
4 Before you model: Communication and logistics of projects
- Structuring planning meetings for ML project work
- Soliciting feedback from a cross-functional team to ensure project health
- Conducting research, experimentation, and prototyping to minimize risk
- Including business rules logic early in a project
- Using communication strategies to engage nontechnical team members
In my many years of working as a data scientist, I’ve found that one of the biggest challenges that DS teams face in getting their ideas and implementations to be used by a company is rooted in a failure to communicate effectively. This isn’t to say that we, as a profession, are bad at communicating.
It’s more that in order to be effective when dealing with our internal customers at a company (a business unit or cross-functional team), a different form of communication needs to be used than the one that we use within our teams. Here are some of the biggest issues that I’ve seen DS teams struggle with (and that I have had personally) when discussing projects with our customers:
- Knowing which questions to ask at what time
- Keeping communication tactically targeted on essential details, ignoring insignificant errata that has no bearing on the project work
- Discussing project details, solutions, and results in layperson’s terms
- Focusing discussions on the problem instead of the machinations of the solution
Since this field is so highly specialized, no common layperson’s rubric exists that distills our job in the same way as for other software engineering fields. Therefore, an extra level of effort is required. In a sense, we need to learn a way of translating what it is that we do into a different language in order to have meaningful conversations with the business.
We also need to work hard at quality communication practices in general as ML practitioners. Dealing with complex topics that are inevitably going to be frustratingly confusing for the business requires a certain element of empathetic communication.
Figure 4.1 shows a generic conversation path that I’ve always found to work well, one that we will apply throughout this chapter.
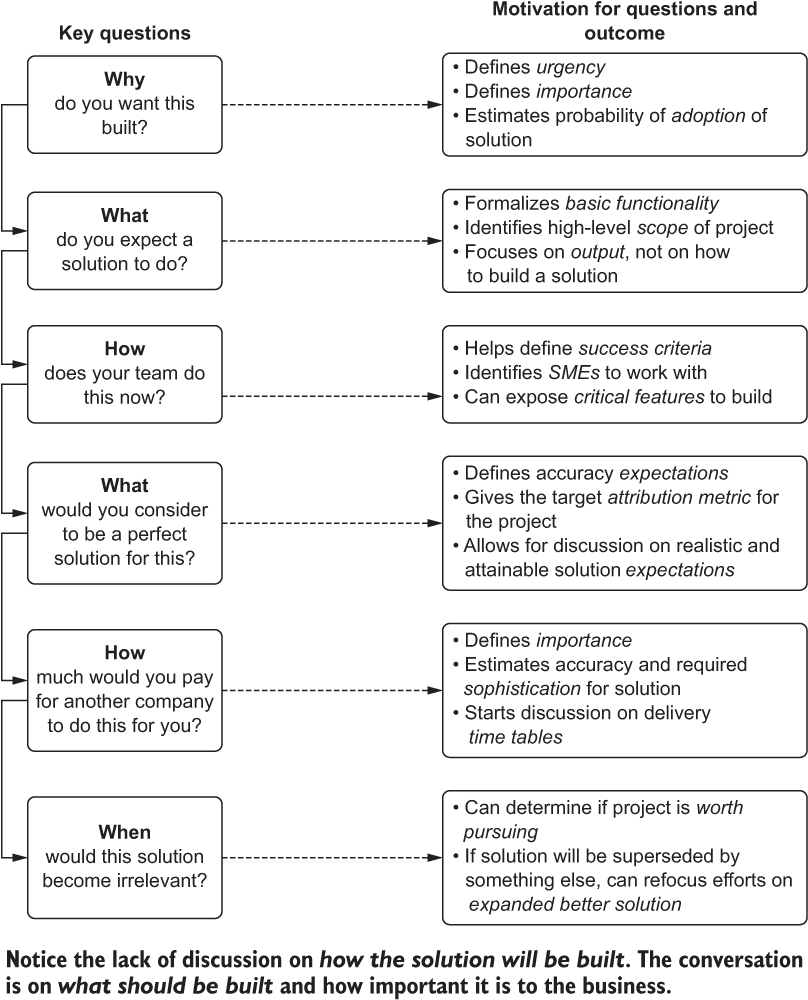
Figure 4.1 Critical questions to have with a business unit during a first planning meeting, followed by the critically important answers that will inform what, how, and when to build the solution
By using a clear, to-the-point communication style that focuses on outcomes, those project outcomes can be more closely aligned with business expectations of the work. A pointed discussion with this as the primary goal helps define what to build, how to build it, when to have it done by, and what the success criteria is. It’s effectively the entire recipe outlined for every further stage of the project up to and including flipping the switch to On in production.
4.1 Communication: Defining the problem
As covered in chapter 3, we’re going to continue discussing the product recommendation system that our DS team was tasked with building. We’ve seen a juxtaposition of ineffective and effective ways of planning a project and setting scoping for an MVP, but we haven’t seen how the team got to the point of creating an effective project plan with a reasonable project scope.
The first example meeting, as we discussed in section 3.1, revolved around the end goal in highly abstract terms. The business wanted personalization of its website. The DS team’s first error during that conversation was in not continuing the line of questioning. The single most important question was never asked: “Why do you want to build a personalization service?”
Most people, particularly technical people (likely the vast majority of the people who will be in a room discussing this initial project proposal and brainstorming session), prefer to focus on the how of a project. How am I going to build this? How is the system going to integrate to this data? How frequently do I need to run my code to solve the need?
For our recommendation engine project, if anyone had posed this question, it would have opened the door to an open and frank conversation about what needs to be built, what the expected functionality should be, how important the project is to the business, and when the business wants to start testing a solution. Once those key answers are received, all of the details surrounding logistics can be conducted.
The important thing to keep in mind with these kickoff meetings is that they’re effective when both sides—customer and supplier of the solution—are getting what they need. The DS team is getting its research, scoping, and planning details. The business is getting a review schedule for the work to be conducted. The business gets the inclusiveness that’s paramount to the project success, which will be exercised at the various presentations and ideation sessions scheduled throughout the project (more on these presentation boundaries is covered in section 4.1.2). Without a directed and productive conversation, as modeled in figure 4.1, the respective people in the meeting would likely be engaged in the thought patterns shown in figure 4.2.
By focusing the meeting on a common purpose, the areas of individual responsibility and expectation of each persona in figure 4.2 can be collaboratively directed toward defining the project and helping to ensure its success.
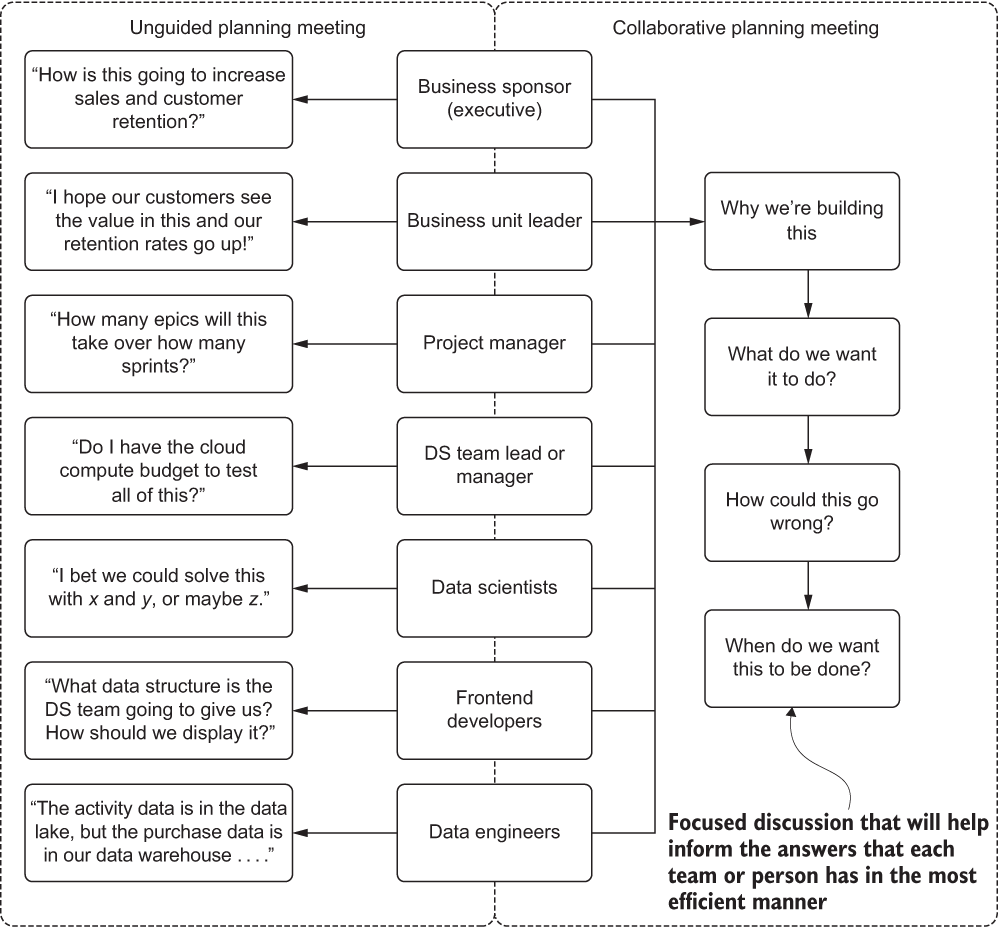
Figure 4.2 Comparison of unguided and guided planning meetings
The other primary benefit to collectively discussing the project’s key principles is to help define the simplest possible solution that solves the problem. By having buy-in from the business unit, feedback from SMEs, and input from fellow software engineers, the end solution can be crafted to meet the exact needs. It can also be adapted to new functionality at each subsequent phase without causing frustration for the larger team. After all, everyone discussed the project together from the start.
A great rule of thumb for ML Development Always build the simplest solution possible to solve a problem. Remember, you have to maintain this thing and improve it to meet changing needs as time goes on.
4.1.1 Understanding the problem
In our scenario, the unguided nature of the planning meeting(s) resulted in the DS team members not having a clear direction on what to build. Without any real definition from the business of the desired end state, they focused their effort solely on building the best collection of recommendations for each user that they could prove with scoring algorithms. What they had done was effectively missed the plot.
At its core, the problem is a fundamental breakdown in communication. Without asking what the business wanted from their work, they missed the details that meant the most to the business unit (and to the external “real” customers). You’ll always want to avoid situations like this. These breakdowns in communication and planning can play out in multiple ways, ranging from slow, simmering passive-aggressive hostility to outright shouting matches (usually one-sided) if the realization is made toward the end of a project.
The what for this recommendation is far more important to everyone on the team than the how. By focusing on the functionality of the project’s goal (the “What will it do?” question), the product team can be involved in the discussion. The frontend developers can contribute as well. The entire team can look at a complex topic and plan for the seemingly limitless number of edge cases and nuances of the business that need to be thought of for building not just the final project, but the MVP as well.
The easiest way for the team that’s building this personalization solution to work through these complex topics is by using simulation and flow-path models. These can help identify the entire team’s expectations for the project in order to then inform the DS team about the details needed to limit the options for building the solution.
The best way for the team working on this project to go through this conversation is to borrow liberally from the best practices of frontend software developers. Before a single feature branch is cut, before a single Jira ticket is assigned to a developer, frontend dev teams utilize wireframes that simulate the final end state.
For our recommendation engine, figure 4.3 shows what a high-level flow path might look like initially for a user journey on the website with personalization features applied. Mapping even simplistic architectural user-focused journeys like this can help the entire team think about how all of these moving parts will work. This process also open up the discussion to the nontechnical team members in a way that is far less confusing than looking at code snippets, key-value collections, and accuracy metrics plotted in highly confusing representations that they are unfamiliar with.
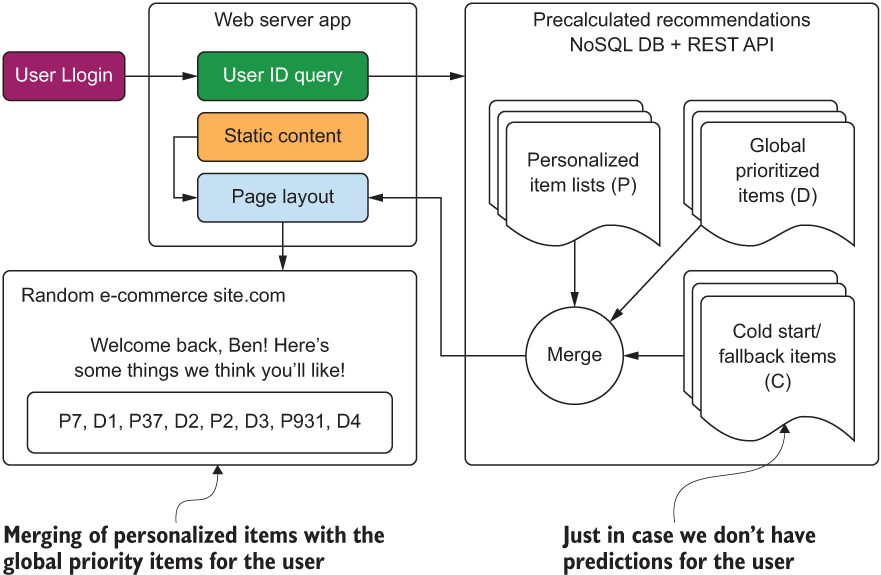
Figure 4.3 A simplified, basic overview of the personalization recommendation engine to aid in planning requirements and features of a personalization project. This is the core, minimal functionality to start an ideation session from.
NOTE Even if you’re not going to be generating a prediction that is interfacing with a user-facing feature on a website (or any ML that has to integrate with external services), it is incredibly useful to block out the end-state flow of the project’s aims while in the planning stage. This doesn’t expressly mean to build out a full architectural diagram for sharing with the business unit, but a line diagram of the way the pieces of the project interact and the way the final output will be utilized can be a great communication tool.
Diagrams such as this one are helpful for conducting a planning discussion with a broader team. Save your architecture diagrams, modeling discussions, and debates on the appropriateness of scoring metrics for a recommendation system to internal discussions within the DS team. Breaking out a potential solution from the perspective of a user not only enables the entire team to discuss the important aspects, but also opens the discussion to the nontechnical team members who will have insights into points to consider that will directly impact both the experimentation and the production development of the actual code.
Because the diagram is so incredibly simple and facilitates seeing the bare-bones functionality of the system, while hiding the complexity contained inside the Precalculated Recommendations section in particular, the discussion can begin with every person in the room being engaged and able to contribute to the ideas that will define the project’s initial state. As an example, figure 4.4 shows what might come from an initial meeting with the broader team, discussing what could be built in a thorough ideation session.
Figure 4.4, when compared with figure 4.3, shows the evolution of the project’s ideation. It is important to consider that many of the ideas presented would likely have not been considered by the DS team had the product teams and SMEs not been part of the discussion. Keeping the implementation details out of the discussion allows for everyone to continue to focus on the biggest question: “Why are we talking about building this, and how should it function for the end user?”
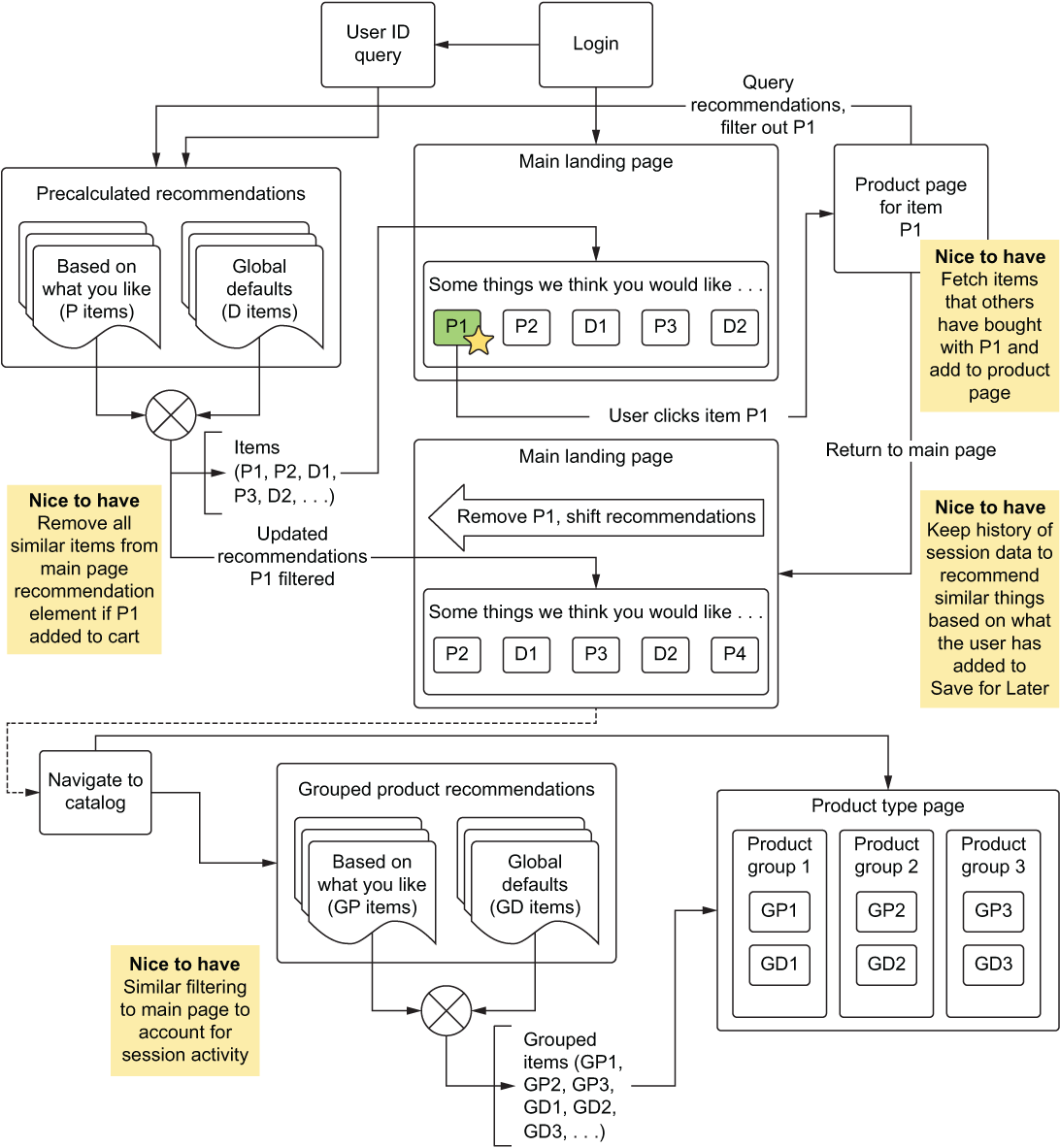
Figure 4.4 Additions made to the core minimal functionality as a result of an inclusive ideation session within a cross-functional team
In figure 4.4, notice the four items marked Nice to have. This is an important and challenging aspect of initial planning meetings. Everyone involved wants to brainstorm and work toward making the best possible solution to the problem. The DS team should welcome all of these ideas but add a caveat to the discussion that a cost is associated with each addition.
A sincere focus should be made on the essential aspects of the project (the MVP). Pursuit of an MVP ensures that only the most critical aspects will be built first. The other requirement is that they function correctly before including any additional features. Ancillary items should be annotated as such; ideas should be recorded, referenceable, modified, and referred to throughout the experimentation and development phases of the project. What once may have seemed insurmountably difficult could prove to be trivial later as the code base takes shape, and it could be worthwhile to include these features even in the MVP.
The only bad ideas are those that get ignored. Don’t ignore ideas, but also don’t allow every idea to make it into the core experimentation plan. If the idea seems far-fetched and incredibly complex, simply revisit it later, after the project is taking shape and the feasibility of implementation can be considered when the total project complexity is known to a deeper level.
While walking through this user-experience workflow, it could be discovered that team members have conflicting assumptions about how one of these engines work. The marketing team assumes that if a user clicks something, but doesn’t add it to their cart, we can infer dislike of the product. Those team members don’t want to see that product in recommendations again for the user.
How does this change the implementation details for the MVP? The architecture is going to have to change.
It’s a whole lot easier to find this out now and be able to assign scoped complexity for this feature while in the planning phase than before a model is built; otherwise, the change has to be monkey-patched to an existing code base and architecture. The defined functional architecture also may, as shown in figure 4.4, start adding to the overall view of the engine: what it’s going to be built to support and what will not be supported. Functional architecture design will allow the DS team, the frontend team, and the DE team to begin to focus on what they respectively will need to research and experiment with in order to prove or disprove the prototypes that will be built. Remember, all of this discussion happens before a single line of code is written.
Asking the simple question “How should this work?” and avoiding focusing on the standard algorithmic implementations is a habit that can help ensure success in ML projects more so than any technology, platform, or algorithm. This question is arguably the most important one to ask to ensure that everyone involved in the project is on the same page. I recommend asking this question along with the necessary line of questioning to eke out the core functionality that needs to be investigated and experimented on. If there is confusion or a lack of concrete theories regarding the core needs, it’s much better to sit in hours of meetings to plan things out and iron out all of the business details as much as possible in the early stages, rather than waste months of your time and effort in building something that doesn’t meet the project sponsor’s vision.
What does the ideal end-state look like?
The ideal implementation is hard to define at first (particularly before any experimentation is done), but it’s incredibly useful to the experimentation team to hear all aspects of an ideal state. During these open-ended stream-of-consciousness discussions, a tendency of most ML practitioners is to instantly decide what is and isn’t possible based on the ideas of people who don’t understand what ML is. My advice is to simply listen. Instead of shutting down a thread of conversation immediately as being out of scope or impossible, let the conversation happen.
You may find an alternative path during this creative ideation session that you otherwise would have missed. You might just find a simpler, less unique, and far more maintainable ML solution than what you may have come up with on your own. The most successful projects that I’ve worked on over the years have come from having these sorts of creative discussions with a broad team of SMEs (and, when I’ve been lucky, the actual end users) to allow me to shift my thinking into creative ways of getting as close as possible to their vision.
Discussing an ideal end state isn’t just for the benefit of a more amazing ML solution, though. Engaging the person asking for the project to be built allows their perspective, ideas, and creativity to influence the project in positive ways. The discussion also helps build trust and a feeling of ownership in the development of the project that can help bring a team together.
Learning to listen closely to the needs of your ML project’s customer is one of the most important skills of an ML engineer—far more than mastering any algorithm, language, or platform. It will help guide what you’re going to try, what you’re going to research, and how to think differently about problems to come up with the best solution that you possibly can.
In the scenario shown in figure 4.4, the initial planning meeting results in a rough sketch of the ideal state. This likely will not be the final engine (based on my experience, that most certainly is never the case). But this diagram will inform how to convert those functional blocks into systems. It will help inform the direction of experimentation, as well as the areas of the project that you and the team will need to research thoroughly to minimize or prevent unexpected scope creep, as shown in figure 4.5.
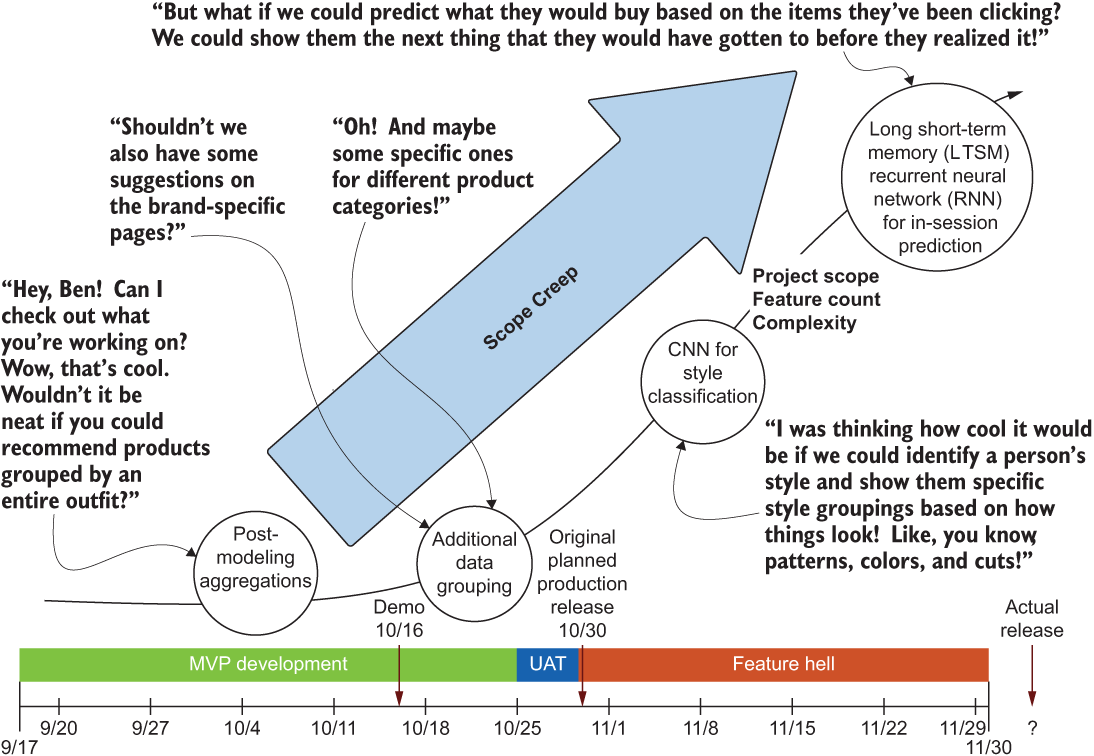
Figure 4.5 The dreaded scope creep of an ML project. Be clear at the outset of planning that this will not be tolerated, and you shouldn’t have to worry about it.
Figure 4.5 should be familiar to any reader who has ever worked at a startup. The excitement and ideas that flow from driven and creative people who want to do something amazing is infectious and can, with a bit of tempering, create a truly revolutionary company that does a great job at its core mission. However, without that tempering and focus applied, particularly to an ML project, the sheer size and complexity of a solution can quite rapidly spiral out of control.
NOTE I’ve never, not even once, in my career allowed a project to get to the level of ridiculousness shown in figure 4.5 (although a few have come close). However, on nearly every project that I’ve worked on, comments, ideas, and questions like this have been posed. My advice: thank the person for their idea, gently explain in nontechnical terms that it’s not possible at this time, and move on to finish the project.
Who is your champion for this project that I can work with on building these experiments?
The most valuable member of any team I’ve worked with has been the SME—the person assigned to work with me or my team in order to check our work, answer every silly question that we had, and provide creative ideation that helped the project grow in ways that none of us had envisioned. While usually not a technical person, the SME has a deep connection and expansive knowledge of the problem. Taking a little bit of extra time to translate between the world of engineering and ML to layperson’s terms has always been worth it, primarily because it creates an inclusive environment that enables the SME to be invested in the success of the project since they see that their opinions and ideas are being considered and implemented.
I can’t stress enough that the last personyou want to fill this role is the actual executive-level project owner. While it may seem logical at first to assume that being able to ask the manager, director, or VP of a group for approval of ideation and experimentation will be easier, I can assure you that this will only stagnate a project. These people are incredibly busy dealing with dozens of other important, time-consuming tasks that they have delegated to others. Expecting this person—who may or may not be an expert in the domain that the project is addressing—to provide extensive and in-depth discussions on minute details (all ML solutions are all about the small details, after all) will likely put the project at risk. In that first kick-off meeting, make sure to have a resource from the team who is an SME and has the time, availability, and authority to deal with this project and the critical decisions that will need to be made throughout.
When should we meet to share progress?
Because of the complex nature of most ML projects (particularly ones that require so many interfaces to parts of a business as a recommendation engine), meetings are critical. However, not all meetings are created equally.
While it is incredibly tempting for people to want to have cadence meetings on a certain weekly prescribed basis, project meetings should coincide with milestones associate with the project. These project-based milestone meetings should
- Not be a substitute for daily standup meetings
- Not overlap with team-focused meetings of individual departments
- Always be conducted with the full team present
- Always have the project lead present to make final decisions on contentious topics
- Be focused on presenting the solution as it stands at that point and nothing else
At the early meetings, it is imperative for the DS team to communicate to the group the need for these event-based meetings. You want to let everyone know that changes that might seem insignificant to other teams could have rework risks associated with them that could translate to weeks or months of extra work by the DS team. Similarly, DS changes could have dramatic impacts on the other teams.
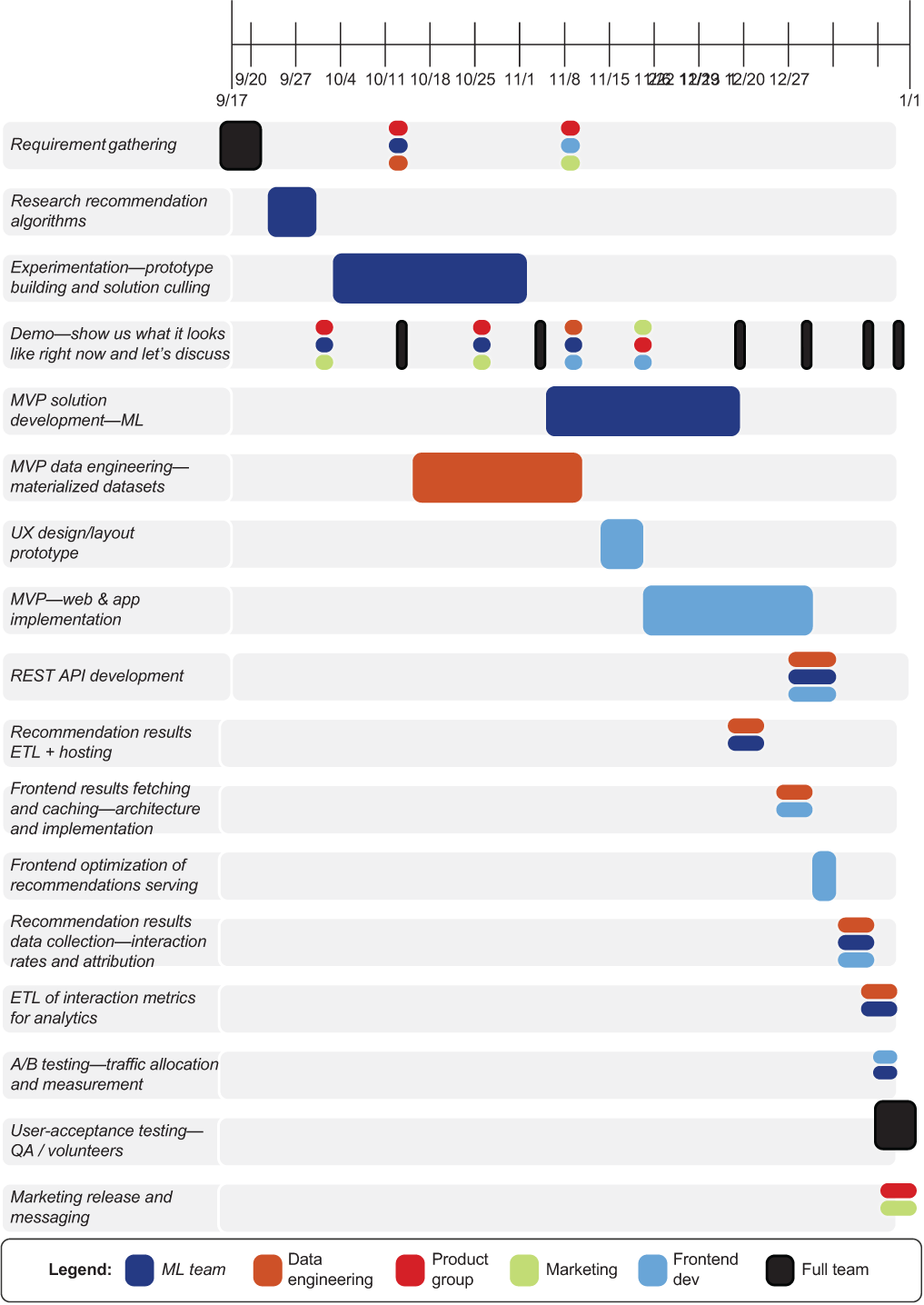
Figure 4.6 Cross-functional team project timeline chart. Notice the frequency and membership requirements for each demo and discussion (most are for the full team).
To illustrate the interconnectedness of the project and how hitting different deliveries can impact a project, let’s take a look at figure 4.6. This chart shows what this solution would look like in a relatively large company (let’s say over 1,000 employees) with the roles and responsibilities divided among various groups. In a smaller company (a startup, for instance), many of these responsibilities would fall either on the frontend or DS team rather than separate DE teams.
Figure 4.6 shows how dependencies from the ML experimentation, for instance, affect the future work of both the DE and frontend development teams. Adding excessive delays or required rework results in not only the DS team reworking its code, but also potentially weeks of work being thrown away by an entire engineering organization. This is why planning, frequent demonstrations of the state of the project, and open discussions with the relevant teams are so critical.
Figure 4.7 illustrates a high-level Gantt chart of the milestones associated with a general e-commerce ML project, focusing solely on the main concepts. Using charts like this as a common focused communication tool can greatly improve the productivity of all the teams and reduce a bit of the chaos in a multidisciplinary team, particularly across the walls of department barriers.
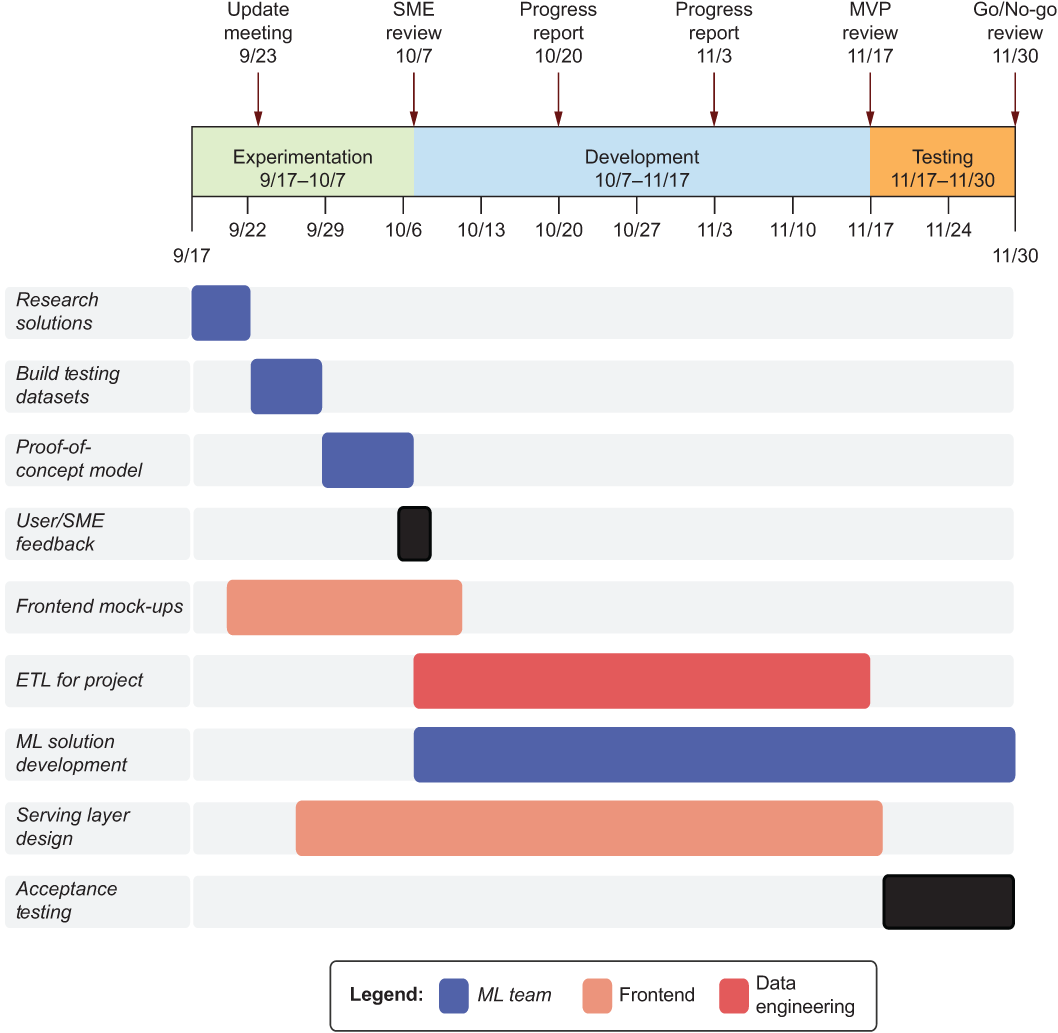
Figure 4.7 High-level project timeline for engineering and DS
As the milestone arrows along the top of figure 4.7 show, at critical stages, the entire team should be meeting together to ensure that all team members understand the implications of what has been developed and discovered so that they may collectively adjust their own project work. Most teams that I’ve worked with hold these meetings on the same day as their sprint planning, for what that’s worth.
These breakpoints allow for demos to be shown, basic functionality to be explored, and risks identified. This common communication point has two main purposes:
- Minimizing the amount of time wasted on rework
- Making sure that the project is on track to do what it set out to do
While spending the time and energy to create Gantt charts for each and every project is not absolutely necessary, creating at least something to track progress and milestones against is advisable. Colorful charts and interdisciplinary tracking of systems development certainly doesn’t make sense for solo outings led by a single ML engineer handling the entire project. But even when you may be the only person putting fingers to keyboard, figuring out where major boundaries exist within the project’s development and scheduling a bit of a show-and-tell can be extremely helpful.
Do you have a demonstration test set from a tuned model that you want to make sure solves the problem? Set a boundary at that point, generate the data, present it in a consumable form, and show it to the team that asked for your help in solving the problem. Getting feedback—the right feedback—in a timely manner can save you and your customer a great deal of frustration.
4.1.2 Setting critical discussion boundaries
The next question that begs to be asked is, “Where do I set these boundaries for my project?” Each project is completely unique with respect to the amount of work required to solve the problem, the number of people involved in the solution, and the technological risks surrounding the implementation.
But a few general guidelines are helpful for setting the minimum required meetings. Within the confines of the recommendation engine that we’re planning on building, we need to set some form of a schedule indicating when we will all be meeting, what we will be talking about, what to expect from those meetings, and most important, how the active participation from everyone involved in the project will help minimize risk in the timely delivery of the solution.
Let’s imagine for a moment that this is the first large-scale project involving ML that the company has ever dealt with. It’s the first time that so many developers, engineers, product managers, and SMEs have worked in concert, and none of them have an idea of how often to meet and discuss the project. You realize that meetings do have to happen, since you identified this in the planning phase. You just don’t know when to have them.
Within each team, people have a solid understanding of the cadence with which they can deliver solutions—assuming they’re using some form of Agile, they’re likely all having scrum meetings and daily stand-ups. But no one is really sure what the stages of development look like in other teams.
The simplistic answer is, naturally, a frustrating one for all involved: “Let’s meet every Wednesday at 1 p.m.” Putting a “regularly scheduled program” meeting in place, with a full team of dozens of people, will generally result in the team not having enough to talk about, demo, or review. Without a pointed agenda, the importance and validity of the meeting can become questioned, resulting in people failing to show up when something critical needs review.
The best policy that I’ve found is to set deliverable date meetings with tangible results to review, a strong agenda, and an expectation of contribution from everyone who attends. That way, everyone will realize the importance of the meeting, everyone’s voice and opinions will be heard, and precious time resources will be respected as much as is practicable.
The more logical, useful, and efficient use of everyone’s time is to meet to review the solution-in-progress only when something new needs review. But when are those decision points? How do we define these boundaries in order to balance the need to discuss elements of the project with the exhaustion that comes with reviewing minor changes with too-frequent work-disrupting meetings?
It depends on the project, the team, and the company. The point I’m making is that it’s different for every situation. The conversation about these expectations of meeting frequency, the meeting agenda, and the people who are to be involved simply needs to happen to help control the chaos that could otherwise arise and derail progress toward solving the problem.
Post-research phase discussion (update meeting)
For the sake of example within our scenario, let’s assume that the DS team identifies that two models must be built to satisfy the requirements from the planning phase user-journey simulation. Based on the team members’ research, they decide that they want to pit both collaborative filtering and frequent-pattern-growth (FP-growth) market-basket analysis algorithms against deep learning implementations to see which provides a higher accuracy and lower cost of ownership for retraining.
The DS lead assigns two groups of data scientists and ML engineers to work on these competing implementations. Both groups generate simulations of the model results on the exact same synthetic customer dataset, providing mock product images to a wireframe of the pages displaying these recommendations for the actual website.
This meeting should not focus on any of the implementation details. Instead, it should focus solely on the results of the research phase: the whittling down of nigh-infinite options that have been read about, studied, and played with. The team has found a lot of great ideas and an even larger group of potential solutions that won’t work based on the data available, and has reduced the list of great ideas to a bake-off of two implementations that they’ll pit against each other. Don’t bring up all of the options that you’ve explored. Don’t mention something that has amazing results but will likely take two years to build. Instead, distill the discussion to the core details required to get the next phase going: experimentation.
Show these two options to the SMEs, solely within the confines of presenting what can be done with each algorithmic solution, what is impossible with one or both, and when the SMEs can expect to see a prototype in order to decide which they like better. If no discernable difference exists in the quality of the predictions, the decision of which to go with should be based on the drawbacks of the approaches, leaving the technical complexity or implementation details out of the discussion.
Keep the discussion in these dense meetings focused on relatable language and references that your audience will comprehend and associate with. You can do the translating in your head and leave it there. The technical details should be discussed only internally by the DS team, the architect, and engineering management.
In many cases that I’ve been involved with, the experimental testing phase may test out a dozen ideas but present only the two most acceptable to a business unit for review. If the implementation would be overly onerous, costly, or complex, it’s best to present options that will guarantee the greatest chance of project success—even if they’re not as fancy or exciting as other solutions. Remember: the DS team has to maintain the solution, and something that sounds really cool during experimentation can turn into a nightmare to maintain.
Post-experimentation phase (SME/UAT review)
Following the experimentation phase, the subteams within the DS group build two prototypes for the recommendation engine. In the previous milestone meeting, the options for both were discussed, with their weaknesses and strengths presented in a way that the audience could understand. Now it’s time to lay the prediction cards out on the table and show off what a prototype of the solution looks like.
Before, during reviews of the potential solutions, some pretty rough predictions were shown. Duplicate products with different product IDs were right next to one another, endless lists of one product type were generated for some users (there’s no way that anyone likes belts that much), and the list of critical issues with the demo were listed out for consideration. In those first early pre-prototypes, the business logic and feature requirements weren’t built out yet, since those elements directly depended on the models’ platform and technology selection.
The goal of the presentation that completes the experimentation phase should be to show a mock-up of the core features. Perhaps elements need to be ordered based on relevancy. Special considerations may require recommending items based on price point, recent non-session-based historical browsing, and the theory that certain customers have implicit loyalty to certain brands. Each of these agreed-upon features should be shown to the entire team. The full implementation, however, should not be done by this point, but merely simulated to show what the eventual designed system would look like.
The results of this meeting should be similar to those from the initial planning meeting: additional features that weren’t recognized as important can be added to the development planning, and if any of the original features are found to be unnecessary, they should be removed from the plan. Revisiting the original plan, an updated user experience might look something like figure 4.8.
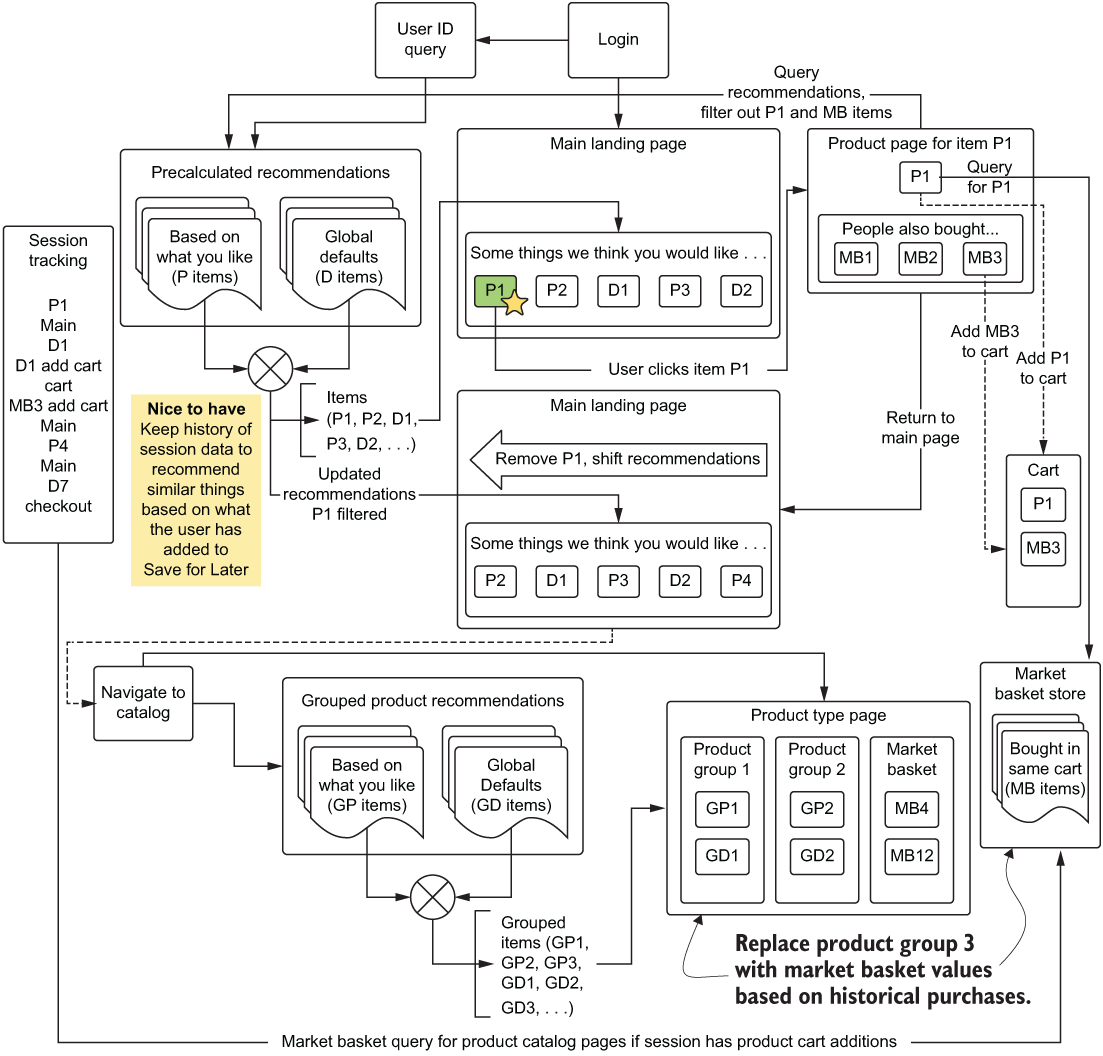
Figure 4.8 The final wireframe design of the recommendation engine resulting from the review of the experimentation results
With the experimentation phase out of the way, the DS team can explain that the nice-to-have elements from earlier phases are not only doable but can be integrated without a great deal of extra work. Figure 4.8 shows the integration of those ideas (market-basket analysis, dynamic filtering, and aggregated filtering), but also maintains one idea as a “nice to have.” If it is found that, during development, the integration of this feature would be attainable, it is left as part of this living planning document.
The most important part of this stage’s meeting is that everyone on the team (from the frontend developers who will be handling the passing of event data to the server to conduct the filtering, to the product team) is aware of the elements and moving pieces involved. The meeting ensures that the team understands which elements need to be scoped, as well as the general epics and stories that need to be created for sprint planning. Arriving at a collaborative estimation of the implementation is critical.
Development sprint reviews (progress reports for a nontechnical audience)
Conducting recurring meetings of a non-engineering-focused bent are useful for more than just passing information from the development teams to the business. They can serve as a bellwether of the state of the project and help indicate when integration of disparate systems can begin. These meetings should still be a high-level project-focused discussion, though.
The temptation for many cross-functional teams that work on projects like this is to turn these update meetings into either an über-retrospective or a super sprint-planning meeting. While such discussions can be useful (particularly for integration purposes among various engineering departments), those topics should be reserved for the engineering team’s meetings.
A full-team progress report meeting should make the effort to generate a current-state demonstration of progress up to that point. Simulations of the solution should be shown to ensure that the business team and SMEs can provide relevant feedback on details that might have been overlooked by the engineers working on the project. These periodic meetings (either every sprint or every other sprint) can help prevent the aforementioned dreaded scope creep and the 11th-hour finding that a critical component that wasn’t noticed as necessary is missing, causing massive delays in the project’s delivery.
MVP review (full demo with UAT)
Code complete can mean different things to different organizations. In general, it is widely accepted to be a state in which
- Code is tested (and passes unit/integration tests).
- The system functions as a whole in an evaluation environment using production-scale data (models have been trained on production data).
- All agreed-upon features that have been planned are complete and perform as designed.
This doesn’t mean that the subjective quality of the solution is met, though. This stage simply means the system will pass recommendations to the right elements on the page for this recommendation engine example. The MVP review and the associated UAT that goes into preparing for this meeting is the stage at which subjective measures of quality are done.
What does this mean for our recommendation engine? It means that the SMEs log in to the UAT environment and navigate the site. They look at the recommendations based on their preferences and make judgments on what they see. It also means that high-value accounts are simulated, ensuring that the recommendations that the SMEs are looking at through the lens of these customers are congruous to what they know about those types of users.
For many ML implementations, metrics are a wonderful tool (and most certainly should be heavily utilized and recorded for all modeling). But the best gauge of determining whether the solution is qualitatively solving the problem is to use the breadth of knowledge of internal users and experts who can use the system before it’s deployed to end users.
At meetings evaluating the responses to UAT feedback of a solution developed over a period of months, I’ve seen arguments break out between the business and the DS team about how one particular model’s validation metrics are higher, but the qualitative review quality is much lower than the inverse situation. This is exactly why this particular meeting is so critical. It may uncover glaring issues that were missed in not only the planning phases, but in the experimental and development phases as well. Having final sanity checks on the results of the solution can only make the end result better.
There is a critical bit of information to remember about this meeting and review period dealing with estimates of quality: nearly every project carries with it a large dose of creator bias. When creating something, particularly an exciting system that has a sufficient challenge to it, the creators can overlook and miss important flaws because of familiarity with and adoration of it.
A parent can never see how ugly or stupid their children are. It’s human nature to unconditionally love what you’ve created.
If, at the end of one of these review meetings, the only responses are overwhelmingly positive praise of the solution, the team should have concerns. One of the side effects of creating a cohesive cross-functional team of people who all share in a collective feeling of project ownership is that emotional bias for the project may cloud judgment of its efficacy.
If you ever attend a summarization meeting about the quality of a solution and hear nary an issue, it would behoove you and the project team to pull in others at the company who have no stake in the project. Their unbiased and objective look at the solution could pay dividends in the form of actionable improvements or modifications that the team, looking through its bias of nigh-familial adoration of the project, would have completely missed.
Preproduction review (final demo with UAT)
The final preproduction review meeting is right before “go time.” Final modifications are complete, feedback from the UAT development-complete tests have been addressed, and the system has run without blowing up for several days.
The release is planned for the following Monday (pro tip: never release on a Friday), and a final look at the system is called for. System load testing has been done, responsiveness measured through simulation of 10 times the user volume at peak traffic, logging is working, and the model retraining on synthetic user actions has shown that the models adapt to the simulated data. Everything from an engineering point has passed all tests.
—Everyone who is exhausted by countless meetings
This final meeting before release should review a comparison to original plans, the features rejected for being out of scope, and any additions. This can help inform expectations of the analytics data that should be queried upon release. The systems required to collect the data for interactions for the recommendations have been built, and an A/B testing dataset has been created that can allow for analysts to check the performance of the project.
This final meeting should focus on where that dataset will be located, how engineers can query it, and which charts and reports will be available (and how to access them) for the nontechnical members of the team. The first few hours, days, and weeks of this new engine powering portions of the business is going to receive a great deal of scrutiny. To save the sanity of the analysts and the DS team, a bit of preparation work to ensure that people can have self-service access to the project’s metrics and statistics will ensure that critical data-based decisions can be made by everyone in the company, even those not involved in creating the solution.
4.2 Don’t waste our time: Meeting with cross-functional teams
Chapter 3, in discussing the planning and experimentation phases of a project, noted that one of the most important aspects to keep in mind (aside from the ML work itself) is the communication during those phases. The feedback and evaluation received can be an invaluable tool to ensure that the MVP gets delivered on time and is as correct as can be so that the full development effort can proceed.
Let’s take another look at our Gantt chart from figure 4.7 for keeping track of the high-level progress of each team’s work throughout the phases. For the purposes of communication, however, we’re concerned with only the top portion, shown in figure 4.9.
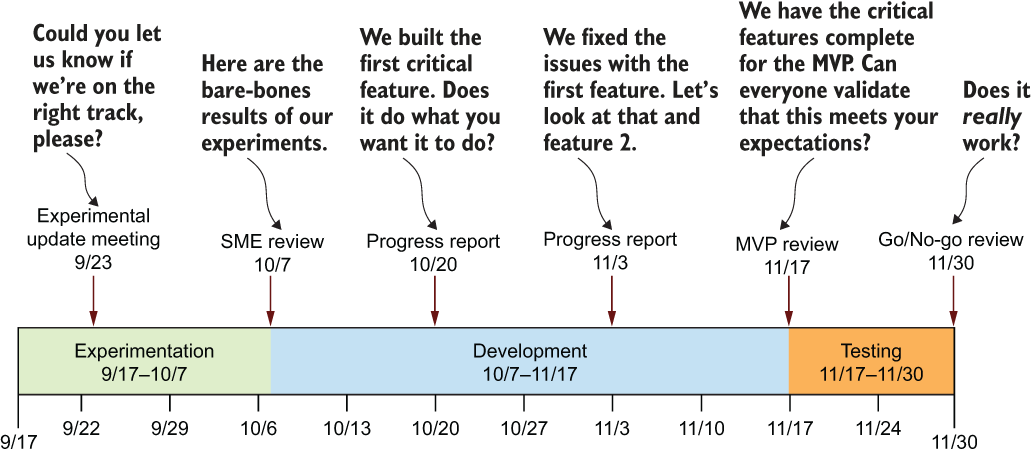
Figure 4.9 A translation of the critical meeting boundaries during the project
Depending on the type of project being built, countless more meetings may be spread throughout the phases (as well as follow-up meetings for months after release to review metrics, statistics, and estimations of the resiliency of the solution). Even if the development phase takes nine months, for instance, the biweekly progress report meetings are just repetitive discussions on the progress of accomplishments during the previous sprint. We’re going to break down these phases in detail next.
4.2.1 Experimental update meeting: Do we know what we’re doing here?
The experimental update meeting is the one that the DS team dreads more than any other, and the meeting that everyone else is incredibly excited for. The meeting interrupts the DS team in the midst of half-baked prototype implementations and unfinished research. The state of elements in flux is at nearly peak entropy.
This meeting is perhaps the second most important meeting in a project, though. This is the second-to-last time for the team members to have the ability to graciously raise a white flag in surrender if they’ve discovered that the project is untenable, will end up taking more time and money than the team has allocated, or is of such complexity that technologies will not be invented within the next 50 years to meet the requirements set forth. This is a time for honesty and reflection. It’s a time to set one’s ego aside and admit defeat, should the situation call for it.
The overriding question dominating this discussion should be, “Can we actually figure this out?” Any other discussions or ideations about the project are completely irrelevant at this point. It is up to the DS team to report on the status of its discoveries (without getting into the weeds of model-specific details or additional algorithms that they will be employing for testing, for example). The most critical discussion points for this meeting should be the following:
Aside from these direct questions, there really isn’t much else to discuss that will do anything other than waste the time of the DS team at this point. These questions are all designed to evaluate whether this project is tenable from a personnel, technology, platform, and cost perspective.
Provided that the answers are all positive in this meeting, work should commence in earnest. (Hopefully, no further interruptions to the work of the DS team members occur so that they can meet the next deadline and present at the next meeting.)
4.2.2 SME review/prototype review: Can we solve this?
By far the most important of the early meetings, the SME review is one you really don’t want to skip. This is the point at which a resource commit occurs. It’s the final decision on whether this project is going to happen or will be put into the backlog while a simpler problem is solved.
During this review session, the same questions should be asked as in the preceding meeting with the SME group. The only modification is that they should be tailored to answering whether the capability, budget, and desire exist for developing the full solution, now that the full scope of the work is more fully known.
The main focus of this discussion is typically on the mocked-up prototype. For our recommendation engine, the prototype may look like a synthetic wireframe of the website with a superimposed block of product image and labels associated with the product being displayed. It is always helpful, for the purposes of these demonstrations, to use real data. If you’re showing a demonstration of recommendations to a group of SME members, show their data. Show the recommendations for their account (with their permission, of course!) and gauge their responses. Record each positive—but more important, each negative—impression that they give.
At the end of the demonstration, the entire team should have the ability to gauge whether the project is worth pursuing. You’re looking for consensus that the recommended approach is something that everyone in the group (regardless of whether they know how it works) is comfortable with as an appropriate direction that the project is about to take.
Unanimity is not absolutely critical. But the team will be more cohesive if everyone’s concerns are addressed and an unbiased and rational discussion is had to assuage their fears.
4.2.3 Development progress review(s): Is this thing going to work?
The development progress reviews are opportunities to “right the ship” during development. The teams should be focusing on milestones, such as these that show off the current state of the features being developed. Using the same wireframe approach used in the experimentation review phase is useful, as well as using the same prototype data so that a direct comparison between earlier stages can be seen by the entire team. Having a common frame of reference for the SMEs is helpful in order for them to gauge the subjective quality of the solution in terms that they fully understand.
The first few of these meetings should be reviews of the actual development. While the details should never go into the realm of specific aspects of software development, model tuning, or technical details of implementation, the overall progress of feature development should be discussed in abstract terms.
If, at a previous meeting, the quality of the predictions was determined to be lacking in one way or another, an update and a demonstration of the fix should be shown to ensure that the problems were solved to the satisfaction of the SME group. It is not simply sufficient to claim that “the feature is complete and has been checked into master.” Prove it instead. Show them the fix with the same data that they had to originally identify the problem.
As the project moves further and further along, these meetings should become shorter and more focused on integration aspects. By the time the final meeting comes along for a recommendation project, the SME group should be looking at an actual demo of the website in a QA environment. The recommendations should be updating as planned through navigation, and validation of functionality on different platforms should be checked. As the complexity grows in these later stages, it can be helpful to push out builds of the QA version of the project to the SME team members so that they can evaluate the solution on their own time, bringing their feedback to the team at a regularly scheduled cadence meeting.
4.2.4 MVP review: Did you build what we asked for?
By the time you’re having the MVP review, everyone should be both elated and quite burned out on the project. It’s the final phase; the internal engineering reviews have been done, the system is functioning correctly, the integration tests are all passing, latencies have been tested at large burst-traffic scale, and everyone involved in development is ready for a vacation.
The number of times I’ve seen teams and companies release a solution to production right at this stage is astounding. Each time that it’s happened, they’ve all regretted it. After an MVP is built and agreed upon, the next several sprints should focus on code hardening (creating production-ready code that is testable, monitored, logged, and carefully reviewed—we’ll get to all of these topics in parts 2 and 3 of this book).
Successful releases involve a stage after the engineering QA phase is complete in which the solution undergoes UAT. This stage is designed to measure the subjective quality of the solution, rather than the objective measures that can be calculated (statistical measures of the prediction quality) or the bias-laden subjective measure of the quality done by the SMEs on the team who are, by this point, emotionally invested in the project.
UAT phases are wonderful. It’s at this point when the solution finally sees the light of day in the form of feedback from a curated group of people who were external to the project. This fresh, unbiased set of eyes can see the proposed solution for what it is, not for the toil and emotion that went into building it.
While all of the other work in the project is effectively measured via the Boolean scale of works/doesn’t work, the ML aspect is a sliding scale of quality dependent on the interpretations of the end consumer of the predictions. For something as subjective as the relevancy of recommendations to an end user, this scale can be remarkably broad. To gather relevant data to create adjustments, one effective technique is a survey (particularly for a project as subjective as recommendations). Providing feedback based on a controlled test with a number ranking of effective quality can allow for standardization in the analysis of the responses, giving a broad estimation of any additional elements that need to be added to the engine or settings that need to be modified.
The critical aspect of this evaluation and metric collection is to ensure that the members evaluating the solution are not in any way vested in creating it, nor are they aware of the inner workings of the engine. Having foreknowledge of the functionality of any aspect of the engine may taint the results, and certainly if any of project team members were to be included in the evaluation, the review data would be instantly suspect.
When evaluating UAT results, it is important to use appropriate statistical methodologies to normalize the data. Scores, particularly those on a large numeric scale, need to be normalized within the range of scores that each user provides to account for review bias that most people have (some tending to either score maximum or minimum, others gravitating around the mean value, and others being overly positive in their review scores). Once normalized, the importance of each question and how it impacts the overall predictive quality of the model can be assessed and ranked, and a determination of feasibility to implement be conducted. Provided that there is enough time, the changes are warranted, and the implementation is of a low-enough risk to not require an additional full round of UAT, these changes may be implemented in order to create the best possible solution upon release.
Should you ever find yourself having made it through a UAT review session without a single issue being found, either you’re the luckiest team ever, or the evaluators are completely checked out. This is quite common in smaller companies, where nearly everyone is fully aware and supportive of the project (with an unhealthy dose of confirmation bias). It can be helpful to bring in outsiders in this case to validate the solution (provided that the project is not something, for instance, akin to a fraud detection model or anything else of extreme sensitivity).
Many companies that are successful in building solutions for external-facing customers typically engage in alpha or beta testing periods of new features for this exact purpose: to elicit high-quality feedback from customers who are invested in their products and platforms. Why not use your most passionate end users (either internal or external) to give feedback? After all, they’re the ones who are going to be using what you’re building.
4.2.5 Preproduction review: We really hope we didn’t screw this up
The end is nigh for the project. The final features have been added from UAT feedback, the development has been finished, the code hardened, QA checks have all passed, and the solution has been running for over a week without a single issue in a stress-testing environment. Metrics are set up for collecting performance, and analytics reporting datasets have been created, ready to be populated for measuring the success of the project. The last thing to do is to ship it to production.
It’s best to meet one final time, but not for self-congratulations (definitely do that later, though, as a full cross-functional team). This final preproduction review meeting should be structured as a project-based retrospective and analysis of features. Everyone at this meeting, regardless of area of expertise and level of contribution to the final product, should be asking the same thing: “Did we build what we set out to build?”
To answer this question, the original plans should be compared to the final designed solution. Each feature that was in the original design should be gone through and validated that it functions in real time from within the QA (testing) environment. Do the items get filtered out when switching between pages? If multiple items are added to the cart in succession, do all of those related products get filtered or just the last one? What if items are removed from the cart—do the products stay removed from the recommendations? What happens if a user navigates the site and adds a thousand products to the cart and then removes all of them?
Hopefully, all of these scenarios have been tested long before this point, but it’s an important exercise to engage in with the entire team to ensure that the functionality is conclusively confirmed to be implemented correctly. After this point, there’s no going back; once it’s released to production, it’s in the hands of the customer, for better or for worse. We’ll get into how to handle issues in production in later chapters, but for now, think of the damage to the reputation of the project if something that is fundamentally broken is released. It’s this last preproduction meeting where concerns and last-minute fixes can be planned before the irrevocable production release.
4.3 Setting limits on your experimentation
We’ve gone through the exhausting slog of preparing everything that we can up until this point for the recommendation engine project. Meetings have been attended, concerns and risks have been voiced, plans for design have been conducted and based on the research phase, and we have a clear set of models to try out. It’s finally time to play some jazz, get creative, and see if we can make something that’s not total garbage.
Before we get too excited, though, it’s important to realize that, as with all other aspects of ML project work, we should be doing things in moderation and with a thoughtful purpose behind what we’re doing. This applies more so to the experimentation phase than any other aspect of the project—primarily because this is one of the few completely siloed-off phases.
What might we do with this personalized recommendation engine if we had all the time and resources in the world? Would we research the latest whitepaper and try to implement a completely novel solution? (You may, depending on your industry and company.) Would we think about building a broad ensemble of recommendation models to cover all of our ideas? (Let’s do a collaborative filtering model for each of our customer cohorts based on their customer lifetime value scores for propensity and their general product-group affinity, and then merge that with an FP-growth market-basket model to populate sparse predictions for certain users.) Perhaps we would build a graph-embedding to a deep learning model that would find relationships in product and user behavior to potentially create the most sophisticated and accurate predictions achievable.
All of these are neat ideas and could be worthwhile if the entire purpose of our company was to recommend items to humans. However, these are all very expensive to develop in the currency that most companies are most strapped for: time.
We need to understand that time is a finite resource, as is the patience of the business unit requesting the solution. As we discussed in section 3.2.2, the scoping of the experimentation is tied directly to the resources available: the number of data scientists on the team, the number of options we are going to attempt to compare, and, most critically, the time that we have to complete this. The final limitations that we need to control for, knowing that there are limited constraints on time and developers, is that only so much can be built within an MVP phase.
It’s tempting to want to fully build out a solution that you have in your head and see it work exactly as you’ve designed it. This works great for internal tools that are helping your own productivity or projects that are internal to the DS team. But pretty much every other thing that an ML engineer or data scientist is going to work on in their careers has a customer aspect, be it an internal or external one. This means that you will have someone else depending on your work to solve a problem. They will have a nuanced understanding of the needs of the solution that might not align with your assumptions.
Not only is it, as mentioned earlier, incredibly important to include them in the process of aligning the project to the goals, but it’s potentially dangerous to fully build out a tightly coupled and complex solution without getting their input on the validity of what you’re building to the issue of solving the problem. The way of solving this issue of involving the SMEs in the process is to set boundaries around prototypes that you’ll be testing.
4.3.1 Set a time limit
Perhaps one of the easiest ways to stall or cancel a project is by spending too much time and effort on the initial prototype. This can happen for any number of reasons, but most of them, I’ve found, are due to poor communication within a team, incorrect assumptions by non-DS team members about how the ML process works (refinement through testing with healthy doses of trial, error, and reworking mixed in), or an inexperienced DS team assuming that they need to have a “perfect” solution before anyone sees their prototypes.
The best way to prevent this confusion and complete wasting of time is to set limits on the time allotted for experimentation surrounding vetting of ideas to try. By its very nature, this limitation will eliminate the volume of code written at this stage. It should be clear to all members of the project team that the vast majority of ideas expressed during the planning stages are not going to be implemented for the vetting phase; rather, in order to make the crucial decision about which implementation to go with, the bare minimum amount of the project should be tested.
Figure 4.10 shows the most minimalistic amount of implementation required to achieve the goals of the experimentation phase. Any additional work, at this time, does not serve the need at the moment: to decide on an algorithm that will work well at scale and at cost, and that meets objective and subjective quality standards.
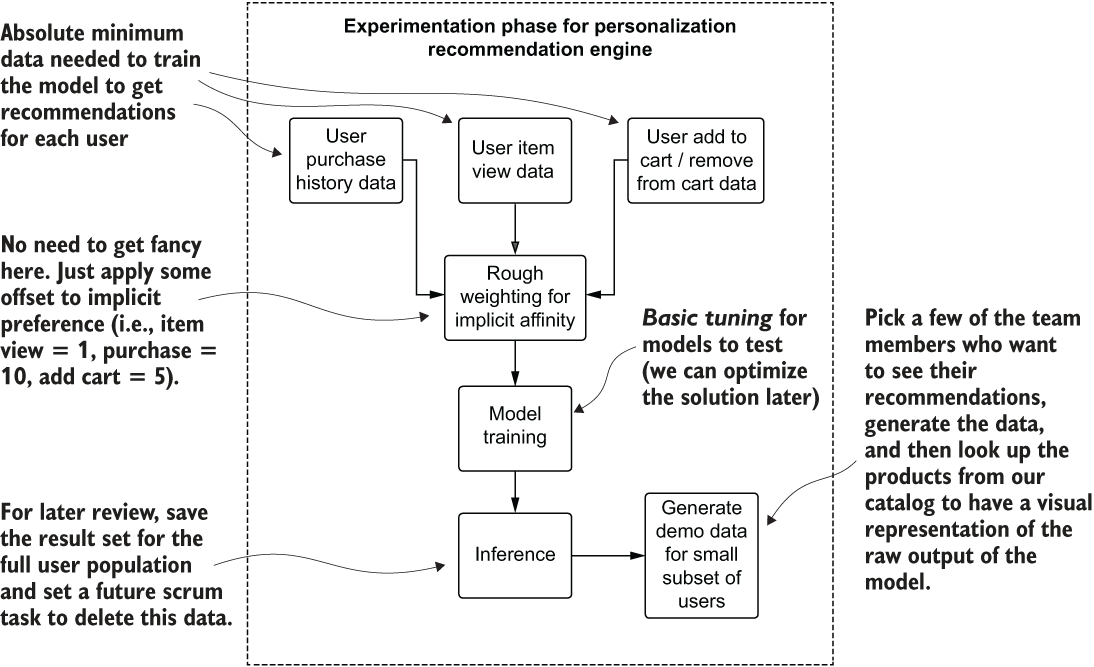
Figure 4.10 Mapping the high-level experimentation phase for the teams testing ideas
In comparison, figure 4.11 shows a simplified view of some potential core features based on the initial plan from the planning meeting.
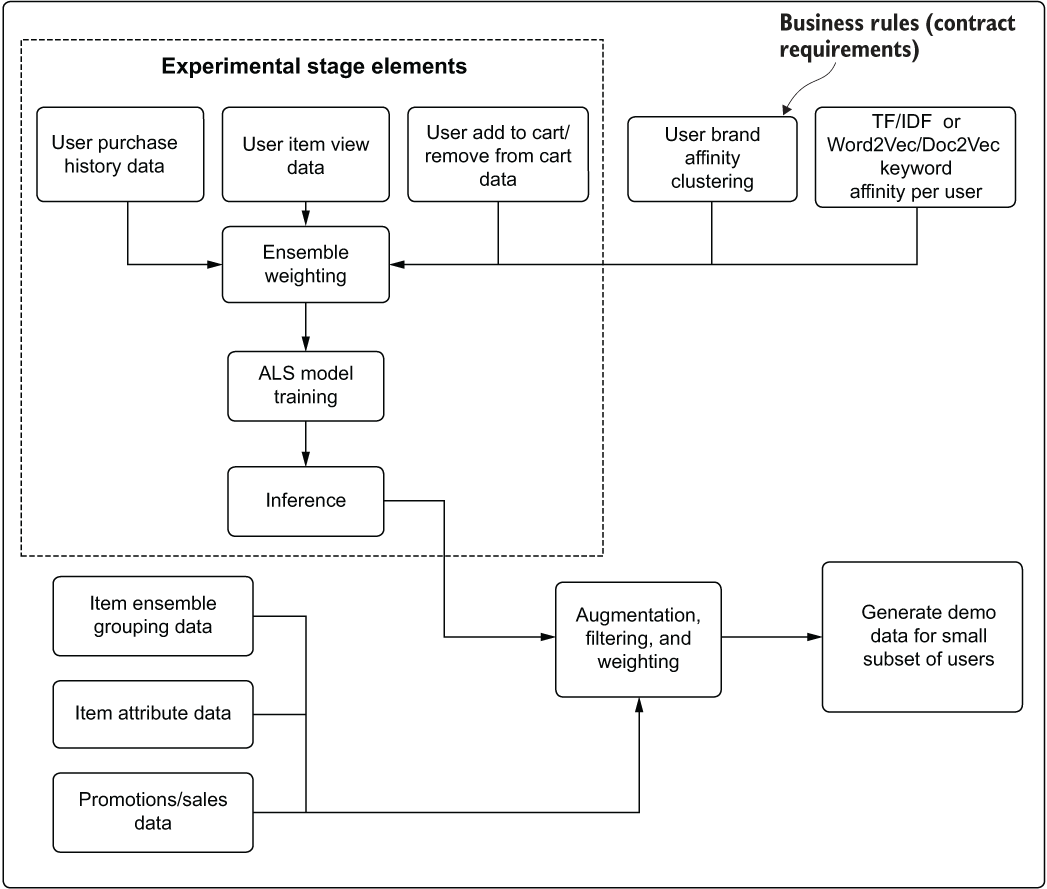
Figure 4.11 A pseudo architectural plan for the expanded features involved in the development phase, realized by conducting effective experimentation and getting feedback from the larger team
By comparing figure 4.10 and figure 4.11, it should be easy to imagine the increasing scope of work involved in the transition from the first plan to the second. Entirely new models need to be built, a great deal of dynamic run-specific aggregations and filtering need to be done, custom weighting must be incorporated, and potentially dozens of additional datasets need to be generated. None of these elements solves the core problem at the boundary of experimentation: which model should we go with for developing?
Limiting the time to make this decision will prevent (or at least minimize) the natural tendency of most ML practitioners to want to build a solution, regardless of plans that have been laid out. Sometimes forcing less work to get done is a good thing for the cause of reducing churn and making sure the right elements are being worked on.
4.3.2 Can you put this into production? Would you want to maintain it?
While the primary purpose of an experimentation phase, to the larger team, is to make a decision on the predictive capabilities of a model’s implementation, one of the chief purposes internally, among the DS team, is to determine whether the solution is tenable for the team. The DS team lead, architect, or senior DS person on the team should be taking a close look at what is going to be involved in this project, asking difficult questions, and producing honest answers. Some of the most important questions are as follows:
- How long is this solution going to take to build?
- How complex is this code base going to be?
- How expensive is this going to be to train based on the schedule it needs to be retrained at?
- Does my team have the skill required to maintain this solution? Does everyone know this algorithm/language/platform?
- How quickly will we be able to modify this solution should something dramatically change with the data that it’s training or inferring on?
- Has anyone else reported success with using this methodology/platform/language/API? Are we reinventing the wheel or are we building a square wheel?
- How much additional work will the team have to do to make this solution work while meeting all of the other feature goals?
- Is this going to be extensible? When the inevitable version 2.0 of this is requested, will we be able to enhance this solution easily?
- Is this testable?
- Is this auditable?
Innumerable times in my career, I’ve been either the one building these prototypes or the one asking these questions while reviewing someone else’s prototype. Although an ML practitioner’s first reaction to seeing results is frequently, “Let’s go with the one that has the best results,” many times the “best” one ends up being either nigh-impossible to fully implement or a nightmare to maintain.
It is of paramount importance to weigh these future-thinking questions about maintainability and extensibility, whether regarding the algorithm in use, the API that calls the algorithm, or the very platform that it’s running on. Taking the time to properly evaluate the production-specific concerns of an implementation, instead of simply the predictive power of the model’s prototype, can mean the difference between a successful solution and vaporware.
4.3.3 TDD vs. RDD vs. PDD vs. CDD for ML projects
We seem to have an infinite array of methodologies to choose from when developing software. From waterfall to the Agile revolution (and all of its myriad flavors), each has benefits and drawbacks.
We won’t discuss the finer points of which development approach might be best for particular projects or teams. Absolutely fantastic books have been published that explore these topics in depth, and I highly recommend reading them to improve the development processes for ML projects. Becoming Agile in an Imperfect World by Greg Smith and Ahmed Sidky (Manning, 2009) and Test Driven: TDD and Acceptance TDD for Java Developers by Lasse Koskela (Manning, 2007) are notable resources. Worth discussing here, however, are four general approaches to ML development (one being a successful methodology, the others being cautionary tales).
Test-driven development or feature-driven development
Pure test-driven development (TDD) is incredibly challenging to achieve for ML projects (and certainly unable to achieve the same test coverage in the end that traditional software development can), mostly due to the nondeterministic nature of models themselves. A pure feature-driven development (FDD) approach can cause significant rework during a project.
But most successful approaches to ML projects embrace aspects of both of these development styles. Keeping work incremental, adaptable to change, and focused on modular code that is not only testable but focused entirely on required features to meet the project guidelines is a proven approach that helps deliver the project on time while also creating a maintainable and extensible solution.
These Agile approaches will need to be borrowed from and adapted in order to create an effective development strategy that works not only for the development team, but also for an organization’s general software development practices. In addition, specific design needs can dictate slightly different approaches to implementing a particular project.
At one point, all ML projects resulted from prayer-driven development (PDD). In many organizations that are new to ML development, projects still do. Before the days of well-documented high-level APIs to make modeling work easier, everything was a painful exercise in hoping that what was being scratched and cobbled together would work at least well enough that the model wouldn’t detonate in production. That hoping (and praying) for things to “just work, please” isn’t what I’m referring to here, though.
What I’m facetiously alluding to is rather the act of frantically scanning for clues for solving a particular problem by following bad advice from either internet forums or someone who likely has no more actual experience than the searcher. The searcher may find a blog covering a technology or application of ML that seems somewhat relevant to the problem at hand, only to find out, months later, that the magical solution that they were hoping for is nothing more than fluff.
Prayer-driven ML development is the process of handing over problems that one doesn’t know how to solve into the figurative hands of some all-knowing person who has solved it before, all in the goal of eliminating the odious tasks of proper research and evaluation of technical approaches. Taking such an easy road rarely ends well. With broken code bases, wasted effort (“I did what they did—why doesn’t this work?”) and, in the most extreme cases, project abandonment, this is a problem and a development antipattern that is growing in magnitude and severity.
The most common effects that I see happen from this approach of ML “copy culture” are that people who embrace this mentality want to either use a single tool for every problem (Yes, XGBoost is a solid algorithm. No, it’s not applicable to every supervised learning task) or try only the latest and greatest fad (“I think we should use TensorFlow and Keras to predict customer churn”).
If all you know is XGBoost, everything looks like a gradient boosting problem.
When limiting yourself in this manner—not doing research, not learning or testing alternate approaches, and restricting experimentation or development to a narrow set of tools—the solution will reflect those limitations and self-imposed boundaries. In many cases, latching onto a single tool or a new fad and forcing it onto every problem creates suboptimal solutions or, more disastrously, forces you to write far more lines of unnecessarily complex code in order to fit a square peg into a round hole.
A good way of detecting whether the team (or yourself) is on the path of PDD is to see what is planned for a project’s prototyping phase. How many models are being tested? How many frameworks are being vetted? If the answer to either of these is “one,” and no one on the team has solved that particular problem several times before, you’re doing PDD. And you should stop.
Also known as cowboy development (or hacking), chaos-driven development (CDD) is the process of skipping experimentation and prototyping phases altogether. It may seem easier at first, since not much refactoring is happening early on. However, using such an approach of building ML on an as-needed basis during project work is fraught with peril.
As modification requests and new feature demands arise through the process of developing a solution, the sheer volume of rework, sometimes from scratch, slows the project to a crawl. By the end (if it makes it that far), the fragile state of the DS team’s sanity will entirely prevent any future improvements or changes to the code because of the spaghetti nature of the implementation.
If there is one thing that I hope you take away from this book, it’s to avoid this development style. I’ve not only been guilty of it in my early years of ML project work, but have also seen it become one of the biggest reasons for project abandonment in companies that I’ve worked with. If you can’t read your code, fix your code, or even explain how it works, it’s probably not going to work well.
By far the most detrimental development practice—designing an overengineered, show-off implementation to a problem—is one of the primary leading causes of projects being abandoned after they are in production. These resume-driven development (RDD) implementations are generally focused on a few key characteristics:
- A novel algorithm is involved.
- A new (unproven in the ML community) framework for executing the project’s job is involved (with features that serve no purpose in solving the problem).
- A blog post, or series of blog posts, about the solution are being written during development (after the project is done is fine, though!).
- An overwhelming amount of the code is devoted to the ML algorithm as opposed to feature engineering or validation.
- An abnormal level of discussion in status meetings is about the model, rather than the problem to be solved.
This isn’t to say that novel algorithm development or incredibly in-depth and complex solutions aren’t called for. They most certainly can be. But they should be pursued only if all other options have been exhausted.
For the example that we’ve been reviewing throughout this chapter, if someone were to go from a position of having nothing in place at all to proposing a unique solution that has never been built before, objections should be raised. This development practice and the motivations behind it are not only toxic to the team that will have to support the solution but will poison the well of the project and almost guarantee that it will take longer, be more expensive, and do nothing apart from pad the developer’s resume.
4.4 Planning for business rules chaos
As part of our recommendation engine that we’ve been building throughout this chapter (or, at least, speaking of the process of building), a great many features crept up that were implemented and that augmented the results of the model. Some of these were to solve particular use cases for the end result (collection aggregations to serve the different parts of the site and app for visualization purposes, for instance), while others were designed for contractual obligations to vendors.
The most critical ones protect users from offense or filter inappropriate content. I like to refer to all of these additional nuances to ML as business rules chaos. These specific restrictions and controls are incredibly important but also frequently the most challenging aspects of a project to implement correctly.
Failing to plan for them accordingly (or failing to implement them entirely) is an almost guarantee that your project will be shelved before it hits its expected release date. If these restrictions are not caught before release, they could damage the brand of your company.
4.4.1 Embracing chaos by planning for it
Let’s pretend for a moment that the DS team working on the MVP for the recommendation engine doesn’t realize that the company sells sensitive products. This is understandable, since most e-commerce companies sell a lot of products, and the DS team members are not product specialists. They may be users of the site, but certainly aren’t all likely to be intimately familiar with everything that’s sold. Since they aren’t aware that items could be offensive as part of recommendations, they fail to identify these items and filter them out of their result sets.
There’s nothing wrong with missing this detail. In my experience, details like this always come up in complex ML solutions. The only way to plan for them is to expect things like this to come up, and to architect the code base in such a way that it has proverbial “levers and knobs”—functions or methods that can be applied or modified through passed-in configurations. Then, implementing a new restriction doesn’t require a full code rewrite or weeks of adjustments to the code base to implement.
When in the process of developing a solution, a lot of ML practitioners tend to think mostly about the quality of the model’s predictive power above all other things. Countless hours of experimentation, tuning, validating, and reworking of the solution is done in the pursuit of attaining a mathematically optimal solution that will solve the problem best in terms of validation metrics. Because of this, it can be more than slightly irritating to find out that, after having spent so much time and energy in building an ideal system, additional constraints need to be placed onto the model’s predictions.
These constraints exist in almost all systems (either initially or eventually if the solution is in production for long enough) that have predictive ML at their core. There may be legal reasons to filter or adjust the results in a financial system. There could, perhaps, be content restrictions on a recommendation system based on preventing a customer from taking offense to a prediction (trust me, you don’t want to explain to anyone why a minor was recommended an adult-oriented product). Whether for financial, legal, ethical, or just plain old common-sense reasons, inevitably something is going to have to change with the raw predictions from most ML implementations.
It’s definitely a best practice to understand potential restrictions before you start spending too much time in development of a solution. Knowing restrictions ahead of time can influence the overall architecture of the solution and the feature engineering, and allow for controlling the method in which an ML model learns the vector. It can save the team countless hours of adjustment and eliminate costly-to-run and difficult-to-read code bases filled with never-ending chains of if/elif/else statements to handle post hoc corrections to the output of the model.
For our recommendation engine project, a lot of rules likely need to be added to a raw predictive output from an ALS model. As an exercise, let’s revisit the earlier development phase work component diagram. Figure 4.12 shows the elements of the planned solution specifically intended to enforce constraints on the output of the recommendations. Some are absolutely required—contract requirement elements, as well as filters intended to cull products that are inappropriate for certain users. Others are ideas that the project team suspects are going to be heavily influential in getting the user to engage with the recommendation.
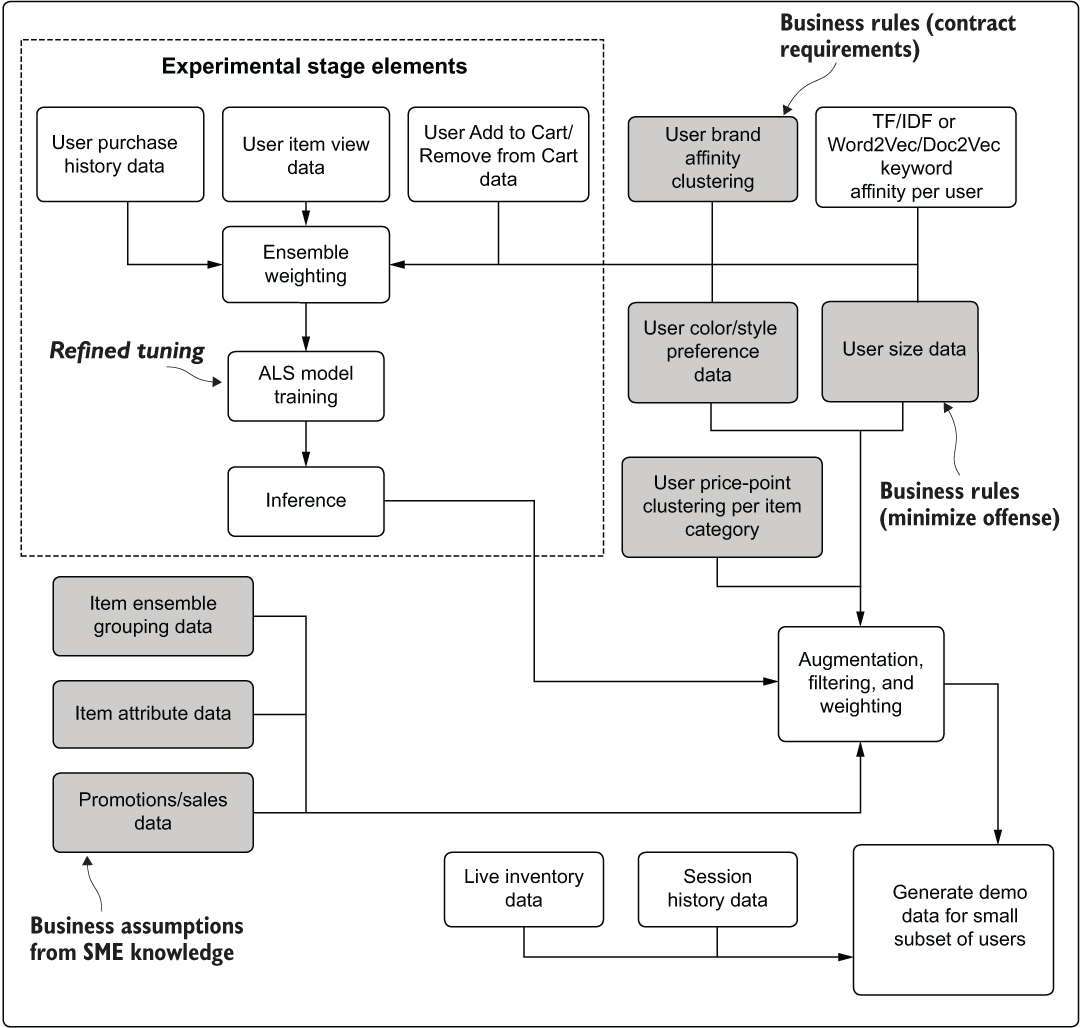
Figure 4.12 Identifying business contextual requirements for the recommendation engine project—a risk-detection diagram, in other words
This diagram shows the locations, but more important, the type of business restriction to the model. In the planning phases, after experimentation and before full development begins, it is worthwhile to identify and classify each of these features.
The absolutely required aspects, shown in figure 4.12 as Business Rules, must be planned within the scope of the work and built as an integral part of the modeling process. Whether they’re constructed in such a way as to be tune-able aspects of the solution (through weights, conditional logic, or Boolean switches) is up to the needs of the team, but they should be considered essential features, not optional or testable features.
The remaining aspects of rules, marked in figure 4.12 as Business Assumptions, can be handled in various ways. They could be prioritized as testable features (configurations will be built that allow for A/B testing different ideas for fine-tuning the solution). Alternatively, they could be seen as future work that is not part of the initial MVP release of the engine, simply implemented as placeholders within the engine that can be easily modified at a later time.
4.4.2 Human-in-the-loop design
Whichever approach works best for the team (and particularly for the ML developers working on the engine), the important fact to keep in mind is that these sorts of restrictions to the model output should be identified early and allowances be made for them to be mutable for the purposes of changing their behavior, if warranted. The last thing that you want to build for these requirements, though, is hardcoded values in the source code that would require a modification to the source code in order to test.
It’s best to approach these items in a way that you can empower the SMEs to modify the performance, to rapidly change the behavior of the system without having to take it down for a lengthy release period. You also want to ensure that controls are established that restrict the ability to modify these without going through appropriate validation procedures.
4.4.3 What’s your backup plan?
What happens when there’s a new customer? What happens with recommendations for a customer that has returned after having not visited your site in more than a year? What about for a customer who has viewed only one product and is returning to the site the next day?
Planning for sparse data isn’t a concern just for recommendation engines, but it certainly impacts their performance more so than other applications of ML.
All ML projects should be built with an expectation of data-quality issues arising, necessitating the creation of fallback plans when data is malformed or missing. This safety mode can be as complex as using registration information or IP geolocation tracking to pull aggregated popular products from the region that the person is logging in from (hopefully, they’re not using a virtual private network, or VPN), or can be as simple as generic popularity rankings from all users. Whichever methodology is chosen, it’s important to have a safe set of generic data to fall back to if personalization datasets are not available for the user.
This general concept applies to many use cases, not just recommendation engines. If you’re running predictions but don’t have enough data to fully populate the feature vector, this could be a similar issue to having a recommendation engine cold-start problem. There are multiple ways to handle this issue, but at the stage of planning, it’s important to realize that this is going to be a problem and that a form of fallback should be in place in order to produce some level of information to a service expecting data to be returned.
4.5 Talking about results
Explaining how ML algorithms work to a layperson is challenging. Analogies, thought-experiment-based examples, and comprehensible diagrams to accompany them are difficult at the best of times (when someone is asking for the sake of genuine curiosity). When the questions are posed by members of a cross-functional team who are trying to get a project released, it can be even more challenging and mentally taxing, since they have expectations regarding what they want the black box to do. When those same team members are finding fault with the prediction results or quality and are aggravated at the subjectively poor results, this adventure into describing the functionality and capabilities of the chosen algorithms can be remarkably stressful.
In any project’s development, whether at the early stages of planning, during prototype demonstrations, or even at the conclusion of the development phase while the solution is undergoing UAT assessment, questions will invariably come up. The following questions are specific to our example recommendation engine, but I can assure you that alternative forms of these questions can be applied to any ML project, from a fraud-prediction model to a threat-detection video-classification model:
- “Why does it think that I would like that? I would never pick something like that for myself!”
- “Why is it recommending umbrellas? That customer lives in the desert. What is it thinking?!”
- “Why does it think that this customer would like t-shirts? They only buy haute couture.”
The flippant answer to all of these questions is simple: “It doesn’t think. The algorithm only ‘knows’ what we ‘taught’ it.” (Pro tip: if you’re going to use this line, don’t; for the sake of further tenure in your position, place emphasis on those quoted elements when delivering this line. On second thought, don’t talk to colleagues like this, even if you’re annoyed at having to explain this concept for the 491st time during the project.) The acceptable answer, conveyed in a patient and understanding tone, is one of simple honesty: “We don’t have the data to answer that question.” It’s best to exhaust all possibilities of feature-engineering creativity before claiming that, but if you have, it’s really the only answer that is worth giving.
What has been successful for me is to explain this issue and its root cause through articulating the concept of cause and effect, but in a way that relates to the ML aspect of the problem. Figure 4.13 shows a helpful visualization for explaining what ML can, but also, more important, what it cannot do.
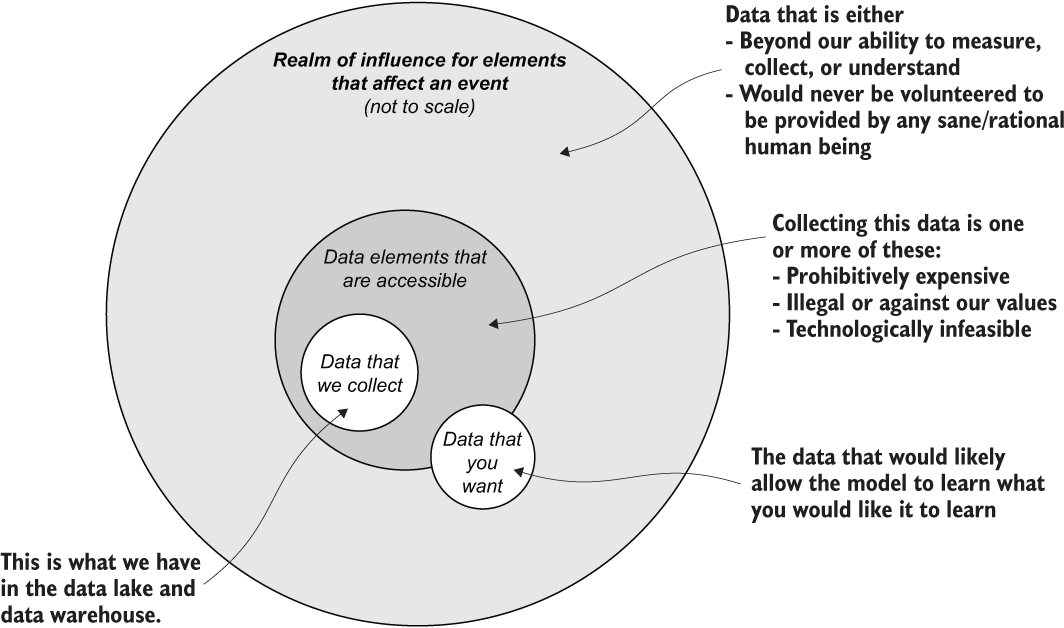
Figure 4.13 Realms of data for ML—we can’t have it all
As figure 4.13 shows, the data that the person in the review meeting is asking for is simply beyond the capability to acquire. Perhaps the data that would inform someone’s subjective preference for a pair of socks is of such a personal nature that there is simply no way to infer or collect this information. Perhaps, in order to have the model draw the conclusion that is being asked for, the data to be collected would be so complex, expensive to store, or challenging to collect that it’s simply not within the budget of the company to do so.
When an SME at the meeting asks, “Why didn’t this group of people add these items to their cart if the model predicted that these were so relevant for them?,” there is absolutely no way you can answer that. Instead of dismissing this line of questioning, which will invariably lead to irritation and frustration from the asker, simply posit a few questions of your own while explaining the view of reality that the model can “see.” Perhaps the user was shopping for someone else. Perhaps they’re looking for something new that they were inspired by from an event that we can’t see in the form of data. Perhaps they simply just weren’t in the mood.
There is a staggering infiniteness to the latent factors that can influence the behavior of events in the “real world.” Even if you were to collect all of the knowable information and metrics about the observable universe, you would still not be able to predict, reliably, what is going to happen, where it’s going to happen, and why it will or will not happen as such. It’s understandable for that SME to want to know why the model behaved a certain way and the expected outcome (the user giving us money for our goods) didn’t happen; as humans, we strive for explainable order.
Relax. We, like our models, can’t be perfect.
The world’s a pretty chaotic place. We can only hope to guess right at what’s going to happen more than we guess wrong.
Explaining limitations in this way (that we can’t predict something that we don’t have information to train on) can help, particularly at the outset of the project, to dispel assumed unrealistic capabilities of ML to laypeople. Having these discussions within the context of the project and including how the data involved relates to the business can be a great tool in eliminating disappointment and frustration later as the project moves forward through milestones of demos and reviews.
Explaining expectations clearly, in plain-speak, particularly to the project leader, can be the difference between an acceptable risk that can be worked around in creative ways and a complete halt to the project and abandonment due to the solution not doing what the business leader had in mind. As so many wise people have said throughout the history of business, “It’s always best to under-promise and over-deliver.”
Summary
- Focusing cross-functional team communication on objective, nontechnical, solution-based, and jargon-free speech will aid in creating a collaborative and inclusive environment that ensures an ML project meets its goals.
- Establishing specific milestones for project functionality demonstrations to a broad team of SMEs and internal customers will dramatically reduce rework and unexpected functionality shortcomings in ML projects.
- Approaching the complexities of research, experimentation, and prototyping work with the same rigor that is applied to Agile development can reduce the time to arrive at a viable option for development.
- Understanding, defining, and incorporating business rules and expectations early in a project will help ensure that ML implementations are adapted and designed around these requirements, rather than shoehorning them in after a solution is already built.
- Avoiding discussion about implementation details, esoteric ML-related topics, and explanations about how the internals of an algorithm work will help deliver a clear and focused discussion of the performance of a solution, allowing for creative discourse from all team members.