
Chapter 12. Generalization Redux
There can be only one.
—Duncan McLeod, Highlander TV and movie franchise
Thus far we have discussed the notion of class in terms of single set entities. The class defines the unique set of properties that all member entities of that class have. In Chapter 3 the notion of generalization was introduced via an overview. In this chapter we will get into some unique issues around generalization. Ironically, though generalization is very powerful, much of this chapter is devoted to the pitfalls of using generalization and will encourage you to be judicious in its use. To review from Chapter 3:
• A generalization is a relation that describes how specialized objects may be generalized.
• A specialization is a relation that describes specialized details of a subset of objects.
• Inheritance is simply a set of rules for resolving object properties in a generalization.
• Inclusion polymorphism enables substitution of behaviors within a generalization.
• Every member of a subclass is a member of its superclass.
• An object represents a single instantiation of the entire generalization.
• A generalization in UML is essentially a Venn diagram from set theory.
Basically the first two points are views of the same thing. OO generalization addresses a rather common situation in most problem spaces: The members of a class are clearly logically related, but some members have a few unique, specialized properties. OO generalization provides a convenient mechanism for describing that. In other words, generalization enables us to deal with minor variations in a set of closely related entities.
Subclassing
When thinking about generalization the obvious example is a taxonomy, as in a zoological taxonomy that classifies various critters. We start with a very generic critter, such as Animal. We then subdivide animals into phyla like Reptile, Amphibian, Fish, and Mammal based on some specific criteria such as living on land, in the sea, or both.1 These subdivisions form branches where every member of the branch shares the same properties that were used to distinguish that branch from other branches. We can then further subdivide the branches in a similar fashion indefinitely.
Essentially this sort of subclassing represents categorization based on properties. The view in Figure 12-1(a) represents the common tree form that we might see in a paleontology class where the tree’s branches represent evolutionary sequence as well as a division of properties. In OO development we are concerned with a more restricted view that is based purely on the subdivision of sets of properties. In set theory we employ a Venn diagram to describe such categorization, as in Figure 12-1(b). The dots in the figure represent individual critters. All the dots contained within a subclass boundary are members of that subset. Conversely, the subclass boundary encloses all members that share exactly the same properties. In the example, the Amphibian subset boundary represents the intersection of the Reptile and Fish subsets where members share the properties of being able to live both on land and in the sea.
Figure 12-1. Mapping of taxonomies into Venn diagram sets and subsets
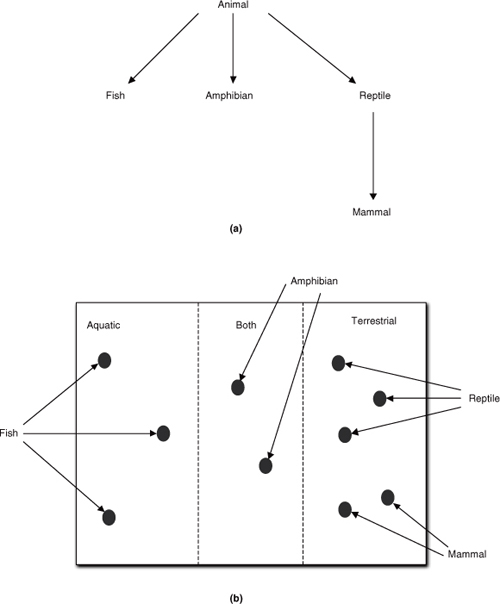
Superclass: A set whose members are further divided into subsets and whose properties represent properties common to all of its descendant subclasses.
Subclass: A set containing a subset of members of some superclass based on a unique set of specialized properties or associations.
We organize the properties that are common to all members of two (sibling) subsets by placing them in a parent superclass. By creating multiple levels in the subclassing tree with individual subclassing relations chained together we can create quite complex hierarchical categorization around common and specialized property sets.
Notation and Rules
The subclassing association notation is quite simple. Each superclass and subclass is represented by a normal Class in the Class diagram. The subclassing relation is indicated by a special sort of association that looks like a garden rake. The teeth connect to the subclasses, and the handle connects to the superclass via a diamond symbol. Unlike an association, there are no roles, conditionality, or multiplicity. There is, however, a unique identifier to identify the association that is called a discriminator.
A subclass can, itself, be a superclass in another generalization. In other words, we can build complex hierarchical trees using subclassing associations. But at each level the superclass has its own unique subclassing association to its subclasses. Thus each subclassing association within such a multi-level tree must have its own discriminator.
Figure 12-2 represents an OO generalization view of our previous example taxonomy. There is some poetic license with the properties because we are just showing the notation, not a real taxonomy.2
Figure 12-2. Mapping a taxonomy into an OO generalization
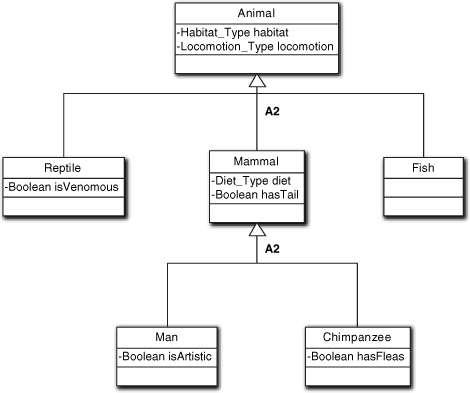
The OO subclassing relation differs from conventional sets and subsets because it has some additional rules that restrict the way we form the relation:
- The set of members of a subclass is disjoint from the sets of members of its sibling subclasses. That is, a given member of the parent superclass will be a member of exactly one descendant subclass.
- The union of members of all sibling subclasses is a complete set of members of the parent superclass. That is, if a class has subclasses, then every member of that superclass must also be a member of one of the subclasses.
- Only leaf subclasses may be instantiated. This is a crucial difference in the way the relational data model is applied to OO generalization compared to Entity Relationship Diagrams used in Data Modeling for RDB schemas. More on this below.
Technically UML does not require any of these constraints. But in MBD we would place the UML qualifiers {disjoint, complete} on each subclassing association. However, as a practical matter, since the MDA profile for MBD requires all single subclassing associations to be disjoint and complete, most tools supporting the profile assume it. The third constraint is really a construction constraint on the developer, so there is no UML notation for it; just make sure the subclasses defined are complete sets and this comes more or less for free.
A generalization is disjoint if a member of the superclass can belong to only one subclass.
A generalization is joint if a member of the superclass can belong to more than one subclass.
One reason the MDA profile for MBD emphatically requires these constraints is that they make life much easier for code generators without significantly affecting our ability to model the problem space. Far more important, though, is that all three constraints are really general OOA/D constraints if we want unambiguous model specifications. Unfortunately we can’t back up that assertion until later in the chapter.
There is one important exception to the {disjoint, complete} rule that is needed to support multi-directed subclassing associations in the model, as in Figure 12-3. Whenever a class participates in multiple subclassing associations as a superclass, that is known as multi-directional subclassing. If the relations are disjoint they should have different discriminators. In Figure 12-3, the relations would be disjoint if a given Part could be a member of only one of the five subclasses.
Figure 12-3. Example of multi-directional subclassing
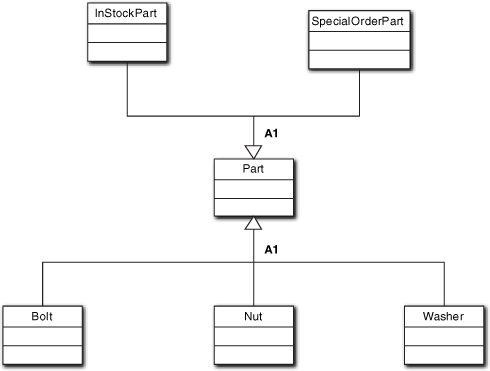
If the associations are joint they should have the same discriminator, as in the figure. In Figure 12-3, a given Part can be both an InStockPart and a Nut. But the Part can be a member of only one subclass from each relation.
Generalization and Specialization
As you no doubt recall, we identify classes based upon all the members having exactly the same set of properties. Figure 12-4 is a Venn diagram with the dots representing various critters where we are interested in specific properties of Humans. The subset boundaries surround members of the species that share the indicated characteristics. Since being a vertebrate is one of the defining characteristics of being a human (in zoological terms), that property set coincides with the entire set of humans; if it doesn’t have an internal skeleton it isn’t human, no matter who its mother was. On the other hand, humans can lose fingers or toes through accidents, cannibalism, and whatnot, so not all humans may actually have the proper count at a given moment in time, though the vast majority would.
Figure 12-4. Mapping of objects (dots) to containing subset boundaries
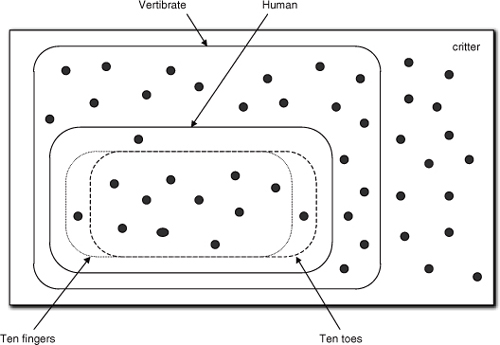
No one would seriously contend that the subset of members who lost fingers or toes after birth were not Human in a zoological sense. Therefore, it would be hard to justify the notion that we needed to define separate classes for Human With Ten Fingers But Not Ten Toes and so on. We would not even seriously consider doing that for Humans who were born without the normal complement of fingers or toes due to birth defects. That’s because zoological taxonomies are defined based upon subclasses having a large number of properties rather than individual properties, and some properties, like internal skeleton, are more important to categorization than others. Thus we can accommodate minor variations in the lesser properties.
The notion of generalization fits well with that fuzziness of definition. The collection of properties provides a general view of what a Human is without requiring that it be satisfied in every detail. However, if the membership of a subset is large and the details are sufficiently pronounced, then we can think of that subset of members as being specialized in a unique category. This is the case for Anthropoids whose members all share critical characteristics—internal skeleton, bearing live young, having hair, bipedal, and so on. However, it is quite clear that large subsets of Anthropoid members are quite different in the same ways. Nonetheless, all Anthropoids possess the same general characteristics.
Humans and Chimpanzees are significantly different in a very consistent manner, so a zoologist can tell them apart at a glance and a paleontologist can tell them apart by looking at a single bone. That’s because the subsets of unique Human properties and unique Chimpanzee properties are large enough and consistent enough to warrant classification in their own right. Yet they share 98% of the genes in their genomes. Given that genetic similarity, it is difficult to deny that they are logically related in some fashion. Specialization comes into the picture by enabling us to think of Humans and Chimpanzees in general terms as Anthropoids for most of their properties and as unique specializations for a few of their properties.
Consider Figure 12-1(b) again. How do we relate Amphibians to Reptiles and Fish via generalization or specialization? In reality, Amphibians are very real denizens of our world, so they deserve their own class. They have the property that they live on land and they live in water. The other critters have the property of living on land or living in water, but not both. So Amphibian can’t be a superclass for Reptile and Fish subclasses because all members of those subclasses do not share all its properties (e.g., a Fish does not live on land). That is, Amphibian can’t be a generalization of properties common to both Fish and Reptiles.
What does work is to make both Fish and Reptile generalizations of Amphibian, as shown in Figure 12-5. There are a number of problems3 with this, but the main point is that it is tough to justify Amphibian as a specialization when it is really just a merge of two classes’ properties. The bottom line here is that even though generalization and specialization usually apply to OO subclassing associations, that is not always the case.
Figure 12-5. Multiple generalization
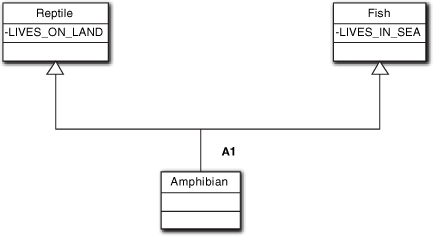
That is not to suggest that you should not think about subclassing in terms of generalization and specialization. On the contrary, they are quite useful concepts when applied generally. The zoological taxonomy was chosen deliberately as an example because, despite its familiarity to the casual observer, it presents a number of issues that affect OO abstraction when creating subclasses. The point here is simply that zoological taxonomies don’t map exactly to OO subclassing, and it is important to understand why they don’t. In particular, there is one crucial factor related to zoological taxonomies that was not even mentioned: They are based more on Darwinian evolution than property sets. Thus zoological taxonomies are not precisely defined when we look at them from the perspective of OO development, where objects’ properties are limited to knowledge and behavior responsibilities. Things are further complicated by inheritance and polymorphism, as we shall see shortly.
Categorization
In the end, generalization is really just a form of categorization. We subdivide logical entities into component entities based upon some set of properties. The subdividing is driven by the general notion of generalization, and we have a set of mechanical rules in the form of normalization for organizing the properties in a systematic manner. We also marry a tree graphic with the existing notation for Classes in a Class diagram as a convenient way to organize everything.
Keep subclassing simple.
This is the cardinal rule of good OO subclassing. It can be theoretically justified in terms of basic OO principles like cohesion. The more specialized properties that are involved in the subclassing decision, the more properties there are in the root superclass, because all members of all the leaf subclasses are also members of the superclass—along with their specialized responsibilities. So when looking at the union properties of all leaf subclasses, the very nature of specialization tends to break down cohesion of the superclass even if we adjust for the level of detail. For this reason, a reviewer should be very suspicious of subclassing trees with a large number of leaf subclasses. That sort of thing can almost always be simplified by employing some sort of delegation.
In addition, simplicity can be justified on a much more practical level. Software needs to be maintained, and adding specializations to an existing tree can be tricky because of the duck-billed platypus problem. Since requirements changes, unlike zoological taxonomies, exist in the future rather than the past, they are chaotically unpredictable. Thus there is a risk that the new class simply won’t fit due to normal form problems or LSP problems (which we’ll get to shortly), so the entire tree will have to be restructured. That can have some rather nasty implications for existing clients when using polymorphic substitution.
Another reason for simplicity is that the OO subclassing association is inherently static; it exists regardless of the specific dynamics of the problem solution. This means that we must change the relation to affect changes in what the application does, which effectively eliminates the possibility of using parametric polymorphism to apply changes through external data without touching the application itself. As indicated in Chapter 5, encoding invariants while leaving detailed differences to external data is a very powerful tool in OO design. Unfortunately, the subclassing relation is an impediment to doing that because of its static nature. Therefore, to maximize the benefits of parametric polymorphism, we should try to limit subclassing to situations where change is quite unlikely in the problem space.
All classes in a generalization must abstract entities from the same problem space.
As indicated earlier, all of the classes in a Class diagram (other than association classes) should abstract an identifiable set in some problem space. That applies to all the classes in a subclassing association, including superclasses.4
There is a further restriction on the classes in a generalization that they all abstract from the same problem space. (Though the subject matter of a subsystem usually implies a single problem space, there is no methodological tenet that requires that.) This constraint ensures cohesion by avoiding hybrid objects whose properties are unrelated, which we will talk about a bit more when we discuss composition later in the chapter.
Methodologically, it is good practice to carry this notion further by requiring that the abstracted entity should be of obvious relevance to the subject matter. When presented with a superclass of Things With Color, a domain expert should not fix you with a quizzical look and say, “So? I can grok that concept, but I thought we were looking for identifiable things specifically related to my Automatic Scenic Vista Painting Generator.” In other words, the superclass entity should have a direct and clear semantic connection to the particular subclass entities in hand.
Superclasses should abstract problem space entities that have a specific is-a association exclusively to the members of their subclasses.
Recall how we got around the Normal Form violation for a color attribute for different classes. There isn’t a Normal Form violation because the color of an Automobile is not the same thing as the color of a Mail Box or the color of a Star. That is, we can restrict the semantics of the color of responsibility to the class identity even though the values across classes may be the same (i.e., have the same data domain of taupe, puce, and fuchsia).
This is just an analogous view of the importance of a direct semantic connection between superclasses and subclasses. To justify generalization in moving the Color responsibility to the superclass, the semantics of the property must be generalized; we need a more general semantics for color of. Thus the color of the Automobile superclass entity needs to make sense in its own right just as the color of must also work for a Sedan subclass. For that to work, the superclass entity must be identifiable and its membership must be limited to the union of members of all of its subclasses. The notion of Things With Color is too vague because it includes virtually all concrete entities, not just those being related through subclassing in a particular problem context.
The generalization must exist in the problem space.
When we create subclasses we should not be subdividing software artifacts. Instead, we should be subdividing problem space entities. To apply subclassing the underlying problem space entities must have a recognizable structure to support that subdivision. For conceptual entities that is often quite easy because the problem space naturally subdivides concepts in terms of subsets. Thus we readily recognize that employment contracts and prenuptial agreements are both specialized versions of the general notion of contract. So an employment contract logically is a contract and subclassing is appropriate.
For many concrete entities, though, any decomposition is usually based on Whole/ Part. Thus an automobile may be decomposed into parts like drive train, body, wheels, and so on in your neighborhood chop shop. But once those parts are identified, they exist in their own right. So a wheel is not an automobile and subclassing is not appropriate. For concrete entities like Engine Block, subclasses are often based upon some problem space notion of type. (This is the dictionary sense, not the 3GL type system sense.) That notion may be manifested in something like a model number. Normally it will be characterized by a set of data attributes that will have fixed values for each model.
One of the interesting challenges in OO abstraction is deciding whether or not to create subclasses and, if so, exactly how to do it. In Figure 12-6, which view is correct? In the figure both versions seem equivalent. Every instance has a unique serialNumber identity. In both versions the instances for a specific model will have identical values for cylinderCount, weight, and cylinderVolume. Are they equivalent models?
Figure 12-6. An example of recasting generalization as knowledge
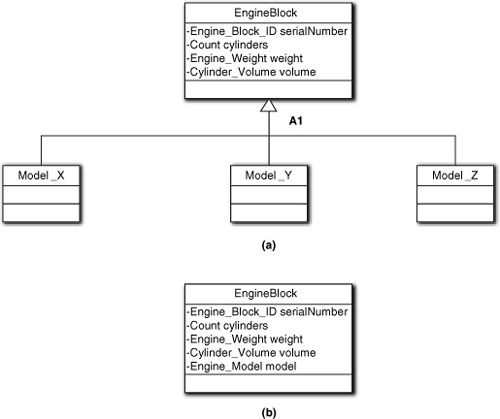
If you were awake when we talked about normalization you will realize that the values in cylinderCount, weight, and cylinderVolume are dependent on engine model rather than the entity identity, serialNumber. That’s a no-no because non-key attributes should be dependent only on the class key (identity attribute). So we can’t use Figure 12-6(b) at all. However, Figure 12-6(a) looks a bit weird because the subclasses have no specializations. In addition, every member of a given model subclass will have exactly the same values for attributes like weight, which should make us suspicious that the value is not dependent solely on the object identity.5 That should be a clue that Figure 12-6(a) may not be quite right.
To properly evaluate this let’s look at the possible reasons why we might need subclassing in practice to solve the problem in hand.
- To collect common properties (generalization)
- To separate specialized properties (specialization)
- To support associations with other objects that may only collaborate with a particular subset of the members of the superclass
- To enable inclusion polymorphism
The last reason is only of interest if the subclasses have different behaviors in response to the same message, but our objects appear to be dumb data holders. The third reason is actually fairly common, but so far there is nothing to indicate that this situation is relevant, so we can ignore it as well. That leaves us with the first two reasons, which don’t seem relevant. All of this should prompt us to look for an alternative to generalization, especially when combined with our concern about identical values for the subclass members.
Consider Figure 12-7. We have abstracted the entire notion of “model” into its own class, each of whose instances have attribute values that are wholly dependent on the object identity, model. This directly and more clearly addresses the previous normalization issue. It also leaves the engine block to be the monolithic entity it naturally is in the problem space. In addition, we only need one object of Model for each model identity, and each object will have unique values that depend solely on the Model identity. With this model we have eliminated the generalization entirely. (What we have done is delegation, which we will be talking about in detail shortly.) So we are back to a variation on Figure 12-6(b) where we separate out an intrinsic concept.
Figure 12-7. Parametric polymorphism as an alternative to generalization
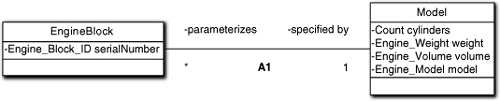
The points of this example are threefold.
- We decomposed the entity (an engine block) in the problem space by recognizing a conceptual overlay (engine model) that was already intrinsically associated with the entity in the problem space.
- Normal form can be a useful tool for recognizing problems.
- The thought processes were driven by a desire to abstract the problem space naturally in the most intuitive manner for the problem in hand. Thus subclasses without specialized attributes did not seem natural.
It is fundamental to OOA/D design that whatever conceptual mapping we apply be known in the problem space.
Necessary condition: Any domain expert should be able to provide a fairly accurate description of each class in a subclassing association just from the name.
Sufficient condition: Members of each leaf subclass will have a clear and unique role to play in the solution.
This is the ultimate acid test for whether we have properly captured a subclassing association. In Figure 12-6(a), the notion of ModelX exists in the problem space, so the necessary condition for subclassing is satisfied. We rejected it because there was no obvious way that members of the ModelX subset contributed to the problem solution in some unique manner (given the requirements provided).
Fortunately, this example is about as tough as it gets for deciding whether subclassing is appropriate. As a practical matter, in the vast majority of modeling situations subclasses will be obvious because of different knowledge attributes being needed in different subclasses or the presence of unique behavior responsibilities for certain members. Thus any bridge architect will readily recognize that there is a difference between suspension bridges and cantilever bridges for the same reason you will be interested in distinguishing them as Bridge subclasses: They deal with different subject matters and have different provisions even though they are both bridges and share many characteristics. More important, it will be obvious that those differences exist to a domain expert, and there will likely be an agreed terminology for them.
Inclusion Polymorphism
Inclusion polymorphism was introduced in Chapter 3. As a quick review, let’s start with a simple example. In Figure 12-8 the client, Problem, needs something sorted. It invokes a sort algorithm to do that. The differences between algorithms are typically performance issues that depend on things like the number of elements to sort.6 That context is addressed by instantiating the association to the best algorithm, which will be a member of a particular subclass.7
Figure 12-8. Generalization to provide substitution of different implementations of the same behavior responsibility
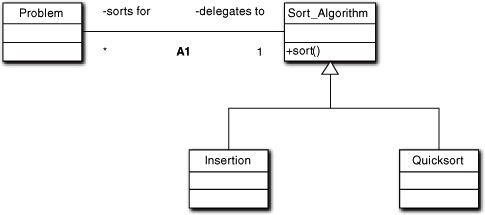
From the client’s viewpoint, though, they are all the same; they simply sort elements. So Problem sends exactly the same sort(...) message regardless of what specific algorithm implementation is invoked. To ensure this all we need is for each subclass of Sort Algorithm to provide an appropriate response to the sort(...) message. Thus the actual behavior implementation executed will be substituted based on which subclass member is at the end of the A1 association when Problem sends the sort(...) message. That association is instantiated dynamically based upon the context that determines which algorithm is the most appropriate. Substituting behavior implementations transparently from the client’s viewpoint based upon subclass instance is known as inclusion polymorphism.
Note that the association between Problem and Sort Algorithm is at the superclass level. An association with the superclass is how we define the scope of substitution. Such an association means that the client is indifferent to which subclass descendant actually implements the responsibility; it will accept the implementation of any leaf subclass that is a direct descendant. If there are multiple levels of subclassing, then the designated superclass will determine the overall “fan-out” of which subclass implementations are acceptable to the client navigating the association. (If some of the “fan-out” implementations are unacceptable, then the tree will have to be accessed at a different superclass.) The way we think of this is that the client navigates to a superclass that provides an interface. The instantiation of the association to a particular subclass member provides the actual implementation when the interface responsibility is invoked.
Figure 12-8 represents the purest form of inclusion polymorphism where only the implementation of the behavior is substituted. In that case, the execution results are not affected because the answer will be the same regardless of the algorithm employed. However, a less pure form, illustrated in Figure 12-9, is far more powerful where we actually substitute different behaviors that produce different results.8 This enables the program results to change dynamically based upon runtime context without the client knowing or caring about it. In Figure 12-9 a completely different Benefit is computed depending on how the A1 association is instantiated.
Figure 12-9. Generalization used to provide different behavior responsibilities
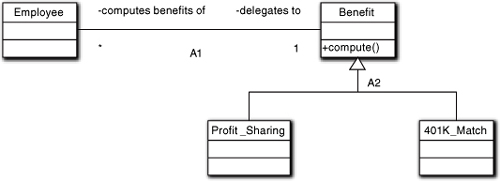
This is a very powerful OO technique because it separates the concerns of collaboration—like it is time to compute a benefit—from the concerns of defining context that depends upon a separate suite of rules and policies—like determining which benefit needs to be computed. When the computeBenefit(...) message is sent, the results are completely different depending on how A1 is instantiated. This becomes clearer when we expand the horizons a bit.
In Figure 12-10 we take some liberties with the UML notation because we do not define the subclass operation when it implements a superclass operation since it will have the same name. To demonstrate a point, though, we have indicated the subclass behavior implementations of the attacked behavior as if they were specialization behaviors unique to each subclass. Think of the subclass behaviors (UML operations) as describing how the subclass implements a response to the superclass’ attacked message (UML interface element).
Figure 12-10. Basic substitution of behaviors through generalization
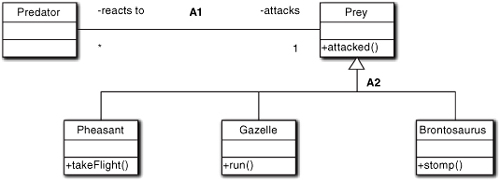
In this case, the superclass Prey defines a behavior responsibility for being attacked that will be shared by all members of all its subclasses. However, the subclasses don’t respond in exactly the same manner. In fact, when we look at the subclass responses they are so different that it becomes difficult to conjure up a single method name that describes what they all do in the superclass.
Nonetheless, as long as the Prey’s client doesn’t care which response the critter makes once it is committed to the chase, the substitution is quite legal. It is also quite powerful because we are not limited to the conventional definition of “implementation.” In this example, we are really substituting entirely different behaviors rather than different implementations of the same behavior.
That combination of disparate subclass behaviors and the client not caring about which is actually employed is both a blessing and a curse. While it leads to a very powerful means of dealing with context-dependent behavior substitution dynamically, it also opens the door to all sorts of problems that we will discuss shortly when we talk about LSP.
Why {disjoint, complete} Subsets?
We are now equipped to provide a better justification for these methodological constraints. Consider the Predator/Prey example from Figure 12-10. It is unlikely that a lone predator on the scale of a Velociraptor will want the behavior resulting from attacking an adult Brontosaurus. To exclude attacking a Brontosaurus, it wants to navigate an association directly to, say, a Gazelle. Then the Velociraptor is going to get a real big surprise if the member of the Gazelle subset that it attacks also happens to possess the properties of a Brontosaurus.
In other words, we insist on disjoint subsets to avoid exactly those sorts of set intersection surprises when navigating direct associations with a particular class. Whoever is navigating has a right to expect that every member of that class will have exactly the advertised set of properties without surprises. If we couldn’t count on that, then the dynamic qualification we would have to provide every time we navigated an association would be an intolerable burden on the dynamic model, not to mention opening up copious opportunities for foot-shooting.
The need for complete subsets is a bit more subtle because it lies in a negative specification. Suppose we have a set of subclasses that are not complete. Then there will be members of the superclass that are not members of any of the subclasses. What if we want to access only members of the superclass that are not in any subclass? That subset membership is defined as not being members of any other subset. Such negative definitions can lead to nasty problems when the program is modified, especially when polymorphic access is used (see Figure 12-11).
In Figure 12-11(a), each subclass provides a different implementation of the fly() behavior. Let’s assume that in the initial problem context the only other birds that were relevant were all flightless. To access only the subset of flightless birds, we need a direct association to Avian that selects member participants based upon not being in other subsets. That is already ugly because it involves testing the nature of the subclass, but it’s possible. In addition, it looks strange because every subclass has a fly() property. This is because we can’t put fly() in the superclass, even though it is common to each subclass, given that it doesn’t apply to the other members of Avian. Thus the model looks like something odd is going on, but we don’t know what because it is hidden in those “special” members of Avian.
Figure 12-11. An illustration of why the union of sibling subclasses needs to be complete sets of the parent superclass
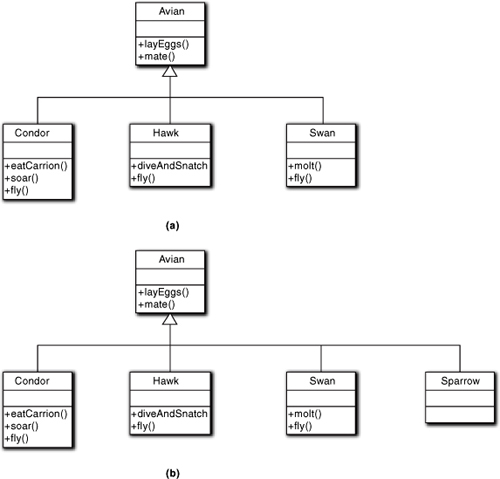
Now suppose the requirements change and we have to add Sparrow, as in Figure 12-11(b). Now we have an ambiguity for whoever does the maintenance: Is Sparrow a new set of Avians that were not relevant to the original problem? Or were Sparrow members included in the Avians that were not subclassed originally? The original developer knows, but not necessarily a different maintainer, because the model is not clear about those Avians that are not members of explicit subsets. In other words, the original notion of flightless birds is not visible in any way.
This problem is especially nasty because it is quite likely the maintainer may not even think about it. The reason is that the problem lies in whoever was navigating that association to Avian to access those pure (not subclassed) Avians. In other words, the problem lies in the context of some existing collaboration that is probably totally unrelated to why the Sparrow subclass was added.
You may argue that in this case it doesn’t matter because Sparrow isn’t flightless, so the original collaboration is unaffected. True, but the maintainer can’t know that without looking at the original collaboration context—assuming the maintainer is even aware of it. There are also other ways to break the client. What if Sparrow members are only now relevant (i.e., weren’t previously instantiated) but they have no special properties relative to the problem in hand, so they are just lumped into the Avian superset? Now the condition for the Avian access is that the members selected aren’t in any other subset and they aren’t Sparrows; that is, the definition of what an Avian is has changed without telling the original client of Avian. That’s why negative definitions are bad news.
A lot of words have been put around these two rules of subclassing, because it’s amazing how few OO developers don’t understand the sorts of ambiguities that violation of these rules introduces. Considering the potential for nasty problems during maintenance, violating these rules should be grounds for breaking the developer’s thumbs. Even more surprising is how many OOPL designers do not seem to understand it either. All these problems could be completely eliminated if the language designers simply did not enable us to create a superclass instance without specifying a leaf subclass.
Multi-directional Subclassing, Multiple Inheritance, and Composition
The same generalization may be involved in multiple subclassing relations. That is, a superclass may have multiple subclassing associations with different subsets. This is known as multi-directional or compound subclassing. Some examples appear in Figure 12-12.
Figure 12-12. Different generalizations for the same basic semantics
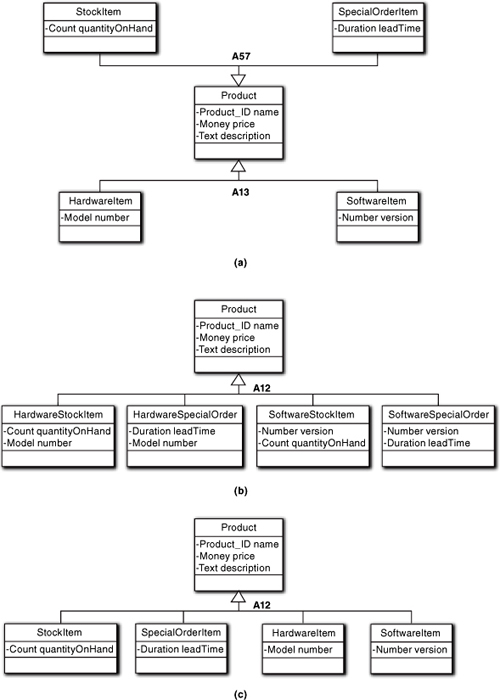
The interesting question in Figure 12-12(a) is: What properties does a leaf Product object have? A Product is either a StockItem or a SpecialOrderItem, but not both. Similarly, it is either a HardwareItem or a SoftwareItem, but not both. But can a Product be both a StockItem and a SoftwareItem? In this case, the answer is yes because the associations have different discriminators, A57 and A13. Each relation represents an independent view of Product subsets, and every Product object will be categorized by both relations.
That means the individual relations are disjoint but the unions of subclass members of each relation both contain exactly the same members, which happens to be the complete set of superclass members. This is because both unions are independently complete sets of the same superclass, which effectively means that the number of subclasses of Product is combinatorial, as indicated in Figure 12-12(b) with a single subclassing relation. In other words, the compound subclassing of the in Figure 12-12(a) could have been expressed as Figure 12-12(b); they are equivalent. The value of the first view becomes apparent when we consider the combinatorial expansion if A57 and A13 each had, say, half a dozen subclasses. More important, the dual-relation view provides a separation of concerns that is much easier to understand.
What if the relation discriminators were the same in Figure 12-12(a)? It would mean that the relations were not independent views of the same Product members, which means that only the union of all subsets for both associations is complete. The subclasses remain disjoint sets, though, so a Product object would have to be a member of exactly one of the subclasses among the two associations without any combining of properties. In effect, that could be expressed as the third view in the Figure 12-12(c) with a single association. Again, the value of using multiple associations here lies in separating concerns so that the models are more understandable.
Use multi-directional subclassing to make the model more comprehensible.
Multi-directional subclassing enables us to view the root superclass generalization in different ways. However, it doesn’t fundamentally change what the subclassing is and how the properties are resolved compared to an equivalent single subclassing association. In contrast, we can provide fundamental changes by combining multiple subclassing associations through composition. In composition, the associations “meet” at the subclass level rather than the superclass level. In other words, a subclass may descend from multiple superclasses.
Generalization resolves sets that entirely include subsets.
Composition resolves intersections between sets.
Going back to Figure 12-6, we could not employ generalization to extract the Amphibian properties because not all members of the Reptile and Fish sets had both properties. However, that intersection situation is represented exactly when Amphibian inherits from two different superclasses. The subset defined by the intersection is “composed” from the intersecting sets. Thus the concept of composition is just a mathematical dual of generalization.
Whenever a subclass descends from multiple superclasses we have what is known as composition. It is also known as multiple inheritance because the subclass inherits or resolves properties from more than one superclass. While subclasses in single or multi-directional subclassing are always objects of a single root source, subclasses in a composition are composed from multiple, often disparate sources.
Figure 12-13 is a classic example of representing a hierarchical tree, and every POS order entry site will have a similar representation somewhere to manage user navigation. We could represent such a tree with a single Node and a reflexive, conditional parent/child association, but this version eliminates the conditionality of the association. This is important because it converts dynamic rules embedded in the code into static associations, which reduces code size and opportunities for inserting defects. It also enables the LeafNode, RootNode, and IntermediateNode elements to have unique properties, which is likely necessary in most real-world POS sites.
Figure 12-13. Model of category navigation for a POS site
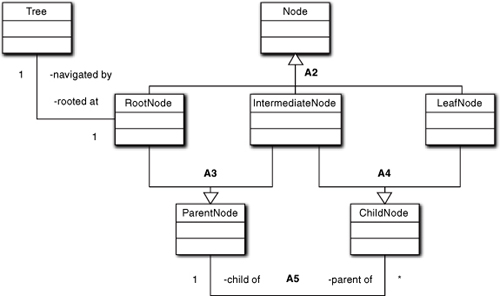
Typically the traversal algorithm is placed in Tree and it “walks” the hierarchy. This representation enables that algorithm to be much simpler because it can determine exactly what to do next based upon the type of node it has in hand; there is no elaborate “memory” needed about the context of where it has been or where it is going. (Leon Starr provides some excellent examples of this sort of thing in his book, which we highly recommend.9) That is largely enabled by the use of composition in forming LeafNode, RootNode, and IntermediateNode.
The same rules of disjoint, complete sets apply to the individual associations. Inheritance is also the same; each subclass has the union of all relevant superclass properties. We just have to traverse multiple lines of ascendancy to collect that union. What makes composition unique is that the root superclasses can abstract quite disparate entities, which results in subclasses that are hybrids of potentially quite diverse properties.
That is not the case in the Node example because the notions of ChildNode and ParentNode are semantically closely related to the notion of a hierarchical tree. In fact, it would have been plausible to introduce another subclassing association between Node and ChildNode/ParentNode, making them a sort of multi-directional subclassing of Node. In that type of semantically cohesive situation, composition is reasonably benign.
However, composition is not a very OO notion because it can lead to serious cohesion problems. When the root superclasses are logically very different, the subclass tends to lose its cohesion. It can also lead to subclasses that cannot be directly mapped to problem space entities. This is most obvious when we consider the “-able” compositions common today in object-based interoperability infrastructures or RAD layered models. Such infrastructures tend to make extensive use of composition because it is a very convenient way to cobble together complex behaviors in a generic fashion that is independent of individual problem context. So when we need to, say, stream an object’s attributes to a file, we make the object a composite by inheriting stream facilities from a Streamable superclass.
That works nicely for layered model and interoperability infrastructures because much of the grunt work can be handled transparently by hidden infrastructure implementations that understand the way the language compiler implements classes. In addition, such infrastructures are much more generic than typical applications, and their problem space is really the computing space. However, it presents a problem for mapping the object to the problem space in an individual application because such hybrids may not exist there. (In the streamable case, we are actually making a hybrid from two different problem spaces!) To see the problem, try walking into your nearest Honda showroom and asking to test drive a Streamable Accord. This is why one of the earlier guidelines in the chapter required generalization classes to be from the same problem space.
Composition is also heavily used in functional programming, and within that paradigm it is very useful because it “plays” very well with other features built around the lambda calculus view. Unfortunately, there is a tendency for developers to try to mix and match things that seem neat in different paradigms. Because multiple inheritance is a convenient way to implement composition in an OO environment, there has been a recent tendency to import composition as a mainline OO technique. Sadly, those efforts are often misguided because the OO and functional programming approaches are fundamentally incompatible. Construction paradigms exist as methodologies because their practices play together well in the overall context, providing a synergy that is greater than the sum of the parts. Cross-pollination of basic techniques between incompatible paradigms risks undermining that overall synergy. That happens when we apply composition in an OO context in a manner that results in subclasses that are not logically cohesive.
Use composition very cautiously and insist on semantic cohesion among the root superclasses.
Most of the abuses of composition in an OO environment occur when dealing with hybrids from multiple problem spaces, as in the “streamable” example. That should actually be rather rare when practicing MBD because when separating concerns during application partitioning, we naturally tend to have subject matters that isolate particular problem spaces. For example, almost every MBD application will have separate subsystems for UI, persistence, and hardware access. Therefore, the notion of streaming to a file would be limited to the persistence access subsystem, removing the need for problem solution classes in other subsystems to have streaming facilities.
Nonetheless, we need to exercise great caution when employing composition. Always keep in mind that it is a technique that is characteristic of functional programming, not OO programming.10 It should only be used within these constraints: (a) The root superclasses are logically related, and (b) the hybrid subclasses are valid problem space entities.
Before leaving the topic of composition, we need to note that composition is not tied solely to multiple subclassing. At the OOP level we can also implement composition by embedding classes within other classes. So using multiple subclassing and inheritance is just one (rather elegant) way to implement composition. In UML, the closest we can come to embedding one class in another is to define a composition association between them and the composition association isn’t part of the MBD MDA profile. Thus, at the OOA level, all problem space classes are peers, regardless of what optimizations might be necessary in OOD/P to satisfy nonfunctional requirements. Thus the only classes that get embedded in other classes at the OOA level are knowledge attribute ADTs.
The last point to make before leaving this topic is about the special case in Figure 12-14.11
Figure 12-14. An illegal generalization
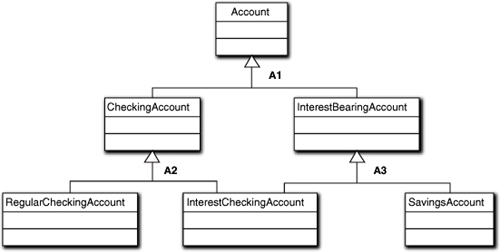
What’s wrong with this picture? Hint: As Mellor and Balcer point out, the Inter-estCheckingAccount is illegal. The question is, Why? Because, by the rules of inheritance, it is both a CheckingAccount and an InterestBearingAccount. That is illegal because the A1 subclasses must be disjoint sets. This is easily seen by examining the corresponding Venn diagram in Figure 12-15.
Figure 12-15. A conundrum for mapping properties in terms of class sets. Where do interestbearing accounts go?
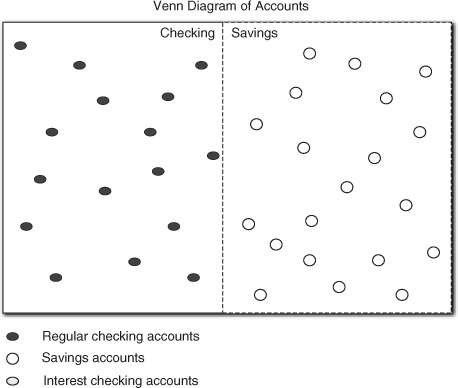
The problem with Figure 12-15 is that there is nowhere to put the dots representing Interest Checking accounts. That’s because InterestBearingAccount and CheckingAccount represent classes defined with different properties. All members of each class must have exactly the same properties as every other member of the class. Therefore, if we try to instantiate an Interest Checking account in the subset of Checking accounts we have a problem because the rest of the accounts in that group do not have the property of bearing interest. Conversely, we can’t place those members among the Interest Bearing accounts because they have Checking Account properties that other members of the class don’t have. The general rule of thumb is that the same subclass can’t have multiple superclasses that derive from the same root superclass.
Liskov Substitution Principle
While superclasses are not instantiated, inclusion polymorphism depends upon being able to send messages to the instance in hand by knowing nothing more about it than it is a member of some superclass. This enables behaviors to be substituted transparently from the client’s viewpoint. Alas, we must be a bit careful about that substitution.
In 1988 Barbara Liskov12 came up with a fundamental principle that constrains substitution in type systems, known as the Liskov Substitution Principle (LSP).
If for each object o1 of type S there is an object o2 of type T such that for all programs P defined in terms of T, the behavior of P is unchanged if o1 is substituted for o2, then S is a subtype of T.
This is a definition that only a type maven could love, so try this paraphrase:
Any client sending a message to an instance identified only as a superclass must be indifferent to which descending subclass the instance actually belongs.
If you are an astute observer you will no doubt notice that this paraphrase is not quite the same as Liskov’s. Her principle is a constraint on the object types while ours is a constraint on the client’s view of the substitution. Also, you should recall that OOA/D is about class systems rather than type systems. The main difference, though, is that if we interpret LSP literally, it is almost impossible to enforce in any practical OO application employing inclusion polymorphism, while the paraphrase is more feasible.
That’s because of the phrase “behavior of P is unchanged.” Taken literally, this phrase essentially means that only implementations of the exact same behavior could be substituted, such as insertion versus Quicksort implementations in the sorting example earlier. But the real power of polymorphic substitution is achieved when we substitute different behaviors and get different results. In other words, when we use inclusion polymorphism we actually want different things to happen. We just want them not to be so different that the partner in the collaboration cares. Clearly, the program is going to behave differently (i.e., produce different results) if we substitute the behavior that actually responds when we send the same message. To see this, go back to the Prey example earlier in the chapter and speculate about the program results of the Predator attacking a Gazelle versus attacking a Brontosaurus. If LSP is so irrelevant to the way we use polymorphism, why make a big deal about it?
One reason is that LSP is a popular discussion on OOPL forums—there are endless discussions about whether a Square can be a subtype of Rectangle, often leading to amusing flame wars. That’s because people keep trying to apply LSP quite literally to OOPL code. Given a literal view of program behavior, we can always find some special context where the program behavior, expressed as a DbC contract, can be broken. The reality is that LSP is virtually useless when literally applied to subtyping at the OOP level; it is simply too constraining to be of practical use.
Another reason for the online flame wars is that the participants are blinded by the merging of message and method in the OOPLs. The discussions tend to get bogged down in implementation details under the assumption that the client is requesting something specific to be done (Do This) at the superclass level. In many of those cases the problem would simply disappear if we could name the superclass method differently (i.e., treat it as a message that announces something the sender did).13
Recall that OOA/D is about class systems rather than type systems. Therefore, we need to recast the constraints in a manner that is useful for the design view of OO software construction. That recasting is represented by the paraphrase of the principle. Instead of worrying about the behavior results being the same, we worry about whether the client (more precisely: the collaboration context within the overall solution) cares about the possible differences in those results. In OOA/D we address this in several ways.
We treat messages as announcements of some change in the application state that was triggered by the sender of the message. Throughout this book we have been beating the drum that the message sender should have no knowledge about what the response to the message will be. So in that sense, LSP should never be a problem at the OOA/D level because the client has no expectations. In MBD we enforce this because we only define what events (messages) the superclass may accept on behalf of its subclasses, not their responses.
As pointed out previously, when we think of “client” we should take a more generic view of the collaboration in terms of DbC contracts between the receiver and whoever sends the message. If we access through a superclass we need to define a contract for that collaboration that applies for all members of the set, regardless of their subclass. One way to do this is by properly abstracting the invariants of the service to be provided. Symbolically we indicate that by providing an appropriately generic name for the behavior at the superclass level. This requires thinking carefully about the context of collaboration and the fundamental nature of the services provided.
In MBD we carry that further because we limit the context to a particular subject matter through application partitioning. This tends to narrow the view of what services are necessary. We also place a lot of emphasis on cohesion and, consequently, avoid complex subclassing trees. Also, we tend to look for other alternatives to subclassing in the problem space. Finally, our emphasis on association abstraction and navigation as a means for enforcing problem space rules tends to ensure that the contexts for superclass access are rather limited and well-defined. All these things tend to make LSP largely irrelevant at the OOA level.
Nonetheless, it is important to understand why LSP is important overall so that we can deal with those rare situations where it may come into play. In an initial development we can usually define a correct implementation where LSP is satisfied fairly routinely. LSP issues usually arise when we modify an existing subclassing tree by adding new classes somewhere in the tree.14 Whenever that happens there is a risk that we will break an existing superclass access context. That is, the developer directed the message with certain assumptions about what will happen in the overall solution context. Changing the way behaviors are substituted can invalidate those assumptions.
That presents a very practical problem whenever we modify a subclassing tree that is accessed polymorphically. We must go to every client that accesses the tree via a superclass and verify that the client is still indifferent to the behaviors for all new or modified descendent subclasses. In the event that a client’s indifference is broken, the client access context will have to be modified, which will probably entail a change to its implementation—serious stuff, because clients are supposed to be unaffected by service changes.
One way to think about this is to recall that the entire tree exists to resolve properties of a single object. Inheritance defines what behaviors the object actually implements by “walking” the tree. Thus the tree is, in a sense, part of the implementation of the object. To properly address a superclass message, the developer must understand that implementation. This breaks encapsulation and implementation hiding.
Avoid polymorphic message addressing in the OOA; use it only when it clearly exists in the problem space.
Before sending in a death threat because this seems to indicate MBD is throwing out a characteristic OO feature, note that the context is limited to the OOA. We rarely see behavior taxonomies outside the computing spaces, much less polymorphic substitution of behaviors. Therefore, we should be suspicious about abstracting one from a customer problem space. As it happens, the primary use for inclusion polymorphism lies in the computing space, especially for OOP dependency management. One reason is that the computing space is about algorithmic computing, which means that we have exotic facilities expressly for manipulating behaviors. In addition, 3GLs are based upon type access and procedural processing, which is ideally suited to such substitution.
However, we do see a lot of data inheritance and we can have LSP problems with that. The model in Figure 12-16 actually appeared in an online LSP debate. Amazingly, the debate took up a huge amount of bandwidth over a couple of weeks without anyone realizing what the real problem was.15 That was because the debate was focused on various proposed behaviors that operated on the data without paying much attention to the knowledge definitions themselves.
Figure 12-16. Example of a knowledge LSP violation
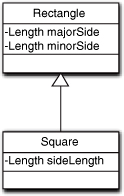
If you have been paying attention you will note that there is only one subclass, so the author was one of those who never heard of the complete subset rule. Right away this should indicate that something is wrong because it is kind of tough to come up with a proper name for a sibling subclass for Square that also is-a Rectangle.16
The real problem here, though, is that the common knowledge attributes in Rectangle aren’t common. Square defines its own specification for the same knowledge semantics. By the rules of inheritance, majorSideLength and minorSideLength are attributes that all of Rectangle’s subclasses share. Therefore, Square should provide an implementation of them; instead, Square provides a different knowledge specification and implementation. More to the point, they are defined as individual properties of Rectangle that are part of the unique suite of properties defining the Rectangle class. This means Square cannot combine them into a single property like sideLength, even if the semantic made sense.
In fact, the semantic doesn’t make sense because the representations of two distinct sides versus a single side are not the same since they are defining characteristics of the class of objects. The developer has chosen to abstract the essential nature of various polygons in terms of differences in the way sides are defined. At best they are only equivalent in particular contexts of use. It is that distinction of defining nature versus context equivalence that lies at the heart of the LSP problem. LSP insists that they should be equivalent in all contexts, but it is trivial to construct contexts where public access will be different for the two representations (e.g., someone invokes setMinorLength and setMajorLength with different values for a Square).
You can redefine the implementation of a knowledge attribute in a subclass, but you cannot redefine the nature of the attribute.
If you take care not to violate this rule, you are unlikely to encounter LSP problems with your data inheritance and accessing of that data through a superclass.
Alternatives to Generalization
Though elegant, subclassing has a number of disadvantages. We’ve already mentioned that static structure tends to get in the way of encoding invariants while leaving detailed differences to external data. Another problem is that complex subclassing trees often reflect lack of cohesion in the root superclass abstraction. Complex trees can be difficult to modify because of the duck-billed platypus problem in the form of introducing LSP problems. For these reasons we have the following guidelines, in descending priority:
Prefer parametric polymorphism wherever it is reasonable.
Prefer delegation if reasonable.
Keep subclassing trees simple.
Keep subclassing trees to one level wherever possible.
As a practical matter, doing the last two usually involves at least partial use of the first two.
Delegation
There are at least two definitions of delegation currently in use. The more restricted one is that an object has a public responsibility it delegates to another object by simply relaying the message it receives to the other object.
In Figure 12-17 when ClassA gets a doIt() message, it simply invokes ClassB::doIt(). The key point here is that ClassA has a publicly designated responsibility that it abdicates to ClassB by relaying the client’s message as-is to ClassB unbeknownst to the client.
Figure 12-17. Example of improper delegation implementation

Once we delegate, the responsibility no longer belongs to the original object.
Unfortunately, this sort of thing is done all the time in OOP today, which is a sad commentary on developers’ knowledge of OOA/D fundamentals. Don’t do that! Behavior is a property just like knowledge and it is subject to normalization, just like data attributes. Two different classes should never have exactly the same behavior property because it violates Third Normal Form. (For those of you who are relationally challenged, it violates one-fact-one-place.)
It also violates the basic OO paradigm of peer-to-peer collaboration. If ClassB has the actual implementation of the doIt() behavior, then the client should be collaborating directly with ClassB rather than through a middleman (ClassA). When ClassA acts as a middleman, it is doing exactly the same thing that a higher-level function in a hierarchical functional decomposition tree does when it invokes a lower-level function to do something that is part of its own specification. Peer-to-peer collaboration in OO development is expressly intended to eliminate those sorts of hierarchical dependency chains.
To see why this is Not Good, think about what happens if requirements change and we need to change the interface to ClassB::doIt() by adding an argument to the data packet.17 Clearly, the client needs to add the required data to the message, so it needs to change in addition to ClassB::doIt(). However, with this form of delegation we also need to change A since the new data must be passed through its interface. Thus we are forced to modify A when it no longer has anything at all to do with the collaboration between the client and B. This is especially bad in the OOP-level type systems because we must change the type signature of ClassA, which defines what ClassA is. So to accommodate a change in a personal collaboration between ClassB and the client, we need to change the definition of ClassA!
In contrast, if we remove the ClassA::doIt() responsibility from the figure, we have the second, more general form of OOA/D delegation. The basic idea is that objects in ClassA would originally have the doIt() responsibility, but to simplify ClassA we decide to delegate that responsibility to another object in another class, ClassB. We abstract ClassB to handle that particular responsibility. Now the client needs to navigate through ClassA to get to the responsibility. To do that, the client needs to know nothing about the ClassA semantics. Better yet, ClassA does not know about the message specifics, so it is unaffected by the requirements change.
The important thing to note is that when we do that splitting, each responsibility is “owned” by only one of the new set of classes. Since the classes were originally one, they will be related in some fundamental way by an association. Therefore, a client who needs to access the responsibility may have to navigate “through” the original object on the new association path to get to the right service-owning object. Though association navigation is more complicated, we preserve peer-to-peer collaboration and eliminate hierarchical dependency.
Delegations must exist in the problem space.
The same notion of problem space entity decomposition for subclassing decomposition applies to delegation decomposition. Proper delegation can’t be an arbitrary splitting up of object abstractions. An object abstracts a single identifiable problem space entity and the class just defines a set of similar objects. If we split classes, we are also splitting the underlying entities that they abstract. To be a valid split, the original underlying problem space entity must be logically composed of other identifiable entities. However we split the class, the new classes must represent those component entities from the problem space. In other words, the delegation must already exist in the problem space as we decompose the original problem space entity into its constituents at a finer level of abstraction.
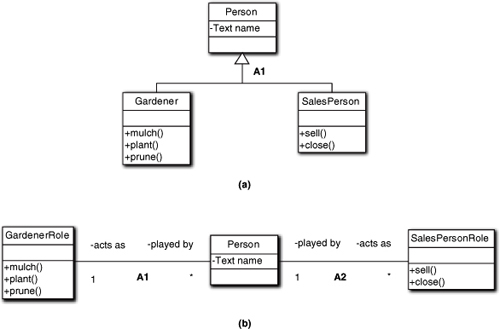
Quite frequently the problem space decomposition will be conceptual, even for concrete entities. For example, a Person is not decomposable except from the viewpoint of an organ bank. However, the Person may play multiple roles in the problem context. Thus we can abstract a Role that has individual responsibilities that would otherwise accrue to a Person. Abstracting roles is far and away the most common form of delegation.
The two views in Figure 12-18 capture all the same responsibilities relevant to the problem in hand. But the delegation view is a clearer representation of what is being modeled.
Figure 12-18. Using role objects as an alternative to generalization
Parametric Polymorphism
We already talked about parametric polymorphism extensively in Chapter 5 because it goes hand-in-hand with extracting invariants from the problem space. So we won’t talk about it here, other than to mention that quite often it recasts behavior generalization to a data generalization rather than completely eliminating the generalization.
Basic Abstraction
Generalization, delegation, and parametric polymorphism just represent different approaches to abstracting the problem space. Whichever approach we choose, it will somehow include all the same responsibilities necessary to solve the problem in hand. But we have considerable latitude when identifying entities and responsibilities necessary to solve a given problem in hand. This is because customer problem spaces and their entities offer far more variety than computing space entities that are constrained by mathematical definition. Thus we get to apply a lot of interpretation to the problem space.
Subclassing, delegation, and parametric polymorphism are just examples of analysis patterns that are so common they warrant a degree of methodological formalization. There will be situations where you can avoid generalization by simply interpreting the problem space in a different manner so that independent entities are abstracted with properties defined differently to achieve the same solution goals. Because such situations will be unique on a problem-by-problem basis, there are no additional patterns to present as guidelines. All we can do is offer the following bon mot:
When abstracting the problem space, don’t accept the first plausible model that seems to address all the requirements. Look for and evaluate alternative abstractions and divisions of responsibilities.