
Chapter 4. MBD Road Map
He who knows the road can ride full trot.
Italian proverb
OO methodologies tend to be complex, and MBD is no exception. In addition, MBD represents a rather unique synergy of OO features that is difficult to appreciate until the whole thing is grokked, thus it is difficult to thread one’s way through the forest without some context. This chapter provides a basic overview of some key elements of the MBD philosophy. That philosophy is basically an OO modeling philosophy; MBD simply provides a different emphasis than other approaches.
Problem Space versus Computing Space
This is unquestionably the central concept underlying model-based OO methodologies in general and MBD very much in particular. Very early in the development of the formal software design approaches a distinction was made between analysis, which dealt with the problem space, and design, which dealt with the computing space. This was originally formalized in Structured Development techniques in the late ’60s. That eventually evolved into classical OOA and OOD modeling.
When computing moved out of university labs and into corporations in the ’50s, it became readily apparent that the MIS types did not think about or describe problems the same way the computer scientists did.1 They employed a different vocabulary and their problems tended to be more complex and diffuse. More important, their problems were not defined with mathematical precision; they were inherently fuzzy and were expressed ambiguously in natural language.
The notion that requirements needed to be expressed more rigorously than natural language drove the development of a number of ingenious analysis techniques. The difference between the customer’s problem space and the software developer’s problem space was recognized, and analysis was regarded as a requirements specification technique rather than a software development technique. The job description of systems analyst was created, but that person usually lived with the customer and threw the analysis over a wall to programmers.
OOA and OOD are both aspects of solution design in the OO paradigm; both represent solutions to the customer problem.
When the OO paradigm was formalized in the ’70s the founding gurus assumed problem analysis was part of requirements specification, so it was a prerequisite for OO development. They also felt there was a need to provide distinct stepping-stones for software design, so they made the separation of OOA and OOD central to the OO paradigm. They saw an OOA model as an intermediate stepping-stone solution to the problem on the way to developing the final software solution. The OOA model represented the abstract resolution to the customer’s functional requirements that happened to be expressed exclusively in the customer’s terms. In the 2000s this separation of the customer view of the solution from the computing view became further formalized in OMG’s Model Driven Architecture (MDA) where the OOA model became a Platform Independent Model (PIM), and there is no confusion about the fact that the PIM is a model of a solution even though it provided an explicit bridge to the customer’s domain.
Basically the Founding Gurus saw a continuum of solutions:
Requirements → OOA model → OOD model → OOP code → BAL → Executable
where everything to the right of a Requirements was a solution to the problem. Those solutions represented decreasing levels of abstraction and increasing inclusion of Turing detail moving to the right. Each step was viewed as a stepping-stone in incremental conversion of problem space semantics to computing space semantics.
At the same time, everything to the left of the Executable was regarded as specification of whatever was immediately to the right. In addition, each → implied a process that brought added value to the development. Thus a linker/loader brought explicit addressing, support services, and whatnot to the compiler’s BAL code to produce an executable memory image; the compiler brought various levels of optimization for a particular instruction set, and so on.
Thus the OO paradigm formalized development by bringing several innovative notions to the table: incorporation of the customer’s domain in the solution, stepping-stones in development, successive levels of abstraction, and the dichotomy of specification and solution. The dichotomy of specification and solution is particularly noteworthy because it was quite a new view of development. This dichotomy is summarized in Table 4-1.
Table 4-1. Dichotomy of Process Steps as Both Solution and Specification
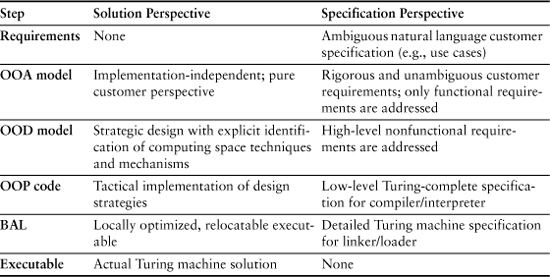
While the OO paradigm formalized several discrete development steps, the OOA and OOD model steps represented an especially important demarcation. The OOA model was envisioned as a pure customer solution—one that could be used unchanged to guide the implementation of a purely manual system in the customer’s environment, however inefficient that solution might be.2 Only when shifting to the OOD model is anything included in the solution that is specific to a software solution.
This separation of computing space from customer space concerns is absolutely essential to translation-based methodologies like MBD. It enables a solution to be created in the OOA model that can be both tested and verified with the customer without worrying about the myriad details related to computers. More importantly, it provides a complete and unambiguous specification for the software that does not constrain the implementation choices for the transformation engine (or subsequent elaboration).
That separation also enables a great deal of skills specialization. If the OOA model is complete and unambiguous, then the transformation engine does not have to understand the semantics of the problem or its context in the customer’s domain. It only needs to understand the semantics of the OOA model notation’s artifacts (i.e., a meta model of the OOA notation). Thus, the transformation engine developer need not be expert in the customer domain and can specialize in computing space issues like caching strategies, network protocols, file systems, and the nuances of implementation language syntax.
Similarly, the application developer constructing the OOA model does not need to be expert in computing paradigms. The application developer simply needs to understand the basic rules for developing OOA models and the semantics of the notation syntax. Thus the application developer can focus on the customer’s domain to ensure that the solution functionality provided is what the customer really wants and needs. To that extent, the developer of an OOA solution is roughly comparable to the systems analyst from structured development.
After appropriate implementation technologies have been selected (target language, infrastructures, libraries, OS, etc.), a transformation engine can be built for that environment3 that will correctly construct an application for any OOA model. Better yet, if the transformation engine developers are clever people, they can provide computing space optimization as well—just like a 3GL compiler can optimize the instructions without knowing the semantics of the specific problem that the 3GL program is solving for the customer.
In the translation community this is known as design reuse because the transformation engine only needs to be developed once for the particular computing environment. That is a little misleading because the design being referenced is that of the transformation engine rather than the application. To the extent that the transformation engine is providing automation of design efforts that an elaboration application developer would have to provide in OOD/P, though, it is accurate. Design reuse is enormously powerful and provides virtually all of the productivity advantages of translation.4
Problem Space
It is fine to talk about separation of problem and computing spaces, but that doesn’t explain what they are.
A key determinant of the problem space is that it is where the customer5 lives. Whoever is defining the requirements has a particular domain in mind when doing so. Whatever functionality the software has is something that a human would have to do in that domain if there was no software.6 That domain is the problem space. Note that a “customer” does not have to be a physical person. For example, the customer can be hardware if you are doing hardware control systems, or it could be another software application if your software is a component in a larger system. In those situations we typically personify the “customer” as if it were a person. In such cases, the problem space becomes the domain where the customer would live if it were a person.
Usually the problem space is clearly outside and unrelated to the computing space where software lives. This is the case in obvious situations like inventory control, point-of-sales (POS) order entry, portfolio management, air traffic control, and whatnot. It is slightly less clear for scientific applications like linear programming packages and weather forecasting systems that tend to be highly algorithmic, since Turing machines were designed to do algorithms.
Things start getting really tricky for R-T/E systems because the only hardware we can access with software has to look very much like a computer. But things really get murky when the software is for the computing space (e.g., a device driver or network router software). Interestingly, the most difficult software to model is that which is driven directly by computing space needs. It becomes difficult to identify an abstract “manual” solution in that domain because the entities we are trying to abstract from the customer domain are already implementation artifacts.
As a clarification, in this book any unqualified reference to customer refers to whoever defines requirements for the overall application and lives in the same domain as the client. That is, it is the business customer when there are several different customers defining requirements for different subject matters. That customer will typically know little or nothing about the computing space, and this is who the OO paradigm aims at when providing the OOA stepping-stone.
Computing Space
Fortunately the computing space is relatively easy to define.
The computing space is the environment where a software solution is implemented.
The operative words are “software” and “implemented”; if those are both relevant, we are in the computing space where software developers (and transformation engine developers!) live. In some situations it may also be the customer space, in which case you may have more difficulty separating their concerns from design implementation concerns.
Essentially, the computing space is where all the tools, strategies, techniques, mechanisms, and processes related to software development and execution are encountered. Typically these include such things as:
• Implementation languages (C, Smalltalk, C++, Java Script)
• Technologies (TCP/IP, EJB,.NET, ESB, XMI)
• Hardware (instruction set, endian)
• Policies (interoperability standards, network protocols, two-phase commit)
• Paradigms (refactoring, coding standards, SOA, porting state via XML/XMI)
• Optimizations (look-ahead caching, stateless objects)
As the list indicates, just about everything that has anything to do with software lives in the computing space. Unless you are developing transformation engines, defining the computing space is only important to defining what OOA models are not about. One of the most difficult things for people new to OOA modeling to believe is that it is possible to develop a solution that doesn’t somehow directly depend upon all this stuff.
There is another aspect of the computing space that is important to MBD and translation though. The computing space tends to be very mathematically based. Everything from basic data structures to dual processor optimization is invariably based upon unambiguous theorems from set theory, graph theory, relational theory, and so forth. This is crucial to translation because it enables the unambiguous specification represented by OOA model artifacts to be mapped deterministically into implementation mechanisms. It also enables optimization.
Transformation
As mentioned earlier, the basic development approach of converting an OOA model into an executable in a particular computing space is known as translation. The mechanical process of converting a particular OOA model into a 3GL or 2GL model is known as transformation. Technically it is possible to do a manual transformation, but that would be traditional elaboration. MBD is geared toward automated transformation by providing the necessary rigor to the OOA models that a code generator needs.
The process of transformation is beyond the scope of this book. However, it is very central to MBD, and many of the things in MBD are done to ensure the completeness, precision, and lack of ambiguity necessary for transformation.
This is not to say that the OOA modeling approach described in this book is not applicable to projects where traditional elaboration is used. The virtues of completeness, precision, and lack of ambiguity are applicable in any software development environment.
MBD must practice these virtues to support translation, but every model-based OO methodology should practice them.
Maintainability
In Chapter 2 the case was made that the primary goal of the OO paradigm is application maintainability in the face of volatile requirements. That discussion made the point that maintainability will be enhanced if the software structure emulates the problem space infrastructure. MBD is very much in tune with this philosophy precisely because the OOA model is the centerpiece of the approach. Throughout the later chapters you will observe a ubiquitous emphasis on problem space abstraction. That, in turn, drives MBD’s emphasis on things like invariants and application partitioning.
Domain Analysis
The traditional view of domain analysis is that it is separate from software development. That is, it is concerned with describing the environment where the software is used rather than the software itself. This view is only partially correct. While true domain analysis often models things that are not of any interest to the software, it also models lots of things that are crucial to the software.
In the OO paradigm’s formative years, OOA was often thought of as an analysis of the customer’s domain that was broader than the software. Consequently, when formal Domain Modeling notations and techniques were developed, they were quite closely based upon the early OO paradigms.7 One way to view an application’s OOA model is that it is a subset of a full domain analysis. Assume that a Domain Model includes processes that are currently done manually and that need to be replaced with software. In that situation the OOA model should look essentially the same as the Domain Model because the OOA model describes the solution in the customer’s terms.
In MBD we believe that developing an understanding of the customer’s environment equivalent to Domain Modeling is essential to good software development. While the approach of MBD is somewhat different than traditional Domain Modeling and MBD goes considerably further in detail, the basic concepts are inextricably linked. So if you have ever done formal Domain Modeling you will recognize a lot of familiar stuff in MBD. Some of the ways Domain Modeling dovetails with MBD are
• Understand the customer environment. This is the primary goal because in MBD we want the software structure to parallel the customer’s infrastructure. To build a good OOA model we must understand the broad context where the software is used. That context is most easily understood by examining an existing Domain Model.
• Understand the customer solution. In MBD we seek to understand how the customer would solve the problem without a computer. While this has benefits in facilitating model validation with the customer, the main goal is to represent customer infrastructure in the software structure.
• Identify invariants. A key goal in design is to identify invariants that apply to a class of problems similar to the one in hand. We then model the invariants, enabling the differences among the problem class members to be described in data. This makes the application more maintainable in the long term and reduces the application size, which enhances reliability. That’s because requirements changes represent a new problem to be solved, one that happens to be closely related to the original problem.
• Elicit, analyze, and specify requirements. Technically, almost all development methodologies, including MBD, cop out and assume software development begins with an existing statement of requirements.8 Unfortunately this utopian situation rarely exists in practice; when getting into the application details the requirements usually turn out to be incomplete, inconsistent, and ambiguous. The problem space focus of MBD enables developers to identify requirements problems, and to resolve them early and easily in Domain Modeling terms that the customer hopefully understands.
• Use cases. Since use cases are really a mechanism for specifying requirements, they are not directly a part of MBD. However, they provide a very convenient organization of Domain Model processes into specific application requirements, so the application developer should be prepared to use them. This is because use cases are ideal for partitioning requirements among subsystems and specifying method behaviors. In fact, MBD not only uses them, it strongly encourages creating them for individual subsystems after application partitioning to clarify how requirements have been allocated to subsystems.
Modeling Invariants
The basic idea behind modeling invariants is actually quite simple: Encode things that are unlikely to change and relegate the volatile details to external parametric data. Intuitively this makes a whole lot of sense, because if the code only contains things that don’t change, it shouldn’t need to be touched very often.9 In addition, data is usually much easier to understand and modify than code, so if most changes can be done in data the developer will be more productive. While invariants are central to the MBD philosophy, we should point out that they really should be central to every software design approach, even non-OO approaches. Since the entire next chapter is devoted to invariants, we won’t go into them further here.
Partitioning the Application
Invariants can be expressed in a lot of different ways. One way that is particularly interesting is the partitioning of applications. MBD places great store in careful partitioning of the application based upon subject matter, level of abstraction, and allocation of requirements through client/service relationships.
But partitioning the application is really a systems design activity, especially for very large applications. The partitions essentially provide a high-level structure for the entire application. Because it is important enough to the application side of MBD discussed in this book, we will provide a chapter to summarize the technique. The key idea to take away here is that application partitioning is the keystone of MDB development; everything else in the application design is built on that foundation.
A Static View
Since MBD is a modeling methodology, it should be no surprise that there are several different types of models employed. These can be broadly categorized as static and dynamic. The static models describe the organization and fixed structure of the application that is always present. This view is summarized in Table 4-2.
Table 4-2. Static Models
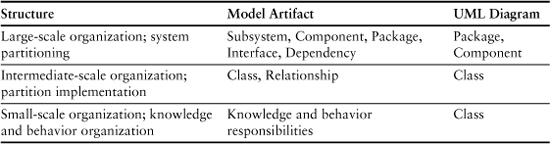
The Package and Component diagrams are syntactically the simplest diagrams in UML. At the same time they are semantically rich, and they may well be the most important for large applications. Essentially, these diagrams describe the overall organization and configuration management (e.g., release contents) of the application.
While the Class diagram identifies what behaviors are needed (methods) and where they are located, the Class diagram is primarily a description of the knowledge (attributes) processed in the application. Associations express intrinsic structural relationships among abstractions, not explicit communications. Taken together these diagrams provide a skeleton upon which the execution dynamics are based.
In OOA/D the static views are the primary place where problem space abstraction is done. The entities and their responsibilities are identified there. One also defines fundamental logical relationships among them that will be the basis for later dynamic collaboration. Those relationships already exist in the problem domain. To put it another way, the static model records problem space abstraction.
A Dynamic View
The dynamic models deal with the execution time view of what the application does. These models describe behavior and communications. They are summarized in Table 4-3. Generally only the first three diagrams—Sequence, Collaboration, and Statechart—are necessary for an OOA model. Use Case diagrams are sometimes explicitly identified to relate specific requirements expressed in use cases to model artifacts when developing larger applications.10
Table 4-3. Mapping of Problem Space Structure to Models
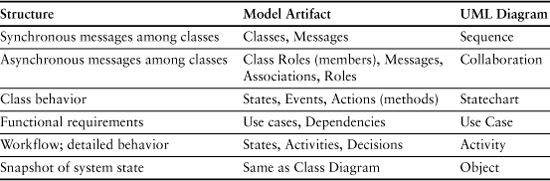
Activity and Object diagrams are not used in MBD because MBD employs an AAL to specify method dynamics. If you recall, an AAL is an abstract text language used to specify behavior within a method or state machine action. The AAL replaces the functions of the Activity and Object diagrams by specifying detailed behavior and instance access.
The Sequence and Collaboration diagrams are used to describe the communications among classes. Finite state machines (Statecharts) are used to describe all behavior in MBD that directly affects or reflects flow of control. MBD also supports subsystem and class methods (synchronous services) to describe behavior, but there are restrictions on what such methods can do. All method and state action processing is described using the AAL.
MBD primarily employs state machines to organize object behaviors. There are three reasons for this. The first is that an asynchronous behavior communication model is the most general way to describe behavior. The second reason is that objects often have multiple behavior responsibilities, and there are often intrinsic constraints in the problem space on the sequencing of those behaviors. State machine transitions provide an excellent way of enforcing such constraints through static structure. The third reason is that the mathematical rules that govern finite state machines are an almost perfect match for enforcing fundamental OO notions like encapsulation, self-containment, logical indivisibility, and decoupling interfaces.
At this point you should have a pretty clear impression that the MBD view of behavior is probably not your father’s view. The MBD view is very disciplined, and it requires the developer to be precise, rigorous, and very clear-headed about what is being described. The benefit of that discipline lies in relatively simple models that are very robust.
In this overview, though, we need to address a couple of popular misconceptions. One is that not everything can be described in state machines. That is quite true. But the exceptions are not directly addressed by the OO paradigm anyway because they are specialized algorithms. For the types of problems addressed in OO development, we can always find a means of expressing the solution essentials in finite state machines. There will be plenty of examples in Part III, but the key insight is to think of a state machine as being a way to express sequencing constraints on operations. Once we have that insight, state machines start to become obvious solutions for a lot of complex problems.
The second misconception is that rigorous approaches like MBD stifle creativity. The problem is that this notion confuses the discovery of the solution with the recording of the solution. The creative act lies in figuring out how to solve the problem in an elegant fashion. That is an intellectual activity quite different from writing down that solution.
Of all the things we do as software developers, the least creative is writing code.
That is true whether we are writing on a plug board, in BAL, in a 3GL, or in a 4GL like UML. Programming, in the sense of writing code, is essentially quite a boring mechanical activity at any of those levels. The creative part lies in figuring out what code should be written.
The reality is that the Turing machine is a highly deterministic and narrowly defined mathematical construct. Alan Turing deserves credit for being very creative in inventing it. But people writing programs in pure Turing constructs only deserve credit for perseverance, not creativity. The closer we get to the Turing machine the more deterministic the choices are and the less creative we need to be to make those choices.
Writing down an OOA model may be a lot more abstract and may enable a lot more wiggle room than writing BAL code, but any creativity advantage is relative at best. It is still a pretty mechanical process: “If I want to express this [brilliant idea], then I can only do it that way.” All we do when moving to higher levels of abstract description above plug boards is reduce the amount of tedious recording, not the tedium of recording itself.
Sure, MBD has methodological rules that must be followed. But those rules exist to ensure that the solution description is complete, precise, and unambiguous. They also represent a minimum set of rules to achieve those goals. Every engineer, regardless of specialty, must work within the framework of design rules, and they are often a whole lot more detailed than those that constrain the typical software developer. The existence of reasonable constraints does not curtail creativity for a software engineer any more that it does for architects, civil engineers, mechanical engineers, or any of the rest.11
In MBD, accuracy of communication is paramount.
The OOA model is a medium of communication. MBD is, indeed, driven by the need to communicate properly with a very literal-minded transformation engine. To that end, the methodology is designed to ensure accuracy in the communication. That accuracy, though, is just as valuable when communicating with other developers.
Typically the models are developed as a team effort on white boards and are only committed to a tool when everyone is agreed. During highly creative sessions, the model is constantly modified. One of the advantages of rigor is that everyone immediately understands exactly the same thing when a change is proposed. The team may debate very creatively about whether the change is correct, appropriate, or even elegant, but they never misunderstand what the change implications are with respect to requirements because there is no ambiguity. This is an extremely valuable side effect of rigor.