
3 Before you model: Planning and scoping a project
- Defining effective planning strategies for ML project work
- Using efficient methods to evaluate potential solutions to an ML problem
The two biggest killers in the world of ML projects have nothing to do with what most data scientists ever imagine. These killers aren’t related to algorithms, data, or technical acumen. They have absolutely nothing to do with which platform you’re using, nor with the processing engine that will be optimizing a model. The biggest reasons for projects failing to meet the needs of a business are in the steps leading up to any of those technical aspects: the planning and scoping phases of a project.
Throughout most of the education and training that we receive leading up to working as a DS at a company, emphasis is placed rather heavily on independently solving complex problems. Isolating oneself and focusing on showing demonstrable skill in the understanding of the theory and application of algorithms trains us to have the expectation that the work we will do in industry is a solo affair. Given a problem, we figure out how to solve it.
The reality of life in a DS capacity couldn’t be further than the academic approach of proving one’s knowledge and skill in solving problems alone. This profession is, in actuality, far more than just algorithms and amassing knowledge of how to use them. It’s a highly collaborative and peer-driven field; the most successful projects are built by integrated teams of people working together, communicating throughout the process. Sometimes this isolation is imposed by company culture (intentionally walling off the team from the rest of the organization under the misguided intention of “protecting” the team from random requests for projects), and other times it is self-imposed.
This chapter covers why this paradigm shift that has ML teams focusing less on the how (algorithms, technology, and independent work) and more on the what (communication about and collaboration in what is being built) can make for a successful project. This shift helps reduce experimentation time, focus the team on building a solution that will work for the company, and plan out phased project work that incorporates SME knowledge from cross-functional teams to help dramatically increase the chances of a successful project.
The start of this inclusive journey, of bringing together as many people as possible to create a functional solution that works to solve a problem, is in the scoping phase. Let’s juxtapose an ML team’s workflow that has inadequate or absent scoping and planning (figure 3.1) with a workflow that includes proper scoping and planning (figure 3.2).
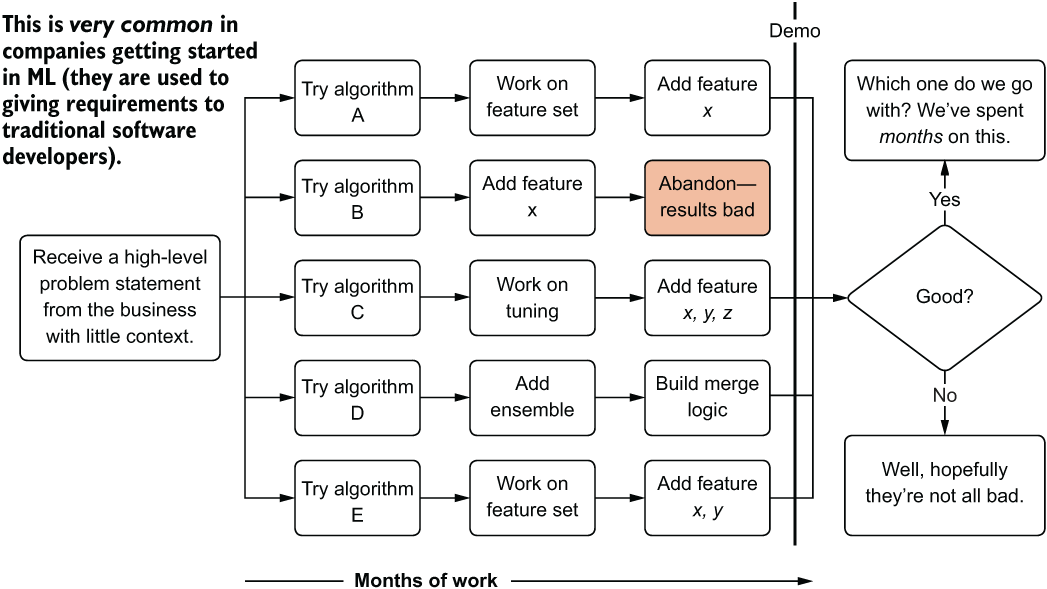
Figure 3.1 A lack of planning, improper scoping, and a lack of process around experimentation
Through absolutely no fault of their own (unless we want to blame the team for not being forceful with the business unit to get more information, which we won’t), these ML team members do their best to build several solutions to solve the vague requirements thrown their way. If they’re lucky, they’ll end up with four MVPs and several months of effort wasted on three that will never make it to production (a lot of wasted work). If they’re terribly unlucky, they’ll have wasted months of effort on nothing that solves the problem that the business unit wants solved. Either way, no good outcome results.
With the adequate scoping and planning shown in figure 3.2, the time spent building a solution is reduced considerably. The biggest reason for this change is that the team has fewer total approaches to validate (and all are time-boxed to two weeks), mostly because “early and often” feedback is received by the internal customer. Another reason is that at each phase of new feature development, a quick meeting and demonstration of the added functionality is shown for acceptance testing by the SMEs.
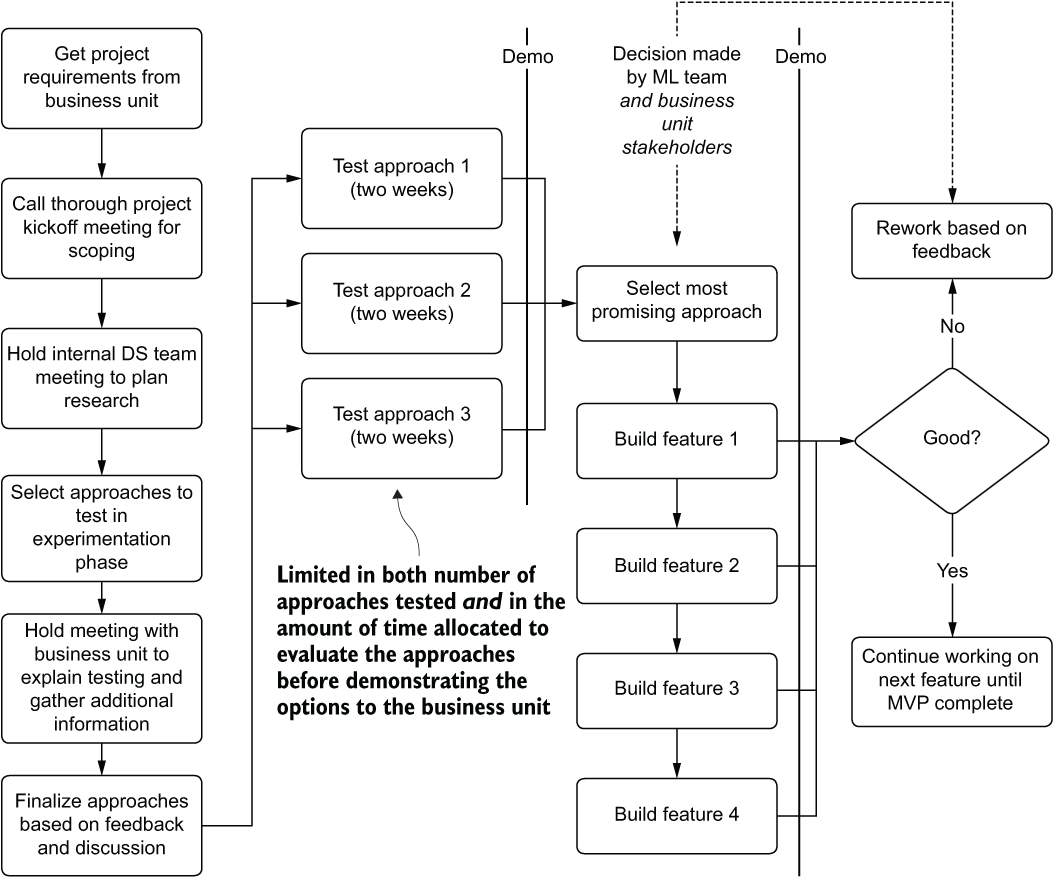
Figure 3.2 A thoroughly scoped, planned, and collaborative ML MVP project road map
To add to the substantial efficiency improvement, the other large benefit to this methodology of inclusiveness with the internal customer is a significantly increased probability of the end solution meeting the business’s expectations. Gone is the extreme risk shown in figure 3.1: delivering demonstrations of multiple solutions after months of work, only to find that the entire project needs to be restarted from scratch.
Throughout this chapter (and the next), we’ll go through approaches to help with these discussions, a rubric that I’ve used to guide these phases, and some lessons that I’ve learned after messing up this phase so many times.
3.1 Planning: You want me to predict what?!
Before we get into how successful planning phases for ML projects are undertaken, let’s go through a simulation of a typical project’s genesis at a company that doesn’t have an established or proven process for initiating ML work. Let’s imagine that we work at an e-commerce company that is just getting a taste for wanting to modernize its website.
After seeing competitors tout massive sales gains by adding personalization services to their websites for years, the C-level staff is demanding that the company needs to go all in on recommendations. No one in the C-suite is entirely sure of the technical details about how these services are built, but they all know that the first group to talk to is the ML nerds. The business (in this case, the sales department leadership, marketing, and product teams) calls a meeting, inviting the entire ML team, with little added color to the invitation apart from the title, “Personalized Recommendations Project Kickoff.”
Management and the various departments that you’ve worked with have been happy with the small-scale ML projects that your team has built (fraud detection, customer valuation estimation, sales forecasting, and churn probability risk models). Each of the previous projects, while complex in various ways from an ML perspective, were largely insular—handled within the ML team, which came up with a solution that could be consumed by the various business units. None of these projects required subjective quality estimations or excessive business rules to influence the results. The mathematical purity of these solutions simply was not open to argument or interpretation; either they were right, or they were wrong.
Victims of your own success, the team is approached by the business with a new concept: modernizing the website and mobile applications. The executives have heard about the massive sales gains and customer loyalty that comes along with personalized recommendations, and they want your team to build a system for incorporation to the website and the apps. They want each and every user to see a unique list of products greet them when they log in. They want these products to be relevant and interesting to the user, and, at the end of the day, they want to increase the chances that the user will buy these items.
After a brief meeting during which examples from other websites are shown, they ask how long it will be before the system will be ready. You estimate about two months, based on the few papers that you’ve read in the past about these systems, and set off to work. The team creates a tentative development plan during the next scrum meeting, and everyone sets off to try to solve the problem.
You and the rest of the ML team assume that management is looking for the behavior shown in so many other websites, in which products are recommended on a main screen. That, after all, is personalization in its most pure sense: a unique collection of products that an algorithm has predicted will have relevance to an individual user. This approach seems pretty straightforward, you all agree, and the team begins quickly planning how to build a dataset that shows a ranked list of product keys for each of the website’s and mobile app’s users, based solely on the browsing and purchase history of each member.
For the next several sprints, you all studiously work in isolation. You test dozens of implementations that you’ve seen in blog posts, consume hundreds of papers’ worth of theory on different algorithms and approaches to solving an implicit recommendation problem, and finally build out an MVP solution using alternating least squares (ALS) that achieves a root mean squared error (RMSE) of 0.2334, along with a rough implementation of ordered scoring for relevance based on prior behavior.
Brimming with confidence that you have something amazing to show the business team sponsor, you head to the meeting armed with the testing notebook, graphs showing the overall metrics, and sample inference data that you believe will truly impress the team. You start by showing the overall scaled score rating for affinity, displaying the data as an RMSE plot, as shown in figure 3.3.
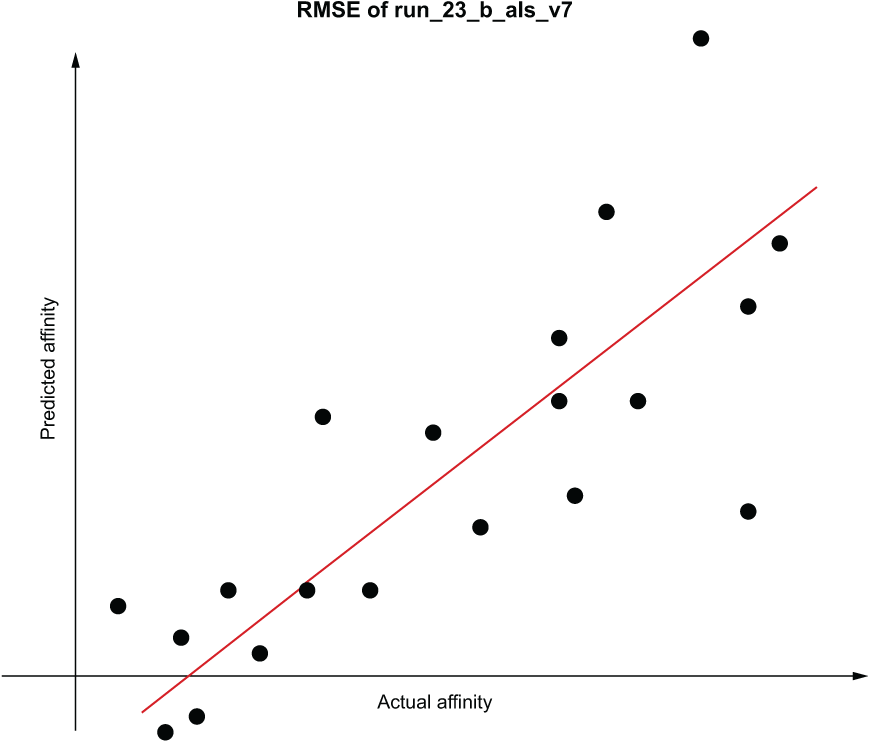
Figure 3.3 A fairly standard loss chart of RMSE for the affinity scores to their predicted values
The response to showing the chart is lukewarm at best. A bevy of questions arise, focused on what the data means, what the line that intersects the dots means, and how the data was generated. Instead of a focused discussion about the solution and the next phase you’d like to be working on (increasing the accuracy), the meeting begins to devolve into a mix of confusion and boredom. In an effort to better explain the data, you show a quick table of rank effectiveness using non-discounted cumulative gain (NDCG) metrics to illustrate the predictive power of a single user chosen at random, as shown in figure 3.4.
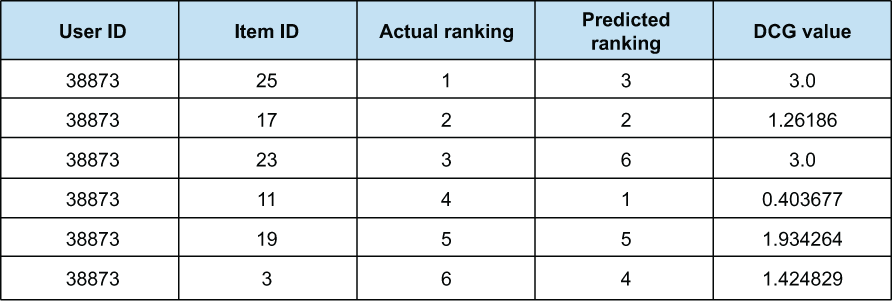
Figure 3.4 NDCG calculations for a recommendation engine for a single user. With no context, presenting raw scores like this will do nothing beneficial for the DS team.
The first chart created a mild sense of perplexity, but the table brings complete and total confusion. No one understands what is being shown or can see the relevance to the project. The only thing on everyone’s mind is, “Is this really what weeks of effort can bring? What has the data science team been doing all this time?”
During the DS team’s explanation of the two visualizations, one of the marketing analysts begins looking up the product recommendation listing for one of the team members’ accounts in the sample dataset provided for the meeting. Figure 3.5 illustrates the results along with the marketing analyst’s thoughts while bringing up the product catalog data for each recommendation in the list.
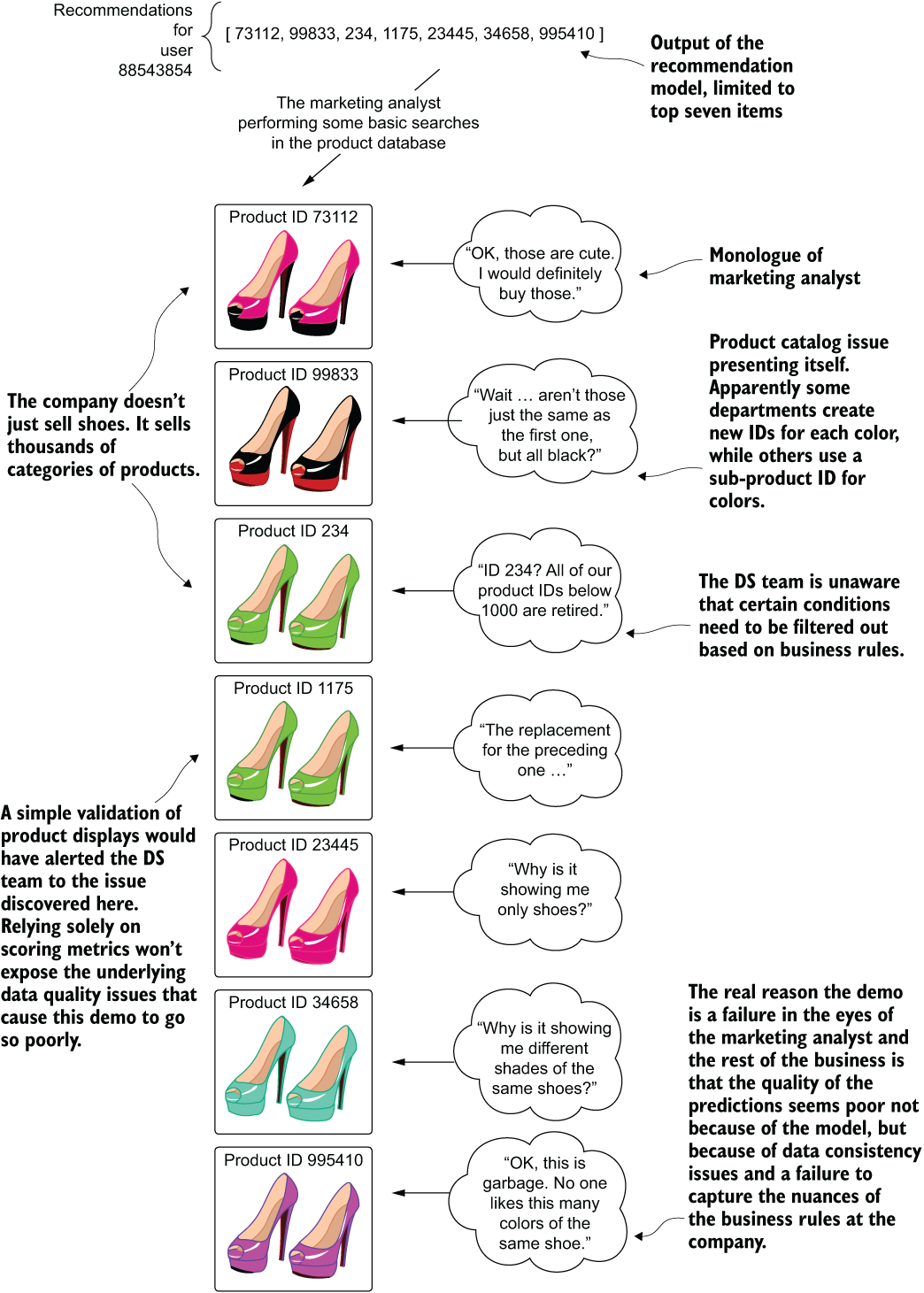
Figure 3.5 Using visual simulation for SME qualitative acceptance testing
The biggest lesson that the DS team learns from this meeting is not, in fact, the necessity of validating the results of its model in a way that would simulate the way an end user of the predictions would react. Although an important consideration, and one that is discussed in the following sidebar, it is trumped quite significantly by the realization that the reason that the model was received so poorly is that the team didn’t properly plan for the nuances of this project.
The DS team simply hadn’t understood the business problem from the perspective of the other team members in the room who knew where all of the proverbial “bodies were buried” in the data and who have cumulative decades of knowledge around the nature of the data and the product. The onus of this failure doesn’t rest solely on the project manager, the DS team lead, or any single team member. Rather, this is a collective failure of every member of the broader team in not thoroughly defining the scope and details of the project. How could they have done things differently?
The analyst who looked up their own predictions for their account uncovered a great many problems that were obvious to them. They saw the duplicated item data due to the retiring of older product IDs and likewise instantly knew that the shoe division used a separate product ID for each color of a style of shoe, both core problems that caused a poor demo. All of the issues found, causing a high risk of project cancellation, were due to improper planning of the project.
3.1.1 Basic planning for a project
The planning of any ML project typically starts at a high level. A business unit, executive, or even a member of the DS team comes up with an idea of using the DS team’s expertise to solve a challenging problem. While typically little more than a concept at this early stage, this is a critical juncture in a project’s life cycle.
In the scenario we’ve been discussing, the high-level idea is personalization. To an experienced DS, this could mean any number of things. To an SME of the business unit, it could mean many of the same concepts that the DS team could think of, but it may not. From this early point of an idea to before even basic research begins, the first thing everyone involved in this project should be doing is having a meeting. The subject of this meeting should focus on one fundamental element: Why are we building this?
It may sound like a hostile or confrontational question to ask. It may take some people aback when hearing it. However, it’s one of the most effective and important questions, as it opens a discussion into the true motivations for why people want the project to be built. Is it to increase sales? Is it to make our external customers happier? Or is it to keep people browsing on the site for longer durations?
Each of these nuanced answers can help inform the goal of this meeting: defining the expectations of the output of any ML work. The answer also satisfies the measurement metric criteria for the model’s performance, as well as attribution scoring of the performance in production (the very score that will be used to measure A/B testing much later).
In our example scenario, the team fails to ask this important why question. Figure 3.6 shows the divergence in expectations from the business side and the ML side because neither group is speaking about the essential aspect of the project and is instead occupied in mental silos of their own creating. The ML team is focusing entirely on how to solve the problem, while the business team has expectations of what would be delivered, wrongfully assuming that the ML team will “just understand it.”
Figure 3.6 sums up the planning process for the MVP. With extremely vague requirements, a complete lack of thorough communication about expectations for the prototype’s minimum functionality, and a failure to reign in the complexity of experimentation, the demonstration is considered an absolute failure. Preventing outcomes like this can be achieved only in these early meetings when the project’s ideas are being discussed. Widening the overlap between these regions of expectation gap is the responsibility of the DS team lead and project manager. At the conclusion of planning meetings, an ideal state is alignment of everyone’s expectations (without anyone focusing on implementation details or specific out-of-scope functionality to potentially be added in the future).
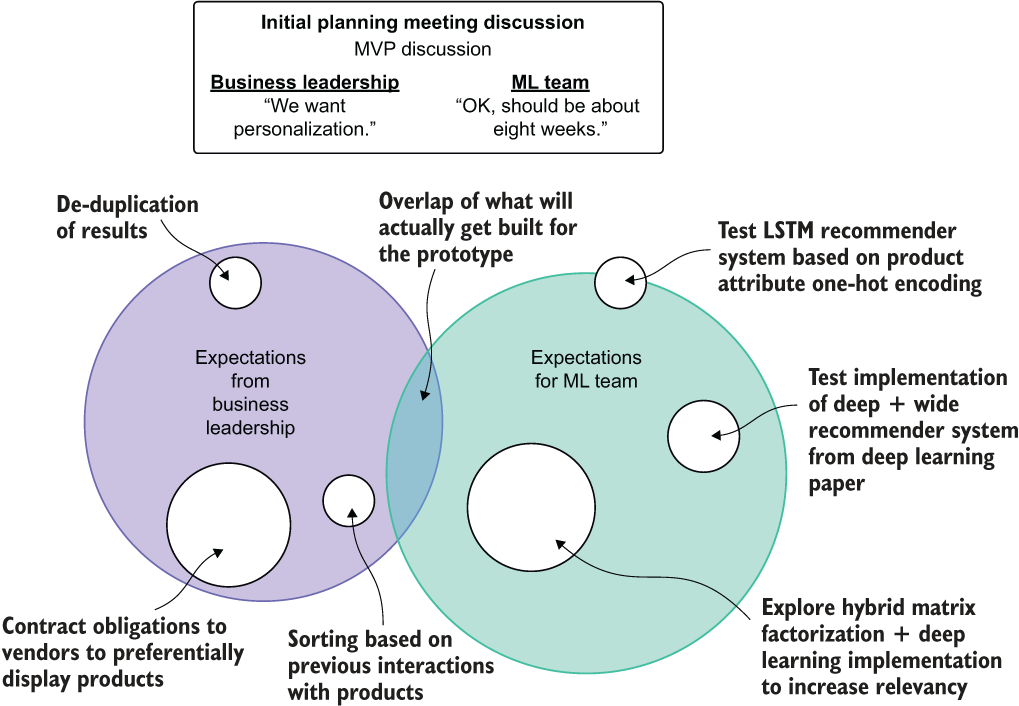
Figure 3.6 Project expectation gap driven by ineffective planning discussions
Continuing with this scenario, let’s look at the MVP demonstration feedback discussion to see the sorts of questions that could have been discussed during that early planning and scoping meeting. Figure 3.7 shows the questions and the underlying root causes of the present misunderstandings.
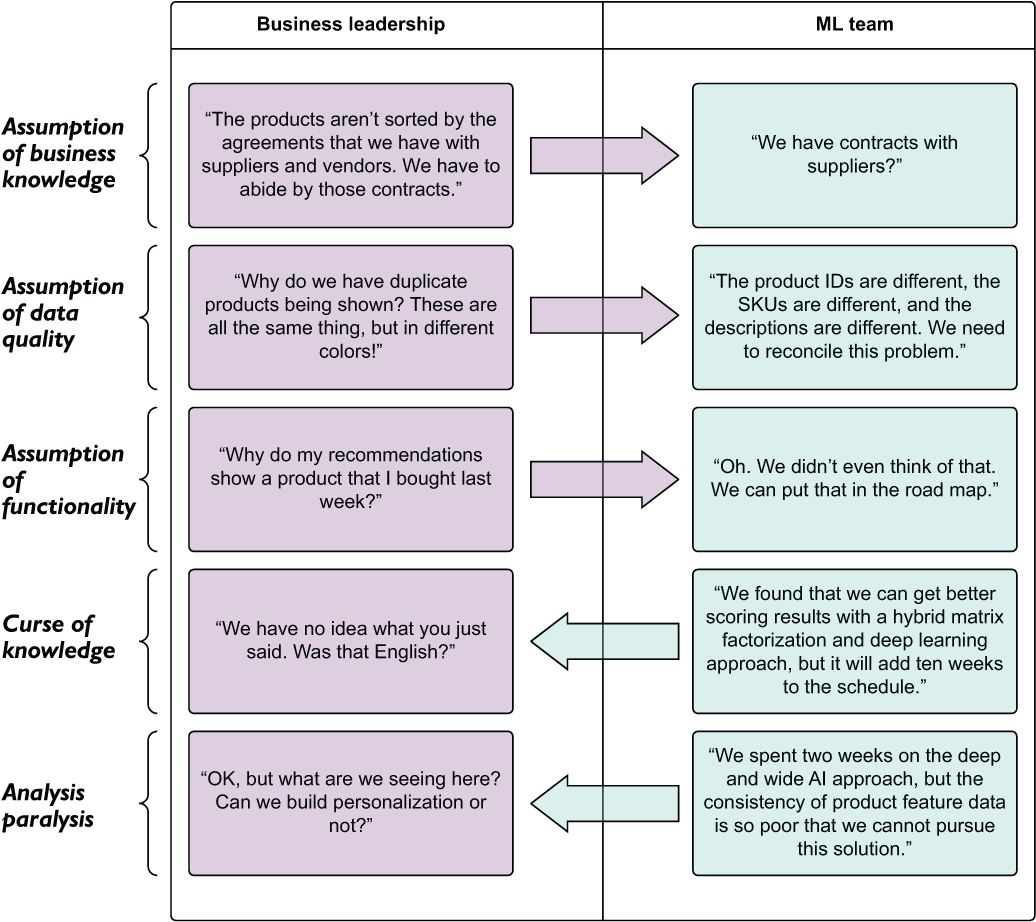
Figure 3.7 The results of the MVP presentation demo. Questions and their subsequent discussions could have happened during the planning phase to prevent all five core issues that are shown.
Although this example is intentionally hyperbolic, I’ve found elements of this confusion present in many ML projects (those outside of primarily ML-focused companies), and this is to be expected. The problems that ML is frequently intended to solve are complex, full of details that are specific and unique to each business (and business unit within a company), and fraught with disinformation surrounding the minute nuances of these details.
It’s important to realize that these struggles are going to be an inevitable part of any project. The best way to minimize their impact is to have a thorough series of discussions that aim to capture as many details about the problem, the data, and the expectations of the outcome as possible.
Assumption of business knowledge
Assumption of business knowledge is a challenging issue, particularly for a company that’s new to utilizing ML, or for a business unit at a company that has never worked with its ML team before. In our example, the business leadership’s assumption was that the ML team knew aspects of the business that the leadership considered widely held knowledge. Because no clear and direct set of requirements was set out, this assumption wasn’t identified as a clear requirement. With no SME from the business unit involved in guiding the ML team during data exploration, there simply was no way for them to know this information during the process of building the MVP either.
An assumption of business knowledge is often a dangerous path to tread for most companies. At many companies, the ML practitioners are insulated from the inner workings of a business. With their focus mostly in the realm of providing advanced analytics, predictive modeling, and automation tooling, scant time can be devoted to understanding the nuances of how and why a business is run. While some obvious aspects of the business are known by all (for example, “we sell product x on our website”), it is not reasonable to expect that the modelers should know that a business process exists in which some suppliers of goods would be promoted on the site over others.
A good solution for arriving at these nuanced details is to have an SME from the group that is requesting a solution be built for them (in this case, the product marketing group) explain how they decide the ordering of products on each page of the website and app. Going through this exercise would allow for everyone in the room to understand the specific rules that may be applied to govern the output of a model.
The onus of duplicate product listings in the demo output is not entirely on either team. While the ML team members certainly could have planned for this to be an issue, they weren’t aware of it precisely in the scope of its impact. Even had they known, they likely would have wisely mentioned that correcting for this issue would not be a part of the demo phase (because of the volume of work required and the request that the prototype not be delayed for too long).
The principal issue here is in not planning for it. By not discussing the expectations, the business leaders’ confidence in the capabilities of the ML team erodes. The objective measure of the prototype’s success will largely be ignored as the business members focus solely on the fact that for a few users’ sample data, the first 300 recommendations show nothing but 4 products in 80 available shades and patterns.
For our use case, the ML team believed that the data they were using was, as told to them by the DE team, quite clean. Reality, for most companies, is a bit more dire than what most would think when it comes to data quality. Figure 3.8 summarizes two industry studies, conducted by IBM and Deloitte, indicating that thousands of companies are struggling with ML implementations, specifically noting problems with data cleanliness. Checking data quality before working on models is pretty important.
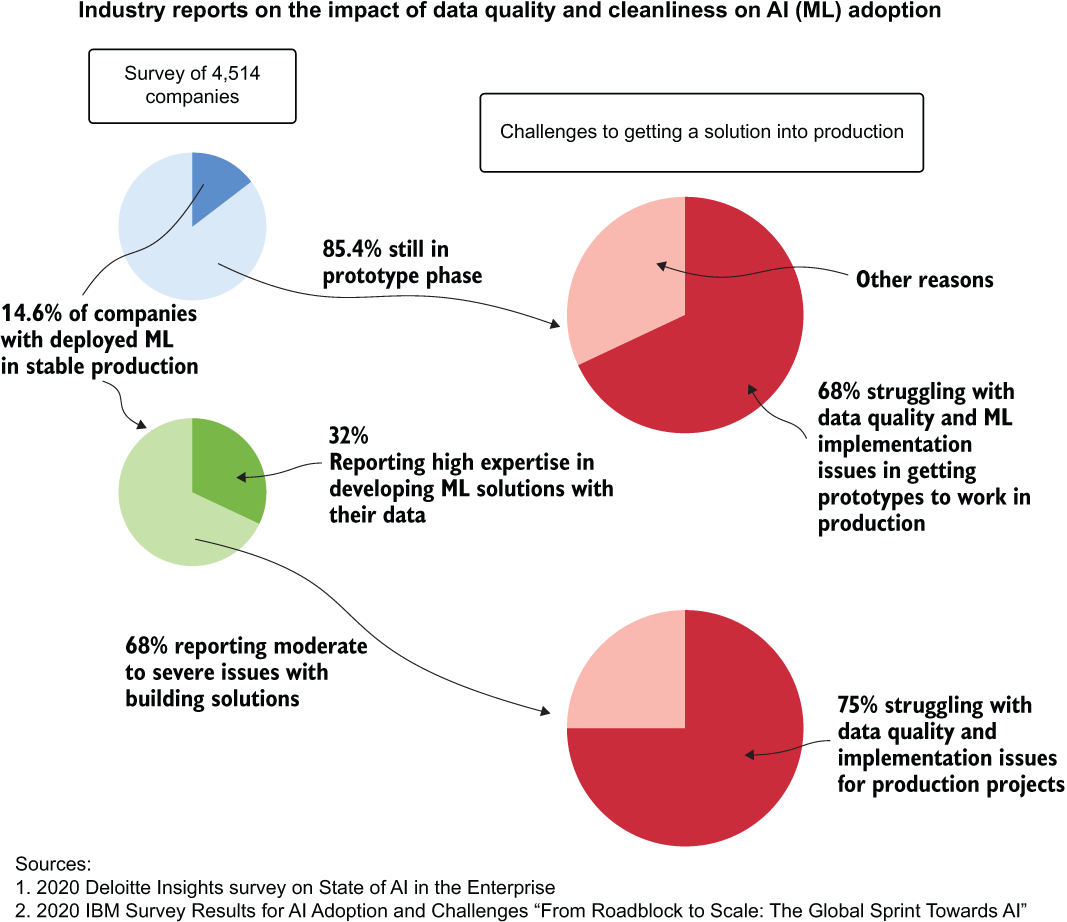
Figure 3.8 The impact of data quality issues on companies engaging in ML project work. Data quality issues are common, and as such, should always be vetted during the early stages of project work.
It’s not important to have “perfect” data. Even the companies in figure 3.8 that are successful in deploying many ML models to production still struggle with data quality issues regularly (75% as reported). These problems with data are just a byproduct of the frequently incredibly complex systems that are generating the data, years (if not decades) of technical debt, and the expense associated with designing “perfect” systems that do not allow an engineer to generate problematic data. The proper way to handle these known problems is to anticipate them, validate the data that will be involved in any project before modeling begins, and ask questions about the nature of the data to the SMEs who are most familiar with it.
For our recommendation engine, the ML team members failed to not only ask questions about the nature of the data that they were modeling (namely, “Do all products get registered in our systems in the same way?”), but also validate the data through analysis. Pulling quick statistical reports may have uncovered this issue quite clearly, particularly if the unique product count of shoes was orders of magnitude higher than any other category. “Why do we sell so many shoes?,” posed during a planning meeting, could have instantly uncovered the need to resolve this issue, but also resulted in a deeper inspection and validation of all product categories to ensure that the data going into the models was correct.
In this instance, the business leaders are concerned that the recommendations show a product that was purchased the week before. Regardless of the type of product (consumable or not), the planning failure here is in expressing how off-putting this would be to the end user to see this happen.
The ML team’s response of ensuring that this key element needs to be a part of the final product is a valid response. At this stage of the process, while it is upsetting to see results like this from the perspective of the business unit, it’s nearly inevitable. The path forward in this aspect of the discussion should be to scope the feature addition work, make a decision on whether to include it in a future iteration, and move on to the next topic.
To this day, I have not worked on an ML project where this has not come up during a demo. Valid ideas for improvements always come from these meetings—that’s one of the primary reasons to have them, after all: to make the solution better! The worst things to do are either dismiss them outright or blindly accept the implementation burden. The best thing to do is to present the cost (time, money, and human capital) for the addition of the improvement and let the internal customer decide if it’s worth it.
The ML team, in this discussion point, instantly went “full nerd.” Chapter 4 covers the curse of knowledge at length, but for now, realize that, when communicating, the inner details of things that have been tested will always fall on deaf ears. Assuming that everyone in a room understands the finer details of a solution as anything but a random collection of pseudo-scientific buzzword babble is doing a disservice to yourself as an ML practitioner (you won’t get your point across) and to the audience (they will feel ignorant and stupid, frustrated that you assume that they would know such a specific topic).
The better way to discuss your numerous attempts at solutions that didn’t pan out: simply speak in as abstract terms as possible: “We tried a few approaches, one of which might make the recommendations much better, but it will add a few months to our timeline. What would you like to do?”
Handling complex topics in a layperson context will always work much better than delving into deep technical detail. If your audience is interested in a more technical discussion, gradually ease into deeper technical aspects until the question is answered. It’s never a good idea to buffalo your way through an explanation by speaking in terms that you can’t reasonably expect them to understand.
Without proper planning, the ML team will likely just experiment on a lot of approaches, likely the most state-of-the-art ones that they can find in the pursuit of providing the best possible recommendations. Without focusing on the important aspects of the solution during the planning phase, this chaotic approach of working solely on the model purity can lead to a solution that misses the point of the entire project.
After all, sometimes the most accurate model isn’t the best solution. Most of the time, a good solution is one that incorporates the needs of the project, and that generally means keeping the solution as simple as possible to meet those needs. Approaching project work with that in mind will help alleviate the indecisions and complexity that can arise from trying to choose the best model.
3.1.2 That first meeting
As we discussed earlier, our example ML team approached planning in a problematic way. How did the team get to that state of failing to communicate what the project should focus on, though?
While everyone on the ML team was quietly thinking about algorithms, implementation details, and where to get the data to feed into the model, they were too consumed to ask the questions that should have been posited. No one was asking details about the way the implementation should work, the types of restrictions needing to be in place on the recommendations, or whether products should be displayed in a certain way within a sorted ranked collection. They were all focused on the how instead of the why and what.
Conversely, the internal marketing team members bringing the project to the ML team did not clearly discuss their expectations. With no malicious intent, their ignorance of the methodology of developing this solution, coupled with their intense knowledge of the customer and the way they want the solution to behave, created a perfect recipe for a perfect implementation disaster.
How could this have been handled differently? How could that first meeting have been orchestrated to ensure that the greatest number of hidden expectations that the business unit team members hold (as we discussed in section 3.1.1) can be openly discussed in the most productive way? It can be as easy as starting with a single question: “What do you do now to decide which products to display in which places?” In figure 3.9, let’s look at what posing that question may have revealed and how it could have informed the critical feature requirements that should have been scoped for the MVP.
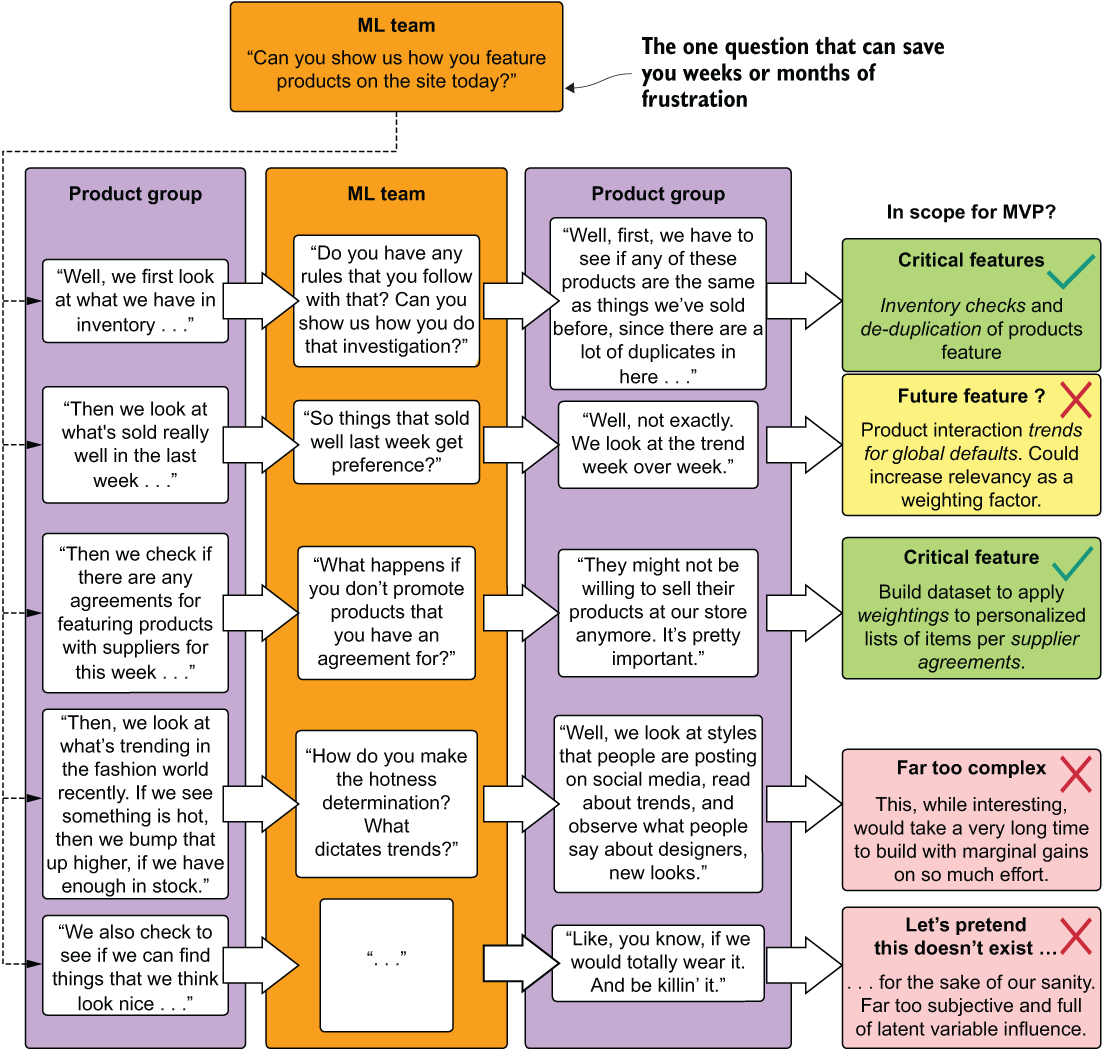
Figure 3.9 An example scoping and planning meeting that focuses on the problem to define features
As you can see, not every idea is a fantastic one. Some are beyond the scope of budget (time, money, or both). Others are simply beyond the limits of our technical capabilities (the “things that look nice” request). The important thing to focus on, though, is that two key critical features were identified, and a potential additive future feature that can be put in the backlog for the project.
Although this figure’s dialogue may appear to be quite caricatural, this is a nearly verbatim transcription of an actual meeting I was part of. Although I was stifling laughter a few times at some of the requests, I found the meeting to be invaluable. Spending a few hours discussing all of the possibilities that SMEs see was able to give me and my team a perspective that we hadn’t considered, in addition to revealing key requirements about the project that we never would have guessed or assumed without hearing them from the team.
The one thing to make sure to avoid in these discussions is speaking about the ML solution. Keep notes so that you and fellow DS team members can discuss later. It’s critical that you don’t drag the discussion away from the primary point of the meeting (gaining insight into how the business solves the problem currently).
One of the easiest ways to approach this subject is, as shown in the following sidebar, by asking how the SMEs currently solve the problem. Unless the project is an entirely greenfield moon-shot project, someone is probably solving it in some way or another. You should talk to them. This methodology is precisely what informed the line of questioning and discussion in figure 3.9.
We’ll discuss the process of planning and examples of setting periodic ideation meetings later in this chapter in much more depth.
3.1.3 Plan for demos—lots of demos
Yet another cardinal sin that the ML team members violated in presenting their personalization solution to the business was attempting to show the MVP only once. Perhaps their sprint cadence was such that they couldn’t generate a build of the model’s predictions at times that were convenient, or they didn’t want to slow their progress toward having a true MVP to show to the business. Whatever the reason, the team members actually wasted time and effort while trying to save time and effort. They were clearly in the top portion of figure 3.10.
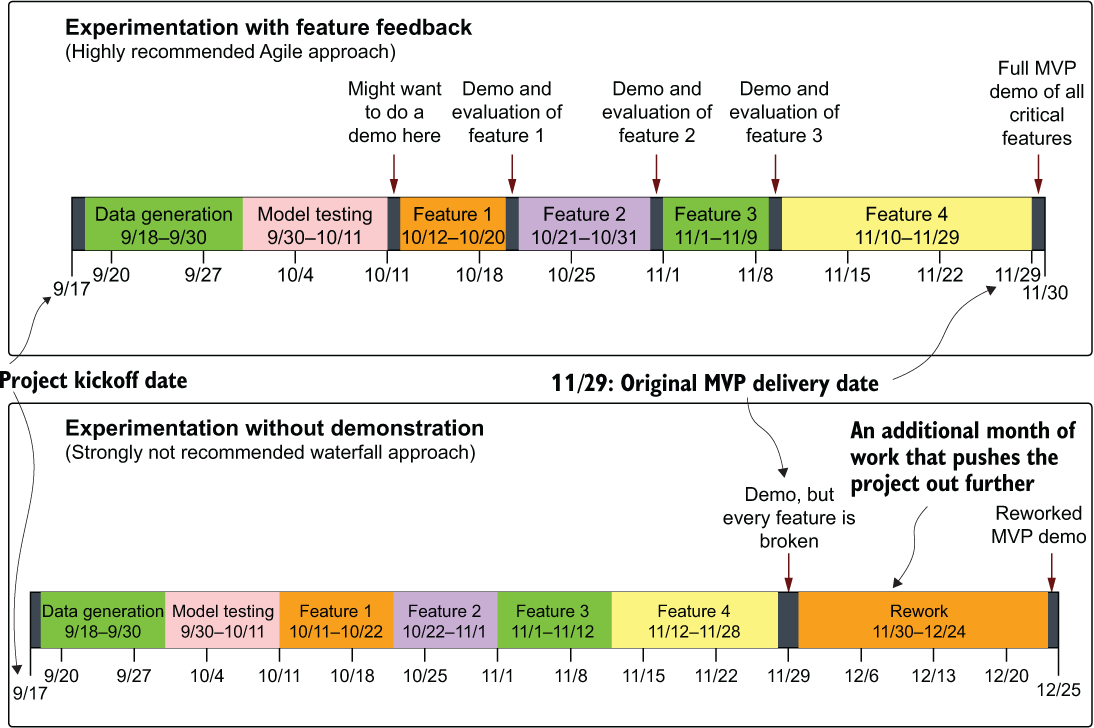
Figure 3.10 Timeline comparison of feedback-focused demo-heavy project work and internal-only focused development. While the demonstrations take time and effort, the rework that they save is invaluable.
In the top scenario (frequent demonstrations of each critical feature), some amount of rework is likely associated with each feature after the demonstrations. Not only is this to be expected, but the amount of time required to adjust features when approached in this Agile methodology is reduced, since fewer tightly coupled dependencies exist when compared with the rework needed for the bottom develop-in-a-vacuum approach.
Even though Agile practices were used within the ML team, to the marketing team, the MVP presentation was the first demo that they had seen in two months of work. At no point in those two months did a meeting take place to show the current state of experimentation, nor was any plan communicated about the cadence of seeing results from the modeling efforts.
Without frequent demos as features are built out, the team at large is simply operating in the dark with respect to the ML aspect of the project. The ML team, meanwhile, is missing out on valuable time-saving feedback from SME members who would be able to halt feature development and help refine the solution.
For most projects involving ML of sufficient complexity, far too many details and nuances exist to confidently approach building out dozens of features without having them reviewed. Even if the ML team is showing metrics for the quality of the predictions, aggregate ranking statistics that “conclusively prove” the power and quality of what they’re building, the only people in the room who care about that are the ML team. To effectively produce a complex project, the SME group—the marketing group—needs to provide feedback based on data it can consume. Presenting arbitrary or complex metrics to that team is bordering on intentional obtuse obfuscation, which will only hinder the project and stifle the critical ideas required to make the project successful.
By planning for demos ahead of time, at particular cadences, the ML-internal Agile development process can adapt to the needs of the business experts to create a more relevant and successful project. The ML team members can embrace a true Agile approach: testing and demonstrating features as they are built, adapting their future work, and adjusting elements in a highly efficient manner. They can help ensure that the project will actually see the light of day.
3.1.4 Experimentation by solution building: Wasting time for pride’s sake
Looking back at the unfortunate scenario of the ML team members building a prototype recommendation engine for the website personalization project, their process of experimentation was troubling, but not only for the business. Without a solid plan in place for what they would be trying and how much time and effort they would be spending on the different solutions they agreed on pursuing, a great deal of time (and code) was unnecessarily thrown away.
Coming out of their initial meeting, they went off on their own as a team, beginning their siloed ideation meeting by brainstorming about which algorithms might best be suited for generating recommendations in an implicit manner. About 300 or so web searches later, they came up with a basic plan of doing a head-to-head comparison of three main approaches: an ALS model, a singular value decomposition (SVD) model, and a deep learning recommendation model. Having an understanding of the features required to meet the minimum requirements for the project, three separate groups began building what they could in a good-natured competition.
The biggest flaw in approaching experimentation in this way is in the sheer scope and size of the waste involved in doing bake-offs like this. Approaching a complex problem by way of a hackathon-like methodology might seem fun to some, not to mention being far easier to manage from a process perspective by the team lead (you’re all on your own—whoever wins, we go with that!), but it’s an incredibly irresponsible way to develop software.
This flawed concept, solution building during experimentation, is juxtaposed with the far more efficient (but, some would argue, less fun) approach of prototype experimentation in figure 3.11. With periodic demos, either internally to the ML team or to the broader external cross-functional team, the project’s experimentation phase can be optimized to have more hands (and minds) focused on getting the project as successful as it can be as fast as possible.
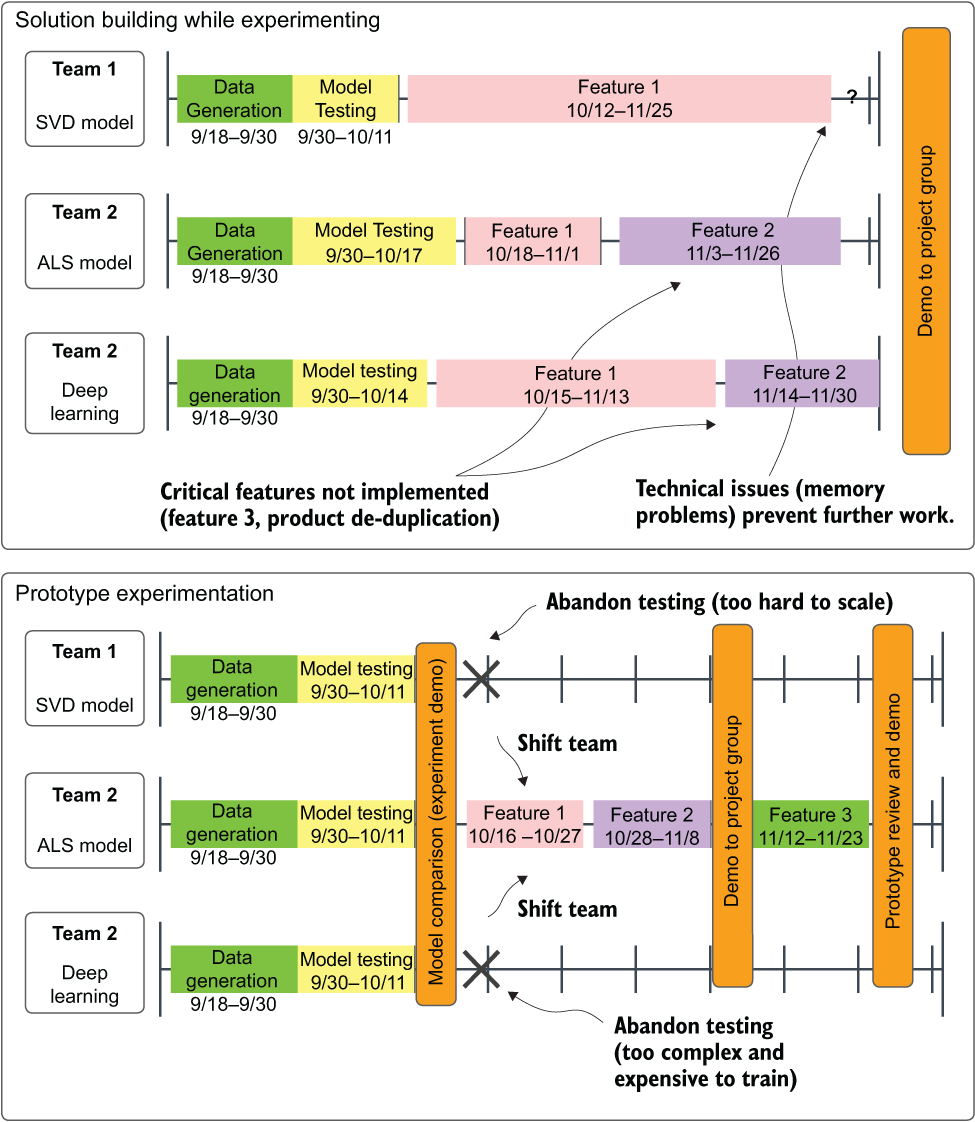
Figure 3.11 Comparison of multiple-MVP development (top) and experimentation culling development (bottom). By culling options early, more work (at a higher quality and in less time) can get done by the team.
As shown in the top section of figure 3.11, approaching the problem of a model bake-off without planning for prototype culling runs two primary risks. First, in the top portion, Team A had difficulty incorporating the first primary feature that the business dictated was critical.
Since no evaluation was done after the initial formulation of getting the model to work, a great deal of time was spent trying to get the feature built out to support the requirements. After that was accomplished, when moving on to the second most critical feature, the team members realized that they couldn’t implement the feature in enough time for the demo meeting, effectively guaranteeing that all of the work put into the SVD model would be thrown away.
Teams using the other two approaches, both short-staffed on the implementation of their prototypes, were unable to complete the third critical feature. As a result, none of the three approaches would satisfy the critical project requirements. This delay to the project, due to its multidiscipline nature, affects other engineering teams. What the team should have done instead was follow the path of the bottom Prototype Experimentation section.
In this approach, the teams met with the business units early, communicating ahead of time that the critical features wouldn’t be in at this time. They chose instead to make a decision on the raw output of each model type that was under testing. After deciding to focus on a single option, the entire ML team’s resources and time could be focused on implementing the minimum required features (with an added check-in demo between the presentation of the core solution to ensure that they were on the right track) and get to the prototype evaluation sooner.
Focusing on early and frequent demos, even though features weren’t fully built out yet, helped both maximize staff resources and get valuable feedback from the SMEs. In the end, all ML projects are resource-constrained. By narrowly focusing on the fewest and most potentially successful options as early as possible, even a lean set of resources can create successful complex ML solutions.
3.2 Experimental scoping: Setting expectations and boundaries
We’ve now been through planning of the recommendation engine. We have the details of what is important to the business, we understand what the user expects when interacting with our recommendations, and we have a solid plan for the milestones for our presentations at certain dates throughout the project. Now it’s time for the fun part for most of us ML nerds. It’s time to plan our research.
With an effectively limitless source of information at our fingertips on the topic, and only so much time to do it, we really should be setting guidelines on what we’re going to be testing and how we’re going to go about it. This is where scoping of experimentation comes into play.
The team should, by this time, having had the appropriate discovery sessions with the SME team members, know the critical features that need to get built:
- We need a way to de-duplicate our product inventory.
- We need to incorporate product-based rules to weight implicit preferences per user.
- We need to group recommendations based on product category, brand, and specific page types in order to fulfill different structured elements on the site and app.
- We need an algorithm that will generate user-to-item affinities that won’t cost a fortune to run.
After listing out the absolutely critical aspects for the MVP, the team can begin planning the work estimated to be involved in solving each of these four critical tasks. Through setting these expectations and providing boundaries on each of them (for both time and level of implementation complexity), the ML team can provide the one thing that the business is seeking: an expected delivery date and a judgment call on what is or isn’t feasible.
This may seem a bit oxymoronic to some. “Isn’t experimentation where we figure out how to scope the project from an ML perspective?” is likely the very thought that is coursing through your head right now. We’ll discuss throughout this section why, if left without boundaries, the research and experimentation on solving this recommendation engine problem could easily fill the entire project-scoping timeline. If we plan and scope our experimentation, we’ll be able to focus on finding, perhaps not the best solution, but hopefully a good enough solution to ensure that we’ll eventually get a product built out of our work.
Once the initial planning phase is complete (which certainly will not happen from just a single meeting), and a rough idea of what the project entails is both formulated and documented, there should be no talk about scoping or estimating how long the actual solution implementation will take, at least not initially. Scoping is incredibly important and is one of the primary means of setting expectations for a project team as a whole, but even more critical for the ML team. However, in the world of ML (which is very different from other types of software development because of the complexity of most solutions), two distinct scopings need to happen.
For people who are accustomed to interactions with other development teams, the idea of experimental scoping is completely foreign, and as such, any estimations for the initial phase scoping will be misinterpreted. With this in mind, however, it’s certainly not wise to not have an internal target scoping for experimentation.
3.2.1 What is experimental scoping?
Before you can begin to estimate how long a project is going to take, you need to research not only how others have solved similar problems but also potential solutions from a theoretical point of view. With the scenario that we’ve been discussing, the initial project planning and overall scoping (the requirements gathering), a number of potential approaches were decided on. When the project then moves into the phase of research and experimentation, it is absolutely critical to set an expectation with the larger team of how long the DS team will spend on vetting each of those ideas.
Setting expectations benefits the DS team. Although it may seem counterproductive to set an arbitrary deadline on something that is wholly unknowable (which is the best solution), having a target due date can help focus the generally disorganized process of testing. Elements that under other circumstances might seem interesting to explore are ignored and marked as “”will investigate during MVP development” with the looming deadline approaching. This approach simply helps focus the work.
The expectations similarly help the business and the cross-functional team members involved in the project. They will gain not only a decision on project direction that has a higher chance of success in the end, but also a guarantee of progress in the near-term future. Remember that communication is absolutely essential to successful ML project work, and setting delivery goals even for experimentation will aid in continuing to involve everyone in the process. It will only make the end result better.
For relatively simple and straightforward ML use cases (forecasting, outlier detection, clustering, and conversion prediction, for example), the amount of time dedicated to testing approaches should be relatively short. One to two weeks is typically sufficient for exploring potential solutions for standard ML; remember, this isn’t the time to build an MVP, but rather to get a general idea of the efficacy of different algorithms and methodologies.
For a far more complex use case, such as this scenario, a longer investigation period can be warranted. Two weeks alone may be needed to devote simply to the research phase, with an additional two weeks of “hacking” (roughshod scripting of testing APIs, libraries, and building crude visualizations).
The sole purpose of these phases is to decide on a path, but to make that decision in the shortest amount of time practicable. The challenge is to balance the time required to make the best adjudication possible for the problem against the timetable of delivery of the MVP.
No standard rubric exists for figuring out how long this period should be, as it is dependent on the problem, the industry, the data, the experience of the team, and the relative complexity of each option being considered. Over time, a team will gain the wisdom that will make for more accurate experimental (“hacking”) estimates. The most important point to remember is that this stage, and the communication to the business unit of how long it will take, should never be overlooked.
3.2.2 Experimental scoping for the ML team: Research
In the heart of all ML practitioners is the desire to experiment, explore, and learn new things. With the depth and breadth of all that exists in the ML space, we could spend a lifetime learning only a fraction of what has been done, is currently being researched, and will be worked on as novel solutions to complex problems. This innate desire shared among all of us means that it is of the utmost importance to set boundaries around how long and how far we will go when researching a solution to a new problem.
In the first stages following the planning meetings and general project scoping, it’s now time to start doing some actual work. This initial stage, experimentation, can vary quite significantly among projects and implementations, but the common theme for the ML team is that it must be time-boxed. This can feel remarkably frustrating for many of us. Instead of focusing on researching a novel solution to something from the ground up, or utilizing a new technique that’s been recently developed, sometimes we are forced into a “just get it built” situation. A great way to meet that requirement of time-bound urgency is to set limits on how much time the ML team has to research possibilities for solutions.
For the recommendation engine project that we’ve been discussing in this chapter, a research path for the ML team might look something like figure 3.12.

Figure 3.12 Research planning phase diagram for an ML team determining potential solutions to pursue testing. Defining structured plans such as this can dramatically reduce the time spent iterating on ideas.
In this simplified diagram, effective research constrains the options available to the team. After a few cursory internet searches, blog readings, and whitepaper consultations, the team can identify (typically in a day or so) the “broad strokes” for existing solutions in industry and academia.
Once the common approaches are identified (and individually curated by the team members), a full list of possibilities can be researched in more depth. Once this level of applicability and complexity is arrived at, the team can meet and discuss its findings
As figure 3.12 shows, the approaches that are candidates for testing are culled during the process of presenting findings. By the end of this adjudication phase, the team should have a solid plan of two or three options that warrant testing through prototype development.
Note the mix of approaches that the group selects. Within the selections is sufficient heterogeneity that will help aid the MVP-based decision later (if all three options are slight variations on deep learning approaches, for instance, it will be hard to decide which to go with in some circumstances).
The other key action is whittling down the large list of options to help prevent the chances of either over-choice (a condition in which making a decision is almost paralyzing to someone because of the overabundance of options) or the Tyranny of Small Decisions (in which an accumulation of many small, seemingly insignificant choices made in succession can lead to an unfavorable outcome). It is always best, in the interests of both moving a project along and in creating a viable product at the end of the project, to limit the scope of experimentation.
The final decision in figure 3.12, based on the team’s research, is to focus on three separate solutions (one with a complex dependency): ALS, SVD, and a deep learning (DL) solution. Once these paths have been agreed upon, the team can set out to attempt to build prototypes. Just as with the research phase, the experimentation phase is time-boxed to permit only so much work to be done, ensuring that a measurable result can be produced at the conclusion of the experimentation.
3.2.3 Experimental scoping for the ML team: Experimentation
With a plan in place, the ML team lead is free to assign resources to the prototype solutions. At the outset, it is important to be clear about the expectations from experimentation. The goal is to produce a simulation of the end product that allows for an unbiased comparison of the solutions being considered. There is no need for the models to be tuned, nor for the code to be written in such a way that it could ever be considered for use in the final project’s code base. The name of the game here is a balance between two primary goals: speed and comparability.
A great many things need to be considered when deciding which approach to take, and these are discussed at length in several later chapters. But for the moment, the critical estimation at this stage is about the performance of the solutions as well as the difficulty of developing the full solution. Estimates for total final code complexity can be created at the conclusion of this phase, thereby informing the larger team of the estimated development time required to produce the project’s code base. In addition to the time commitment associated with code complexity, this can also help inform the total cost of ownership for the solution: the daily run cost to retrain the models, generate inferences of affinity, host the data, and serve the data.
Before setting out to plan the work that will be done through the generally accepted best methodology (Agile) by writing stories and tasks, it can be helpful to create a testing plan for the experimentation. This plan, devoid of technical implementation details and the verbose nature of story tickets that will be accomplished throughout the testing phases, can be used to not only inform the sprint planning but also track the status of the bake-off that the ML team will be doing. This can be shared and utilized as a communication tool to the larger team, helping to show the tasks completed and the results, and can accompany a demo of the two (or more!) competing implementations being pursued for options.
Figure 3.13 shows a staged testing plan for the experimentation phase of the recommendation engine.
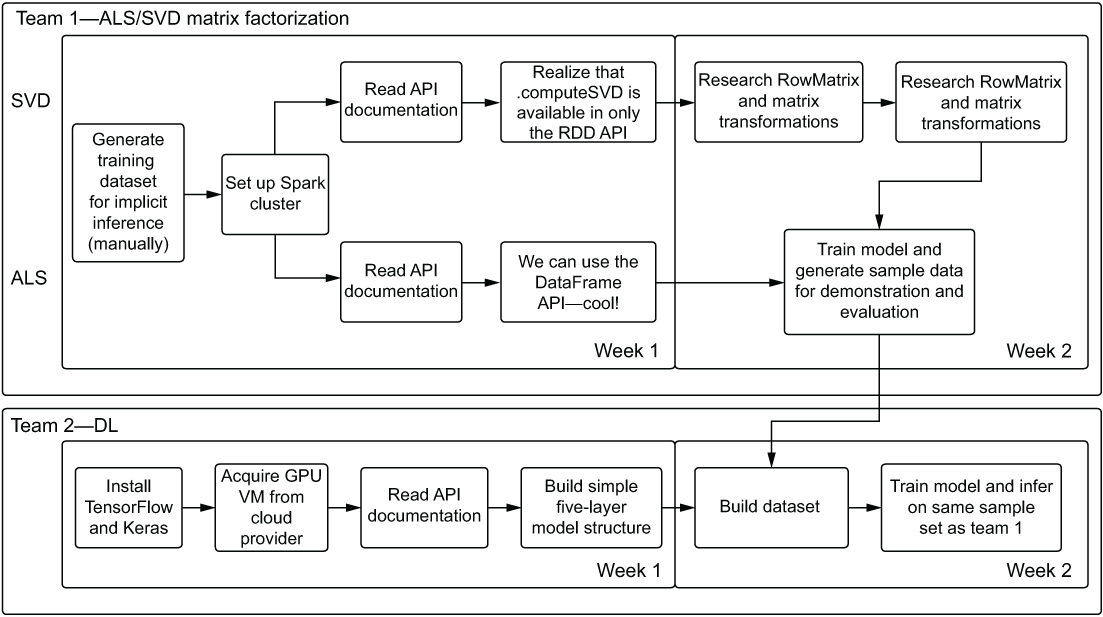
Figure 3.13 An experimentation tracking flow chart for two of the prototyping phases for the recommendation engine project
These testing paths clearly show the results of the research phase. Team 1’s matrix factorization approach shows a common data source that needs to be manually generated (not through an ETL job for this phase of testing). Based on the team members’ research and understanding of the computational complexity of these algorithms (and the sheer size of the data), they’ve chosen Apache Spark to test out solutions. From this phase, both teams had to split their efforts to research the APIs for the two models, coming to two very different conclusions. For the ALS implementation, the high-level DataFrame API implementation from SparkML makes the code architecture far simpler than the lower-level RDD-based implementation for SVD. The team can define these complexities during this testing, bringing to light for the larger team that the SVD implementation will be significantly more complex to implement, maintain, tune, and extend.
All of these steps for team 1 help define the development scope later. Should the larger team as a whole decide that SVD is the better solution for their use case, they should weigh the complexity of implementation against the proficiency of the team. If the team isn’t familiar with writing a Scala implementation that utilizes Breeze, can the project and the team budget time for team members to learn this technology? If the experimentation results are of significantly greater quality than the others being tested (or are a dependency for another, better solution), the larger team needs to be aware of the additional time that will be required to deliver the project.
Team 2’s implementation is significantly more complex and requires as input the SVD model’s inference. To evaluate the results of two approaches such as this, it’s important to assess the complexity.
If the results for team 2 are significantly better than those of the SVD on its own, the team should be scrutinizing a complex solution of this nature. The primary reason for scrutiny is the level of increased complexity in the solution. Not only will it be more costly to develop (in terms of time and money), but the maintenance of this architecture will be much harder.
The gain in performance from added complexity should always be of such a significant level that the increased cost to the team is negligible in the face of such improvement. If an appreciable gain isn’t clearly obvious to everyone (including the business), an internal discussion should take place about resume-driven development (RDD) and the motive for taking on such increased work. Everyone just needs to be aware of what they’re getting into and what they’ll potentially be maintaining for a few years should they choose to pursue this additional complexity.
Tracking experimentation phases
An additional helpful visualization to provide to the larger team when discussing experimental phases is a rough estimate of what the broad strokes of the solution will be from an ML perspective. A complex architectural diagram isn’t necessary, as it will change so many times during the early stages of development that creating anything of substantial detail is simply a waste of time at this point of the project.
However, a high-level diagram, such as the one shown in figure 3.14 that references our personalization recommendation engine, can help explain to the broader team what needs to be built to satisfy the solution. Visual “work architecture” guides like this (in an actual project it would have a great deal more detail) can also help the ML team keep track of current and upcoming work (as a complement to a scrum board).
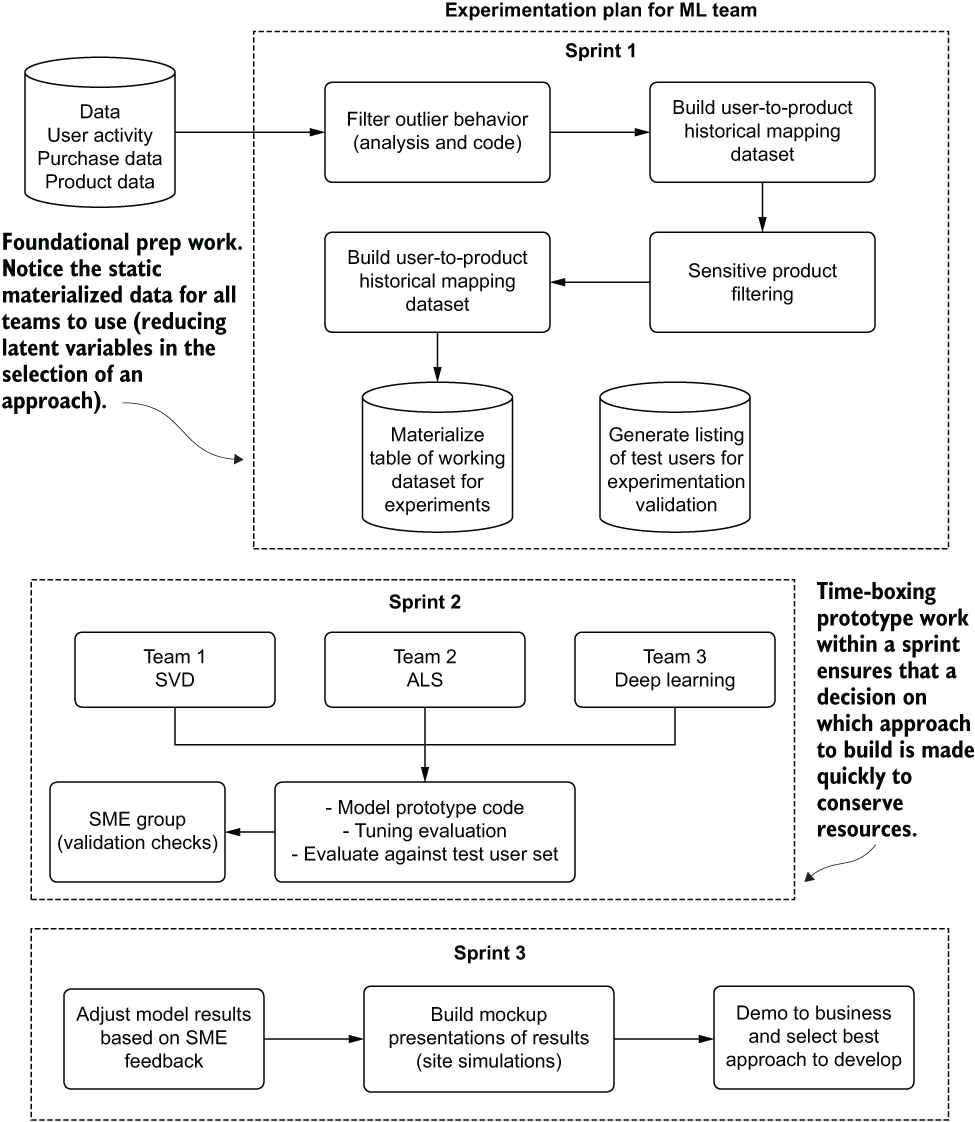
Figure 3.14 A high-level experimental phase architecture for the scenario project
These annotations can help communicate with the broader team at large. Instead of sitting in a status meeting that could include a dozen or more people, working diagrams like this one can be used by the ML team to communicate efficiently with everyone. Various explanations can be added to answer questions about what the team is working on and why at any given time, as well as to provide context to go along with chronologically focused delivery status reports (which, for a project as complex as this, can become difficult to read for those not working on the project).
Understanding the importance of scoping a research (experiment) phase
If the ML team members working on the personalization project had all the time in the world (and an infinite budget), they might have the luxury of finding an optimal solution for their problem. They could sift through hundreds of whitepapers, read through treatises on the benefits of one approach over another, and even spend time finding a novel approach to solve the specific use case that their business sees as an ideal solution. Not held back by meeting a release date or keeping their technical costs down, they could easily spend months, if not years, just researching the best possible way to introduce personalization to their website and apps.
Instead of just testing two or three approaches that have been proven to work for others in similar industries and use cases, they could work on building prototypes for dozens of approaches and, through careful comparison and adjudication, select the absolutely best approach to create the optimal engine that would provide the finest recommendations to their users. They may even come up with a novel approach that could revolutionize the problem space. If the team were allowed to be free to test whatever they wanted for this personalized recommendation engine, the ideas whiteboard might look something like figure 3.15.
Figure 3.15 Coming up with potential ways to solve the problem
After a brainstorming session that generated these ideas (which bears striking resemblance to many ideation sessions I’ve had with large and ambitious DS teams), the next step that the team should take collectively is to start making estimations of these implementations. Attaching comments to each alternative can help formulate a plan of the two or three most likely to succeed within a reasonable time of experimentation. The commentary in figure 3.16 can assist the team with deciding what to test out to meet the needs of actually shipping a product to production.
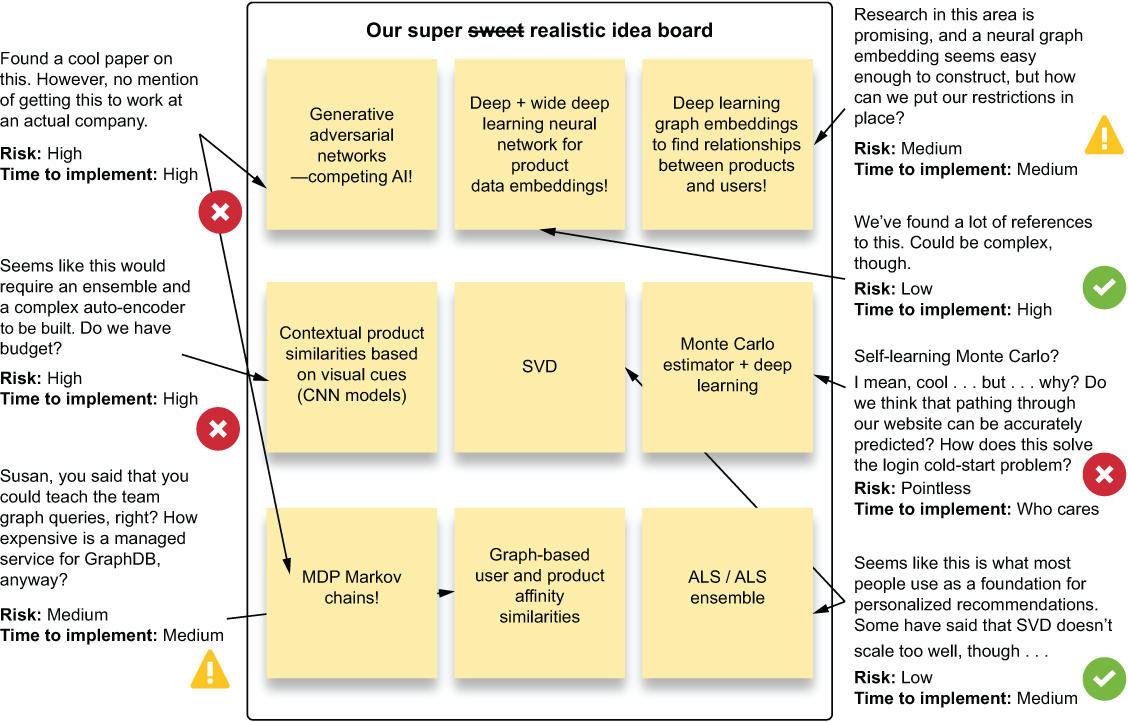
Figure 3.16 Evaluating and rating options discussed during a brainstorming session. This is an effective way to generate the two or three approaches to test against one another during experimentation.
After the team goes through the exercise of assigning risk to the different approaches, as shown in figure 3.16, the most likely and least risky options can be decided on that fit within the scope of time allocated for testing. The primary focus of evaluating and triaging the various ideas is to ensure that plausible implementations are attempted. To meet the goals of the project (accuracy, utility, cost, performance, and business problem-solving success criteria), pursuing experiments that can achieve all of those goals is of the utmost importance.
Some Advice The goal of experimentation is to find the most promising and simplest approach that solves the problem, not to use the most technologically sophisticated solution. Focusing on solving the problem and not on which tools you’re going to use to solve it will always increase the chances of success.
Take a look at figure 3.17. This is a slightly modified transposed time-based representation of the experimentation plan for two of the teams working on the experimentation phase. The most critical part to notice is at the top: the time scale.
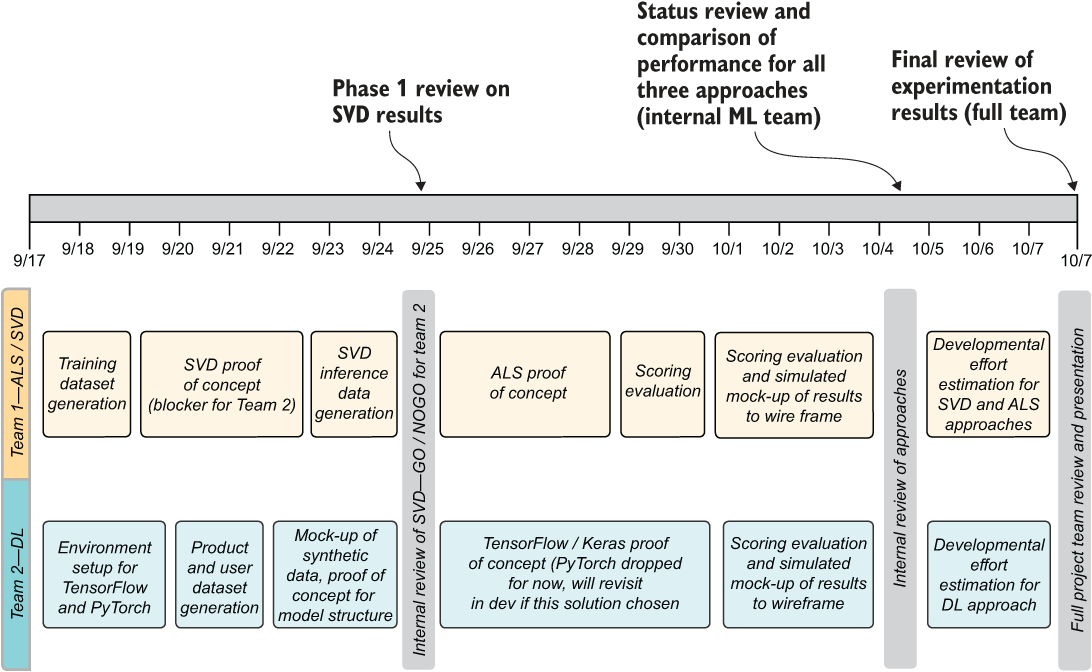
Figure 3.17 Chronological representation for two of the teams working on the experimentation phase of the project
This critical factor—time—is the one element that makes establishing controls on experimentation so important. Experimentation takes time. Building a proof of concept (PoC) is a grueling effort of learning new APIs, researching new ways of writing code to support the application of a model, and wrangling all the components together to ensure that at least one run succeeds. This can take a staggering amount of effort (depending on the problem).
Were the teams striving to build the best possible solution to do a bake-off, this time scale would stretch for many months longer than figure 3.17 shows. It’s simply not in the company’s interest to spend so many resources on trying to achieve perfection through two solutions that will never see the light of day. However, by limiting the total expenditure of time and accepting that the comparison of implementation strategies will be significantly less than perfect, the team can make an informed decision that weighs the quality of prediction against the total cost of ownership for the direction being chosen.
We time-block each of these elements for a final reason as well: to move quickly into making a decision for the project. This concept may well be significantly insulting to most data scientists. After all, how could someone adequately gauge the success of an implementation if the models aren’t fully tuned? How could someone legitimately claim the predictive power of the solution if all of its components aren’t completed?
I get it. Truly, I do. I’ve been there, making those same arguments. In hindsight, after having ignored the sage advice that software developers gave me during those early days of my career about why running tests on multiple fronts for long periods of time is a bad thing, I realize what they were trying to communicate to me.
If you had just made a decision earlier, all that work that you spent on the other things would have been put into the final chosen implementation.
Even though I knew what they were telling me was true, it still was a bit demoralizing to hear, realizing that I wasted so much time and energy.
Time blocking is also critical if the project is entirely new. Moon-shot projects may not be common in companies with an established ML presence, but when they do arise, it’s important to limit the amount of time spent in the early phases. They’re risky, have a higher probability of going nowhere, and can end up being remarkably expensive to build and maintain. It’s always best to fail fast and early for these projects.
The first time anyone approaches a new problem that is foreign to their experience, a lot of homework is usually required. Research phases can involve a lot of reading, talking to peers, searching through research papers, and testing code in Getting Started guides. This problem compounds itself many times over if the only available tooling to solve the problem is on a specific platform, uses a language that no one on the team has used before, or involves system designs that are new to the team (for example, distributed computing).
With the increased burden of research and testing that such a situation brings, it’s even more of a priority to set time limits on research and experimentation. If the team members realize that they need to get up to speed on a new technology to solve the business problem, this is fine. However, the project’s experimentation phase should be adapted to support this. The key point to remember, should this happen, is to communicate this to the business leaders so that they understand the increase in scope before the project work commences. It is a risk (although we’re all pretty smart and can learn new things quickly) that they should be made aware of in an open and honest fashion.
The only exception to this time-blocking rule occurs if a simple and familiar solution can be utilized and shows promising results during experimentation. If the problem can be solved in a familiar and easy manner but new technology could (maybe) make the project better, then taking many months of learning from failures while the team gets up to speed on a new language or framework is, in my opinion, unethical. It’s best to carve out time in the schedules of a DS team for independent or group-based continuing education and personal project work to these ends. During the execution of a project for a business is not the time to learn new tech, unless there is no other option.
How much work is this going to be, anyway?
At the conclusion of the experimental phase, the broad strokes of the ML aspect of the project should be understood. It is important to emphasize that they should be understood, but not implemented yet.
The team should have a general view of the features that need to be developed to meet the project’s specifications, as well as any additional ETL work that needs to be defined and developed. The team members should reach a solid consensus about the data going into and coming out of the models, how it will be enhanced, and the tools that will be used to facilitate those needs.
At this juncture, risk factors can begin to be identified. Two of the largest questions are as follows:
These questions should be part of the review phase between experimentation and development. Having a rough estimate can inform the discussion with the broader team about why one solution should be pursued over another. But should the ML team be deciding alone which implementation to use? Inherent bias will be present in any of the team’s assumptions, so to assuage these factors, it can be useful to create a weighted matrix report that the larger team (and the project leader) can use to choose an implementation.
Figure 3.18 shows an example of one such weighted matrix report (simplified for brevity) to allow for active participation by the greater team. The per-element ratings are locked by the expert reviewer who is doing the unbiased assessment of the relative attributes of different solutions, but the weights are left free to modify actively in a meeting. Tools like this matrix help the team make a data-driven choice after considering the various trade-offs of each implementation.
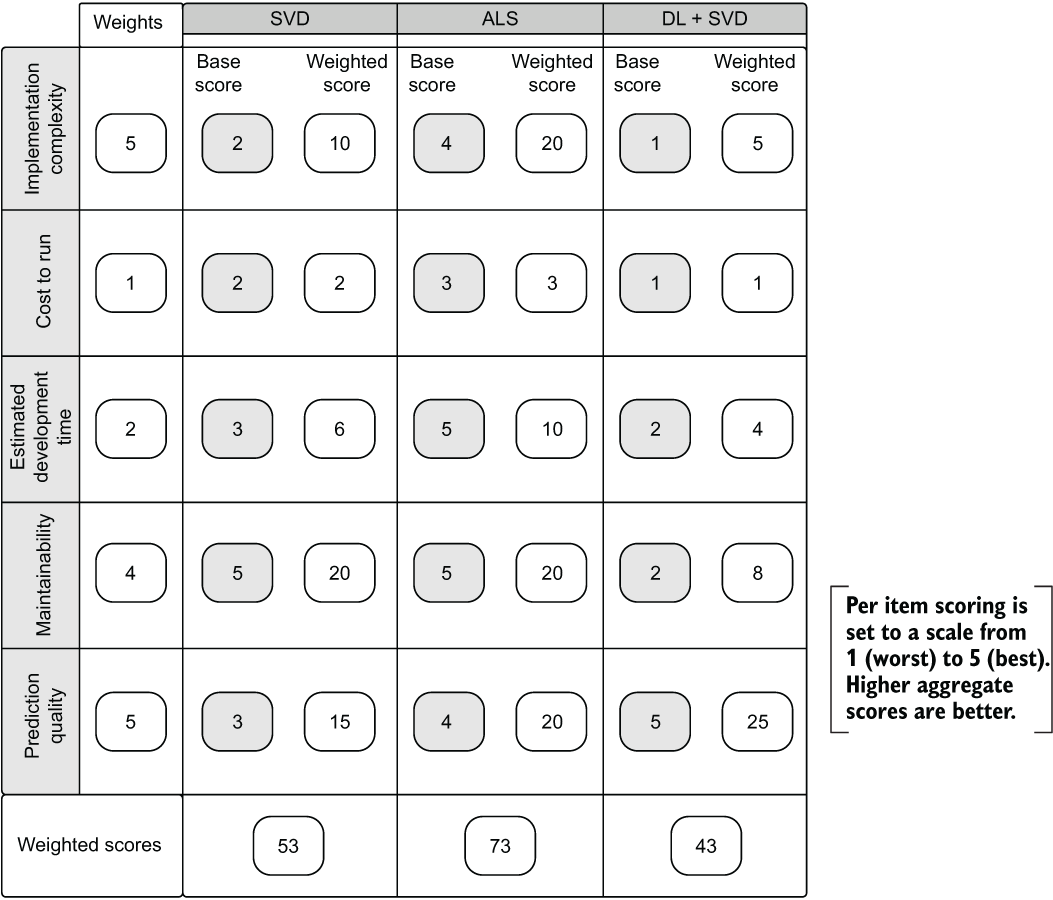
Figure 3.18 Weighted decision matrix for evaluating the experimental results, development complexity, cost of ownership, ability to maintain the solution, and comparative development time of the three tested implementations for the recommendation engine
If this matrix were to be populated by ML team members who had never built a system this complex, they might employ heavy weightings to Prediction Quality and little else. A more seasoned team of ML engineers would likely overemphasize Maintainability and Implementation Complexity (no one who has ever endured them likes never-ending epics and pager alerts at 2 a.m. on a Friday). The director of data science might only care about Cost to Run, while the project lead may only be interested in Prediction Quality.
The important point to keep in mind is that this is a balancing act. With more people who have a vested interest in the project coming together to debate and explain their perspectives, a more informed decision can be arrived at that can help ensure a successful and long-running solution.
At the end of the day, as the cliché goes, there is no free lunch. Compromises will need to be made, and they should be agreed upon by the greater team, the team leader, and the engineers who will be implementing these solutions as a whole.
Summary
- Spending time at the beginning of projects focused solely on how best to solve a given problem leads to great success. Gathering the critical requirements, evaluating approaches without introducing technical complexity or implementation details, and ensuring that communication with the business is clear helps avoid the many pitfalls that would necessitate rework later.
- Using principles of research and experimentation from Agile methodologies, ML projects can dramatically reduce the time to evaluate approaches and determine feasibility of the project much faster.