
Chapter 2. Object Technology
The real danger is not that machines will begin to think like men, but that men will begin to think like machines.
—Sydney J. Harris
Structured Development (SD) revolutionized the way software was developed. It provided a systematic approach to software construction much more in line with the techniques more mature engineering disciplines regularly used. SD enabled much larger applications to be built much faster. By the late ’70s it was becoming clear that despite being a boon to productivity, SD had some glaring weaknesses; those weaknesses were discussed in Chapter 1.
At the same time, OO methodologists were noting that an interesting side effect of the OO paradigm was that applications tended to be more maintainable. So around 1980 the emphasis on OOA/D switched gears in a subtle way. Until then the methodologies were primarily focused on expressing designs in terms compatible with the new OOPLs. They devised graphical notations of OOPL constructs, and their methodologies were geared to expressing basic design concepts in those notations.1 But around 1980 the methodologists started to emphasize how OOA/D could be used to address the specific weaknesses of SD.
The remainder of this chapter is an overview of OO development at the executive summary level. We start with some basic elements of the construction philosophy underlying the OO paradigm. Then we move on to specific mechanisms and techniques that address the SD problems. The goal is to provide context by discussing how the OO paradigm addressed some of the problems of the hacker and SD eras. Most of the major features will be discussed in greater detail in later chapters.
Basic Philosophy
The OO paradigm is rather sophisticated compared to previous software development approaches. It is not very intuitive in a hardware computational sense, so it requires a mindset that is rather unique. The paradigm is also comprised of a number of disparate concepts that need to play together. Here we will identify the fundamental notions that will be glued together in Parts II and III.
Maintainability
In the ’70s there were a number of empirical studies of how software was developed. Two stunning conclusions came out of those studies.
- Most software shops devoted over 70% of their development effort to maintenance.
- The effort required to modify an existing feature often required 5 to 10 times more effort than developing the feature originally.
Clearly something was wrong with that picture. In the late ’70s this became the software crisis, and the academic discipline of software engineering was introduced to address it.2 At that time software engineering was primarily devoted to fixing SD to address the problems; if everyone just did SD right, then the problems would go away.3
After 1980 the primary goal of the OO paradigm became application maintainability. The OO gurus looked at the root causes of the problems (as described in Chapter 1) and decided that fixing SD was not viable. There were systemic problems like functional decomposition and marriage to hardware computational models that could not be fixed with a Band-Aid approach. Not surprisingly, the OO gurus saw the OO paradigm as the path out of the maintainability wilderness. So OOA/D methodologies sought to ensure that maintainable software could be constructed.
Maintainability is the primary goal of OOA/D.
Some wags have paraphrased Vince Lombardi4 by saying maintainability is the only goal. Productivity for original development is very near the bottom of the list of goals. On the other hand, productivity for maintenance is very high on the list. Reliability is also high on the list because one of the main reasons traditional maintenance required so much effort was that the changes themselves were so complex they inserted defects. Everything in modern OOA/D is focused on providing more robust, maintainable, and reliable applications.
As a corollary, a fundamental assumption of the OO paradigm is that requirements are volatile over the life of a software product. If that is not the case, as in some areas of scientific programming, the OO paradigm may be a poor choice for development.
Problem Space Abstraction
Nobody likes change.
Developers don’t like change because it means they need to maintain legacy code rather than moving on to wonderful new challenges. As it happens, the customers of software don’t like change either. When change occurs in their domain, they will try to accommodate it in a way that will minimize disruption of their existing infrastructure (i.e., the processes, practices, policies, standards, techniques, and whatnot that are part of how they handle day-to-day operations).
When change filters down to the software as new requirements, it will be easier to incorporate if the software structure mimics the customer’s domain structure.
This is a fundamental assumption underlying the OO paradigm. Essentially it assumes that all change originates in the customer’s domain and must be dealt with there prior to defining new requirements for existing software. The customer will take the path of least resistance in accommodating that change in the customer domain. So the customer will have already done much of the work of accommodating the change as a whole before it filters down to the software. If the software structure accurately reflects the customer’s domain structure, then the customer will have already done part of the developer’s job.
These notions about change are why the single most distinctive feature of the OO paradigm is problem space abstraction. No other software construction methodology uses abstraction to anywhere near the extent that the OO paradigm uses it, and the OO paradigm is the only one that emphasizes abstracting noncomputing domains.
A major goal of the OO paradigm is to emulate the customer’s domain structure in the software structure.
Very few customer domains are computing space domains; therefore those domains are not based on hardware computational models. They are enormously varied and rich in conceptual material. They are also very complex, much more so than typical computational environments. That complexity, variation, and richness would overwhelm any attempt at literally emulating it in the software.5 So we need some way of simplifying the customer view and emphasizing the structural elements that are important to the specific problem in hand.
The design tool that does that is abstraction. Abstraction is ubiquitous in OOA/D. It is the primary tool for capturing the customer’s domain structure. We will revisit problem space abstraction later in this chapter for an overview of mechanisms and come back to it throughout the rest of the book.
OOA, OOD, and OOP
In Chapter 1 it was noted that SD introduced two new steps, analysis and design, into the software development process. The goal was to provide stepping-stones between the customer space and the computing space that would lose less information in the translation of customer requirements to software implementation. The OO paradigm provides similar stepping-stones, but places a very different spin on what analysis means.
In SD, analysis was a hybrid of high-level software design and problem analysis. Many SD authors referred to it as problem analysis—determining what the real problem to be solved was. The OO paradigm assumes that one does problem analysis when one elicits and analyzes requirements. That is, problem analysis is a prerequisite to requirements specification because we can’t specify requirements for a solution unless we know what the problem actually is. So object-oriented analysis (OOA) is quite different from SD analysis.
OOA results in a full solution for the problem’s functional requirements that is independent of particular computing environments.
In the OO paradigm, the OOA represents the customer’s view of the solution because problem space abstraction expresses it in terms of the customer’s domain structure. Because the OOA is expressed purely in customer terms, it can only address functional requirements. (Addressing nonfunctional requirements like size, performance, and security necessarily depends on how a specific solution is implemented.) As such, it is independent of the particular computing environment where the application will be implemented. Thus OOA is a true stepping-stone representing a problem space solution that is more readily mapped to the customer requirements. But because we use a notation that is based on the same underlying mathematics as the computing space, that customer view is readily elaborated into a computing solution.
OOD is an elaboration of an OOA solution that resolves nonfunctional requirements at a strategic level for a specific computing environment.
The definition of object-oriented design (OOD) is also different from that of SD, but less so. OOD is an elaboration of the OOA solution that deals explicitly with nonfunctional requirements at a strategic level. It specifies a high-level design view of the solution that accommodates fundamental characteristics of the local computing environment.
OOP is an elaboration of an OOD solution that provides tactical resolution of all requirements at the 3GL level.
Object-oriented programming (OOP) resolves all requirements at a tactical level (e.g., specific languages, network protocols, class libraries, technologies, and whatnot).
Note that the definitions of OOA, OOD, and OOP are more rigorously defined than their counterparts under SD. More important, there is a clear separation of concerns—functional versus nonfunctional requirements and customer space versus computing space—that is designed to manage complexity in large applications better.
Subject Matter
All OO artifacts—subsystems, objects, and responsibilities—represent some recognizable subject matter that exists in the problem domain. The term subject matter is difficult to define. The dictionary definition is that it is something to be considered or discussed, which is just a tad vague. But that simplistic definition does capture the notion of thinking about what the subject of an abstraction is. It also captures the very common team practice of developing abstractions by consensus. But this still comes up short in describing a rather rich concept.
A subject matter defines and bounds the thing, tangible or intangible, that is being abstracted.
Alas, this definition, in its generality, is only slightly more focused on the OO paradigm than the dictionary definition. The problem is that the definition has to be readily mapped into the potentially infinite variety of customer problem spaces. But at least this definition introduces the notion that an abstraction must have clear boundaries, which is important to functional isolation, encapsulation, and separation of concerns. In the interest of providing more insight into the notion as it relates specifically to objects, it is useful to describe a subject matter in terms of the following qualifications.
• It has a cohesive set of intrinsic responsibilities relevant to the problem in hand.
• It is characterized by a unique suite of rules and policies.
• It is defined at a particular level of abstraction.
• It is readily identifiable by experts in the problem domain.
• Its boundaries are well-defined by experts in the problem domain.
• It is logically indivisible at the context’s level of abstraction. (We will have more to say about logical indivisibility shortly.)
We do not model or code subject matter per se, largely because of the difficulty and ambiguity in defining it. Instead, we describe it in terms of obligations to know or do things. If everyone who touches a subsystem, object, or responsibility does not have a clear and consistent understanding of the subject matter (i.e., what it is), then inevitably there will be trouble. If you could only supply carefully crafted external documentation of one thing in an application, it should be subject matters.
Separation of Concerns
This is actually one of the more important concepts in the OO paradigm. The basic idea is that we should manage complexity through divide and conquer. Essentially, we manage complexity by decomposing the problem into smaller pieces that are more easily dealt with. This is not an original idea by any means; the functional decomposition that was central to SD did exactly this. What the OO paradigm brings to the table is a unique marriage of decomposition and a flexible view of logical indivisibility that is enabled by different levels of subject matter abstraction.
The OO paradigm essentially provides us with more tools for managing separation of concerns than SD did in the two-dimensional, hierarchical functional decomposition of sequences of operations. As a practical matter, there are four basic elements to separation of concerns in the OO paradigm.
- Cohesion. Any concern is a cohesive concept that has well-defined scope and boundaries. Thus the notion of managing inventory is a cohesive concept in most businesses.
- Subject matter. We can associate the concern with a specific, identifiable subject matter in some problem space. There is a body of rules, policies, data, and whatnot that one can associate with a subject matter called inventory management. Though conceptual, it is readily identifiable, and any domain expert will understand the subject matter semantics.
- Isolation. We can encapsulate the concern using standard OO techniques. In the case of inventory management, the scale would dictate encapsulation at the application or subsystem level.
- Decoupling. We separate the subject matter from other subject matters and minimize dependencies on the details of how it works across boundaries.
Note that the definitions of OOA, OOD, and OOP earlier are a good example of separation of concerns at the methodological level. The line in the sand between OOA and OOD separates the concerns of functional versus nonfunctional requirements. It also separates the concerns of the customer’s domain from those of the computing domain. Separation of concerns is applicable all the way down to the responsibility level. As we shall see later in the book, responsibilities must be cohesive, logically indivisible, and intrinsic. That is just another way of saying that they represent a separation of very specific concerns away from other concerns.
Levels of Abstraction
Long before the OO paradigm, the idea of layering in products often conformed to the notion of levels of abstraction. The lower layers tended to be more detailed and less abstract with very specialized behaviors. Meanwhile the higher layers were more general and abstract with broadly defined behaviors. SD’s functional decomposition provided a similar sort of ordering of levels of abstraction.
In software construction, there is a succession of abstract views as we move back from the 3GL program model, as indicated in Figure 2-1. As we move from top to bottom, we move from greater abstraction to lesser abstraction as more and more Turing detail is added. The nature of classes from OOA through OOPL code will also tend to move from abstract problem space abstractions like Customer to concrete computing space abstractions like String.
Figure 2-1. Levels of abstraction in a typical OO development process. Abstraction decreases as we move down and more computing space detail is added. Each stage above “Load” provides a model of the actual computer instructions. Those models are a specification of the problem solution at the next lower level of abstraction. At the same time, every stage’s output is a solution for the model specification of the previous stage.
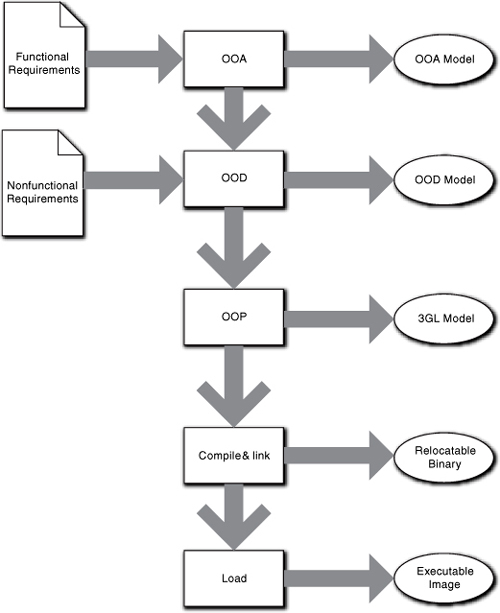
These stages represent quite different views. Thus the OOA represents a customer view of the solution and only addresses functional requirements while the OOD view is a computing space view that resolves nonfunctional requirements. Similarly, the Loader view of the problem is devoid of customer semantics while providing a view as close to the hardware computational models as one can get in software. Since the OO paradigm is based largely on abstraction, it figures that we should be able to use that to our advantage. As it happens, methodologically the OO paradigm employs levels of abstraction to assist in everything from defining overall application structure to dependency management.
Probably the most important application lies in defining overall program structure. While the original OO paradigm provided lots of tools and ideas, MBD has refined the notion of abstraction for this purpose more than any other OO methodology. We will talk about this in detail in Chapter 6. For now just keep in mind that a subsystem defines a level of abstraction, and all objects that implement that subsystem should be abstracted at that level of abstraction.
Problem Space Abstraction
At the core of all OO methodologies is the identification and abstraction of entities in some customer domain.6 Those entities must be readily identifiable, but they can be either concrete, such as Car, House, or Person, or they can be conceptual, such as Contract, Law, or Obligation. In most customer spaces entities can be quite complex with multiple properties or characteristics. But those characteristics will be explicitly associated with the entity by the customer.
The primary task of problem space abstraction is to identify entities in the problem space and their properties that are relevant to the problem in hand.
We call the abstraction of such an entity an object. So the basic notion of an object as a bundle of properties associated with an identifiable entity is a direct result of problem space abstraction designed to emulate the customer domain’s structure.
If we look in an unabridged dictionary for a definition of abstraction, we find three distinct definitions. The first captures the idea of extracting particular characteristics. The second describes it as a conceptual generalization of the common essence of similar concrete things. The third captures the notion of a summary. The notion of abstraction in the OO paradigm has aspects of all three of these definitions. In the end, though, abstraction modifies reality and there are five ways that abstractions can modify reality.
- Eliminate characteristics. Real entities usually have a large number of characteristics. Often many of these are simply not relevant to the problem in hand; for a dogcatcher facing a growling dog, knowing whether the dog is housebroken is merely a distraction.
- De-emphasize characteristics. Another way to simplify abstractions is to just de-emphasize characteristics rather than eliminate them entirely. The criteria used to identify the different groups of critters in a phylum can be quite complex (e.g., warm-blooded, egg-layer, etc.). If we don’t care about the details of the classification scheme, we could have a single attribute, Critter Type, where we provide values of “platypus” or “aardvark.” In doing so, we have de-emphasized the entire classification scheme context to a single type descriptor.
- Generalize characteristics. Sometimes the characteristics of individual instances have minor variations that are not important to the problem in hand. In this case we wish to generalize the characteristics in the application so that the differences disappear. If an application is printing a poster depicting the various snakes in the southeastern United States, it probably doesn’t matter much that there are three broad classes of venom that help distinguish certain snakes for herpetologists. Poisonous versus nonpoisonous is probably good enough.7
- Emphasize. An abstraction can select parts of the customer’s problem space entity and place special emphasis on them. A metric for a process, such as defect rate, can usually take on values across a wide range. However, if we are doing statistical process control, we are only interested in whether or not a value lies within a predefined envelope or range. In that case we might decide to substitute a Boolean attribute for defect rate samples whose values represent In Control and Out Of Control. We are still viewing defect rate values, but a crucial aspect of that metric has been emphasized.
- Coalesce characteristics. Abstraction is not limited to objects. It can be applied to the characteristics that comprise those abstractions. The idea here, though, is to extend the notion of generalization to capture multiple characteristics as a single abstract characteristic. A classic example of this is the mathematical notion of a complex number that contains both a real and an imaginary part. Most problem solutions that deal with complex numbers can be described without ever having to deal with the individual real and imaginary parts. In those cases it is fair to abstract the complex number into a single, scalar “value” in the OOA/D models.8
The last issue concerning abstraction is where they come from. The simple answer is that they come from the problem space. They represent entities in the problem space. So what is an entity? The following definition is useful.
Entity: An entity is a real thing, possibly intangible, that is readily recognized as distinct by experts in a particular problem domain.
The entities from which we form abstractions may be concrete things, concepts, roles, or anything else in the problem space. The key aspect is that it is perceived to be a cohesive, identifiable thing by the gurus of the problem space.
All entities and their object abstractions have unique identity.
This is a corollary to the notion that domain experts perceive the entity to be distinct. Each entity must be somehow uniquely identifiable, and each object abstracts exactly one such entity from the problem space. The notion of identity conveniently maps into the more rigorous set theory that underlies the OO paradigm and UML.
So what happens when we have an inventory bin full of 6-32×1 cap head screws? Does each screw have a name? Hardly. But an individual screw is still identifiable, if for no other reason than being the one picked from the bin. A DBMS will get around this problem by providing an artificial identity (e.g., an autonumber key) for each item. The OO paradigm has an even more subtle means of dealing with implied identity through relationships. Thus objects can be identified based on who they are associated with. For example, we might break up the notion of automobile into distinct objects like body. If the Automobile object is identified by a unique VIN number, then the body object may be uniquely identified as the only one associated with a particular, explicitly identified Automobile.
Encapsulation
One of the first problems attacked was hiding implementations so that other program units would not trample on them. In SD this was done through APIs, but they were usually only applied to large-scale program units. The OO paradigm formalizes the notion of implementation hiding through encapsulation; thus all implementations are encapsulated behind interfaces. The OO paradigm just made the notion of encapsulation so fundamental that it was applied to all abstractions.
An abstraction incorporates two views: an internal one for describing how the abstraction works, and an external one for describing what the abstraction is about.
The combination of abstraction and encapsulation enabled a separation of semantics (what an entity was contractually responsible for knowing or doing) and implementation (how the entity knew or did it). The interface provides the external view while the stuff behind the interface provides the internal view. Thus the role of the interface subtly changed from a mechanism to provide module boundaries to a mechanism for hiding details.
Cohesion
In Chapter 1 we indicated that SD did not provide adequate guidelines for ensuring cohesion for application elements. That is, there was no systematic approach to cohesion. The OO paradigm provides a very systematic approach and uses cohesion explicitly as a design tool. Specifically, the OO paradigm depends on the problem space to provide cohesiveness. Thus objects are cohesive in that they provide a bundle of related properties that are unique to a specific entity in the problem space. A reviewer of an OOA model will always ask, “Will a domain expert easily recognize this object and be able to describe what it is just from the name?” Similarly, object properties are individually cohesive because they represent intrinsic, logically indivisible, and separably identifiable properties of a particular problem space entity in the problem space.
Cohesion maps to distinct problem domain entities and their unique properties.
This linking of cohesion to what is recognizable as distinct (entities) and logically related (the properties that characterize them) in the problem space is one of the unique contributions of the OO paradigm.
Logical Indivisibility
Another rather unique feature of the OO paradigm is the emphasis on logical indivisibility. In traditional functional decomposition, only the leaf functions at the base of the tree had to be logically indivisible. In practice, such functions were usually one level above 3GL language operators like “+” and “-”. That was because one decomposed until there wasn’t anything left to decompose.
The OO notion of logical indivisibility is much more flexible because it depends on the level of abstraction of the problem and individual subsystem subject matter. Different OO methodologies recognize somewhat different levels of logical indivisibility.9 MBD recognizes four fundamental levels of logical indivisibility:
- Subsystem. A subsystem is a large-scale element of an application based upon encapsulating the functionality associated with a single, large-scale problem space subject matter. A subsystem is implemented with collaborating objects.
- Object. An object abstracts a single identifiable entity from a subsystem subject matter’s problem space. An object has responsibilities to know and do things. Objects are abstracted in a manner that is consistent with the level of abstraction of the containing subsystem’s subject matter.
- Object responsibility. An object responsibility represents a single, fundamental unit of knowledge or behavior with respect to the problem in hand. The responsibility is defined at the level of abstraction of the containing object’s subject matter.
- Process. To describe the dynamics of behavior responsibilities one needs to express problem space rules and policies in terms of fundamental computational operations. These can range from arithmetic operators to complex algorithms defined outside the problem space in hand. A process is one or more cohesive operations on state data that are logically inseparable at the containing behavior responsibility’s level of abstraction.
The OO notion of logical indivisibility means that the abstraction is self-contained, intrinsic, and cohesive such that there is no point in further subdivision at the given level of abstraction. That is, in any solution context the abstraction can always be contemplated as a whole. The OO paradigm then encapsulates that abstraction behind an interface so that its more complex implementation is hidden.
The power of flexible logical indivisibility probably isn’t very obvious at the moment and you are wondering why such a big deal is made out of it. To see its utility you need to get some more methodological ducks in a row. However, an example might help to make the point. The author once worked with a very large device driver (~ 3 MLOC). In one high-level subsystem there was a single object knowledge attribute that was represented as a scalar data value at that level of abstraction. In that subsystem we were dealing with flow of control at a very high level and didn’t care about the details. In a subsystem at a lower level of abstraction, though, that “value” expanded into more than a dozen classes, thousands of objects, and on the order of 109 individual data elements. It cannot be overemphasized how useful it is to be able to think about such complexity as a simple scalar knowledge attribute when dealing with high-level flow of control.
This flexible notion of logical indivisibility allows us to essentially “flatten” the functional decomposition tree so that we don’t have tediously long decomposition chains. It also allows us to create different solutions by simply connecting the dots (behavior responsibilities) differently. We see examples of this in later chapters.
Communication Models
The world of Turing is inherently serial because one instruction is executed at a time and instructions are ordered. The reality is that things like distributed and/or concurrent processing are no longer limited to R-T/E. The simplistic days of batch processing in data processing systems are long gone. Today’s software is interactive, distributed, interoperable, concurrent, and so on. Today’s problems are inherently asynchronous. If one is building large, complex applications, one has to deal with it.10
In OOA/D behavior responsibilities are accessed asynchronously.
That is, it is assumed that a behavior responsibility can be triggered independent of the execution of any other behavior responsibility. In addition, there may be an arbitrary delay between the time the trigger was generated and the response is actually processed. In other words, one cannot count on a behavior responsibility executing serially in a predefined order immediately after some other behavior executes.
We will have a lot more to say about this in Part III on dynamic descriptions. For the moment all you need to know is why this is the case. The reason is that an asynchronous communication model is the most general description of behavior. If one can solve the problem under asynchronous assumptions, one can implement that solution as-is in any implementation environment: serial, synchronous, asynchronous, and/or concurrent. It may not be easy and one may have to provide a lot of infrastructure, but one can always implement it without modifying the solution logic. It is beyond the scope of this book to prove it, but that is not necessarily true for serial/synchronous solution designs if one tries to implement them in a truly asynchronous or concurrent environment. If one starts with a synchronous description and tries to implement in an inherently asynchronous environment, such as a distributed system, one may have to modify the solution logic in order to implement it correctly.
As R-T/E people can testify, getting an asynchronous communication model to work is not easy.11 But once it is working, it will tend to be quite stable and fairly easy to modify. More important, though, is that the OOA author does not need to worry about the details of concurrency and whatnot when forming the solution. The OOA model will Just Work no matter where it is implemented.
Knowledge is always accessed directly from its source when needed.
What this means is that when a behavior responsibility needs data to chew on, it goes directly to the data owner and gets a fresh value. In effect this means that we assume knowledge access is synchronous (i.e., the requesting behavior responsibility will pause until the knowledge is acquired). This assumption is necessary if one assumes asynchronous behavior communications in order to preserve developer sanity.
Message data is knowledge that represents a snapshot in time.
This corollary essentially means that in well-formed OO applications messages rarely have data packets because behavior responsibilities access the data they need directly.12 This is in marked contrast with the traditional procedural context where procedures usually have arguments. If one employs an asynchronous behavior communication model, one cannot assume the data passed with the message will not become obsolete because of the arbitrary delays. So the only reason to pass knowledge in messages is because one needs the data to be bound to a specific point in the solution flow of control. An example of such snapshots might be data from multiple sensors that needs to be processed together from the same sampling time slice.
But if we know the implementation will be synchronous, why bother? Because what we know today may not be true tomorrow. If we create the OOA solution with a synchronous model and some future change in the deployment environment moves a subsystem or some objects onto another platform, we want that change to be relatively easy to implement. What we don’t want is a shotgun refactoring of the flow of control. If one does the OOA solution right in the first place, that will never be a major problem later when the implementation environment changes.
As a bonus we will find that the added discipline in the OOA model will make it more robust and easier to modify when the functional requirements change. One reason is that the scope of access of data is limited to the method needing the data. Procedures provide a very convenient scope boundary in the computing space. That simplifies data integrity issues because one sees what data is accessed and when it is accessed within the method scope. But if data is passed one is necessarily concerned with where and when the data was acquired, which extends the scope of data integrity concerns back up the call stack to wherever the data was acquired.13
Breadth-First Processing (aka Peer-to-Peer Collaboration)
In Chapter 1 we discussed SD’s depth-first, hierarchical functional decomposition and some problems associated with it. Again, objects save the day. Since objects have self-contained implementations due to abstraction, encapsulation, and logical indivisibility, they allow breadth-first communications. This is because if you tell an object to do something, it does it, and then it is finished because it is logically indivisible and self-contained.
From its clients’ viewpoint it is atomic; an object is a single identifiable entity. Therefore, the important flow of control in the application is described in terms of object interactions (in OO terms, collaborations). This raises the level of abstraction of flow of control considerably. In fact, as we will see later in the book, when defining collaborations, one doesn’t really care which object responsibilities are involved; the message is viewed as a collaboration between objects rather than between responsibilities (i.e., the receiving object selects the appropriate behavior for the message using its current internal state).
The value of the breadth-first paradigm shows up during application maintenance, particularly when debugging problems. Unless you have tried it, it is hard to imagine how powerful this approach is. In the author’s experience when developing software like this, about two-thirds of the bugs fixed were diagnosed by inspection in a matter of minutes. In equivalent procedural code it was more like one-fifth.
In the first pilot project the author ever did with the OO paradigm, the hardware guys were using the software as a diagnostic tool to figure out how the hardware should really work. So the hardware was changing underneath the software on essentially a continuous basis. We could usually have a hardware change correctly implemented in software before the hardware guys could finish breadboarding it.
Just as we completed that pilot project, Marketing changed the performance requirements. To meet the new requirements we had to completely rework inter-task communications from shared files to shared memory and make fundamental changes to things like the way the hardware was initialized. We turned those changes in a week.14 That totally astounded everyone familiar with the project because it would have taken a couple of months to do it if the application had been written procedurally like our other drivers up to that time. (The Marketeers had already fallen on their swords and told the customer privately that there would be a few months’ delay based on past performance for similar changes!)
Another way of describing breadth-first flow of control is to say that collaboration between objects is on a peer-to-peer basis. At each point in the solution, the next action to be performed is triggered by a message that passes directly from the object raising the trigger condition to the object having the response. There is no indirection or middlemen involved in the collaboration. That is a direct result of abstraction combining with logical indivisibility to ensure that each behavior is self-contained.15
Elaboration versus Translation
Elaboration is characterized by a succession of stages—OOA → OOD → OOP—for developing the application where the developer adds value directly to each stage. The OOA is incrementally elaborated with strategic detail related to the computing environment until one has a completed OOD. At that point the OOA no longer exists. Then the OOD is incrementally elaborated with tactical detail to provide an OOP solution. This was the classic way OO applications were developed through the late ’80s.
In contrast, the translationists draw a very sharp line in the sand between OOA and OOD. They preserve the OOA as an implementation-independent, abstract solution to the customer’s problem. They then use a full code generator (known as a transformation engine) to translate the OOA into a code model (3GL or Assembly). The transformation engine essentially automates OOD and OOP.
The main advantage of the elaborationist approach is that everyone knows how to do it. One downside is a tendency to mire down in design paralysis because there is no clear criteria for when the OOA or OOD is completed. Another downside is that when porting to another computing environment, one can’t separate the customer’s problem solution from the implementation elaborations. Also, it is necessary to invest in dependency management refactoring during OOP to make the 3GL program maintainable. And to preserve copies of the OOA/D models for posterity, one is faced with multiple edits for maintenance changes. But the biggest price is the redundant effort in providing implementation infrastructure that is reinvented for every application. In a typical 3GL program at least 60% of the code will be devoted directly or indirectly to particular technologies (e.g., XML) and optimization techniques (e.g., caching) that address nonfunctional requirements or tactical 3GL solutions. That code essentially gets reinvented for each application.
There are several advantages to translation:
• It separates the problem space solution logic from the implementation issues in the computing environment, allowing one to focus on these two problems separately. In practice this means that functional requirements (OOA) are resolved independently from nonfunctional requirements (OOD and OOP). This promotes specialization between application problem solving and implementation optimization.
• It allows the same OOA solution to be ported to different computing environments without change and with complete confidence that the problem solution logic still works.
• It allows a one-time effort to develop a transformation engine in a given computing environment. That transformation engine can then be reused to translate every application OOA to be run in that environment. In effect one has massive OOD/P design reuse across applications for a given computing environment.
• The exit criteria for completion of OOA is unambiguous because the OOA model is executable.16 It is done when the tests for functional requirements pass.
• No dependency management refactoring is needed since only the OOA models are maintained as requirements change, and physical coupling is a pure 3GL problem.
• The OOA solution is roughly an order of magnitude more compact than a 3GL solution, which greatly improves communication and comprehensibility by focusing on the essential elements of the solution.
Alas, there are some disadvantages to translation:
• The computing space may be deterministic, but it is also enormously complex. So providing adequate optimization in transformation engines is nontrivial; building a transformation engine in-house is not recommended. As a result, today’s commercial transformation engines tend to be pricey. It took from the early ’80s to the late ’90s to develop optimization techniques to the point where translation code was competitive in performance with elaboration code. That is a substantial investment to recover.
• The OOA model must be very rigorous. Code generators do what one says, not what one meant, so the developer must use a good analysis and design methodology. Winging it is not an option, and the developer needs to learn about things like state machines because they provide the necessary rigor.
• Moving from traditional elaboration to translation is a major sea change in the way a shop develops software. Processes for everything from configuration management to test development will be affected because one essentially has a different set of development stages.
As indicated in the Introduction, MDB is a translationist methodology. The author believes that translation techniques are as inevitable as the conversion from Assembly to 3GLs in the ’60s. Automation in the computing space has been inexorable since the ’50s. When the author started out, his first program was on a plug board, FORTRAN and COBOL were academic curiosities, linkers and loaders were just appearing, and BAL was the silver bullet that was going to solve the software crisis. We’ve come a long way since then. Translation has already been institutionalized in niche markets, such as HPVEE and RAD IDEs for CRUD/USER processing. It is inevitable that general-purpose 4GLs will supersede the 3GLs.
However, the design principles of this book’s methodology apply equally well to elaboration as they do to translation. Developing an application OOA model with MBD will lead to a highly maintainable application, and it will be a complete, precise, and unambiguous specification for the remaining elaboration stages. In other words, an MBD OOA model is what elaboration developers really should be providing anyway but rarely do.
The Message Paradigm
To be able to hide the implementations of knowledge and behavior, one needs a shield behind which those implementations can lurk. Thus every object or subsystem has an interface that hides its implementation. The notion of interfaces is hardly new.
That the OO paradigm employs them at the fine-grained level of objects is interesting, but not cosmological in importance. On the other hand, one of the most profound differences between the OO paradigm and other software construction approaches is the way interfaces are implemented.
An interface defines a collection of messages to which an entity will respond.
This concept was what the OOA/D deep thinkers came up with to address a bunch of disparate problems. In so doing, they made the construction of OO software fundamentally unique and completely changed the way a developer thinks about constructing software.
Objects would communicate by sending each other messages, and the receiving objects would select some behavior in response to that message. This neatly decoupled the sender of the message from the receiver because the sender did not have to know anything about how the receiver would respond. This was potentially a very powerful and versatile approach. For one thing, in OOA/D a message can be quite abstract, representing with equal facility the setting of an interrupt bit in hardware, a timer time-out, or clicking a GUI control. For another, it allowed the receiver considerable latitude in responding. The receiver might respond to the same message with different behaviors depending upon its internal state. Or the receiver might ignore the message in some situations. Basically, this was a really good idea provided the sender of the message had no expectations about what would happen in response to the message.
Messages are not methods. Messages are the class interface while methods are the class implementation.
This separation of message and method was the reason the why the OO view of interfaces led to a very different way of constructing software. Traditionally in SD’s functional decomposition, higher-level functions invoked lower-level functions that were extensions of the higher-level function’s obligations, so the higher-level function expected what would happen. Since specifications of the descendant functions were subsets of the higher-level function’s specification, the higher-level function not only expected what the lower level function did, it depended on it. Thus the fundamental paradigm for navigating the functional decomposition tree was Do This, as we saw in Chapter 1.
But in the OO paradigm, the fundamental paradigm is peer-to-peer collaboration among logically indivisible entities and behaviors such that we can change the solution by simply reorganizing where messages go without touching the method implementations. Now messages become announcements of something the sender did: I’m Done. The announcement dovetails with DbC so that a message simply announces that some particular condition now prevails in the state of the solution.
As we shall see in Part III, this enables DbC to be used to rigorously define correct flow of control by matching the postcondition of the method where the message originates with the precondition for executing the next method in the overall solution’s flow of control. Effectively, we have a poor man’s formal methods to ensure correct flow of control.
In addition, we have excellent decoupling because all the message sender needs to know is what it did. Thus if all the message sender is doing is announcing something it did, it needs to know nothing about the responder. Similarly, since the receiver simply responds to a message, it doesn’t need to know anything about the sender of the message. This drastically reduces coupling because the only shared knowledge is the message and its data packet.
The way methods in the OO paradigm are designed stems from methodological techniques for problem space abstraction. Those techniques ensure cohesive, logically indivisible, and self-contained responsibilities. But those techniques all assume the notion of I’m Done flow of control as an alternative to the Do This flow of control of SD. That is, the OO message paradigm ties everything together and without it those techniques would have limited utility. While problem space abstraction may be the most important distinguishing characteristic of the OO paradigm, the message paradigm is a very close second.
Before we leave the message paradigm it should be pointed out that MBD places more constraints on the message interface than other OO methodologies. At the object level in MBD almost all messages are simple knowledge requests or state machine events. One implication of this is that these interfaces are pure by-value data interfaces. This means that MBD explicitly prohibits the more egregious forms of coupling, such as passing object references to behavior methods.
Object Characteristics
This topic provides an overview of the basic building blocks of the OO paradigm. The word object is overloaded. The Dictionary of Object Technology has no less than seventeen formal definitions, and its discussion of the term covers fourteen pages.17 To avoid that level of ambiguity, this book is going to stick to one set of definitions that is generic enough to avoid a lot of controversy:
Class. Any uniquely identified set of objects having exactly the same responsibilities. The class itself enumerates the set of shared responsibilities that all its members have.
Object. An abstraction of some real, identifiable entity in some problem space. The underlying entity may be concrete or conceptual. The object abstraction is characterized by a set of responsibilities. Objects with exactly the same set of responsibilities are members of the same class.
Instance. An object that is instantiated by software in memory (or indirectly in a persistent data store) during execution of a problem solution.
Responsibility. Abstracts a quality of a problem space entity as an obligation for knowledge (to know something) or an obligation for behavior (to do something). In the OO paradigm there is no direct way to express notions like purpose; such problem space qualities must be abstracted in terms of knowledge and/or behavior responsibilities. The underlying reason for this restriction is to provide an unambiguous mapping to the set, graph, and other mathematics that define the computing space. For example, a knowledge responsibility can be conveniently mapped into the notion of state variables, while behavior can be mapped into the notion of a procedure.
The relationships between these elements is illustrated in Figure 2-2. Customer space entities like Dick and Jane have unique qualities that we can abstract in objects in our conceptual design space. Those objects correspond directly to Dick and Jane. Since those objects have exactly the same sorts of abstract properties, we can group them in a class set. That class captures the notion of person from the customer domain. Eventually we will need to instantiate those objects in software at runtime as instances. Those instances will have concrete representation in memory locations where the properties become binary values.
Figure 2-2. The relationship between entities, objects, classes, and instances. Entities have qualities that are abstracted as object properties. Objects with the same property sets form classes. Objects are instantiated with specific values in computer memory.
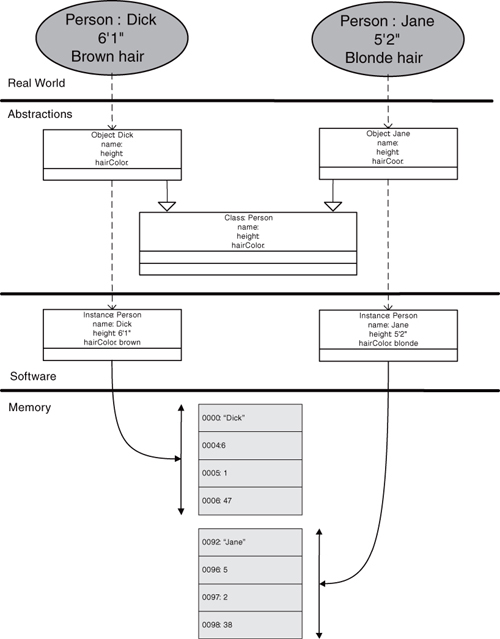
Probably the most controversial definition just given is for instance. Many authors use object and instance as synonyms. In MBD we find it useful to distinguish between the conceptual design abstraction (object) that exists in the design whether the application is executing or not and the memory image (instance) of the abstraction at runtime. Usually objects are instantiated dynamically based upon the immediate context of the solution, and that instantiation has obvious importance to when things happen in the solution.
Attributes
Attributes define the knowledge for which each object of a class is responsible. The operative word here is responsible. Attributes describe the knowledge that any object of the class can be expected to provide or manage. A common misconception is that attributes represent physical data stores. Usually they do, but that is a coincidence of implementation because knowledge is commonly mapped to data in the computing space. For our purposes here, attributes simply describe what the instance must know, not how they know it. That is separate from the value of what a specific object knows. Individual objects in a class set can have quite different values of a given attribute, or they may coincidentally have the same values for the attribute. The values of attributes depend solely on the identity of the owning object.
Methods
A method implements a specific behavior responsibility that all instances of a class must provide. Each method of a class is an encapsulation of particular business rules and policies for a particular behavior. Traditionally, the method name is used as a shorthand description to describe what the behavior is while the method body hides how that behavior is actually executed.
The OOA/D only specifies what behavior responsibilities should do, not how they do it.
A behavior responsibility can be quite complex even though it is logically indivisible at the owning object’s level of abstraction. To specify what a behavior method should do we need a special language that can specify such things in an abstract fashion consistent with the rest of the model. Therefore, we need an Abstract Action Language (AAL) that is designed to be a specification language rather than an implementation language.18 While the syntax of most AALs is intentionally similar to that of 3GLs, they are really quite different things, as you shall see in Chapter 18.