
In this chapter, we will look at different pieces of the MIM Service component. You will learn that many of the MIM Service components work hand-in-hand with one another. MIM Service provides a web service API along with a customizable web portal for user and policy management.
Here's what we will discuss in this chapter:
- MIM Service request processing
- The MIM Service Management Agent
- Understanding the portal and UI
The AD and HR (SQL Server) MAs only give the synchronization engine the possibility of talking to these data sources. For MIM to apply codeless logic to the data flow, we need to use a special MA that connects the MIM Synchronization service to the MIM Service interface.
Before we talk about the MIM MA (referred to as the FIM MA by the product), its dependencies, and what is needed to get things flowing through the system, we need to understand some of the technology's mechanics. Before we dive a bit deeper into the request overview, we want to touch upon and remind you about the fact that in FIM/MIM, we have three main phases:
- Authentication
- Authorization
- Action
If you have worked with FIM in the past, you may have seen this graphic many times, but we feel this is an important visualization of the topic discussed:
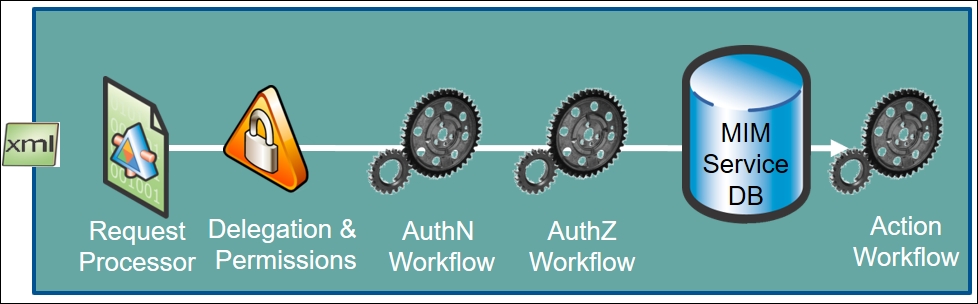
The MIM request pipeline starts with the request object creation, then the Management Policy Rule evaluation. The authentication workflow(s) are next, followed by the authorization workflow(s). Finally, any action workflow(s) are processed which is considered in most cases as the work completed. As a note, any request coming from the synchronization account will bypass all authentication and authorization workflows; only the action workflows would be applied:

We will communicate with MIM Service using a request. A request is essentially a compilation of a set of commands to perform. The set of commands can create, read, update, and delete—or what we call, perform CRUD operations. When we talk about a CRUD operation within MIM Service, we refer to the creating, reading, updating, or deleting operations on data within the MIM Service database. A request can be submitted by a variety of endpoints and could go through a C# service or a web service request to update an object.
The following figure illustrates how different systems can work with MIM Service. On the right-hand side, we have shown that the MIM synchronization engine is making a request to create an employee from an HR system. On the far left-hand side, a user uses the Outlook add-in to submit a request to join a distribution group from an e-mail (an update operation). At the center of the figure, someone is shown using the MIM portal to read distribution list memberships. Lastly, we can have a custom script that makes a request to delete a security group because the group no longer has members:

When MIM Service receives data from a client to perform a particular CRUD operation, it follows a sequence of events every time. During this request creation, we will send a request for what we want to do: create, update, read, or delete. When a request is sent, MIM Service will perform an evaluation to determine where the request could end up, thus impacting a set or determining what policy rules will be applied (we will talk about policy rules later in this chapter). Once the evaluation is done, we will send the request back to MIM Service with the actual request key and its policies, informing whether it is permitted and whether there are any authentication or authorization workflows that apply to the particular request. What gets applied, of course, is a result of your MIM development. The takeaway here is that an evaluation is performed before an MIM Service request can be processed.
Let's circle back and explain a few MIM concepts, such as set objects and the Management Policy Rule (MPR) object. MPR is an MIM object used to define permissions or to check or apply business logic for the authentication and authorization requirements. An MPR object is configurable to allow you to apply logic around business executions such as action workflows. The set object is another special object within MIM Service that is similar to dynamic distribution groups but without group limitations. A set is a combination of objects based on XPath definitions and can have members from any MIM object type—even the custom objects you create:

Earlier, we talked about the life cycle of a typical request or its child request. There are six final statuses, three in the precommit and three in postcommit:
- Precommit:
- Denied
- Canceled
- Failed
- Postcommit:
- Completed
- CanceledPostProcessing
- PostProcessing Error
When we look at the request operations, we see that there may be additional data exchanges that the client needs to be aware of. An example is when you view the MIM portal. Rendering the portal is not one simple client call to the service but many calls that make up a single page. The service has to confirm your access type, and then multiple calls are done around objects that you might be a part of. Viewing the MIM portal is a simple example of how the client controls the conversation via a service API between initiating and completion. Understanding the six states of the status allows you to know where in the process the request failed. From a troubleshooting standpoint, you will know whether the failure was a client-side issue, a server-side issue, or both.
It is also important to know that the read operation is not persisted in the MIM Service database, and there isn't an audit trail for this type of activity. The other operations, create, update, and delete, however, persist to the request object and provide an audit trail. Note that the request object stays in the MIM Service database until it is expired and deleted by the system process.
Request processing involves cache tables within FIM/MIM Service. That is, if you were to submit an update request, you would see a stored procedure performing the update. Let's walk through a single update request and take a look at the evaluation and creation of the request:
- First, we can get the security context of the user by making a request in the SQL profiler trace, as follows:

- Then, we will get the resource type for the request. In this case, it is
person. - Next, we can see the following two built-in accounts:
- This is the first built-in account:

- This is the second built-in account:

- This is the first built-in account:
- Next, we will evaluate the request:

- We can now see the postprocessing phase and update the request status:
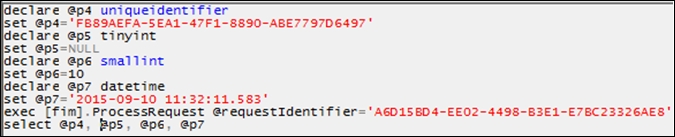
- Then, we will update the request:

- Lastly, we can see the complete request status:

The preceding exercise was a simple update to an attribute, but you can imagine how backend processing can get complex quickly if you have multiple management policies and rules. If the system needed to apply an action or authorization, you would have seen such an event during phase 4 followed by multiple actions that we call collateral requests or workflows.
Once a request is in the completed state, MIM Service will query every 10 seconds to request to complete or mark it as completed with an expiration date. This is used for the clearing and purging of system objects.
Let's talk about how the system takes care of expired requests. The system handles the deletion of expired request objects by the SQL Server agent job FIM_DeleteExpiredSystemObjects, which is scheduled to run once per day. The job can be run multiple times depending on your overall run history. The job of FIM_DeleteExpiredSystemObjects is to find all the requests with the expiration time that is prior to the current time; gather up all the dependent system objects, such as workflow approvals and approval responses; and then delete these objects from the MIM objects value tables. The process involves multiple tables, scrubs only the data, and leaves object ID behind.
Keep in mind that the FIM_DeleteExpiredSystemObjects SQL agent job will only clean 20,000 expired objects per run. If you happen to have 40,000 expired request workflows and approvals/responses, then it is highly recommended to run this agent job twice or even three times a day.
We know how to clean up expired objects, but how are the expiration date timestamps calculated on the object? The object expiration date time is calculated by a customizable 30-day retention, which can be set up by going to the portal and clicking on Administration, then on All Resources, and finally on System Resource Retention Configuration:

There are some things to note about expiration retention. The retention period takes effect on any new requests you make. That is, changing the retention period will not change the retention period of past objects, only that of new ones. To look at the expiration system trends, you would need to look at what the retention period is set to and the objects that are about to expire, as shown in the following SQL script:
SELECT COUNT(*) AS NumberOfExpiredRequest, CONVERT(DATE, ValueDateTime) AS ExpirationDate FROM fim.ObjectValueDateTime WITH(NOLOCK) WHERE AttributeKey = 82 AND ObjectTypeKey = 26 GROUP BY CONVERT(DATE, ValueDateTime) ORDER BY ExpirationDate

In the results of the preceding script, we will see the number of expired requests and the expiration of this request. We now have to look at the expiration retention. Subtract the expiration date (that you see under ExpirationDate in the preceding screenshot) from the current date to give you an idea about which day you have a high number of requests per day. Again, this will only go as far back as your agent job is running, or not running in some cases, so if you have a set of 30 days, you should only see 30 days' worth of requests in the expiration date and time.
So, how do we apply policies in MIM? Simple, we have a defined object called Management Policy Rule that defines a set of object definitions, conditions, or events that can occur in MIM Service. It is the MPR object that defines the permission and possible mapped workflows. There are two types of MPR:
Additional reading on the request processing model can be found at http://bit.ly/MIMrequestProcessing.
When we talk about service partitions, there can be questions about its impact on the system, such as what the recovery plan for service partitions is, what would happen if one's service dies, and how the recovery would happen. Before we talk about high availability, which will come up in a later section, we need to understand the design fundamentals of MIM Service and how service partitions work. Service partitions were introduced as a way of looking at a particular request coming from a particular endpoint and then tying this request to this service. In our example, we have two MIM Service servers, but during the installation, we gave a single MIM service address MIMService.thefinancialcompany.net. Using one service address, we fundamentally changed the way the two servers will behave. Essentially, we put the two servers into a single service partition.
If we had done the default configuration for the two servers, we would have two service partitions called TFCMIM01 and TFCMIM02. By providing an alias for the service partition, we created a central location for both the servers to process requests and workflows:

When we look at when a request is made, there is asynchronous processing that ties the request and associated workflows to the service partition ID to be used. For example, a single service partition might have the service partition ID of 2. Partitioning the service would allow you to isolate the work streams so that you can have something similar to a user portal and an admin portal.
The first time MIM Service starts, it registers the server name in the database along with the service partition name that is assigned a global unique ID for each partition. In our example shown as follows, we have one service partition with multiple servers. If there is no server name defined in the MIM Service configuration, then it will use the default server name. That is, if you install MIM Service on two servers without making a configuration change, you would have two service partition names.

In the preceding screenshot, we can see the configuration database. We have two MIM server services, and they are tied to the service partition ID 2 in the service partition. Note that the ProcessSystemPartition column is set to 1 for both, which means all nodes will process any system-related event.
The service configuration settings are customizable and contained in the Microsoft.ResourceManagement.Service.exe.config file, as shown here:
A few other common configuration items are in the following table. You can look at the service configuration file for more configurable settings:
We will go over the configuration of the activities as we use them in our scenario.
All the activities under authentication are explained as follows:

- Lockout Gate: The lockout gate is a critical activity to make sure you lock out invalid attempts against a workflow. The lockout gate is typically used with the self-service password reset.
- One-Time Password Email Gate: As with the SMS gate, this activity sends a code to a user's registered e-mail address. The gate is configurable to allow a user to register an e-mail or to use an e-mail that comes from a system.
- One-Time Password SMS Gate: SMS gate is an API starting point to integrate your SMS service provider to send a code to a user's registered mobile device.
- Phone Gate: This is a new gate that was developed to integrate with the phone factor authentication, now known as Azure MFA.
- QA Gate: This gate is typically used for the self-service password reset. In this activity, you will define questions, and the user will register answers that will later be used to prove their identity.
Authorization activities are used to authorize specific requests, such as adding a user to a group or sending an e-mail:

- Approval: This allows you to control who is authorizing the request, such as a manager, application owner, or group owner.
- Filter Validation: Filter validation is a function that confirms whether a set or group is valid XPath.
- Function Evaluator: Function evaluator allows you to format the data pipeline to attributes and objects. Take a look at http://bit.ly/MIMFunctions for more information.
- Group Validation: This is used to restrict nested group restrictions that are found in AD and cross-forest scenarios.
- Notification: A notification is used to send a customizable template e-mail to targets, say, if a group is changed.
- PAM Request MFA Validation: This allows multi-factor authorization using Azure MFA.
- PAM Request Validation: This allows the system to verify that you are a valid requestor in the candidate list.
- Requestor Validation: This confirms that you are not able to add or remove members to or from a specific group that you do not own.
The last set of activities are action workflows. When selecting this type of workflow, we can see an option appear:
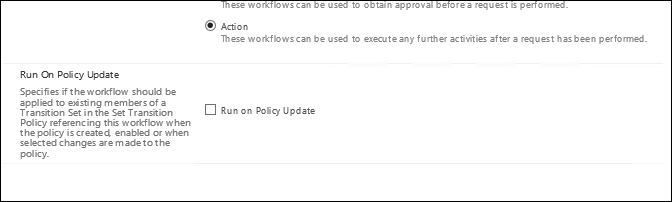
You will then see all the action activities available, as shown in the following screenshot:

- Active Directory - Add User to Group: This adds a user to an AD group.
- Active Directory Password Reset Activity: This performs a user password reset by doing a WMI call to the synchronization engine.
- Function Evaluator: This allows formatting the data pipeline to attributes and objects.
- Notification: This is an e-mail generation activity.
- Synchronization Rule Activity: This applies a specific sync rule to a user, otherwise known as Expected Rule Entry (ERE).
Let's focus our attention on the action workflow and Run on Policy Update. Failure to understand this single setting has created numerous organizational problems, effectively breaking request processing in the system by generating millions of unnecessary requests.
When you select the Run on Policy Update setting, any time you make any change to the management policy rule that this workflow is tied to, the system will reevaluate all targeted objects and run the policy or action against it to verify it is true.
Let's say your manager wants to update the company attribute for all users. To make the change, create a new workflow that fires off an activity to update the company's attribute. Set the workflow to Run on Policy Update. Next, create a disabled management policy rule that targets the All Active People set. When you enable the MPR object, the policy is considered updated, so the workflow executes against all the users in this set. Future changes to the MPR object will fire off the workflow to everyone again, so you should unselect Run on Policy Update when your one-time change is completed. Future accounts that fall into your set criteria will have the company set, but existing accounts will not be (and should not need to be) re-evaluated.