
One of the features that has helped make MySQL so popular over the years is the support for replication which allows you to have a MySQL instance that automatically receives the updates from its source and applies them. With quick transactions and a low latency network, the replication can be in near-real time, but note that as there is no such thing as synchronous replication in MySQL except for NDB Cluster, there is still a delay which potentially can be large. A recurring task for database administrators is to work on improving the performance of the replication. Over the years, there have been many improvements to MySQL replication including some that can help you improve the replication performance.
This chapter focuses on traditional asynchronous replication. MySQL 8 also supports Group Replication and its derivative InnoDB Cluster. It is beyond the scope of this book to go into the details of Group Replication; however, the discussion still applies in general. For details of Group Replication, the book Introducing InnoDB Cluster by Charles Bell (Apress) (www.apress.com/gp/book/9781484238844) is recommended together with the MySQL reference manual (https://dev.mysql.com/doc/refman/en/group-replication.html) for the latest updates.
This chapter will start out providing a high-level overview of replication with the purpose of introducing terminology and a test setup that will be used for the section on replication monitoring. The other half of the chapter discusses how the performance of the connection and applier threads can be improved and how replication can be used to offload work to a replica.
Replication Overview
Before you dive into improving the performance of replication, it is important to discuss how replication works. This will help agreeing on a terminology and to have a reference point for the discussion in the rest of this chapter.
Traditionally the terms master and slave have been used to describe the source and target of MySQL replication. In recent times, the terminology has moved toward using the words source and replica. Likewise, on the replica, the two thread types for handling the replication events have traditionally been called I/O thread and SQL thread, whereas the current terms are connection thread and applier thread. This book will to the largest extent possible use the new terms; however, the old terms are still present in some contexts.
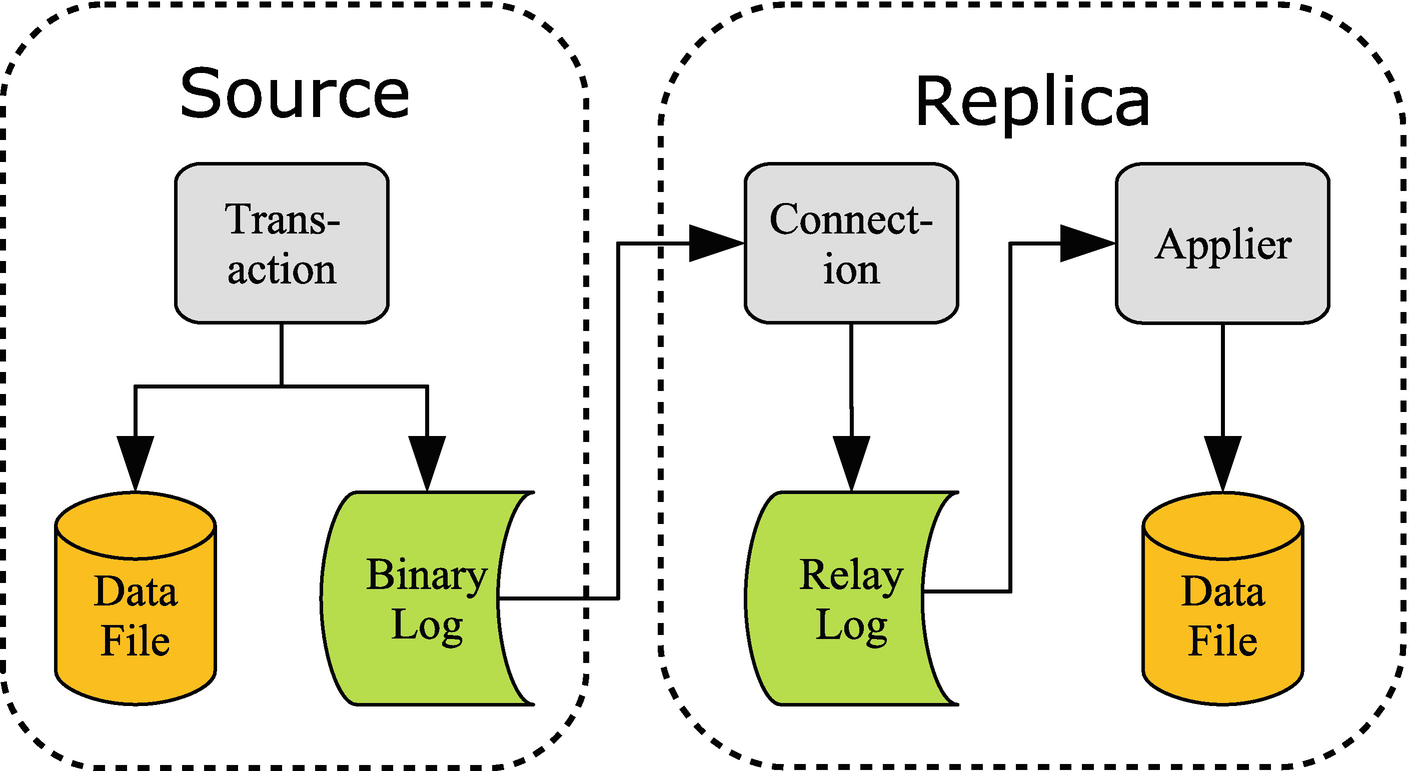
Replication overview
When a transaction commits its changes, the changes are written both to the InnoDB specific files (redo log and data files) and to the binary log. The binary log consists of a series of files as well as an index file with the index file listing the binary log files. Once the events have been written to the binary log file, they are sent to the replica. There may be more than one replica in which case the events are sent to all the replicas.
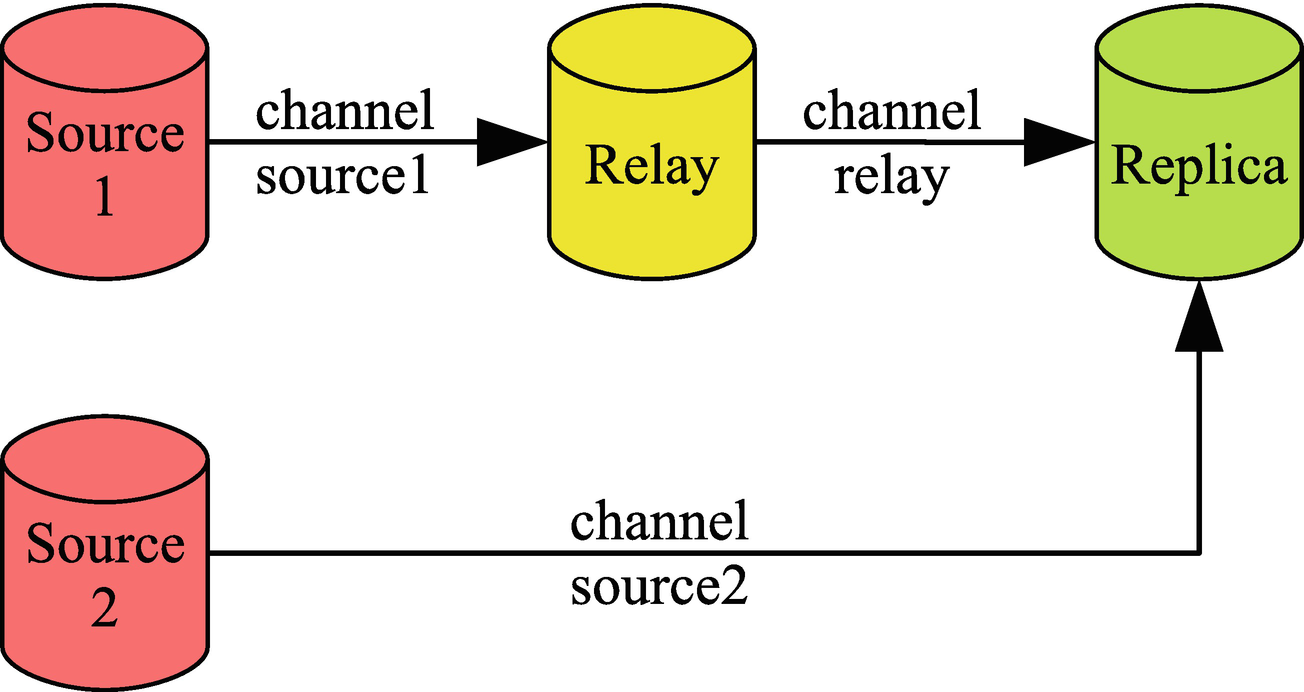
Replication topology with two replication streams
Here Source 1 replicates to the Relay instance which in turn replicates to the Replica instance. Source 2 also replicates to the Replica instance. Each channel has a name to make it possible to distinguish between them, and in multi-source replication, each channel must have a unique name. The default channel name is an empty string. When monitoring is discussed, it will use a replication setup like the one in the figure.
Monitoring
When you encounter replication performance problems, the first step is to determine where the delay is introduced in the chain of steps described in the previous section. If you have been using replication in earlier versions of MySQL, you may jump to the SHOW SLAVE STATUS command to check the health of the replication; however, in MySQL 8 that is the last source of monitoring information to check.
The status tables include much more detailed information about the replication delays in the form of timestamps with microsecond resolution for each step in the replication process and with timestamps from both the original and immediate sources.
You can query the tables using SELECT statements. This allows you to query the information you are most interested in, and you can manipulate the data. This is particularly an advantage when you have multiple replication channels in which case the output of SHOW SLAVE STATUS quickly becomes hard to use when inspecting it in the console as the output scrolls off the screen.
The data is split into logical groups with one table per group. There are separate tables for the configuration and applier processes and separate tables for the configuration and status.
The Seconds_Behind_Master column in SHOW SLAVE STATUS has traditionally been used to measure the replication delay. It essentially shows how long time has passed since the transaction started on the original source. That means, it only really works when all transactions are very quick and there are no relay instances. Even then it does not provide any information of where the cause of a delay is. If you are still using Seconds_Behind_Master to monitor the replication delay, you are encouraged to start switching to the Performance Schema tables.
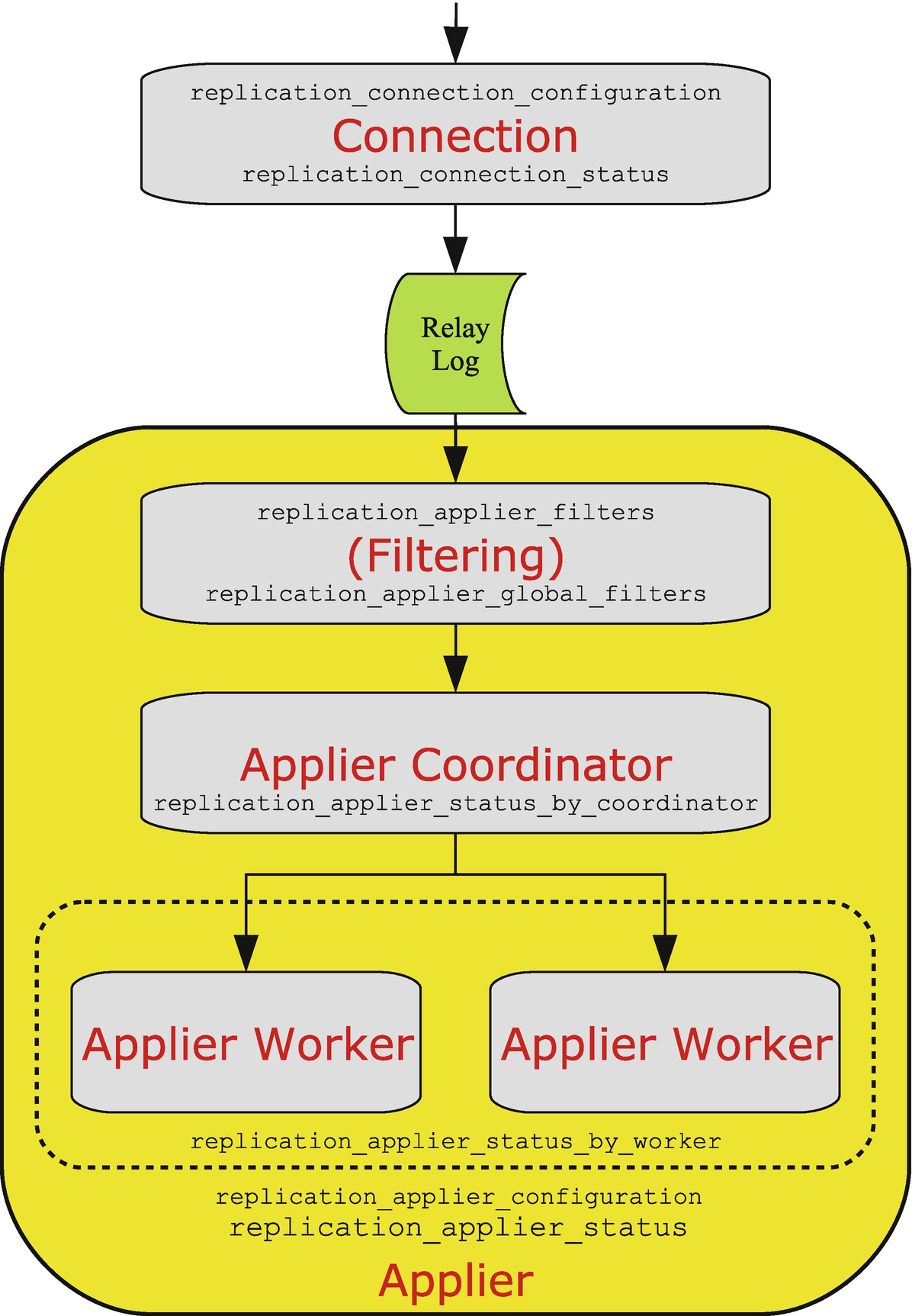
The replication processes and their monitoring tables
The events arrive at the top of the figure from the immediate source and are processed by the connection thread which has the two tables replication_connection_configuration and replication_connection_status. The connection thread writes the events to the relay log, and the applier reads the events from the relay log while applying the replication filters. The replication filters can be found in the replication_applier_filters and replication_applier_global_filters tables. The overall applier configuration and status can be found in the replication_applier_configuration and replication_applier_status tables.
In case of parallel replication (also known as a multithreaded slave), the coordinator then handles the transactions and makes them available for the workers. The coordinator can be monitored through the replication_applier_status_by_coordinator table. If the replica uses single-threaded replication, the coordinator step is skipped.
The final step is the applier worker. In case of parallel replication, there are slave_parallel_workers threads per replication channel, and each thread has a row with its status in the replication_applier_status_by_worker table.
The rest of this section covers the Performance Schema replication tables for the connection and applier as well as the log status and Group Replication tables.
Connection Tables
The first step when replication events arrive at a replica is to write them to the relay log. It is the connection thread that handles this.
replication_connection_configuration: The configuration of each of the replication channels.
replication_connection_status: The status of the replication channels. This includes timestamps showing when the last and current queuing transaction was originally committed, when it was committed on the immediate source instance, and when it was written to the relay log. There is one row per channel.
The replication connection tables
The configuration table largely corresponds to the options that you can give when setting up replication with the CHANGE MASTER TO statement , and the data is static unless you explicitly change the configuration. The status table mostly contains volatile data that changes rapidly as events are processed.
LAST_QUEUED_TRANSACTION_ORIGINAL_COMMIT_TIMESTAMP: The time when the event was committed on the original source (Source 1).
LAST_QUEUED_TRANSACTION_IMMEDIATE_COMMIT_TIMESTAMP: The time when the event was committed on the immediate source (Relay).
LAST_QUEUED_TRANSACTION_START_QUEUE_TIMESTAMP: The time when this instance started to queue the event – that is, when the event was received and the connection thread started to write the event to the relay log.
LAST_QUEUED_TRANSACTION_END_QUEUE_TIMESTAMP: The time when the connection thread completed writing the event to the relay log.
The timestamps are in microsecond resolution, so it allows you to get a detailed picture of how long the event has been on its way from the original source to the relay log. A zero timestamp ('0000-00-00 00:00:00') means that there is no data to return; this can, for example, happen for the currently queueing timestamps when the connection thread is fully up to date. The applier tables provide further details about the event’s journey through the replica.
Applier Tables
The applier threads are more complex as they both handle filtering of events and applying events, and there is support for parallel appliers.
replication_applier_configuration: This table shows the configuration of the applier threads for each replication channel. Currently the only setting is the configured replication delay. There is one row per channel.
replication_applier_filters: The replication filters per replication channel. The information includes where the filter was configured and when it became active.
replication_applier_global_filters: The replication filters that apply to all replication channels. The information includes where the filter was configured and when it became active.
replication_applier_status: The overall status for the appliers including the service state, remaining delay (when a desired delay is configured), and the number of retries there have been for transactions. There is one row per channel.
replication_applier_status_by_coordinator: The applier status as seen by the coordinator thread when using parallel replication. There are timestamps for the last processed transaction and the currently processing transaction. There is one row per channel. For single-threaded replication, this table is empty.
replication_applier_status_by_worker: The applier status for each worker. There are timestamps for the last applied transaction and the transaction currently being applied. When parallel replication is configured, there is one row per worker (the number of workers is configured with slave_parallel_workers) per channel. For single-threaded replication, there is one row per channel.
The replication_applier_status_by_worker table
The timestamps follow the same pattern as you have seen earlier with information for both the last processed and current transactions. Notice that for the first row, all timestamps are zero which shows that the applier cannot take advantage of the parallel replication.
For the last applied transaction with the global transaction identifier 4d22b3e5-a54f-11e9-8bdb-ace2d35785be:213 in the second row, it can be seen that the transaction was committed on the original source at 11:29:36.1076, committed on the immediate source at 11:29:44.822024, started to execute on this instance at 11:29:51.910259, and finished executing at 11:29:52.403051. That shows that each instance adds a delay of around eight seconds, but the transaction itself only took half a second to execute. You can conclude the replication delay is not caused by applying a single large transaction, but it is rather a cumulative effect of the relay and replica instances not being able to process transactions as fast as the original source, that the delay was introduced by an earlier long-running event and the replication has not yet caught up, or that the delay is introduced in other parts of the replication chain.
Log Status
The log_status table
The LOCAL column includes information about the executed global transaction identifiers and the binary log file and position on this instance. The REPLICATION column shows the relay log data related to the replication process with one object per channel. The STORAGE_ENGINES column contains the information about the InnoDB log sequence numbers.
Group Replication Tables
If you use Group Replication, then there are two additional tables that you can use to monitor the replication. One table includes high-level information about the members of the group, and the other has various statistics for the members.
replication_group_members: The high-level overview of the members. There is one row for each member, and the data includes the current status and whether it is a primary or secondary member.
replication_group_member_stats: Lower-level statistics such as the number of transactions in the queue, which transactions are committed on all members, how many transactions originated locally or remotely, and so on.
The replication_group_members table is most useful to verify the status of the members. The replication_group_member_stats table can be used to see how each node views what work has been done and whether there is a high rate of conflicts and rollbacks. Both tables include information from all nodes in the cluster.
Now that you know how to monitor replication, you can start working on optimizing the connection and applier threads.
The Connection
The connection thread handles the outbound connection to the immediate source of the replication, reception of the replication events, and saving the events to the relay log. This means that optimizing the connection process revolves around the replication events, the network, maintaining the information about which events have been received, and writing the relay log.
Replication Events
When row-based replication is used (the default and recommended), the events include information about the row that was changed and the new values (before and after images). By default, the complete before image is included for update and delete events. This makes it possible for the replica to apply the events even if the source and replica have the columns in different order or have different primary key definitions. It does however make the binary log – and thus also the relay logs – larger which means more network traffic, memory usage, and disk I/O.
If you do not require the full before image to be present, you can configure the binlog_row_image option to minimal or noblob. The value minimal means that only the columns required to identify the row are included in the before image, and the after image only includes the columns changed by the event. With noblob, all columns except blob and text columns are included in the before image, and blob and text columns are only included in the after image if their values have changed. Using minimal is the optimal for performance, but make sure you test thoroughly before making the change on your production system.
Make sure you have verified that your application works with binlog_row_image = minimal before making the configuration change on production. If the application does not work with the setting, it will cause replication to fail on the replicas.
The binlog_row_image option can also be set at the session scope, so a possibility is to change the option as needed.
The Network
The main tuning options inside MySQL for the network used in replication are the interface used and whether compression is enabled. If the network is overloaded, it can quickly make replication fall behind. An option to avoid that is to use a dedicated network interface and route for the replication traffic. Another option is to enable compression which can reduce the amount of data transferred at the cost of higher CPU load. Both solutions are implemented using the CHANGE MASTER TO command .
Replace the addresses and other information as needed.
It may be tempting to not enable SSL to improve the network performance. If you do that, the communication including authentication information and your data will be transferred unencrypted, and anyone who gets access to the network can read the data. Thus, it is important for any setup handling production data that all communication is secure – for replication that means enabling SSL.
uncompressed: Disable compression. This is the default.
zlib: Use the zlib compression algorithm.
zstd: Use the ztd version 1.3 compression algorithm.
Before MySQL 8.0.18, you specify whether to use compression with the slave_compressed_protocol option. Setting the option to 1 or ON makes the replication connection use zlib compression if both the source and replica support the algorithm.
If you have the slave_compressed_protocol option enabled in MySQL 8.0.18 or later, it takes precedence over the MASTER_COMPRESSION_ALGORITHMS. It is recommended to disable slave_compressed_protocol and use the CHANGE MASTER TO command to configure the compression as it allows you to use the zstd algorithm and it makes the compression configuration available in the replication_connection_configuration Performance Schema table.
Maintaining Source Info
The replica needs to keep track of information it has received from the source. This is done through the mysql.slave_master_info table . It is also possible to store the information in a file, but this has been deprecated as of 8.0.18 and is discouraged. Using a file also makes the replica less resilient to recover from crashes.
With respect to the performance of maintaining this information, then the important option is sync_master_info. This specifies how frequently the information is updated with the default being every 10000 events. You may think that similar to sync_binlog on the source side of the replication, it is important to sync the data after every event; however, that is not the case.
It is not necessary to set sync_master_info = 1 and doing so is a common source of replication lags.
The reason it is not necessary to update the information very frequently is that it is possible to recover from a loss of information by discarding the relay log and fetching everything starting from the point the applier has reached. The default value of 10000 is thus good, and there is rarely any reason to change it.
The exact rules when the replication can recover from a crash are complex and change from time to time as new improvements are added. You can see the up-to-date information in https://dev.mysql.com/doc/refman/en/replication-solutions-unexpected-slave-halt.html.
Writing the Relay Log
The relay logs are the intermediate storage of the replication events between the connection receiving the replication events and the applier has processed them. There are mainly two things that affect how quickly the relay log can be written: the disk performance and how often the relay log is synced to disk.
You need to ensure that the disk you write the relay log to has enough I/O capacity to sustain the write and read activity. One option is to store the relay logs on a separate storage so other activities do not interfere with the writing and reading of the relay log.
How often the relay log is synchronized to disk is controlled using the sync_relay_log option which is the relay log equivalent of sync_binlog. The default is to synchronize every 10000 events. Unless you use position-based replication (GTID disabled or MASTER_AUTO_POSITION=0) with parallel applier threads, there is no reason to change the value of sync_relay_log as recovery of the relay log is possible. For position-based parallel replication, you will need sync_relay_log = 1 unless it is acceptable to rebuild the replica in case of a crash of the operating system.
This means that from a performance perspective, the recommendation is to enable global transaction identifiers and set MASTER_AUTO_POSITION=1 when executing CHANGE MASTER TO. Otherwise, leave the other settings related to the master info and relay log at their defaults.
The Applier
The applier is the most common cause of replication lags. The main problem is that the changes made on the source are often the result of a highly parallel workload. In contrast, by default the applier is single threaded, so a single thread will have to keep up with potential tens or hundreds of concurrent queries on the source. This means that the main tool for combating replication lags caused by the applier is to enable parallel replication. Additionally, the importance of primary keys, the possibility of relaxing data safety settings, and the use of replication filters will be discussed.
There is no effect of changing the sync_relay_log_info setting when you use a table for the relay log repository and use InnoDB for the mysql.slave_relay_log_info table (both are the default and recommended). In this case, the setting is effectively ignored, and the information is updated after every transaction.
Parallel Applier
Configuring the applier to use several threads to apply the events in parallel is the most powerful way to improve the replication performance. It is however not as simple as setting the slave_parallel_workers option to a value greater than 1. There are other options – both on the source and replica – to consider.
Configuration options related to parallel replication
Option Name and Where to Configure | Description |
|---|---|
binlog_transaction_dependency_tracking Set on the source | Which information to include in the binary log about the dependencies between transactions. |
binlog_transaction_dependency_history_size Set on the source | How long information is kept for when a row was last updated. |
transaction_write_set_extraction Set on the source | How to extract write set information. |
binlog_group_commit_sync_delay Set on the source | The delay to wait for more transactions to group together in the group commit feature. |
slave_parallel_workers Set on the replica | How many applier threads to create for each channel |
slave_parallel_type Set on the replica | Whether to parallelize over databases or the logical clock. |
slave_pending_jobs_size_max Set on the replica | How much memory can be used to hold events not yet applied. |
slave_preserve_commit_order Set on the replica | Whether to ensure the replica writes the transactions to its binary log in the same order as on the source. Enabling this requires setting slave_parallel_workers to LOGICAL_CLOCK. |
slave_checkpoint_group Set on the replica | The maximum number of transactions to process between checkpoint operations. |
slave_checkpoint_period Set on the replica | The maximum time in milliseconds between checkpoint operations. |
The most commonly used of the options are binlog_transaction_dependency_tracking and transaction_write_set_extraction on the source and slave_parallel_workers and slave_parallel_type on the replica.
The binary log transaction dependency tracking and write set extraction options on the source are related. The transaction_write_set_extraction option specifies how to extract write set information (information about which rows are affected by the transaction). The write sets are also what Group Replication uses for conflict detection. Set this to XXHASH64 which is also the value required by Group Replication.
The binlog_transaction_dependency_tracking option specifies what transaction dependency information is available in the binary log. This is important for the parallel replication to be able to know which transactions are safe to apply in parallel. The default is to use the commit order and rely on the commit timestamps. For improved parallel replication performance when parallelizing according to the logical clock, set binlog_transaction_dependency_tracking to WRITESET.
The binlog_transaction_dependency_history_size option specifies the number of row hashes that are kept providing information on which transaction last modified a given row. The default value of 25000 is usually large enough; however, if you have a very high rate of modifications to different rows, it can be worth increasing the dependency history size.
On the replica, you enable parallel replication with the slave_parallel_workers option . This is the number of applier worker threads that will be created for each replication channel. Set this high enough for the replication to keep up but not so high that you end up having idle workers or that you see contention from a too parallel workload.
The other option that is often necessary to update on the replica is the slave_parallel_type option. This specifies how the events should be split among the applier workers. The default is DATABASE which as the name suggests splits updates according the schema they belong to. The alternative is LOGICAL_CLOCK which uses the group commit information or the write set information in the binary log to determine which transactions are safe to apply together. Unless you have several layers of replicas without including write set information in the binary log, LOGICAL_CLOCK is usually the best choice.
If you use the LOGICAL_CLOCK parallelization type without write sets enabled, you can increase binlog_group_commit_sync_delay on the source to group more transactions together in the group commit feature at the expense of a longer commit latency. This will give the parallel replication more transactions to distribute among the workers and thus improve the effectiveness.
The other major contributor to replication lags is the absence of primary keys.
Primary Keys
When you use row-based replication, the applier worker processing the event will have to locate the rows that must be changed. If there is a primary key, this is very simple and efficient – just a primary key lookup. However, if there is no primary key, it is necessary to examine all rows until a row has been found with the same values for all columns as the values in the before image of the replication event.
Such a search is expensive if the table is large. If the transaction modifies many rows in a relatively large table, it can in the worst case make replication seem like it has come to a grinding halt. MySQL 8 uses an optimization where it uses hashes to match a group of rows against the table; however, the effectiveness depends on the number of rows modified in one event, and it will never be as efficient as primary key lookups.
It is strongly recommended that you add an explicit primary key (or a not-NULL unique key) to all tables. There is no savings in disk space or memory by not having one as InnoDB adds a hidden primary key (which cannot be used for replication) if you do not add one yourself. The hidden primary key is a 6 byte integer and uses a global counter, so if you have many tables with hidden primary keys, the counter can become a bottleneck. Furthermore, if you want to use Group Replication, it is a strict requirement that all tables have an explicit primary key or a not-NULL unique index.
Enable the sql_require_primary_key option to require all tables to have a primary key. The option is available in MySQL 8.0.13 and later.
If you cannot add a primary key to some tables, then the hash search algorithm works better the more rows are included in each replication event. You can increase the number of rows grouped together for transactions modifying a large number of rows in the same table by increasing the size of binlog_row_event_max_size on the source instance of the replication.
Relaxing Data Safety
When a transaction is committed, it must be persisted on disk. In InnoDB the persistence is guaranteed through the redo log and for replication through the binary log. In some cases, it may be acceptable on a replica to relax the guarantees that the changes have been persisted. This optimization comes at the expense that you will need to rebuild the replica if the operating system crashes.
InnoDB uses the option innodb_flush_log_at_trx_commit to determine whether the redo log is flushed every time a transaction commits. The default (and safest setting) is to flush after every commit (innodb_flush_log_at_trx_commit = 1). Flushing is an expensive operation, and even some SSD drives can have problems keeping up with the flushing required from a busy system. If you can afford losing up to a second of committed transactions, you can set innodb_flush_log_at_trx_commit to 0 or 2. If you are willing to postpone flushes even further, you can increase innodb_flush_log_at_timeout which sets the maximum amount of time in seconds between flushing the redo log. The default and minimum value is 1 second. That means if a catastrophic failure happens, you will likely need to rebuild the replica, but the bonus is that the applier threads can commit changes cheaper than the source and thus easier keep up.
The binary log similarly uses the sync_binlog option which also defaults to 1 which means to flush the binary log after each commit. If you do not need the binary log on the replica (note that for Group Replication the binary log must be enabled on all notes), you can consider either disabling it altogether or to reduce the frequency the log is synced. Typically, in that case, it is better to set sync_binlog to a value such as 100 or 1000 rather than 0 as 0 often ends up causing the entire binary log to be flushed at once when it is rotating. Flushing a gigabyte can take several seconds; and, in the meantime, there is a mutex that prevents committing transactions.
If you relax the data safety settings on a replica, make sure you set them back to the stricter values if you promote the replica to become the replication source, for example, if you need to perform maintenance.
Replication Filters
Replication filter options
Option Name | Description |
|---|---|
replicate-do-db replicate-ignore-db | Whether to include the changes for the schema (database) given as a value. |
replicate-do-table replicate-ignore-table | Whether to include the changes for the table given as a value. |
replicate-wild-do-table replicate-wild-ignore-table | Like the replicate-do-table and replicate-ignore-table options but with support for the _ and % wildcards in the same way as when writing LIKE clauses. |
The parentheses around world are required as you can specify a list if you need to include more than one database. If you specify the same rule more than once, the latter applies, and the former is ignored.
To see the full rules for CHANGE REPLICATION FILTER, see https://dev.mysql.com/doc/refman/en/change-replication-filter.html.
Replication filters work best with row-based replication as it is clear which table is affected by an event. When you have a statement, the statement may affect multiple tables, so for statement-based replication it is not always clear whether a filter should allow the statement or not. Particular care should be taken with replicate-do-db and replicate-ignore-db as with statement-based replication they use the default schema to decide whether to allow a statement or not. Even worse is to use replication filters with a mix of row and statement events (binlog_format = MIXED) as the effect of a filter can depend on the format the changes replicate with.
It is best to use binlog_format = row (the default) when you use replication filters. For the complete rules for evaluation replication filters, see https://dev.mysql.com/doc/refman/en/replication-rules.html.
That concludes the discussion of how to improve the replication performance. There is one topic left which is kind of the opposite of what has been discussed thus far – how to improve the performance of the source by using the replica.
Offloading Work to a Replica
If you have problems with an instance being overloaded by read queries, a common strategy to improve the performance is to offload some of the work to one or more replicas. Some common scenarios are to use replicas for read scale-out and to use a replica for reporting or backups. This section will look at this.
Using replication (e.g., using Group Replication’s multi-primary mode) does not work as a way to scale out writes as all changes must still be applied on all nodes. For write scale-out, you need to shard the data, for example, as it is done in MySQL NDB Cluster. Sharding solutions are beyond the scope of this book.
Read Scale-Out
One of the most common uses of replication is to allow read queries to use a replica and, in that way, reduce the load on the replication source. This is possible because the replicas have the same data as their source. The main thing to be aware of is that there will even at the best of time be a small delay from a transaction is committed on the source until a replica has the change.
If your application is sensitive to reading stale data, then an option is to choose Group Replication or InnoDB Cluster which in versions 8.0.14 and later supports consistency levels, so you can ensure the application uses the required level of consistency.
For a good explanation of how to use the Group Replication consistency levels, the blog by Lefred at https://lefred.be/content/mysql-innodb-cluster-consistency-levels/ is highly recommended together with the links at the top of the blog to blogs by the Group Replication developers.
Using replicas for reads can also help you bring the application and MySQL closer to the end user which reduces the roundtrip latency, so the user gets a better experience.
Separation of Tasks
The other common use of replicas is to perform some high-impact tasks on a replica to reduce the load on the replication source. Two typical tasks are reporting and backups.
When you use a replica for reporting queries, you may benefit from configuring the replica differently than the source to optimize it for the specific workload it is used for. It may also be possible to use replication filters to avoid including all the data and updates from the source. Less data means the replica has to apply fewer transactions and write less data, and you can read a larger percentage of the data into the buffer pool.
It is also common to use a replica for backups. If the replica is dedicated to backups, then you do not need to worry about locks and performance degradation due to disk I/O or buffer pool pollution as long as the replica can catch up before the next backup. You can even consider shutting the replica down during the backup and perform a cold backup.
Summary
This chapter has looked at how replication works, how to monitor and improve the performance of the replication process, and how to use replication to distribute the work across several instances.
The start of the chapter provided an overview of replication including introducing the terminology and showed where you can find monitoring information for the replication. In MySQL 8, the best way to monitor replication is to use a series of Performance Schema tables that split the information out depending on the thread type and whether it is the configuration or status. There are also tables dedicated to the log status and Group Replication.
The connection thread can be optimized by reducing the size of the replication event by only including minimal information about the before values for the updated rows in the replication events. This will not work for all applications though. You can also make changes to the network and to writing the relay log. It is recommended to use GTID-based replication with auto-positioning enabled which allows you to relax the synchronization of the relay log.
The two most important things for the performance of the applier are to enable parallel replication and to ensure all tables have a primary key. Parallel replication can be either over the schema the updates affect or by the logical clock. The latter is often what performs the best, but there are exceptions, so you will need to verify with your workload.
Finally, it was discussed how you can use replicas to offload work that would otherwise have to be performed on the replication source. You can use replication for read scale-out as you can use the replicas for reading data and dedicate the source for tasks that require writing data. You can also use replicas for highly intensive work such as reporting and backups.
The final chapter will go into reducing the amount of work being done by use of caching.