
Chapter 3. Querying the object model: the basics
- Entity Framework querying techniques
- Capturing the generated SQL
- Insights into the Entity Framework query engine
- Common query pitfalls
In the first part of this book, you gained a strong understanding of where Entity Framework stands and how it can be integrated into your application. Now it’s time to start digging deep into the technology to understand the most important thing: how you use it.
In this chapter, you’ll learn about the most basic feature in Entity Framework: querying. In particular, you’ll learn how the Object Services layer enables you to query the database and which other components collaborate with it. What’s more, you’ll learn how to inspect the SQL generated by Entity Framework so that you can decide whether to use it or to handcraft a custom SQL command. By the end of this chapter, you’ll understand how querying works under the covers and the theory behind it.
3.1. One engine, many querying methods
In chapter 2, you saw a couple of LINQ to Entities queries, but those just scratched the surface of the Entity Framework querying system. There is more than one method for querying the model, and more than one structure that can be used to execute queries.
These are the possible ways of querying with Entity Framework:
- LINQ to Entities through Object Services— You write LINQ to Entities queries, and the Object Services layer is responsible for handling the returned entities’ lifecycles.
- Query builder methods and Entity SQL through Object Services— You use query builder methods to create Entity SQL queries. The Object Services layer is then responsible for handling the returned entities’ lifecycles.
- Entity SQL through Object Services— You write the full Entity SQL query on your own, without resorting to query builder methods, and then submit it through Object Services, which takes care of the entities’ lifecycles.
- Entity SQL through Entity Client— You bypass the Object Services layer and retrieve the data not as objects, but as a conceptual shaped set of DbDataRecord instances.
This chapter and the next focus on Object Services and LINQ to Entities, so we’ll only cover the first option here. The other methods are covered in chapter 9, which is dedicated to Entity SQL and Entity Client.
3.2. The query engine entry point: Object Services
In chapter 1, you learned that the Object Services layer’s task is managing objects’ life-cycles from retrieval to persistence. The main class of the Object Services layer is ObjectContext. As you saw in chapter 2, it’s the most useful class for your code because it provides the only entry point for executing LINQ to Entities queries.
One of the features of the Visual Studio designer is that, along with generating entities, it generates another class that inherits from ObjectContext and that has a set property for each object model class (with some exceptions). This property represents the entity set. You can think about the entity set as a database table—it doesn’t actually contain data, but the entity set is what you write queries against. Later, in section 3.2.4, you’ll see how a query written against the entity set is turned into SQL and returns the data. For the moment, though, let’s focus on entity sets.
The property representing an entity set is of type ObjectSet<T>. The generic parameter corresponds to the type of the class that the entity set exposes. In OrderIT, the property that enables order retrieval is Orders; its type is ObjectSet<Order>, and it has the following definition.
Listing 3.1. The Orders property definition in the context class
C#
public partial class OrderITEntities : ObjectContext
{
public ObjectSet<Order> Orders
{
get
{
return _orders ??
(_orders = CreateObjectSet<Order>("Orders"));
}
}
private ObjectSet<Order> _orders;
}
Public Partial Class OrderITEntities
Inherits ObjectContext
Public ReadOnly Property Orders() As ObjectSet(Of Order)
Get
If _orders Is Nothing Then
_orders = CreateObjectSet(Of Order)("Orders")
End If
Return _orders
End Get
End Property
Private _orders As ObjectSet(Of Order)
End Class
ObjectSet<T> inherits from ObjectQuery<T>, which was the class used in Entity Framework v1.0. ObjectSet<T> adds some convenient methods while maintaining compatibility with the past.
The ObjectContext class isn’t abstract. The only reason the wizard generates a specialized class that inherits from ObjectContext is to automatically generate the entity-set properties plus some helper methods. The generated class is perfect as is, and you should always use it.
If there is a case where you can’t use it, you can instantiate the ObjectContext class directly and pass the connection string name (more about connection strings in section 3.2.1). After that, you can use the CreateObjectSet<T> method, passing the entity set name as a parameter (more about this in chapter 4), to create the Object-Set<T> instance. You can see such code in the following snippet:
C#
using (ObjectContext ctx = new ObjectContext("name=ConnStringName"))
{
var os = ctx.CreateObjectSet<Order<("Orders");
}
VB
Using ctx As new ObjectContext("name=ConnStringName")
Dim os = ctx.CreateObjectSet(Of Order)("Orders")
End Using
As you can see, manually creating an ObjectSet<T> instance isn’t difficult at all. But we still haven’t encountered a situation where this is necessary—the wizard-generated file has always worked well for us.
Note
ObjectContext implements the IDisposable interface. We strongly recommend adopting the Using pattern to ensure that all resources are correctly released. For brevity’s sake, we won’t show the context-instantiation code in subsequent snippets; ctx will be the standard name of the variable representing it.
When you instantiate the designer-generated context class, you don’t need to pass the connection string name to the constructor, whereas you have to pass it when working directly with ObjectContext. The designer knows what the connection string name is (you passed it in the designer wizard that created the object model and the context class, as you saw in chapter 2); and when the template generates the context-class code, it creates a constructor that invokes the base constructor, passing the connection string name. The context-class constructor is visible in the following snippet:
C#
public class OrderITEntities
{
public OrderITEntities() : base("name=ConnStringName") { }
}
VB
Public Class OrderITEntities
Public Sub New()
MyBase.New("name=ConnStringName")
End Sub
End Class
The template generates other constructors that accept the connection string, including an EntityConnection object (the connection to the Entity Client). This way, you can change the connection string programmatically when needed.
Under the covers, Object Services takes care of lots of tasks:
- Manages connection strings
- Transforms LINQ to Entities queries into an internal representation understood by Entity Client
- Transforms database query results into objects
- Ensures that only one object exists for each row in the database (no duplicates)
- Enables capturing the SQL code issued against the database
- Enables database script creation and the creation and dropping of databases
We’ll look at these features in the following subsections. Let’s start at ground level and look at the connection string.
3.2.1. Setting up the connection string
As you’ve seen, the connection string name is mandatory for the ObjectContext class. How you pass the connection string is slightly different in the Entity Framework compared to how you do it with other ADO.NET frameworks. In Entity Framework, you have to apply the (case-insensitive) prefix Name= to the connection string:
Name=ConnStringName
This isn’t the only difference from what you’re likely to be used to. The connection string itself is quite odd. This is how the connection string for OrderIT appears in the connectionString section of the configuration file.
Listing 3.2. A connection string example
<add
name="ConnStringName"
connectionString="
metadata=res://*/Model.csdl| res://*/Model.ssdl|res://*/Model.msl;
provider=System.Data.SqlClient;
provider connection string='
Data Source=.sqlexpress;
database=EFInactionOrders;
Integrated Security=True;
MultipleActiveResultSets=True
'
"
providerName="System.Data.EntityClient"
/>
The structure is always the same, but the data is organized in an unusual way. The attribute name represents the name of the connection string, and it’s the one used when passing the connection string name to the context constructor. So far, so good.
The connectionString attribute is very different from what you’re used to seeing, and it probably looks a bit muddled. You must understand how it’s made, because you’ll have to modify it when changing databases (when moving from development to production servers, for instance). It’s split into three subsections:
- metadata—In this part, you specify where the three mapping files are located, separating the locations with pipe (|) characters. If the files are stored as plain text on the disk, you specify the path. If the files are stored as resources in the assembly, the res://*/filename convention is used.
- provider—Here you specify the ADO.NET invariant provider name for the database, as if you were populating the providerName attribute of the connection-String node.
- provider connection string—This represents the real connection string to the database. If you need to include a double-quote (") character, you must use its escaped format (") to avoid collision with XML format.
Finally, the providerName attribute contains the System.Data.EntityClient string, which is the invariant Entity Framework provider name.
Setting up the connection is an important task. Fortunately, it’s handled by the designer, so you only have to touch it when you change databases. If you need to build it at runtime, you can use the EntityConnectionStringBuilder class.
Creating Connection Strings in Code
Usually the connection string can be put in the configuration file and read by the application. In some scenarios, though, you may need to change the connection string at runtime. We’ve encountered this situation a couple of times.
In the first case, each attribute of the connection string was returned by a service. This isn’t the world’s best architecture, but sometimes you have to live with it.
In the second case, the application was built to deal with two different versions of SQL Server (2005 and 2008). This meant having two different SSDL files, so the correct one had to be chosen at runtime based on the database version. There were two solutions:
- Creating the connection string by manually concatenating strings
- Building the connection string at runtime using EntityConnectionString-Builder
Needless to say, the second option was the better choice and is the one we’ll discuss
The EntityConnectionStringBuilder class inherits from the ADO.NET base class DbConnectionStringBuilder, and it’s responsible for building a connection string starting from a set of parameters and for parsing a given connection string into single parameters. Its properties are described in table 3.1.
Table 3.1. Properties of the EntityConnectionStringBuilder class
|
Property |
Description |
|---|---|
| Metadata | Corresponds to the metadata section in the connection string. |
| Provider | Corresponds to the provider section in the connection string. |
| ProviderConnectionString | Corresponds to the provider connection string section in the connection string. |
| ConnectionString | The connection string in Entity Framework format. When you set it, the previous properties are automatically populated. When you modify one of the preceding properties, the connection string is automatically updated to reflect the changes. |
In the first case we outlined, where the connection string was returned by a service, you can use DbConnectionStringBuilder class’s ability to generate a connection string from a single parameter. You can receive the Metadata, Provider, and Provider-ConnectionString parameters from the web service and use them to set up the connection string and pass it to the context constructor, as shown here.
Listing 3.3. Building a connection string
C#
var connStringData = proxy.GetConnectionStringData();
var builder = new EntityConnectionStringBuilder();
builder.Provider = connStringData.Provider;
builder.Metadata = connStringData.Metadata;
builder.ProviderConnectionString = connStringData.ProviderConnectionString;
using (var ctx = new OrderITEntities(builder.ConnectionString))
{
...
}
VB
Dim connStringData = proxy.GetConnectionStringData() Dim builder = new EntityConnectionStringBuilder() builder.Provider = connStringData.Provider builder.Metadata = connStringData.Metadata builder.ProviderConnectionString = connStringData.ProviderConnectionString Using ctx = New OrderITEntities(builder.ConnectionString) ... End Using
The important thing is that the data must not contain the section name. For instance, the provider parameter must contain the value System.Data.SqlClient, and not Provider=System.Data.SqlClient. The Provider= string is automatically handled by the EntityConnectionStringBuilder class.
In the second case, where we built the connection string at runtime, we only needed to change part of the connection string: the SSDL location. In this case, you can put the connection string in the configuration file, putting a placeholder {0} in the SSDL location. Once you know the database version, you can replace the placeholder with the correct SSDL path. This could be done with a simple String.Format, but the EntityConnectionStringBuilder has the ability to parse a connection string and populate the related properties.
The following solution first loads the connection string and then uses the String.Format statement on the Metadata property only.
Listing 3.4. Modifying an existing connection string
C#
var builder = new EntityConnectionStringBuilder();
builder.ConnectionString = connString;
builder.Metadata = String.Format(builder.Metadata, "res://*/Model.ssdl");
using (var ctx = new OrderITEntities(builder.ConnectionString))
{
...
}
VB
Dim builder = New EntityConnectionStringBuilder() builder.ConnectionString = connString builder.Metadata = String.Format(builder.Metadata, "res://*/Model.ssdl") Using ctx = New OrderITEntities(builder.ConnectionString) ... End Using
The connection string is only the first part of the game. We mentioned in chapter 1 that one of the key features of Entity Framework is that it lets you write queries against the object model and not against the database. In the next section, we’ll focus on this and look at what happens under the covers.
3.2.2. Writing queries against classes
Because the database is completely abstracted by the EDM, you can write queries against the classes, completely ignoring the underlying database organization. Entity Framework uses mapping information to translate those queries into SQL. This workflow is explained in figure 3.1.
Figure 3.1. Queries written against classes are transformed into SQL.

The abstraction between classes and the database isn’t too difficult to grasp. If a property is named differently from the column of the table it’s mapped to, you still use the property name in your query—this is obvious because you query against the class. With LINQ to Entities, you probably won’t type the wrong name because Visual Studio’s IntelliSense will give you hints about the correct name. What’s more, the compiler will throw an error if you type the incorrect property name.
Other situations can lead to differences between the database and the object model. Customers and suppliers have their own classes, but there is only one table containing their data. Once again, you write your queries against these entities, and not against the Company table.
Furthermore, we’ve grouped address information into a complex type. When writing queries, they’re accessed like a part of a type, whereas in the database they’re plain columns.
At first, these differences might deceive you, especially if you’re experienced with the relational model. But after a bit of practice, you’ll see that writing queries this way is more intuitive and productive than writing SQL. Classes represent your business scenario more meaningfully than the relational model, with the result that writing a query against classes is more business oriented (and more natural) than writing SQL. What’s more, the intricacies of the relationships between classes are handled by Entity Framework, so you don’t need to care how the data is physically related.
Now that you understand how a query against the model is different from a query against the database, we can touch on another important subject. How is a LINQ to Entities query processed by the Object Services layer, and why does it become SQL instead of triggering an in-memory search against the entity set?
3.2.3. LINQ to Entities queries vs. standard LINQ queries
LINQ is an open platform that can be customized to execute queries against any data source (a plethora of providers on the web can retrieve data from web services and databases like Oracle and MySQL, NHibernate, and so on). The important caveat is that the entry point for querying is a list implementing the IEnumerable<T> interface.
ObjectSet<T> implements IEnumerable and another interface that’s required to customize LINQ: IQueryable<T>. This interface holds a reference to an object that implements the IQueryProvider interface, and that object overrides the base LINQ implementation. Instead of triggering a local search, it analyzes the query and starts the SQL-generation process.
Now you know why queries written against ObjectSet<T> are evaluated differently than queries against other data sources. But that just explains how the query translation process starts, and why a LINQ to Entities query becomes SQL. In the next section, you’ll discover how a query gets translated into SQL, you’ll learn how it’s executed, and you’ll see that data is returned as a set of objects.
3.2.4. Retrieving data from the database
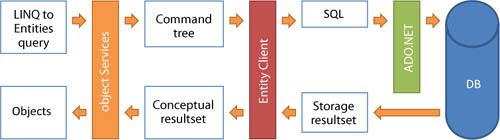
When you execute a query, the LINQ provider hosted by the entity set parses the query and creates a command tree. Because you’re writing the query against classes, the command tree represents the query conceptually.
Object Services passes the command tree to the Entity Client, which, with the aid of mapping and the storage files, transforms it into a native SQL command. After that, the Entity Client uses the ADO.NET provider specified in the provider section of the connectionString attribute to launch the SQL against the database and obtain the result. The query result is then shaped in a tabular way that reflects the object model structure, as you saw in section 1.6.
Finally, the data is returned to the Object Services layer, which instantiates (or materializes) the objects. Figure 3.2 illustrates this process.
Figure 3.2. How a LINQ to Entities query passes through different layers and becomes a set of objects
After scalar, complex, and reference properties are filled in, and before collection properties are dealt with, the context triggers the ObjectMaterialized event. This event accepts the entity that’s being materialized and allows you to perform some logic before the object is returned to the application. The following listing shows how you can use this event.
Listing 3.5. Attaching a handler to the ObjectMaterialized event
C#
public OrderITEntities()
{
ctx.ObjectMaterialized +=
new ObjectMaterializedEventHandler(ctx_ObjectMaterialized);
}
void ctx_ObjectMaterialized(object sender, ObjectMaterializedEventArgs e)
{
var o = entity as Order;
//any logic
}
Public Sub New() AddHandler ctx.ObjectMaterialized, AddressOf ctx_ObjectMaterialized End Sub Private Sub ctx_ObjectMaterialized(ByVal sender As Object, ByVal e As ObjectMaterializedEventArgs) Dim o = TryCast(entity, Order) 'any logic End Sub
As you can see, subscribing to the ObjectMaterialized event is like subscribing to any other event in the .NET Framework class library.
There’s an important caveat that you must keep in mind about the materialization step: the context implements the Identity Map pattern.
3.2.5. Understanding Identity Map in the context
The context holds references for all the entities it reads from the database and identifies them by their key properties. Before the context materializes a new entity, it checks whether one with the same key and of the same type already exists. If it does exist, the context returns the in-memory entity, discarding data from the database.
This pattern is named Identity Map, and it’s vital for application consistency. Without the Identity Map, if you read an order, someone else updated it, and you read it again, you’d have two instances with different data representing the same order. Which one would be correct? Which one should you update? Should the OrderIT user know about it? The answers would depend on the situation, so you should never let this happen.
Keeping references to entities and checking whether there’s already one in the context during materialization are heavy burdens for the context. Fortunately, this behavior isn’t needed by all applications. Consider a web page that displays orders in a grid. After the orders are read from the context, they won’t be touched in any way, so there’s no point in storing references to the objects. Skipping this step makes the context lighter, because it doesn’t memorize objects, and faster, because the Identity Map check doesn’t happen.
Note
In chapter 19, you’ll see how tweaking applications in ways like this can dramatically improve performance.
More broadly speaking, you can choose the way the context treats entities after each query. This choice is made at the query level and not at the context level, meaning that the same context can use objects in one way for some queries and in another way for other queries.
More specifically, the context has four ways of managing entities returned by a query. You can set any of the following values for the MergeOption property:
- AppendOnly—If the entity is already in the context, it’s discarded, and the context one is returned. If the entity isn’t in the context, it’s added. (This is the default behavior.)
- NoTracking—The entity isn’t stored by the context.
- OverwriteChanges—If the entity is in the context, it’s overwritten with values from the database and then is returned. If the entity isn’t in the context, it’s added.
- PreserveChanges—If the entity is in the context, properties modified by the user remain untouched, and the others are updated using database values. If the entity isn’t in the context, it’s added.
In our experience, the AppendOnly and NoTracking options have covered all our needs. We have never needed to use the other options. Nonetheless, never forget that they exist—one day you could need them.
Note
A context can’t hold more than one object of the same type with the same key. For instance, it can’t hold two orders or customers with the same key. In chapter 6, you’ll learn that such operations cause exceptions. Also note that if a retrieved entity is tracked by a context, and a query retrieves it again, the ObjectMaterialized event isn’t raised because the context entity is returned—there’s no materialization process.
As mentioned in the previous list, AppendOnly is the default behavior, but you can override it by setting the MergeOption property of the entity set. This property is an enum of MergeOption type (defined in the System.Data.Objects namespace) whose possible values are in the previous list. Here’s how you can set tracking behavior.
Listing 3.6. Setting tracking options
C#
var companies = ctx.Companies.ToList(); ctx.Orders.MergeOption = MergeOption.NoTracking; var orders = ctx.Orders.ToList();
VB
Dim companies = ctx.Companies.ToList() ctx.Orders.MergeOption = MergeOption.NoTracking Dim orders = ctx.Orders.ToList()
Objects in the companies list are stored by the context because tracking is enabled by default. Objects in the orders list aren’t tracked because the Orders entity set has been configured for no tracking.
So far, you’ve only had a brief description of the querying options. We’ll cover more intricacies in chapter 6, which is dedicated to persistence.
The entity-set properties hide a nasty trap when dealing with tracking. They expose an ObjectSet<T> instance, but the way the instance is created affects the way you have to set tracking.
Createobjectset<T> and Tracking
The default code generator and the POCO generator create code that instantiates an entity set lazily when it’s first accessed. After the instance is created, it’s reused for the entire context lifecycle. The result is that when you configure the tracking option, it remains the same for all queries issued against that entity set, unless you change it.
We have seen projects where, instead of reusing the same instance, a new one is created each time the entity set property is accessed. In this case, setting the tracking option has no effect. The ObjectSet<T> instance on which you set the option is different from the one returned when you later access the entity-set property. The result is that the context follows the default behavior.
To overcome this problem, you can assign the entity-set property to a local variable and then work directly with it, as shown here:
C#
var set = ctx.Companies; set.MergeOption = MergeOption.NoTracking; var companies = set.ToList();
VB
Dim set = ctx.Companies set.MergeOption = MergeOption.NoTracking Dim companies = set.ToList()
Setting the MergeOption property of the entity set isn’t the only way to configure tracking. You can also use the Execute method.
Execute and Tracking
The Execute method allows you to perform a query and set tracking in a single call. Keep in mind that, in this case, the value passed to the method overrides the entity set configuration.
Listing 3.7. Setting tracking via the Execute method
C#
ctx.Companies.MergeOption = MergeOption.NoTracking; var companies = ctx.Companies.Execute(MergeOption.AppendOnly);
VB
ctx.Companies.MergeOption = MergeOption.NoTracking Dim companies = ctx.Companies.Execute(MergeOption.AppendOnly)
Tracking is a key feature of Entity Framework. You’ll find other APIs in this O/RM tool that are affected by tracking, and we’ll discuss them in chapters 6 and 10. Now it’s time to move on and discover how the Object Services layer interacts with the Entity Client.
3.2.6. Understanding interaction between Object Services and Entity Client
The ObjectContext class keeps an instance of the EntityConnection class. Just as the context is your entry point to Object Services, the connection is the entry point to the Entity Client. This instance isn’t intended only for internal use—it’s publicly exposed via the Connection property of the context. The context even has a constructor that accepts a connection.
The context handles this connection for you. It instantiates a new one if one has not been generated yet, opening it before executing a query and closing it when the query has been executed. When it persists objects, it opens the connection, starts the transaction, and commits or rolls back the transaction depending on whether an exception occurs.
Because you can access the connection through the context, you can manipulate it at will. Suppose that within the scope of a context, you must execute five queries. Opening and closing the connection each time isn’t the best way to go. It isn’t particularly expensive if the ADO.NET provider is configured for connection pooling (which is the default for SQL Server), but it can surely be optimized.
What you can do is manually handle the lifetime of the connection. When you manually open the connection, the context stops handling it, leaving it open and turning over to you the burden of physically closing it. This means you can open the connection, execute the five queries, and then close the connection within a single open-query-close cycle.
Note
Even if you don’t close the connection, it will be disposed of automatically when the context is disposed of. This is why we recommend the Using pattern.
You can further customize the interaction between the context and the connection by creating an instance of the connection and passing it to one of the context constructors. This way, the context ignores the connection lifecycle, leaving you in charge of its complete management.
This holds true during context disposal too. If the connection isn’t generated by the context, it isn’t disposed of. What’s bad about this is that if you forget to close or dispose of the connection, it remains open until the garbage collector clears everything. Don’t make this mistake.
In chapter 9, we’ll go deeper inside the Entity Client and the EntityConnection class. Right now, though, it’s time to take a look at the SQL generated by the Entity Client.
3.2.7. Capturing the generated SQL
Even if Entity Framework generates the SQL code, you can’t assume the code is fine as is. You must always make sure that the generated statements perform well and don’t require too many database resources to execute. Sometimes the generated query will be too heavy or complex, and you can get better performance by using a stored procedure or handcrafting the SQL.
The easiest way to inspect the SQL is to use the profiler tool that’s included among the client-management tools that ship with most modern databases. With this tool, you can monitor all the statements executed against the database and then analyze the ones that need refinement or complete replacement.
Usually, this monitoring requires high-level permissions on the database, and sometimes you won’t have such power. Fortunately, the Object Services layer comes to your aid with the ObjectSet<T> class’s ToTraceString method. Here’s how you can use it:
C#
var result = ctx.Orders.Where(o => o.Date.Year == DateTime.Now.Year); var SQL = (result as ObjectQuery).ToTraceString();
VB
Dim result = ctx.Orders.Where(Function(o) o.Date.Year = DateTime.Now.Year) Dim SQL = TryCast(result, ObjectQuery).ToTraceString()
Notice that this code doesn’t cast to ObjectQuery<T> but to ObjectQuery. ObjectQuery<T> inherits from ObjectQuery, which is where the ToTraceString method is implemented.
All the steps in query processing should now be clear to you. But there is still one thing to know about the object creation done by the Object Services layer. We said that Object Services materializes the entities using the conceptual resultset coming from the Entity Client. What we didn’t say is that the materialized entities may not be your model entities.
3.2.8. Understanding which entities are returned by a query
When you query for an order, you expect the returned entity to be of type OrderIT.Model.Order. This is pretty normal. You ask for an order, and you get an order. So you’ll be surprised that, by default, the returned entity is of type OrderIT.Model.Order_XXX, where X is a number.
If you’re accustomed to other O/RM tools, such as NHibernate, you’ll be aware of what needs this technique satisfies. But if you’re new to O/RM, you’re probably trying to figure out the reason for this. What is this class? Who defined it? Why are you getting this class instead of the one you defined?
The answers are simple. The new class is a runtime-generated proxy. A proxy is a class that inherits from the one you expect and injects code in your properties to transparently add behavior to your class. Because the proxy is generated at runtime, nobody defined it. If you open the assembly with Reflector, you’ll see that there is no definition of such a class.
Note
Reflector is a tool that lets you browse a .NET assembly and discover its classes and their code. It’s free, and you can download it from www.red-gate.com/products/reflector/.
Using reflection and runtime code emittance, Entity Framework generates a class that inherits from your type, injects custom code into properties, and then instantiates the class. The last question is probably the most interesting: Why?
The reason for this process is to provide features like lazy loading, object tracking, and others, without requiring you to write a single line of code. For instance, Entity Framework 1.0 compliant classes had to inherit from a base class or implement interfaces, and write custom code in each property to interact with the object-tracking system. Thanks to the proxy technique, such plumbing is no longer required, because the necessary code is created dynamically by the proxy. Figure 3.3 shows a simplification of the code inside a proxy.
Figure 3.3. The proxy class (bottom) inherits from the object model class (top) and overrides properties.

Making a POCO class extensible requires that you not seal it. To enable object tracking by the proxy, all properties must be virtual. If you need to enable lazy loading (more on this in the next chapter), even navigation properties must be virtual.
Note
You can turn off proxy creation and let the Object Services layer return the plain instance. Setting the ContextOptions.ProxyCreation-Enabled property to false disables this feature. By default, its value is true. A typical scenario where proxies are a problem is with web services, because a method that returns a proxy might run into serialization issues. Using a plain instance and not a proxy makes your class less powerful from an Entity Framework perspective, but it’s still a fully functional class and you can still use it without any problem.
3.2.9. When is a query executed?
Generally speaking, LINQ queries are executed when the application code processes data (for instance, using a foreach or a for) or when certain methods are invoked (ToList, ToArray, First, Single, and so on).
Each time a LINQ to Entities query is executed, Entity Framework goes to the database and retrieves data. When it transforms data from record to object, it scans the in-memory objects to see if one is already there. If it is, the context returns the in-memory object, discarding the record. If it isn’t, the context materializes the record into an object, puts it in memory, and returns it.
Let’s look at an example. Suppose you have to iterate over the result of a query twice, as follows.
Listing 3.8. Iterating twice over query results, causing double query execution
C#
var result = LINQToEntitiesQuery;
foreach(var o in result)
{
...
}
foreach(var o in result)
{
...
}
Dim result = LINQToEntitiesQuery For Each o in result ... Next For Each o in result ... Next
Each time the foreach (or For Each) statement is executed, a round trip to the database is triggered. The context doesn’t care whether you have executed the same query before.
If the query is more complex than simply retrieving all orders, or if lots of data is returned, the double execution represents a serious problem for performance. The easy workaround is to force execution the first time and then download the objects in memory. Later, the in-memory collection is looped, so no round trip to the database is necessary. Here’s the code for this useful technique.
Listing 3.9. Iterating twice over query results, causing single query execution

This approach must be followed not only for queries that return a list of objects, but for queries that return a single object too. Entity Framework makes no distinction between queries that return an object and queries that return a collection.
You can override the Identity Map behavior of the context so it doesn’t keep objects in memory, but that wouldn’t affect the double-execution problem.
The last thing to point out about the context is that it can re-create the database starting from the EDM.
3.2.10. Managing the database from the context
The ObjectContext class has four interesting methods that let you work with the database structure:
- CreateDatabase—Creates the database using the connection string and the information in the SSDL
- CreateDatabaseScript—Generates the database-creation script using the information in the SSDL
- DatabaseExists—Verifies that the database specified in the connection string exists
- DeleteDatabase—Deletes the database specified in the connection string
Note
This may seem a subject outside the scope of this chapter, but you can’t query a database if it doesn’t exist.
These methods are useful when you create an application and don’t create an installation package. When the application starts, you can use DatabaseExists and Create-Database to create the database if it doesn’t exist.
Apart from this situation, these methods aren’t particularly important. Nonetheless, they’re another string in your bow. Maybe one day you’ll need them.
3.3. Summary
In this chapter, you have learned the basics of querying. Although you haven’t seen much code in action, everything you’ve read in this chapter will benefit you in the real world.
For instance, you’ll often have to modify the connection string, so having its structure clear in your mind is useful because it’s complex. Similarly, when you’re debugging an application, being able to inspect the SQL that’s generated is important, because Entity Framework doesn’t always generate friendly SQL.
Last, but not least, you have learned that a query is always executed against the database unless its result is downloaded in the client memory. This is an essential point, because often it’s the cause of inadvertent query execution. We’ve often seen projects where the developers were not aware of this caveat, and the performance of their applications suffered.
Now that we’ve covered the fundamentals, it’s time to write real queries.