
Chapter 8. Handling concurrency and transactions
- Understanding the concurrency problem
- Configuring concurrency
- Managing concurrency exceptions
- Managing transactions
Suppose you want to book a flight online. You search for the flight you want and find an available seat, but when you click the reservation button, the system says the flight is fully booked. If you search for the flight again, it isn’t shown.
What happened is that at the moment when you searched for the flight, a seat was available; but in the time between the search response and the booking attempt, someone else booked the last seat. There were concurrent searches for the last seat, and the first person to book it won. If the booking application hadn’t checked for concurrency, the flight would have been overbooked.
When you book a flight, you register on the carrier’s website, and your information is stored so it can be retrieved and updated anytime you want. This kind of data is rarely updated and is only modified by you or a carrier’s employee. Contention in this context is so low that you can easily live without concurrency checks.
These examples demonstrate why and when concurrency management is essential for a serious application. This chapter will dig deep into this subject, because it’s a simple Entity Framework feature to use, but it’s easy to misunderstand.
The second subject covered in this chapter is transaction management. In the previous chapter, we looked at manually updating product-availability data before and after SaveChanges. These updates were not executed in the same transaction as the commands issued by the SaveChanges method, which would cause data inconsistency if exceptions occurred during persistence. The commands issued manually and the commands generated by SaveChanges must be executed in the same transaction.
Similarly data must often be updated on more than one database or sent to outside systems, like Microsoft Message Queuing (MSMQ), and everything must be transactional. Thanks to the classes in the System.Transaction namespace, it’s easy to manage these scenarios. If you have never used these classes, you’ll enjoy seeing them in action.
It’s time to cover concurrency. The example of booking a flight gave a good picture of what concurrency is all about, so now we’ll look at how the concurrency problem fits into OrderIT.
8.1. Understanding the concurrency problem
The user’s business is growing every day, and the company now needs employees to register and manage incoming orders. This means that two or more people will be working on the application at the same time, accessing and sometimes modifying the same data. OrderIT needs to coordinate updates to avoid having two employees working on the same order at the same time and overriding each other’s data.
8.1.1. The concurrent updates scenario
Consider this scenario: a big customer has different departments that place orders. Department 1 calls employee 1 to place an order. A few hours later, department 1 calls employee 1 again to update the order. At the same time, department 2 calls employee 2 to update the same order, adding some products. If you think about the code in the previous chapter, you can probably imagine where this is headed.
The two employees retrieve the order. Employee 1 modifies some details, adds a couple more, and saves the order. Employee 2 removes a detail and saves the order a minute later. What happens is that employee 1 saves data and employee 2 overrides it with other data. The two employees will never be aware of this problem, and an incorrect shipment will be delivered to the customer.
There’s a worse scenario. If department 2 called to delete the order instead of modifying it, the customer would lose the entire order. Figure 8.1 illustrates potential problems arising from not managing concurrency during persistence.
Figure 8.1. A typical concurrency scenario. Both users read the same data, employee 1 saves the records first, and employee 2 overrides them later. New detail 3 and the modifications to detail 2 are lost.

Technically speaking, there could be contention on every editable entity in the application. It’s always possible for two users to work contemporarily and unknowingly on the same data. But in the real world, very little data is subject to contention, and often it’s not important enough to deserve a concurrency check.
For instance, order data is vital and must always be checked. Customer and supplier data is surely important, but not as important as orders. What’s more, customers and suppliers are less frequently updated, reducing the risks a lot. As a result, it’s probably not worth handling concurrency checks for them. The same considerations apply to products; after they’re added to the database, they’re rarely changed except for their prices (which is something you won’t change often) and their quantity in stock (which is handled manually, as you saw in chapter 7).
Now that the problem is clear, let’s look at the possible solutions. The first adopts a pessimistic approach, locking the database rows until they’re updated. This approach has pros and cons, as you’ll see in the next section.
8.1.2. A first solution: pessimistic concurrency control
When you need to update data and want to be sure that nobody else can do so at the same time, the safest way to go is exclusively physically locking the data on the database. When data is locked, other users can’t access it either to read or update it. This way, nobody else can change the data until it’s updated or unlocked. This approach is named pessimistic, and it’s illustrated in figure 8.2.
Figure 8.2. In pessimistic concurrency, employee 1 reads the data, and it can’t be read by employee 2 until it’s saved by employee 1.
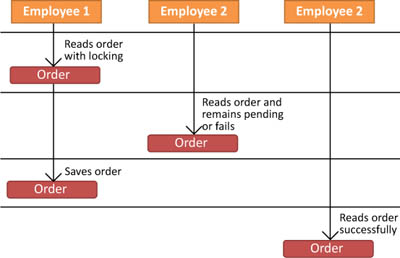
What’s good about pessimistic concurrency control is that it grants a single user exclusive access to the information, eliminating any possibility of contentions. What’s bad is that exclusive locking produces many complications from a performance and usability point of view.
Locking the row exclusively makes it impossible for other users to read information. That means even if another user wants to see the order, they can’t. If the user who holds the lock works on the order for a long time, they slow down other people’s productivity. What’s worse, if the application crashes (and don’t say it shouldn’t happen; it does), the lock remains there until it expires or a DBA manually removes it.
Note
A less aggressive policy might allow other users to read data but not to modify it.
Pessimistic concurrency is a good technique, but its cons often outweigh its pros. Unless you’re obliged to use it, other approaches are preferable.
The basic idea behind pessimistic concurrency is that because there might be data contention, the data is locked by the first reader. Another technique that solves concurrency problems starts with an opposite approach: because data contention isn’t frequent, it’s pointless to lock data. The check for contention is performed only during the update phase.
8.1.3. A better solution: optimistic concurrency control
How often will multiple users work simultaneously on the same order or customer or whatever else? If this happens, is it a problem for the first person who updates the data to win, and for the others to have to reapply their modifications? Usually the answers to these questions are “almost never” and “no,” respectively.
Locking in this sort of situation would be only a waste of resources, because there is low, or no, contention. A softer approach can be taken. You can allow all users to read and even change data, but when you update the database, you must check that nothing in the record has been changed since data retrieval. This is the optimistic approach.
The easiest way to do this is to add a version column that changes on every row modification. In the case of concurrent modifications, the first to save the data wins; the others can’t update the data because the version has changed since they read it. Figure 8.3 illustrates this concept.
Figure 8.3. With optimistic concurrency, employee 1 and employee 2 read order version 1. Employee 1 saves the order, which is updated to version 2. Employee 2 saves order version 1 and gets an exception.

Checking the version column is as easy as including the value initially read from the database in the SQL WHERE clause, along with the ID of the order. This means the real key of the row is the primary-key columns plus the version column, as shown here:
UPDATE [order] SET ..., version = 2 WHERE OrderId = 1 AND version = 1
If the query updates the row, you know that the version hadn’t changed since the order was read. If the query doesn’t update any rows, that’s because the version number had changed, and there was a concurrency problem. In figure 8.3, the same UPDATE is issued by two employees: employee 1 wins, and employee 2 gets the exception because the version had changed.
When using optimistic concurrency, we recommend you use an autogenerated column for the row version (TimeStamp or RowVersion for SQL Server) so you don’t have to manage its value manually.
Note
Sometimes you can’t change the table structure to add a version column, such as when you have a legacy database. In this case, you can use some or all of the columns to perform a concurrency check. Those you choose for the concurrency check will end up in the WHERE clause.
By not using locks, optimistic concurrency improves system scalability and usability because the data is always available for reading. This improvement comes at the cost of managing versioning in the code, but that’s not a heavy burden, as you’ll discover later. The main drawback is that unless you write some sophisticated code, the users who get the concurrency exceptions will have to read the updated data and then reapply their modifications. It’s a waste of time that is usually affordable, but sometimes it isn’t.
8.1.4. The halfway solution: pessimistic/optimistic concurrency control
This last technique takes the pros of the previous approaches. It doesn’t allow concurrent modifications to an order, nor does it physically lock the row on the database.
The way it works is pretty simple. First you add version and flag columns to the table. Then, when a user edits the data, the user’s application issues a command to the database to set the flag column to true. If two users do this simultaneously, the first wins. After that, anyone can read the data, but nobody can modify it because the client checks the flag and denies any modifications until it’s set back to false. This is the pessimistic/optimistic approach.
This technique minimizes contention over the data, but it suffers from the same limitations as pessimistic concurrency control. If the application crashes, the lock must be removed manually. If the user who’s editing the order goes to get coffee or to a meeting without saving or canceling the modifications, other users are prevented from making modifications. You can create a demon that kills locks held for longer than a certain amount of time, but that increases the complexity needed do to manage concurrency.
This last technique isn’t a perfect solution; it’s another string in your bow. Broadly speaking, optimistic concurrency is the best choice in most scenarios. If it doesn’t fit your needs, try the pessimistic/optimistic approach; and only if that isn’t appropriate should you move on to pessimistic concurrency.
Now that you have a clear understanding of the concurrency problem, it’s time to look at how you can take care of it from a database point of view. It’s time to see how Entity Framework can help in managing concurrency.
8.2. Handling concurrency in Entity Framework
Entity Framework makes concurrency management easy. It handles most of the plumbing, leaving you only the burden of managing configuration and handling exceptions when they occur.
The first thing you need to know is that Entity Framework doesn’t support pessimistic concurrency control. That’s by design, and the development team doesn’t intend to add this feature in the future. That gives you an idea of how little pessimistic concurrency is used in the real world.
By design, only optimistic concurrency is supported. The pessimistic/optimistic approach is an artifact that can be re-created in a few lines of code.
8.2.1. Enabling optimistic concurrency checking
It’s time to enable optimistic concurrency in OrderIT. To do so, you need to follow these steps:
1. Add a version column to the Order, Company, and Product tables. Name the column Version, and set its type as TimeStamp (RowVersion if you SQL Server 2008 or higher).
2. Right-click the designer, and choose Update Model from Database. The designer opens a dialog box displaying the last form of the wizard, which lets you generate the model from the database (we discussed the wizard in chapter 2). Click the OK button.
3. The designer updates the Order, Company, and Product entities, adding a Version property and mapping it to the new Version column in the mapped tables. Because the TimeStamp/Row-Version type is managed by SQL Server, the columns in the SSDL and the property in the CSDL are automatically marked as Computed.
4. Right-click the Version property in the Company entity, and select Properties.
5. In the Properties window, change the Concurrency Mode to Fixed, as shown in figure 8.4.
Figure 8.4. Enabling concurrency checking for a property in the designer
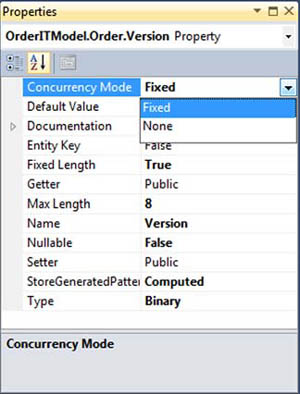
6. Repeat steps 4 and 5 for the Order and Product entities.
In terms of EDM, step 5 sets the Concurrency-Mode attribute of the Version property to Fixed, as shown here:
<Entity Type="Company" Abstract="True">
...
<Property Name="Binary" Type="timestamp" Nullable="false"
a:StoreGeneratedPattern="Computed" ConcurrencyMode="Fixed" />
</Entity>
That’s it. When you’re done, the Version property will automatically be appended in the WHERE clause of the UPDATE and DELETE SQL commands.
It’s important to note that the value used in the WHERE clause isn’t the one from the entity but the one from the original value of the entry in the state manager. If you attach the entity to the context, and the Version property is 1, that value will be used in the query even if you set the property’s value to 2 (which you should never do intentionally, but could be done by a bug). This makes sense because for concurrency you have to use the original value from the database and not a new one.
Now that the configuration is finished, it’s time to move on to the code. Although Entity Framework manages all the plumbing, you still need to write code to introduce concurrency management into the persistence process. More specifically, you have to manage the version column and handle the concurrency exception.
8.2.2. Optimistic concurrency in action
In the previous chapter, we looked at how to persist entities in different scenarios using different techniques:
- Connected scenario
- Disconnected scenario with the ChangeObjectState method
- Disconnected scenario with the ApplyCurrentValues method
- Connected and disconnected scenarios with graphs
Let’s analyze how concurrency affects these techniques.
Handling Concurrency in the Connected Scenario
The connected scenario is once again the easiest to code. It doesn’t require any modification because the original value of the Version property is in sync with the database. If you read the entity from the database and Version is 1, that value will be used in the WHERE clause, so there is nothing you have to do.
Handling Concurrency in the Disconnected Scenario with Changeobjectstate
In the disconnected scenario, you have an entity and you have to attach it to the context and persist it. As in the connected scenario, the code doesn’t change here. You must only make sure that the Version property has the same value as when the data was initially read.
For instance, suppose you have created a web form to display customer data. You read the Customer entity, display it, store its Version property in the ViewState, and then dispose of both the entity and the context. When the user saves the modifications, you create a new context and re-create the entity, populating properties with the form’s data. When you attach the re-created entity to the new context, the value of the properties is used by the context to populate the original value of the entry in the state manager. The result is that the value of the Version property at the moment it’s attached to the context is the value used in the WHERE clause.
If you set the value of the Version property to the value previously saved in ViewState after the entity is attached to the context, the original value of the Version property in the state manager entry is null because when the entity was attached, the Version property was null. The result is that the UPDATE command uses the NULL value in the WHERE clause, and the row isn’t updated; this causes a concurrency exception to be raised by Entity Framework.
If you serialize the entire Customer entity in ViewState or in the ASP.NET session, you don’t need to maintain the version. Because the object isn’t disposed of when the form is displayed, when the user saves data you can retrieve the object from ViewState or the ASP.NET session and update the object’s properties with the form values, leaving the version unmodified. When you attach the object to the context, the Version property is already set, so the original value in the entry is set too. When you persist the customer, the UPDATE command will place the correct value in the WHERE clause.
Handling Concurrency in the Disconnected Scenario with ApplyCurrentValues
When you use the ApplyCurrentValues method in the disconnected scenario, you query for the current data in the database and then apply your changes. This means the original values of the entry are those read by the database. When you call ApplyCurrentValues, the current values in the entry are modified but the original values (which are those read from the database) aren’t.
Here a big problem arises. When you invoke SaveChanges, the generated WHERE clause uses the original value of the Version property, which holds the current database value. The consequence is that the database’s current value is used in the WHERE clause, causing the data to be modified even if it has since been changed by someone else.
Let’s look at an example: employee 1 reads the customer with ID 1 and version 1 from the database. Later, employee 2 reads and updates the same customer (so that it’s now ID 1, version 2 in the database). Then employee 1 updates the customer and saves it with ID 1, version 1.
When employee 1 triggers persistence, you read the customer from the database (ID 1, version 2) and use ApplyCurrentValues to update the customer data with the input customer object containing the modified data. After the call to ApplyCurrentValues, the current values of the entry contain the modified data, but the original values are still those read from the database (ID 1, version 2). The result is that the UPDATE command generated during persistence will be the following:
UPDATE ... WHERE CompanyId = 1 and Version = 2
As you see, even if the version of the customer has been changed since employee 1 read it, the updates are applied because the version isn’t the original one read by employee 1 but the one last read from the database. The modifications made by employee 2 are lost.
Fortunately, there is a way to granularly change the original values of an entry. This allows you to modify the original value of the Version property, setting it to the one held by the entity (1 in the preceding example), ensuring that the WHERE clause is correct.
To accomplish this, you have to use the ObjectStateEntry’s GetUpdatable-OriginalValues method, which returns an OriginalValueRecord instance. This class has a set of SetXXX methods that allow you to modify the values inside OriginalValue-Record. The following snippet shows how you can use the SetValue method, which is the most generic one:
C#
var entry = ctx.ObjectStateManager.GetObjectStateEntry(dbEntity);
var origValues = entry.GetUpdatableOriginalValues();
origValues.SetValue(origValues.GetOrdinal("Version"), entity.Version);
VB
Dim entry = ctx.ObjectStateManager.GetObjectStateEntry(dbEntity)
Dim origValues = entry.GetUpdatableOriginalValues()
origValues.SetValue(origValues.GetOrdinal("Version"), entity.Version)
SetValue is a nontyped method. We used it because Version is imported as a Byte[] and there isn’t a SetByteArray (or similar) method. If you already know that you’re updating a string or integer or another simple type, you can use SetString, SetInt32, SetDateTime, SetBoolean, and so on.
When you have updated the original value of Version, you can safely invoke SaveChanges. The complete code is shown in the following listing.
Listing 8.1. Performing concurrency checks with ApplyCurrentValues
C#
private void UpdateCustomerWithApplyCurrentValues(Customer cust)
{
using (var ctx = new OrderITEntities())
{
var dbCust = ctx.Companies.OfType<Customer>()
.First(c => c.CompanyId == cust.CompanyId);
ctx.Companies.ApplyCurrentValues(cust);
var entry = ctx.ObjectStateManager.GetObjectStateEntry(dbCust);
var origValues = entry.GetUpdatableOriginalValues();
origValues.SetValue(origValues.GetOrdinal("Version"), cust.Version);
ctx.SaveChanges();
}
}
VB
Private Sub UpdateCustomerWithApplyCurrentValues(ByVal cust As Customer)
Using ctx = New OrderITEntities()
Dim dbCust = ctx.Companies.OfType(Of Customer)().
First(Function(c) c.CompanyId = cust.CompanyId)
ctx.Companies.ApplyCurrentValues(cust)
Dim entry = ctx.ObjectStateManager.GetObjectStateEntry(dbCust)
Dim origValues = entry.GetUpdatableOriginalValues()
origValues.SetValue(origValues.GetOrdinal("Version"), cust.Version)
ctx.SaveChanges()
End Using
End Sub
You have now seen that performing a concurrency check on an entity is mostly a matter of configuration. A little tweak in the code is required only in this particular scenario. But when graphs come into play, more changes must be made.
Handling Concurrency with Graphs in the Connected and Disconnected Scenarios
You know that order persistence involves a graph consisting of the order and its details. Technically speaking, we could put a Version property in both entities, but we’ve chosen to put it only on the order for this example. We made this choice because the details can’t exist without an order; even if you modify only one detail, the order version should be updated.
If yours is the only application working on the database, everything is fine. If other applications also work on the database, all have to respect the rule of updating the order when a detail is touched. If this didn’t happen, the concurrency checks would be inconsistent, and you should add a version property in the order details too. (We won’t take this route in this chapter.)
To update the order version even if only a detail is changed, you have to make sure the Order instance is in Modified state; otherwise, no update will be performed and no concurrency check will happen.
If you work in a connected scenario and don’t change any properties, or if you use ApplyCurrentValues and nothing was modified, the state of the entity remains Unchanged. Using ChangeObjectState to set the order to Modified ensures that everything is updated properly.
Optimistic Concurrency and Inheritance
When dealing with inheritance, there is an important rule to know: you can’t use a property of an inherited type for concurrency. For instance, you couldn’t use a property in the Customer or Supplier entity for concurrency checks; only properties in the Company entity can be used. If, to enable concurrency, you use properties from an inherited type, you’ll get a validation error from the designer or a runtime exception when instantiating the context. In OrderIT, this would also apply to the Product hierarchy.
Products are persisted using the TPT strategy (as discussed in chapter 2). When dealing with TPT, you may need to update only a property of an inherited entity (for example, Shirt or Shoe in OrderIT). When SaveChanges generates the SQL, it updates only the table containing the column mapped to the modified property. The table containing the versioning column isn’t touched, because there aren’t any modified properties that must be persisted to it. This way, the concurrency check isn’t performed.
To perform the concurrency check, Entity Framework performs a nice trick. Suppose a user modifies a shirt and changes only the size. Size is a column in the Shirt table, so its modification doesn’t affect the Product table, which contains the version column. When SaveChanges is called, Entity Framework issues a fake UPDATE command against the Product table to perform a concurrency check, as you can see in this listing.
Listing 8.2. Performing concurrency checks with TPT hierarchies

The first query executes the fake UPDATE on the Product table to see if the command would update a row ![]() . If the update affects 0 records, a concurrency exception is thrown. The SELECT
. If the update affects 0 records, a concurrency exception is thrown. The SELECT ![]() is executed only because Version property is marked as Computed, so its value is immediately retrieved from the database after any command. Finally, if no concurrency exception has been
raised, the UPDATE on the Shirt table is executed
is executed only because Version property is marked as Computed, so its value is immediately retrieved from the database after any command. Finally, if no concurrency exception has been
raised, the UPDATE on the Shirt table is executed ![]() .
.
You’ve now seen how to make Entity Framework generate the correct SQL to check for concurrency. What we haven’t done yet is handle the exception generated when you update stale data.
8.2.3. Catching concurrency exceptions
When an update doesn’t affect any rows, the context raises an OptimisticConcurrency-Exception exception, which inherits from UpdateException and doesn’t add any methods or properties. Its only purpose is letting you handle exceptions related to persistence and concurrency. Handling this exception is simple, as shown in this listing.
Listing 8.3. Intercepting concurrency exception
try
{
...
ctx.SaveChanges();
}
catch (OptimisticConcurrencyException ex)
{
Log.WriteError(ex.StateEntries, ex.InnerException);
}
catch (UpdateException ex)
{
//Some logic
}
VB
Try ... ctx.SaveChanges() Catch ex As OptimisticConcurrencyException Log.WriteError(ex.StateEntries, ex.InnerException) Catch ex As UpdateException //Some logic End Try
The catching logic is pretty simple. Just keep in mind that if you handle both concurrency and update exceptions, you have to catch the concurrency exception first. Because OptimisticConcurrencyException inherits from UpdateException, if you put the catch block with UpdateException first, the code in that block is executed and the other catch blocks are ignored even if the exception is of type OptimisticConcurrency-Exception.
Catching the exceptions is straightforward, but what should you do when you catch them? Logging the exception is pointless, because it isn’t caused by a bug in the code. Letting the system solve the problem is too risky. The right approach is to create instruments to let the user decide what to do.
8.2.4. Managing concurrency exceptions
Suppose that employee 1 and employee 2 are unknowingly modifying data about a customer at the same time. Employee 1 changes the web-service password and saves the data. Employee 2 changes the name, saves the data, and gets the exception. It would be great if employee 2 could see what’s been changed since the data was read and try to fix the problem, instead of reloading the form and modifying the data from scratch. In this example, employee 2 could reload the form and enter the new name again; in bigger forms with lots of information, this might be an unbearable waste of time.
Your best ally is the ObjectContext class’s Refresh method, which restores entry and entity values, depending on your choice, with data from the database. It accepts the entity to be refreshed and an enum specifying what data must be refreshed. The enum is of type System.Data.Objects.RefreshMode and has two possible values: ClientWins and StoreWins.
If you pass ClientWins, the method updates the original values of the entry in the state manager (the object context cache) with those from the data source. The current values and the entity remain untouched. Furthermore, all properties are marked as Modified even if they’re unchanged.
If you pass StoreWins, the original and current values of the entry and the entity are refreshed with data from the data source. Furthermore, the state is rolled back to Unchanged because the entity now reflects the database’s state. This means all the modifications made by the user are lost.
Getting back to the example, you can use the Refresh method and then use the current and original values of the entry to show the user how things have changed on the database since the data was last read. Users can review the changes and choose between the database version and their own entries.
Refreshing Values from the Database
Refreshing values from the database is fairly easy: you invoke Refresh and pass in the ClientWins value, as shown in the following listing. This way, the original values in the state manager entry reflect the server data, and the current values in the state manager entry reflect the data edited by the user.
Listing 8.4. Refreshing entities with values from the server
C#
try
{
ctx.SaveChanges();
}
catch (OptimisticConcurrencyException ex)
{
var errorEntry = ex.StateEntries.First();
ctx.Refresh(RefreshMode.ClientWins, errorEntry.Entity);
...
}
VB
Try ctx.SaveChanges() Catch ex As OptimisticConcurrencyException Dim errorEntry = ex.StateEntries.First() ctx.Refresh(RefreshMode.ClientWins, errorEntry.Entity) ... End Try
If you invoke SaveChanges after Refresh, the database is correctly updated with employee 2’s new name value, because all properties are marked as Modified. What’s bad about this is that employee 1’s password change is updated with employee 2’s value, which is the old one before employee 1’s modification. That’s why employee 2 must see the changes and confirm them.
Building the Comparison Form
There are many ways to show original and current values to the user. You can take a form-by-form approach or opt for a generic solution. We’ll take the generic approach here because it’s quicker.
At first, you might consider creating a form that displays a grid with the name and original and current values of each property. The problem with this implementation is that complex types can’t be represented in a row. We choose a tree view. It has check boxes that allow the user to specify which properties to save and which to ignore. Figure 8.5 shows such a form.
Figure 8.5. The tree view showing original and current values of the conflicting Customer entry. Employee 2 is changing the name from “Giulio Mostarda” to “Stefano Mostarda”. In the meantime, employee 1 has changed the password from “PWD1” to “password1”.

The form may seem complex at first, but it’s easy to understand when you get used to it.
Note
Including check boxes for properties of complex properties and for original and current value nodes is pointless. They’re included because we’re lazy and didn’t want to override the tree-view rendering.
Here’s the main code used to create the form in figure 8.5.
Listing 8.5. Showing entry values in a tree view display
C#
private void EntriesComparer_Load(object sender, EventArgs e)
{
var modifiedProperties = _entry.GetModifiedProperties();
for (int i=0;
i<_entry.OriginalValues.FieldCount; i++)
{
var isModified = modifiedProperties.Any(n => n ==
_entry.OriginalValues.GetName(i));
TreeNode node = new TreeNode(CreateNodeText(
_entry.OriginalValues.GetName(i), isModified));
node.Tag = _entry.OriginalValues.GetName(i);
tree.Nodes.Add(node);
if (_entry.OriginalValues[i] is DbDataRecord)
DrawComplexType(node,
_entry.OriginalValues[i] as DbDataRecord,
_entry.CurrentValues[i] as DbDataRecord);
else
DrawProperty(node, _entry.OriginalValues[i],
_entry.CurrentValues[i]);
}
}
Private Sub EntriesComparer_Load(ByVal sender As Object,
ByVal e As EventArgs)
Dim modifiedProperties = _entry.GetModifiedProperties()
For i As Integer = 0 To
_entry.OriginalValues.FieldCount - 1
Dim isModified = modifiedProperties.Any(
Function(n) n = _entry.OriginalValues.GetName(i))
Dim node As New TreeNode(CreateNodeText(
_entry.OriginalValues.GetName(i), isModified))
node.Tag = _entry.OriginalValues.GetName(i)
tree.Nodes.Add(node)
If TypeOf _entry.OriginalValues(i) Is DbDataRecord Then
DrawComplexType(node,
TryCast(_entry.OriginalValues(i), DbDataRecord),
TryCast(_entry.CurrentValues(i), DbDataRecord))
Else
DrawProperty(node, _entry.OriginalValues(i),
_entry.CurrentValues(i))
End If
Next
End Sub
DrawProperty generates a node whose text indicates the name of the property and whether it’s marked as Modified. It then renders two child nodes for the current and original values of the property. DrawComplexType creates a node and then invokes DrawProperty to generate a child node for each of its properties.
In the end, building the visualizer is straightforward. What’s challenging is writing the code to let users persist its modifications. In this case, employee 2 selects the Name property to mark it as to-persist and then clicks the Merge button. At this point, you have to roll back the state to Unchanged and then manually mark the properties selected by the user (Name in this case) as Modified.
To switch the state to Unchanged, you use the entry’s ChangeState method. But the problem with this method is that not only does it change the state, it also overrides the original values with the current ones (remember, it calls the AcceptChanges method of the ObjectStateEntry class). This poses a problem, because the current value of Version still contains the old value, which will overrides the original (most updated) value. If you invoke SaveChanges now, you’ll still get an exception.
Let’s consider this step by step. Employee 1 and employee 2 read the customer with Version 1. Employee 1 updates Version to 2. Then, employee 2 saves the data using Version 1 and gets an exception. When Refresh is invoked, the original value of Version becomes 2, but the current Version remains 1. When ChangeState is then invoked, the original value of Version becomes 1 because it’s overwritten with the original value. This way the UPDATE will always fail. Table 8.1 shows this workflow. The last row shows that the original value is set to the incorrect value.
Table 8.1. The update workflow and the problem with the version value
|
Employee |
Action |
Database version |
Current version |
Original Version |
|---|---|---|---|---|
| Employee 1 | Reads customer | 1 | 1 | 1 |
| Employee 2 | Reads customer | 1 | 1 | 1 |
| Employee 1 | Saves customer | 2 | ||
| Employee 2 | Saves customer and gets exception | 2 | 1 | 1 |
| Employee 2 | Refresh method | 2 | 1 | 2 |
| Employee 2 | ChangeState to Unchanged | 2 | 1 | 1 |
| Employee 2 | Saves customer and gets exception | 2 | 1 | 1 |
The trick to resolving this is the same one you saw in listing 8.1. You save the original value of Version into a variable, modify the state to Unchanged, and then restore the original value using the variable by using the GetUpdatableOriginalValues method and the OriginalValueRecord class’s methods that you saw in section 8.2.2. This listing shows the code.
Listing 8.6. Persisting only selected columns
C#
private void Merge_Click(object sender, EventArgs e)
{
ApplyChanges = true;
object version = _entry.OriginalValues["Version"];
_entry.ChangeState(EntityState.Unchanged);
_entry.GetUpdatableOriginalValues()
.SetValue(
_entry.OriginalValues.GetOrdinal("Version"),
version);
foreach (TreeNode node in tree.Nodes)
{
if (node.Checked)
_entry.SetModifiedProperty(node.Tag.ToString());
}
Close();
}
VB
Private Sub Merge_Click(ByVal sender As Object, ByVal e As EventArgs)
ApplyChanges = True
Dim version As Object =
_entry.OriginalValues("Version")
_entry.ChangeState(EntityState.Unchanged)
_entry.GetUpdatableOriginalValues().
SetValue(
_entry.OriginalValues.GetOrdinal("Version"),
version)
For Each node As TreeNode In tree.Nodes
If node.Checked Then
_entry.SetModifiedProperty(node.Tag.ToString())
End If
Next
Close()
End Sub
This code saves the version, rolls back the entity to Unchanged, sets the version, and then sets the checked properties as Modified. The visualizer form is a generic form that is opened by another form to resolve conflicts. ApplyChanges is a property of the visualizer form that informs the calling form that the SaveChanges method must be invoked after the user has finished checking the changed values. The complete code for the method that saves the data from the edit form now looks like the following.
Listing 8.7. Complete code for managing concurrency exceptions
C#
try
{
ctx.SaveChanges();
}
catch (OptimisticConcurrencyException ex)
{
var errorEntry = ex.StateEntries.First();
ctx.Refresh(RefreshMode.ClientWins, errorEntry.Entity);
var form = new EntriesComparer(errorEntry);
form.ShowDialog();
if (form.ApplyChanges)
ctx.SaveChanges();
}
VB
Try
ctx.SaveChanges()
Catch ex As OptimisticConcurrencyException
Dim errorEntry = ex.StateEntries.First()
ctx.Refresh(RefreshMode.ClientWins, errorEntry.Entity)
Dim form = New EntriesComparer(errorEntry)
form.ShowDialog()
If form.ApplyChanges Then
ctx.SaveChanges()
End If
End Try
Under some circumstances, you can handle concurrency problems automatically, without user involvement. For instance, you may have a rule stating that if the Name is modified, the user must check what happened. Another rule may state that if a user modifies the shipping address while another modifies the billing address, the system must reconcile everything automatically. Fortunately, by working with Refresh, this shouldn’t be too difficult to achieve.
Note
In this example, we assumed that concurrency is handled by a property named Version. Using metadata from the EDM (which we’ll discuss more in chapter 12), you can write a generic method that looks for properties that have the ConcurrencyMode attribute set to Fixed, and use those properties instead of embedding a property name in code.
Congratulations. You have achieved the master level in concurrency management. As a reward, you can go on to the next stage, which is transaction management. It mostly involves persistence processes, but you’ll discover that it might even have an impact on queries.
8.3. Managing transactions
When you invoke SaveChanges, the context automatically starts a transaction and commits or rolls it back depending on whether the persistence succeeded. This is all transparent to you, and you’ll never need to deal with it.
But sometimes persistence is complex. Think about the product-availability calculation in the previous chapter. When you update an order, you iterate over each detail, adding the old quantity using a custom command, and then invoke SaveChanges. Then you add, for each detail, the new quantity using another custom command.
The problem with such a solution is that the custom commands aren’t executed in any transaction. If a problem occurs during SaveChanges, the first set of custom commands is executed and committed, the order isn’t committed, and the second set of custom commands isn’t even executed. The result is that the product availability values are compromised.
That’s a simple example. A more complex scenario is when you have to integrate your application with an external system. For instance, when you save the order, you may have to send a message over MSMQ or update another database. Everything must be executed in the scope of a transaction.
Even if these actions have different natures and use different technologies, they can be grouped together in the same transaction by using the TransactionScope class. It’s defined in the System.Transactions namespace inside the System.Transactions assembly.
The TransactionScope class is pretty simple to use. You instantiate it in a using statement, and before disposing of it, you either invoke its Complete method to mark the transaction as committed or do nothing to roll it back. In the using block, you put all the code that must execute in the scope of the transaction. The following snippet shows how simple the code is:
using (var transaction = new TransactionScope())
{
...
scope.Complete();
}
VB
Using transaction = New TransactionScope() ... scope.Complete() End Using
It’s that easy. But how is it possible? How can a class handle transactions that span multiple databases and different technologies? The answer lies in the Microsoft Distributed Transaction Coordinator (MSDTC or simply DTC). It’s a component embedded in Windows that coordinates transactions across different platforms.
Connecting to the DTC is an expensive task, so TransactionScope tries not to do it unless it’s necessary. When you connect to the database, the DTC starts a classic transaction: SqlTransaction, OleDbTransaction, or another as appropriate. If you connect to a second database or another platform like MSMQ, TransactionScope automatically promotes the transaction to the DTC. As the following listing shows, this behavior is totally transparent; you don’t have to change your code to adapt to the different transaction technology.
Listing 8.8. An example of transaction promotions


Consider the calculation of product availability during order persistence. To execute all the commands in a single transaction, you can wrap them in a TransactionScope using block. What’s absolutely great is that because only one database is involved, the transaction isn’t promoted to the DTC, sparing resources and gaining performance.
Note
SQL Server 2008 has improved its capabilities in avoiding transaction promotion. With SQL Server 2008, transaction promotion happens less frequently than it does with SQL Server 2005.
If you want to know whether some code will cause a transaction to be promoted, you have to use SQL Profiler, because it always specifies when this happens. You can see an example in figure 8.6.
Figure 8.6. The first INSERT is executed under a database transaction. Later, the transaction is promoted, and then the second INSERT is issued.
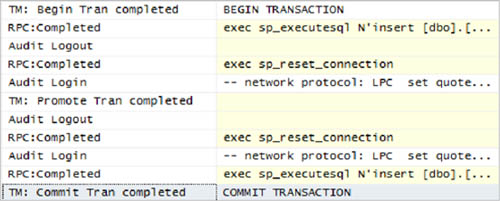
SQL Profiler is useful during development and debugging. If you want to control how many transactions are promoted and monitor related statistics, you’ll have to resort to performance counters, which have a category dedicated to DTC.
In listing 8.7, the value SaveOptions.DetectChangesBeforeSave is passed to the SaveChanges method. Passing such a value without combining it with the Save-Options.AcceptAllChangesAfterSave value guarantees that the entities’ modifications in the context aren’t committed after the SaveChanges has finished executing.
8.3.1. The transactional ObjectContext
You know that SaveChanges accepts an enum of type SaveOptions, indicating whether it has to invoke DetectChanges and AcceptAllChanges. If no value is passed to SaveChanges, or if the value SaveOptions.AcceptAllChangesAfterSave is specified, then when SaveChanges has finished its job, the objects in Modified and Added states return to Unchanged, and the ones in Deleted state are removed from the context. (This is the SaveChanges method’s commit phase for entities that you learned about in chapter 7.)
If you pass the value SaveOptions.DetectChanges to the SaveChanges method and don’t pass SaveOptions.AcceptAllChangesAfterSave, the entities’ commit phase isn’t triggered. This is exactly what you need when extending the transaction span, because if something fails in commands executed after the SaveChanges method, the transaction is rolled back and the entities in the context maintain their state.
After you’ve committed the transaction, you can manually call the AcceptAll-Changes method to bring the objects into a clean state. This is necessary because the entities’ commit phase in the object context isn’t transactional. You have to manually take care of keeping everything synchronized.
Transactions are widely used to provide an all-or-nothing method of saving data on databases, but they’re useful when reading data too.
8.3.2. Transactions and queries
You can’t roll back a read; it’s pure nonsense. But you can use a transaction to control an important aspect of data retrieval: the isolation level. You can use it to decide what types of records can be read and whether they can be modified. For instance, you may decide to search for rows that are in the database, including those that aren’t committed yet. Or you may decide to include uncommitted rows and enable their modifications too.
These options are configurable via the IsolationLevel property of the TransactionScope class. It’s an enum of type IsolationLevel and can have the following values:
- Unspecified
- Chaos
- ReadUncommitted
- ReadCommitted
- RepeatableRead
- Serializable
- Snapshot
If you’re used to database transactions, you’ll know what these levels correspond to. We won’t cover them here, but if you want to delve more into this subject, the MSDN documentation is a good starting point: http://mng.bz/hGel. The following snippet shows how to set the isolation level of a transaction:
C#
var transaction = new TransactionScope(TransactionScopeOption.Required,
new TransactionOptions()
{
IsolationLevel = IsolationLevel.ReadUncommitted
}
);
VB
Dim transaction As New TransactionScope(TransactionScopeOption.Required,
New TransactionOptions() With
{
.IsolationLevel = IsolationLevel.ReadUncommitted
}
)
Some years ago, transactions would have been a complex subject. Nowadays, thanks to the DTC component and the TransactionScope class, controlling them is incredibly simple.
8.4. Summary
You’ve now finished the second part of this book, which means you have enough knowledge to develop an application using Entity Framework as a persistence engine. Concurrency and transaction management complete the circle, because they integrate with persistence, which was covered in the previous chapter.
Now you can handle concurrent writes to the same data and make custom SQL commands work in the same transaction as the SaveChanges method, even if those SQL commands are external to Entity Framework. That makes you an Entity Framework pro.
It’s time to become a master by learning a few other features. For instance, Entity SQL isn’t as easy to use as LINQ to Entities is, but sometimes it makes life easier. Another feature that you must learn about is the use of stored procedures. In environments where the DBA is the governor of the database, learning how to use stored procedures and functions is fundamental. These and other topics will be the subject of the next part of the book.