the mapping, ProxyDataContractResolver invokes the ObjectContext class’s static Get-ObjectType method, which returns the base type of the proxy, which is the POCO entity (for example, Customer is the base type of CustomerProxy).
Because WCF knows the POCO entity, WCF treats the proxy as if it were the POCO entity, so WCF serializes the entity without any problem. It’s that easy.
ProxyDataContractResolver is great, but it does nothing on its own. You must plug it into the WCF pipeline. We’ll look at how to do this in the next section, where you’ll start to develop a service.
You now have a clear idea of what intricacies you face when developing a service application. In the next sections, you’ll develop services that use plain entities, DTOs, and STEs so that the full spectrum of options will be covered. By the end of the chapter, you’ll have a solution for each situation.
16.2. Developing a service using entities as contracts
In many projects, entities are fully exposed through a web service (so DTOs aren’t used). If the client can access all of an entity’s properties, using the entity to exchange data between client and server isn’t an issue. If the client shouldn’t access some entity’s properties, using the entity to exchange data between client and server isn’t the best solution. For instance, as we mentioned in the previous section, exposing the Customer entity in OrderIT poses a problem because you don’t want to send WS* properties back and forth. However, as long as you don’t set them when you send the entity to the client, and you don’t update them when the entity comes back, you can let the properties flow across the tiers.
Let’s look at how you can create a service that uses the Customer entity to let the customer read and update its personal data. The first thing to do is to create a service interface like the one in this listing.
Listing 16.1. The interface exposed by the service
[ServiceContract]
public interface IOrderITService
{
[OperationContract]
Customer Read();
[OperationContract]
void Update(Customer customer);
}
VB
<ServiceContract()> _ Public Interface IOrderITService <OperationContract()> _ Function Read() As Customer <OperationContract()> _ Sub Update(ByVal customer As Customer) End Interface
The Read method returns the current customer. There’s no CustomerId parameter because the web service is secured, and the security check returns the id of the logged-in customer. This way, you’re sure that a call to Read returns data about the current customer.
The Update method takes the customer back and updates it.
Note
Update accepts a Customer entity, but it could have accepted single properties (shipping address, city, name, and so on). There are pros and cons in both techniques, so choosing one approach or the other is a matter of personal taste.
The implementation of Read queries for the customer by the ID, blanks out the WS* properties, and returns the entity to the caller. The code is shown in the following listing.
Listing 16.2. The implementation of the Read method
C#
public Customer Read()
{
using (var ctx = new OrderITEntities())
{
var result = ctx.Companies
.OfType<Customer>()
.FirstOrDefault(
c => c.CompanyId == _customerId);
result.WSPassword = String.Empty;
result.WSUsername = String.Empty;
result.WSEnabled = false;
return result;
}
}
Public Function Read() As Customer
Using ctx = New OrderITEntities()
Dim result = ctx.Companies.
OfType(Of Customer)().
FirstOrDefault(
Function(c) c.CompanyId = _customerId)
result.WSPassword = String.Empty
result.WSUsername = String.Empty
result.WSEnabled = False
Return result
End Using
End Function
The query to retrieve the customer is simple, and you’ve seen it several times before. Blanking out the WS* properties is pretty simple too. The entire method is definitely trivial.
At runtime, the code performs correctly; but when WCF serializes the entity, a serialization exception is thrown because result is a proxied instance of the Customer entity. In the next section, you’ll see how to overcome this problem, but for the moment we’ll let it stand and examine how to handle the Update method.
Update takes the modified customer and persists it. The problem here is that it should only update the address-related properties and the name, and ignore the others.
If you mark the entity as Modified using the ChangeObjectState method, all the properties will be modified even if they’re blank or null. If you retrieve the customer from the database and then use ApplyCurrentValues to update it with the values from the input entity, you’ll have the same problem. The password is blank in the input entity, and it has a value in the one coming from the database. Because ApplyCurrentValues overrides database entity values with ones from the input entity, the blank value would be persisted.
The ideal solution should allow you to set the entity as Modified but for only some of the properties to be updated. This result can be achieved using the ObjectStateEntry class’s SetModifiedProperty method, which marks a property (and the entry) as Modified. You see it in action in this listing.
Listing 16.3. The implementation of the Update method
C#
public void Update(Customer customer)
{
using (var ctx = new OrderITEntities())
{
ctx.Companies.Attach(customer);
var entry = ctx.ObjectStateManager.
GetObjectStateEntry(customer);
entry.SetModifiedProperty("ShippingAddress");
entry.SetModifiedProperty("BillingAddress");
entry.SetModifiedProperty("Name");
ctx.SaveChanges();
}
}
Public Sub Update(ByVal customer As Customer)
Using ctx = New OrderITEntities()
ctx.Companies.Attach(customer)
Dim entry = ctx.ObjectStateManager.
GetObjectStateEntry(customer)
entry.SetModifiedProperty("ShippingAddress")
entry.SetModifiedProperty("BillingAddress")
entry.SetModifiedProperty("Name")
ctx.SaveChanges()
End Using
End Sub
First the entity is attached to the context. After that, the related entry is retrieved and the properties that were updatable by the user are marked as Modified. Finally, the entity is persisted. This way, only marked properties are persisted.
Updating a single entity is fairly simple. But as we said before, when it comes to orders and details, the situation becomes more complex.
16.2.1. Persisting a complex graph
Updating just the order or a detail is pretty simple, because you can reuse the same technique used for the customer. What’s difficult is understanding what details have been added or removed.
In section 7.3.3, you learned how to detect what’s been changed. The drawback in that code is that it requires a comparison between details in the database and the details you’ve been passed by the client. To avoid this, you can establish a logic contract with the client: deleted details are always sent to the server with only the ID set (and with all other properties at their default values), added details are assigned an ID of 0, and other details are considered to be modified. This way, you can retrieve deleted, added, and modified details in a snap using simple LINQ queries.
The disadvantage of this technique is that you move some business logic to the client, and that’s not good from a design point of view. That’s why we disregard this pattern and opt for the comparison with the database, despite its additional querying.
Naturally, customers can’t change an order’s estimated or actual shipping dates, nor can they change an order detail’s discount. To prevent customers from updating this data, you can use the same technique discussed in the preceding section.
So far, you’ve sent full entities over the wire, taking care to blank out properties that shouldn’t be seen by the client. But wouldn’t it be better if the properties that shouldn’t be shown to the client weren’t exposed by the service at all, so you could avoid writing the code that blanks these properties out? Let’s look at how to do that.
16.2.2. Optimizing data exchanges between client and server
If you want to fully customize the way you send data back and forth, using DTOs is the best way. You can use plain entities and have them behave sort of like DTOs, but this solution has some disadvantages that we’ll analyze in this section.
By default, WCF exposes all entities’ public properties to the client. You can change this behavior and selectively decide what properties to expose by applying WCF-specific attributes on classes and properties. For example, you can apply attributes on the CompanyId, Name, ShippingAddress, and BillingAddress properties so that only they are available to the client. The following listing shows how to apply such attributes to classes.
Listing 16.4. Marking entities for WCF custom serialization


The attributes to use are DataContract ![]() and DataMember
and DataMember ![]() . DataContract must be applied on the class to specify that only properties decorated with DataMember should be exposed by the service. The result of listing 16.4 is that in the WSDL exposed by the service, Company contains the CompanyId, Name, and Version (required for concurrency checks) properties, and Customer contains only the Shipping-Address and BillingAddress properties. When the client generates its classes from the WSDL, it will create them with only those properties and will
never know that on the server, the classes contain more properties.
. DataContract must be applied on the class to specify that only properties decorated with DataMember should be exposed by the service. The result of listing 16.4 is that in the WSDL exposed by the service, Company contains the CompanyId, Name, and Version (required for concurrency checks) properties, and Customer contains only the Shipping-Address and BillingAddress properties. When the client generates its classes from the WSDL, it will create them with only those properties and will
never know that on the server, the classes contain more properties.
Note
Manually modifying entities isn’t the best practice because the modifications are lost at each code generation. It’s better to create a custom annotation in the EDM and then modify the template that generates the code (as we discussed in chapter 13).
Exposing only the correct properties is optimal not only from a design point of view but for performance too. When you send full entities with blanked-out properties, the empty properties are still sent to the client. Not sending the WS* properties over the wire means that less data is sent and more requests can be served.
In the code for reading the customer, the only difference is that you don’t need to blank out the WS* properties because they’re not sent to the client. In the update phase, nothing changes because only the addresses and name properties must be updated.
Note
Even if the Customer entity that goes over the wire is different from the actual one (it has fewer properties), WCF is able to map it to the original one by using the DataContract and DataMember attributes.
We’ve already talked about the serialization problem, but we haven’t talked much about its solution. Let’s look at that now.
16.2.3. Dealing with serialization in WCF
The easiest way to make an entity that’s returned by a query serializable by WCF is to set the ContextOptions.ProxyCreationEnabled property of the context to false (by default, it’s true) before performing the query. This way, you obtain the plain entity instead of a proxied one, eliminating any serialization problem.
Disabling proxy generation isn’t always possible because you may need lazy loading or change tracking. In such cases, you need to serialize a proxied instance.
In section 16.1.3, you’ve learned that ProxyDataContractResolver is the key to proxy serialization. The contract resolution is a WCF feature that enables you to map the actual type (the proxy) to a WCF known type (the entity exposed) using the workflow illustrated in figure 16.3.
Figure 16.3. WCF knows Customer, and when it receives CustomerProxy, it uses the resolver to map CustomerProxy to Customer.

ProxyDataContractResolver performs such mappings but it isn’t able to interfere with the WCF pipeline. That’s something you have to do manually. Fortunately, this process is pretty simple; you just have to create an attribute and decorate the service interface methods with it. You can see the code for the attribute in the following listing.
Listing 16.5. Class that plugs the contract resolver into WCF


The ProxyResolverAttribute class intercepts both the client ![]() and service
and service ![]() serialization processes, setting the actual resolver to a ProxyDataContractResolver instance. The SetResolver method is the most important, because it’s here that you retrieve the serialization behavior
serialization processes, setting the actual resolver to a ProxyDataContractResolver instance. The SetResolver method is the most important, because it’s here that you retrieve the serialization behavior ![]() and set its resolver to ProxyDataContract-Resolver
and set its resolver to ProxyDataContract-Resolver ![]() .
.
After the attribute class is created, you decorate the Read interface method with the attribute, as shown in the next snippet:
C#
[OperationContract] [ProxyResolverAttribute] Customer Read();
VB
<OperationContract()> _ <ProxyResolverAttribute()> _ Function Read() As Customer
From now on, each time WCF tries to serialize entities in the Read method, it will use the Entity Framework resolver. By applying the attribute to all service methods, you can work with both plain and proxied entities everywhere, without worrying about their serialization. This is a huge step forward for productivity and simplicity.
Working with proxies introduces the problem of lazy loading during serialization. This problem deserves a brief discussion.
Beware Lazy Loading When Serializing
The Customer entity doesn’t have any navigation properties. Order is the opposite, because it references the customer and the details.
Suppose you want to write a method that returns just the order without details and customer. When WCF serializes the order, it uses all public properties, or those marked with the DataMember attribute. If the Order instance is a proxy, the access to its navigation properties causes them to be lazy-loaded and then serialized to be sent to the client. Depending on how you write the code, two things can happen.
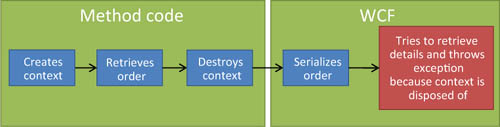
One option is to instantiate the context in a using statement. When the WCF serializer accesses the properties, the context is gone. This causes the access to navigation properties by the serializer to throw an exception, because the lazy-loading code needs the context. Figure 16.4 shows this flow.
Figure 16.4. The flow when the context is disposed of and a proxied entity is later serialized. Accessing the navigation properties (OrderDetail) causes the navigation properties to be lazy loaded and a serialization exception to be thrown because the context is disposed of.
The second option is to not use the using statement. When the WCF serializer accesses the properties, the context is still there because it’s referenced by the proxied entity, and the properties are lazy-loaded. For instance, when the OrderDetails property is accessed, details are dynamically loaded and added to the message sent to the client. Because the details are proxy instances, the access to the Product property causes it to be, once again, lazy loaded and added to the message. Finally, because Product has a reference to the suppliers, they’re loaded too.
The result in this case is that a method that should return an order returns an enormous quantity of useless and unwanted data. Depending on how many associations are in the model, the entire database could be sent to the client (or you’ll receive a WCF exception due to message size). What’s even worse than sending a huge and useless message to the client is for the database to be flooded by lots of queries generated by the lazy-loading feature. Figure 16.5 shows this nightmare!
Figure 16.5. When lazy loading is active, serialization can generate lots of unwanted queries to the database, which may lead to an entire graph being loaded.

There are two ways to solve these problems:
- Disable proxy creation (and use Include if you need to eager load some properties).
- Disable lazy loading before sending data to the client.
Both options work, so which you choose must be evaluated on a case-by-case basis.
You’ve learned in this section that there are some tricks to developing a service using Entity Framework–generated entities. Let’s see how to overcome these potential problems using the DTO approach.
16.3. Developing a service using DTOs
A DTO is a standalone class used only for communication purposes. By creating a DTO, you can easily control what data is sent to the client. In fact, customizing entities to add serialization attributes can be a real pain due to the complexity of modifying the EDM and template (unless you generate the model once, modify it manually, and never regenerate it ... but that’s an extremely improbable scenario).
Creating a DTO for the Customer class is just a matter of creating a class containing the properties you need to expose to the client. You can create and maintain such a class manually, but nothing prevents you from using custom annotations in the EDM and a template to generate the class. The DTO class is simple, as you see in this listing.
Listing 16.6. The DTO class for the customer
C#
public class CustomerDTO
{
public int CompanyId { get; set; }
public string Name { get; set; }
public AddressInfo ShippingAddress { get; set; }
public AddressInfo BillingAddress { get; set; }
public Byte[] Version { get; set; }
}
VB
Public Class CustomerDTO Public Property CompanyId() As Integer Public Property Name() As String Public Property ShippingAddress() As AddressInfo Public Property BillingAddress() As AddressInfo Public Property Version() As Byte() End Class
Let’s leave the Read and Update methods working with the full entities and create two new methods: ReadDTO and UpdateDTO. These methods won’t work with Customer but with CustomerDTO. Adding methods to the service interface is trivial, so we’ll move directly to their implementation. Here’s the ReadDTO method.
Listing 16.7. The ReadDTO method using DTO

The ReadDTO implementation is trivial because you can create a CustomerDTO instance directly in the LINQ to Entities query ![]() and return it.
and return it.
The UpdateDTO implementation consists of more code, but it’s still pretty simple.
Listing 16.8. The UpdateDTO method using DTO


You don’t have a Customer entity, so you need to create one using DTO properties. Because you don’t have all of the Customer entity’s properties, the best solution is creating a Customer stub (an entity where only key properties are set), setting its CompanyId and Version properties ![]() , attaching it to the context
, attaching it to the context ![]() , and then setting other properties using DTO properties
, and then setting other properties using DTO properties ![]() . This way, the context will persist only properties modified after the entity was attached to the context and won’t care
if other properties (such as username and password) are empty or null; it won’t persist them.
. This way, the context will persist only properties modified after the entity was attached to the context and won’t care
if other properties (such as username and password) are empty or null; it won’t persist them.
Note
Unlike CompanyId, the Version property isn’t necessary for the attaching process. The reason it’s set before attaching in listing 16.8 is that we care about concurrency. To perform the concurrency check, Entity Framework uses the value in the OriginalValues property of the entry. If you didn’t set the Version property before attaching the entity, the entry’s original value would be null because the original values are set with the value of the properties when the entity is attached to the context. In that case, the persistence would fail, raising an Optimistic-ConcurrencyException.
Even with DTOs, updating a single entity isn’t complex. Let’s look at what it takes to use DTOs to maintain the order graph.
16.3.1. Persisting a complex graph
Assume that you’ve created the DTOs for both order and details. After the client updates the data and sends it back, you can use the code from the previous section to modify the order.
To determine which details have been added, deleted, and modified, you can go to the database (arguably a best practice) and perform a comparison, or use the logic contract (arguably a worst practice).
If you choose the first option, there’s a caveat you have to know about. Because the OrderDetailDTO and the OrderDetail classes are different, you can’t use the Intersect and Except LINQ methods, as we discussed in chapter 7, because they work on classes of the same type. The workaround is to compare only the IDs of the objects, instead of comparing the objects, as you did in chapter 7. This is shown in the following listing (where order is the DTO instance and dbOrder is the order from the database).
Listing 16.9. Detecting added, deleted, and modified details in an order
C#
var added = order.OrderDetails.Where(d => !dbOrder.OrderDetails.Any(od => od.OrderDetailId == o.OrderDetailId)); var deleted = dbOrder.OrderDetails.Where(d => !order.OrderDetails.Any(od => od.OrderDetailId == o.OrderDetailId)); var modified = order.OrderDetails.Where(d => dbOrder.OrderDetails.Any(od => od.OrderDetailId == o.OrderDetailId));
VB
Dim added = order.OrderDetails.Where(Function(d) _
Not dbOrder.OrderDetails.Any(Function(od) _
od.OrderDetailId = o.OrderDetailId))
Dim deleted = dbOrder.OrderDetails.Where(Function(d) _
Not order.OrderDetails.Any(Function(od) _
od.OrderDetailId = o.OrderDetailId))
Dim modified = order.OrderDetails.Where(Function(d) _
dbOrder.OrderDetails.Any(Function(od) _
od.OrderDetailId = o.OrderDetailId))
When you know what’s changed, the hardest part is done and you can persist entities easily. Added details are added to the details collection of the dbOrder variable, deleted ones are removed through a call to the DeleteObject method of the details entity set, and updated ones are modified by setting their properties to the DTO settings. Easy, isn’t it?
If you compare development using DTOs with development using Entity Framework–generated entities, you’ll find that DTOs don’t increase complexity, they guarantee optimal performance, and they decouple your entities from the service interface. These are all great reasons to adopt DTOs.
So far, the client has received an object (the client doesn’t know whether it’s an entity or a DTO), modified it, and sent it back to the service. Let’s now investigate another scenario where the client and server exchange both information about the entity and information about what entity’s properties have been modified on the client, so the service can update the database easily. Objects that contain both data and information about what’s changed on the client are called STEs.
16.4. Developing a service using STEs
So far, we’ve followed a pattern where the client invokes a method on the service to obtain entities. The client modifies these entities and sends them back to the service. These entities contain data and nothing else.
If they contained information about what’s changed on the client (change-tracking information), it would be much easier for the service to update the database. It would even be better if these entities themselves contained the behavior to detect and store changes made on the client. Self-tracking entities (STEs) contain all these features: entity data and internal change-tracking behavior.
By having an inner change-tracking manager, the entity can set its actual state as Modified when a property is modified, so the server doesn’t need to discover what’s been changed. The same way, when a linked entity is removed or added (think about details in an order), the entity keeps track of the change. When the entity is sent back to the service, the context reads the tracking information in the entity’s change-tracker component and immediately knows what to do without your having to write code to detect changes on your own.
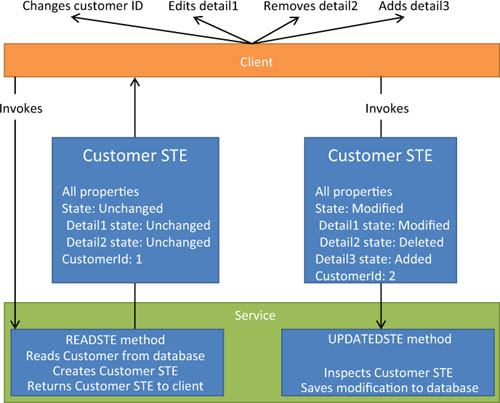
Figure 16.6 shows the entire workflow of an entity sent from the server to the client, which modifies it and then sends it back to the server.
Figure 16.6. The client reads the STE, modifies it, and then sends it back. During the process, the STE keeps track of the changes.
As you may expect, STEs are generated through template. The template that generates STEs, in addition to creating the entities and their properties adds the inner change-tracking code to the entities. The template that generates the context code creates an ObjectContext extension method that accepts an STE, reads change-tracking information from it, and then sets the state manager so that it reflects the entity changes.
Naturally, tracking information must be part of the entity, and this entity structure is described in the WSDL. But the WSDL doesn’t describe behavior. How does the client know how to populate the change-tracking information? The answer is the logic contract.
An STE exposes a structure containing entity data and change-tracking data. It’s up to the client to correctly populate the latter. As we’ve said, exposing such business logic to the client isn’t optimal, but STEs introduce so many benefits that in some cases we can make exceptions.
We say “some cases” because STEs aren’t always the best option. We’ll discuss this more at the end of this section. First, let’s create a service using STEs.
16.4.1. Enabling STEs
The first step in adding STEs to a project is creating them. Entity Framework ships with a template for generate this type of entity:
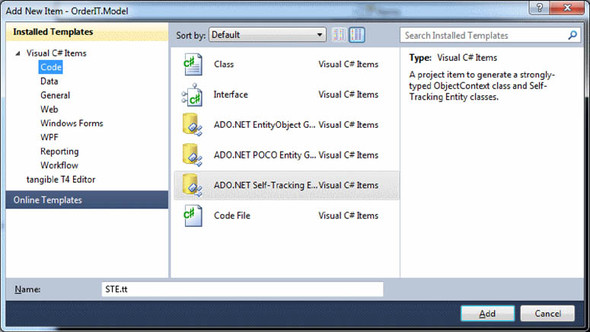
- In OrderIT.Model, add a STE folder named STE.
- Inside the folder, add a new template of type ADO.NET Self-Tracking Entities Generator and name it STE, as shown in figure 16.7. Two templates are added to the solution: one for the context (STE.Context.tt) and one for the entities (STE.tt).
Figure 16.7. Adding STEs to the project
- Open the context template, and set the inputFile variable to the path of the EDMX file (../model.edmx).
- Create a new assembly, name it OrderIT.Model.STE, cut the entities template file, and paste it inside this new assembly.
- Open the entities template, and set the inputFile variable to the relative path of the EDMX (../OrderIT.Model/model.edmx).
- In the OrderIT.Model assembly, add a reference to the OrderIT.Model.STE assembly.
Now you have an assembly with all the entities and the context in OrderIT.Model. This is the best configuration, as you’ll discover later.
Next, let’s investigate how the STE template generates the entities and the context.
16.4.2. Inside an STE
An STE is a POCO entity that has properties plus some infrastructure code that manages serialization and adds change-tracking capabilities to the entity itself. The infrastructure code that manages serialization is made of the DataContract, DataCollection, and DataMember attributes, which decorate the entity and its properties to be serialized. The change-tracking infrastructure code in the entity consists of the IObjectChangeTracker interface and its implementation in the entity. This interface is vital for change tracking.
Understanding the Entity Change Tracker
The IObjectChangeTracker interface declares the ChangeTracker property, which is of type ObjectChangeTracker. As you may guess from the name, the ObjectChange-Tracker class is responsible for entity’s change-tracking behavior. You can consider the ObjectChangeTracker to be equivalent to the ObjectStateManager class, but limited to one entity.
The ObjectChangeTracker (change tracker from now on) is particularly complex. It has the following properties:
- ChangeTrackingEnabled—Specifies whether the change tracking is enabled or not, with a Boolean value
- ObjectState—Specifies the state of the entity
- ObjectsRemovedFromCollectionProperties—Contains objects removed from a collection navigation property (for instance, details removed from an order)
- OriginalValues—Contains the original values for properties that were changed
- ExtendedProperties—Contains extended properties needed for Entity Framework internals (for instance, if you use independent associations, it contains the keys of the referenced entities)
Each of these properties is related to a key feature of the change tracker. Change-TrackingEnabled is true by default, and it’s mostly there because the change tracker needs to set it appropriately during the entity’s serialization and deserialization phase. You’ll probably never need to turn it off, but doing so will pose no problem other than the fact that modifications won’t be tracked.
ObjectState is important because when the entity is sent back to the server, it’s attached to the context, which analyzes the entity and sets its state to the value specified by the ObjectState property. By default, an STE is in Added state, not Unchanged.
ObjectsRemovedFromCollectionProperties is one of the most important properties. When you use DTOs or entities to exchange data between the server and the client, and an object from a collection navigation property is removed (for instance, a detail is removed from an order) that object is removed from the collection and it isn’t sent to the service. The consequence is that on the service you have to perform a comparison between the database’s and the entity’s data to determine which details have been removed.
When you use STEs, if an object is removed from a collection navigation property, it’s moved into the ObjectsRemovedFromCollectionProperties property. When the entity is sent back to the server, you don’t need to perform a comparison with the database to discover which objects have been removed from the collection navigation property because these objects are in the ObjectsRemovedFromCollectionProperties property of the STE’s change tracker. The context on the server sets all objects in the ObjectsRemovedFromCollectionProperties property to Deleted state.
OriginalValues maintains the original values of properties that are required for concurrency management. In the case of the Customer entity, it contains the original value of the Version property. This way, concurrency management is handled without you having to do anything.
ExtendedProperties is a repository for properties needed by Entity Framework, and you never have to deal with it.
How the Change Tracker Detects Entity Modification
In addition to IObjectChangeTracker, an STE implements INotifyPropertyChanged. The change tracker subscribes to the PropertyChanged event that’s raised by the setter of entity properties. In the handler of the event, the change tracker sets the entity state to Modified (if it’s not already in Added or Deleted state) and registers the original value of the property if it’s used for concurrency or is part of the key.
Collection properties are of type TrackableCollection<T>, which inherits from ObservableCollection<T>. This collection exposes the CollectionChanged event, which is raised when an item is added or removed. The change tracker subscribes to this event so it knows when an object is removed from the collection and can store the object in the ObjectsRemovedFromCollectionProperties internal property.
Managing Entity State
STEs also offer some interesting methods. The most important methods are the MarkAs* methods (where the asterisk stands for a state), which allow you to manually modify the internal state of an entity.
- MarkAsAdded—Marks an entity as Added
- MarkAsUnchanged—Marks an entity as Unchanged
- MarkAsModified—Marks an entity as Modified
- MarkAsDeleted—Marks an entity as Deleted
The StartTracking and StopTracking methods allow you to enable and disable change tracking, respectively. They do this by setting the ChangeTrackingEnabled property of the change tracker.
Finally, the AcceptChanges method accepts all modifications and sets the state of the entity to Unchanged. You can think of it as a sort of commit for modifications.
That covers how an STE tracks its modifications, keeps its internal state, and lets you manually modify it. The next thing you need to know is how the context is generated and how it reads the STEs internal state.
16.4.3. Inside the context
The context generated by the STE template isn’t any different from the one generated by the POCO template, except for one thing: in the constructor, the proxy creation is disabled so that plain entities are returned. The STE template also generates another class that contains an extension method to the ObjectContext class.
The extension method is ApplyChanges<T>, and it’s responsible for accepting an STE, attaching it to the context, analyzing its properties, and reflecting the changes stored in the entity change tracker to the context state manager. After the Apply-Changes<T> invocation, the state of the entry in the context-state manager will be the same as that of the entity in its change tracker.
What’s more, if the entity attached has navigation properties that contain other entities, those entities are attached to the context too, and their state is poured into the state manager. This way, in a single method call, you’ve prepared a whole graph for persistence. Sounds cool, doesn’t it?
Now let’s write some code.
16.4.4. Using STEs
When the client generates classes from the WSDL, it knows it has to populate data in the change-tracking properties, but it doesn’t know how to do that. You could write this code manually, but that’s a pain.
Fortunately, because the STE template generates classes with both data and behavior, you can reference the assembly with STE from both server and client. This is why you created a separated assembly for the STE earlier. This way, when Visual Studio generates the classes from the WSDL, it doesn’t create entities but just WCF classes for communicating with the service, because the entities are already referenced.
Note
As you can imagine, there are several problems arising from this configuration. We’ll talk about the problems and solutions shortly.
On the service, let’s add two new methods that use the Customer STE: ReadSTE and UpdateSTE. Implementing the interface to add these methods is extremely simple. You don’t even need to apply the serialization behavior required to serialize a proxy, because the STE context disables proxied-class generation. Let’s skip the interface code and move on to the method implementation.
The ReadSTE method is pretty simple. You instantiate the context and return data for the logged-in customer.
Listing 16.10. The ReadSTE method implementation
C#
public Customer ReadSTE()
{
using (var ctx = new OrderITEntities())
{
return ctx.Companies
.OfType<Customer>()
.FirstOrDefault(c => c.CompanyId == _customerId);
}
}
VB
Public Function ReadSTE() As Customer
Using ctx = New OrderITEntities()
Return ctx.Companies.
OfType(Of Customer)().
FirstOrDefault(Function(c) c.CompanyId = _customerId)
End Using
End Function
This code is straightforward, but ... wait: the Customer entity contains web service–related data that you don’t want sent over the wire. Because the Customer STE is shared between the client and the service, you can modify the entity, removing the DataMember attribute from the properties (as discussed in section 16.2.2) or blanking them before returning the entity (see section 16.2). So far, there’s nothing new.
What’s different is the UpdateSTE method. In this method, you can create the context, call the ApplyChanges<T> method to copy the entity’s change tracker information to the context state manager, and call the SaveChanges method.
Listing 16.11. The UpdateSTE method implementation
C#
public void UpdateSTE(Customer customer)
{
using (var ctx = new OrderITEntities())
{
ctx.Companies.ApplyChanges(customer);
ctx.SaveChanges();
}
}
VB
Public Sub UpdateSTE(ByVal customer As Customer)
Using ctx = New OrderITEntities()
ctx.Companies.ApplyChanges(customer)
ctx.SaveChanges()
End Using
End Sub
The internal state of the Customer STE is Modified. The ApplyChanges<T> method attaches the entity to the context, reads the state, and invokes the ChangeState method to synchronize the state in the state manager. You learned in chapter 6 that when you use the ChangeState or ChangeObjectState method, all properties are marked as Modified, so the UPDATE statement will update all the properties.
This is what you have to avoid, because you don’t want the customer to be able to change the web service information. The solution is awkward because after Apply-Changes<T>, you should mark the entity as Unchanged and then mark the single properties as Modified, as in listing 16.3. In this case, STE fails to be useful.
Let’s now look at a case where STEs show their full power: persisting complex graphs.
Updating a Complex Graph with Stes
So far, you’ve used a single entity. You may think that updating an order may be different, but it’s not, because the ApplyChanges<T> method scans navigation properties too. Thanks to the properties of the ObjectTracker class, having a single entity or an object graph makes no difference.
An UpdateOrderSTE method would look like this:
C#
ctx.Orders.ApplyChanges(order); ctx.SaveChanges();
VB
ctx.Orders.ApplyChanges(order) ctx.SaveChanges()
If the order contains details, they’re attached to the context too. Added, removed, and modified details are stored in the Order entity change-tracker. When Apply-Changes<T> is invoked, the state of each detail is poured into the context state manager so you don’t have to do anything. The logic contract between the client and the server is handled by STE change tracker and the ApplyChanges<T> method.
Having the logic contract handled automatically, and having a single API to manage everything, is a strong point for STEs. Unfortunately, they’re useful only in scenarios where the client can change all the entity’s properties. In scenarios where only some properties can be updated, STEs are more likely to complicate your life than ease it.
Adding or Deleting an Entity Using Stes
STEs show their enormous power when updating an entity or a complex graph. In other scenarios they’re valid, but not that powerful.
When you need to add an entity, you don’t have either concurrency problems or need to compare with data in the database. There’s not even any need to resort to ApplyChanges<T>, although it works perfectly well, because you can directly invoke AddObject.
Deleting an entity is even simpler, because only the ID and the concurrency token (if used) are required. You can pass these properties to the service method, create a stub inside it with just these properties, attach the stub to the context, and invoke DeleteObject.
Many-to-Many Relationships and Stes
Suppose you have to develop a method that updates a product and its associated suppliers. This method will accept the Product STE, which contains the Suppliers property listing the suppliers.
Suppose that on the client side, you have to associate a new supplier to a product. If you create a Supplier instance, add it to the Suppliers property of the Product instance, and send the product back to the service, you’d expect the association to be created. But it doesn’t work like that. Previously we mentioned that an STE is, by default, in Added state. On the service, after the call to ApplyChanges<T>, the Supplier entry is marked as Added, so when SaveChanges is invoked, Entity Framework tries to create a new row for the supplier in the Company table of the database. This causes an exception to be raised, because the properties required to persist the supplier aren’t set. This problem can be solved both on the client and on the service.
On the client side, you can invoke the Supplier entity’s MarkAsUnchanged method. This way, the entity state becomes Unchanged, and when ApplyChanges<T> is invoked, the entry in the context will become Unchanged as well.
The problem with this approach is that it requires some code on the client, meaning that if a client doesn’t follow this path, exceptions are raised on the server. It’s much better to solve the problem in the service to cut down on the possibility of errors.
On the service, there are two ways of solving the problem. The first one, shown in the next snippet, is to invoke the MarkAsUnchanged method on all entities in the Suppliers property before calling ApplyChanges<T>:
C#
product.Suppliers.ForEach(s => s.MarkAsUnchanged); ctx.ApplyChanges(product);
VB
product.Suppliers.ForEach(s => s.MarkAsUnchanged) ctx.ApplyChanges(product)
The second approach is to call ApplyChanges<T>, retrieve all Added entities of type Supplier in the state manager, and invoke ChangeObjectState to set their states to Unchanged. The following code demonstrates this technique:
C#
ctx.ApplyChanges(product); ctx.ObjectStateManager .GetObjectStateEntries(EntityState.Added) .Where(e => e.Entity is Supplier) .ForEach(s => s.ChangeState(EntityState.Unchanged);
VB
ctx.ApplyChanges(product) ctx.ObjectStateManager. GetObjectStateEntries(EntityState.Added). Where(Function(e) TypeOf e.Entity Is Supplier). ForEach(Function(s) s.ChangeState(EntityState.Unchanged))
That’s all you need to do. We have demonstrated this process on many-to-many relationships because it fits in perfectly with OrderIT, but the same technique can be applied to other types of relationships.
Internal State and Context State
There’s a caveat that’s worth mentioning. If you have an STE attached to the context, modifying it (by changing a property or invoking a MarkAs* method) will cause the STE change tracker to change the entity state, but it won’t have any effect on the context state manager until the DetectChanges method is invoked. This happens because the context generated by the STE template disables proxy creation, so the instances created queries are plain entities, which, as you learned in chapter 6, aren’t connected to the context.
Now that you know how to use STEs, it’s time to talk a bit about their pros and cons.
16.4.5. STE pros and cons
The code that tracks changes within STEs isn’t simple. That’s why the Entity Framework team added the STE template, which reads data from the EDMX file and generates the STE.
If you’re the client developer, you can freely use the STE assembly. If the clients can be developed by any consumer, you can distribute the STE assembly to those who develop on .NET 4.0 and beyond. If the clients can be heterogeneous (such as Java or PHP), client developers are responsible for creating their entities and for creating the change-tracking behavior to ensure that the contract with the service is honored (guaranteeing that the state is correct, that entities removed from collection properties are stored in the change tracker, and so on). As we’ve said before, creating change-tracking behavior in entities isn’t easy, so non-.NET clients are pretty hard to create; that’s a big obstacle.
Another con of STEs is that they expose the full entity to the clients. As we’ve mentioned in this chapter, that’s bad because often you don’t want to send all of an entity’s properties to the client.
We already hinted that when an STE is in Modified state, the ApplyChanges<T> method uses the ObjectStateManager class’s ChangeObjectState method to set the entity state to Modified in the context state manager. You know that when the ChangeObjectState method is used to set an entity’s state to Modified, all the entity’s properties are marked as Modified, so all of them will be persisted on the database. In cases where only some properties must be updated, this is an inconvenience because allowing only some properties to be updated requires manually reworking the entry in the state manager.
It’s clear that STEs are the answer only in cases where full entities can be sent over the wire without any problems. In such cases, STEs greatly simplify development, and you should always use them. In all other cases, we strongly recommend using DTOs.
16.5. Summary
Developing a service is challenging. The disconnected nature of services makes it impossible to track changes made to entities on the client side. This requires you to write code on the service side to detect what’s been changed on the client. To further complicate the scenario, not all entities’ properties should be sent to the clients.
Using the entities generated by the POCO template is a viable solution, but it results in full entities going back and forth. That’s good in some cases but not optimal in others. If some properties shouldn’t be sent over the wire, using WCF attributes may optimize things, but you have a better solution.
In such cases, the best way to go is to use a DTO so you achieve full control over the data that’s sent over the wire, and you ensure complete decoupling between the service and the entities used for persistence.
Eventually, in scenarios where you have full control over the clients, you can use STEs so that changes made on the client side are stored inside the entities and made available to the service when they’re sent back.
Now you’re ready for the next subject: integrating Entity Framework in Windows Forms and WPF applications.