
Chapter 13. Identifying Knowledge
Knowledge is of but two kinds. We know a subject ourselves, or we know where we can find information upon it.
—Samuel Johnson, letter to James MacPherson
Most knowledge attributes are fairly easy to identify because they describe physical properties of inanimate objects in the problem space. Thus notions like color, length, and part number are easily recognized and abstracted as attributes. The next tier of attributes contains mildly conceptual but commonly used aggregates, such as address, a combination of street, city, and state; name, a combination of given and family names for a person; and location, a set of coordinates. Since they are commonly used in the problem space, they are also usually easy to identify, as in the examples.
The third tier of attributes represents a high degree of abstraction of the problem space. Because of the subtlety involved, these tend to be the most challenging for novice OO developers. One convenient way to classify these sorts of knowledge properties is the following:
• Aggregates of data that we abstract as scalar ADTs in a particular subsystem whose level of abstraction is relatively high. The trick here is to recognize that the level of abstraction of the subsystem in hand does not care about certain details. We tailor the knowledge abstraction to the abstraction of the subsystem.
• A choice from among several possible abstract views of the knowledge. This involves tailoring the subsystem’s objects to the subject matter of the subsystem. In other words, we need to find the right abstraction for the problem in hand.
• The direct result of anthropomorphization where we may have a choice about which problem space entity “owns” the knowledge. These are situations when we must allocate to inanimate problem space entities the control responsibilities that a person would normally do. Similarly, there may be knowledge needed to support those control responsibilities that a person would normally know, so we have a choice about which inanimate object it is allocated to.
The goal in this chapter is to describe some practical techniques for uncovering knowledge attributes in the third tier. But first we need to review the proper mindset for uncovering knowledge attributes.
What Is the Nature of OO Knowledge?
Knowledge is not data—it is a responsibility for knowing something.
We abstract objects in terms of intrinsic responsibilities, which means we do not care how the object knows what it does; we are concerned only with what it should know. It cannot be overemphasized how important this distinction is to OOA/D. If we think purely in terms of responsibility, then we will have little difficulty with encapsulation.
The notion of data is highly overloaded in the computing space, and most of that overloading is related to how information is stored on a computer platform. Since we are dealing with OOA models in translation, we are only concerned with the customer’s view of the information, not the computer’s. Therefore, it is important to think of knowledge properties in a rather generic way, one that is independent of implementation details. In OOA/D, knowledge properties are always abstracted from the computing space through ADTs. So try to forget everything you have ever seen in 3GLs, including the OOPLs.
In Part III, when we talk about dynamics, we will see that in many situations knowledge and behavior are interchangeable, kind of like a physicist’s view of mass and energy. Thus we often have a choice about whether an object needs to know something or do something to solve the problem in hand. Making that choice is about interpreting and abstracting the problem space, not the traditional computing space view of algorithms + data = programs.
OO knowledge is intrinsic.
Another important mindset issue lies in the fact that object responsibilities are intrinsic. A knowledge responsibility describes what an object knows about itself. In Figure 13-1(a), events is an intrinsic property of EventQueue even though it counts objects outside of itself. That’s because EventQueue’s fundamental mission in life is to manage Events, so it is a reasonable intrinsic responsibility for knowing how many Events it is managing at any given time.
Figure 13-1. Examples of good and bad allocation of object properties
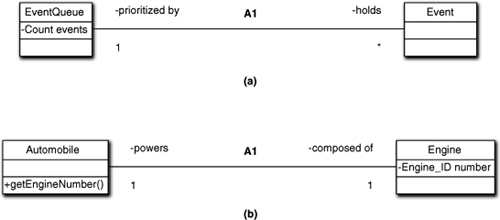
Unfortunately, an all-too-common side effect of careless delegation is that an object knows things it shouldn’t about the object to which it delegated responsibilities. That is reflected in Figure 13-1(b) where a client needing the serial number of an Automobile’s engine would query Automobile for it rather than navigating to Engine to get it directly. As indicated in the last chapter, once the Engine has been extracted from Automobile to capture unique, delegated properties, those properties are no longer Automobile’s. Therefore, Automobile has no business knowing anything about them; it becomes an anonymous waypoint along the navigation path of collaborations between clients and Engine.
Fortunately, this sort of problem is very easy to recognize in MBD when writing abstract action language. There are no 3GL-like getters when accessing knowledge,1 so for a client to access the engine number from Automobile there would have to be an engineNumber attribute in Automobile, which would fail reviewer checks for normal form in the Class diagram (i.e., engineNumber would be an attribute of two objects from different classes with exactly the same semantics, value, and identity dependence).
Abstracting Aggregates
Because levels of abstraction differ among the application’s subsystems, we need to push the notion of ADTs even further. We need to abstract the knowledge responsibilities to be consistent with the subsystem’s level of abstraction. As mentioned in Chapter 2, it is not uncommon for a scalar ADT attribute in one subsystem to map into an entire class, multiple classes, or even an entire subsystem when viewed at a lower level of abstraction. The tricky part is recognizing the high-level ADT abstraction in the subsystems at a higher level of abstraction. Unfortunately, our compulsions over the data view in the computing space encourage us to think in terms of aggregates of data rather than abstractions of information. These issues become apparent in Figure 13-2.
Figure 13-2. Model of pattern-based digital testing. Stimuli are applied to tester pins sequenced in time by patterns (time slices).
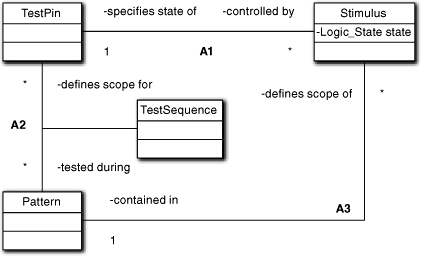
Figure 13-2 represents a view of the way digital hardware is tested when using a pattern-based tester. During each time slice, each tester pin is driven by a particular stimulus that is essentially a logic state (0 or 1) for the pin. (The set of stimuli and responses within a time slice is known as a pattern.) The stimuli in the time slices need to be sequenced in a particular order for a given test because the unit under test has internal state that is accumulated over many time slices. (The view in Figure 13-2 is actually greatly simplified; the real model involves nearly two dozen classes with a lot of unique data elements.) Now consider the architectural context of the full device driver for a digital test system, as shown in Figure 13-3.
Figure 13-3. Subsystem context for a tester of digital electronics
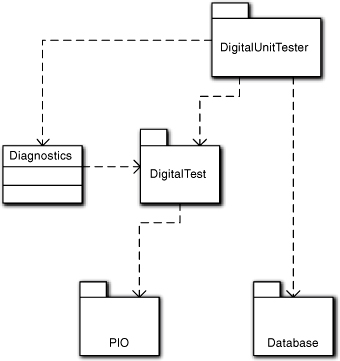
(Again, this view of the application partitioning is vastly oversimplified; the actual device driver has roughly thirty subsystems.) In this, the DigitalTest subsystem has the model illustrated in Figure 13-2 because it needs to talk to the hardware via the PIO subsystem one pin and one time slice at a time. (Its mission is to load the stimuli into the tester’s hardware memory.) But what is the view of a digital test in the Digital Unit Tester subsystem?
In that subsystem we were interested in the overall control of the tester that coordinates things like selecting tests, executing them, and invoking diagnostics if the test fails. At that level of abstraction a digital test is monolithic (e.g., “run test 52C”). It might well be abstracted as a single Digital Test class that was a dumb data holder with the attributes name and testData. All the complexity of Figure 13-2 would be completely hidden by the testData ADT because at that level of abstraction there is no interest in the individual data elements within a digital test.2
Look for ways to deal with knowledge at its highest level of abstraction.
It is very important to be aware of the need to abstract knowledge when dealing with subsystems at a high level of abstraction. One way to do this is to put a mental boundary around data aggregates and determine (a) if there is some problem space abstraction that maps to that boundary, and (b) whether the current subsystem cares about any specific elements within that boundary. In fact, it is usually a good idea to look for ways in which the subsystem in hand can do its job without the specific elements in the aggregate, even when initially it seems intuitive that it does care about individual elements. For example, it might seem intuitive to manipulate the patterns as classes while hiding their individual stimuli in an ADT because at a high level, pattern-based digital testers manipulate patterns. In other words, patterns are a fundamental structural element of the tester, which is why we describe the class of testers as pattern-based. Nonetheless, within a particular subsystem in the application we can still extract an even more generic concept in the form of testData where even individual patterns are hidden.
If this advice seems vaguely familiar, it should. What is being advocated here is basically identifying knowledge invariants in the problem space by raising the level of abstraction. This is one reason why this chapter’s leading quote is apropos. We need to separate the information we must have at hand from the information that is available elsewhere. As usual, the ultimate source of wisdom is the problem space itself. The point here is that we need to use abstraction and extract invariants from the problem space for knowledge attributes, just as we do for classes and behavior responsibilities.
When modeling a college that used pass/fail grading for freshman and letter grading for other years, we might be tempted to define an isFreshman attribute that determines how the value in gradeValue is interpreted, as in Figure 13-4. This is not a good way to define the Grade attributes for several reasons, but the one of concern here is that the value of isFreshman is not an intrinsic property of Grade.
Figure 13-4. A bad way to deal with pass/fail grading for freshmen
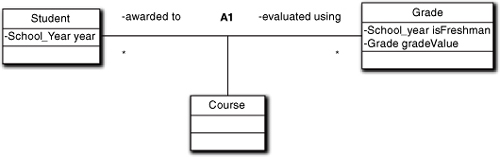
In reality, the isFreshman value depends on the value of the Student’s year. We can get into this sort of problem by thinking in terms of data, such as viewing gradeValue as consecutive integer codes, where 0 cleverly represents both fail in pass/fail and F in letter grading while 1 represents pass in pass/fail and D in letter grading. We are then faced with the problem of interpreting the value of 1 correctly,3 so we introduce the kludge of isFreshman because that will be easier than going to Student to determine the year.
Pop quiz: Which of the following solutions is better when eliminating isFreshman?
A. Subclass Grade into FreshmanGrade and UpperClassmanGrade, where each subclass provides a different semantics for gradeValue.
B. Enumerate the data domain of gradeValue as {A, B, C, D, F, Pass, Fail}.
C. Use the existing codes, but let the client navigate to Student to determine how they should be interpreted.
D. Any of the above.
E. None of the above.
Technically the answer is (D) because the “best” solution depends upon exactly what the problem in hand is, and we could probably find a scenario where any of them could be viable.4 The corollary is that there will be situations where one or more of them will be at least inconvenient. And if the application is complex, there may be multiple contexts for accessing gradeValue where there is a different “best” solution for each context. Making those sorts of decisions when tailoring to the problem in hand is why OO developers get the Big Bucks.
It is probably worthwhile to discuss what the relative disadvantages of these solutions are. In the subclassing case, A, the client will have to know what subclass it is accessing. We can’t define gradeValue in the superclass because each subclass now has different semantics for it (as opposed to a different implementation of the same semantics). This means the client will have to navigate a direct association to the correct subclass, and we will have to make sure that is properly instantiated. Usually that will only be an optimal solution if different clients exclusively access either freshman grades or upperclassmen grades.
Using the existing codes, C is going to be wrong in almost any conceivable situation. To see this, think about the implicit assumption in the example that the year the Student is in determines whether pass/fail is appropriate. What if the school decides to give pass/fail grades based on just standard Freshman courses and a freshman decides to take an advanced course; does the freshman get a letter grade? Now the interpretation of the grade depends upon the Student being a freshman and the course is a standard Freshman course. Surgery will be required on the client to obtain that extra information and process it properly. But that is likely to be completely unrelated to what the client is supposed to be doing with the grades once they are properly interpreted.
The basic problem is that the client must understand how the grade is assigned and that is probably none of the client’s business. The only conceivable situation where this could be viable is if the only client is Student, who should already know what year it is in, and it was a one-shot application where we did not have to worry about the way grades were assigned being changed.5
That leaves us with reorganizing the data domain of gradeValue, B. This will almost always be a viable solution. For example, we can view the deficiencies of (C) as symptomatic of the overloading of code value semantics. With the indicated data domain, that overloading problem goes away, and the client is no longer concerned with how the grade is assigned; it just deals with the value as is. In Normal Form terms we are defining a simple data domain that includes all possible grade values. The downside of this is that the clients all have to deal with the entire data domain. That is, they must be prepared to deal appropriately with a Pass value as well as a B value.
But before leaving the pop quiz, note that (B) essentially combined isFreshman and gradeValue into a single ADT because the client no longer needs to access isFreshman. We will still need isFreshman in Student because somebody needs to assign the grade, and to do that they will have to access the right decision variables. But once the ADT value is assigned, any client can access that knowledge without knowing anything about Student.
That is an interesting bit of legerdemain since all we did was redefine code values so that the {0, 1} data was no longer ambiguous. In fact, the semantics of gradeValue was always {pass, fail, A, B, C, D, F} in the problem space! So in that sense the entire example and the pop quiz was a red herring. The real problem here is the mapping of abstract ADT values to numeric data values, which is the transformation engine’s problem rather than the application developer’s problem.
The main point in wandering this garden path was to underscore the point made earlier that knowledge responsibilities are defined in the problem space rather than the computing space. In the problem space there are seven flavors of the notion of a course grade. We can abstract those as enumerated symbols that are unique. Thus fail is not an F and pass is not a funny sort of D. Each is a uniquely identifiable grade in the problem space.
However, there is an even more important moral to highlight. The responsibility is for the Grade object to know the value of the grade. More important, it is only to know that value. The responsibility is not about how the grade value is determined or what we want to do with the value once it has been provided. Therefore, if we had not gotten side tracked by the circumstances of assigning a grade, how it is implemented, or what it is used for, we probably would have gotten directly to (B) without even thinking about it.
In part the side tracks were encouraged by referring to data domain in the example, which kept the {0, 1} view within sight.
Attribute ADTs have an associated value domain. The most useful ADTs have purely symbolic values from the problem space.
It is often useful to think about attribute ADTs as values rather than data because of the numeric baggage that the notion of data carries in the computing space. If a HouseBoat has price attribute, the value of that attribute is very likely to be highly numeric. That’s fine, because in the problem space it is a nice scalar number in most situations, but is also not exactly taxing on our creative talents.
In the OO paradigm we must abstract every problem space entity in terms of just two kinds of responsibilities: knowledge and behavior. That can get challenging when the qualities are inherently abstract. It also gets challenging when we need to generalize complex qualities as indivisible invariants. In both decision theory and economics there are very similar notions of utility, which represents a single abstract value of something that is not directly quantifiable or is an aggregate of other values. We need to get used to the similar idea that an ADT is a scalar value that can represent arbitrary complexity. Quite often we will need to think of that “value” symbolically.
Picking the Right Abstraction
While knowledge is an intrinsic responsibility, we abstract it with the overall problem context in mind.
So far we have aggregated the isFreshman and gradeValue knowledge attributes into a single gradeValue ADT. Whether we were driven to that change by an aversion to value overloading, a perceived violation of 1st Normal Form, the dependence of isFreshman on year, a fear of added complexity in client behaviors, or simply having our aesthetic sensibilities offended really doesn’t matter. The new abstraction will be a better one in most situations by many standards. We did that by changing the semantics of individual valid values of gradeValue. Instead of thinking of {pass, fail} as equivalent to or alternatives for {A, B, C, D, F}, we thought of {pass, fail} as additional unique and independent values of grade.
That change reflects a tailoring of the abstraction to the problem in hand. In other words, we changed the way we view the notion of “a grade” at a fundamental level for this problem solution by eliminating any ambiguity in interpreting the gradeValue in the problem context. In doing so, we created a single ADT whose scalar “value” is unambiguous for all clients in the problem context.
Knowledge abstractions rarely exist in a vacuum.
We also relegated any concerns the problem space might have about equivalence to whoever actually does the assignment of a grade. Encapsulating the rules and policies of processing a grade is a quite separate issue from defining our gradeValue semantics, but those decisions in the overall solution need to play together. When selecting that definition we needed some vision of how we planned to assign grades and how we planned to use them in the solution to the problem in hand.
As a practical matter for an example as simple as this one, we probably wouldn’t think a great deal about that solution vision. That’s because good OO practices like separation of concerns, decoupling, and whatnot would conspire to have us think in terms of assigning values and using values as different activities. Perhaps more important, limiting the responsibility to simply knowing the current value of the grade would lead us to viewing the values as distinct. So, to an experienced OO developer, (B) in the pop quiz would seem the most natural without worrying a great deal about how the values were assigned or used.
The change is a rather subtle one, but subtlety is what good abstraction is all about. Alas, there aren’t a lot of cookbook techniques for doing that. It is primarily a matter of having the right mindset, which requires judgment and experience. The two key aspects of that mindset, though, are problem space abstraction (as opposed to data descriptions) and focusing on what is needed to solve the problem in hand.
One technique for doing that is to extract invariants from the problem space. When talking about invariants in Chapter 5, an example for doing depreciation was used. If you review that example you will see that the tailoring of the abstraction was primarily about the way we represent knowledge. In fact, the abstraction substituted a data structure for an algorithm. The key insight was recognizing that the formula could be broken up into two steps with an intermediate data structure. From the application solution’s perspective, several executable formulas were replaced by a single, simpler formula and a data structure for knowing the period fractions.
In fact, one way to describe parametric polymorphism is that it is about extracting generic, invariant behaviors such that the detailed behaviors are handled through knowledge abstractions, thus we substitute knowledge responsibilities for detailed behavior responsibilities. That fundamentally changes the way we solve the problem in hand. So when we substitute a new semantic to combine isFreshman and gradeValue, we also change the way that clients will use the information to solve the problem.
That’s one important reason why we abstract objects and their responsibilities before we worry about the dynamics of behaviors and connecting the behavior dots for the overall problem solution. When we define knowledge ADTs we are also defining the skeleton on which the overall solution will depend. Therefore, it is very important to come up with the best knowledge ADT for the problem in hand.
Abstracting What People Do
As we discussed in Chapter 2, when we abstract inanimate entities we tend to imbue them with control behaviors that people would normally provide in a manual solution. This is important because it actually enables us a lot of flexibility in allocating responsibilities. Thus the same inanimate entities abstracted in two different applications may not have responsibilities allocated in the same ways or even to the same objects. This doesn’t violate the notion of abstracting intrinsic properties. It simply reflects that anthropomorphized behaviors only become intrinsic when they are assigned to the inanimate entity in the problem context. Technically that assignment is an interpretation of the problem itself.
Since some knowledge responsibilities track the needs of behaviors, their assignment to inanimate objects is also flexible, albeit a lot less so than behaviors. Anthropomorphized knowledge tends to be relatively rare, and we will have a lot more to say about anthropomorphizing in Part III, The Dynamic Model. Here we are concerned with knowledge that is usually discovered in an iterative fashion when allocating behavior responsibilities. For example, we tend to associate a knowledge attribute for elementCount whenever we deal with stack behavior. We may abstract a Stack object and it will go there. However, providing a stack might be necessary to implementing a behavior in an object abstracted for other reasons. The stack then becomes part of that object’s implementation and elementCount will follow it.
As mentioned earlier in the chapter, the easiest knowledge properties to identify are those that really are intrinsic to inanimate objects (e.g., size, color, etc.). So it may be useful to make an initial pass at identifying such attributes as a “warm up” when forming a Class diagram; then we can attack the needs of the behaviors assigned to objects. It is important to note, though, that knowledge and behavior need to play together properly when dealing with anthropomorphization. The flexibility in assigning properties carries with it the need to make sure the assignments make the most sense for the problem in hand.
When in doubt make anthropomorphic assignments that seem most natural for the problem.
For example, suppose we have classes for Automobile and Bill Of Sale with a 1:1 relationship between them. Now we need to assign an attribute for exciseTax. Which object should own it? Most likely it goes with Bill Of Sale because generating a sale is when a excise tax becomes relevant. But what if this application is primarily about pricing the automobile and the Bill Of Sale is just a form that gets printed out once a deal is agreed? Then the information the dealer and customer are negotiating over is mainly associated with the Automobile. We might find it convenient to make the semantics be the actual money amount, rather than the tax percentage, and the computation—which a person would have to do if the software application didn’t exist—of the amount might be assigned to Automobile. In that context it might make sense to put exciseTax in Automobile and let Bill Of Sale simply be a specification object for formatting the printing of data from Automobile and other relevant objects.6
The remainder of this chapter is devoted to a set of questions with answers you may find useful when trying to discover the knowledge attributes. The questions are an indirect reflection of the mindset issues we’ve been talking about.
What Does the Underlying Entity Know?
This is clearly the key question. The criteria for determining this is found in the context of the problem itself. We abstract only those properties we need to solve the problem in hand. So the question can be rephrased as: What does the underlying entity need to know to solve this problem? In practice we can further subdivide this by noting that there are things the entity itself needs to know to satisfy its own behavioral responsibilities, and there are things that the entity needs to know so that other entities can satisfy their behavior responsibilities.
Note that the only reason we need knowledge attributes at all is so that behaviors can do their thing properly. Knowledge attributes are state variables that preserve the application’s state between the executions of behaviors, and that state can only change if a behavior does something to change the application state. Conversely, all MBD behaviors are essentially operations that do at least one of three things: modify the state of the solution (i.e., change states in a state machine), modify a state variable, or send a message. If the behavior does none of these things, then there would be no point in executing it because it would have no effect on the final solution results. Thus knowledge attributes are intimately related to the behavior responsibilities necessary to solve the problem in hand. So we have an alternative phrasing of the question:
What do the problem solution’s behaviors need to know from this entity?
As a practical matter we usually provide an initial cut at the knowledge properties in the Class diagram before defining the specific behaviors (i.e., in MBD we define behaviors with Statecharts after the Class diagram is done). The point in the preceding paragraph is simply that we don’t create the Class diagram in a vacuum. We always have some general notion of the behaviors necessary to solve the problem7 even when creating the static models like a Class diagram. Therefore we need to consider the broad behavioral context when abstracting the knowledge responsibilities.
Many knowledge attributes are pretty obvious and can be extracted quickly from the problem space. After these are recorded, it is usually a good idea to make a pass over the Class diagram, one class at a time, to seek out those attributes that are less obvious after the behavior responsibilities are identified. For each class, determine what information would probably be needed to execute those responsibilities properly. Finally, decide what classes should logically provide any knowledge not captured so far.
What Subset of Entity Knowledge Should the Object Abstraction Know?
The goal here is to keep focused on the problem in hand. Typical entities in customer problem spaces are quite complex and can be viewed in many different ways. To manage that complexity we must be careful to select only a subset of the entity’s properties that are of interest to the problem in hand. Because of the way we partition applications, we are really only interested in a part of the customer’s overall problem—that which is related to the subsystem subject matter in hand. Each subsystem is an encapsulation of a view of a particular problem space, and we need to select for abstraction only the properties that are relevant to that view.
What Is the Subject Matter?
Subject matter is the key issue when deciding what knowledge properties to abstract. The subject matter will severely limit our view of the entity and what we need from it. This becomes most obvious when we “tailor” the subject matter by extracting invariants. Typically such invariants will greatly simplify our view by raising the level of abstraction and that will further limit what properties are of interest.
For example, dredging up our banking example, in a subsystem dealing with the business rules and policies of banking we need to know certain things about a Customer Account to deal with various transactions, such as the current balance and the overdraft limit. In that context, these are simple, independent state variables that will be expressed as knowledge attributes. In a GUI subsystem that presents them to a teller, they will be represented as Text Box instances with a large number of individual attributes, only one of which is the actual value. In an ATM controller, the balance will be necessary, but it will probably not be an attribute. Instead, it will simply be pass-through data in message data packets between the network port and the display device.8 Things like the overdraft limit will not appear at all in ATM controllers because that only affects whether a withdrawal can be made, which is the Bank’s decision. Thus the balance appears in all three subsystems but it is an attribute in only two, while the overdraft limit appears in two subsystems as an attribute but doesn’t appear in the third at all. It is worthwhile going through the reasoning behind these different treatments.
If it isn’t in the requirements, you probably don’t need it.
That is the situation for the overdraft limit in the ATM subsystem. The requirements for the subsystem will include what is displayed to the customer, what information the customer supplies, and what information the bank supplies. In today’s ATMs, none of those inputs include the overdraft limit. As a sanity check we consider what the ATM does and, by implication, what it doesn’t do. There is nothing in the subsystem requirements or the subject matter mission that deals with banking rules and policies for validating customer transactions, which is the only reason we would need the overdraft limit. In fact, those rules and policies are explicitly delegated to the banking subsystem on the other side of the network port. So the overdraft limit has no semantic value to the problem the ATM controller software is solving, and we can ignore it by not abstracting from the problem space.
Be suspicious of any knowledge attribute that seems to only support rules and policies specifically allocated to another subject matter.
This guideline is hardly etched in steel tablets because we know that different functionality (reflected in different subject matters) can operate on the same data. However, in the case of something like overdraft limit, it is pretty clear that the property is carnally connected to the rules and policies of transaction validation. That’s because the notion of overdraft really only exists in terms of banking policies.
Why is balance an attribute in a GUI subsystem supporting tellers but not in the ATM subsystem given that it exists in both as a display element? Good question, Grasshopper. There are two reasons that it is an attribute in the GUI subsystem. First, the notion of Customer Account is captured there, albeit decomposed into Window and Control abstractions. There is an explicit tie to entity identity via the Window instance identity and the relationships to Controls. In addition, the Controls provide similar identity mapping for balance versus overdraft limit. When the teller views the screen there will be no confusion about the fact that the teller is viewing a Customer Account with its Balance and Overdraft properties. While the GUI paradigm provides a very different view of the entity, the GUI subsystem still exists to display the banking subsystem’s entities.
While that makes it likely that any entity property in the banking subsystem will be a property if present in the GUI subsystem, it doesn’t mean that all entity properties from the banking subsystem need to be displayed. That will be determined by the requirements for the GUI subsystem (i.e., the GUI designer’s specification), and if display is not required, the properties would not be abstracted in the GUI subsystem.
The second reason is that the value has to be persisted between GUI operations. The GUI has its own suite of responsibilities so that it can do lots of housekeeping while the values remain displayed. In addition, windows may be hidden from view or even closed temporarily while the GUI still keeps track of the data for later display. Thus the values must persist across GUI behaviors. This segues to why the balance value is present in the ATM subsystem but isn’t a property of any classes implementing that subsystem.
Knowledge that persists across fundamental subject matter operations must be preserved in state variables.
The corollary is that if the knowledge does not persist across behavior executions within the subject matter, it may not need to be a class attribute, which is the case for balance in the ATM subsystem. The value is provided as external data that is decoded from one message data packet (from the network port) and encoded into another message data packet (to the display device) within a single behavior scope. It is purely transient within the ATM subsystem.9
Note that an acid test for this sort of situation is that the value is not associated with any entity that the ATM needs to abstract. Since the ATM controller subject matter has no intrinsic responsibilities that would need to abstract a Customer Account, this test passes. An interesting question arises, though, if we find that we must save the value of balance across multiple behaviors within the ATM controller. Then we must save the value as an attribute, but where? The answer is to make it an attribute of an object that abstracts the notion of a message or transaction, rather than the Customer Account.10 Given our description of the subject matter as a message processor, we can very likely map any persistence into a Message or Transaction object because the scope of persistence is very likely not to extend beyond a transaction’s scope.
This brings up an interesting point about abstraction. Let’s say we abstract a Balance Request subclass of Transaction with a value attribute that holds the balance in the context of a user’s request for a current balance. A Balance Request is not a Customer Account, yet we know that its attribute and the Customer Account’s balance attribute have exactly the same state variable value. Isn’t something wrong with that picture? More specifically, isn’t there a Normal Form violation somewhere?
The answer is no, because we have two entirely different subject matters on either side of the interface that model different problem spaces. Our ATM controller exists to re-dispatch messages between a network port, a user, and some hardware. In that subject matter domain, it is quite reasonable to abstract an entity like Balance Request that has a balance attribute. That entity is quite real, albeit conceptual, in the controller context. The semantics of the balance attribute is not that of an account balance; rather, it is simply a value that is, at most, constrained by some generic limits on size and whether it is integer or real. It could just as easily be the amount the user is requesting for a withdrawal.
To see this more clearly, suppose that instead we had abstracted Network Message rather than a subclass of Transaction. It would have a generic value attribute that could be a balance, a withdrawal amount, or a deposit amount. But that semantics would only come into play when we encode/decode the data packet using the message identifier to determine which hardware driver is relevant. In that context, the message identifier is driving the processing, not the banking semantics of the value. The value is processed differently depending upon which device driver receives it, and all those device drivers care about is the numeric value itself.
Using the Balance Request abstraction may be more convenient for the problem in hand because we already abstracted Transaction. We will also name objects to provide a mapping to the underlying problem space. But we should not infer any particular semantics for the knowledge attribute that has Account semantics. In other words, the balance is just the value associated with a Balance Request in the ATM controller context. The fact that it is owned by something we call a Balance Request just provides us with a modicum of traceability when it is time to map that request into the banking software on the other side of the network port.
Those problem spaces coexist to the extent that the value attribute of Network Message will contain the same value as the balance attribute of Customer Account in a particular request context. Nonetheless, they are different problem spaces that can be abstracted independently. We, as omniscient developers, know how to map between those problem spaces. We can do so because we understand the context where the Network Message value attribute contains a Customer Account balance value and the context when it contains, say, the amount of a withdrawal request. We then provide software constructs to enforce the relevant mapping rules of those contexts across the subsystem boundary to ensure that the software works correctly in all cases. (Actually, the constructs come pretty much “for free” when we parse the message identifier.)
There are two points in this digression with the Network Message example. The first is to reemphasize that we must focus on the subject matter itself when abstracting knowledge attributes. The semantics of the value attribute of Network Message is not that of an account balance in that subject matter, even though we might specifically have a user request for current balance in mind when deciding we needed a Network Message object with a particular identifier. (The same is true for the Balance Request abstraction; the mapping lies in the Transaction identity.) The second point is that subject matters are often unique problem spaces that need to be abstracted independently even though there necessarily exist mappings between them.
The services a subsystem provides are dictated by external problem contexts, but the abstractions that implement the subsystem are dictated by only the subject matter, its problem space, and its level of abstraction.
So when evaluating what knowledge responsibilities are needed, be alert to shifts in the level of abstraction and the nature of the problem space being modeled. Try to avoid abstracting to the overall problem context.
What Is the Level of Abstraction?
The value attribute in the Network Message above is a good example of how the level of abstraction affects the way we abstract knowledge responsibilities. The Network Message entity is, itself, quite abstract because it represents a different problem space where we do not care about the semantics of the message content. As was indicated, this results in a very generic view of the value that only depends upon its properties as a data element. That is, in two different messages or transactions the semantics of the attribute could be quite different (e.g., account balance versus withdrawal amount), but the handling of the value will be pretty much the same (i.e., it will be forwarded to a hardware device driver as an integer or real number with specific maximum range and precision). Thus we need additional information, such as a message identifier or transaction type, to keep track of and map the semantics across subsystem boundaries.
When in doubt, provide the most abstract view of knowledge that the problem in hand will allow.
In other words, we describe knowledge responsibilities with ADTs, so we should use them as fully as possible. Here the problem in hand is what is being solved by the subsystem, not the overall problem the application exists to solve. In solving the subject matter’s problem, we seek every opportunity to extract solution invariants from the problem space. Invariants are always represented at a higher level of abstraction than particular solutions. However, it is not sufficient to simply recognize that all network messages look pretty much the same in a given context like an ATM controller (e.g., {message ID, <data packet>}). We also have to make sure that the way we abstract the entity’s properties is consistent with that abstract view. If we follow the above guideline we will reinforce any invariants we have identified. More important, we will often uncover better entity abstractions, improve our solution collaborations, and even discover invariants from the bottom up when applying this guideline.
The other side of this abstraction coin is that we should let the level of abstraction of the subsystem itself drive the way we abstract knowledge responsibilities in the same way that it drives identifying entities. In the ATM controller subsystem we have defined the mission in terms of encoding and decoding messages and dispatching them. In addition, we pointedly omitted requirements related to banking rules and policies for things like validating accounts, approving withdrawals, and so forth. Thus the ATM controller’s subject matter is very focused.
This subject matter has very detailed requirements concerning sequences of hardware operations, network protocols, and mapping messages to hardware components. In addition, in the overall banking system’s structure it is a pretty low level service, equivalent to a UI. Nonetheless, it is actually quite abstract compared to the banking services subsystem as far as the semantics of banking is concerned.11 The ATM controller subsystem has recast the banking semantics into message processing in a very mechanical but quite general way. So, when we define knowledge responsibilities we have to do so within the context of the way the subject matter abstracts things.
Even though our ATM controller is part of a banking system, we do not want to think in terms of business details like balances and withdrawal amounts. We will map to those concepts through the subsystem interface that defines the messages we process and through the way we encode/decode message data packets. But within the subsystem the entities and their knowledge are abstracted without that semantics. One of the most common ways to bleed cohesion across subsystems is to abstract a subsystem in terms of the overall business paradigm rather than just the nature of the subject matter in hand.
Does the Abstraction Need to Coalesce Entity Knowledge?
A lot of authors view the primary value of describing knowledge attributes with ADTs as strong typing; that is, it prevents Skyscraper objects from showing up in the midst of our Pristine Landscape. This is certainly valuable during OOP where the OOPLs employ type systems. However, at the OOA/D level it is really secondary to the ability to represent and manipulate complex data structures as scalar knowledge values. This ability is crucial to the flexible view of logical indivisibility that enables OO applications to avoid hierarchical implementation dependencies.
Look for opportunities to abstract data aggregates as scalar ADTs.
We’ve already talked about the way a simple attribute ADT in one subsystem can be expanded into complex structures involving multiple classes or even entire subsystems, so we won’t repeat that here. However, we will emphasize that the developer needs to proactively look for opportunities to “hide” aggregates as ADTs.
At first blush, the obvious way to do this would seem to involve looking for aggregates (e.g., lists, arrays, etc.) where other objects in the subsystem do not need to access individual members of the aggregate. Alas, if you just do this you will find there are few opportunities to abstract such aggregates into scalar ADTs, because the elements usually show up in an Object Blitz and we tend to express aggregates of them through 1:* and *:* relationships to other objects. So by the time we are looking for specific knowledge properties, we tend not to have obvious arrays and lists around.
More to the point, the elements show up as objects in the Object Blitz because we think we need them individually to solve the problem. By the nature of an Object Blitz, that is usually pretty well-founded, so it will be unusual to be able to eliminate both the element class and the * relationship. Nonetheless, blitzes aren’t infallible so it is definitely worth a pass over the model to check for the possibility. The question to ask about any * relationship is: At this subsystem’s level of abstraction, do we need to access objects of the *-side class individually?
So we need to look for aggregates in other ways. By far the most common is lumping together dissimilar but related attributes that we have already identified. A classic example is grouping {street, city, state, postal code} attributes into an Address ADT when it turns out the subject matter doesn’t care about the individual elements. In a case like this it is usually pretty obvious, and before we have finished enumerating the individual attributes someone on the team will usually push back on why they are needed.
Therefore, we should keep an eye out for attributes that we initially think are needed individually but where we can raise the level of abstraction so that they aren’t needed. In Figure 13-5 we have a very simplistic view of artifacts in a fantasy computer game. The Skeletal Model and Segments are one way of representing movement of the artifact at a scale that is computationally feasible. The game artifact, the Ogre, is subdivided into connected elements, Segments, that can be moved individually to provide articulation. To make things easy, we have included only the knowledge attributes of Segment for this discussion, and the obvious question is: How can we abstract some or all of those attributes into a single scalar ADT?
Figure 13-5. Simplistic model of a computer game
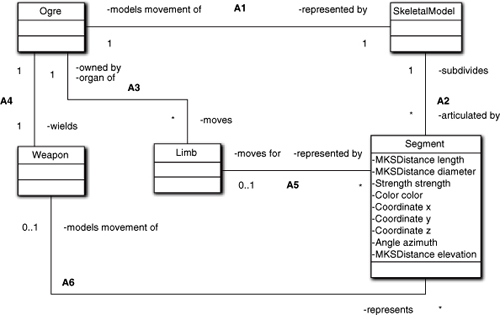
First, think about why we are modeling this. That is, what is the subject matter? Let’s assume this is a high-level subsystem that exists to manage the game semantics. It enforces the rules of the game itself, such as Ogres always attack Heroes. It deals with the game actions at the level of the Ogre attacking a Hero and swinging a sword at the Hero’s head. Those “high-level” movements are then relayed to some graphics rendering subsystem that does magical algorithmic things to create a smoothly flowing display. Given that context, how do we abstract the knowledge attributes of Segment?
One fairly obvious notion is position. We have five attributes that supply a very detailed view of where a particular limb element is at any time. Do we really care about that when thinking about swinging a sword at the Hero’s head? Not really. We will care a lot about it in a very low-level service subsystem that contains all sorts of exotic graphics algorithms for display rendering, and we will care a lot about those details in a lower-level subsystem that deals with the physics of motion, collisions, and whatnot. But we probably don’t care much about the specific location of the Ogre’s forearm in the game logic subsystem.
What about the other attributes? It might be tempting to abstract these into something like segmentData, or we might make a case for length and diameter being abstracted as geometry. There wasn’t enough information provided about the game semantics yet to make that call. For example, suppose the Hero always attacks the longest limb or targets an injury (low strength) first. Then we would need the length and/or strength attributes explicitly to target things like sword swings. But if we only needed strength, then geometry would probably be a good abstraction.
But to keep things simple, let’s suppose we don’t need any of the attributes. Now segmentData is looking pretty good. Could we also include position in that as well? Maybe. This depends on who the game artifact interacts with. It was already suggested that there are likely to be multiple supporting subsystems. Clearly geometry, position, and color are things the display rendering subsystem would need to know. But a subsystem that just computes movement trajectories for things like swinging a sword would not care about color. A combat subsystem that resolves damage would care about strength and geometry (for lopped off limbs) but not position. The point here is that even though we might be able to use segmentData to capture everything from the perspective of the subject matter in hand, it would not be desirable from the perspective of communicating with other subsystems.
ADTs that are passed to other subsystems need to be abstracted consistently with the other subsystems’ requirements.
With this in mind, segmentData is probably not the best choice because it contains irrelevant information for a particular service subsystem.
Having analyzed options for how to express Segment’s attributes into ADTs, let’s switch gears and say that was a waste of time because it was a trick question. Given the simplifying assumption that this subsystem does not care about any of the attributes individually, we really don’t need Segment, much less its attributes. To see this, think about whether this subsystem would even need to manipulate segmentData or its variants. This subsystem is about Ogres swinging Swords at Heroes’ heads. We have already relegated details for display rendering, movement physics, and whatnot to service subsystems. Why would we need an abstraction that enables swinging a sword to be approximated for graphical and combat resolution?
The answer is that we don’t need segmentData for any reason other than to pass data to service subsystems. So why do we need to pass the data to service subsystems? Because the Skeletal Model has been defined in this subsystem. Why? Good question, that.12 A skeletal model is a mathematical technique for solving different problems: display and movement resolution. It is basically a design strategy for dealing with an entirely different suite of requirements for things like graphics rendering and motion physics. It has nothing to do with the Game semantics at the level of an Ogre swinging a Sword at a Hero’s head. So if we eliminate the Skeletal Model and Segment classes, the whole problem of abstracting attribute ADTs becomes a non-issue. In the relevant subsystems, there will be views of the Skeletal Model with all the attributes needed for that subsystem.
In case you are wondering, those models will very likely be instantiated via parametric polymorphism from external configuration data. This enables this subsystem to cause the corresponding Skeletal Model to be created in the service subsystem by simply supplying identity and some basic type information (Big Nasty Ogre versus Little Annoying Ogre) that the game system already logically knows. That information will be used to access the correct configuration data to initialize all the attributes properly. Ain’t it great when a Plan comes together?