
2 Your data science could use some engineering
- Elucidating the differences between a data scientist and an ML engineer
- Focusing on simplicity in all project work to reduce risk
- Applying Agile fundamentals to ML project work
- Illustrating the differences and similarities between DevOps and MLOps
In the preceding chapter, we covered the components of ML engineering from the perspective of project work. Explaining what this approach to DS work entails from a project-level perspective tells only part of the story. Taking a view from a higher level, ML engineering can be thought of as a recipe involving a trinity of core concepts:
- Technology (tools, frameworks, algorithms)
- People (collaborative work, communication)
- Process (software development standards, experimentation rigor, Agile methodology)
The simple truth of this profession is that project work that focuses on each of these elements are generally successful, while those that omit one or many of them tend to fail. This is the very reason for the hyperbolic and oft-quoted failure rates of ML projects in industry (which I find to be rather self-serving and panic-fueled when coming from vendor marketing materials).
This chapter covers, at a high level, this trio of components for successful projects. Employing the appropriate balance of each, focused on creating maintainable solutions that are co-developed with internal customers in a collaborative and inclusive fashion, will greatly increase the chances of building ML solutions that endure. After all, the primary focus of all DS work is to solve problems. Conforming work patterns to a proven methodology that is focused on maintainability and efficiency translates directly to solving more problems with much less effort.
2.1 Augmenting a complex profession with processes to increase project success
In one of the earliest definitions of the term data science, as covered in Data Science, Classification, and Related Methods (Springer, 1996), compiled by C. Hayashi et al., the three main focuses are as follows:
- Design for data—Specifically, the planning surrounding how information is to be collected and in what structure it will need to be acquired to solve a particular problem
- Collection of data—The act of acquiring the data
- Analysis on data—Divining insights from the data through the use of statistical methodologies to solve a problem
A great deal of modern data science is focused mostly on the last of these three items (although in many cases, a DS team is forced to develop its own ETL), as the first two are generally handled by a modern data engineering team. Within this broad term, analysis on data, a large focus of the modern DS resides: applying statistical techniques, data manipulation activities, and statistical algorithms (models) to garner insights from and to make predictions upon data.
The top portion of figure 2.1 illustrates (in an intentionally brief and high-level manner) the modern data scientist’s focus from a technical perspective. These are the elements of the profession that most people focus on when speaking about what we do: from data access to building complex predictive models utilizing a dizzying array of algorithmic approaches and advanced statistics. It isn’t a particularly accurate assessment of what a data scientist actually does when doing project work, but rather focuses on some of the tasks and tools that are employed in solving problems. Thinking of data science in this manner is nearly as unhelpful as classifying the job of a software developer by listing languages, algorithms, frameworks, computational efficiency, and other technological considerations of their profession.

Figure 2.1 The merging of software engineering skills and DS into the ML engineer role
We can see in figure 2.1 how the technological focus of DS from the top portion (which many practitioners focus on exclusively) is but one aspect of the broader system shown in the bottom portion. It is in this region, ML engineering, that the complementary tools, processes, and paradigms provide a framework of guidance, foundationally supported by the core aspects of DS technology, to work in a more constructive way.
ML engineering, as a concept, is a paradigm that helps practitioners focus on the only aspect of project work that truly matters: providing solutions to problems that actually work. Where to start, though?
2.2 A foundation of simplicity
When it comes down to truly explaining what data scientists do, nothing can be more succinct than, “They solve problems through the creative application of mathematics to data.” As broad as that is, it reflects the wide array of solutions that can be developed from recorded information (data).
Nothing is prescribed regarding expectations of what a DS does regarding algorithms, approaches, or technology while in the pursuit of solving a business problem. Quite the contrary, as a matter of fact. We are problem solvers, utilizing a wide array of techniques and approaches.
Unfortunately for newcomers to the field, many data scientists believe that they are providing value to a company only when they are using the latest and “greatest” tech that comes along. Instead of focusing on the latest buzz surrounding a new approach catalogued in a seminal whitepaper or advertised heavily in a blog post, a seasoned DS realizes that the only thing that really matters is the act of solving problems, regardless of methodology. As exciting as new technology and approaches are, the effectiveness of a DS team is measured in the quality, stability, and cost of a solution it provides.
As figure 2.2 shows, one of the most important parts of ML work is navigating the path of complexity when facing any problem. By approaching each new ask from a business with this mindset as the veritable cornerstone of ML principles (focusing on the simplest solution possible that solves the business’s problem), the solution itself can be focused on, rather than a particular approach or fancy new algorithm.
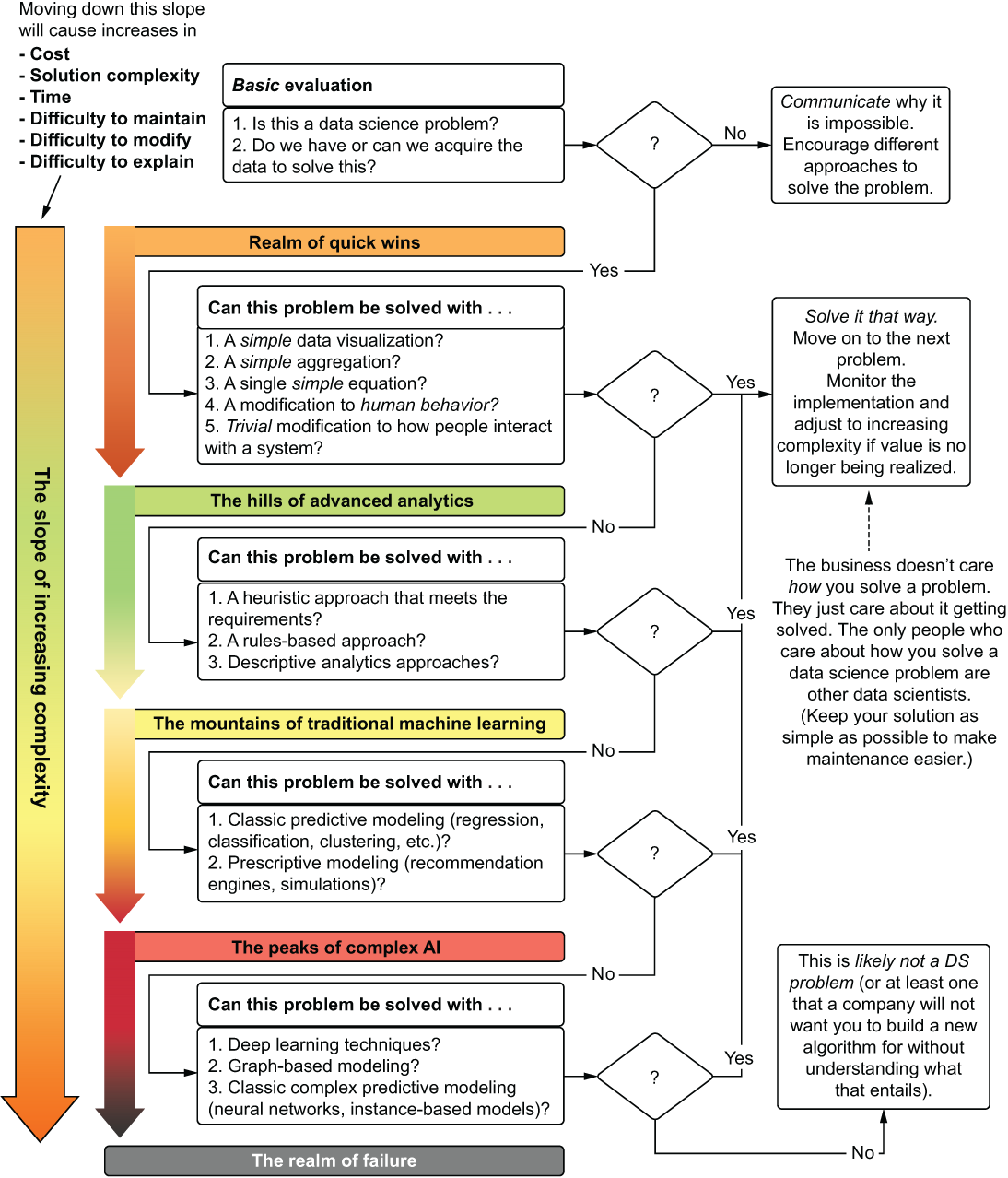
Figure 2.2 Guide for building the simplest solution to an ML problem
Having a focus built around this principle—of pursuing the simplest possible implementation to solve a problem—is the foundation upon which all other aspects of ML engineering are built. It is by far the single most important aspect of ML engineering, as it will inform all other aspects of project work, scoping, and implementation details. Striving to exit the path as early as possible can be the single biggest driving factor in determining whether a project will fail.
2.3 Co-opting principles of Agile software engineering
Development operations (DevOps) brought guidelines and a demonstrable paradigm of successful engineering work to software development. With the advent of the Agile Manifesto, seasoned industry professionals recognized the failings of the way software had been developed. Some of my fellow colleagues and I took a stab at adapting these guiding principles to the field of data science, shown in figure 2.3.

Figure 2.3 Agile Manifesto elements adapted to ML project work
With this slight modification to the principles of Agile development, we have a base of rules for applying DS to business problems. We’ll cover all of these topics, including why they are important, and give examples of how to apply them to solve problems throughout this book. While some are a significant departure from the principles of Agile, the applicability to ML project work has provided repeatable patterns of success for us and many others.
However, two critical points of Agile development can, when applied to ML project work, dramatically improve the way that a DS team approaches its work: communication and cooperation, and embracing and expecting change. We’ll take a look at these next.
2.3.1 Communication and cooperation
As discussed many times throughout this book (particularly in the next two chapters), the core tenets of successful ML solution development are focused on people. This may seem incredibly counterintuitive for a profession that is so steeped in mathematics, science, algorithms, and clever coding.
The reality is that quality implementations of a solution to a problem are never created in a vacuum. The most successful projects that I’ve either worked on or have seen others implement are those that focus more on the people and the communications regarding the project and its state rather than on the tools and formal processes (or documentation) surrounding the development of the solution.
In traditional Agile development, this rings very true, but for ML work, the interactions between the people coding the solution and those for whom the solution is being built are even more critical. This is due to the complexity of what is involved in building the solution. Since the vast majority of ML work is rather foreign to the general layperson, requiring years of dedicated study and continual learning to master, we need to engage in a much greater effort to have meaningful and useful discussions.
The single biggest driving factor in making a successful project that has the least amount of rework is collaborative involvement between the ML team and the business unit. The second biggest factor to ensure success is communication within the ML team.
Approaching project work with a lone-wolf mentality (as has been the focus for most people throughout their academic careers) is counterproductive to solving a difficult problem. Figure 2.4 illustrates this risky behavior (which I’ve done early in my career and seen done dozens of times by others).
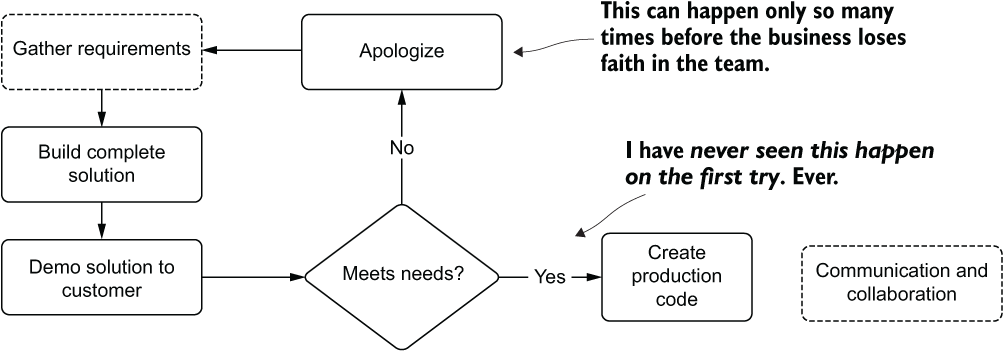
Figure 2.4 The hard-learned lesson of working on a full ML solution in isolation. It rarely ends well.
The reasons for this development style can be many, but the end result is typically the same: either a lot of rework, or a lot of frustration on the part of the business unit. Even if the DS team has no other members (a “team” of a single person), it can be helpful to ask for peer reviews and demonstrate the solution to other software developers, an architect, or SMEs from the business unit department that the solution is being built for.
The absolute last thing that you want to do (trust me, I’ve done it, and it’s ugly) is to gather requirements and head off to a keyboard to solve a problem without ever talking to anyone. The chances of meeting all of the project requirements, getting the edge cases right, and building what the customer is expecting are so infinitesimally small that, should it work out well, perhaps you should look into buying some lottery tickets with all of the excess luck that you have to spare.
A more comprehensive and Agile-aligned development process for ML bears a close resemblance to Agile for general software development. The only main difference is the extra levels of internal demonstrations that won’t necessarily be required for software development (a peer review feature branch typically suffices there). For ML work, it’s important to show the performance as a function of how it affects the data being passed into your code, demonstrate functionality, and show visualizations of the output. Figure 2.5 shows a preferable Agile-based approach to ML work, focused heavily on collaboration and communication, both internally and externally.
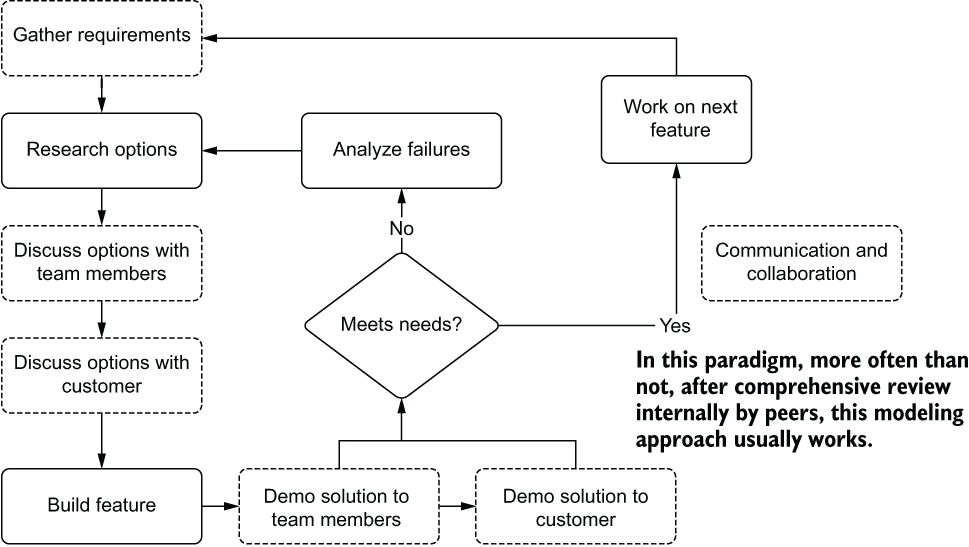
Figure 2.5 ML Agile feature creation process, focusing on requirement gathering and feedback
The greater level of interaction among team members will nearly always contribute to more ideas, perspectives, and challenges to assumed facts, leading to a higher-quality solution. If you choose to leave either your customers (the business unit requesting your help) or your peers out of the discussions (even around minute details in development choices), the chances that you're building something that they weren't expecting, or desiring, go up.
2.3.2 Embracing and expecting change
It is of utmost importance, not only in experimentation and project direction, but also in project development, to be prepared and expect inevitable changes to occur. In nearly every ML project I've worked on, the goals defined at the beginning of the project never turned out to be exactly what was built by the end. This applies to everything from specific technologies, development languages, and algorithms, to assumptions or expectations about the data—and, sometimes, even to the use of ML to solve the problem in the first place (a simple aggregation dashboard to help people solve a problem more efficiently, for example).
If you plan for the inevitable change, you can help focus on the most important goal in all DS work: solving problems. This expectation can also help remove focus from the insignificant elements (which fancy algorithm, cool new technology, or amazingly powerful framework to develop a solution in).
Without expecting or allowing for change to happen, decisions about a project’s implementation may be made that make it incredibly challenging (or impossible) to modify without a full rewrite of all work done up to that point. By thinking about how the direction of the project could change, the work is forced more into a modular format of loosely coupled pieces of functionality, reducing the impact of a directional pivot on other parts of the already completed work.
Agile embraces this concept of loosely coupled design and a strong focus on building new functionality in iterative sprints so that even in the face of dynamic and changing requirements, the code still functions. By applying this paradigm to ML work, abrupt and even late-coming changes can be relatively simplified—within reason, of course. (Moving from a tree-based algorithm to a deep learning algorithm can’t happen in a two-week sprint.) While simplified, this doesn’t guarantee simplicity, though. The fact simply stands that anticipating change and building a project architecture that supports rapid iteration and modification will make the development process much easier.
2.4 The foundation of ML engineering
Now that you’ve seen the bedrock of DS work in the form of adapting Agile principles to ML, let’s take a brief look at the entire ecosystem. This system of project work has proven to be successful through my many encounters in industry with building resilient and useful solutions to solve problems.
As mentioned in the introduction to this chapter, the idea of ML operations (MLOps) as a paradigm is rooted in the application of similar principles that DevOps has to software development. Figure 2.6 shows the core functionality of DevOps.
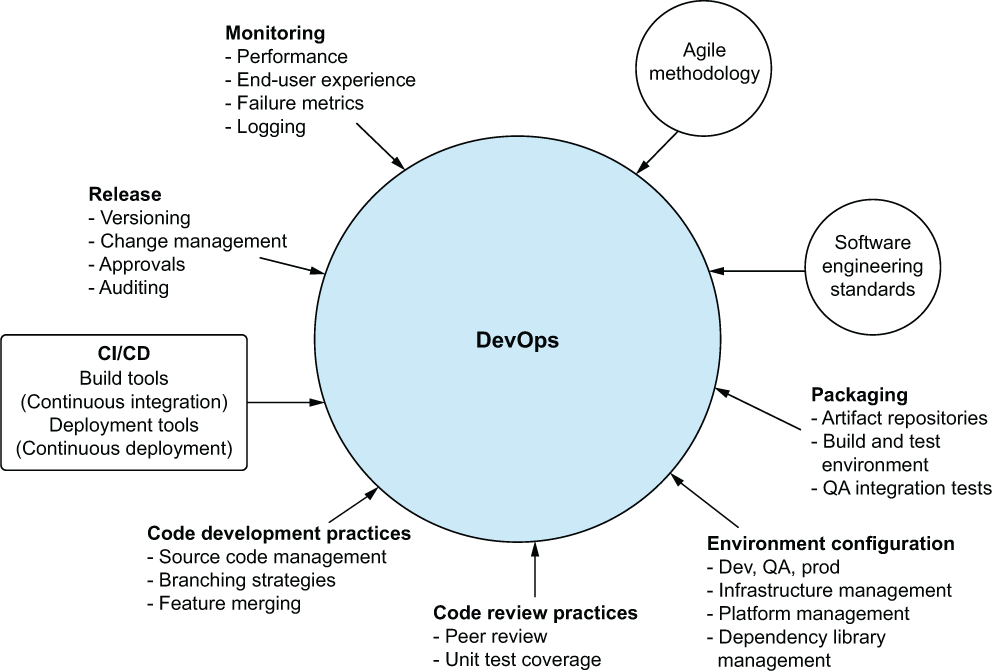
Figure 2.6 The components of DevOps
Comparing these core principles, as we did in section 2.3 to Agile, figure 2.7 shows the data science version of DevOps: MLOps. Through the merging and integration of each of these elements, the most catastrophic events in DS work can be completely avoided: the elimination of failed, cancelled, or non-adopted solutions.
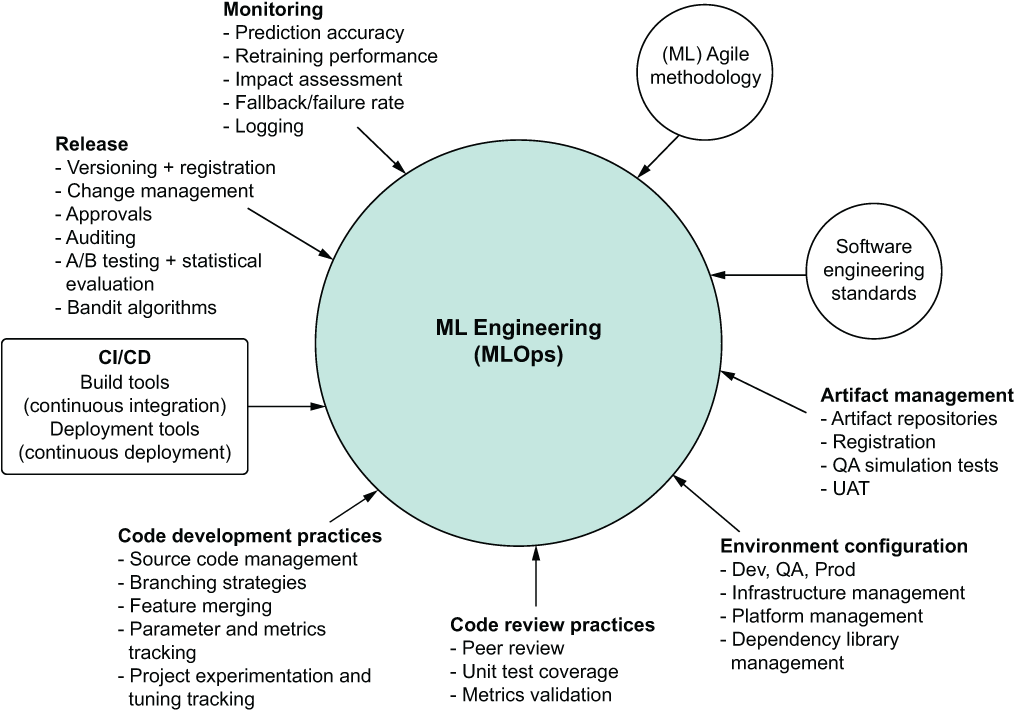
Figure 2.7 Adaptation of DevOps principles to ML project work (MLOps)
Throughout this book, we’ll cover not only why each of these elements is important, but also show useful examples and active implementations that you can follow along with to further cement these practices in your own work. The goal of all of this, after all, is to make you successful. The best way to do that is to help you make your business successful by giving a guideline of how to address project work that will get used, provide value, and be as easy as possible to maintain for you and your fellow DS team members.
Summary
- ML engineering brings the core functional capabilities of a data scientist, a data engineer, and a software engineer into a hybrid role that supports the creation of ML solutions focused on solving a problem through the rigors of professional software development.
- Developing the simplest possible solution helps reduce development, computational, and operational costs for any given project.
- Borrowing and adapting Agile fundamentals to ML project work helps shorten the development life cycle, forces development architectures that are easier to modify, and enforces testability of complex applications to reduce maintenance burdens.
- Just as DevOps augments software engineering work, MLOps augments ML engineering work. While many of the core concepts are the same for these paradigms, additional aspects of managing model artifacts and performing continuous testing of new versions introduce nuanced complexities.