
Chapter 11. Referential and Knowledge Integrity
You can’t get there from here. If you could, it would be too late.
—Old Borscht Comedy Circuit punch line
Referential integrity is essentially about making sure we access the right objects during collaborations. Knowledge integrity is about ensuring that any knowledge accessed is timely and consistent. While referential integrity applies to either behavior or knowledge collaborations, knowledge integrity is only concerned with knowledge access. In addition, referential integrity is about who participates in a collaboration, while knowledge integrity is about what is accessed and when it is accessed.
This all sounds quite straightforward, but in practice it has historically generated a great deal of angst. Methodologically, MBD defines assumptions and practices that greatly reduce the problems associated with integrity. The assumptions and practices most relevant to integrity have already been discussed in passing in prior chapters.
• Knowledge access is assumed to be synchronous, and operations access knowledge directly on an as-needed basis.
• Behavior access is asynchronous.
• All objects have unique identity.
• The static model (Class diagram) should be normalized.
• Collaborations are peer-to-peer using I’m Done messages.
• Behaviors are encapsulated as cohesive and logically indivisible operations.
• Finally, the transformation engine (or elaboration OOD/P) is primarily responsible for enforcing knowledge and referential integrity.
The last point is particularly important because it really drives how we construct an OOA model. The MBD construction practices ensure that the transformation can enforce knowledge and referential integrity in an unambiguous fashion. Thus, we are usually not consciously concerned about those issues when constructing the OOA model because the way we construct it largely defers those issues to the transformation engine.
In this chapter we will examine how these things play together to ensure that the OOA model can be implemented in a manner that enforces knowledge and referential integrity. We will also discuss a few common situations where the application developer must explicitly think about these issues.
Knowledge Integrity
This issue is concerned with two things.
- Timeliness. Any knowledge accessed must be current with respect to the context where it is accessed.
- Consistency. The value of any knowledge accessed must be consistent with other knowledge accessed in the context where it is accessed.
Note the emphasis on the context where it is accessed. Knowledge is always accessed by behavior responsibilities or from outside the subsystem. The behavior responsibility (or external actor) provides the context of access. That is why in OOA/D we want a method to access the knowledge it needs directly, rather than depending on other behaviors to provide the knowledge. This direct, as-needed access narrowly defines the scope where knowledge integrity must be enforced; the scope is bounded by a single operation. As we shall see, it also enables us to incorporate timeliness and consistency constraints in DbC preconditions for executing the operation needing the knowledge.
Timeliness
Timeliness relates to when knowledge values are updated within the problem solution context (i.e., at the right point in the solution flow of control). That is, the requirements will tell us when knowledge must be updated, and we just need to connect the flow-of-control dots so that happens before we need the knowledge. This can be resolved rigorously with DbC if we include the need for update in the precondition for executing the operation in hand. (We will discuss that DbC technique in Part III, The Dynamic Model.)
Since we don’t think about things like concurrent processing in the OOA model, all we have to do is connect our behaviors correctly with messages so that we ensure knowledge is updated before it is needed. Usually that is fairly straightforward, and we have a rigorous DbC technique for those cases where it is not. It is straightforward because of the way we abstract behavior responsibilities and connect them with messages. (This will become more clear when we discuss dynamics and “handshaking” in Part III, The Dynamic Model.)
Consistency
The much nastier problem is consistency because there are several potential sources of inconsistency. One common consistency problem arises because of concurrent processing. In a concurrent processing environment there is a potential for someone else to be simultaneously writing the knowledge that we are reading. This is just a variation on the timeliness problem identified earlier in the sense that if someone else writes the value while we are using it, it is no longer current. Exactly the same mechanisms can be used for this sort of concurrency problem that we employ for timeliness problems, and we can make a simple assumption in the OOA:
At the OOA level we assume that no knowledge accessed from the current context will be modified from outside that context as long as the current context is active.
This assumption makes life much easier because it defers the grunt work of enforcement to the transformation engine. Fortunately, as mentioned above, by limiting the scope of the current context, it is actually relatively easy to provide that enforcement.
A stickier problem for consistency arises when multiple bits of knowledge are needed by the same operation. Thus if we have a telephone number that is represented by multiple attributes for country code, area code, exchange, and number, we need all of those attribute values to be for the same telephone. If our timeliness constraint is honored when the operation is invoked, we can be sure they have been updated correctly. If we extend the above assumption to include all the knowledge the operation needs, the problem of race conditions as some of the values get changed while we are reading them also goes away. And as long as our Class diagram is normalized, we can be confident that we got the correct attributes when we navigated to the object owning them. Once again, the way we did problem space abstraction combines with a simplifying assumption so that this kind of consistency usually is not a problem.
Unfortunately, there are a couple of special situations where we need to pay attention: snapshots and dependent attributes.
Snapshots versus Immediate Access
We have emphasized thus far that it is important to access knowledge synchronously when it is needed. When we get around to talking specifically about messages, you will discover that it is relatively rare to have any attribute values in the data packet for a message that accesses a behavior responsibility. Usually the only time that happens is in messages going to or coming from another subsystem. The reason should be fairly clear at this point: We access knowledge directly, so there is no reason to pass it around. We only see knowledge passed around in synchronous services whose job is to deal with knowledge responsibilities explicitly.
But what if the solution wants an historical view rather than a current view? Then we could provide the historical view via message data packets. This sort of situation is known as a “snapshot” view where we collect knowledge responsibility values at a particular point in the solution for later processing. Behaviors operate on those knowledge values as a consistent set even though some or all of the underlying attribute values might have been modified by the time the behaviors actually execute.
This is most commonly manifested in sampling. Consider software that tracks readings from multiple temperature sensors on a mixing vat in a chemical plant. Typically the sensor hardware updates the temperature value every few microseconds. However, vat temperature can’t possibly be regulated in that time frame, so we sample the temperature values and apply smoothing. A fairly sophisticated system might do the smoothing based on multiple complete sets of sensor readings. However, when the sensors are sampled may be a variable that describes the stability of the readings. That is, we sample more frequently when the values are changing relatively quickly, and we sample less frequently when the values are not changing rapidly. Thus the consistency rules are applied dynamically.
It should be clear that solving this problem is likely to require processing sets of temperature values that were recorded before the “current” set of sensor readings. To keep things straight, we will need to explicitly manage which samples are acquired and when they are processed. So the operations chewing on the samples can’t go and get them on an as-needed basis; somebody will have to hand the samples to the operation, and that message data packet becomes a consistent “snapshot” of the state of sampling at a moment in time.
When we must use snapshot message passing, consistency enforcement becomes the application developer’s responsibility.
The transformation engine has limited psychic abilities, so it can’t know when the scope of knowledge integrity has moved beyond the scope of the operation. Therefore, the application developer now owns the problem of knowledge integrity and must explicitly enforce it at the model level. Fortunately, once we realize that a snapshot is required, it is usually pretty easy to collect the snapshot values in a consistent manner.
Dependent Attributes
This is an exceptional situation that appears when a Class diagram is not normalized fully. The situation arises when the values of some knowledge attribute are directly dependent on the values of other knowledge attributes, which is technically a Normal Form violation. The classic case is the equation:
Mass = Volume x Density
Clearly there are situations when an object, such as Birthday Cake, might be logically responsible for knowing all three of these characteristics about itself. That’s fine, but it creates a special knowledge consistency problem because Mass needs to be modified whenever Volume or Density is modified. That’s something a code generator or OOP developer needs to know about so that consistency can be preserved. Therefore, we attach a notational adornment, a back-slash, to the dependent attribute in the class model, as shown in Figure 11-1.
Figure 11-1. Notation for dependent attribute (mass)

The getters and setters are included, which you will recall we normally do not do by convention, to underscore another point. Note that there is no setter for Mass. That’s because we have defined it to be a dependent variable so we can only modify it through its independent variables. This clearly makes sense, because if we attempted to change Mass we wouldn’t know whether to modify Volume or Density or both. So, in addition to signaling the need to address knowledge integrity, the notation also enables the model compiler to detect erroneous attempts to write to the dependent variable directly.
What if the dependent variable is in another object? It seems pretty clear that if all the variables are in the same object, we could simply not provide a data store for Mass; since it can only be read, we could compute it each time get_mass is invoked. But how would that work if Mass is encapsulated in another class? Consider the situation in Figure 11-2.
Figure 11-2. Example of dependent attributes across classes
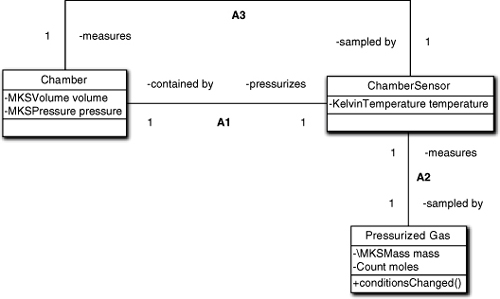
In this case, the Mass of the Pressurized Gas is dependent on variables in two different classes. The computation here is deviously controlled by Boyle’s Law,1 which we need to figure out the density to get the mass. For whatever reason during problem space abstraction, it was deemed important to solving the problem that Pressurized Gas know its mass. That leads to a conundrum because Pressurized Gas needs to access other objects’ attributes to know its own mass.
The “trick” here is that Pressurized Gas can use a data store for the mass attribute; we just need to ensure that it is updated whenever temperature or pressure is changed. We assume that Chamber monitors pressure and Chamber Sensor monitors temperature, both on some unspecified basis, so they need to notify Pressurized Gas when their attribute changes. This will Just Work provided we use synchronous services so that Pressurized Gas’s mass is modified within the same action scope as the independent attribute is modified. That’s because knowledge access is treated as instantaneous, and our unit of scope for knowledge integrity is the single behavior action that does the sampling.
The problem is that we can’t just update mass directly via a setter; we have to be more circumspect about it by notifying Pressurized Gas that something has happened via conditions_changed. That synchronous service is invoked by whatever behavior in Chamber or Chamber Sensor detects the change to pressure or temperature, respectively. Why not just set it directly? The answer lies in separation of concerns and cohesion. To set it directly, whoever does the write would have to understand the formulas for computing it. It is hard to justify Chamber understanding that, much less Chamber Sensor. This leads to two generalizations:
If the independent variables are not in the same object as the dependent variable, the owner of the dependent variable should be responsible for the rules of the dependency.
If the independent variables are not in the same object as the dependent variable, the developer must explicitly provide synchronization.
The first point is just common sense; encapsulate the rules with the knowledge to which they apply. The second point simply recognizes that code generators do not have psychic powers. In the Pressurized Gas example, it is clear there is a lot of stuff going on in the surrounding context and the mass computation itself. That context will very likely provide its own suite of rules and policies for the circumstances when the mass value must be consistent. Therefore, deciding when to update the independent variables and when to notify Pressurized Gas that they have been modified will depend on much more than just the formulas. (We could make a case that the reason the developer is responsible for knowledge integrity here is that the model was deliberately denormalized, which segues to . . .)
Normalization of Attributes
We talked about normalization in Chapter 1, but it is worthwhile reviewing what we need to do to ensure that a Class diagram is in Third Normal Form. This is because normalization is important to knowledge integrity in a variety of ways. The most obvious way is institutionalizing the maxim of one-fact-one-place, which has been enshrined as a Good Practice since the origins of software development. It doesn’t require an advanced degree to figure out that updating information is a lot easier if it is located in one place.
However, there are more subtle reasons for normalization. They involve keeping the information in the right place so that its value is unambiguous, and ensuring that the value is consistent with the level of abstraction. So we are going to “walk” through some of the practical implications of Third Normal Form in this subsection.
1NF. All knowledge attributes should be a simple domain.
This means that the semantics of the knowledge responsibility must be logically indivisible at the level of abstraction of the containing subsystem. If all you need is a string of digits to pass to a phone dialer device driver, then a telephone number is a simple domain. If you are allocating calls to telemarketers based upon country or area codes, then a telephone number is not a simple domain because it consists of several individual elements with unique semantics that are important to the problem in hand.
One of the most common violations occurs when attributes are used for “double duty” to hold normal values or some sort of flag value to represent a special case where normal values are not relevant. For example, we might define a Rectangle object with two attributes for the lengths of the sides, Major Side and Minor Side. However, for the special case of a square, the Minor Side is not relevant, so we might be tempted to provide a value of UNSPECIFIED to indicate the special case.
That’s a 1NF violation because the semantics of Minor Side now has two orthogonal semantic elements: the length of the side and whether the Rectangle is square or not. To see that, note that it would be clearer if we used IS_SQUARE as a mnemonic instead of UNSPECIFIED. In other words, we must understand whether the particular Rectangle is a square to properly interpret the Minor Side length. Therefore, being a square is an important feature of Rectangle that represents a valid knowledge responsibility. That responsibility is quite different than knowing the length of a side, so it warrants its own knowledge attribute.
A variation on this theme is a Position class with attributes of Coordinate1 and Coordinate2 that is used for either polar coordinates (Coordinate1 is azimuth and Coordinate2 is distance) or Cartesian coordinates (Coordinate1 is the abscissa and Coordinate2 is the ordinate). This is extremely fragile because the context of access must somehow know which version of Position it has in hand, which opens the door for virtually unlimited foot-shooting. One fix, of course, is to add an attribute that identifies the coordinate type. But is that legal?
No, it’s not. Adding the attribute does not change the fact that the domain of Coordinate1 is either an azimuth or abscissa coordinate but never both at the same time. The semantics of the value is still not a simple domain because an azimuth is not an abscissa. Whoever accesses that value must view it with different semantics to process it properly. As it happens, this is a very common situation whenever coordinate conversions are required, so we need a way to deal with the problem.
In OO development we deal with the problem through encapsulation. We implement the coordinates in one coordinate system or the other within the object. That implementation always uses a consistent semantic domain. We deal with conversion by providing alternative interfaces, such as get_azimuth, get_distance, get_x, and get_y and let the interface handle the conversion.
If we want to optimize the implementation because the coordinates rarely change compared to the frequency of access, the transformation engine can provide private data stores for azimuth, distance, abscissa, and ordinate in the implementation that are synchronized when one of them changes. However, the public view of the responsibility will still be the generic Coordinate1.
An alternative way of dealing with the problem is through an ADT that combines Coordinate1 and Coordinate2 into a scalar by raising the level of abstraction. Then Position becomes the ADT and it is magically transformed from a first class object into an attribute. There is nothing to prevent us from then providing a descriptor with a type to indicate polar versus cartesian that can be used in manipulations. That’s fair as long as we can manipulate Position without knowing its elements.
This is usually the preferred solution, and it is worth some effort to see if we can’t abstract the clients of the coordinates so that they only need the abstract Location perspective. In effect, we are refining the level of abstraction of the subsystem in this particular context so that Location becomes logically indivisible within the subsystem.
2NF. All knowledge attributes depend on the full object identity.
Basically this means that if object identity is compound (e.g., identity is expressed explicitly in terms of multiple attribute values), then any non-identity attribute must depend on all of the identity attributes, not just some of them. Since many OO developers rarely employ explicit identifiers—much less compound ones—it would appear that this is pretty much irrelevant. Alas, that’s not the case and 2NF is the most common source of Normal Form violations in OO development. In fact, it is because explicit identifiers are rarely employed that such violations are so common; they represent subtle problems that are less obvious without the cue of explicit compound identifiers.
Assume a typical subdivision with multiple house styles and a single prime contractor for each Subdivision. What’s wrong with Figure 11-3? Given the context and the fact that House is the only object shown with attributes, you do not get points for quizmanship by responding, “the attributes of House.” Which attributes are wrong and why?
Figure 11-3. An example of incorrect attribute ownership
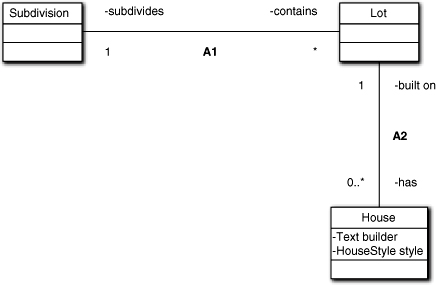
The problem lies with the builder attribute. It depends upon Subdivision, not House, so it belongs in the Subdivision class. While there is a unique builder for each House, the problem space defines the uniqueness of the builder at only the Subdivision level. That is, all Houses within the subdivision are built by the same builder, so associating it with the House is redundant. Contrast that with the notion of style, which is inseparable from House. Let’s look at the same model using explicit, compound identifiers, as in Figure 11-4.
Figure 11-4. An example of using compound identifiers
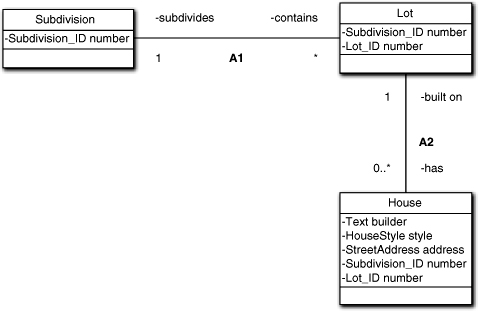
In the diagram, the House address is an alternative identity to the compound identity of {Subdivision_ID, Lot_ID}. The compound identifiers used here are a special case known as derived identifiers. They represent a sort of logical decomposition where classes “cascade” identity from the general to the particular and the domain of individual identifiers is not unique to the class. Thus Lots in different Subdivisions might have the same number, but the lots’ numbers within any given Subdivision will be unique. In this case, House.address represents a unique identifier for any House in any subdivision. In contrast, House.lot_number is only unique within the context of a particular Subdivision, so builder cannot depend on address because it only depends on lot number.
Note that the use of compound, derived, explicit identities makes it quite easy to resolve 2NF issues. We simply “walk” the candidate attribute up the chain of derived identifiers to the point where it is solely dependent on that identifier (or subset of compound identifiers). For this reason we strongly recommend that you provide explicit identifiers for classes in the Class diagram even though MBD doesn’t require them, and you may not otherwise reference them in the model dynamics.
3NF. All knowledge attributes depend on the object identity, the whole object identity, and nothing but the object identity.
Going back to the Position example with an added Type attribute, this is not true because the values of Coordinate1 and Coordinate2 depend upon the new Type attribute rather than the identity of Position. That is, they depend upon another attribute that is not part of the object identity.
Fortunately, this situation is usually pretty obvious if we simply think about it for a moment when looking at the class attributes. It is also easy to fix by brute force. The simple approach is to simply break up the class via delegation.2 In this case the notion of coordinates is pretty fundamental to Position, so it is unlikely we can identify a new class that captures a unique subset of Position semantics in the same sense that we can separate, say, Wheel from Car. So in this case we would probably employ subclassing by converting the Type attribute to a subclass: Position → {PolarPosition, Cartesian-Position}. But that is fodder for the next chapter, so we won’t dwell on it here.
Referential Integrity
As indicated in the chapter opening, referential integrity is about ensuring that we send messages to the right objects. This is largely accomplished by employing the practices established in the previous chapter for instantiating and navigating associations. Those practices can be summarized with two basic ideas.
• Available participants. Constraining the available participants in collaborations is what association instantiation is about. We encapsulate the static rules and policies that determine who qualifies to participate in a logical connection in an object that instantiates the association.
• Selection. When there are multiple potential participants we have the option of selecting one or some subset of those participants. Selection is based upon the properties of the individual participants and is inherently dynamic in nature.
We will deal with selection in Part III, The Dynamic Model. The remainder of this chapter just provides some details related to referential integrity to augment the discussion of association instantiation in the last chapter.
Identity and Referential Attributes
First we need to talk about explicit identity and referential attributes a bit. While we don’t need explicit identifier attributes in a Class diagram, they are often useful in resolving referential integrity issues. That’s because the Class diagram is based on the relational model from set theory, and referential integrity is resolved with those rules. In other words, referential integrity in a Class diagram works as if explicit identity had been used.
However, object identity, when it does appear as explicit knowledge attributes, is somewhat more abstract than in a Data model for an RDB. The object identifier is often better thought of as an abstract handle for the object rather than as a value in a memory data store. Though explicit data values are common for concrete entities in the problem space, such as a customer’s name, they are less common for conceptual entities like Meeting. Whether the identity has a concrete value or not, it is just something that uniquely identifies the underlying problem space entity.
A referential attribute is a knowledge attribute that identifies some other object that participates in an association with the object in hand.
If you are familiar with RDBs, the notion of referential attribute is identical to that in RDB schemas, save for the abstraction of the identity itself. Unlike object identity, we never need explicit referential attributes in a Class model because we rely on the dynamics of relationship instantiation to provide the correct connectivity.3 However, they are similar to association roles in that they can be quite useful for keeping track of what is going on in the model, especially if we are judicious about naming the referential attribute. A good referential identifier name can supplement the association role in clarifying exactly which object is relevant.
As an example, consider a high-rise building where individual elevators are clustered in “banks” of several elevators, as in Figure 11-5. Assuming a pedestrian numeric identification scheme, the first diagram captures the essential elements of the problem space. (All the attributes shown are object identifiers.) Unfortunately, it doesn’t capture the notion of location. Typically, banks of elevators are clustered in different physical locations (e.g., north side versus south side). The second version does that for Bank because location is quality of a bank of elevators. Since it is unique, we can also use it as identity for a Bank. However, a particular elevator doesn’t really care where it is. Therefore, it doesn’t make sense for Elevator to view its bankID identifier in terms of location in the building floor plan. Nonetheless, Elevator.bankID still maps to Bank.location.
Figure 11-5. Options for identity and referential attributes
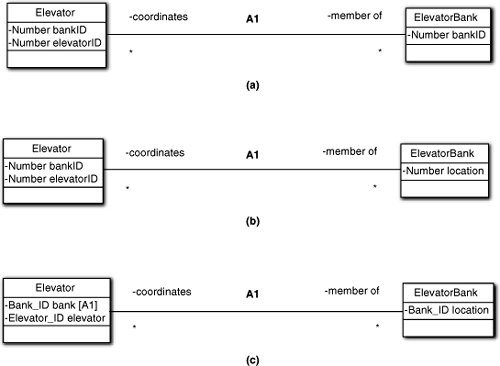
But doesn’t that make it ambiguous (i.e., what the Elevator’s bankID relates to)? In theory, the answer is no because it must map unambiguously to the identifier of a Bank, regardless of its attribute name. In practice, though, there is another problem with versions and parts (a) and (b) of Figure 11-5. The choice of Number as the attribute ADT is not a good one because it is too generic. Thus value of 1 could be either an Elevator identifier or a Bank identifier or a location identifier. More to the point, we cannot use both Elevator identifiers and Bank identifiers together in expressions because they are semantically apples and oranges, but we could use Bank identifiers and Bank locations in expressions since they both identify the same thing. In this simple example we are unlikely to screw that up, but it would be better to use more explicit ADTs, in Figure 11-5(c).
Note the inclusion of the association discriminator with the referential attribute. This indicates unequivocally that the attribute is a referential attribute for the A1 association. That is true even though it is also part of the compound identifier of Elevator. In addition, the correspondence between Elevator.bankID and Bank.location is made clear because of the ADT, BankID, that is unique within each class. All in all, the Figure 11-5(c) conveys much more information about what is going on in the model than the first two examples.
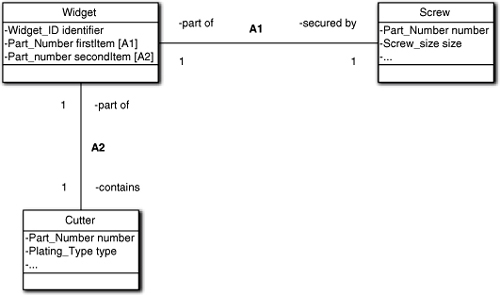
As a somewhat more exotic example, consider Figure 11-6. While the example is contrived to keep things simple, the basic idea is that the PartNumber ADT for firstItem and secondItem is the same, so how do you tell which association they map to? We explicitly indicate that by tacking on the association discriminator. Now it is quite clear what we meant regardless of how we named the attributes or their ADTs. So, we can name our attributes and ADTs to maximize the problem space mapping without worrying a whole lot about the referential mapping.
Figure 11-6. Ambiguity in referential integrity
Association Loops
An association loop is a graph cycle in the Class diagram. Such cycles are quite common in Class diagrams because we define associations as independent binary associations between classes. Since a class may have an arbitrary number of such associations with other classes, graph cycles are common.
Unfortunately, association loops present a problem for referential integrity. When an object from class A in a loop needs to collaborate with an object from class B on that loop, there are <at least> two possible paths to navigate from A to B. The problem is that the constraints on participation of the individual associations along those paths may be different, resulting in different sets of available B participants depending upon which path was navigated.
We’ve already seen the example in Figure 11-7(a) and examined some of the issues, but it is worth reviewing. If we take the association roles seriously, it is clear that the set of Courses we reach by A1 → A2 is not the same as the set we reach by A3 → A4. Though A1 and A3 are explicitly tied to Department, and A2 is indirectly tied to Department, since a Course is taught by only one Teacher (in our example), A4 is not so constrained because a Student can take Courses offered by Departments other than that of the Student’s major. Thus the set of available participants for A3 → A4 is substantially larger than the set of participants reached via A1 → A2.
Figure 11-7. Navigating the correct association in a collaboration
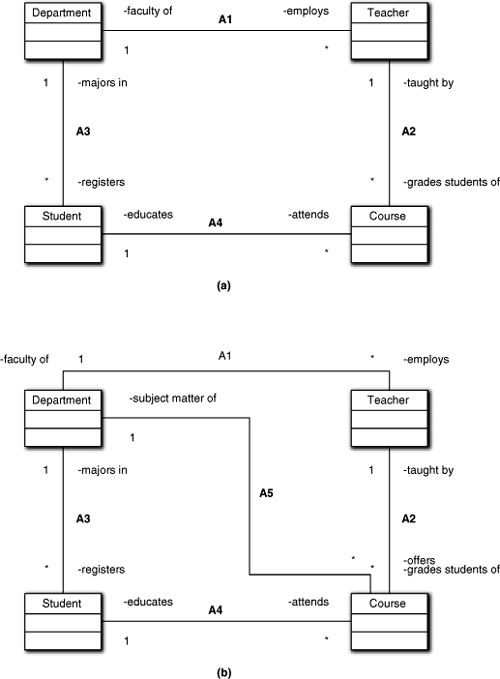
The point here is that association loops provide the opportunity to go awry by navigating the wrong path in a loop for the collaboration in hand. For example, suppose this application exists to prepare a registry of students by department and a registry of courses by department. To do that, some object elsewhere in the application will iterate over Department instances and for each one will obtain a list of the Department’s Students and a list of the Department’s Courses.
Obtaining the list of the Department’s Students is pretty obvious; we navigate A3 because that association essentially defines exactly the desired list as the set of available participants. A careless developer might then continue on to A4 to obtain the list of Department’s Courses since the Department’s Students will be attending the Department’s Courses, right? Oops, now we get all the Student’s elective Courses in other Departments. (We also miss Courses not currently attended by Students majoring in that Department.) Fortunately, that sort of mistake would require pretty epic incompetence for anyone with even a modest amount of problem space knowledge.
Instead, we navigate A1 → A2. Oops, now we get Courses outside the Department where the Teacher is a guest lecturer. This is less obvious, and this sort of arcane problem space detail is the kind of thing that can readily be overlooked when navigating associations.
Be wary of selections based solely upon the static set of available participants.
The problem here is that the associations reflect the problem space quite accurately but the problem itself requires a finer level of selection than just the available participants in the fundamental problem space structure; that is, the selection requires a dynamic adjustment for the particular collaboration. There is a tendency to equate the collaboration selection to the static participation, especially when they are almost the same. This sort of myopia results in navigating A1 → A2 to get the Department’s Courses. The A1 → A2 path is so much better than the A3 → A4 path, making it easy to overlook that it isn’t quite right either.
There are two ways to deal with these sorts of loop problems. We can define a direct association whose static participation is defined to be the desired set. The second example, in Figure 11-7(b), provides A5 to do exactly this. Though reasonable, there is usually a trade-off against diagram clutter if we create an association for every possible collaboration. Generally, we only add such associations when (a) they are critically important to the problem solution, or (b) there is no way to navigate the collaboration using selection on existing associations.
Note the use of “generally” above. As it happens, this is one of the exceptions where we have no choice but to add a direct association. But we need to describe the alternative to demonstrate why.
The second approach is to use selection based upon an attribute of Course. There is no apparent way to use selection on the associations in the example as stated because there aren’t any handy attributes defined. However, it is relatively easy to add an attribute to Course that identifies the Department sponsoring the Course. Now we can navigate A1 → A2 and select conditionally on the basis of the Department associated with the Course being the same as the Department in hand. We could even navigate A3 → A4 and then select conditionally on the same attribute.
This will work quite well without A5, so why do we need a direct association in this case? The answer lies in what the Course attribute really is—it is a referential attribute. That’s because (a) its value is the identity of a specific Department, and (b) its value is meaningless in the problem context unless that particular Department exists. The selection is being based, albeit indirectly, on identity.
If selection is based upon the value of a referential attribute, there must be a corresponding direct association to the referenced class (unless the attribute is part of a derived identity).
That bon mot may seem a tad obtuse, but all it’s really saying is that if we have a referential attribute to another object’s identity, we need a direct association to the other object’s class. That follows from the relational data model because embedded referential attributes exist to define such associations.
But why does this rule exist? The short answer is that it will make the application more robust. We could safely write abstract action language to instantiate Courses with the correct Department attribute value without A5. However, that construction will be fragile when we complicate things with guest lecturers and multiple Teachers for a Course. Those complications may alter where and how we get the Department value. For example, if initially we create a Course only when a Teacher is assigned, we might navigate through Teacher to Department to get the value. That becomes ambiguous if things change and multiple Teachers from different Departments are enabled.
Relational versus OO Paradigms: Worlds Apart
Previously we noted that the way RDB Data Models use relationships is quite different than the way associations are used in OOA/D. But until now we haven’t had enough background to understand differences and their implications. It is important to understand the differences for a couple of reasons. Most software today uses an RDB for data persistence, so we need to know how to bridge the gap between the paradigms. Perhaps more relevant in the context is that a number of converts to OO development from RAD development have sought to migrate common RAD practices to the OO arena because they are familiar.4 That migration rarely ends well, and it is important to understand why.
The relational paradigm5 is very good at storing and finding data in a problem-independent way. It is a general mechanism and is ideally suited to ad hoc navigation of relationships. For example, in a 1:* relationship the relational paradigm places a referential attribute to the 1-side tuple in each *-side tuple. Navigation is very direct from a given *-side tuple to the related 1-side tuple. Conversely, we can always get to all the *-side tuples from a given 1-side tuple by searching the set of *-side tuples for the referential attribute whose value exactly matches the identifier of the 1-side tuple in hand.
That navigation in either direction is completely unambiguous regardless of the problem context, so you can always get to the data you need. More important, it always works for any two piles of tuples related through a 1:* relationship, so it is very general. It is also ideally suited to accessing large piles of related data (i.e., the notion of a dataset of multiple tuples created by a join across tables that selects sets of tuples from each table). That’s because the uniform navigation of relationships makes it mechanically easy to cobble together complex queries that access lots of data in a single access. The key ideas here are
• Relationship navigation is primarily for collecting data aggregates.
• Relationship navigation starts at the table level.
• Relationship navigation is most efficient for accessing sets of tuples.
• Relationship navigation is very generic.
The price we pay for that generality is the *-side search we must conduct when we want to navigate from the 1-side tuple. In principle, that search is through all of the *-side tuples.6
In contrast, in an OO application we are solving a particular problem. To do that we migrate through a sequence of behaviors that are associated with particular objects, so we always have a particular object in hand at any point in the solution. More important, we need to reach the next behavior by sending a message directly to the single object that owns that next behavior. There are several key ideas in this description:
• Collaboration navigation is primarily for sequencing behaviors.
• Collaboration navigation starts at a single object.
• Collaboration navigation is peer-to-peer to a single object.
• Collaboration is about a single object-to-object message.
In a simplistic sense, we can summarize the differences between the paradigms as
The relational paradigm is about finding data while the OO paradigm is about finding behaviors.
The relational paradigm is about managing data while the OO paradigm is about processing data.
While we also navigate associations to obtain knowledge attributes, the primary goal in solution collaborations is to connect the flow of control dots of behavioral processing in the solution. Since we want tailor our solution to the problem in hand, we instantiate associations so that we can navigate from one solution step (operation) to the next with a minimum of difficulty. In other words, we want to use the nature of the specific problem and its domain to minimize searches. This is why associations are instantiated at the object level rather than the class level; it limits the size of the search set in *-side navigations to only those objects that are reachable.
In an application we never want to use relational paradigms like query-based processing unless the problem being solved is CRUD/USER.