
13 ML development hubris
- Applying refactoring to overengineered implementations to increase development velocity
- Identifying code to target for refactoring
- Establishing simplicity-driven development practices
- Adopting new technologies via sustainable means
- Comparing build, buy, and prior art in implementations
The preceding chapter focused on critical components used to measure a project’s overall health from a purely prediction-focused and solution efficacy perspective. ML projects that are built to support longevity through effective and detailed monitoring of their inputs and outputs are certainly guaranteed to have a far higher success rate than those that do not. However, this is only part of the story.
Another major factor in successful projects has to do with the human side of the work. Specifically, we need to consider the humans involved in supporting, diagnosing issues with, improving, and maintaining the project’s code base over the lifespan of the solution.
Note When a project is released to production, that is merely the beginning of its life. The real challenge of ML is to keep something running well over a long period of time.
This human element comes in the following form:
- How the code is crafted—Can other people read it and understand it?
- How the code performs—Is it deterministic? Does it have unintentional side effects?
- How complex the code is—Is it over- or under-engineered for the use case?
- How easy it is to improve—ML code is in a constant state of refactoring.
Throughout this chapter, we’ll look at signs to watch out for that define patterns making an ML code base a nightmare to maintain. From fancy code flexing (show-off developers) to empire-building framework creators, we’ll be able to identify these issues, see alternatives, and understand why the most effective design pattern for ML project code development is the same as for all of the other aspects of the project.
TIP Build something only as complex as it needs to be to solve the problem at hand. People have to maintain this code, after all.
This chapter covers many of the dangerous ways that I’ve learned the lesson of pursuing simplicity in code, defining patterns of sustainable ML development that can, hopefully, save you from some painful mistakes I’ve made over the years.
13.1 Elegant complexity vs. overengineering
Imagine for a moment that we’re starting a new project. It’s not too much of a departure from the last two chapters (spoiler alert: it has to do with dogs). We have some data about the dogs. We know their breed, age, weight, favorite food, and whether they’re generally of a favorable disposition. In addition, we have labeled data that measured whether each dog was exhibiting signs of hunger when they walked into our pet store franchise.
Armed with this data, we’d like to build a model that predicts, based on the registered data of our canine consumers, whether we should offer them a treat when they pass through the checkout line.
NOTE Yes, I’m fully aware of how silly this is. It makes my wife chuckle, though, so the scenario is staying.
As we begin working on investigating the data, we realize that we have a truly enormous amount of training data. Billions upon billions of rows of data. We’d like to utilize it all in the training of the model, though, so our platform decision leaves a simple choice for running this: Apache Spark.
Since we’ve been using Python so extensively throughout this book, let’s use this chapter to delve into another language used extensively for large-scale (in terms of training row count volume) ML projects: Scala. Since we’ll be using Spark’s ML library, in order to effectively build a feature vector from our columnar data, we’ll need to identify any noncontinuous data types and convert them to indexed integer values.
Before we get into code examples that show the differences between the topic of this section, let’s discuss the scales of ML coding practices. I like to think of development style (with regards to code complexity) as a delicate balancing act, illustrated in figure 13.1.
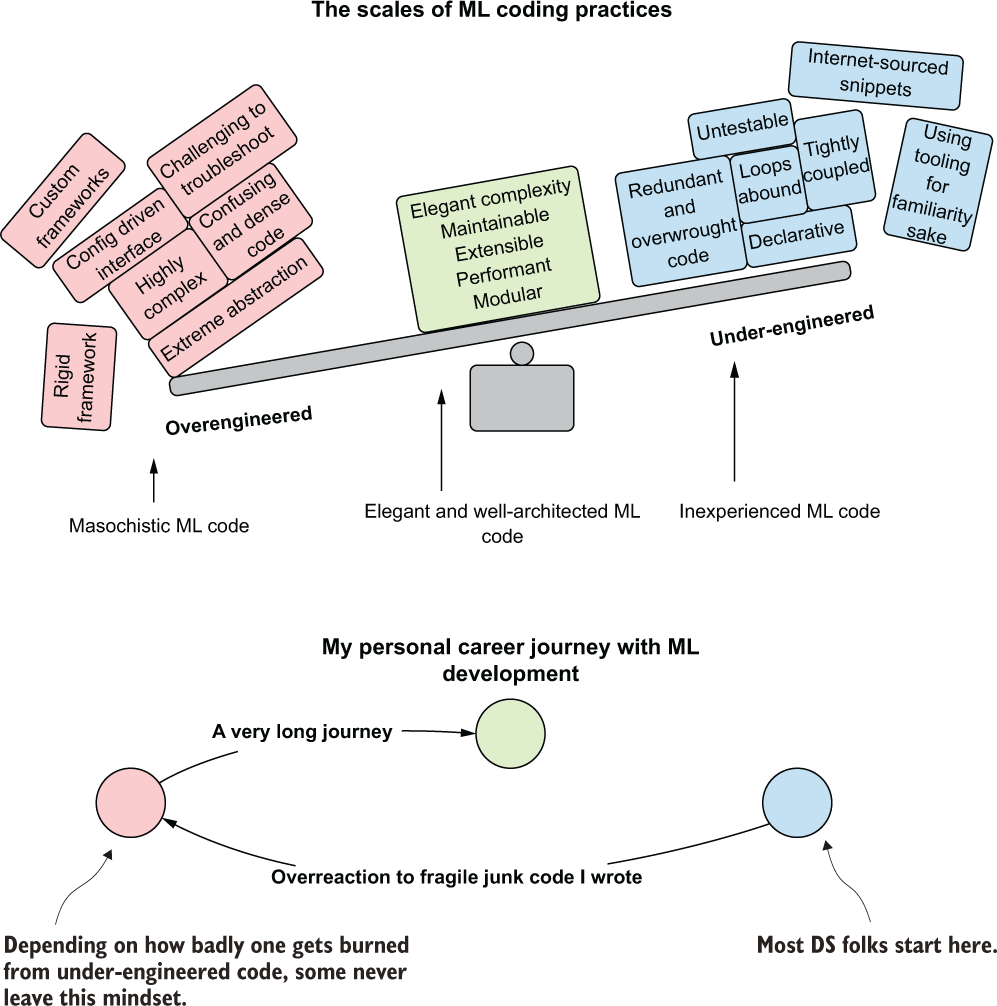
Figure 13.1 Striking a balance between these two extremes of software development practices can lead to more effective and production-stable project work.
On the right side of this scale, we have very lightweight code. It’s highly declarative (almost script-like), monotonous (statements copied and pasted many times over with slight changes to the arguments), and tightly coupled (changing one element means scouring through the code and updating all of the string-based configuration references).
These lightweight code bases often can seem like they are written by groups of people all working for different companies. In many cases, they are, as entire functions and snippets of code are lifted in their entirety from popular developer Q&A forums. An additional feature that many of them share is a reliance on heavily popular frameworks and tooling that are well-documented (or, at least, are complex enough that a sufficient density of questions and answers has been provided on the aforementioned developer forums to liberally borrow from), regardless of how well suited the use case is. Here are some key identifiers of this behavior:
- Using a framework intended for large-scale ML when the training dataset is in the thousands of rows and dozens of columns. (Instead of using SparkML, for example, stick to pandas and use Spark for training in broadcast mode.)
- Building real-time serving atop large-scale serving architecture when the request volume will never hit more than a few requests per minute. (Instead of using Kubernetes with Seldon, build a simple Flask app in a Docker container.)
- Setting up a streaming ingestion service for large-scale microbatch predictions when there are a few hundred predictions to be made per hour and the SLA can be measured in minutes. (Instead of using Kafka, Spark Structured Streaming, or Scala user-defined functions, use the Flask app.)
- Building a time-series forecasting model using an LSTM running on GPU hardware with Horovod multi-GPU gang scheduling mode for a univariate time series that can be predicted with single-digit RMSE values with a simple ARIMA model. (Use an ARIMA model and choose the far cheaper CPU-based VMs instead).
On the left side of the scale, however, is the polar opposite. The code is dense, succinct, highly abstract, and typically complex. The left side can work in some groups and organizations, but by and large, it’s unnecessary, confusing, and limits the number of people who can contribute to the project by virtue of the experience required in understanding advanced language features. Some ML engineers will, after having dealt with a sufficiently large and complex project using the lightweight scripting style of ML development, pursue the left side’s heavy code approach on subsequent projects. The struggles that they had maintaining the scripted style and all of the extensive coupling that was present might lead to an explosion of abstracted operators that rapidly borders on building a generic framework. I can quite honestly say that I was that very person, reflected in my journey at the bottom of figure 13.1.
Sitting pleasantly in the middle of the figure is the balanced approach that has the greatest probability for long-term success of a team’s development style. Let’s take a look at examples of how our code might look when getting started with these two competing polar opposites.
13.1.1 Lightweight scripted style (imperative)
Before we get into the code of the minimalistic declarative style of writing our prototype ML model, let’s take a brief look at what our data looks like. Table 13.1 shows a sample of the first five rows of the dataset.
Table 13.1 Sample of data from our hungry dog dataset
We can clearly see that the majority of our data will need to be encoded, including our label (target) of hungry.
Let’s take a look at how we could handle these encodings by building a vector and running a simple DecisionTreeClassifier by using the Pipeline API from SparkML. The code for these operations is in the following listing. (See the “Why Scala?” sidebar for why I’m choosing to show these examples in Scala rather than Python.)
Listing 13.1 Imperative model prototype
import org.apache.spark.ml.feature.{StringIndexer,
VectorAssembler,
IndexToString}
import org.apache.spark.ml.classification.DecisionTreeClassifier
import org.apache.spark.ml.evaluation.BinaryClassificationEvaluator
import org.apache.spark.ml.Pipeline
val DATA_SOURCE = dataLarger ❶
val indexerFood = new StringIndexer()
.setInputCol("favorite_food")
.setOutputCol("favorite_food_si")
.setHandleInvalid("keep")
.fit(DATA_SOURCE) ❷
val indexerBreed = new StringIndexer()
.setInputCol("breed")
.setOutputCol("breed_si")
.setHandleInvalid("keep")
.fit(DATA_SOURCE) ❸
val indexerGood = new StringIndexer()
.setInputCol("good_boy_or_girl")
.setOutputCol("good_boy_or_girl_si")
.setHandleInvalid("keep")
.fit(DATA_SOURCE)
val indexerHungry = new StringIndexer()
.setInputCol("hungry")
.setOutputCol("hungry_si")
.setHandleInvalid("error")
.fit(DATA_SOURCE) ❹
val Array(train, test) = DATA_SOURCE.randomSplit(
Array(0.75, 0.25)) ❺
val indexerLabelConversion = new IndexToString()
.setInputCol("prediction")
.setOutputCol("predictionLabel")
.setLabels(indexerHungry.labelsArray(0))
val assembler = new VectorAssembler()
.setInputCols(Array("age", "weight", "favorite_food_si",
"breed_si", "good_boy_or_girl_si")) ❻
.setOutputCol("features")
val decisionTreeModel = new DecisionTreeClassifier()
.setLabelCol("hungry_si")
.setFeaturesCol("features")
.setImpurity("gini")
.setMinInfoGain(1e-4)
.setMaxDepth(6)
.setMinInstancesPerNode(5)
.setMinWeightFractionPerNode(0.05) ❼
val pipeline = new Pipeline()
.setStages(Array(indexerFood, indexerBreed, indexerGood,
indexerHungry, assembler, decisionTreeModel,
indexerLabelConversion)) ❽
val model = pipeline.fit(train) ❾
val predictions = model.transform(test) ❿
val lossMetric = new BinaryClassificationEvaluator() ⓫
.setLabelCol("hungry_si")
.setRawPredictionCol("prediction")
.setMetricName("areaUnderROC")
.evaluate(predictions)❶ dataLarger is a Spark DataFrame containing the full dataset from the sample in table 13.1.
❷ Indexes the first String-typed column (breed) and creates a new 0th ordered descending-sort based on occurrence frequency
❸ Builds the indexer for the next categorical (String) column (good thing that there are only four of them, right?)
❹ Builds the indexer for the target (label) column
❺ Creates the train and test splits
❻ Defines the fields (columns) that will be used for the feature vector
❼ Builds a decision-tree classifier model (hyperparameters hardcoded for brevity)
❽ Defines the order of operations to take and wrap in a pipeline (heavily modified during experimentation)
❾ Fits the pipeline against the training data (performs all stages of the pipeline, returning the processing steps along with the model as a single object of staged operations)
❿ Predicts against the test data for scoring purposes
⓫ Calculates the scoring metric (in this case, areaUnderROC) and returns the metric value
This code should look relatively familiar. It’s what we all see when we look at API documentation for a particular modeling framework. In this case, it’s Spark, but similar examples exist for any particular framework. It’s of an imperative style, meaning that we’re providing the execution steps directly in our code, preserving the manner in which we would do this step by step. While it makes the code incredibly easy to read (which is why examples in Getting Started guides use this format), it’s a nightmare to modify and extend as we work through different tests during experimentation and MVP development.
I never realized how much of a struggle writing code in this imperative style would be when I first started working on ML projects. Much of my code looked like listing 13.1. So why am I harping on this, if it’s something that I admit freely to having done for dozens of projects early in my career as a data scientist?
What happens if, during our experimentation and testing, we find that we have to add more features to this model? What if we go through extensive EDA and find that there are 47 additional features that we can include that might make the model perform better? What if they’re all categorical?
Then our code, if built in the imperative design style shown in listing 13.1, will become an unmanageable wall of text. We’ll be using the Find functionality in our browser or IDE in order to know where to go in the code to update things. The VectorAssembler constructor alone will start to be a massive array of strings that will be hard to maintain.
Writing complicated code bases in this fashion is error-prone, fragile, and headache inducing. While the reasons stated previously are bad enough during the experimentation and development phases of a project, think about what happens if the source data changes (a column gets renamed in a source system). How many places in the code base would we have to update? Could we get to them all in time while we’re on call? Would we find them all and be able to recover the job before we have a service disruption for the predictions?
I’ve lived that life. My success rate for fixing things (adjusting the code base to support a fundamental change that happened upstream in the data) before the lack of new predictions became obvious and a problem was, at that time, just under 40%.
So, what I applied myself to, after suffering these frustrations, was to dance along that teetering plane of balance to the entire opposite side. I became my own (and my teams’) worst enemy by embracing extreme abstraction and object-oriented principles, and truly thought I was doing the right thing by producing incredibly complex code.
13.1.2 An overengineered mess
So, what did a younger Ben build? He built something like the following listing.
Listing 13.2 Overly complex model prototype
case class ModelReturn(
pipeline: PipelineModel,
metric: Double
) ❶
class BuildDecisionTree(data: DataFrame, ❷
trainPercent: Double,
labelCol: String) {
final val LABEL_COL = "label" ❸
final val FEATURES_COL = "features"
final val PREDICTION_COL = "prediction"
final val SCORING_METRIC = "areaUnderROC"
private def constructIndexers(): Array[StringIndexerModel] = { ❹
data.schema
.collect {
case x if (x.dataType == StringType) & (x.name != labelCol) => x.name
}
.map { x =>
new StringIndexer()
.setInputCol(x)
.setOutputCol(s"${x}_si")
.setHandleInvalid("keep")
.fit(data)
}
.toArray
}
private def indexLabel(): StringIndexerModel = { ❺
data.schema.collect {
case x if (x.name == labelCol) & (x.dataType == StringType) =>
new StringIndexer()
.setInputCol(x.name)
.setOutputCol(LABEL_COL)
.setHandleInvalid("error")
.fit(data)
}.head
}
private def labelInversion( ❻
labelIndexer: StringIndexerModel
): IndexToString = {
new IndexToString()
.setInputCol(PREDICTION_COL)
.setOutputCol(s"${LABEL_COL}_${PREDICTION_COL}")
.setLabels(labelIndexer.labelsArray(0))
}
private def buildVector( ❼
featureIndexers: Array[StringIndexerModel]
): VectorAssembler = {
val featureSchema = data.schema.names.filterNot(_.contains(labelCol))
val updatedSchema = featureIndexers.map(_.getInputCol)
val features = featureSchema.filterNot(
updatedSchema.contains) ++ featureIndexers
.map(_.getOutputCol)
new VectorAssembler()
.setInputCols(features)
.setOutputCol(FEATURES_COL)
}
private def buildDecisionTree(): DecisionTreeClassifier = { ❽
new DecisionTreeClassifier()
.setLabelCol(LABEL_COL)
.setFeaturesCol(FEATURES_COL)
.setImpurity("entropy")
.setMinInfoGain(1e-7)
.setMaxDepth(6)
.setMinInstancesPerNode(5)
}
private def scorePipeline(testData: DataFrame,
pipeline: PipelineModel): Double = {
new BinaryClassificationEvaluator()
.setLabelCol(LABEL_COL)
.setRawPredictionCol(PREDICTION_COL)
.setMetricName(SCORING_METRIC)
.evaluate(pipeline.transform(testData))
}
def buildPipeline(): ModelReturn = { ❾
val featureIndexers = constructIndexers()
val labelIndexer = indexLabel()
val vectorAssembler = buildVector(featureIndexers)
val Array(train, test) = data.randomSplit(
Array(trainPercent, 1.0-trainPercent))
val pipeline = new Pipeline()
.setStages(
featureIndexers ++
Array(
labelIndexer,
vectorAssembler,
buildDecisionTree(),
labelInversion(labelIndexer)
)
)
.fit(train)
ModelReturn(pipeline, scorePipeline(test, pipeline))
}
}
object BuildDecisionTree { ❿
def apply(data: DataFrame,
trainPercent: Double,
labelCol: String): BuildDecisionTree =
new BuildDecisionTree(data, trainPercent, labelCol)
}❶ Case class definition for currying data from the main method return signature (returns both the pipeline and the scoring metric)
❷ Class containing the model generation code. At an early phase in a project (as this level of complexity would be), this is unnecessary to generate. Refactoring dependencies within the methods will be far more complex than imperative scripting.
❸ Externalizes the constants from the methods utilizing them (final production code would have these in their own module)
❹ Maps over the contents of the DataFrame’s schema and applies a StringIndexer to any field that is of String type and is not the label (target) field.
❺ Method for generating a String indexer if the label (target) is of String type. Note that other values are not handled here, so a full generic implementation has not been built.
❻ Label inverter that converts the label back into the original values. In this implementation, there are no checks for handling if the target value does not meet the criteria for indexing. In that case, this code will throw an exception.
❼ Dynamic means of generating a feature vector by manipulating the column listing and types to include. This doesn’t include other types of data aside from numeric and string types, which would not include those other column types into the feature vector.
❽ The hyperparameters for this decision-tree classifier are hardcoded. While just a placeholder, the refactoring that will be needed in this coding style for tuning will be extensive. Since this is a private method, the main method signature will either need these values passed in as arguments, or the class constructor will need these values to be passed in at instantiation. This is a poor design.
❾ While this is a somewhat flexible design for building a pipeline based on the data passed in, it can be challenging for others to contribute to, involving paying close attention to the orders of operations that need to happen should additional stages be inserted into the pipeline constructor.
❿ Companion object to the class. This certainly should wait until the finalized API design is complete for the project.
This code might not look too absurd at first. It does, after all, greatly minimize verbosity when considering what would occur if we added additional features to the model’s feature vector. In point of fact, if we were to add even 1,000 additional features to the model, the code would stay the same. That might seem to be a distinct bonus to approaching writing ML code in this manner.
What would happen if we needed different behavior for some fields than others for the StringIndexer? Suppose that some fields could support having the invalid keys (categorical values that were not present during training) appended to a catchall index value, while others could not. In that case, we’d have to modify this code extensively. We’d need to abstract the method constructIndexers() and apply a case and match statement to generate indexers for different types of columns. We would then likely need to modify the passed-in signature argument to the wrapper methods to include a tuple (or a case class definition) of the field name and how to handle the validation of key existence.
While this approach scales well, it’s a cumbersome act to undertake during experimentation phases. Instead of focusing on validating the performance of different experiments to run against a model type, we’re spending a great deal of time refactoring our class, adding new methods, abstracting complexity away, and potentially all in the pursuit of an idea that might not work out well at all.
Approaching prototyping work in this manner (high abstraction and generalization) is a recipe for disaster when considering productivity. In the early phases of a project, it’s best to adopt a less complex style of coding that supports rapid iteration and modification. Moving toward the style exhibited in listing 13.2 is much more applicable to the final pre-release phases of a project (code hardening), specifically when the components for producing the final project solution are known, defined, and can be identified as necessary for the code base. As an example of how I approach these phases of development work, see figure 13.2.
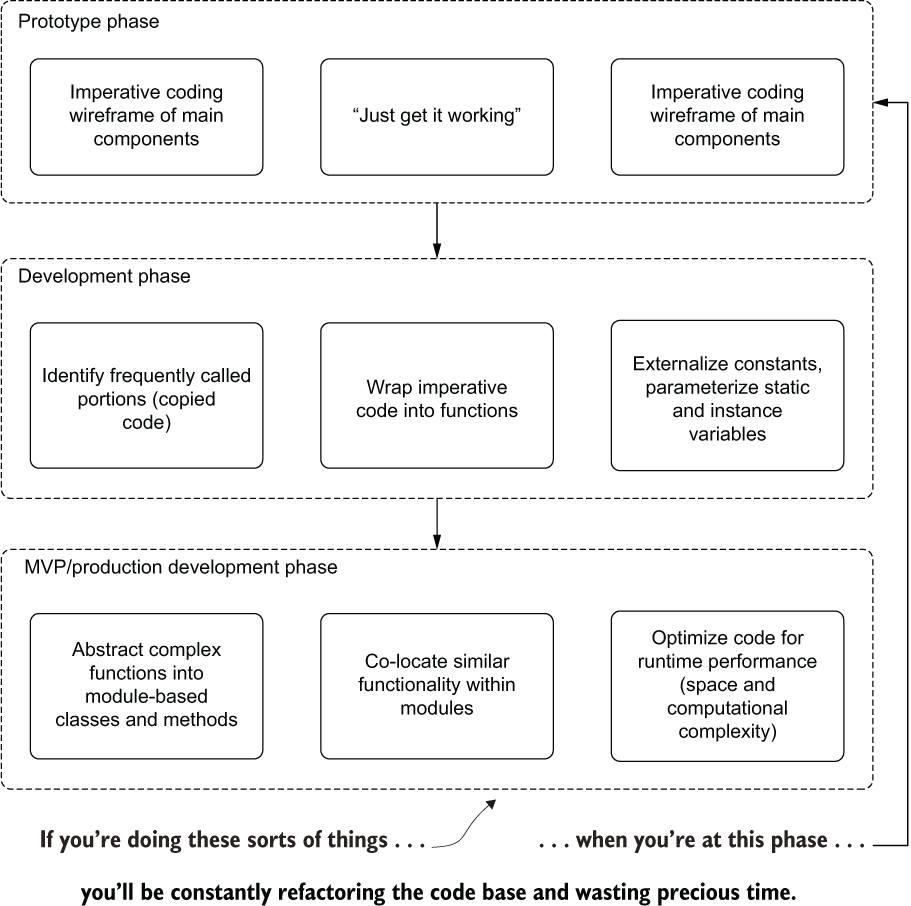
Figure 13.2 Avoiding refactoring hell by phased ML development
Because of the highly variable nature of prototyping (everything is quite fluid and elements need to change quickly), I typically stick to minimal imperative programming techniques. As the development successively moves toward a production build for the project, more and more of the complex logic is abstracted to maintainable and reusable parts in separate modules.
Building an overengineered and overly complex code architecture early in the process will, as shown in listing 13.2, create walled-in scenarios that make refactoring for feature enhancements incredibly complex. Pursuing an overengineered development approach early in a project will only waste time, frustrate the team, and eventually lead to a far more complex and difficult-to-maintain code base.
Don’t do as I did. Fancy-looking code, particularly early in development, can only bring you problems. Choosing to pursue the simplest and most minimalistic implementation opens the door for extensibility when you need it, cohesive code structure for when you’re writing production code, and a far easier-to-troubleshoot code base that isn’t filled with technical debt (and dozens of TODO statements that will never get fixed).
13.2 Unintentional obfuscation: Could you read this if you didn’t write it?
A rather unique form of ML hubris materializes in the form of code development practices. Sometimes malicious, many times driven by ego (and a desire to be revered), but mostly due to inexperience and fear, this particular destructive activity takes shape through the creation of unintelligibly complex code.
For our scenario, let’s take a look at a common and somewhat simplistic task: recasting data types to support feature-engineering tasks. In this journey of comparative examples, we’ll take a dataset whose features (and the target field) need to have their types modified to support the pipeline-enabled processing stages to build a model. This problem, at its most simplistic implementation, is shown in the next listing.
Listing 13.3 Imperative casting
def simple(df: DataFrame): DataFrame = { ❶
df.withColumn("age", col("age").cast("double")) ❷
.withColumn("weight", col("weight").cast("double")) ❸
.withColumn("hungry", col("hungry").cast("string")) ❹
}❶ Encapsulates the modifications of the passed-in DataFrame by returning a DataFrame
❷ Converts the age column to Double from its original Integer type (for demonstration purposes only)
❸ Ensures that the weight column is of type Double
❹ Casts the target column from Boolean to String for the encoders to work
From this relatively simple and imperative-style implementation of casting fields in a DataFrame, we’ll look at examples of obfuscation and discuss the impacts that each might have for something as seemingly simple as this use case.
NOTE In the next section, we’ll look at bad habits that some ML engineers have when writing code. Listing 13.3, it must be mentioned, is not intended to be disparaging in its approach and implementation. There is nothing wrong with an imperative approach when building ML code bases (provided the code base doesn’t have tight coupling requiring dozens of edits if one column changes). It becomes a problem only when the complexity of the solution makes modifying imperative code a burden. If the project is simple enough, stick with simpler code. You’ll thank yourself for the simplicity when you need to modify it and add new features.
13.2.1 The flavors of obfuscation
This section progresses through a sliding scale of complexity, with code examples that become progressively less intelligible, more complex, and increasingly harder to maintain. We’ll analyze bad habits of some developers to aid you in identifying these coding patterns and to call them out for what they are—crippling to productivity and absolutely requiring refactoring to be maintainable.
If you find yourself going down one of these rabbit holes, these examples can serve as a reminder to not follow these patterns. But before we get to the examples, let’s look at the personas that I’ve seen with respect to development habits, shown in figure 13.3.
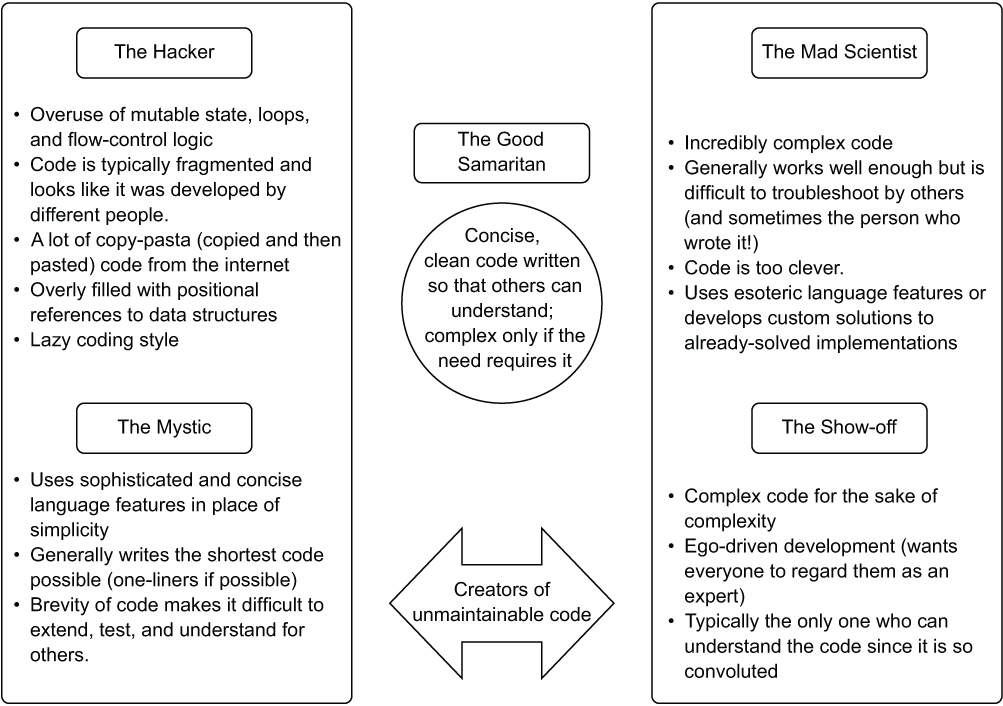
Figure 13.3 The different personas in ML code development. Moving away from the central region has a high probability of creating a lot of problems for the team in the future.
These personas are not meant to identify a particular person, but rather to describe traits that a DS may go through during their journey of becoming a better developer. A nearly overwhelming number of people I’ve met (as well as myself) started off writing code as the Hacker. We’d find ourselves stuck on a problem that we’d never encountered before and instantly move to search online for a solution, copy someone’s code, and if it worked, move on. (I’m not saying that looking on the internet or in books for information is a bad thing; even the most experienced developers do this quite frequently.)
As coding experience becomes deeper, some may lean toward one of the other three coding styles or, if they’re mentored properly, move directly to the center region. Some people have something to prove—usually only to themselves, as most people just want their peers to write the sort of code that comes from a Good Samaritan developer. Others may feel that the least number of lines of code is an effective development strategy, though they’re sacrificing legibility, extensibility, and testability in the process. Figure 13.4 shows the patterns that I’ve come across (and personally experienced).
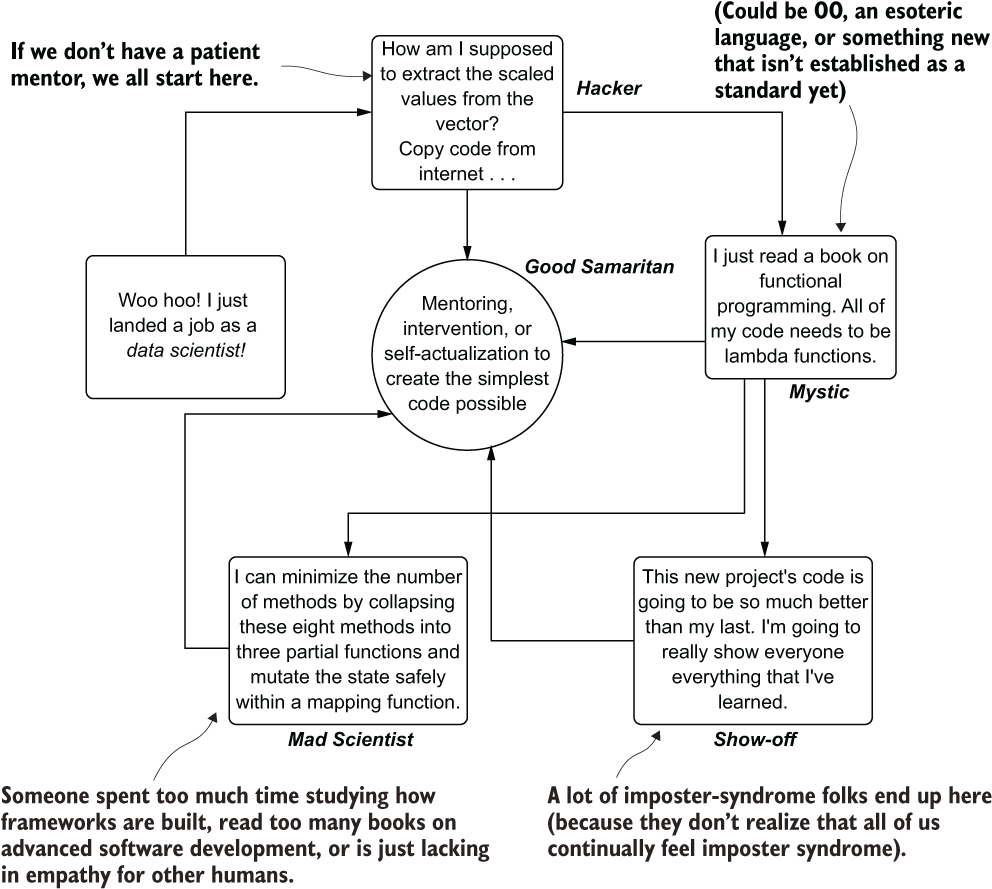
Figure 13.4 The paths of becoming a better developer
This circuitous path leads to increasingly complex and unnecessarily complicated implementations before landing on the pinnacle of wisdom-fueled experience. The best we can hope for while making this journey is to have the ability to recognize and learn the better path—specifically, that the simplest solution to a problem (that still meets the requirements of the task) is always the best way to solve it.
In the following sections, we’ll look at versions of listing 13.3, wherein we are trying to recast some columns in a Spark DataFrame in order to prepare for feature-engineering transformations. It’s a seemingly simple task, but by the end of this section, hopefully you’ll be able to see just how “clever” someone can be by creating different types of confusing (and potentially very broken) implementations.
A Hacker mentality is, for the most part, simply born from inexperience and a feeling of being completely overwhelmed with the concepts of software development (ML or not). Many people in this mode of development feel nervous about asking for help in building solutions or in understanding how other team members’ solutions are built. Crippling feelings of inadequacy, known as imposter syndrome, may limit this person’s growth potential if they are not provided effective mentoring and acceptance by the larger team.
Many of their projects or contributions to projects may feel completely disjointed and tonally dissonant. It may seem like different people were involved in crafting the code within the pull request that they submitted. It’s likely true that there were: anonymous contributors to Stack Overflow.
Figure 13.5 summarizes many of the thoughts I had when I started writing full project code many years ago. I’ve asked other junior DS folks, after particularly rough peer reviews of their code, what motivated them to copy code from Stack Overflow, and their thought processes are paraphrased here as well.
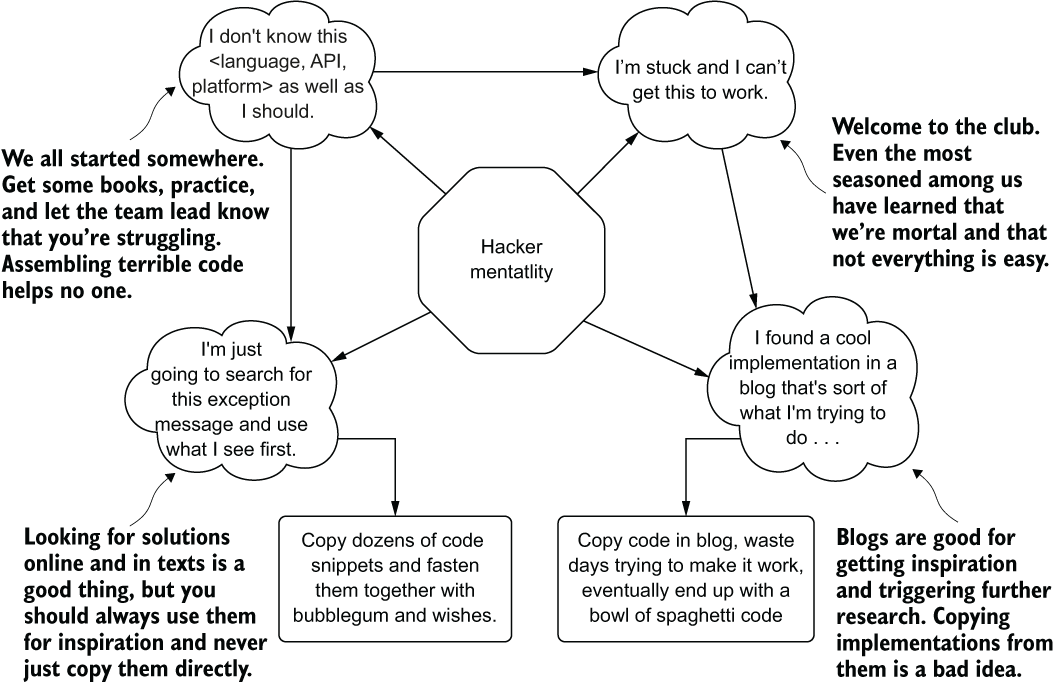
Figure 13.5 The Hacker thought pattern, creating chaotic and unstable code bases, is where we all start in ML.
A Hacker’s code looks like a patchwork quilt. The lack of coherent structure, inconsistent naming conventions, and varying degrees of code quality is likely to get flagged repeatedly in a code or peer review submission. A test of the code (if any unit tests are written) will likely show many points of fragility in the implementation.
Listing 13.4 shows an example of what the Hacker type of developer might come up with for a solution to the column-recasting problem. While not directly indicative of a cobbled-together state, it’s definitely full of antipatterns.
Listing 13.4 Hacker’s attempt at casting columns
def hacker(df: DataFrame,
castChanges: List[(String, String)]): DataFrame = { ❶
var mutated = df ❷
castChanges.foreach { x => ❸
mutated = mutated.withColumn(x._1,
mutated(x._1).cast(x._2)) ❹
}
mutated ❺
}
val hackerRecasting = hacker(dogData, List(("age", "double"),
("weight", "double"),
("hungry", "string"))) ❻❶ The function argument castChanges is strange. What does the list of tuples represent?
❷ Mutating objects is not considered a good practice in this instance. The DataFrame is immutable by nature, but declaring it as a var allows mutation to support this hacky method chaining in the foreach iterator.
❸ Iterates over the List of tuples that are passed in
❹ Positional notation for tuples is confusing, highly error prone, difficult to understand, and opens the door for frustration in API usage. (What happens if the data type and column names are switched?)
❺ Returning the mutated DataFrame will still preserve encapsulation, but it’s a code sniff.
❻ Example usage with the cumbersome definition of a List of tuples for the castChanges argument
In this code, we can see that the logic displayed is similar to the inherently mutable nature of Python. Instead of researching how to safely iterate over a collection to apply chained methods to an object, this developer implements a strong antipattern in Scala: mutating a shared state variable. In addition, because the function’s argument castChanges has no concept of what those String values should be (which one should be the column name and which the data type is being cast to), the user of this function would have to look at the source code to understand which one goes where.
Recognizing these code smells in your peers’ work is critical. Whether those people are brand-new to the team (or the profession), or have a great deal of experience and are simply “phoning it in,” an effort should be made to help them. This is a perfect opportunity to work with a fellow member of the team, help them increase their skills, and in the process, build a stronger team full of engineers who are all creating more maintainable and production-stable code.
As we progress in gaining skill and exposure to new concepts in ML software development, the next logical journey is to learn FP techniques. Unlike traditional software development, a great deal of DS coding work lends itself to functional composition. We ingest data structures (typically represented as array collections), perform operations on them, and return the modified state of the data in an encapsulated fashion. Many of our operations are based on applying algorithms to data, whether through direct calculation of values or through a transformation of structure. To a large degree, much of our code bases could be written in a stateless FP fashion.
At its core, many tasks in ML are functional. There is definitely a strong case to apply functional programming techniques to many of the operations that we do. The Mystic developer persona is not someone who selectively chooses appropriate places to use FP paradigms, however. Instead, they dedicate their time and effort to making the entire code base functional. They pass around configuration monads to functions in a semblance of weak state, sacrificing composition in favor of an almost fanatical zeal for the adherence of FP standards. To illustrate, figure 13.6 shows my thought processes when I discovered FP and all the wonders that it can bring to a code base.
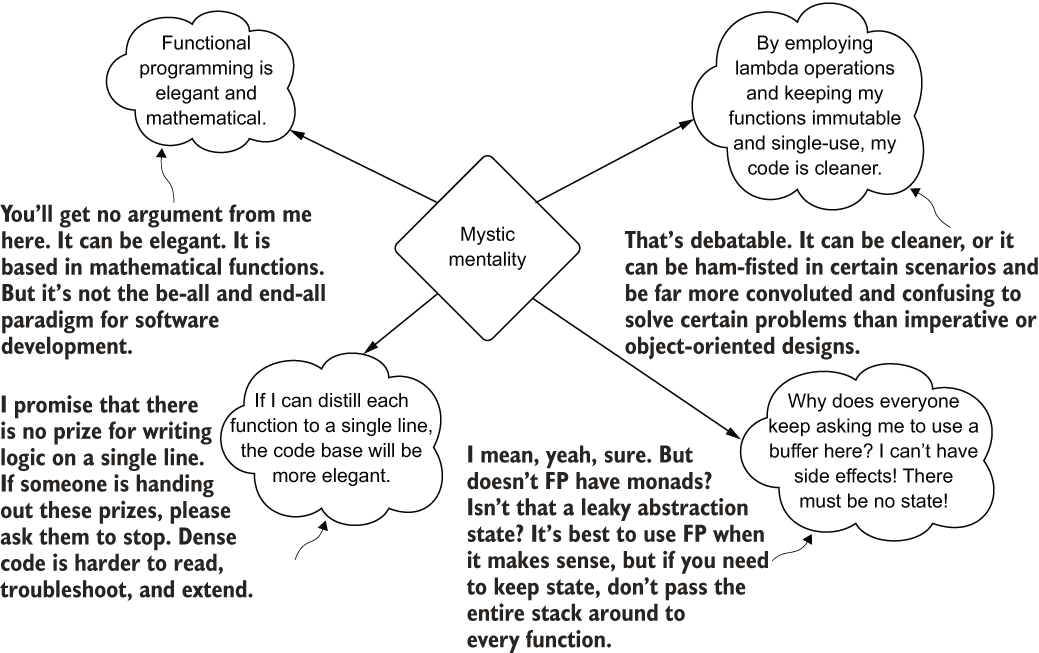
Figure 13.6 Inside the mind of an FP purist (the Mystic)
When I first began learning FP concepts, trying my hardest to convert all of my code into this standard, I found its conciseness liberating, efficient, and elegant. I enjoyed the simplicity of stateless coding and the purity of pure encapsulation. Gone were the side-effect problems of mutating state in my earlier hacky code, replaced with slick and stylistic map, flatmap, reduce, scan, and fold. I absolutely loved the idea of containerizing and defining generic types as a way to reduce the lines of code I had to write, maintain, and debug. Everything just seemed so much more elegant.
In the process of refactoring code in this way, I managed to enrage the other people who were looking at each heavy-handed refactoring. They were right to call me out for increasing the complexity of the code base, decoupling functions in ways that didn’t need decoupling, and generally making the code harder to read. To get a good sense of what this implementation style would look like for our column casting, see the following listing.
Listing 13.5 A pure functional programming approach
def mystic(df: DataFrame,
castChanges: List[(String, DataType)]
): DataFrame = { ❶
castChanges.foldLeft(df) { ❷
case (data, (c, t)) =>
data.withColumn(c, df(c).cast(t)) ❸
}
}
val mysticRecasting = mystic(dogData,
List(("age", DoubleType),
("weight", DoubleType),
("hungry", StringType))) ❹❶ The function signature’s castChanges argument is safer than the Hacker’s implementation. By requiring a DataType abstract class to be passed in, the chances of introducing unintentional bugs via this function are reduced.
❷ Using a foldLeft (mapping over the castChanges collection and applying an accumulator to the passed-in DataFrame df) allows for the mutated state of the DataFrame to be far more efficient than in the Hacker approach.
❸ Case matching to define the structure of the passed-in argument castChanges allows for elimination of the complicated (and annoying) positional reference that was in the Hacker implementation. This code is far cleaner.
❹ Using the function doesn’t save much on typing versus the Hacker implementation, but you can see how having these defined types for the casting conversion type makes the use of this function better.
As you can see, this implementation has a distinct functional nature. Technically speaking, for this use case, this implementation is the best of all the examples in this section. The DataFrame object is mutated in a safe accumulator-friendly way (the mutation state of chaining operations on the DataFrame is encapsulated within foldLeft), the argument signature utilizes base types as part of the casting (minimizing errors at usage time), and the matching signature used prevents any confusing variable-naming conventions.
The only way that I would make this a bit better would be to utilize a monad for the castChanges argument. Defining a case class constructor that could hold the mappings of column name to casting type would further prevent misuse or any confusing implementation details for others who wished to use this little utility function.
The issue in listing 13.5 isn’t the code; rather, it is in the philosophical approach of someone who writes code in this manner and enforces these patterns everywhere in the code base. If you detect these sorts of development patterns everywhere in a code base, replete with highly convoluted and confusing state currying that ships the entire stack around to each function, you should have a chat with this person. Show them the light. Let them know that this pursuit of “purity” is as much a fool’s errand as tilting at windmills. They’re not the only one who has to maintain this, after all.
The Show-off persona can come in several forms. It can be an incredibly advanced independent contributor who has a lengthy history of developing software with no ML components. They may look at an ML project and try to build a custom implementation of an algorithm that otherwise exists in a popular open source library. They could also be a person who has graduated from being a Hacker type of developer, and armed with a deeper understanding of the implementation language and software design patterns, chooses to show everyone on the team how good they are now.
Regardless of why this sort of person builds complexity into their implementations, it will impact the team and the projects that the team must maintain in the same manner. The person who built it will end up owning it if the code isn’t refactored.
There’s absolutely nothing wrong with complexity in code if the use case and the problem being solved warrant that complexity. However, the Show-off type builds in complexity simply for the sake of overengineering the solution to appear skilled to others on the team. I imagine the mental state of people who fit the Show-off persona to look like figure 13.7.
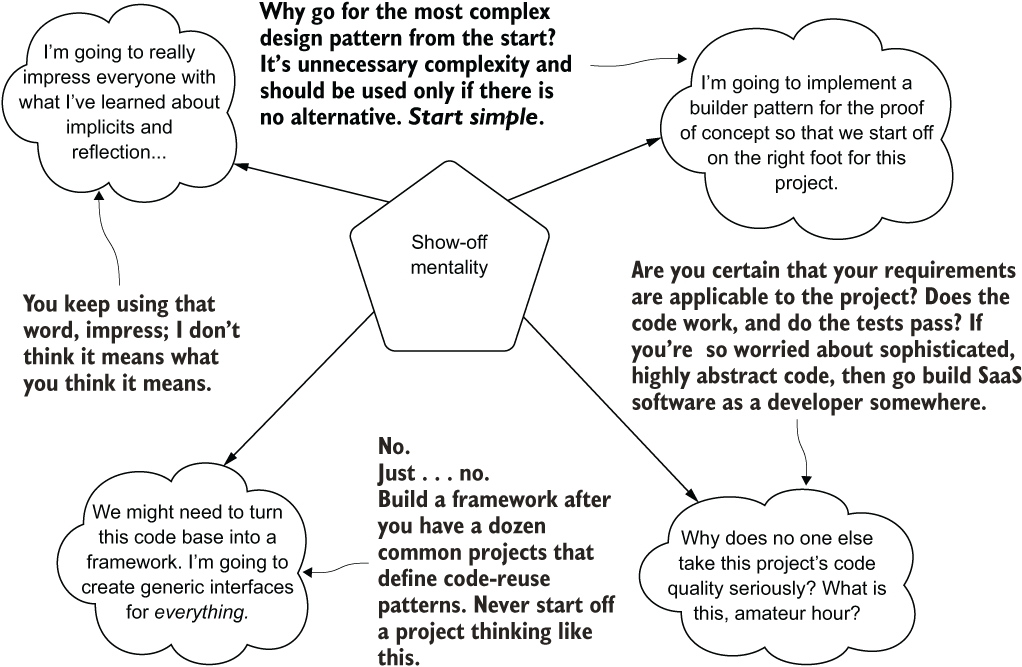
Figure 13.7 The unhelpful habits and thoughts of the Show-off
These habits and thinking patterns are significantly less than pleasant to endure when you’re this person’s coworker. The ideas that they’re conveying aren’t bad (except for the toxic one at the bottom right). Builder patterns, heavy abstraction, implicit typing, reflection, and well-crafted interfaces are all good things. However, they’re tools to be used when the need arises.
The problem with the way this person thinks and writes code is that they’ll start off implementing a project from the initial commit on the first branch with skeleton stubs for a grand project architecture that is completely unneeded. This is the sort of ML engineer who is focused solely on the code sophistication of the project and has little to no regard for the actual project’s purpose. In this blindness, they typically strive toward writing very complex code that, to the rest of the team, seems intentionally obfuscated because of the overwhelming level of overengineering that they’ve done for the problem at hand.
TIP If you want everyone to think you’re smart, sign up for Jeopardy and win some rounds. If you’re flexing through your code, all you’re doing is putting your team in jeopardy.
Let’s take a look at our casting scenario function, this time written in the Show-off development style.
Listing 13.6 The Show-off’s casting implementation
val numTypes =
List(IntegerType, FloatType, DoubleType, LongType, DecimalType, ShortType)❶
def showOff(df: DataFrame): DataFrame = {
df.schema
.map(
s =>
s.dataType match { ❷
case x if numTypes.contains(x) => s.name -> "n" ❸
case _ => s.name -> "s" ❹
}
)
.foldLeft(df) {
case (df, x) => ❺
df.withColumn(x._1, df(x._1).cast(x._2 match {
case "n" => "double"
case _ => "string" ❻
}))
}
}
val showOffRecasting = showOff(dogData) ❼❶ Defining the matching numeric types is fine for this particular implementation. What happens if integers need to be handled differently? The refactoring required to stick with this design pattern would be substantial!
❷ The matching approach isn’t bad on the data type of the passed-in DataFrame. That’s the only good thing to say about this block of code.
❸ The mapping of the column name to the conversion type is odd. It’s consumed in the next statement.
❹ Wildcard catch for all other conditions. What happens if the passed-in DataFrame contains a collection?
❺ Lazy passing of the map collection (x) from the first stage. Now position notation is required to access those values.
❻ Once again, the wildcard match. An ArrayType or ListType column would present serious issues here.
❼ At least the instantiation of this function is pretty simple.
This code works. It behaves exactly as the three preceding examples did. It’s just hard to read. By trying to show off skills and “advanced” language features, some pretty poor decisions were made.
First off, the initial mapping over the schema fields is completely unnecessary. Creating the Map type column that consists of a pseudo-enumeration of single character values to column name is not only useless, but also confusing. The collection generated from that first stage, which is then folded over in the accumulator action to the DataFrame, is instantly consumed, forcing the creation of a “temporary” Map object collection to apply the correct type casting. Finally, in the laziness of not wanting to fully write out all of the conditional matches that may occur, there’s a wildcard match case in the final section. What happens when someone needs to handle a different data type? What are the steps for updating this to support binary types, integers, or Boolean values? Extending this is not going to be particularly fun.
Be wary of people who write code like this, particularly if they’re a senior person on your team. A conversation about how important it is for everyone on the team to be able to maintain the code and troubleshoot it is a good approach. It’s not likely that they’re intentionally trying to make the code complex for others. With a request for a simpler implementation, they’ll likely deliver and adjust their development strategy with this in mind for the future.
The Mad Scientist developer is well-intentioned. They’re also someone who has progressed on the path of knowledge of software development to a point far exceeding the fundamentals. With the amount of experience, number of projects, and sheer volume of code that they’ve written, they’ve begun to utilize advanced techniques within the languages (they typically are highly fluent in more than one) to reduce the amount of code that needs to be maintained.
These people typically think of how to tackle problems based on efficiency of development rather than from a position of wanting to be recognized for the sophistication of their code. They’ve learned a great deal over the years and have had to maintain (and refactor) less-than-optimal code enough that they choose to compose their implementations in ways that make it easier to troubleshoot and maintain.
These are noble goals when the rest of the team is of a similar level of technological competency as they are. However, most teams comprise a myriad of humans of differing levels of development competency. Crafting complex but highly efficient code can be a hindrance to the effectiveness of more junior people on the team. To illustrate these thought processes, figure 13.8 shows a bit of the Mad Scientist’s mind.
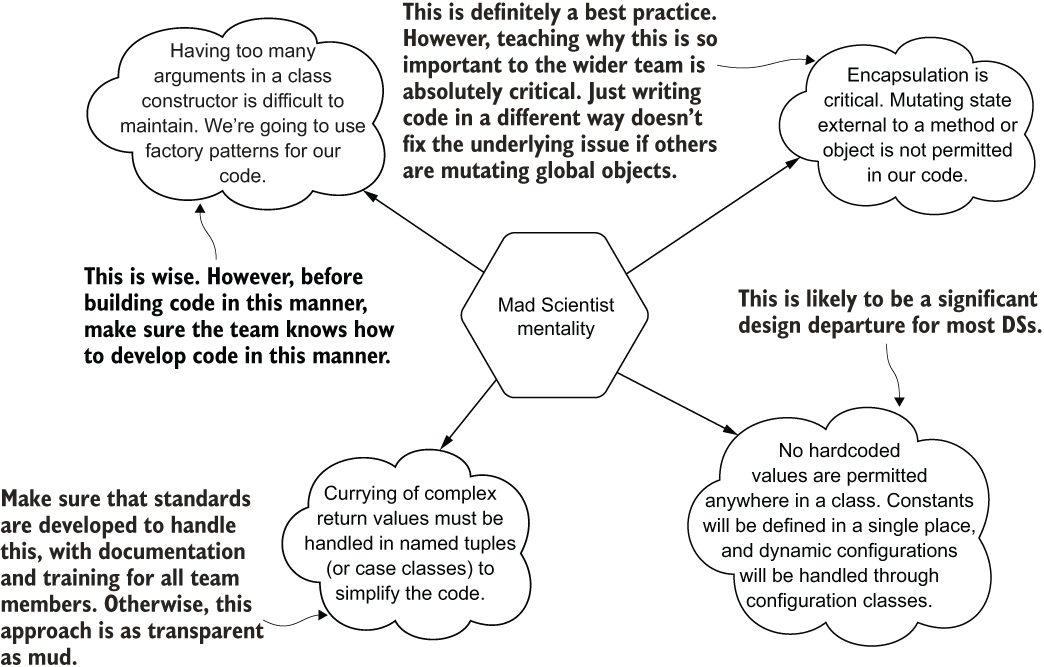
Figure 13.8 Without appropriate teaching and mentorship to the rest of the team, a more senior, highly advanced ML engineer may write code that’s highly obscure and complicated.
Notice that the Mad Scientist’s points are not bad ones. They’re perfectly relevant and considered to be general best practices. However, the problem with this mentality arises when all the other humans working with the code aren’t aware of these standards.
If code is written with these compositional rules in mind and just “thrown over the wall” by issuing a PR on a branch without the rest of the team being aware of why these standards are so important, the code design and implementation will be unintelligible to them. Let’s look at our continuation of casting examples for how this Mad Scientist developer would potentially write this code in listing 13.7.
Listing 13.7 A slightly more sophisticated casting implementation
val numTypes = List(FloatType, DoubleType, LongType, DecimalType, ShortType)
def madScientist(df: DataFrame): DataFrame = {
df.schema.foldLeft(df) { ❶
case (accum, s) => ❷
accum.withColumn(s.name, accum(s.name).cast(s.dataType match { ❸
case x: IntegerType => x
case x if numTypes.contains(x) => DoubleType
case ArrayType(_,_) | MapType(_,_,_) => s.dataType
case _ => StringType
})) ❹
}
}❶ Similar to the preceding examples, except we’re iterating directly on the collection returned from the df.schema getter
❷ Moves away from the confusing name reference df as in previous examples. Although it would be encapsulated here (and safe), naming it df is confusing to read.
❸ Uses named entities from the return of the schema (variable s) to prevent unexpected bugs in the future
❹ By wrapping the decision logic within the casting statement, there are fewer lines of code. Matching directly to types from the metadata of the schema is going to be more future-proof as well.
Now, there’s nothing wrong with this code. It’s concise, covers the use case needed rather well, and is designed to not spontaneously detonate if complex types (arrays and maps) are in a column in the dataset. The only caveat here is to ensure that design patterns like this are maintainable by your team. If they’re OK with maintaining and writing code in this manner, it’s a good solution. However, if the rest of the team is used to imperative-style programming, this code design can be as cryptic as if it were written in a different language.
If the team is facing overwhelming mountains of imperative calls, it would be best to introduce the team to coding styles exemplified in listing 13.7. Taking the time to teach and mentor the rest of the team on more efficient development practices can accelerate project work and reduce the amount of maintenance involved in supporting projects. However, it is absolutely critical for more senior people to educate other team members as to why these standards are important. This does not mean throwing out a link to a language specification (someone linking the PEP-8 standard of Python to a PR is a pet peeve of mine), nor just firing off branches containing dense and efficient code at the team. Rather, it means crafting well-documented code, providing examples in the internal team documentation store, conducting training sessions, and sitting through pair programming with the less experienced members of the team.
If you happen to be one of these Mad Scientist types, writing elegant and well-constructed code that is misunderstood and opaque to the rest of your team members, the first thing that you should be thinking about is teaching. It is far more effective to help everyone understand why these paradigms of development are good than to write scathing PR review notes and reject merge requests. After all, if you’re writing good code and submitting it to a team that doesn’t have experience in the paradigms that you’re utilizing, it’s just as obfuscated as the mess of the Show-off code in listing 13.6.
Let’s look at a safer, more legible, and slightly more standard method of solving this problem. Here’s what a more maintainable implementation would look like.
Listing 13.8 A safer bet on invalid types casting
object SimpleReCasting { ❶
private val STRING_CONVERSIONS = List(
BooleanType, CharType, ByteType) ❷
private val NUMERIC_CONVERSIONS = List(
FloatType, DecimalType) ❸
def castInvalidTypes(df: DataFrame): DataFrame = {
val schema: StructType = df.schema ❹
schema.foldLeft(df) {
case (outputDataFrame, columnReference) => {
outputDataFrame.withColumn(columnReference.name,
outputDataFrame(columnReference.name)
.cast(columnReference.dataType match {
case x if STRING_CONVERSIONS.contains(x) =>
StringType ❺
case x if NUMERIC_CONVERSIONS.contains(x) =>
DoubleType ❻
case _ => columnReference.dataType ❼
}))
}}}}❶ Uses an object for encapsulation and more efficient garbage collection by the JVM
❷ Explicitly declares the data types that we want to convert to StringType
❸ Explicitly declares the data types that we want to convert to DoubleType
❹ Breaks out the schema reference purely to reduce the code complexity and make it more approachable to others reading it
❺ Converts the types that we declared to StringType if they’re in our configuration listing
❻ Converts only the numeric types that match our listing to DoubleType
❼ Don’t touch anything else. Just leave it be.
Notice the wrapping of the code in an object? This is to isolate references to those Lists that are defined. We don’t want variables like that defined globally in a code base, so encapsulating them in an object serves that purpose.
In addition, the encapsulation makes it far easier for the garbage collector to remove references to objects that are no longer needed. SimpleRecasting, once used and no longer referred to within the code, will be removed from the heap along with all other encapsulated objects within it. The seemingly more verbose naming convention (which helps a new reader follow along with what is being acted upon within the foldLeft operation), enables this code to be read more clearly than the briefer code of listing 13.7.
A final note regarding this code is that the operations are entirely explicit. This is the largest hallmark of the difference in this code as compared to all previous examples, except for the original reference in listing 13.3 of the imperative casting. Here, as in that earlier example, we’re changing only the typing of column types that we’re explicitly commanding the system to change. We’re not defaulting behavior to “just cast everything else as String” or anything else that would create fragile, unpredictable behavior.
This approach to thinking about coding will save you a lot of frustrating hours, days, and months of your life troubleshooting seemingly innocuous code that blows up in production. We’ll revisit some of the ways that defaulting unknown state to a static value (or imputed values) can come back to bite us as ML engineers in the next chapter. For now, just realize that being explicit about actions is definitely a good design pattern for ML.
13.2.2 Troublesome coding habits recap
In the preceding section, we focused on several, shall we say, unfriendly ways to write code. Each is bad in its own way and for a myriad of reasons, but the worst offending reasons are in table 13.2.
The most important aspect of writing code to keep in mind is that the code that you create is not purely for the benefit of the system executing it. If that were the case, the profession would likely never have moved away from low-level code frameworks for writing instructions (second-generation languages such as assembly languages or, for the truly masochistic, first-generation machine code).
Table 13.2 Developer implementation sins
Languages have advanced through higher-order generations not for the sake of computational efficiency for the processor and memory of the computers; rather, it has been for the sake of the humans writing, and more important, reading the code to figure out what it does. We write code, using high-level APIs when we can, and construct our code in ways to make it easy to read and maintain, solely for the benefit of our peers and future selves.
Avoid the habits listed in table 13.2 and move toward writing the code needed by you, your team, and the sort of technical talent that you’re targeting to hire in the future for roles in your group. Doing so will help make everyone productive and able to contribute to building and maintaining solutions, and will prevent inefficient refactoring of horribly complex code bases to fix crushing technical debt wrought by unthinking developers.
13.3 Premature generalization, premature optimization, and other bad ways to show how smart you are
Let’s suppose that we’re starting a new project with a team of relatively advanced (from a software development perspective) ML engineers. At the start of the project, the architect decides that the best way to control the state of the code is to design and implement a framework for executing the modeling and inference tasks. The team is incredibly excited! Finally, the team members think, some interesting work!
In their collective giddiness, none of them realize that, aside from illegible code, one of the worst forms of hubris is that of spending time where time does not need to be spent. They’re about to build useless framework code bases that serve no real purpose apart from being a justification for their own existence.
13.3.1 Generalization and frameworks: Avoid them until you can’t
The first thing that the team does is work on a product requirements document (PRD) that outlines what they want their unique framework to do. A general design, based on a builder pattern, is drafted. The architect wants the team to do the following:
- Ensure that custom default values are utilized throughout the project code (not relying on API defaults)
- Enforce overriding of certain elements of the modeling process with respect to tuning hyperparameters
- Wrap the open source APIs with naming conventions and structural elements that are more in line with the code standards at the company
Before experimentation is done, a plan of features is developed, as shown in figure 13.9.
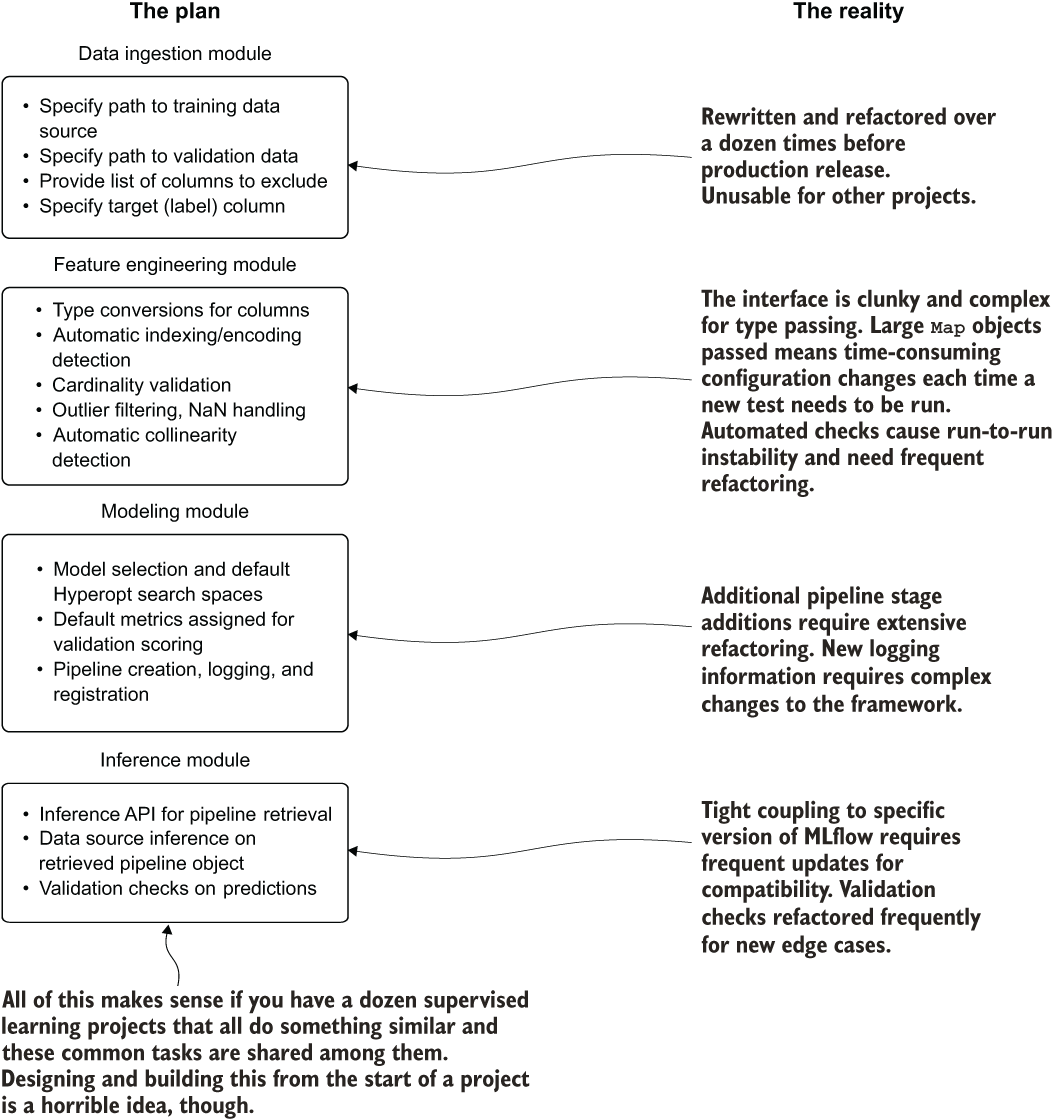
Figure 13.9 The hopes and dreams of an architect trying to build a cohesive wrapper around disparate frameworks to support all ML needs of the company. Spoiler alert: it doesn’t end well.
This plan for critical features is more than a little ambitious. Were this to proceed, the Reality aspects shown at the right side of the figure would likely play out (they’ve always happened whenever I’ve seen someone attempt to do this). Full of rework, refactoring, and redesign, this project would be doomed.
Instead of focusing on solving the problem by using existing frameworks (such as Spark, pandas, scikit-learn, NumPy, and R), the team would be supporting not only a project solution, but a custom implementation of a framework wrapper—and all of the pain that goes along with that. If you’re not staffed with dozens of software engineers to support a framework, it’s best to think carefully about planning to construct one.
Adding to the immense workload of building and maintaining such a software stack is the simple fact that you’d be attempting to support a wrapper that is more generic than the framework that it is wrapping. Engaging in work like this never ends well for two primary reasons:
- You now own a framework—This means updates, compatibility guarantees, and a truly massive amount of testing to write (you are writing tests, right?). Functionality assurances are now in lockstep with the packages that you’re using to build the framework.
- You now own a framework—Unless you’re planning on making it truly generic, open sourcing it and having a community of committers involved in its growth, and committing to maintaining it, it’s pointless work to engage in.
Pursuing generalized approaches truly makes sense only if a direct need for that exists. Does a critical new functionality need to be developed to make another framework for ML work more efficiently? Perhaps think about contributing to that open source framework, then. Is there a need to stitch together disparate low-level APIs to solve a common problem? This is likely a good case for the creation of a framework.
The last thing that you should be thinking about when starting a project, unlike our architect friend, is setting about building a custom framework to support that particular project. The premature generalization work involved (in time, distraction, and frustration) will detract heavily from the project’s pending work, will delay and disrupt productive work that should be focused on solving the problem, and will inevitably need to be reworked many times over throughout the evolution of the project. It’s simply not worth it.
13.3.2 Optimizing too early
Let’s suppose we work for a different company—one without that architect from the previous section, preferably. This company, instead of an empire-building architect, has an advisor to the DS team who comes from a backend engineering background. Throughout this person’s career, they’ve focused on SLAs that can be measured in milliseconds, algorithms that traverse collections in the most efficient way possible, and vast amounts of time eking out every available CPU cycle. Their world is entirely focused on the performance of discreet portions of code.
On the first project, the advisor wants to contribute to the DS team’s work by helping to build out a load tester. Since the team is yet again dealing with determining whether dogs are hungry when entering the local pet supply store, the advisor guides the team on implementing a solution.
Based on their experience and knowledge of Scala for backend systems, the team members end up focusing on something that is highly optimized for minimizing the memory pressure on the JVM. They want to eschew mutable buffer collections in favor of explicit collection building (using only the minimum amount of memory needed) with a fixed predetermined size of the collection. Because of prior experience, they spend a few days building the code in order to generate the data needed to test the throughput of the modeling solution for inference purposes.
To start, the advisor works on defining the data structure that is going to be used for testing. Listing 13.9 shows both the data structure and the defining static parameters to generate the data with.
NOTE The Scala formatting in listing 13.9 is condensed for printing purposes and is not representative of proper Scala syntax design.
Listing 13.9 Configuration and common structures for data generator
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types._
import org.apache.spark.sql.{DataFrame, SparkSession}
import scala.collection.mutable.ArrayBuffer
import scala.reflect.ClassTag
import scala.util.Random
case class Dogs(age: Int, weight: Double, favorite_food: String,
breed: String, good_boy_or_girl: String, hungry: Boolean) ❶
case object CoreData { ❷
def dogBreeds: Seq[String] = Seq("Husky", "GermanShepherd", "Dalmation", "Pug", "Malamute", "Akita", "BelgianMalinois", "Chinook", "Estrela", "Doberman", "Mastiff")
def foods: Seq[String] = Seq("Kibble", "Spaghetti", "Labneh", "Steak",
"Hummus", "Fajitas", "BœufBourgignon", "Bolognese")
def goodness: Seq[String] = Seq("yes", "no", "sometimes", "yesWhenFoodAvailable")
def hungry: Seq[Boolean] = Seq(true, false)
def ageSigma = 3
def ageMean = 2
def weightSigma = 12
def weightMean = 60
}
trait DogUtility { ❸
lazy val spark: SparkSession = SparkSession.builder().getOrCreate() ❹
def getDoggoData[T: ClassTag](a: Seq[T], dogs: Int, seed: Long): Seq[T] = {
val rnd = new Random(seed)
Seq.fill(dogs)(a(rnd.nextInt(a.size)))
} ❺
def getDistributedIntData(sigma: Double, mean: Double, dogs: Int,
seed: Long): Seq[Int] = {
val rnd = new Random(seed)
(0 until dogs).map(
_ => math.ceil(math.abs(rnd.nextGaussian() * sigma + mean)).toInt)
} ❻
def getDistributedDoubleData(sigma: Double, mean: Double, dogs: Int,
seed: Long): Seq[Double] = {
val rnd = new Random(seed)
(0 until dogs).map( _ => math.round(math.abs(rnd.nextGaussian() * sigma * 100 + mean)).toDouble / 100)
} ❼
}❶ Defines the dataset schema (with typing) for testing
❷ Uses a case object to store static values for data generation (a pseudo-enumeration in Scala)
❸ Uses a trait for multiple inheritance to test different implementations and to keep the code cleaner
❹ We’ll use a Spark session reference in the objects later, so having it available in the trait makes sense.
❺ Uses a generic type to randomly fill in values (Strings or Booleans) into a fixed-size sequence
❻ Generates a random Gaussian distribution of Integer values based on the passed-in mean and sigma values
❼ Generates a random Gaussian distribution of Double values based on the mean and sigma
Now that the helper code has been developed to control the behavior and nature of the simulation data, the advisor tests the performance of the methods defined in the trait DogUtility. The performance scales well to hundreds of millions of elements after a few hours of tweaking and refactoring.
It should go without saying that this implementation is a bit of an overkill for the problem at hand. Since this is at the start of the project, not only are the features required for the end-result condition of the model not fully defined, but the statistical distribution of the features hasn’t been analyzed yet. The advisor decides that it’s now time to build the actual control execution code for generating the data as a Spark DataFrame, as shown in the next listing.
Listing 13.10 An overly complex and incorrectly optimized data generator
object PrematureOptimization extends DogUtility { ❶
import spark.implicits._ ❷
case class DogInfo(columnName: String,
stringData: Option[Either[Seq[String],
Seq[Boolean]]], ❸
sigmaData: Option[Double], ❹
meanData: Option[Double],
valueType: String) ❺
def dogDataConstruct: Seq[DogInfo] = { ❻
Seq(DogInfo("age", None, Some(CoreData.ageSigma),
Some(CoreData.ageMean), "Int"),
DogInfo("weight", None, Some(CoreData.weightSigma),
Some(CoreData.weightMean), "Double"),
DogInfo("food", Some(Left(CoreData.foods)), None, None, "String"),
DogInfo("breed", Some(Left(CoreData.dogBreeds)),
None, None, "String"),
DogInfo("good", Some(Left(CoreData.goodness)),
None, None, "String"),
DogInfo("hungry", Some(Right(CoreData.hungry)),
None, None, "Boolean"))
}
def generateOptimizedData(rows: Int,
seed: Long): DataFrame = { ❼
val data = dogDataConstruct.map( x => x.columnName -> {
x.valueType match {
case "Int" => getDistributedIntData(x.sigmaData.get,
x.meanData.get, rows, seed)
case "Double" => getDistributedDoubleData(x.sigmaData.get,
x.meanData.get, rows, seed)
case "String" => getDoggoData(x.stringData.get.left.get,
rows, seed) ❽
case _ => getDoggoData(
x.stringData.get.right.get,
rows,
seed)
}
} ❾
).toMap ❿
val collection = (0 until rows).toArray ⓫
.map(x => {
Dogs(
data("age")(x).asInstanceOf[Int],
data("weight")(x).asInstanceOf[Double],
data("food")(x).asInstanceOf[String],
data("breed")(x).asInstanceOf[String],
data("good")(x).asInstanceOf[String],
data("hungry")(x).asInstanceOf[Boolean]
)
})
.toSeq
collection.toDF() ⓬
}
}❶ Uses the trait DogUtility defined earlier to have access to the methods and SparkContext defined there
❷ Uses implicits from Spark to be able to cast a collection of case class objects directly through serialization to a DataFrame object (cuts down on a lot of nasty code)
❸ This is a mess. The Either type allows for a right-justified selection between two types and is challenging to extend properly. A generic type would have been better here.
❹ The Option type is here because these values are not needed for some of the configured method calls for the data generators (one doesn’t need to define a sigma for a collection of Strings to be randomly sampled from).
❺ The value type allows for optimized implementations of the generator below (for number of lines, not for ease of comprehension to the reader).
❻ Builds the control payload for defining how the data generators will be called (and in which order)
❼ An overly fancy and optimized (for code length) implementation for calling the data generators based on the configuration specified in the method dogDataConstruct (this implementation is fragile)
❽ OK, so this is horrible for accessing a value. Two .get operations? You’ve got to be kidding me.
❾ The root cause of the performance issues noticed below. This defaults to a Seq type but should be an IndexedSeq type to allow for O(1) access to individual values, instead of the current O(n).
❿ Wraps each collection of data in a Map object to make accessing the values by name easier than doing positional notation
⓫ Major problem #2 with this code—mapping over the index positions of each collection to build rows. This is O(kn) in complexity.
⓬ Converts to a Spark DataFrame
After doing some testing on this code, the team members come to realize fairly quickly that the relationship between generated row size and runtime is far from linear. In fact, it’s much worse than linear, being more akin to O(n× log(n)) in computational complexity. Generating 5,000 rows takes about 0.6 seconds, while a heavy load testing of 500,000 rows takes around 1 minute and 20 seconds. With the full load test of 50 million rows, the idea of waiting around for 2 hours and 54 minutes is a bit much.
What went wrong? They spent all of their time optimizing individual parts of the code so that, in isolation, each executed as quickly as possible. When the entire code was executed, it was a dismal mess. The implementation is just too clever in all of the wrong ways.
Why is it so slow, though? It’s the last part that is so crippling. Although the memory pressure is minimal for this implementation, the row count generation within the defined variable collection has to perform a non-indexed position lookup for each Sequence in the Map collection. At each iteration to build the Dogs() objects, the Sequence needs to be traversed to that point in order to retrieve the value.
Now, this example is a bit hyperbolic. After all, if this backend developer was really adept at their optimizations, they likely would have utilized an indexed collection and cast the data object from a Sequence to an IndexedSeq (which would be able to drive directly to the position being requested and return the correct value in a fraction of the time). This implementation, even with that change, is still sniffing about in the wrong place.
The performance is terrible, but that’s only part of the story. What happens to the code in listing 13.10 if another data type needs to be added to be handled in the same manner as the String data? Is the developer going to wrap another Either[] statement around the first one? Is that then going to be wrapped in another Option[] type? How much of an unholy mess is this code going to become if a Spark Vector type needs to be generated? Because it was built in this manner, optimized excessively to an early state of a pre-MVP version of the solution, this code is either going to need to be modified heavily throughout the project to keep it synchronized with the DS team’s feature-engineering work or will need to be rewritten completely from scratch when it becomes cumbersome and unmaintainable. The likeliest path for this code is that it is destined for the infinite well of trash that is an rm-rf command.
The following listing shows a slightly different implementation that utilizes a far simpler approach. This code is focused on reducing the runtime by an order of magnitude.
Listing 13.11 A far more performant data generator
object ConfusingButOptimizedDogData extends DogUtility { ❶
import spark.implicits._
private def generateCollections(rows: Int,
seed: Long): ArrayBuffer[Seq[Any]] = {
var collections = new ArrayBuffer[Seq[Any]]() ❷
collections += getDistributedIntData(CoreData.ageSigma,
CoreData.ageMean, rows, seed) ❸
collections += getDistributedDoubleData(CoreData.weightSigma,
CoreData.weightMean, rows, seed)
Seq(CoreData.foods, CoreData.dogBreeds, CoreData.goodness,
CoreData.hungry)
.foreach(x => { collections += getDoggoData(
x, rows, seed)}) ❹
collections
}
def buildDogDF(rows: Int, seed: Long): DataFrame = {
val data = generateCollections(rows, seed) ❺
data.flatMap(_.zipWithIndex) ❻
.groupBy(_._2).values.map( x => ❼
Dogs(
x(0)._1.asInstanceOf[Int],
x(1)._1.asInstanceOf[Double],
x(2)._1.asInstanceOf[String],
x(3)._1.asInstanceOf[String],
x(4)._1.asInstanceOf[String],
x(5)._1.asInstanceOf[Boolean])).toSeq.toDF()
.withColumn("hungry", when(col("hungry"),
"true").otherwise("false")) ❽
.withColumn("hungry", when(col("breed") === "Husky",
"true").otherwise(col("hungry"))) ❾
.withColumn("good_boy_or_girl", when(col("breed") === "Husky",
"yesWhenFoodAvailable").otherwise(
col("good_boy_or_girl"))) ❿
}
}❶ Identical to the implementation in listing 13.10
❷ To eliminate one stage of the iteration over the collection, we can just append each generated sequence of values (the eventual row data) to a Buffer.
❸ Adds the first column’s data (the integers generated randomly for age) to the Buffer
❹ Iterates through a collection of all the String and Boolean columns’ data and passes their configured allowable values to the generator one by one
❺ Calls the private method defined above to get the ArrayBuffer of randomly sampled data for testing
❻ Iterates over each row collection and generates the Dogs case class structure directly through position notation
❼ Collapses the data to tuples that contain the row values together in the correct generated order
❽ Might as well cast the Boolean field to a String type to save a processing step later
❾ If you’ve ever known a husky, you’ll know that they’re always hungry.
❿ A husky will do anything for food. It will do nothing for an absence of food.
How did the code perform, once refactored? Well, it scales linearly now. The 5,000 rows of data took less than a second; 50,000 rows took 1 second; and 5 million rows returned in just under 1 minute and 35 seconds. The 50 million target that was tested from the previous implementation, however, returns that row count in approximately 15 minutes. That’s quite a bit better than the more than 174 minutes from the earlier implementation.
While this scenario is focused on a load-testing data generator and is esoteric for most DS practitioners, much can be said for other aspects of more ML-centric tasks. What would happen if someone were to focus on optimizing for performance one of the least important (computationally, that is) aspects of an ML pipeline? What if someone focused all of their energy on a project into, as we were looking at in the first section of this chapter, the performance of casting columns to specific types?
Figure 13.10 shows a general breakdown of most ML workflows for a training cycle. Note the Fermi-level estimations for each listed execution action for a generic ML project. Where would you spend your effort if you were trying to optimize this job? Where should you look first for problems and address them?
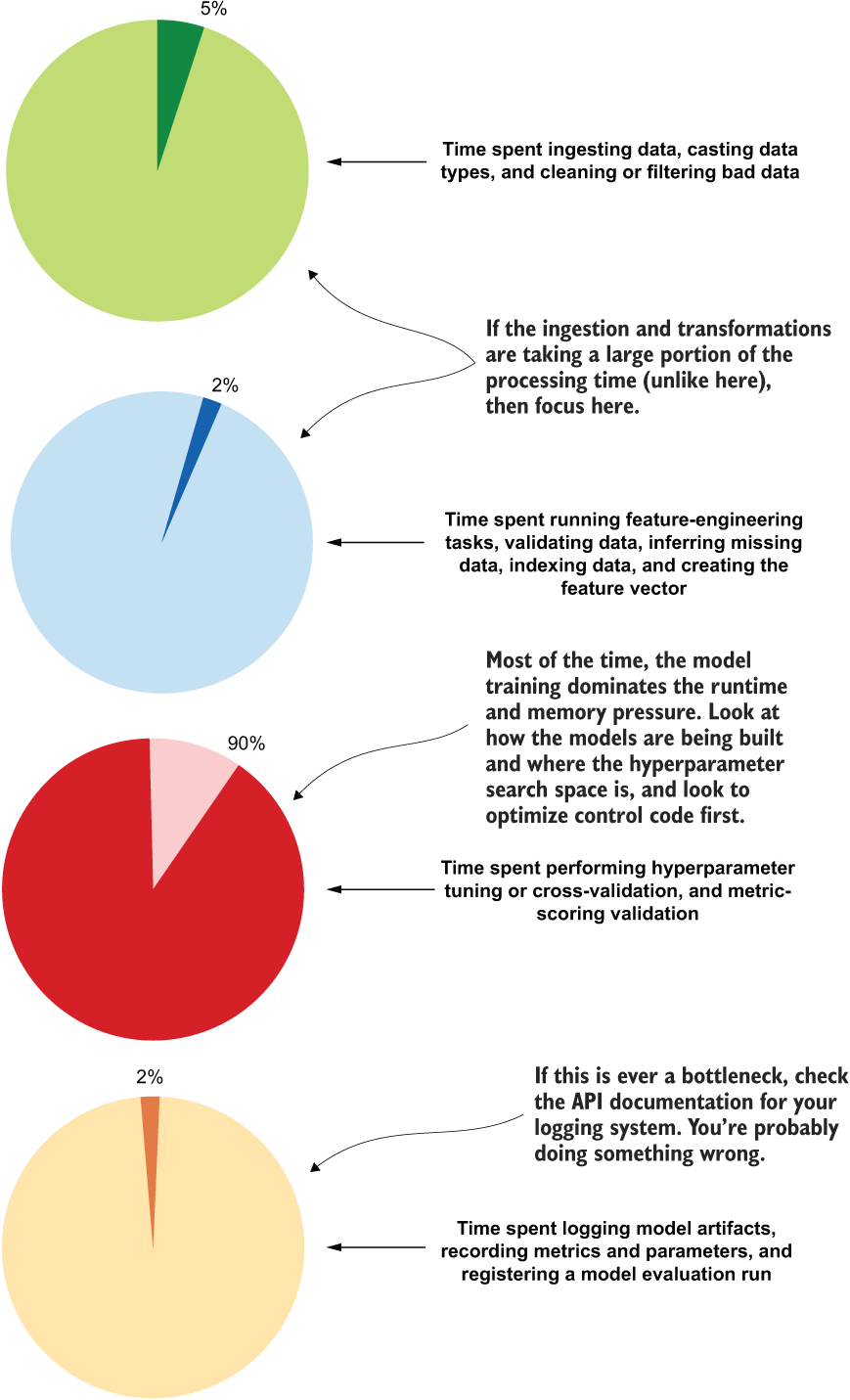
Figure 13.10 A generic breakdown of wall-clock runtime for tasks within an ML pipeline
As you can see, the vast majority of processing time for ML project code is primarily focused on data ingestion manipulations (loading data, joining data, calculating aggregations on data, and converting ordinal and categorical data to numeric representations) and hyperparameter tuning. If you notice that data ingestion is absolutely dominating the runtime of your project (provided that the platform you are utilizing can support massive parallel ingestion and the data storage format is optimal for rapid reading, as in Delta, Parquet, Avro, or a streaming source like Kafka), then look to either replatform your data to a more efficient storage paradigm or research more effective means of manipulating your data.
An incredibly small amount of time is spent on logging, model registration, and basic data manipulation tasks. Therefore, if these show a problem, the fix is likely going to be done relatively easily by reading the API documentation for the module that you’re utilizing and correcting the errors in your code.
Knowing this, any optimization efforts should be primarily focused on reducing the total runtime and CPU pressure of these high temporal-bound stages of a job and not wasted on creating complex and clever code for insignificant portions of the solution. The key takeaway is that the process of optimizing ML code should focus on a few key critical aspects:
- Wait until the entire code base functions end to end before spending time optimizing code. The sheer number and frequency of changes that happen during development will likely make rework of optimized code a frustrating experience.
- Identify the longest-running portions of the code. Attempt to get clever to make these more performant before tackling the portions that are already comparatively fast.
- Don’t reinvent the wheel. If a language construct (or similar functionality in a completely different language, for that matter) will remarkably speed up or reduce memory pressure of what you’re trying to do, just use it. Implementing your own linked list abstract class or designing a new dictionary collection is the ultimate act of hubris. Just use what is out there and move on to solving a more worthwhile problem.
- Explore different algorithms if the runtime is truly terrible. Just because you really like gradient boosted trees doesn’t mean that they’re the ideal solution to every problem. Perhaps a linear model could get relatively close in performance at a fraction of the runtime. Is 0.1% accuracy worth a 50-times increase in budget to run the model?
Embodied within the collective DS-DNA of many teams that I see engage in premature optimization and generalization is the belief that the technical aspects of ML project work supersede the problems that they are trying to solve. They love the tools, the amazing new work being pushed out by large ML-focused organizations, and the rapid advancements being made continually in the ecosystem of ML. These groups care far more about the platforms, the toolkits, the frameworks, the algorithms, and the tech side of ML work than they do about making sure that their approach is going to help their business in the most efficient and maintainable way possible.
13.4 Do you really want to be the canary? Alpha testing and the dangers of the open source coal mine
Let’s pretend for a moment that you are incredibly new to the field of DS. So new, in fact, that it’s your first week on the job. In the office, you look around your desk. Not a single DS on the team has been employed in the profession for more than a month. The manager, an experienced software engineer, is busy with managing not only the DS team, but also the business intelligence team and the data warehousing group, and is busy interviewing additional candidates to fully round out the new DS team.
As a first task, a low-hanging fruit modeling project is generated for the team to tackle. Being told that no, you can’t use your laptops to do the work as you did in school, the direction that the manager gives all of you is to select a framework for developing models.
Within the first few days of research and investigations into platforms and solutions, one of the team members catches wind of a new framework being discussed in blogs. It seems to be forward-thinking, feature-rich, and easy to use. The general discussion around what is planned to be built for it over the coming months is incredibly powerful. There is talk about supporting not only CPU tasks in a distributed massively parallel processing (MPP) system written in C++ that has a slick-looking Python API as an interface, but also GPU clusters and future plans to support a quantum computing interface (quantum oracle optimization of superposition of all possible solutions to least squares problems)!
If you’ve ever read the source code for an ML framework (one that’s used by a majority of professionals in solving actual problems, that is), contributed to one, or built even a wrapper around the functionality exposed in one of the more popular open source ones out there, you’ll realize how silly this “new and hot” framework is. If that describes you, you’d be in the right-hand section of figure 13.11 (not bitter, but rather, wise).
Let’s agree that the team we’re on is entrenched within the middle column of figure 13.11. The team members’ naivete blinds them to the dangers that they’re about to face in embracing this half-baked hubristic monstrosity that an overly ambitious developer is attempting to build. We try it out, we volunteer to be the canary, and our project pays with its life.

Figure 13.11 The hype? It’s real. It also usually means that the object of that hype is really bad (or at least not what it claims to be).
The end result of working in this new and heavily under-construction framework is inevitable: a complete and thorough failure. The failure of getting the project off the ground isn’t because of the API they’re using, nor is it in how they are tuning their solution. The real failure is in the hubris of the developer and the blog hype-o-sphere that surrounds bombastic claims of new functionality and frameworks.
There is absolutely nothing wrong with trying things out. I frequently try out these newly announced packages to see if they’re worthwhile. I do my testing on open source datasets, run them in isolated environments that won’t contaminate my class path with flaky dependencies, and run them through their paces. I evaluate their claimed functionality, check for the ease of enhancing their functionality with custom implementations, and see how the system handles different modeling tasks. Is the memory utilization stable? Is the CPU usage on par (or, hopefully, better!) than comparable systems in widespread use? I ask all of these questions and more through my validations of their claims.
What I never do is attempt to build a project that a business depends on while using one of these packages in their early stages. There are several reasons for this:
- The API’s are going to change—a lot. The entire interface will likely be completely refactored by the time a stable 1.0 release happens. You’ll have to change your code to accommodate.
- Things will be broken. Maybe a few things, but usually a lot of things at the beginning of a project’s alpha release phase. If you build something important on top of flaky code, you’ll be dealing with an unstable project code base.
- There’s no guarantee that the project isn’t going to become shelfware. If a seriously strong community doesn’t exist around the project with hundreds or thousands of contributors and buy-in by a significant portion of the ML community, the code base is likely going to become extinct and abandoned. You really don’t want your project running on dead code.
- Even at the first announced release, tech debt is in there. Corners were cut, shortcuts were traversed, and bugs will be present. It may work great for the demos and be flawless for the prepackaged examples, but it likely won’t work well for your highly specific custom logic that you need to implement to solve your predictive modeling task for your business. At least not until much later in its life cycle.
- Just because it’s new doesn’t mean it’s better. Before deciding on something as critical as a framework or platform, you absolutely have to ignore the marketing hype from companies, blog posters, and the noisy buzz of advertisements. Test things out and perform a scientific study of your options. Select the solution that makes the most sense from a productivity, maintainability, stability, and cost perspective. The shiny new toy could be all of those things, but in my experience, it’s almost never the case (although sometimes these projects do grow into exactly that eventually, so keep an eye on them).
Embracing another person’s hubris is one of the most destructive tasks that can plague an ML team. By not doing proper testing and research of options about how and where to run your code, you run the risk of getting duped into a system that is fundamentally broken and will end up costing your team far more time and money in just keeping the lights on rather than innovating into new project solutions that you should be working on. Let your testing phase be your canary, not your ML projects.
13.5 Technology-driven development vs. solution-driven development
Let’s shift gears from the newbie-crew of DS members in section 13.4 and take a look at working in a group filled with highly experienced ML engineers. Let’s suppose that not a single person on the team has fewer than 20 years of software development experience, and each has grown bored and tired with building different flavors of deep learning models, gradient boosted trees, linear models, and univariate forecasts.
They all yearn to build something to automate away the tedium of the hundreds of predictive models that they are working on. What they want more than anything is a challenge.
When faced with their next major project, an association-rules-based implementation (were they to use a tried-and-true approach), they decide to get clever. They feel as though they could write a more performant version of the FP-growth algorithm on Apache Spark and set to work deriving an equation for an improved version of an FP-tree that can be mined dynamically in such a way as to eliminate one of the core scans of the tree for item collection retrieval.
While well-intentioned, they end up spending three full months working on their algorithm, testing it, and proving that it retains nearly identical results to the reference FP-growth implementation but at a fraction of the time to build and scan the tree. They’ve created a novel algorithm implementation and set to work on using it to solve the business use case that they agreed to develop.
They crack some beers, slap some backs, and get to work on writing their blog post and whitepaper, and prepare for some conference speaking engagements. Oh boy, everyone is going to know just how clever they are now!
They release the solution into production. Everything is working well, and the algorithm is, in their minds, paying for itself every day in cost savings of remarkably improved runtimes. That is, of course, until a major revision for the underlying framework is released. In this new runtime, significant changes are made to the way these trees are constructed in the open source framework, as well as a fundamental level of optimization in how antecedents are building the consequents.
The team is demoralized at the prospect of adjusting the model to fit in with the underlying changes in the developer-level APIs that they used to build their solution. Figure 13.12 illustrates their plight and what they should have done instead.
Figure 13.12 An ML technical debt choose-your-own-adventure path
As you can see, the key decision that derailed the project was in not using preexisting standards that have been proven many times before. Not only did they have to build a solution to support the business use case, but they had to build an entirely new algorithm, integrate it to a framework’s low-level design paradigms, and fully own the implementation to ensure that they can continue to support the business use case that drove the creation of their unique algorithm.
Because their algorithm leveraged so many of the internal structures of the framework to speed up development processes, the team is now left with a new quandary. Do they update their algorithm to work in the new framework version, hoping that it will continue to outperform the provided FP-growth algorithm? Or do they refactor their entire solution to work with the standard algorithm?
There’s no good answer here. Their custom framework is destined to either become shelfware or incur a few quarters’ worth of conversion to make it work.
The principal problem with their attempt was building a custom implementation that they weren’t prepared to support. They were building a solution not to solve the business problem, but rather for notoriety. They wanted to be noticed and appreciated for their skills. The team failed to realize that, while there is nothing really wrong with building new algorithms and advancing the state of the profession, the motivation behind building it should be centered on the necessity to solve a problem.
Had the team members approached the problem with a solution-driven mindset, they never would have entertained the possibility of creating a custom solution. Perhaps they would have contacted the maintainers of the existing popular open source framework and volunteered to create a new version that could be supported by that framework’s community. If there was a distinct need to reduce runtime to meet an SLA and a novel algorithm needed to be built, that’s fine. If you encounter that need, go build it. Just know that you need to maintain that code for as long as that business use case need exists.
I find myself increasingly more and more allergic to this concept of TDD, as it just adds more stress to an already stressful profession. By pursuing the easier (and, arguably, more boring) solution to a problem, particularly if you already have an existing solution to a nearly identical problem in place, you’re leaving the business in better hands. You’ll have less maintenance work to do and more time to creatively use your talents at solving more interesting future problems.
Summary
- Pursuing simple implementations that don’t overreach the immediate needs of a project will save a great deal of refactoring later when the functionality needs to change. Less is more.
- While everyone is at a different stage of growth in software development skills, having a team focus on utilizing common design patterns that are easy to understand and read will ensure that everyone on a team can contribute to and maintain a code base.
- Building unnecessary functionality, complex interfaces, and clever unique implementations within an ML code base only means that you’re having to support and maintain more code, providing no value to the organization. Keeping a code base only as complex as it needs to be to solve a problem is always a wise choice.
- Thoroughly investigating the capabilities, utility, and most important, the needs of any new technology to determine whether it is useful for a project is essential before deciding to integrate any such tooling into a project.
- Take care when working on a project for a business need to focus on implementing only what is needed to solve the problem. Anything apart from what is required for the project is vanity development and detracts from the maintainability of a solution.