
6.5 The Singular Value Decomposition
In many applications, it is necessary either to determine the rank of a matrix or to determine whether the matrix is deficient in rank. Theoretically, we can use Gaussian elimination to reduce the matrix to row echelon form and then count the number of nonzero rows. However, this approach is not practical in finite-precision arithmetic. If A is rank deficient and U is the computed echelon form, then, because of rounding errors in the elimination process, it is unlikely that U will have the proper number of nonzero rows. In practice, the coefficient matrix A usually involves some error. This may be due to errors in the data or to the finite number system. Thus, it is generally more practical to ask whether A is “close” to a rank-deficient matrix. However, it may well turn out that A is close to being rank deficient and the computed row echelon form U is not.
In this section, we assume throughout that A is an m×n
The σi
We begin by showing that such a decomposition is always possible.
Theorem 6.5.1 The SVD Theorem
If A is an m×n
Proof
ATA
Hence,
We may assume that the columns of V have been ordered so that the corresponding eigenvalues satisfy
The singular values of A are given by
Let r denote the rank of A. The matrix ATA
The same relation holds for the singular values
Now let
and
Hence, ∑1
The column vectors of V2
and, consequently, the column vectors of V2
and since V is an orthogonal matrix, it follows that
So far we have shown how to construct the matrices V and Σ of the singular value decomposition. To complete the proof, we must show how to construct an m×m
or, equivalently,
Comparing the first r columns of each side of (3), we see that
Thus, if we define
and
then it follows that
The column vectors of U1
It follows from (4) that each uj,1≤j≤r
It follows from Theorem 5.2.2 that u1,…,um
∎
Observations
Let A be an m×n
The singular values σ1,…,σn
σ1,…,σn of A are unique; however, the matrices U and V are not unique.Since V diagonalizes ATA
ATA , it follows that the vjvj ’s are eigenvectors of ATAATA .Since AAT=UΣΣTUT
AAT=UΣΣTUT , it follows that U diagonalizes AATAAT and that the ujuj ’s are eigenvectors of AATAAT .Comparing the jth columns of each side of the equation
AV=UΣAV=UΣ we get
Avj=σjujj=1,…,nAvj=σjujj=1,…,n Similarly,
ATU=VΣTATU=VΣT and hence
ATuj=σjvjfor j=1,…,nATuj=0for j=n+1,…,mATuj=σjvjATuj=0for j=1,…,nfor j=n+1,…,m The vj
vj ’s are called the right singular vectors of A, and the ujuj ’s are called the left singular vectors of A.If A has rank r, then
v1,…,vr
v1,…,vr form an orthonormal basis for R(AT)R(AT) .vr+1,…,vn
vr+1,…,vn form an orthonormal basis for N(A)N(A) .u1,…,ur
u1,…,ur form an orthonormal basis for R(A)R(A) .ur+1,…,um
ur+1,…,um form an orthonormal basis for N(AT)N(AT) .
The rank of the matrix A is equal to the number of its nonzero singular values (where singular values are counted according to multiplicity). The reader should be careful not to make a similar assumption about eigenvalues. The matrix
M=[0100001000010000]M=⎡⎣⎢⎢⎢⎢0000100001000010⎤⎦⎥⎥⎥⎥ for example, has rank 3 even though all of its eigenvalues are 0.
In the case that A has rank r<n
r<n , if we setU1=(u1,u2,…,ur)V1=(v1,v2,…,vr)U1=(u1,u2,…,ur)V1=(v1,v2,…,vr) and define Σ1
Σ1 as in equation (1), thenA=U1Σ1VT1(6)A=U1Σ1VT1 The factorization (6) is called the compact form of the singular value decomposition of A. This form is useful in many applications.
Example 1
Let
Compute the singular values and the singular value decomposition of A.
SOLUTION
The matrix
has eigenvalues λ1=4
diagonalizes ATA
The remaining column vectors of U must form an orthonormal basis for N(AT)
Since these vectors are already orthogonal, it is not necessary to use the Gram–Schmidt process to obtain an orthonormal basis. We need only set
It then follows that
∎
Visualizing the SVD
If we view an m×n
are mutually orthogonal and the corresponding unit vectors u1,u2,…,ur
Example 2
Let
To find a pair of right singular vectors of A, we must find a pair of orthonormal vectors x and y for which the image vectors Ax and Ay are orthogonal. Choosing the standard basis vectors for ℝ2
are not orthogonal. See Figure 6.5.1.
Figure 6.5.1.

One way to search for the right singular vectors is to simultaneously rotate this initial pair of vectors around the unit circle and for each rotated pair
check to see if Ax and Ay are orthogonal. For the given matrix A, this will happen when the tip of our initial x vector gets rotated to the point (0.6,0.8). It follows that the right singular vectors are
Since
it follows that the singular values are σ1=1.5
∎
Figure 6.5.2.

Numerical Rank and Lower Rank Approximations
If A is an m×n
We will not prove this result, since the proof is beyond the scope of this text. Assuming that the minimum is achieved, we will show how such a matrix X can be derived from the singular value decomposition of A. The following lemma will be useful.
Lemma 6.5.2
If A is an m×n
Proof
∎
If A has singular value decomposition UΣVT
Since
It follows that
Theorem 6.5.3
Let A=UΣVT
In particular, if A′=UΣ′VT

then
Proof
Let X be a matrix in M satisfying (7). Since A′∈?, it follows that
We will show that
and hence that equality holds in (8). Let QΩPT be the singular value decomposition of X, where

If we set B=QTAP, then A=QBPT, and it follows that
Let us partition B in the same manner as Ω.
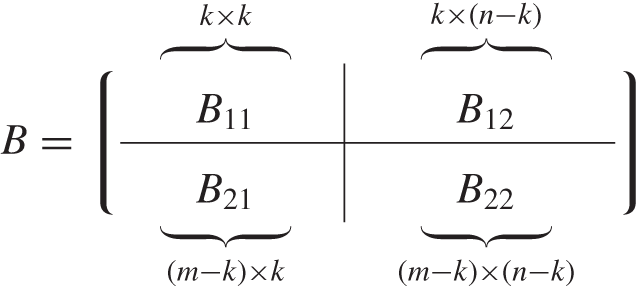
It follows that
We claim that B12=O. If not, then define
The matrix Y is in ? and
But this contradicts the definition of X. Therefore, B12=O. In a similar manner, it can be shown that B21 must equal O. If we set
then Z∈M and
It follows from the definition of X that B11 must equal ΩK. If B22 has singular value decomposition U1ΛVT1, then
Let
Now,
and hence it follows that the diagonal elements of Λ are singular values of A. Thus,
It then follows from (8) that
∎
If A has singular value decomposition UΣVT, then we can think of A as the product of UΣ times VT. If we partition UΣ into columns and VT into rows, then
and we can represent A by an outer product expansion
If A is of rank n, then
will be the matrix of rank n−1 that is closest to A with respect to the Frobenius norm. Similarly,
will be the nearest matrix of rank n−2, and so on. In particular, if A is a nonsingular n×n matrix, then A′ is singular and ‖A−A′‖F=σn. Thus, σn may be taken as a measure of how close a square matrix is to being singular.
The reader should be careful not to use the value of det(A) as a measure of how close A is to being singular. If, for example, A is the 100×100 diagonal matrix whose diagonal entries are all 12, then det(A)=2−100; however, σ100=12. By contrast, the matrix in the next example is very close to being singular even though its determinant is 1 and all its eigenvalues are equal to 1.
Example 3
Let A be an n×n upper triangular matrix whose diagonal elements are all 1 and whose entries above the main diagonal are all −1:
Notice that detdet(A)=det(A−1)=1 and all the eigenvalues of A are 1. However, if n is large, then A is close to being singular. To see this, let
The matrix B must be singular, since the system Bx=0 has a nontrivial solution x=(2n−2,2n−3,…,20,1)T. Since the matrices A and B differ only in the (n,1) position, we have
It follows from Theorem 6.5.3 that
Thus, if n=100, then σn≤1/298 and, consequently, A is very close to singular.
∎
Example 4
Suppose that A is a 5×5 matrix with singular values
and suppose that the machine epsilon is 5×10−15. To determine the numerical rank, we compare the singular values to
Since three of the singular values are greater than 10−13, the matrix has numerical rank 3.
∎