
Chapter 10. Associations
A poor relation—is the most irrelevant thing in nature.
—Charles Lamb, Poor Relations
It is probably safe to say that associations are the second most underutilized feature of OO development.1 The problem is that although OO practitioners are well aware of them, they tend not to pay much attention to them. As it happens associations are extremely important to defining the structure of dynamic collaborations. They allow us to express business rules and policies in static structure rather than behavior responsibilities. Most important of all, they are the primary mechanism through which the OO paradigm limits access to knowledge. These advantages won’t become entirely clear until we see how associations dovetail with the dynamic description in the next section. So for the moment you will have to be satisfied with just laying the foundation in this and the next two chapters.
Though the notation for associations is rather simple, the topic is not. Properly identifying associations in the problem space borders on being an art form because of the richness of the semantics associated with drawing a single line in a diagram. This is reflected in the fact that in UML the association artifact is the only artifact with a notation element (a role) that describes only what the developer was thinking and has no effect on the software solution. We could easily write an entire book on identifying problem space associations. Alas, we don’t have the space but we strongly recommend that you include Leon Starr’s book2 on your reference shelf because it has the most comprehensive discussion on associations to date.
Definitions and Basics
The high-level definition of an association is the traditional dictionary definition: It is a connection. For purposes of OO development we just throw in a few qualifiers.
A relationship defines the structure of a conceptual connection among object members of different classes.
An association is the UML name for a relationship that does not involve subclassing (generalization).
Once again the UML has chosen to provide its own nomenclature rather than employing the generally accepted OO term, relationship. The existence of an association simply says that the individual members of two classes may be logically connected in some fashion. Structure is emphasized because an association says nothing about which particular members are connected. An association just describes constraints that limit which members of the classes may be connected. To that extent it is a set-based concept at the class level rather than the object level. This is important because it allows us to incorporate problem space rules that apply to groups of entities directly in the association definitions rather than in the dynamic description of object behaviors.
Each object will have its own unique set of connections instantiated to specific members of the other class. Even when the object can connect to several objects in the other class, the number of objects it alone can connect to is almost always a very small subset of the total members of the other class. This is illustrated in Figure 10-1.
Figure 10-1. Object-level instantiation of relationships between objects of different classes
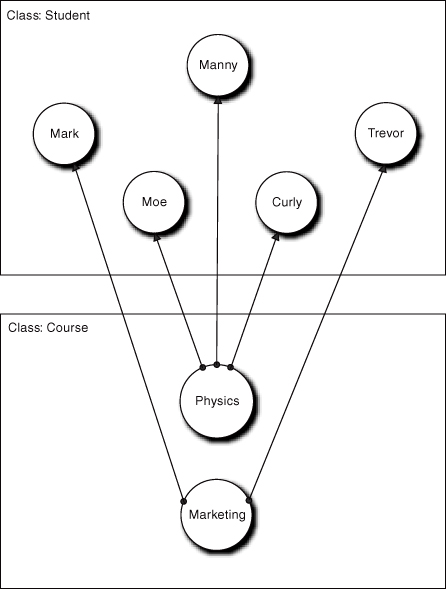
Here the Physics member of class Course will only be actually connected to the Manny, Moe, and Curly members of class Student. Thus if we have a Physics object in hand, we cannot access any other member of the Student class except those three. From the perspective of Physics, Brad and Trevor may as well not exist, because only the indicated connections will actually be instantiated at runtime. Why just those? Because in the problem space there are rules specifying which connections can be made. In this case those problem space rules are defined by the notion of course registration.
In effect, once it is instantiated the relationship enforces those registration rules from the problem space. Even though all of the Courses are connected to Students and all of the Students are connected to Courses, when we look at a particular Student or a particular Course the connections are quite limited. This brings us to the Big Three concepts related to associations.
Instantiation. At some point in the solution we must decide exactly which objects are actually connected. This will be driven by problem space rules and policies, and it is the most important way to capture business rules and policies in static structure. It is also the way that we limit access to objects and, consequently, knowledge.
Navigation. When objects collaborate in a peer-to-peer fashion, they need access to each other. Since that access is restricted by associations, we route the message that triggers that collaboration by traversing a path of one or more associations. In short, we say an object navigates an association path to communicate with its collaboration partner.
Implementation. To be instantiated and navigated there must be some software mechanism that implements the association. At the OOP level there are many tactical choices for association implementation. But in the OOA model we don’t deal with implementation issues, so we won’t be talking about them in this book.
The rules and policies that govern instantiation are usually quite different than those governing collaboration. Association instantiation is about who participates in collaborations, while the collaboration is about what happens and when it happens. So we have another example of the emphasis of separation of concerns in the OO paradigm because we will usually instantiate associations at a different time and place in the application than we will define navigation.
Associations are abstracted from the problem space.
The definition of association navigation introduces the notion of a path of associations. Aside from an awful clutter of the Class diagram, we do not want to create a direct peer-to-peer association for every possible collaboration because that is not the way the problem space usually works. In most problem spaces the logical connections between entities of different kinds reflect fundamental concepts. Thus many People may populate a Nation, but not all of them are citizens with a right to vote. Similarly, many of those People may own Homes, yet there is no intrinsic connection between Nation and Home. Nonetheless, there is a path of connections between Nation and the Homes owned by citizens when the government decides it is time for an economic census.
Associations are always binary; they connect only two classes.
In our zeal for the emulating problem space structure in software structure, we want to ensure that our associations correspond to fundamental connections in the problem domain. Generally, the concepts underlying those connections are complex and the problem domain itself will endeavor to simplify things. One way it does that is by focusing on only two kinds of entities at a time. If you think about notions like contract, debt, and sale, they are almost always between two kinds of entities. There are a few exceptions, like parenthood, but even those can be reduced to binary associations.3
This constraint further dictates that peer-to-peer collaboration may involve navigating multiple associations in a path. This is an MBD constraint since the UML supports ternary and other multiclass associations.4 The reason that MBD does not support more than binary associations is twofold: They are exceedingly rare in most problem domains, so we do not want to clutter a notation to treat special cases uniquely when they can be handled otherwise. More important, the intrinsic “forks” are inherently ambiguous in the context of peer-to-peer collaboration where we want to navigate a single path to a single object. At a minimum, we would need additional notational support to make the right navigation choices, and the UML does not provide that syntax.
A collaboration is a timely interaction between two objects. The participants in collaborations are primarily determined by associations.
Since associations exist in large part to provide structure for collaborations, it is about time to define this notion. Notice the emphasis on being timely. The timing of when to do things in the solution is critical, but who should interact is often invariant, at least across significant portions of the solution. So even though associations directly support collaborations, they are very different things, and the reasons for navigating associations in a solution are usually quite different than the reasons the association exists in the problem space.
An association path is a contiguous sequence of one or more binary associations.
Association paths are orthogonal to class semantics.
In Figure 10-2, if there is no direct association {A → B}, then for object A to collaborate with object B we will have to traverse a path of individual associations to get there. That path may involve navigating “through” the chain of individual connection {A → C}, {C → D}, {D → E}, and {E → B}.
Figure 10-2. Relationship path for navigating collaborations
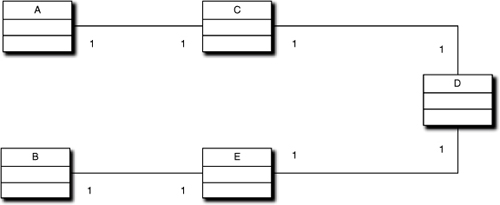
As we shall see in the section on dynamics, we can specify the association path without even knowing what the intermediate objects are.5 In fact, transformation engines typically implement associations very much like aspects from Aspect-Oriented Programming (AOP); they are semantic structures that orthogonally cut across class semantics. The notion that we can implement, instantiate, and navigate associations completely independent from class semantics is very important to the OOA/D mindset because it allows us to decouple collaboration from specific object implementations.
Association paths constrain access to objects because associations are instantiated at the object level.
Associations are an enormously powerful tool for restricting access to state information.
As indicated in Figure 10-2, we instantiate associations on an object-to-object basis so that objects not involved in the association are not even visible, much less accessible. It is surprising that the OO literature rarely mentions associations in terms of constraining access to objects. In fact, though, this is the primary way that the OO paradigm avoids the traditional problems of global data even though object attributes are state variables that persist for the life of the object and are theoretically accessible by any other object in the Class model. Those problems are largely avoided because in practice associations restrict access on a need-to-know basis. The beauty of the technique is that it uses the problem space’s own structure to enforce the restrictions.
But there is another, equally powerful implication of the role associations play in the OO paradigm. Associations allow us to separate the concerns of who, when, what, and why as they relate to collaborations. Generally, each of these concerns will have a separate suite of rules and policies that govern them in the problem space. The OO paradigm allows us to isolate each of those concerns so that they can be managed separately. That, in turn, enables much of the robustness of OO applications in the face of volatile requirements. To see that, let’s look at how each of these collaboration issues is resolved in the OO paradigm.
• Who. Because OO collaboration is peer-to-peer, we need to make sure that the right two objects are collaborating. The primary mechanism the OO paradigm employs to restrict participation in collaborations is the instantiation of associations as just described.
• When. The developer provides the sequencing of activities at the UML Interaction Diagram level by connecting the dots of atomic, self-contained behavior responsibilities. Though usually done informally, it can be done rigorously by employing the DbC techniques described in the next section. It is enabled by thinking about when in terms of announcing conditions that currently prevail in the solution with messages (I’m Done).
• What. This is a matter of problem space abstraction. We define the behaviors that encapsulate problem space rules and policies. It is crucial that we separate message and operation so that we can define operations as intrinsic behaviors that are context independent.
• Why. Basically these are the requirements that determine how the problem solution must work overall. It is the developer’s vision of how everything plays together. It is this vision that extracts invariants from the problem space and identifies the static structure of the application.
Thus we have four distinct contexts for these issues and distinct mechanisms for dealing with them in the design.
Notation
Now that we know why associations are important, it is time to look at how we characterize them in detail. Graphically, an association is just a line in UML between two classes, but it is qualified by the following elements.
• Discriminator. The discriminator just identifies the association uniquely. Uniqueness is only required within subsystem scope, not across subsystems.
• Multiplicity. This defines the number of members of a class that may participate in a connection with a single member of the other class. Because of the symmetry, we have to define multiplicity on both ends of the association.6
• Cardinality. UML allows us to designate explicit numbers for multiplicity as well as ranges and other features. MBD does not specify cardinality because it is really only needed to address nonfunctional requirements. Since the OOA model does not deal with such requirements, it is unnecessary.
• Conditionality. This defines whether participation is conditional (i.e., there may not be any participant in some situations). Like multiplicity, conditionality is specified for both ends of the Association. That is done by prefixing the multiplicity with “0..” if the Association is conditional. (The combined conditionality and multiplicity is read as “zero or one” or “zero or more.”) No prefix is needed if the association is unconditional (i.e., there will always be at least one participant).7
• Role. This is the property mentioned previously where we explicitly indicate what the developer was thinking about when creating the Association. The role describes how a member of the class logically participates in the association. Like multiplicity and conditionality, there is a role for each end of the Association.
• Constraint. A constraint places additional limits on the participation in the collaboration besides multiplicity and conditionality. Constraints can take many forms, and we will talk about some these in greater detail later.
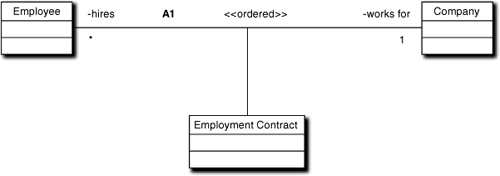
In Figure 10-3 an association exists (a line) between Employee and Company such that a particular Company has many (*) Employees but an Employee works for exactly one Company. The association roles are read as, “Company hires Employee” and “Employee works for a Company.” The association discriminator is “R1,” and the implied collection of Employees is constrained to be ordered in some fashion. The convention is that an end property is placed on the end of the line closest to the object of the role, which is usually a verb phrase.
Figure 10-3. Notation for UML associations
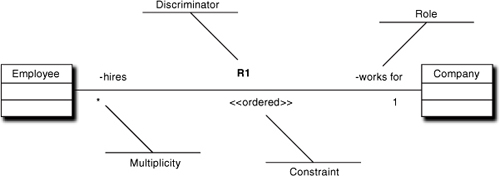
There is a special case, though, when the multiplicity is many on both sides of the association, as shown in Figure 10-4.
Figure 10-4. Use of Association objects to qualify associations
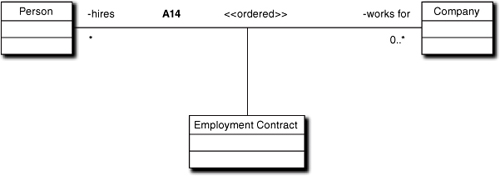
Now the multiplicity allows a Person to work for many Companies at the same time. For reasons we will get to next, many-to-many multiplicity is ambiguous in a pure binary association because it cannot be resolved solely in terms of class attributes (e.g., a single referential attribute as in an RDB). In relational data model terms, it would have to be resolved externally, say through an index. We’ll have more to say about this sort of association later, but for the moment think of the third class, Employment Contract, as a placeholder for some mechanism to remove the ambiguity of reference.
The third class is known as an Association class. It may or may not have problem space semantics (e.g., the notion of an employment contract). An Association class qualifies the association in some fashion. If that qualification is about problem space semantics in addition to simple mechanical resolution of referential integrity, then we can use an Association class to qualify associations whose multiplicities are 1:* or even 1:1, as indicated in Figure 10-5.
Figure 10-5. Applying an Association object to relationships other than *:*
In Figure 10-5 the multiplicity is exactly the same as in Figure 10-3, but we still have an Association object to qualify the association. That’s because additional problem space semantics is unique to that association, and we capture that semantics in the Association object.
That’s all there is to the notation for Associations. You may feel that such a simple view of multiplicity and conditionality can’t possibly be sufficient to justify all those assertions made previously about the power of capturing business rules and policies in association definitions. The rest of this chapter will be devoted to exposing why this very simplistic notation is actually an extremely powerful tool in constructing applications.
The Nature of Logical Connections
You probably noticed the repeated use of the phrase “logical connection” thus far. The reason why associations have roles even though the roles themselves don’t affect the way the software will be implemented is because the developer needs to keep track of the reasons why associations exist. Thus, roles define the logic behind the connection. It is quite common for there to be multiple possible association paths between two collaborating objects. Usually only one of those paths connects exactly the right participants for the collaboration context, because the rules and policies governing the individual associations along the paths will be different. We use the roles then as mnemonic devices to keep track of the different rules and policies. Thus when addressing messages during collaborations, we need to navigate the right association path, and the right path will be determined by matching the logical connections of individual associations to the collaboration context.
When associations are navigated, the sender of a message can have absolute confidence that the message will get to the right object without knowing anything about the rules of participation.
This is very important to long-term robustness in an application. Once an association is properly instantiated, it can be navigated in complete confidence for any purpose. When a Parent spanks a Child, the parent is always sure it is the Parent’s Child and not the next door neighbor’s Child. That’s because the rules of instantiation required that Parent and Child be related in a familial manner to be connected. The Parent sending the Spank message does not have to understand those instantiation rules; all it needs to know is that it can send the Spank message to whatever Child participates in that association.
There is no rule that only one association can exist between two classes, as Figure 10-6 illustrates. In fact, the ability to define multiple associations is a powerful technique for managing collaboration complexity because it allows us to discriminate among different collaboration contexts.
Figure 10-6. Example of multiple associations between the same classes
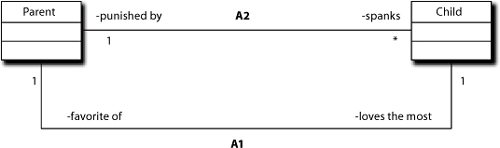
By removing the concerns of participation from the implementation of Parent, we simplify Parent and make it more cohesive. It will also usually be more efficient because most problem space associations are navigated many times compared to the number of times they are instantiated. Elimination of tests to determine the right Child for those navigations should improve performance. Thus, as shown in Figure 10-6, the Parent can send a kiss to the favorite child by simply selecting the right association rather than searching through the entire set of children. In this case, having multiple associations will provide a significant performance benefit in practice.
Such performance improvements and consequent reductions in code size (by isolating instantiation to one place) is not serendipity. It is a direct result of correctly modeling the problem space. In the problem domain a Parent “knows” its Child—recognition is imprinted from birth in a highly efficient and transparent manner. So for any subsequent collaboration with the Child, the Parent does not have to think about that recognition; it already exists in mechanisms separate from any thought process around the collaboration.8
Multiple associations between the same classes should reflect different participation rules and policies.
This bon mot is directly related to the OOA/D set-oriented view of classes. In effect, the association defines a subset of set members on each side of the association. When two associations are instantiated at the object level for a given object, each association should define different criteria for identifying participating objects. That is, for a given object on one side, each association should normally produce a different subset of the objects on the other side.
Notice the weasel word normally in the last sentence. Depending on the specific nature of the criteria rules and policies, it is possible that both criteria might yield the same objects for some given object. In fact, when associations are both * associations, it is fairly common for the subsets of members yielded by each association to have some overlap. The point here is that both associations should not yield identical sets of objects for all possible instantiations.
Navigating to Knowledge versus Navigating to Behavior
As we have already mentioned, the OO approach separates knowledge access from behavior access. When we access knowledge, the access is synchronous, and we can’t avoid knowing what particular knowledge is being accessed. This is because the only reason the knowledge is being accessed is that it is needed by the behavior in hand.
Fortunately, knowledge is static, so the coupling introduced in knowing what knowledge is accessed is relatively benign. That’s because the knowledge always exists as long as the owning object exists. Association navigation ensures that we always get to an existing object, so that only leaves the validity of the data itself. But we access knowledge synchronously, so we know we are getting the latest, most up-to-date value.
In contrast, the I’m Done approach applies to behavior. Messages announce something happening in the solution, and the developer routes them to behaviors that care. Therefore, the sender and receiver need not know the other exists, and neither needs to understand the overall solution context in its implementation. So when we navigate relationships to behavior all we are concerned with is correctly addressing the message.
Once again, this reflects the basic OO practice of separating concerns. Through the use of associations, and the separation of message and operation, we separate the concerns of addressing and timeliness. The sender only needs to understand that it is time to send a message. The addressing is separated out into the association instantiation. The association of a specific behavior with the message is handled by the receiver. And all of this is managed by the developer at a higher level of abstraction than individual object behavior implementations when the collaboration messages are routed.
Association Roles
Ordinarily we would be tempted to capture the reason the association exists in the discriminator name, just as we capture class and responsibility semantics in their names. But doing this poses a problem because associations can be navigated in both directions, and there may be different rules and policies in different directions. So we identify a role for each end of the association to reflect our purpose in navigating in a particular direction.
Defining association roles properly is very important to good modeling. When addressing messages we need to select the correct association path when multiple paths are available. We use the roles as mnemonics for the underlying rules and policies of selecting participants. That, in turn, allows us to identify which particular subsets of candidate collaborators are appropriate for the collaboration context in hand.
Roles should almost always be asymmetric.
The main benefit to proper identification of association roles lies in the exercise of identifying them. This is because we are forced to think clearly about what the roles actually are within the context of the particular problem solution. One of the most useful tricks for thinking about roles properly is to ensure that each role captures a different thought. Each role represents a single object’s view of the connection. Since objects abstract different entities and have unique properties, it figures that participating objects on each side of the association will have different perspectives on the nature of the association.
Whenever a reviewer encounters a symmetric association as in Figure 10-7(a), where each role simply rephrases the same notion of role, it should raise a warning flag. Symmetric associations can very rarely be justified. In Figure 10-7(b) the example provides some useful information about how each class views the collaboration.
Figure 10-7. Bad and good examples of role definitions
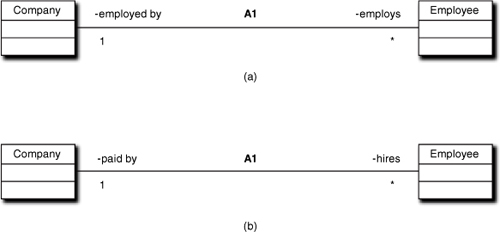
Roles should add information not implicit in the participants.
The second problem with the first example is that it is virtually devoid of information content. The fact that one of the participating classes is named Employee already captures whatever insight the roles convey, so the roles are redundant. The level of abstraction is too high. Roles should be focused on the nature of the specific connection within the subsystem’s subject matter context.
In the second example it is clear that there is some sort of collaboration around hiring. That is, somewhere in the problem solution there will be a sequence of activities specifically related to hiring employees. Similarly, in the second example it is clear that the problem solution is going to have to deal with rules and policies related to payroll. That indicates a particular problem context, such as human resources. The roles might well have been {builds tools for, provides plans to} in another, quite different problem context for the same Company/Employee connection.
Roles should explain something about the connection.
The important thing here is that we are describing the connection, not necessarily a specific collaboration across that connection. There may be several client objects that need to collaborate with Employee for a variety of reasons. But if they want to limit the Employees they collaborate with to those employed by a specific Company, they all need to navigate through the A1 association.
Now clearly we can get carried away with detail and start devising roles like, “builds rear fender dies for all pickup trucks except those with extended or armored bodies.” There is a trade-off to be made here between precision and brevity. We want the most precise description of the connection we can provide in a single phrase. Defining good role phrases is not an easy thing and it requires good vocabulary skills. If you tend to get frustrated trying to find things in a textbook using its index, then you probably want to be sure someone else reviews any role names you assign.
Facetiousness aside, role names should always be reviewed; the more eyes the better. Because formal reviews work best when they just identify problems (as opposed to solving them), we suggest that your process have some mechanism for group discussion of role names that are identified as a problem in a review. This doesn’t have to be a big deal with a full team meeting, but a few people trading ideas will usually come up with something acceptable pretty quickly.
Association Paths
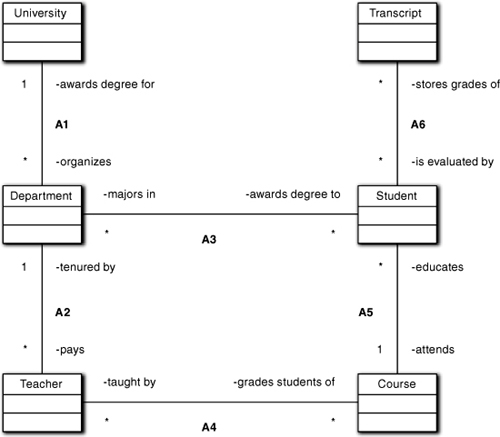
We already discussed the basics of association paths. Now we need to discuss some specific design issues around association paths. In Figure 10-8, one likely use case would involve a recruiter requesting student transcripts from the university.9 Another use case scenario would involve a student’s transcript being updated for the grade received from the teacher in a completed course.
Figure 10-8. Example of the separation of objects along relationship paths
Do not add direct associations if an association path already exists that will navigate to exactly the same set of instances.
Corollary: Define the minimum number of associations necessary to solving the problem in hand.
In both these scenarios, a Transcript object needs to be accessed in a collaboration stemming from two different objects (University and Teacher) that are not directly connected to Transcript. We could insert a direct association for each case, but there are two reasons why that is not a good idea. First, it introduces clutter in the diagram. That clutter isn’t too bad for two scenarios in a small model, but it will quickly become a rat’s nest in a subsystem with 20 to 30 classes with dozens of use cases. As a practical matter we want to keep clutter down so that the model is more comprehensible.
But the most important reason is robustness. If we make a direct connection between University and Transcript, how do we select the right transcripts that the recruiter requested? To do that, University will have to somehow know which transcripts go with which students. (Even worse, the recruiter may want the transcripts for a particular department.) As it happens, the selection rules are already implicit in the association path University → Department → Student → Transcript. We can find any particular transcript, any group of transcripts for particular students, or any group of transcripts for a particular department by simply making the correct searches of the collections implicit in the 1:* associations.10
The second scenario leads us to another aspect of robustness. Consider how a student’s transcript is updated when a teacher provides a course grade. Unless the school is a one-room university, it is actually rather unlikely the teacher updates the transcript directly. There is usually some bureaucratic process, like a departmental review, before a grade is etched permanently into the student’s transcript. And by the time that process is completed, the update task has probably been delegated to some departmental administrative assistant who notifies some scion of officialdom, like a university Registrar, who then delegates it to the Registrar’s AA to do the dirty deed.
For the moment let’s assume that in the application modeled, the problem solution only cares about the recording of the grade, not the process of recording. For example, the actor in the use case for updating the Transcript may be the Registrar’s AA. In that case it really doesn’t matter, and we can abstract the bureaucracy into a direct association between Student and Transcript. But it is likely that the AA is working with a list of Students for a particular Teacher’s Courses, and a user-friendly interface may want to provide that perspective in the UI form in terms of pick lists to define the search criteria in terms of Department, Teacher, Course, and Student. Quelle surprise! An association path already exists, Teacher → Course → Student → Transcript, that captures the fundamental problem space specification.
Now let’s assume that at least some of that bureaucracy is important to the problem at hand. For it to be important to the problem at hand, some set of rules and policies explicitly defined by that bureaucracy must have relevance. At one extreme we need to model the entire process, which means we are missing a bunch of objects, like Registrar, and a bunch of collaborations, like the Teacher submitting a grade to the Department for review. In that case our model is pretty bad, and it might be time for some remedial training because we have missed some major requirements during problem space abstraction.
A more likely scenario is that we didn’t miss by much. For example, the process of reviewing the grades may be an important collaboration between Department and Teacher, but Registrar and all the AA-to-AA missives may be irrelevant. If that’s the case, then the fix is relatively easy. We just have to add a responsibility to review the grade to Department and add another association between Department and Teacher, as shown in Figure 10-9.
Figure 10-9. Modeling departmental policy on reviewing student grades
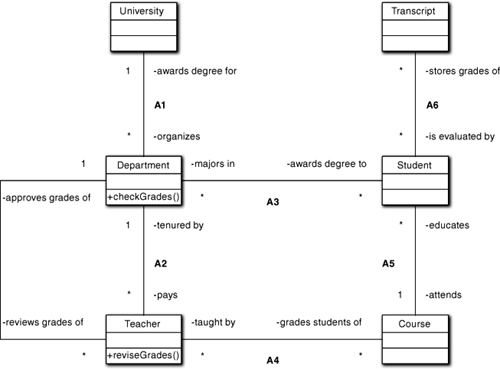
Now Department has the responsibility, checkGrades, to check the bell-curve distribution to approve the grades. If they are satisfactory, it will navigate to the relevant Transcripts and update them. Otherwise, it will issue a rude message to Teacher to revise and resubmit the grades. So Teacher has a responsibility, reviseGrades, to revise the grades and resubmit them to Department.
The basic thing to note is that the original structure of the diagram remains intact because we only added responsibilities to deal with new requirements. If we already had a direct association between Teacher and Transcript, we would have had to undo that. Trivial as this might seem, it is important to not have to undo things we have already done just to accommodate new requirements. (When existing requirements change, we usually do have to undo things, but that is a different context.) Though this example is pretty simplistic, the basic point is to capture only the essential structure of the problem space, which greatly increases the chances that new requirements will be additive.
The second thing to note is that once the new collaboration was introduced, the navigation to actually access Transcript—when it was appropriate to do so—was accommodated by the existing association structure, Department → Student → Tran-script, because that structure had not changed. But how does Department know which Students must be accessed? That segues to the next point about association paths.
The obvious answer to that question is that Teacher includes the students with the grades as part of the data packet when submitting them for validation. But that just begs the question. How did Teacher get them? By navigating the Teacher → Course → Student association. Yet Teacher would have had to do that anyway when it navigated directly in the original direct association scenario (for the same reason that University had to navigate University → Department → Student anyway to select the right Transcripts for the recruiter).
But let’s assume that Teacher does not submit a list of students and grades. Instead, Teacher simply announces to Department that grades are ready. In this scheme Teacher does post an interim grade to Transcript. Now Department navigates Department → Teacher → Course → Student → Transcript to get the grades for review. This scenario might be appropriate in a situation where grades were posted and students could request a review (in which case the new review collaboration is between Student and Department rather than between Teacher and Department).
The important point to note in these scenarios is that they are quite different but they require, at most, a single addition to the association structure, despite the fact that the responsibilities may be quite different and the flow of control, represented by message flows, is quite different. That degree of stability or robustness is only achievable if we include the minimum set of associations necessary to solve the problem in hand and we are careful to capture the fundamental logical connections of the problem space. This is why we define connections as simple binary connections before worrying about specific collaborations. It ensures a fundamental view of the problem space essentials.
Conditionality
Conditionality is conceptually quite simple but is often the source of great angst when trying to gain consensus on the proper problem space model.
An association is conditional if a valid situation exists in the problem space where an entity of one set is not related to any entity of the other set.
The first problem here is the notion of “valid.” We use a broad definition that includes the implication of some span of time where life goes on normally as far as the problem in hand is concerned. Consider the example of getting new license plates for a car.11 There will be some period of time between removing the old plates and installing the new ones when the car will not have plates, which is fine as long as the car is in a private driveway and is not driven until the transfer is complete. However, some people change their plates in the Registry parking lot, and that is technically illegal because the car is in a public lot.
As a practical matter, it is doubtful that even a registry cop would get bent out of shape about such a technical illegality. Nor can we imagine any need for software dealing with auto licensing that would care about that situation in its normal course of operation. We can, however, imagine situations where the lack of plates is important—such as driving without yet installing the new plates. Though rare, such situations have arisen and people have gotten tickets for it. So from the cop’s viewpoint it is possible to have an interesting situation where a car is not fully registered even when the owner paid the Registry and got the plates.12
When you have the task of writing the control software for Robocop, you will probably have to make that association between Car and License Plate conditional on the Plate side. But until then, we still have a hard time imagining a software problem that would care about that situation. Most software would adopt the Registry view that the Car has been issued valid plates regardless of whether they were physically on the Car.
But wait! What about someone who lets their old plates expire before renewing the license? Now there is a real gap where even the Registry view has a Car VBN without a corresponding valid License Plate. Hmm. OK, that’s another case where we need a conditional association that might come up in a much larger number of problem contexts. So when will this association ever be unconditional?
One possibility is the software that manages a fleet of Cars for a rental company. In that case there is likely to be a corporate policy saying we do not rent a car without valid plates, so any car without plates will be removed from the inventory the fleet management software accesses. Now from the fleet management viewpoint, a Car always has a License Plate and the association is unconditional. As a practical matter that will probably be handled by a query constraint on the database. In other words, when the fleet management software queries the database for available Cars, it will explicitly invoke the policy by querying for Cars that are properly licensed.13
This very simple and very real example has introduced a flock of issues that are tricky to resolve. But the resolution comes down to answering two questions.
- Is there a reasonable situation in the problem space where the entities are unrelated?
- Do we care about that situation for the problem in hand?
When answering those questions it is important not to get hung up on implementation decisions. Technically, any time you replace one participant in, say, a 1:1 association, there is some time duration where the entity is not related to any other entity. That’s because instructions take a finite time to execute, which is a very real problem for asynchronous and/or concurrent processing. However, this is a referential integrity issue largely left to the transformation engine or OOD/P. So just model the problem space when defining associations. Between the methodology and the notation, there is sufficient context to resolve integrity issues unambiguously in the implementation.
Look for ways to eliminate conditional associations.
One reason for this bon mot is the trickiness. If you can find a suite of abstractions that clearly eliminate the conditionality, you also remove the angst over whether it really is conditional. But the main reason is that conditional associations require code to be executed for every navigation context. That is, we have to at least check whether the association is actually instantiated prior to every collaboration. In addition, conditionality usually implies some other behavior for that situation, such as recovery.
Figure 10-10 presents models for a hierarchy. The first example is an elegantly compact representation of any hierarchy to be navigated by some Client. The problem is that of the four association ends, three are conditional. This will complicate the code necessary to “walk” the hierarchy, because for every step in the navigation decisions will have to be made about whether the Node in hand is a root node, intermediate node, or leaf node in the hierarchy. In addition, the relevance of those decisions will depend on knowing whether we are navigating up or down the tree. That logic will be further complicated if we need to do depth-first or breadth-first navigations that require back-tracking.
Figure 10-10. A model of a hierarchical tree suitable for navigation in many contexts
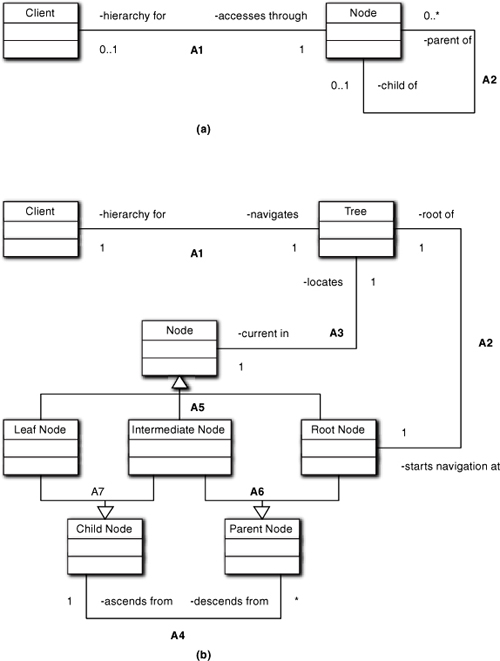
But things will be even more complicated if the nodes are not all created equal. For example, in the page hierarchy for a POS web site the content of the pages will probably be substantially different for leaf Nodes, where individual items are described, than for the root Node, which is likely to be a home page or something similar. That will create problems because code for various alternatives will be embedded in Node or, worse, in the Client who is doing the navigating. It won’t be long before we have a god object, or a lot of bleeding of cohesion between Client and Node as Client must understand more about the details of navigation.
One answer to this problem is the second example in Figure 10-10. Here we have slipped in some material from Chapter 12 by introducing some superclasses. Fortunately, the relevant notation semantics isn’t that big a deal here. All you have to know is that the superclasses in this case provide some very simple-minded commonality across the subclasses, and the subclasses represent disjoint subsets of the parent class’ membership. In this particular case, all they provide is a definition of association instantiation. This can be summarized in Table 10-1.
Table 10-1. Characteristics of Nodes in a Hierarchical Tree

Note that there are no conditional associations in this model. This model can correctly describe any hierarchy except the degenerate case of a single node hierarchy. While it is more complicated because of the additional classes, it does a much better job of making explicit the rules for any sort of hierarchical network. That will pay dividends when we actually describe the dynamics of whatever problem is solved by navigating the hierachy.
The first benefit lies in encapsulation. Consider a POS web site where we would be representing the navigation hierarchy for hyperlinks. In such sites the actual content of root, intermediate, and leaf pages is usually different in significant ways. For example, the arrangement and content of panes will usually be different. Now we can easily encapsulate that logic so that it is completely transparent to the Client who is doing the navigating. There are no decisions to determine what to do when a Node object is accessed; the navigator does exactly the right thing because that is the only option. That is, the navigation rules are implicit in who the Node is (i.e., which subclass it is), and those rules are enforced when instantiating Nodes and their associations.
The second benefit lies in access. By inserting the Tree class we have defined a place for specific traversal algorithms, like depth-first search or breadth-first search, and even exotic tasks like determining the minimum sum of products for a boolean expression. That removes any responsibility for understanding the navigation from Client and isolates it in Tree. It has the added benefit that Tree can keep track of the current node in the traversal via instantiation of the Tree/Node association (A3) rather than Client.
Just as important, we can access the nodes through Node, Parent Node, and Child Node interfaces as the situation warrants. For example, we can navigate up and down the tree in terms of Parent Node and Child Node but then switch the view to the Node view to access the (nonreferential) responsibilities of the node. Again, separation of concerns between hierarchical navigation and node semantics will provide better modularity and simplify the dynamic description.14 For example, we might isolate tree navigation in a separate subsystem from that where the semantics of the individual pages is manipulated. (We probably wouldn’t do that because Tree already isolates that navigation adequately, but it underscores the idea of separation of concerns that the second model facilitates.)
Bear in mind, though, that sometimes the first example will be an adequate model. Where the second model shines is when the root, intermediate, and leaf nodes have differences in attributes or behavior. It is also useful when we must keep track of where we are within the hierarchy (i.e., the notion of current node), when we want to keep the traversal algorithm hidden from the Client, or when the traversal algorithm requires more complex processing like backtracking. If none of these things are necessary to the problem solution and are unlikely to be in the future, then the first example is likely to be sufficient.
Multiplicity
Compared to conditionality, multiplicity is usually pretty easy to figure out. However, it is not always without team angst when establishing consensus. Basically, multiplicity is pretty simple because we only care whether the connection is always to just a single instance or not. If it is always only a single instance, the multiplicity is 1. If there exists any problem space situation relevant to the problem in hand where the connection may be to multiple instances, the multiplicity becomes “one or more,” which we designate with an asterisk in UML. The only tricky part here is deciding what is relevant to the problem in hand.
When abstracting from the problem space only what we need to solve the problem in hand, often that involves simplification of the problem space, and one possible simplification is to reduce a one-or-more participation to a single participation. In the previous examples we had associations that represented the notion of a 1:1 “current” association. That is the most common example of specializing an inherently 1:* association into a 1:1 association by narrowing the temporal scope of participation. In other words, while many objects may be logically connected in the problem space, we may only be interested in one at a time to solve our problem.
There are basically two cases we need to consider. The first is the situation where the inherent 1:* association in the problem space is replaced by a 1:1. The second situation arises when we preserve the 1:* association in the model but then decide we also need a separate 1:1 association between the same entities.
Replacing a Problem Space “One-or-More” with a Model “One”
Clearly, the first thing to determine is whether a 1:* association exists in the problem space between the entities. If it does, then the question we need to answer is Do we care in our problem context? For example, is the “*” on A1 correct in Figure 10-11?
Figure 10-11. One possible model of mapping drivers to driving licenses

It is possible for a Driver to be licensed to drive by many jurisdictions and for different purposes, therefore a 1:* association exists in the problem space. If our application needs to know about all of the licenses during its execution, then we can’t replace it with a 1:1 because we would have no way of navigating to any license other than the one in the association. This would be true for software that, say, revokes a driver’s right to drive in a particular jurisdiction. To notify other jurisdictions with reciprocity agreements it would have to know about multiple licenses.
In contrast, consider the software that records the granting of a license in a particular jurisdiction. In that situation the software doesn’t care how many other jurisdictions have licensed the driver. All it cares about is that the driver passed the qualifications and paid the fee in this jurisdiction. As far as that particular problem is concerned, a Driver has only one License.
Unary multiplicity may be used on the source side of any association where the problem space collaboration is inherently one-way.
This conversion is fairly common for *:* associations in the problem space that are converted to 1:* associations to solve the problem in hand. The association of Student to Course in the Figure 10-8 University example demonstrates this. Clearly, a Student may attend many Courses and a Course may have many registered Students, yet the association in the example is 1 on the Course side. That’s because all of the use case scenarios and hypothesized software missions provided assumed all we cared about was providing the Students for a particular Course. So the only navigation of that association was one-way via Department → Course → Student. That is, nobody cares how many Courses a Student is actually attending in the use cases. However, as soon as the software also needs to solve a problem like determining if a given Student took any classes from a particular Department, that is no longer true and the association must revert to the inherent *:* situation in the problem space.
While we can apply this sort of mental gymnastics whenever the problem in hand only requires one-way collaboration, it is wise to do so very cautiously. The danger is that we can be myopic about the requirements and overly constrain the solution relative to the problem space. The main reason why we employ the OO approach is to provide agility in the face of volatile requirements. One technique to do that is to ensure the software structure parallels the structure of the problem space.
When we “hard-wire” a one-way collaboration in the association multiplicity to simplify the model for a particular set of requirements, we need to be pretty confident that the sorts of changes that are likely in the future will not require two-way collaboration.15 So, when in doubt, we should err on the side of the inherent problem space association. If we model the inherent problem space structure, it can be optimized by the transformation engine and we won’t have to touch the model in the future.
Supplementing a Problem Space Association with a Second Association
In the Client/Node example of Figure 10-10(a), the traversal algorithm would likely be a simple dynamic iteration over processing individual Nodes. We would just use the parent/child Node associations to obtain the next Node to process. Thus we are essentially just iterating over the set of Nodes in the collection, regardless of how we determine the order of processing them. That processing order is purely a matter for the dynamic description of the iteration, so the 0..1:* association is appropriate.
There is a notion of “current” Node in such an iteration, but it only applies within a single iteration cycle.16 As soon as we need to keep track of where we have been we are in a different ball game because the notion of a “current” Node persists outside the iteration cycle. That is clearly true if we were executing some sort of breadth-first or depth-first search that requires backtracking. It would also apply, though, if the iteration is outside the scope of Client. For example. someone else might be asking Client for the “next” Node. Now other processing is going on between iteration cycles that has nothing to do with the iteration mechanics.
Use multiple associations between classes whenever there exist collaborations with different participants.
The notion of different participants in this guideline is just another way of saying that we need a unique association path when the constraints on participating instances are different than for other sorts of collaborations or roles. That’s pretty obvious for the case where we care about a particular current instance from among a set of available instances. The notion of current is a more restrictive constraint than the one on participation in the set of available instances. Let’s revisit the Figure 10-8 University example to illustrate a much more subtle situation. In that example, the Department → Course → Student path restricted the accessed Students substantially compared to the University population as a whole.
But suppose we have a new requirement where we are only interested in, say, computing the average grades for all of a Department’s Courses for both the Students that major in the Department and those that don’t (i.e., we want just two averages). We still need the original associations to resolve the original requirements, but will they still work for the new requirements?
It’s a trick question, Grasshopper, because it is intuitively obvious that they could if we had an attribute for Student that identified the Student’s major. We just “walk” the same set of Students for all of the Department’s Courses and incorporate each Student in the appropriate average based on the Student’s major. So the real question here is Is that the way we should want to model things for both old and new requirements? The answer to this question could easily lead to violence within the development team.
If we look at this issue purely from a problem space perspective, there is a quite natural association between Department and Student that captures the notion of some subset of all Students that major in the Department’s discipline (i.e., the A3 association in Figure 10-8). Since the Students that major in the Department’s discipline are clearly critical to the new requirements, that strongly suggests that we should use it somehow to resolve the new requirements.
The operative phrase is “use it somehow.” There are two problems with this approach. One is that the association would be between Department and Student but we need grades for Students in the Department’s Courses that they took. How do we get from the subset of Students majoring in the Department to their grades in particular Courses? There are ways to do it, but it will be messy with a lot of AAL code. The second problem is about how we separate the subset of Students that take the Department’s Courses but major in different Departments. If you think about it, this is potentially an even bigger mess for the dynamic description.
There are three ways to capture problem space rules: static structure, knowledge responsibilities, and behavior responsibilities. Always use the right one.
The point here is that the Department → Student association for majors clearly exists in the problem space, but it isn’t all that useful for solving the problem in hand. Using an attribute for Major in Student and “walking” the existing association starts to look pretty good, especially when we realize that we have to visit every Student taking a Department’s Courses anyway.17
But just to emphasize that such decisions are not always easy, note that there is a convenient way to use the Department → Student associations for majors to resolve the new requirements. We have two navigation paths: Department → Student → Course and Student → Course → Department, because the Course ↔ Student association can be two way. So we can easily compute the averages for Students majoring in the Department by navigating that path.18 We will leave it as an exercise to figure out how to do something similar for the Students taking Department Courses that did not major in the Department. (As a hint, think: symmetry.)
These two solutions are a very close decision, which is why software developers get the Big Bucks. The final choice will probably be made based on what the team is most comfortable with and what other requirements need to be met. The advantages of the attribute-based solution are that it is simple and works with the existing structure. Its disadvantages are that it requires more dynamic support and is not very elegant in an OO sense. The advantage of the association-based solution is that it explicitly employs static structure in an elegant fashion. The main disadvantage is that if the way averages are computed is changed (e.g., to course-by-course), it might be more complicated to modify.
We have gone pretty far afield from pure multiplicity issues—this was somewhat intentional. You should take away from this subtopic the understanding that the concept of multiplicity is simple, but how it plays within the context of the overall problem solution can be quite complex. When we do OO development we are juggling a lot of Basic Principles that are individually quite simple. But the pattern they form is marvelously complex and a thing of beauty—once we get it right.
Selection versus Participation
We just indicated that we should use multiple associations whenever the participants are different in a connection for different collaboration contexts. If taken literally, that would almost always lead to multiple associations between objects, because we sometimes need to select a subset of instances from a 1:* or *:* association for a particular collaboration. For example, in our University example we might want to establish an honor roll by selecting all the Students registered to a Department who got straight As in that Department’s Courses.
We can make a good case for such an association because the notion of honor roll is prominent in the University problem space. But do we want a special association of all Students who had straight As in core curriculum Courses, who played varsity croquet, and played lead kazoo in the school band? Probably not. So where do we draw a line in the sand between defining specialized associations and simply providing a dynamic search of a somewhat larger set?
If your answer is “It depends upon the size of the search,” then you must have skipped Chapter 2. Go write on the blackboard, “Performance is a nonfunctional requirement. We do not do nonfunctional requirements in the OOA.” Write it 1000 times and use squeaky chalk. Any search of an association collection for particular members in the OOA can be optimized by the transformation engine to a dedicated collection if performance is an issue. Therefore, we are interested in some sort of criteria that can be expressed in solution design terms.
The following criteria is useful to determine if selection warrants a dedicated association.
• Locality of scope. Here we mean that we do not care about the selection beyond the time it is made (e.g., within the scope of a single behavior responsibility). In the case of our Tree example, we created an association to capture the notion of current Node even though we had an existing association path to reach any Node. The reason was that we cared about that particular Node beyond the context of a single iteration cycle that processed the Node in hand. That is, we had to know about it because we might need to return to it later after some arbitrary amount of processing. If the scope where we care is very narrowly defined, then we may not need a dedicated association.
• Commonality of superset. This refers to whether there are multiple contexts that require a subset of a particular set. If those contexts lead to different subsets, then the differences in desired subsets can be handled by selection within the more general constraint defining the set from which they are all extracted. Thus we might want one subset of Students taking a Course who are honors students and another subset of Students taking that Course who major in the Course’s Department. The subsets differ, but they are all derived from the same set of Students taking a particular Course. If the superset is already well constrained it may not be worthwhile to raise small differences in subsets to the level of associations.
• Consistency of selection. Here we mean that the same subset is always accessed from a given context. When a Student’s grades are requested, it might be for Irving Frumpkin or Xerxes Trickleingens. That is, the particular member or subset of members varies from one navigation to the next for the same collaborative purpose. This sort of thing cannot be reasonably expressed as a structural participation because it is inherently dynamic.
In the end, though, choosing between additional associations is largely a matter of judgment. The key idea here is that the decision has nothing to do with performance. The choice should be made on the basis of which approach seems to have the best fit to the problem space for the problem in hand.
Constraints
Association constraints provide an additional limitation on the participants in a connection. This is actually just an alternative to expressing selections. The presence of an association constraint simply limits the connectable instances to a subset of those implicitly available based on the association roles, conditionality, and mutiplicity.
The UML supports the Object Constraint Language (OCL) to specify general constraints on associations. OCL enables us to provide a constraint at the attribute level. For example, we can restrict the association from Department to Student to include only students whose grade point average qualifies them for some special honor, like Dean’s List recognition. Such a constraint depends upon the value of a GPA attribute, not the identity of the Student.
Such constraints are almost always inherently dynamic because attributes change over the life of the participants. Thus a Student may join or leave the Dean’s List based on a single new Course grade. In MBD, all dynamic constraints on associations are dealt with in AAL. In other words, the relevant rules of dynamic constraints are encoded when the association is instantiated or as WHERE conditional clauses on association navigations. So in MBD, OCL is only needed to describe static constraints on associations in the Class diagram. Since static constraints beyond those in roles are quite rare, we are not going to talk about OCL at all, other than the very special situations that follow.
One fairly common constraint on * associations is that the collection is ordered. This is indicated by attaching the {ordered} qualifier to an association. All we care about is that the collection is somehow ordered. (This is similar to 1 versus * for multiplicity; different classes of implementations are required for ordered versus unordered collections.)
The second fairly common static constraint is related to association loops in the Class model. It is quite common for associations to form loops. Consider Figure 10-8 again. The set of associations A2, A3, A4, and A5 form a loop, so we could navigate from Student to Course via A3 → A2 → A4 or via A5. The interesting question is: Do we want to reach the same objects when navigating both paths from a given Department?
In Figure 10-8, the answer is no because there is no constraint requiring that. When we navigate A5, we get the set of Courses for which Students majoring in the Department have registered. When we navigate A3 → A2 → A4 we get the set of Courses that the Department’s Teachers teach. But there is nothing to prevent a Student from registering for a Course in a Department that is not the Student’s major. So typically we will reach a significantly larger subset of Courses navigating via A5 than we get navigating via A3 → A2 → A4. For the problem as stated, that is quite reasonable.
But what if we were only interested in Courses taught by the Department? That might be true if our problem were simply to correlate Student performance versus various Teachers within the Department. Now we don’t care how many Courses the Students majoring in the Department take outside the Department, so we would exclude them from the A5 collection as if they didn’t exist when we instantiated A5. In that case we would expect to reach exactly the same classes via both routes, right?
Not quite, Grasshopper. It is possible that a Teacher teaches a Department Course that is attended only by Students that are not Department majors.19 We really do need to think these sorts of things through. However, the real problem here is worse than that. Associations are instantiated at the object level. Therefore, what we really need to consider is the situation when we have a particular Student, say Irving Frumpkin, and we want the Courses so we can compute his average. When we navigate A5, we get only the Courses Irving is taking. But when we navigate A3 → A2 → A4, we still get every Course taught by every Teacher in Irving’s Department even though we started with only Irving.
The bottom line? In this problem space with these associations it just isn’t reasonable to reach exactly the same Course objects via A5 versus A3 → A2 → A4 when we start from Irving. So when would we have such a constraint? The short answer is that we have such constraints when they are in the problem space.
In the situation of Figure 10-12, there is a problem space constraint that the pool of possible jury members for trials in a district must be registered voters of that district. There is another problem space constraint that says that Trials are presided over by a District Judge. Now if we are in a given District, say Eastern Middlesex County, we can get to a set of Jurors navigating A3 or navigating A2 → A4 → A5. Either way, we always get to exactly the same set of Jurors—because the problem space requires that.
Figure 10-12. Association loop constraints requiring navigation to the same set of objects via either path

We designate that static constraint with “[equal, A2, A4, A5]” that qualifies the A3 discriminator. We read this to mean we get to the same set via A3 as we would get via A2 → A4 → A5. Now let’s make a small change in the Class diagram and substitute Voter for Juror, as in Figure 10-13. Is the constraint still valid?
Figure 10-13. Association loop constraints where the set of objects reached on one path must be a subset of the objects reached along another path

Now we can have Voters who are not empaneled on juries due to age, infirmity, or whatever. So the set we get navigating A2 → A4 → A5 is a subset of the set we obtain by navigating A3, and the constraint is incorrect. This is another somewhat common situation.
Association Classes
We’ve already talked about these classes in Chapter 3 and when discussing definitions and notation here. The goal here is to talk about their importance when they are not simply a placeholder for a special implementation. If their only significance was to be such a placeholder, they would be superfluous because that is implicit in an association with *:* multiplicity.
The interesting situation exists when there is a real problem space entity that logically has the responsibility for understanding the rules and policies of connection. For *:* associations those rules and policies are likely to be fairly complex, so it is likely that such an entity exists. That’s because most problem spaces are pretty well organized around notions like divide-and-conquer, centralization of responsibilities, and separation of responsibilities. So *:* connections are usually converted to two 1:* connections in the problem space. (We will talk about such conversions in more detail shortly.)
The value of including Association classes lies in encouraging the developer to think about the problem space rather than specifying the implementation.
We should always look for a problem space entity that logically captures the referential integrity rules and policies for the connection. The degree of attention devoted should be similar to that devoted to properly identifying association roles.
As an example, let’s revisit the University example assuming our software has something more interesting to do than simply get Course grades onto Transcripts. Then it may become relevant that Students can take multiple Courses at the same time and Courses may be taught by more than one Teacher, as indicated in Figure 10-14.
Figure 10-14. Model expanded to deal with *:* associations
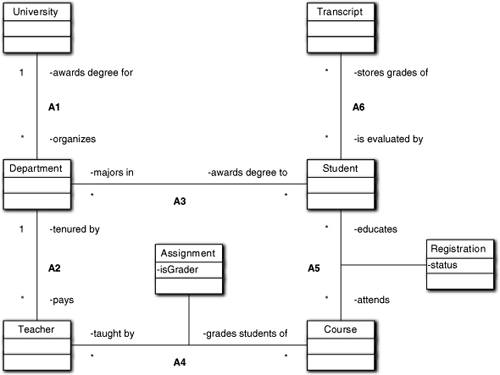
The first thing to note is that we could easily find a problem space entity for the Student ↔ Course association because most universities require Students to register for each Course they plan to attend. So there is probably already an appropriate concept like course registration that captures the bureaucratic details. It is somewhat trickier to come up with a problem space entity for Teacher ↔ Course. But if we think about how teachers are matched up with courses in practice, we find that they are assigned there by a department. So there is likely to be a notion of faculty assignment in the problem space.
In fact, Department itself might be the associative object. There is no rule that an associative object can’t have associations with other classes. Nor is there any rule that precludes Department from having a direct association with Teacher in addition to its role in assigning Teachers to Courses. Such associations are related to Department’s other responsibilities in the problem solution.
The second thing to note is that both these entities are quite conceptual. This is very common with association classes because there is usually some problem space activity for assigning each individual connection. That activity needs to be abstracted into a class, probably through anthropomorphization, and conceptual entities are pretty useful for that.
When looking for problem space entities for Association classes, look for activities related to forming the connection, and then seek a conceptual entity that would logically abstract that behavior.
The third thing to note is that the entities have interesting properties abstracted from the problem space. Thus, because most universities allow students to take courses as “listeners” rather than for credit20 (i.e., they sit in on lectures but don’t do the homework or exams), we have the notion of a Status for the connection. Similarly, we have can have different flavors of teachers for a course, such as lecturers and teaching assistants, so we can have interesting properties associated with those connections as well.
In other words, the Association class highlights the fact that there are real properties associated with connections themselves, rather than the classes being connected. When a student takes one course as a listener and another for credit, that difference can only be captured as an element of the particular connection. Moving the notion of “status” into the Student or Course would be ambiguous.
Alternatively, one could provide multiple associations between Course and Student; one for the set of Students taking the Course for credit and another for the set of Students taking the Course as listeners. That is a valid solution but it has the disadvantage of rigidity. If one subsequently adds the notion of pass/fail versus A–F grading as an option, one will have to create a new association and explicitly provide rules and policies for instantiation. However, if the notions of status and grading policy are captured as attributes, then the static model’s associations are unchanged because all that is modified are knowledge responsibilities. This segues to the next point about Association classes.
The most important thing to note is that the Association classes can add substantially to our understanding of the problem space and the solution. In providing a better model they also help to isolate the connection rules and policies so that the application processing will be simpler. Though it is inappropriate to talk about dynamics here, note that with this model it is a whole lot easier to envision what the code might look like.
Look for Association classes for any association.
Like beer and breakfast, Association classes are not just for *:* associations. They can qualify any association where special knowledge or activities are associated with the connection instantiation that can be isolated in a problem space entity. If they exist, then including them will usually provide better insight into the solution. Of course, Association objects are relatively uncommon for 1:1 or 1:* associations. That’s because the rules and policies of participation are usually simpler.
Reification
Because *:* associations are usually complex, it is desirable to try to manage this complexity through the principle of divide-and-conquer. One way to do that is to convert the single *:* association into two 1:* associations. This conversion is known as reification. The general structural transformation is shown in Figure 10-15(b).
Figure 10-15. Reification of a *:* association to two 1:* associations
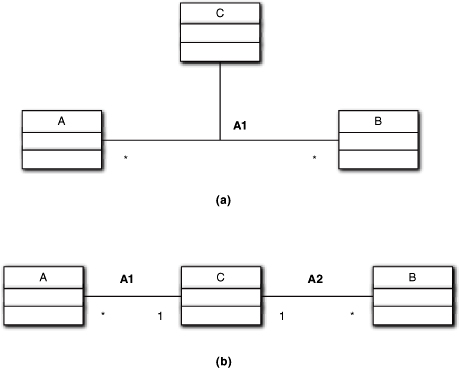
In the reified model the * multiplicity could be on either end of the relationships, so in theory we have four possible combinations of 1:* associations in the reification. Choosing one depends upon how we want to think about the simplification. Figure 10-15(b) shows the most common approach where there is a C object instantiated for each A object and a separate C object instantiated for each B object. Each C represents a collection of Bs or As, respectively. During OOP we might implement C as a private embedded collection object within the A or B implementation.
Note that the association class, C, becomes an “ordinary” object in the reification. Since the OOA is about problem space abstraction, we would want C to be an identifiable problem space entity that is consistent with whatever view of multiplicity we chose. So we would not do an explicit reification in the OOA unless C could abstract an identifiable problem space entity. Essentially, we would leave any reification as an exercise for the transformation engine when there was no underlying problem space entity.
In fact, we rarely do reifications in the OOA model at all, even when the association class abstracts real a problem space entity. That’s because the choice of multiplicities is usually an optimization issue (e.g., performance and heap resources). We only do explicit reifications in the OOA model when the problem space already makes the choice of 1:* associations—that is, when the problem space structure already uses one particular combination of association multiplicities. In that case, we make the reification explicit because we want to emulate exactly what the problem space does. So the main purpose in bringing up reification was to demonstrate that there is a convenient mapping the transformation engine can use.
Identifying Associations
Look for obvious associations first.
This seems to be belaboring the obvious, but it is surprising how quickly a team gets into arcane debates about obscure associations. It is usually a good idea to initially put any association that can’t be agreed upon with a couple of minutes’ debate into the Parking Lot21 and look for another association to define. When the obvious ones where consensus is readily found are done, we go back to the others. Quite often the team finds that the obvious associations provide the necessary navigation paths once they are all in place.
If use cases are available, they provide a very good starting point for looking for “obvious” associations. Select a couple of use cases that represent the most basic functionality or the most common usage of the subject matter. The associations that will be navigated for those use case collaborations are very likely to be the ones most critical to the subject matter.22 That is, those are the ones where it is most important to properly capture the problem space.
There are two reasons why we want to do the obvious or most critical associations first. One is that they are easy, which builds team confidence and gets the team into the zone. A far more important reason, though, is that such associations have a high probability of being correct interpretations of the problem space simply because everyone readily agrees about them. As such, they provide a good foundation as elements of more complex paths. That will help in determining what other associations are necessary and what their characteristics (roles, conditionality, multiplicity) are.
While the order in which associations are discovered is pretty straightforward, identifying individual associations is not quite so easy. When we look at a railroad train schedule with arrival/departure times for a bunch of stations, it is fairly clear that there exists some sort of connection between pairs of stations—especially when we are already aware that railroad trains run on tracks. In most problem spaces there is no tangible connection between entities like railroad tracks, so we need to infer connections between stations by the sequence in time. Even when a tangible connection exists it may not have anything to do with the logical connection we need to make. Therefore, railroad tracks may be a useful cue to station connection for train-routing software, but they might be largely irrelevant to a solution that thinks of an end-to-end connection in terms of trip duration where total distance, maximum speed, and number of stops may dominate.
Once we get past the easy associations, the key to recognizing associations lies in understanding why we care about them. While an association represents a mundane structural description of how members of sets may be connected, the crucial issue is why we care that members of sets are connected. We care because they are used in collaborations between objects that are necessary to solve the problem in hand. Associations provide an overall structure to ensure that the right objects collaborate. Therefore, when trying to identify associations, we need to understand what associations will provide the best constraints on object access. So we usually look at finding the tough associations from the perspective of known collaborations.
Basically it all comes down to answering two questions:
- Which classes need to collaborate?
- Which objects within those classes need to collaborate?
The first question is about responsibilities and direct collaborations between them. We need the same kind of view of high-level collaboration that we employed in determining what entities to abstract and which of their properties to abstract. Let’s “walk” through the reasoning for some of the associations in our University example to see how this works.
If our collaboration in the previous University example is to determine honors students for a department, we know that Department, Student, and Transcript will somehow be involved in the collaboration. It is a megathinker view of the collaboration because we don’t need to know exactly how the collaboration works; all we need to know is what groups of entities are actually involved.
It is the second question that determines the associations, because it implies constraints on the collaboration. In the honors example we know a subset of Students is involved. Implicitly, our knowledge of the problem space requires that the subset be of Students who are degree candidates in a particular Department. We also know the collaboration requires that the Transcript grades for the Students meet the honors criterion, which will further limit the set’s Students.
The natural association of Department with Students enables us to substantially limit the subset of Students provided that association is limited to Students majoring in the Department. As a sanity check we ask: Does that restriction make sense in the problem space? Yes, it does, because Students register as majoring in the Department. (The association between Student and Transcript is obviously 1:1 so that it is constrained as much as possible.)
So far this level of analysis involves a lot of selection (e.g., on grades) that is dynamic in nature. What we need to do is step back and look for the structural or static characteristics of the connections. The selection of honors students is a special case of the more fundamental connection between Department and Student. That connection already limits the association to Students who are degree candidates for the Department. A priori we have no way of knowing which degree candidates will qualify for honors; that will be determined dynamically by the grades in Transcript. But we do know that we can only consider Students who are degree candidates through the Department.
That constraint defines the roles for the association. Multiplicity and conditionality are now relatively easy to determine from the problem space. A Student is a degree candidate for one and only one (at our University) Department. The Department must have at least one degree candidate to justify its existence, and to be viable it needs many. Similarly, we know that each Student must have a Transcript, and a Transcript contains only the grades for a single Student.
Now we can double-check our associations by doing a mental “walk” through the honor roll collaboration’s use case. Assuming we start in Department, can we determine the degree candidates? Yes, they are defined by the association. Can we determine each Student’s grades? Yes, because we can reach the right Transcript through the unambiguous association connecting the student in hand to the right transcript.
Whoa! In my alma mater, honors were granted based upon overall cumulative rating and grades in the courses of the degree program. Grades in courses outside that department didn’t matter except through the minimum cumulative rating. No big deal. There will probably be a cumulative grade point average (GPA) attribute in the Transcript that is updated whenever a new grade is added. This just introduces another constraint on which grades in the Transcript need to be looked at by the department honors committee. That means Course is also a participant in the collaboration, and it will be quickly determined that Department has a connection to the Courses that it alone administers.
Note that we didn’t deal with the detailed dynamics of the collaborations to define the associations. All we care about is who is involved and how the participants are constrained. We don’t care about particular messages, detailed behaviors, or sequences of operations. The last is a particular pitfall when employing use cases because they are organized by sequences of steps.
Look for collaboration connections in the use case steps, not the sequence of steps.
An obvious question is: Why not have a dedicated association between Department and Student just for honors Students? We would just do the same Transcript checking of all Students majoring the Department to instantiate that association with only honors Students. The answer to the question lies in recognizing that instantiating the association is the stated problem’s solution.
Now the commonality of superset and consistency of access that we talked about earlier comes into play. If this were the only use case, then it would be correct to have a dedicated association. As we expand our view to other use cases, such as those already discussed, we will probably find that different use cases access the common superset of the Department’s Students to obtain different subsets of Students for the use case context.
Make sure the connection is identifiable in the problem space.
This is essentially your sanity check on associations. The roles that are assigned to an association should make sense to a domain expert without explanation. This means that they have to be recognizable notions that are easily anthropomorphized. In order to identify the obvious associations it is useful to check the requirements and the problem space for descriptions of things that represent explicit connections. The sorts for things to look for are
• Physical connections. These are things like railroad rights of way, highways, and Ethernet cables that have significance to the problem. Typically they will be abstracted to something more generic like {precedes, follows} for a specific problem. However, a physical connection worth mentioning in the problem statement will almost always represent some kind of association that we need to capture.
• Contracts. Often there are implicit or explicit contracts between different sorts of entities in the problem space that are dictated by standards, laws, or other explicit obligations. Thus an association between Company and Employee has merit because of the concrete manifestation of an employment contract in the problem space.
• Explicit relations. These are most readily recognized by explicit relational vocabulary in the problem statement that effectively describes a role. Be alert for verbs like “has,” “owns,” and “uses.” Also watch for verb-preposition phrases that imply associations like “defined by,” “interprets for,” and “sends to.” In fact, any time the problem statement connects two different sorts of entities through some kind of verb, the odds are good there is an important association between them.
• Explicit selections. These are most readily recognized through explicit constraint vocabulary in the problem statement. These are often reflected in adjectives and adverbs that limit which members of a set of entities, like “largest,” “flagged,” and “past-due.” Associated phrases that provide a comparison threshold or select on a property value, like “more than fifty,” “all blue or green,” and “only ripe,” usually indicate a specific association exists. The trick here is that not all selections warrant a unique association. We want the minimum set of associations needed to solve the problem in hand. We may need to step back and seek out a more general connection for which the specific selection is a special case (e.g., the notion of commonality of superset).
• Whole/part. Clearly, entities that are part of another entity have a logical connection to it. Thus a Wheel may be identifiable on its own merits with unique responsibilities, but if we are assembling vehicles on an assembly line it is also a part of the Vehicle.
• Specification/dependency. Any terminology like “specifies,” “initializes,” “causes ...,” “gets ... from,” and “provides ... to” usually indicates some sort of logical dependency or specification connection.
Examples
For these examples it becomes simpler to display the diagram and then discuss the reasoning behind the way the associations were defined. The commentaries in the following tables are intended to capture the kind of thinking the development team would exercise. However, we will focus only on the simple associations because we haven’t gotten to the chapter on subclassing yet.
The ATM Controller
Figure 10-16 is the most recent version of the ATM Controller Class model. You will note that the associations broadly reflect the sorts of collaborations we discussed when identifying classes and their responsibilities. The collaborations are reflected in the roles that we assign to the associations. This enables us to “walk” use case scenarios through the diagram to provide a sanity check that our structure is sufficient to solve the problem.
Figure 10-16. Preliminary Class diagram for ATM Controller
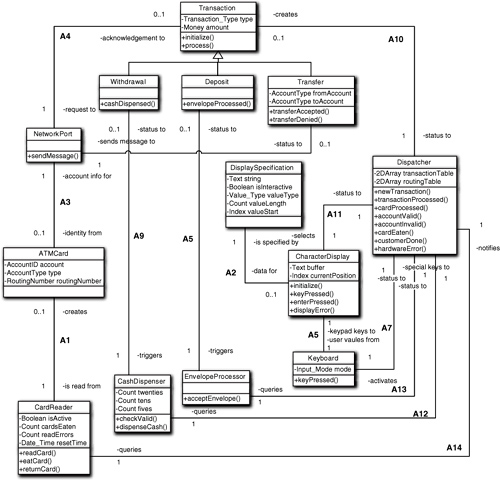
For example, a customer ATM card is inserted into the Card Reader. The Card Reader reads the data, creates a Card instance (A1), and notifies the Dispatcher (A14). The Dispatcher announces this to Character Display (A11) who puts up a welcoming screen and reports back to Dispatcher (A11), who activates the Keyboard (A7). The Keyboard then dispatches customer keystrokes to either Character Display (A6, if they are from the keypad) or Dispatcher (A7, if from dedicated keys). This dialog continues until Dispatcher knows what sort of transaction the customer wants.
Dispatcher then creates the appropriate Transaction subclass (A10) and transfers control to it with the relevant data obtained from Character Display. Transaction initiates a dialog with the bank via Network (A4), who gets addressing information from Card (A3). The Transaction also needs to obtain data (e.g., the amount) from Character Display (A10 + A11). At the appropriate point in the dialog, the Deposit or Withdrawal objects will collaborate with Envelope Processor (A5) or Cash Dispenser (A9), respectively. When the Transaction is complete, Dispatcher is notified (A10) and the Transaction instance is deleted. Dispatcher then collaborates with Character Display (A11) to ask the customer if there is another transaction. If so, the process is repeated. Otherwise, Dispatcher cleans up by initializing the Character Display (A11), deactivating the Keyboard (A7), and notifying Card Reader (A14) that the customer is done so that Card Reader can return the card and delete the Card instance (A1).
The reason we went through this scenario “walk” is to demonstrate something we talked about repeatedly in this and the previous chapters—the level at which we think about collaborations. (Until now we hadn’t covered enough stuff to demonstrate it effectively.) We’ve said that we must be careful to keep our view of collaboration at a high level, and that is reflected in the earlier paragraphs. There is no identification of specific messages; in fact, some collaborations are explicitly described as collections of messages.
Nor does the description get into detailed behavior. For example, we only need to know that Character Display keeps track of characters from the Keyboard for specific input fields in a display buffer. That is sufficient for the collaboration between Transaction and Character Display. The fact that Transfer needs two values while Deposit and Withdrawal only need one is not of interest at this level, so we don’t care how that is handled. Similarly, the entire networking and accounting protocol between Transaction and Network is blithely dismissed as a single protocol despite complexities like two-phase commits (see Table 10-2).
Table 10-2. Association Descriptions for the ATM Controller

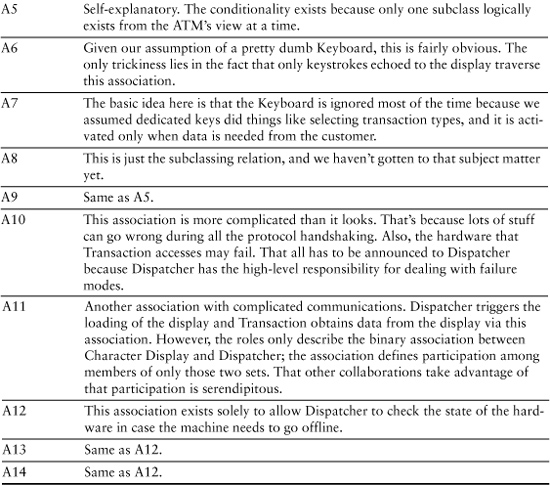
Pet Care Center: Disposition
Table 10-3 describes the associations for the Disposition subsystem. (The full Class model is shown in Figure 10-17.)
Table 10-3. Association Descriptions for the Pet Care Center
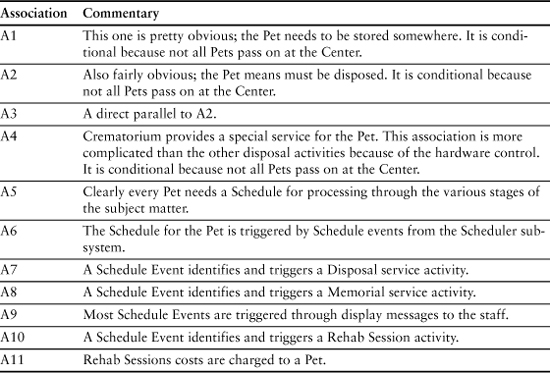
Figure 10-17. Preliminary Class model for the Pet Care Center’s Disposition subsystem
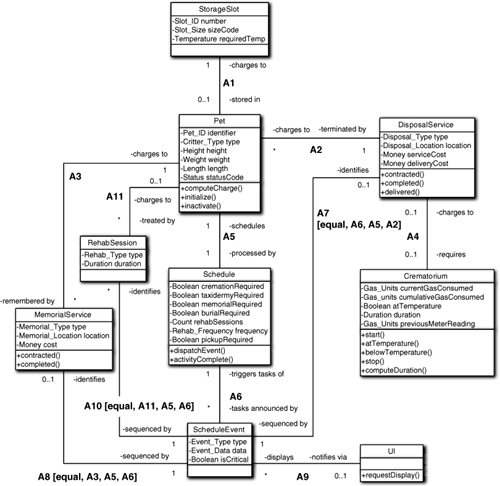
The striking thing about the Class diagram is the “spider web” configuration of associations around Pet. That figures, because a Pet is the center piece of the subsystem and everything revolves around it. However, that is particularly true here because of the event-driven nature of scheduling activities. The real work in the subsystem is done when Scheduler dispatches its events to the right objects. Since an event is about a particular Pet, that addressing essentially is done by navigating paths that are spokes radiating from Pet.