
Chapter 16. States, Transitions, Events, and Actions
Choosing each stone, and poising every weight, Trying the measures of the breadth and height, Here pulling down, and there erecting new, Founding a firm state by proportions true.
—Andrew Marvel: The First Anniversary of the Government under Oliver Cromwell
In the previous chapter we dealt with identifying when state machines are necessary and how to recognize object life cycles. In this chapter we will get into the structural details of how state machines are constructed. The structure is the more mechanical aspect of developing state machines, so this chapter will just flesh out the basics that were described in Chapter 14. The goal in this chapter is simply to establish the proper mindset for developing state machines.
States
Recall that a state is simply a condition where a particular set of problem space rules and policies apply. The natural language notion of “state” as a condition of being is actually pretty useful here. The tricky part lies in the fact that there are at least two perspectives on the notion of condition. One perspective is that the object has a state of being, pretty obvious since we are designing object state machines. The second perspective is somewhat less obvious: that the subsystem as a whole has a state of being.1
When discussing the static description of the solution the notion of intrinsic object properties that were independent of particular collaboration context were emphasized. While we selected the entities and responsibilities to abstract based on the general needs of the problem solution, we were very careful to isolate them and think of them in a generic fashion. Alas, as a practical matter we cannot design state machines without considering context. Thus we need to explicitly consider the context of the overall problem solution in terms of the subsystem’s state of being. The important mindset issue, though, is that we should think of the application in terms of conditions rather than algorithmic sequences.
One way this is reflected is through DbC, which enables us to rigorously determine where and when to generate events by matching state preconditions and to other states’ postconditions. But that only works when we have designed the object state machines so that their states are complementary to the big picture of the overall application’s migration through its states. Similarly, the subsystem perspective came up in the last chapter when we discussed how handshaking depends on collaboration context. Those constraints exist only in the perspective of the overall subsystem state of being.
We can consider the overall problem solution as a migration through state machine states. Then each object state machine state should map unambiguously to one state in the overall solution machine at a time.2
The importance of this metaphor lies in two important corollaries. The first is that each state in the conceptual subsystem state machine simultaneously maps to a single state in every object state machine. One can think of the conditions for each object state machine state as a subset of the conditions that prevail in some state of the overall solution, as illustrated conceptually in Figure 16-1. That’s because every existing object with an object state machine is always in some state, and intuitively that state should map to the state of the overall application.
Figure 16-1. Mapping of state machine states to overall solution states. Shaded states are current states of the object state machine. So, by implication, for Object A to be in state S2, the overall solution must have already proceeded to at least state E. Similarly, state S1 must have prevailed from solution states B through D.
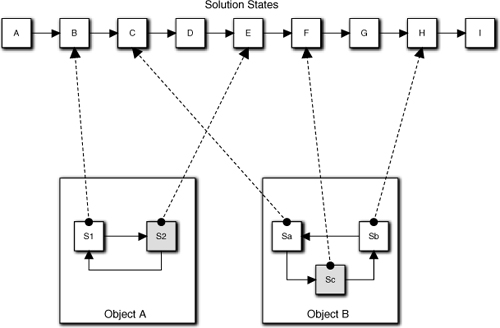
The second corollary is less intuitive. Each state in an object state machine may map to more than one state in the subsystem state machine. There are two reasons for this. The first reason is that we may reuse object behaviors (re-invoke their rules and policies) in different contexts in the overall problem solution. The second reason is related to the fact that we do not continuously execute object rules and policies; they are executed only when the state is entered.
Any object state transition occurs in lockstep with some transition in the conceptual application state machine.
This is really the point of the condition metaphor. There can be no change in an object state machine unless there is a corresponding change in the state of the overall solution. On the other hand, individual object state machines provide enormous flexibility for the solution because their transitions don’t have to map 1:1 with a sequence of transitions in the conceptual subsystem state machine. Thus the same object state machine state can “slide” through a succession of subsystem states because the object is not directly involved with that aspect of the solution; the object stays in the same state while the application migrates through its states. For example, in Figure 16-1, Object A’s S1 state remains the same while the solution migrates through its states B through D. But at least one object FSM will transition whenever the solution transitions to a new state.
To summarize this discussion, the key points are
• Transitions represent changes in the overall solution’s condition.
• Instead of thinking in terms of a sequence of operations, we think of flow of control in terms of transitions between states both at the object level and at the subsystem level.
• Since object actions are triggered by transitions, the proper time to apply a suite of business rules and policies is when something happens in the overall solution to change its state. (This is the basis for the DbC techniques already discussed.)
This notion of migrating through subsystem solution states and object states is critical to MBD because it quite neatly ties together both state variables and algorithmic sequencing in a single concept. So, it is important to consider how state variables enter the picture when mapping object state machines to the overall solution. That is, ensuring that the data is ready is just as important as the sequence of solution operations when determining collaborations and, consequently, identifying states and transitions. For example, in Figure 16-2(a) we have a fairly mundane sampling and filtering controller. Filter1 and Filter2 each process different data from the original samples in Figure 16-2(b). Figure 16-2(c) is a Collaboration diagram for a set of objects that abstract the processing. Figure 16-2(d) is a state machine for the Collector object.
Figure 16-2. Different views of a sensor sampling application: (a) overall block diagram; (b) filtering of separate datasets; (c) collaborations; (d) collector FSM
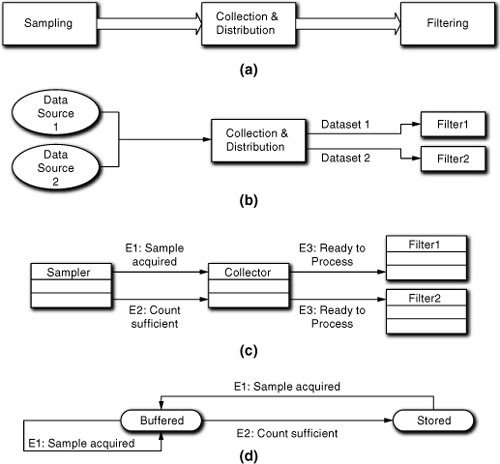
Sampler collects and counts sample values from some hardware in the form of two sets of related but different data as a single overall sample in time. It forwards that sample’s data, one value at a time, to Collector. At the same time, Sampler counts the samples it has acquired. When the count hits a threshold, Sampler generates E2 and resets (Figures 16-2[c] and 16-2[d]). Collector buffers up the data in the overall sample until enough have been collected. At that point it copies the buffered samples to public attributes in other objects as a “snapshot” of the data sampling. Since this is a synchronous knowledge update we are assured that the objects always have consistent data. Collector understands which objects should get which subsets of data from the sample set. Since the filters need to process complete sets of consistent data, Collector notifies them when a new complete set is ready.
This is a quite plausible solution, and many applications doing similar things would have this sort of flow of control. However, the logic within the Collector is likely to be complicated, particularly in the Stored state. If we think about breaking up the processing in the Stored state of Collector so that a state is dedicated to each kind of filtering, we would have a problem with the way Sampler triggers the actual data storing because that is tied to a single state condition (i.e., the overall sample count threshold has been met). But if we think about things a bit more we will note that Filter1 and Filter2 are really tied to the individual subsets of data that Sampler collects. It is basically serendipity that both sorts of filtering happen to need exactly the same snapshot in time, and it is a convenience of implementation to bundle the two sets of data values in a single sample data packet when both subsets are acquired at exactly the same time.
Figure 16-3 explicitly captures this independence. That is, Sampler is really generating two independent streams of data that are processed independently. Sampler generates separate E2a and E2b events for the streams as the data is obtained. This will actually be a more robust model because we can change that policy tomorrow without affecting any of the downstream processing. That more robust solution became evident because thinking about separating the data updates for the E3 events caused us to recognize the intrinsic independence of the sampling sets and filtering in the way we modeled the data collection.
Figure 16-3. State machine for an object managing buffering and storage of samples
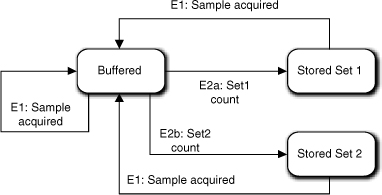
Now for extra credit: What is wrong with the Figure 16-3’s state machine?
The problem lies in what the Buffering state actually does. The description blithely implied that it is some sort of temporary storage for sample value sets until they can be distributed to other objects in a consistent fashion, implying that the storage is limited and that it gets reused once the values have been distributed. In other words, there has to be some sort of clear-and-reset behavior when the values are written, which was probably done in the Storing state of the original model. We now have two states for the old Storing state. How does each state know whether it is safe to reset the buffer for the data? In other words, how does it know that both subsets of values have been distributed when it is distributing only one subset?
The answer is that it can’t (more precisely, it shouldn’t) because the processes are independent. What we will have to do is implement the buffer storage differently so that the two subsets of data are separated. Then only the relevant set of data for the E2a or E2b event is reset in the appropriate state. Since that is a matter of private knowledge implementation, there is nothing really wrong with the state machine per se. The point is that there is no free lunch. We have to look at the big picture when designing state machines and that may include the way the object’s knowledge is implemented.
To get a handle on states, we need something a tad more substantial than the notion of state of being, especially when we define transitions. Alas, a state of being is kind of like art; we know it when we see it. Recall the example of a garage door opener in the previous chapter where the Door had states for {Open, Closing, Closed, Opening}. This seems intuitive enough for a simple example using 20/20 hindsight. But you may also recall that the Closing and Opening states were added in a second bout of navel contemplation (aka an iterative design pass), so they weren’t quite that intuitive initially. Also note that {Open, Closed} and {Opening, Closing} convey different ideas; the first pair is inherently static while the second pair in inherently dynamic. The point here is that there are several ways to view the notion of state of being.
• What the object is. This is a static view like {On, Off} or {Open, Closed}. It is the purest view of state of being.
• What the entity is doing. This is a dynamic view like {Opening, Closing} or {Heating, Cooling} where the entity being modeled is conceptually performing some activity on a continuous basis and all we are providing is the trigger. This situation is common in control systems where the activity is what the underlying hardware entity being modeled actually does. In that situation the rules and policies encapsulated in the state’s action provide initialization, setup, and/or initiation of the activity. This distinction between what the underlying entity does and what the object state’s action does is important. We do not want to define a state condition in terms of what the associated object behavior is, but we can define it in terms of what is happening as a result.
• What role the object is playing. Because we anthropomorphize human behavior onto inanimate entities, it is common to think in terms of roles that the object migrates through during the problem solution.3 The key here is to think about what the role itself is rather than the rules and policies that it executes. In the previous Collector example, the {Buffering, Storing} states could be viewed as roles the Collector plays within the overall solution.
We could summarize these views by saying that we define states in terms of why their rules and policies need to be isolated. While the previous suggestions are useful, they are not the only possible views. The real key is that we need to abstract the state condition as something different than the rules and policies associated with the state condition. In fact, just coming up with good state names is a very useful exercise and should not be done casually, because providing names that do not simply describe the behavior isn’t easy if the behaviors haven’t been encapsulated properly, so we have a check on prior development.4
Transitions
Transitions are rather straightforward; they represent a change in condition from one state to another. However, a more practical view is that they express a sequencing constraint from the problem space or problem solution. Usually the rationalization that determined the need for a state machine in the first place will go a long way toward determining what the sequencing constraints are in the problem space. Since the responsibilities have already been abstracted to be cohesive and logically indivisible, we are left with just connecting the dots for the problem context. In many cases, the constraints will be fairly obvious because, after all, we are modeling a life cycle.
In defining transitions we sequence conditions, not behaviors.
This is really the key mindset issue for defining transitions. While we necessarily need to think about the overall solution context to some degree, we want to keep that thinking as pure and abstract as possible. In particular, we want to avoid thinking about a sequence of operations, as in the steps of an algorithm. That’s because the traditional view of a sequence of operations is inherently synchronous, and with our asynchronous OOA/D behavior model we cannot guarantee that the operations will be executed contiguously. We can guarantee what condition must prevail for the object to execute the operation whenever it is time to do so. Once we know what the conditions are, we can order them relative to one another.
While transitions represent constraints on how the object collaborates with the rest of the world, we need to avoid thinking about the specific events that trigger the transition. Determining where and when events are generated is a logically distinct design task for connecting the dots in the overall problem solution. When we define transitions we are dealing with the supporting static structure for the overall solution flow of control. That static structure is expressed purely in terms of the underlying entity’s intrinsic life cycle and we want to focus our thinking as much as possible on that life cycle.
Like object responsibilities, life cycles in object state machines are highly tailored abstractions of the underlying entity’s actual life cycle.
Note that defining states and transitions is very similar to defining objects and responsibilities in the Class diagram. We use abstraction to select and tailor what we need from the underlying entity based on the problem in hand. But what we abstract are still intrinsic properties of the underlying entity. Thus the states and transitions represent a unique view of the intrinsic entity life cycle tailored to the context of the specific overall solution. It may seem like a fairly minor distinction, but that mapping of context view to intrinsic reality is both ubiquitous and fundamental to OO abstraction. Nurturing that dichotomy in our mindset will pay dividends by removing the temptation to create behavioral dependencies.
A viewpoint that some newcomers to state machine sometimes find useful when looking for states and transitions is to think in terms of situation rather than condition. Because we use the Moore model in MBD, most objects are really doing nothing at all when they are in a state. (The rules and policies associated with the state were executed when the state was entered.) In other words, most objects spend most of their time sitting on their thumbs just waiting for something to happen. However, where they are waiting (i.e., their current FSM state) may be a determining factor in what they will be capable of doing when and if something happens.
As a contrived analogy, imagine a fireman who can be either on duty at the firehouse or off duty at home in bed. When the fire alarm sounds the fireman can respond effectively, or not, depending on where he is. When at the firehouse the fireman has access to the proper equipment to respond because of the location. In fact, it is having access to the equipment that is a condition of being ready to respond to the fire alarm rather than the physical location of home versus firehouse. It is easy to anthropomorphize a notion of the fireman (or object) being in a good situation (i.e., the right place at the right time) when the alarm (or event) occurs. Being in that situation enables the fireman to respond (transition to fighting the fire). Thus the notion of situation, where the dictionary definition has dual meanings of location and condition, can be useful.
Transitions implicitly define when we cannot get there from here.
Regardless of how we view a state machine state, the definition of transitions still comes down to determining what possible states may immediately follow the current state in the overall solution. As constraints, though, what we are really defining are the state migrations that are not possible. Omitting a transition between two particular states (or a reflexive transition to the same state) is essentially saying that there is no possible solution context where the object should migrate between those states. Obviously, we do not design state machines based on the transitions we can’t have, but it is a useful sanity check on the transitions we do have to explicitly verify that all the possible omitted transitions really cannot happen in any solution context.
Events
Events are simply messages.5 We call them events because they announce something noteworthy happening in the application. The crucial mindset issue is that the noteworthy happening occurs elsewhere in the application from the object having the state machine that responds to the event. (You may recall this is why we frown on events that are self-directed.) Because objects collaborate on a peer-to-peer basis, that noteworthy happening will be the execution of an action in another object state machine. As indicated earlier in the discussion of states, that noteworthy happening will also map to a change in the condition of the overall problem solution. Therefore, the event message announces both changes simultaneously.
This has some important methodological implications.
Events do not identify transitions.
In fact, transitions have no unique identity. That’s because to execute a state machine we do not need transition constraints to have unique identity since the transition has no unique, intrinsic characteristics. Since the only thing that distinguishes one transition from another is the state of origin and the state of destination, the STT expresses everything we need to know about transitions. So if you’ve seen one, you’ve seen them all. However, the transition only tells us where we can go when something happens. We need to know when to go, which is what the event provides, so we need to associate the events with the transitions for their happening to be noteworthy.
An interesting implication of the separation of event and transition lies in ignoring events. Recall that in an object state machine we can ignore events in the STT. They are consumed, but the state machine does not execute any rules or policies or change state. That is a uniquely OO view of state machines. In effect, it means that a happening may be noteworthy in the external context where the event is generated, but it may not be noteworthy in the current context of the listening state machine.6 This is a manifestation of the way the OO paradigm separates the concerns of the object that has changed the application state from the concerns of the object that might care about that change. Thus having the added flexibility of determining whether there will be a response at all becomes a local option.
Another manifestation of the flexibility of separating events from transitions is that we can associate the same event with multiple transitions that do not share the same origin and/or destination states. In effect, this provides us with a form of polymorphic behavior substitution for individual objects so that the rules and policies executed in response to the event can be quite different even though the event is generated by the same noteworthy external happening. In other words, the rules and policies that prevail depend on when the happening occurs relative to the receiver’s life cycle.
This sort of thing is actually quite common. For example, in the Garage Door Opener example of Figure 15-13, the E1:clicked event was assigned to four different transitions: Open → Closing; Opening → Closing; Closing → Opening; and Closed → Opening. Thus the resulting rules and policies could be either for the Opening state or the Closing state, depending on the current state of the Door when the Clicker was clicked.
While this might seem like just a cute feature, it is really very important. Imagine for a moment what the code would look like if we did not use a state machine and needed to account for all of the possibilities, such as the pet cat playing with the Clicker as if it were a mouse; basically, we would have a rat’s nest of IF statements to deal with the various combinations. However, in the state machine solution there probably won’t be any IF statements and the action code is likely to be trivial. This is because all the rules and policies were captured statically in the states, transitions, and event assignments. And a crucial enabler for this was the E1:clicked event that could be assigned to multiple contexts. (Of course the cat might cause the motor to overheat, but that’s a hardware problem.)
The event context is not the transition context.
This is the most important implication of the separation of events from state machine transitions in an OO context. Events announce something happening externally. The semantics of the response context may be very different than the semantics of the happening context. In the Garage Door Opener example of Figure 15-13, the semantics of generating the E1:clicked event is about pressing a button on the Clicker control, while the semantics of the response is about opening or closing the door.
But the person doing the clicking knows the semantics, right? She wants the door to open or close; otherwise she wouldn’t be clicking, right? Maybe so. But the person doing the clicking is not the Clicker. The button press is an external stimulus from the application’s perspective and it has no open/close semantics. (To see that, imagine the cat playing with the clicker; the cat isn’t trying to open or close anything except the clicker box.) From the software application’s perspective the Clicker is just a surrogate object for some simple-minded hardware.
However, this segues to the notion of mapping. It is the developer who provides a mapping between what the person doing the clicking wants done and what the Clicker, Door, and their collaborations abstract. One major piece of that mapping lies in designing the state machine states and transitions. Another major piece lies in generating events and assigning them to transitions in the state machines. That assignment provides a mapping between the context of the event generation and the context of the response. Since the OO paradigm emphasizes encapsulation of abstractions that are highly tailored around intrinsic context, the need for such mapping is quite common. The separation of events from transitions is crucial to being able to provide that semantic mapping in a flexible manner.
The last implication of the separation is related to when we assign events. Previously we discussed how we could theoretically apply DbC to generating events by assigning them to transitions after we had designed all the object state machines in the subsystem. That is possible as long as we think of events as pure announcement messages. Conceptually, we want to think of events as a way of connecting the flow-of-control dots for collaborations in the overall problem solution. In other words, defining collaborations is a separate development stage that we can execute after designing the object state machines.
However, as noted in the introductory discussion of DbC in Chapter 2, that is rarely done in practice by experienced state machine developers because they are necessarily thinking about collaborations as they design the state machines and the mapping is often fairly obvious to the experienced eye. Nonetheless, if you are not accustomed to developing interacting state machines, it is strongly suggested that you initially follow the purist approach: Don’t generate events or assign them to transitions until after you have made an initial pass at designing all the subsystem state machines. You will find that, as a novice, generating and assigning the events involves significant iteration over the state machine designs because things won’t match up quite right. This is fine, and it will be an excellent learning exercise.
Before leaving the topic of state machine events we need to address the idea of polymorphic events addressed to a superclass in a subclassing hierarchy. If we employ the Harel model for state machines, the topic becomes mind-numbingly complex. Fortunately MBD does not use Harel, so we will just ignore that possibility. In MBD any superclass state machine is really just a notational convenience to avoid duplicating states and transitions in each subclass state machine. There are two manifestations of this.
In the simplest manifestation, all the subclasses share exactly the same life cycle, in which case the superclass state machine is also the complete state machine for each subclass and we are just drawing it in one place. So what is the point of having subclasses if they all have the same life cycle? Conceivably the subclasses could have different data accessed by synchronous services, but that would be quite rare in this situation. Another rather uncommon justification is that subclasses exist to support explicit relationships that only apply to subsets of members. A much more common reason is because the subclasses have different behaviors associated with the states. In this case the superclass events trigger the behavior substitution of inclusion polymorphism. All we have to do is provide the specialized action method for each subclass and map it to a superclass state.
The second manifestation is somewhat more complicated and occurs when the subclass state machines are different but share some of their states and transitions. In this case, the superclass state machine captures only the shared states and transitions as a matter of notational convenience to reduce duplication in the subclass state machines. However, conceptually there is no superclass state machine in this case. Each subclass has a single state machine that merges its specialized states and transitions with the common ones from the superclass. This becomes a pure mechanical issue for mapping transitions between the superclass states and the subclass states, which will be provided by the transformation engine. Again, the subclass state machine is free to provide a specialized action for the superclass states, so we have the same sort of polymorphic substitution as in the first manifestation.
In both manifestations the notion of a superclass event has an important limitation: It must be a valid event for every subclass in the entire line of descent from the superclass. The events will be polymorphic if the subclasses associate different actions for the superclass state.
Keep any polymorphism simple, and implement it at the leaf subclass level.
This is much simpler than the Harel view where superclass events can be “shortstopped” by superclass actions that execute before the subclass actions and dispatch can be made to subclass states based on history.7 If you encounter a situation that you feel you cannot resolve with this simplistic view, then it is time to review the object abstractions because there is a problem with cohesion. In such situations, look for a delegation resolution with multiple objects.
Actions
You may have discerned a pattern to the mindset issues so far in that states, transitions, and events are regarded as distinct, quasi-independent features of state machines where each has a unique suite of design criteria or issues. That is astute, Grasshopper, because the same thing applies to state actions. States and problem context limit what the entity is responsible for doing. Transitions constrain the sequencing of what the entity does. Events determine when the entity does what it does. Actions are about how the entity does its thing.
Unlike everything we have talked about so far, actions are not the least bit static. As soon as we step into the specification of a state action we are in an entirely different and highly dynamic world compared to the static structural views described thus far. All of the static structure described in umpteen chapters exists to support the dynamics described within state actions. It is only with state actions that we get to anything remotely resembling traditional software programming. So if states, transitions, and events are different critters, then state actions are extraterrestrials.
Action rules and policies are intrinsic to the entity.
This is probably the most important aspect of defining state actions because it is the easiest way to go wrong, especially if we are used to traditional procedural or functional development. We have already hammered on the need for responsibilities to be intrinsic when they are abstracted. At the action level, we flesh out those responsibilities with the detailed business rules and policies that need to be executed. At that level we also need to make sure we describe that execution in terms of intrinsic rules and policies that do not depend in any way on anything going on outside the object (other than knowledge being available). In order words, we need to think of the relevant rules and policies in quite generic terms as we specify them.
Fortunately, the way MBD works already goes a long way toward ensuring that we will not be tempted to pollute our actions with external behavior dependencies. For example, the event-based asynchronous model prevents us from using data returned by invoking other objects’ behaviors (e.g., the traditional procedural function return that immediately introduces an implementation dependency). Similarly, the restrictions MBD places on synchronous services preclude sneaking in behavioral dependencies via the back door. The way we abstract objects and responsibilities from the problem space severely limits the opportunities for foot-shooting.
Nonetheless, all that methodology cannot fully insulate us from temptation, so we need to be vigilant. Because we are dealing with business rules at a different level of abstraction and from a different perspective, it is fairly common to discover small problems with the objects, responsibilities, and state machines when we start to specify state actions. Therefore, be prepared for an iterative design process where you modify objects, responsibilities, and knowledge implementations.
Keep action data needs simple.
This is a corollary of the previous point about the need to think in terms of both data and operation sequencing. When responsibilities were identified in the static view, the emphasis was on cohesion of the behavior, not the data it accesses. When it is time to create state machines, though, we must consider data integrity issues because of the compound nature of action preconditions. The simpler the data needs of the action, the easier it will be to define preconditions and, consequently, rigorously ensure that execution is done at the right time.
Doing that is actually a lot easier than it sounds. Behavior responsibilities exist to modify the state of the application, which is represented in an OO context by state variables (attributes). If the behavior executes but no attribute was modified, then we cannot prove that the responsibility was satisfied.8 So if we were careful about defining behavior responsibilities as cohesive and logically indivisible, they will tend not to modify a lot of attributes. So, in practice, this guideline is more of a checklist item on how we have defined the responsibilities and state conditions. When we find that we are modifying several disparate attributes, we should be suspicious that the action encapsulates distinct sets of rules and policies that might be separated in time by different solution contexts.
Actions should be self-contained.
Actions only modify attributes, instantiate objects and relationships, and/or generate events.
Actions do very few things and we want those actions to be self-contained. Both instantiation and event generation are fundamental processes so they are implicitly self-contained. However, manipulating attributes could be done in a synchronous service and we invoke those services directly from actions. So there is a potential loophole here because the synchronous service could invoke other synchronous services, forming an indefinitely long chain. This is why we made such a big deal about synchronous services only modifying knowledge. If a synchronous service could instantiate or generate events, we break the containment of the invoking action.
Thus the acid test for actions being self-contained lies in unit testing. We should be able to define tests for every object responsibility based on six things.
- Defining a known application state in terms of attribute values accessed by the object’s actions
- The current FSM state of the object
- The ending FSM state of the object
- The resulting state of the application in terms of attribute values modified by the responsibility
- Events generated, including data packet content
- New objects and relationships created
The first two items are the initialization required while the last four items represent observations of the results. As a practical matter, unit testing of an application developed with MBD tends to be very simple and the unit testing is easily automated. Most translation IDEs provide a built-in test harnesses for that.
Obviously, this depends upon having been disciplined about defining synchronous services so that they really are knowledge responsibilities and don’t invoke endless chains of other object synchronous services. Evaluating the self-containment of the action being specified is the last line of defense against spaghetti code. When defining state actions that invoke synchronous services, you should double-check those synchronous services to ensure they really are just manipulating knowledge directly.9
The last thought on the mindset for dealing with state actions is related to exit actions. Exit actions are associated with exiting a state; that is, they are executed whenever there is a transition out of the state, regardless of what the next state is. From a purist viewpoint, exit actions are inconsistent with the Moore model used by MBD. That’s because the state represents a condition where a single set of rules and policies apply. If we execute those rules and policies on entry to the state, then there should be nothing left to execute on exit.
As a practical matter, though, exit actions are similar to self-directed events. We do not want to use them casually, but there are situations where they can reduce the number of states and transitions in the state machine. Usually the underlying reason is the same as for using self-directed events: management of state variables, which are orthogonal to behavioral state machines. So, like self-directed events, as a reviewer you should demand solid justification for employing exit actions.
The Execution Model
If you would like a highly technical description of the execution model for MBD, you will have to go to a source like OMG’s execution specification. When a bunch of academics start debating the nuances of runtime execution, it tends to bring new meaning to words like arcane and obtuse. Fortunately, such detailed descriptions are mostly only of interest to the developers of transformation engines. For the developers of application OOA models, life is much simpler: Essentially the developer can make several simplifying assumptions about execution that the transformation engine developers will have to support. Most of these assumptions have already been covered, but here is a quick review.
• All knowledge access is synchronous. Basically this means that the developer can assume the data is immediately available and consistent within the scope of a single state action. In other words, knowledge access is instantaneous, and the transformation engine will provide a mechanism to ensure the integrity of the data (e.g., nobody else will be writing it while it is being read).
• There is always an event queue for each subsystem. Since all behavior responsibilities are captured in state machines in MBD, this ensures that message and method are separated, and that behavior implementations are decoupled. The transformation may eliminate the event queue in a synchronous implementation, but the application modeler cannot depend on it. Note that this event queue is conceptual; it will not explicitly appear in the model.
• There is only one event queue per subsystem. The OOA developer only needs to worry about functional requirements, so there is no need to be concerned about concurrency, distributed processing, and other complications due to addressing nonfunctional requirements or deployment. Those concerns all belong to a different union.
• Only one state action is executed at a time in a subsystem. That is, the event queue pops one event at a time and waits until the associated action completes before processing the next event. Essentially, this assumption makes the state action a basic, indivisible unit of computation.
• Multiple events between the same sender and receiver will be consumed in the same relative order that they were generated. Though the asynchronous communication model enables arbitrary delays between generating and consuming an event, there are limits to how arbitrary the delays can be. In this special case, the delays cannot change the relative order of events. This is essential to the notion of handshaking to synchronize state machines.
• Events generated by a state machine to itself will be processed before events generated by other state machines. This was discussed in Chapter 14. While not essential, it makes life much easier for ensuring data integrity.
• Algorithmic processing within FSM actions and synchronous services employ the same execution model as the 3GLs. Essentially this means that the detailed dynamic specification of behavior works the same way in an AAL as it does in the 3GLs.
These assumptions combine to provide an asynchronous model for behavior. There is a host of issues the transformation engine developer needs to address to make these assumptions valid, but that is not the application developer’s problem. The only real problem the developer has is the asynchronous model. For most developers who have not dealt with asynchronous models, there is apparently a major hurdle: If there is an arbitrary delay between when a message is sent and when the response is triggered, how can we be sure that things will get done in the right order? As we discussed previously, the answer to this is simple: The event queue makes it Just Work. The R-T/E people adopted the interacting state machine paradigm precisely because it brought order to an inherently asynchronous environment.
To put it another way, the “arbitrary delay” between when an event is generated and when it is consumed is really about how many events are already on the queue when it is pushed.10 So if there are no events on the queue, it will get executed right away, and the only delays will be the wait until the sender action completes and the queue does its processing. If we put events on the queue as soon as the noteworthy happening occurs, they will get popped before events from other noteworthy happenings that occur subsequently. This is because events are only generated in state actions, and we only process one state action at a time with our single event queue. Thus the event queue maintains the order of noteworthy happenings so that they are responded to in the order they occurred. As discussed in the previous chapter, handshaking is the tool we use to ensure that events get on the event queue in the right order.
Alas, life is rarely so simple. The previous logic applies to events generated by interacting state machines within the subsystem during the normal course of subsystem processing. There is another source of events that is truly asynchronous: external events from outside the subsystem. A priori we have no control over when those events are pushed onto the queue. Suppose the subsystem “daisy-chains” a suite of processing activities in response to an external event, E1, as in Figure 16-4(a). Let’s further suppose that due to the way knowledge is distributed among the objects, whoever responds to E4 accesses data that was modified by whoever responded to E1. If so, then we are in trouble if another E1 event is pushed onto the queue before the response to E3 completes, as in Figure 16-4(b). That will cause the data modified by the first E1 event to be overwritten before the response to E4 gets to it.
Figure 16-4. Serializing events through the event queue
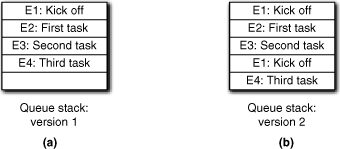
The short answer to this problem is: Deal with it. As the subsystem developer you have to know when asynchronous external events will be a problem for your design and, in those cases, you will have to provide serialization explicitly in the model. Fortunately, it is relatively easy to do because subsystem interfaces are event based in MBD, so the external event just goes onto the subsystem’s event queue. Most of the time it won’t be a problem because you will design your subsystem interface around a protocol when subsystems interact, just like your objects within the subsystems.
For example, if most of your instructions come from the software user via a GUI, your subsystem is likely to have a natural exchange of user requests and subsystem results so that there is no need for the user to submit additional requests until the processing is completed and the results have been supplied. If you can’t trust the user to wait, you can enforce that by having the GUI ignore random user interactions when waiting for results (e.g., give the user an hourglass cursor). The GUI will stop ignoring the user interactions when it gets the results from your subsystem.
However, whenever asynchronous external events can be a problem, the most common answer is usually serialization. In other words, we introduce an explicit queue into the application model to temporarily hold the external events until the application is ready to process them. This queue is unrelated to the event queue that manages object collaborations. It needs to be explicit because it is a necessary element of the solution design.
Another solution is to design the subsystem interfaces so that the subsystem can solicit a request from the client subsystem when it is ready to process. Usually, though, this just moves the explicit queue to the client. An exception is handling hardware interrupts. Since the interrupt is just a bit set in some hardware register, we can just poll the interrupt bit as a knowledge attribute at a convenient point in the software processing rather than modeling the interrupt as an externally generated event.
Naming Conventions
As in the rest of MBD, naming conventions for states and events have a dual role. They obviously provide documentation for posterity. Providing good names has a much greater value because they force the developer to think about what is being modeled. Coming up with good names for states and events is not an easy task, so it forces us to focus on the essence of the life cycle and the problem context. In this sense, providing good names is very much like extracting invariants from the problem space.
Naming states is relatively easy because there are essentially only three basic approaches. The preferred approach is to name states for the condition or state of being they represent. Thus in the garage door opener example of the last chapter, the states {Open, Closing, Closed, Opening} are pretty clearly tied to the notion of door state.
The notion of state condition is closely tied to the preconditions for executing the state’s rules and policies. Since those preconditions are often compound (e.g., “Execute the permanent store after a complete set of samples has been collected, pre-processed, and temporarily stored.”), it can get interesting when we are looking for a single pithy word or phrase. Nonetheless, this is the best way to name states, so we should take some time to find that pithy word or phrase.
The second approach to naming states is to name them consistently with the Moore model. That is, the state is named after what the rules and policies accomplished when they were executed upon entering the state. In effect we are naming the state for the postcondition of executing the rules and policies rather than the precondition. This will usually be indicated by a past tense verb (e.g., Samples Stored). Usually this is easier to do because we have already isolated our behavior into a cohesive, logically indivisible unit, so it is often fairly clear why we are doing it.
The third approach is a variant on the second where we name the state for the role that the action plays in the object life cycle. While valid, this is a last resort because it is often hard to distinguish between the role the rules and policies play in the solution and what they actually do. That is, the idea of role is more closely associated with what the rules and policies are than with the notion of state of being or condition. This becomes a slippery slope that can lead to naming states for their actions, which is a very procedural view of the world.
Naming events can be close to an art form. The problem is that we have one foot in the object, since the event triggers a transition in the object’s life cycle, and we have the other foot in the context, since the event is generated by some noteworthy happening in some other object in the overall solution context. This tends to lead to some degree of schizophrenia since the context of generation may have quite different semantics than those of the receiving object’s life cycle.
There are two possible approaches and each has ardent advocates. One approach is to name the event for the receiver context (i.e., the receiving object’s view of what causes the transition). The logic behind this is that if we are doing event generation in a separate development step from designing the state machine structure, then we are doing some form of DbC to determine where the event should be generated. In that case the generation location is arbitrary compared to the precondition of the receiver’s state.
The second approach is to name the event for the sender context (i.e., the generating object’s view of what happened). The logic behind this approach is that the event is a message announcing that something happened. The only way we can “announce” something happening in a simple message is through the message identity. Therefore, we name events for what happened in the sender’s context.
MBD is partial to the second approach in an OO context because it is more consistent with the OO view of separation of message and method where messages are announcements. It is also more consistent with the general OO notion that we design interfaces to suit the client rather than the service, and the event is basically an interface message. However, that can sometimes get awkward during maintenance if the location where the event is generated needs to change. If the new location has a different semantic context than the original, we would want to name the event differently, which would mean modifying the STT of Statechart diagram for the receiving state machine. If we name events for the receiver context, then this is not a problem and we just have to move the event generation, which we would have to do anyway.
As a practical matter, when there is a wide disparity in sender and receiver contexts we seek to raise the level of abstraction until the event name has an interpretive “fit” to both sender and receiver contexts. This reduces the likelihood that the event name would need to change during maintenance and makes documentation sense in both contexts.