There are several possible reasons why a poorly performing query does not work as expected. This ranges from the query plainly being wrong over a poor schema to lower-level causes such as a nonoptimal query plan or resource contention. This chapter will discuss some common cases and solutions.
The chapter starts out introducing the test data used for most of the examples in the chapter and discussing the symptoms of excessive full table scans. Then it is covered how errors in the query can cause severe performance problems and why indexes cannot always be used even when they exist. The middle part of the chapter goes through various ways to improve queries either by improving the index use or rewriting complex queries. The last part discusses how the SKIP LOCKED clause can be used to implement a queue system and how to handle queries with many OR conditions or an IN () clause with many values.
Test Data
This chapter mostly uses test data specifically created for the examples in the chapter. The file chapter_24.sql in this book’s GitHub repository includes the necessary table definitions and data, if you want to try the examples yourself. The script will delete the chapter_24 schema and create it with the tables.
You can execute the script using the source command in MySQL Shell or the SOURCE command in the mysql command-line client. For example:
mysql shell> source chapter_24.sql
...
mysql shell> SHOW TABLES FROM chapter_24;
+----------------------+
| Tables_in_chapter_24 |
+----------------------+
| address |
| city |
| country |
| jobqueue |
| language |
| mytable |
| payment |
| person |
+----------------------+
8 rows in set (0.0033 sec)
The script requires the world sample database to be installed before sourcing the chapter_24.sql script.
Note
Since index statistics are determined using random dives into the index, their values will not be the same after each analysis. For that reason, you should not expect to get identical outputs when trying the examples in this chapter.
Symptoms of Excessive Full Table Scans
One of the causes for the most severe performance issues is full table scans particularly when there are joins involved and the full table scan is not on the first table in the query block. It can cause so much work for MySQL that it also affects other connections. A full table scan happens when MySQL cannot use an index for the query either because there is no filter condition or there is no index for the conditions present. A side effect of full table scans is that a lot of data gets pulled into the buffer pool, possibly without ever being returned to the application. This can make the amount of disk I/O increase drastically causing further performance issues.
The symptoms you need to look out for to spot when queries perform excessive table scans are increased CPU usage, increased number of rows accessed, low rate of using indexes, and possible increased disk I/O combined with reduced efficiency of the InnoDB buffer pool.
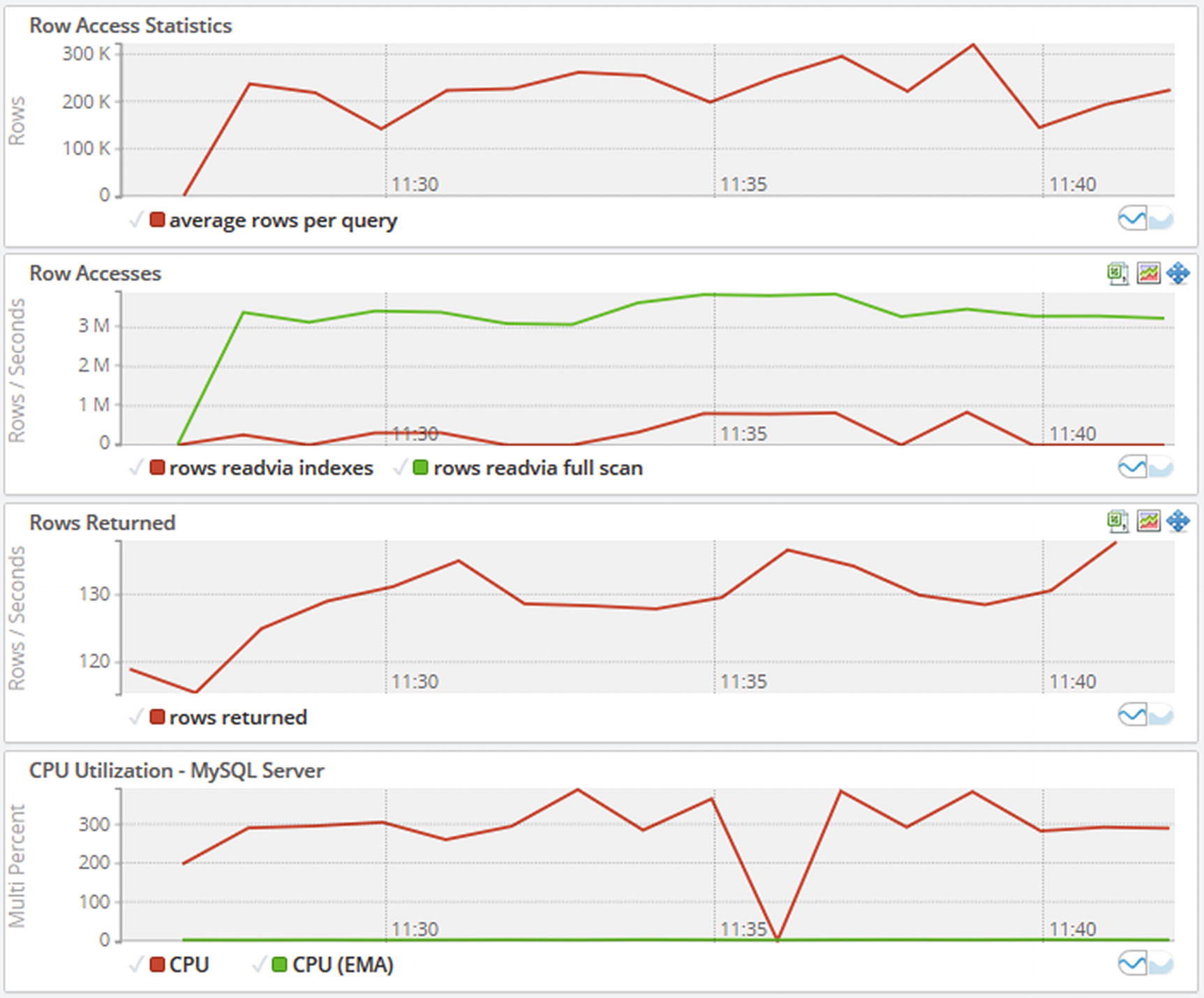
The best way to detect excessive full table scans is to turn to your monitoring. The direct way is to look for queries that have been flagged as using full table scans in the Performance Schema and to compare the ratio of examined rows with the number of returned or affected rows as discussed in Chapter 19. You can also look at the timeseries graphs to spot a pattern of too many rows being accessed or too much CPU usage. Figure 24-1 shows examples of monitoring graphs during a period with full table scans on a MySQL instance. (The employees database is useful if you want to simulate a case like that as it has large enough tables to allow some relatively large scans.)
Figure 24-1
Monitoring graphs while there are queries with full table scans
Notice how at the left side of the graphs, the rows accessed, row access rate for rows read via full scans, and the CPU usage increase. The number of rows returned, on the other hand, changes very little (in percent) compared to the number of rows accessed. Particularly the second graph showing the rate rows are read via index compared to full scans as well as the ratio between rows read and rows returned suggests a problem.
Tip
Full table scans in connection with joins are not as big an issue in MySQL 8.0.18 and later where hash joins can be used for equi-joins. That said, a hash join still pulls more data into the buffer pool than is needed.
The big question is when there is too much CPU usage and too many rows are accessed, and unfortunately the answer is “it depends.” If you consider CPU usage, then all it is really telling is that work is being done, and for the number of rows being accessed and at which rate, those metrics just tell that the application is requesting data. The problem is when too much work is being done and too many rows are accessed for the questions the application needs the answer to. In some cases, optimizing a query may increase some of these metrics rather than reducing them – simply because MySQL with an optimized query is able to do more work.
This is an example why a baseline is so important. You usually get more out of considering changes to the metrics than looking at a snapshot of them. Similarly, you get more out of looking at the metrics in combination – such as comparing rows returned to rows accessed – than looking at them individually.
The next two sections discuss examples of queries accessing an excessive number of rows and how to improve them.
Wrong Query
One of the common reasons for the most poorly performing queries is when the query is written wrongly. This may seem as an unlikely cause, but in practice it can happen more easily than you expect. Typically, the problem is that a join or filter condition is missing or references the wrong table. If you use a framework, for example, using object-relational mapping (ORM), a bug in the framework can also be the culprit.
In the extreme cases, a query with missing filter conditions can make the application time out the query (but not kill it) and retry it, so MySQL keeps executing more and more of the same very badly performing query. This can in turn make MySQL run out of connections.
Another possibility is that the first of the submitted queries start to pull in data to the buffer pool from disk. Then each of the subsequent queries will be faster and faster as they can read some of the rows from the buffer pool and then will slow down when they get to the rows not yet read from disk. In the end, all copies of the query will finish within a short period of time and start to return a large amount of data to the application which can saturate the network. A saturated network can cause connection attempts to fail because of handshake error (the COUNT_HANDSHAKE_ERRORS column in performance_schema.host_cache), and the host the connections are made from can eventually become blocked.
This may seem extreme, and in most cases, it does not become that bad. However, the author of this book has indeed experienced exactly this scenario happen due to a bug in the framework generating the query. Given that MySQL instances nowadays often live in virtual machines in the cloud possibly with a limited amount of resources available such as for CPU and network, it is also more likely that a poor query may end up exhausting the resources.
As an example of a query and query plan where the join condition is missing, consider Listing 24-1 which joins the city and country tables.
-> Table scan on ci (cost=1.78 rows=4188) (actual time=0.025..2.621 rows=4079 loops=1)
-> Hash
-> Table scan on co (cost=25.40 rows=239) (actual time=0.041..0.089 rows=239 loops=1)
1 row in set (0.4094 sec)
Listing 24-1
Query that is missing a join condition
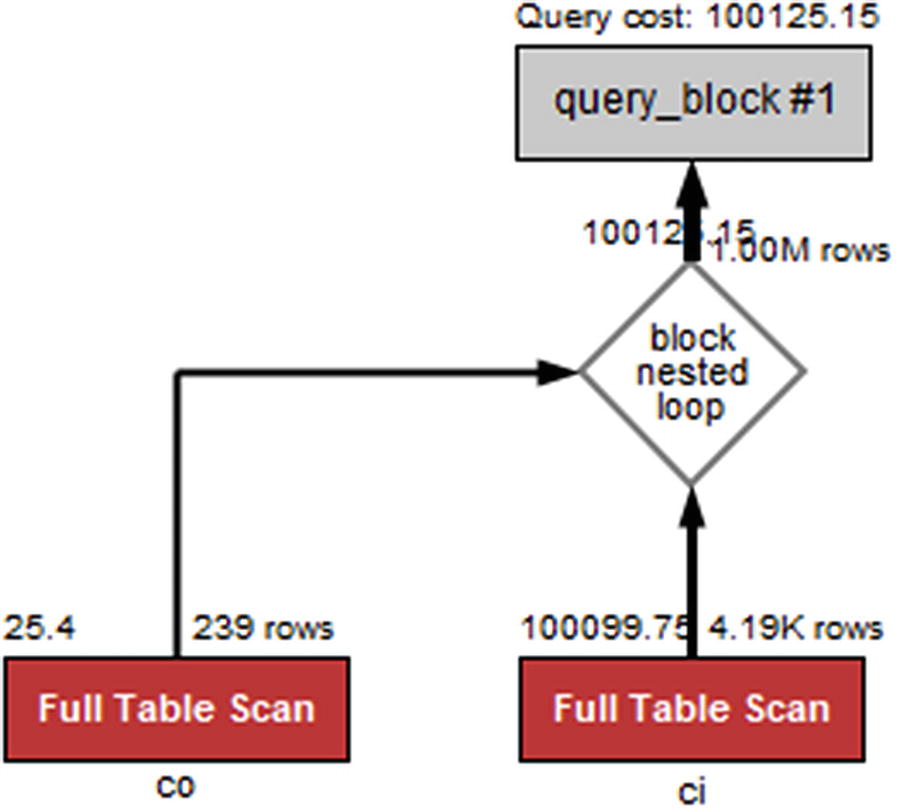
Notice how both tables have the access type set to ALL and that the join is using the join buffer in a block nested loop. A cause that often has similar symptoms is a correct query, but where the query cannot use indexes. The EXPLAIN ANALYZE output shows that a hash join is used in version 8.0.18. It also shows that a total of almost 1 million rows are returned! The Visual Explain diagram for the query is shown in Figure 24-2.
Figure 24-2
Visual Explain for a query that is missing a join condition
Notice here how the two (red) full table scans stand out and how the query cost is estimated to be more than 100,000.
The combinations of multiple full table scans, a very high estimated number of returned rows, and a very high cost estimate are the telltale signs you need to look for.
A cause of poor query performance that gives similar symptoms is when MySQL is not able to use an index for the filter and join conditions.
No Index Used
When a query needs to find rows in a table, it can essentially do it in two ways: accessing the rows directly in a full table scan or going through an index. In cases where there is a filter that is highly selective, it is usually much faster to access the rows through an index than through a table scan.
Obviously, if there is no index on the column the filter applies to, MySQL has no choice but to use a table scan. What you may find is that even if there is an index, then it cannot be used. Three common reasons for this are that the columns are not the first in a multicolumn index, the data type does not match for the comparison, and a function is used on the column with the index. This section will discuss each of these causes.
Tip
It can also happen that the optimizer thinks that an index is not selective enough to make it worth using it compared to a full table scan. That case is handled in the section “Improving the Index Use” together with the example of MySQL using the wrong index.
Not a Left Prefix of Index
For an index to be used, a left prefix of the index must be used. For example, if an index includes three columns as (a, b, c), then a condition on column b can only use the filter if there is also an equality condition on column a.
Examples of conditions that can use the index are
WHERE a = 10 AND b = 20 AND c = 30
WHERE a = 10 AND b = 20 AND c > 10
WHERE a = 10 AND b = 20
WHERE a = 10 AND b > 20
WHERE a = 10
An example where the index cannot be used as effectively is WHERE b = 20. In MySQL 8.0.13 and later, if a is a NOT NULL column, MySQL can use the index using the skip scan range optimization. If a allows NULL values, then the index cannot be used. The condition WHERE c = 20 cannot use the index under any circumstances.
Similarly, for the condition WHERE a > 10 AND b = 20, the index will only be used for filtering on the a column. When a query only uses a subset of the columns in the index, it is important that the order of the columns in the index corresponds to which filters are applied. If you have a range condition on one of the columns, make sure that column is the last one being used in the index. For example, consider the table and query in Listing 24-2.
Query that cannot use the index effectively due to column order
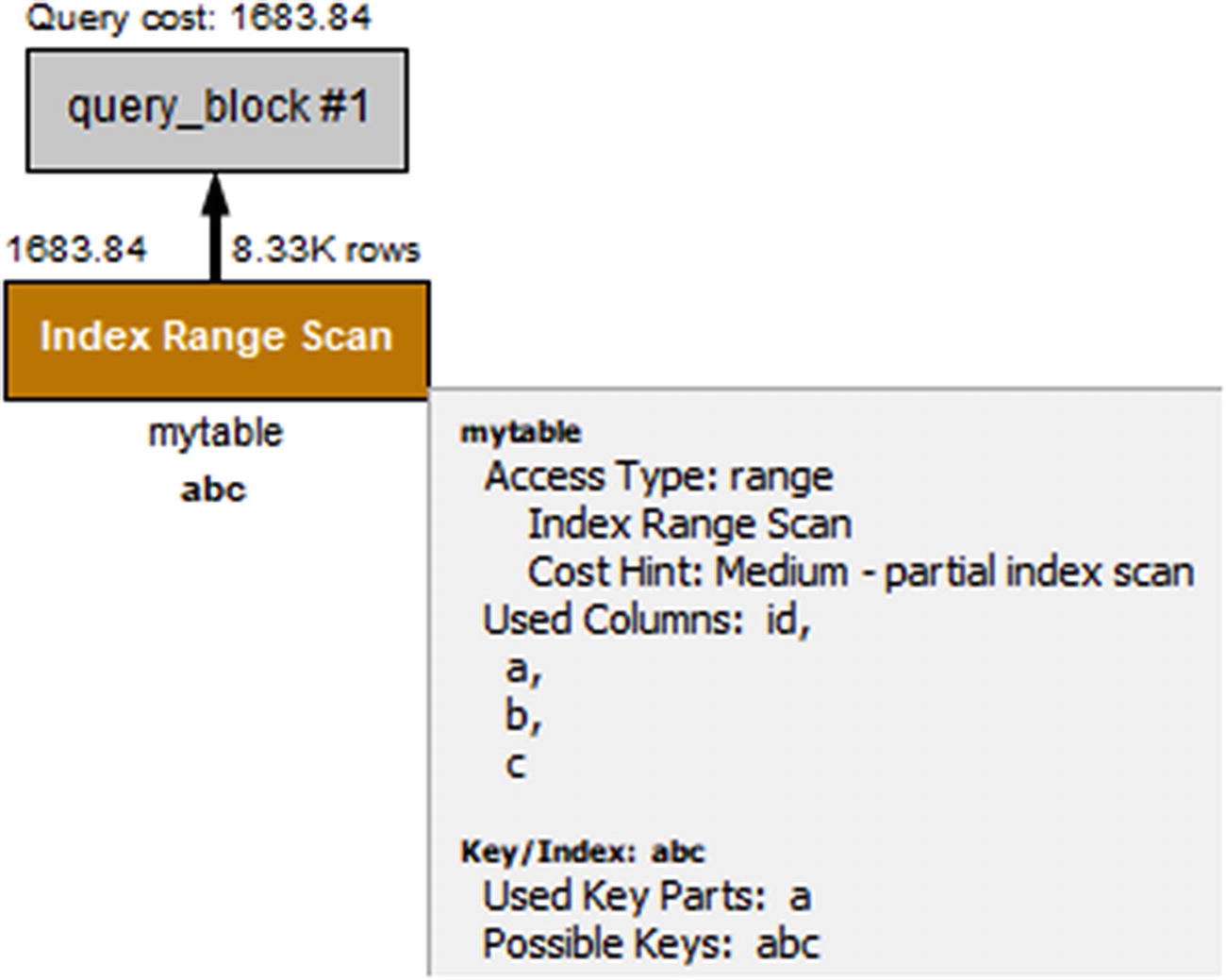
Notice in the EXPLAIN output that the key_len is only 4 bytes, whereas it should be 9 if the index was used for both the a and b columns. The output also shows that it is estimated that only 10% of the rows that are examined will be included. Figure 24-3 shows the same example in Visual Explain.
Figure 24-3
Visual Explain with nonoptimal column order in the index
Notice that the Used Key Parts (near the bottom of the box with additional details) just lists column a. However, if you change the order of the columns in the index, so that column b is indexed before column a, then the index can be used for the conditions on both columns. Listing 24-3 shows how the query plan changes after adding a new index (b, a, c).
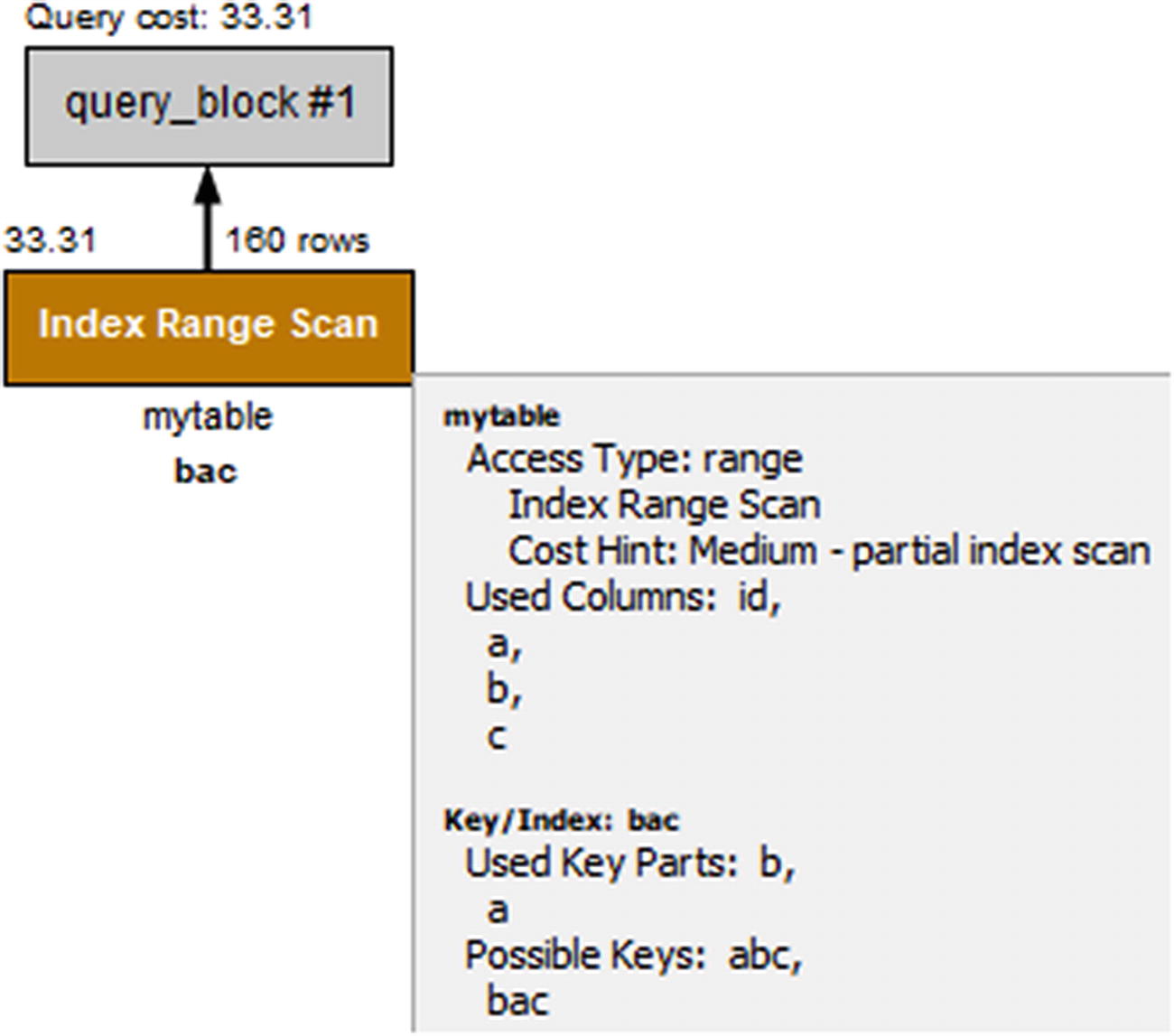
Notice how the key_len column now returns 9 bytes and that the filtered column shows that 100% of the examined rows will be included from the table. The same is reflected in Visual Explain as shown in Figure 24-4.
Figure 24-4
Visual Explain when there is an optimally ordered index
In the figure, you can see that the number of rows that will be examined is reduced from more than 8000 rows to 160 rows and that Used Key Parts now includes both the b and a columns. The estimated query cost has also reduced from 1683.84 to 33.31.
Data Types Not Matching
Another thing that you need to look out for is that both sides of a condition use the same data type and for strings that the same collation is used. If that is not the case, MySQL may not be able to use an index.
When a query is not working optimally because of the data types or collations not matching, it can be hard to realize at first what the problem is. The query is correct, but MySQL refuses to use the index that you expect. Other than the query plan not being what you expect, the query result may also be wrong. This can happen due to the casting, for example:
mysql> SELECT ('a130' = 0), ('130a131' = 130);
+--------------+-------------------+
| ('a130' = 0) | ('130a131' = 130) |
+--------------+-------------------+
| 1 | 1 |
+--------------+-------------------+
1 row in set, 2 warnings (0.0004 sec)
Notice how the string “a130” is considered equal to the integer 0. That happens because the string starts with a non-numeric character and thus is casted to the value 0. In the same way, the string “130a131” is considered equal to the integer 130 as the leading numeric part of the string is casted to the integer 130. The same kind of unintended matches can occur when casting is used for a WHERE clause or a join condition. This is also a case where inspecting the warnings of a query sometimes can help catch the problem.
If you consider the country and world tables in the test schema for this chapter (the table definitions will be shown during the discussion of the example), you can see an example of a join that does not use an index, when the two tables are joined using the CountryId columns. Listing 24-4 shows an example of a query and its query plan.
Warning (code 1739): Cannot use ref access on index 'CountryId' due to type or collation conversion on field 'CountryId'
Warning (code 1739): Cannot use range access on index 'CountryId' due to type or collation conversion on field 'CountryId'
Note (code 1003): /* select#1 */ select `chapter_24`.`ci`.`ID` AS `chapter_24`.`ci`.`Name` AS `Name`,`chapter_24`.`ci`.`District` AS `District`,'Australia' AS `Country`,`chapter_24`.`ci`.`Population` AS `Population` from `chapter_24`.`city` `ci` join `chapter_24`.`country` `co` where ((`chapter_24`.`ci`.`CountryId` = '15'))
Listing 24-4
Query not using an index due to mismatching data types
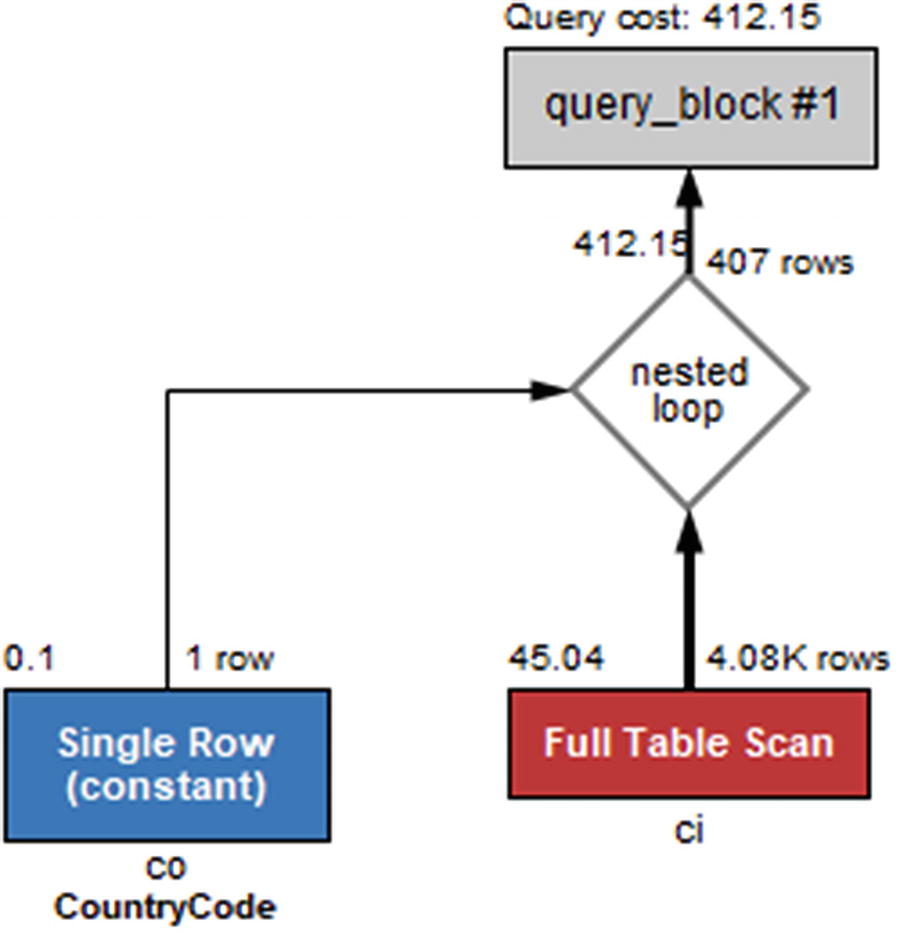
Notice that the access type for the ci (city) table is ALL. This query will neither use a block nested loop nor a hash join as the co (country) table is a constant. The warnings (if you do not use MySQL Shell with warnings enabled, you will need to execute SHOW WARNINGS to fetch the warnings) have been included here as they provide a valuable hint to why it is not possible to use an index, for example: Cannot use ref access on index ‘CountryId’ due to type or collation conversion on field ‘CountryId’. So there is an index that is a candidate, but it cannot be used because the data type or collation is changed. Figure 24-5 shows the same query plan using Visual Explain.
Figure 24-5
Visual Explain where the data types do not match
This is one of the cases where you need the text-based output to get all details as Visual Explain does not include the warnings. When you see a warning like this, go back and check the table definitions. These are shown in Listing 24-5.
The table definitions for the city and country tables
Here it is evident that the CountryId column of the city table is a char(3) column but the CountryId of the country table is an integer. That is why the index on the city.CountryId column cannot be used when the city table is the second table in the join.
Note
If the join goes the other way with the city table being the first table and the country table the second table, then city.CountryId is still casted to an integer, while country.CountryId is not changed, so the index on country.CountryId can be used.
Notice also that the collation is different for the two tables. The city table uses the utf8mb4_general_ci collation (the default utf8mb4 collation in MySQL 5.7 and earlier), whereas the country table uses the utf8mb4_0900_ai_ci (the default utf8mb4 collation in MySQL 8). Different character sets or collations can even prevent the query from executing altogether:
SELECT ci.ID, ci.Name, ci.District,
co.Name AS Country, ci.Population
FROM chapter_24.city ci
INNER JOIN chapter_24.country co
USING (CountryCode)
WHERE co.CountryCode = 'AUS';
ERROR: 1267: Illegal mix of collations (utf8mb4_general_ci,IMPLICIT) and (utf8mb4_0900_ai_ci,IMPLICIT) for operation '='
This is something to be aware of if you create a table in MySQL 8 and use it in queries together with tables created in earlier MySQL versions. In that case, you need to ensure that all tables use the same collation.
The problem with data type mismatch is a special case of using functions in the filters as MySQL does an implicit cast. In general, using functions in filters is something that can prevent the use of an index.
Functional Dependencies
The last common reason for an index not to be used is that a function is applied to the column, for example: WHERE MONTH(birth_date) = 7. In that case, you need to rewrite the condition to avoid the function, or you need to add a functional index.
When possible, the best way to handle a case where the use of a function prevents using an index is to rewrite the query to avoid the function. While a functional index can also be used, unless it helps create a covering index, the index adds overhead which is avoided with a rewrite. Consider a query that wants to find the details of persons born in 1970 as in the example in Listing 24-6 using the chapter_24.person table.
This query uses the YEAR() function to determine the year the person is born in. An alternative is to look for everyone born between January 1, 1970, and December 31, 1971 (both days included), which amount to the same thing. Listing 24-7 shows that in this case the index on the birthdate column is used.
Rewriting the YEAR() function to a date range condition
This rewrite reduces the query from using a table scan examining 1000 rows to an index range scan just examining six rows. A rewrite similar to this is often possible where functions are used on dates which effectively extract a range of values.
Note
It can be tempting to rewrite a date or datetime range condition using the LIKE operator, for example: WHERE birthdate LIKE '1970-%'. This will not allow MySQL to use a query and is discouraged. Use a proper range instead.
It is not always possible to rewrite a condition that uses a function in the way just demonstrated. It may be the condition does not map into a single range or that the query is generated by a framework or a third-party application, so you cannot change it. In that case, you can add a functional index.
Note
Functional indexes are supported in MySQL 8.0.13 and later. If you use an earlier release, you are recommended to upgrade. If that is not possible or you also need the value returned by the function, you can emulate functional indexes by adding a virtual column with the functional expression and creating an index on the virtual column.
As an example, consider a query that finds all persons with a birthday in a given month – for example, because you want to send them a birthday greeting. In principle that can be done using ranges, but it will require one range per year which is neither practical nor very efficient. Instead, you can use the MONTH() function to extract a numeric value of the month (January is 1 and December 12). Listing 24-8 shows how you can add a functional index that can be used together with a query that finds all persons in the chapter_24.person table who have a birthday in the current month.
After the functional index on MONTH(BirthDate) has been added, the query plan shows that the index used is functional_index.
That concludes the discussion of how to add index support for queries that are currently not using an index. There are several other rewrites that relate to using indexes. These will be covered in the next section.
Improving the Index Use
The previous section considered queries where no index was used for a join or WHERE clause. In some cases, an index is used, but you can improve the index, or another index gives better performance, or indexes cannot be used efficiently because of the complexity of the filters. This section will look at some examples of improving queries already using an index.
Add a Covering Index
In some cases when you query a table, the filtering is performed by an index, but then you have requested a couple of other columns, so MySQL needs to retrieve the whole row. In that case, it would be more efficient to add those extra columns to the index, so the index contains all columns required for the query.
Consider the city table in the chapter_24 sample database:
If you want to find the name and district of all cities with CountryCode = 'USA', then you can use the CountryCode index to find the rows. This is efficient as shown in Listing 24-9.
Notice that 12 bytes are used for the index (three characters each up to 4 bytes wide), and the Extra column does not include Using index. If you create a new index with CountryCode as the first column and District and Name as the remaining columns, you have all columns you need for the query in the index. Choose the order of District and Name as it is most likely you will use them together with the CountryCode in filters and ORDER BY and GROUP BY clauses. If it is equally likely that the columns are used in filters, choose Name before District in the index as the city name is more selective than the district. Listing 24-10 shows an example of this together with the new query plan.
When adding the new index, the old index that just covers the CountryCode column is made invisible. That is done because the new index also can be used for all uses where the old index was used, so there is usually no reason to keep both indexes. (Given the index just on the CountryCode column is smaller than the new index, it is possible that some queries benefit from the old index. By making it invisible, you can verify it is not needed before dropping it.)
The key length is still returned to be 12 bytes as that is what is used for the filtering. However, the Extra column now includes Using index to show that a covering index is being used.
Wrong Index
When MySQL can choose between several indexes, the optimizer will have to decide which to use based on the estimated cost of the two query plans. Since the index statistics and cost estimates are not exact, it can happen that MySQL chooses the wrong index. Special cases are where the optimizer chooses not to use an index even if it is possible to use it or the optimizer chooses to use an index where it is faster to do a table scan. Either way, you need to use index hints.
Tip
Index hints can also be used just to affect whether an index is used for sorting or grouping as discussed in Chapter 17. An example where it can be necessary to use an index hint is when the query chooses to use an index for sorting instead of filtering and that causes poor performance – or vice versa. A case where the reverse can happen is when you have a LIMIT clause and using an index for sorting can allow the query to stop the query early.
When you suspect that the wrong index is used, you need to look at the possible_keys column of the EXPLAIN output to determine which indexes are candidates. Listing 24-11 shows an example of finding information about the people in Japan who turn 20 years old in 2020 and speak English. (Imagine you want to send them a birthday card.) Part of the tree-formatted EXPLAIN output has been replaced by ellipsis to improve the readability by keeping most of the lines within the width of the book page.
-> Single-row index lookup on address using PRIMARY...
1 row in set (0.0006 sec)
Listing 24-11
Finding information about the countries where English is spoken
The key table for this example is the person table which is joined both to the language and address tables. The UPDATE and FLUSH statements are used to emulate that the index statistics are out of date by updating the mysql.innodb_index_stats table and flushing the table to make the new index statistics take effect.
The query can use either the BirthDate, AddressId, or LanguageId index. The effectiveness of the three WHERE clauses (one on each table) is determined very accurately as the optimizer asks the storage engine for a count of rows for each condition. The difficulty for the optimizer is to determine the best join order based on the effectiveness of the join conditions and which index to use for each join. According to the EXPLAIN output, the optimizer has chosen to start with the language table and join on the person table using the LanguageId index for the join and finally join on the address table.
If you suspect the wrong indexes are used for the query (in this case, using LanguageId for the join on the person table is not optimal and is only chosen because the index statistics are “wrong”), the first thing to do is to update the index statistics. The result of this is shown in Listing 24-12.
-> Single-row index lookup on address using PRIMARY...
1 row in set (0.0009 sec)
Listing 24-12
Updating the index statistics to change the query plan
This significantly changed the query plan (only part of the tree-formatted query plan is included for readability) which is easiest seen by comparing the tree-formatted query plan. The tables are still joined in the same order, but now a hash join is used to join the language and person tables. This is effective because only one row is expected from the language table, so doing a table scan on the person table and filtering on the birthdate is a good choice. In most cases where the wrong index is used, updating the index statistics will solve the problem, possibly after changing the number of index dives that InnoDB makes for the tables.
Caution
ANALYZE TABLE triggers an implicit FLUSH TABLES for the tables that are analyzed. If you have long-running queries using the analyzed tables, no other queries requiring access to those tables can start until the long-running queries have completed.
In some cases, it is not possible to solve the performance problem by updating index statistics. In that case, you can then use an index hint (IGNORE INDEX, USE INDEX, and FORCE INDEX) to influence which index MySQL will use. Listing 24-13 shows an example of doing this for the same query as before after changing the index statistics back to become outdated.
This time the USE INDEX (BirthDate) index hint is added for the person table which gives the same query plan as when the index statistics were updated. Notice that the possible keys for the person table only include BirthDate. The disadvantage of this approach is that the optimizer does not have the flexibility to change the query plan should the data change, so the BirthDate index is no longer the most optimal.
This example had three different conditions on the person table (the date range for the birthdate and two join conditions). In some cases, when you have multiple conditions on a table, it is beneficial to do some more extensive rewrites of the query.
Rewriting Complex Index Conditions
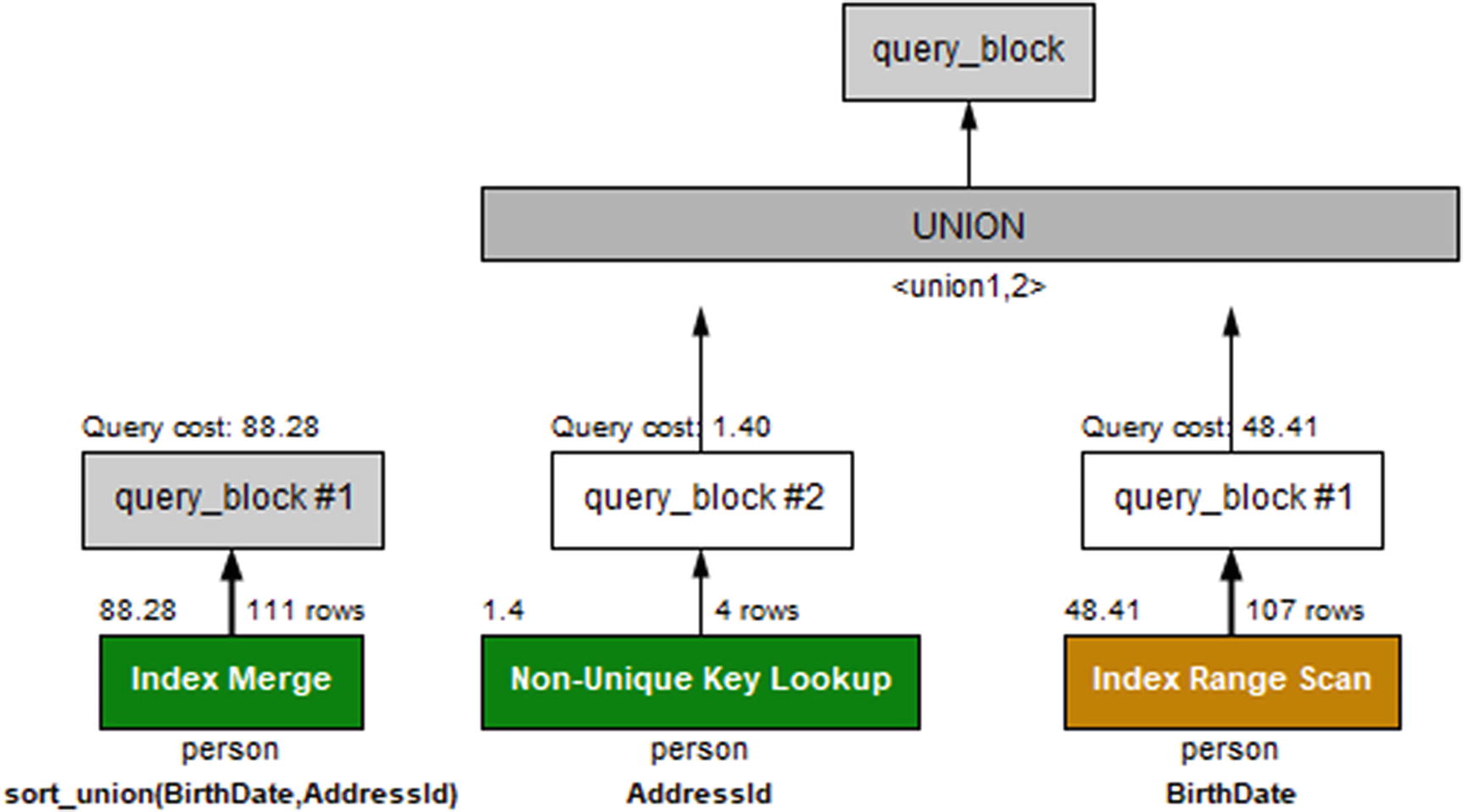
In some cases, a query becomes so complex that it is not possible for the optimizer to come up with a good query plan, and it is necessary to rewrite the query. An example of a case where a rewrite can help includes multiple filters on the same table where the index merge algorithm cannot be used effectively.
-> Index range scan on person using sort_union(BirthDate,AddressId) (cost=88.28 rows=111)
1 row in set (0.0006 sec)
There are indexes for both the BirthDate and AddressId columns, but no index that spans both columns. A possibility is to use an index merge, which the optimizer will choose by default, if it believes the benefit is large enough. Usually this is the preferred way to execute the query, but for some queries (particularly more complex than in this example) it can help to split the two conditions out into two queries and use a union to combine the result:
-> Table scan on <union temporary> (cost=2.50 rows=0)
-> Union materialize with deduplication
-> Index range scan on person using BirthDate, with index condition: (chapter_24.person.BirthDate < DATE'1930-01-01') (cost=48.41 rows=107)
-> Index lookup on person using AddressId (AddressId=3417) (cost=1.40 rows=4)
1 row in set (0.0006 sec)
A UNION DISTINCT (which is also the default union) is used to ensure that rows that fulfill both criteria are not included twice. Figure 24-6 shows the two query plans side by side.
Figure 24-6
Query plans for the original query and rewritten query
On the left is the original query using an index merge (the sort_union algorithm), and on the right is the manually written union.
Rewriting Complex Queries
The optimizer has by MySQL 8 had several transformation rules added, so it can rewrite a query to a form where it performs better. This means that the need for rewriting complex queries keeps reducing as the optimizer knows more and more transformations. For example, as late as the 8.0.l7 release, support was added to rewrite NOT IN (subquery), NOT EXISTS (subquery), IN (subquery) IS NOT TRUE, and EXISTS (subquery) IS NOT TRUE into an antijoin which means the subquery is removed.
That said, it is still good to consider how queries potentially can be rewritten, so you can help the optimizer on its way for the cases where it does not arrive at the optimal solution or it does not know how to do the rewrite on its own. There are also cases where you can take advantage of the support for common table expressions (CTEs – also known as the with syntax) and window functions to make queries more effective and easier to read. This section will start out considering common table expressions and window functions and then finish off rewriting a query using IN (subquery) to a join and to use two queries.
Common Table Expressions and Window Functions
It is beyond the scope of this book to go into the details of using common table expressions and window functions. This chapter will include a few examples to give an idea of how you can use the features. A good starting point for a general overview is MariaDB and MySQL Common Table Expressions and Window Functions Revealed by Daniel Bartholomew and published by Apress (www.apress.com/gp/book/9781484231197).
The common table expressions feature allows you to define a subquery at the start of the query and use it as a normal table in the main part of the query. There are several advantages of using common table expressions instead of inlining the subqueries including better performance and readability. Part of the better performance comes from support of referencing the common table expression multiple times in a query, whereas an inlined subquery can only be referenced once.
As an example, consider a query against the sakila database that calculates the sales per month per the staff member who handled the rental:
SELECT DATE_FORMAT(r.rental_date,
'%Y-%m-01'
) AS FirstOfMonth,
r.staff_id,
SUM(p.amount) as SalesAmount
FROM sakila.payment p
INNER JOIN sakila.rental r
USING (rental_id)
GROUP BY FirstOfMonth, r.staff_id;
If you want to know how much the sales changes from month to month, then you will need to compare the sales for one month with that of the previous month. To do that without using common table expressions, you either need to store the result of the query in a temporary table or duplicate it as two subqueries. Listing 24-14 shows an example of the latter.
SELECT current.staff_id,
YEAR(current.FirstOfMonth) AS Year,
MONTH(current.FirstOfMonth) AS Month,
current.SalesAmount,
(current.SalesAmount
- IFNULL(prev.SalesAmount, 0)
) AS DeltaAmount
FROM (
SELECT DATE_FORMAT(r.rental_date,
'%Y-%m-01'
) AS FirstOfMonth,
r.staff_id,
SUM(p.amount) as SalesAmount
FROM sakila.payment p
INNER JOIN sakila.rental r
USING (rental_id)
GROUP BY FirstOfMonth, r.staff_id
) current
LEFT OUTER JOIN (
SELECT DATE_FORMAT(r.rental_date,
'%Y-%m-01'
) AS FirstOfMonth,
r.staff_id,
SUM(p.amount) as SalesAmount
FROM sakila.payment p
INNER JOIN sakila.rental r
USING (rental_id)
GROUP BY FirstOfMonth, r.staff_id
) prev ON prev.FirstOfMonth
= current.FirstOfMonth
- INTERVAL 1 MONTH
AND prev.staff_id = current.staff_id
ORDER BY current.staff_id,
current.FirstOfMonth;
Listing 24-14
The monthly sales and change in sales without CTEs
This hardly qualifies for the query that is easiest to read and understand. The two subqueries are identical and the same as that used to find the sales per staff per month. The two derived tables are joined by comparing the current and previous months for the same staff member. Finally, the result is ordered by the staff member and the current month. The result is shown in Listing 24-15.
One thing to notice from the result is that there are no sales data in the months September 2005–January 2006. The query assumes the sales amounts are 0 in that period. When rewriting this query to use a window function, it is shown how to add the missing months.
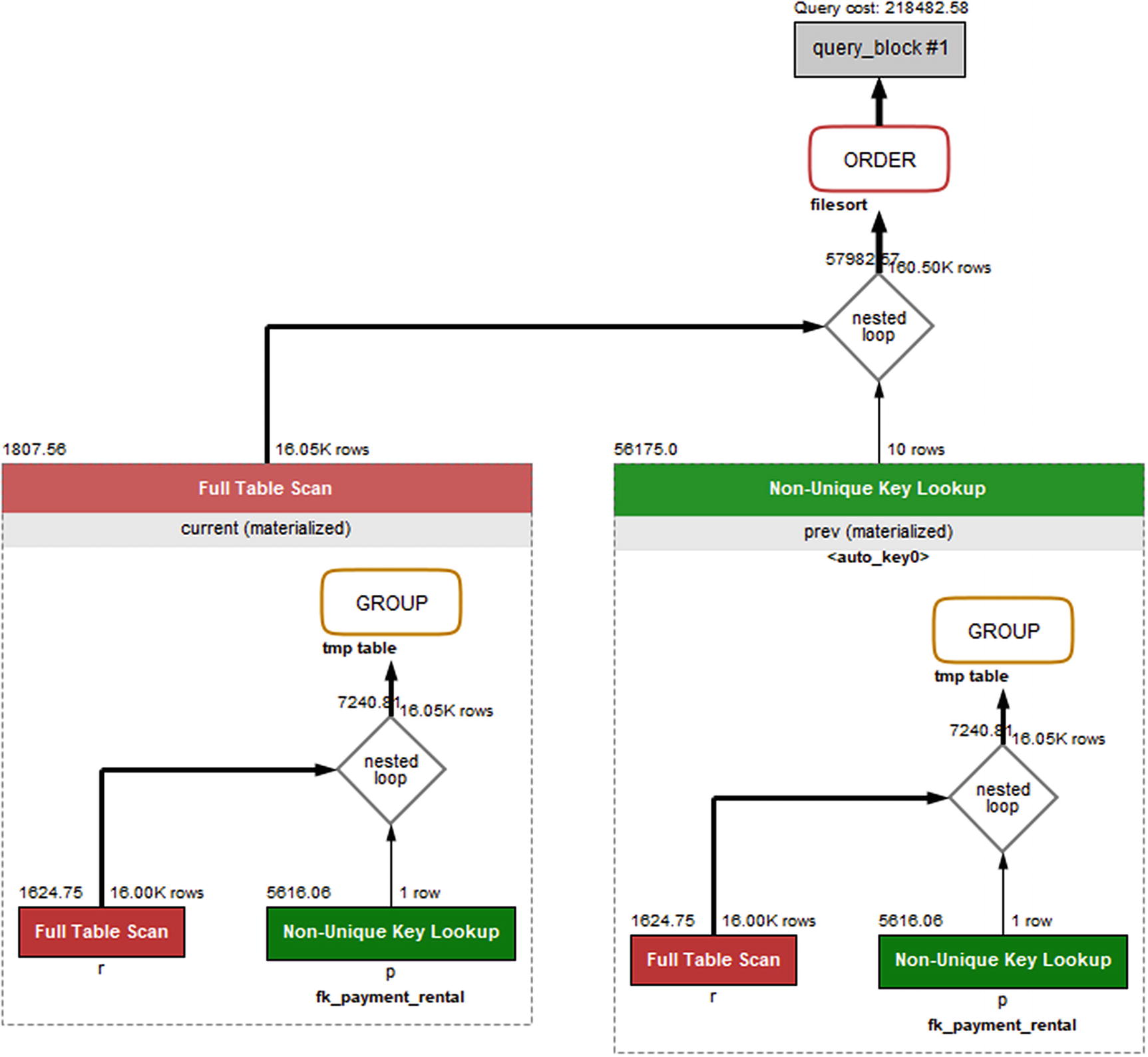
Figure 24-7 shows the query plan for this version of the query.
Figure 24-7
Visual Explain for the non-CTE query
The query plan shows that the subquery is evaluated twice; then the join is performed using a full table scan on the subquery named current and joined using an index (and auto-generated index) in a nested loop to form the result that is ordered by a file sort.
If you use common table expressions, you can just define the subquery once and refer to it twice. This simplifies the query and makes it perform better. The version of the query using common table expressions is shown in Listing 24-16.
WITH monthly_sales AS (
SELECT DATE_FORMAT(r.rental_date,
'%Y-%m-01'
) AS FirstOfMonth,
r.staff_id,
SUM(p.amount) as SalesAmount
FROM sakila.payment p
INNER JOIN sakila.rental r
USING (rental_id)
GROUP BY FirstOfMonth, r.staff_id
)
SELECT current.staff_id,
YEAR(current.FirstOfMonth) AS Year,
MONTH(current.FirstOfMonth) AS Month,
current.SalesAmount,
(current.SalesAmount
- IFNULL(prev.SalesAmount, 0)
) AS DeltaAmount
FROM monthly_sales current
LEFT OUTER JOIN monthly_sales prev
ON prev.FirstOfMonth
= current.FirstOfMonth
- INTERVAL 1 MONTH
AND prev.staff_id = current.staff_id
ORDER BY current.staff_id,
current.FirstOfMonth;
Listing 24-16
The monthly sales and change in sales using CTE
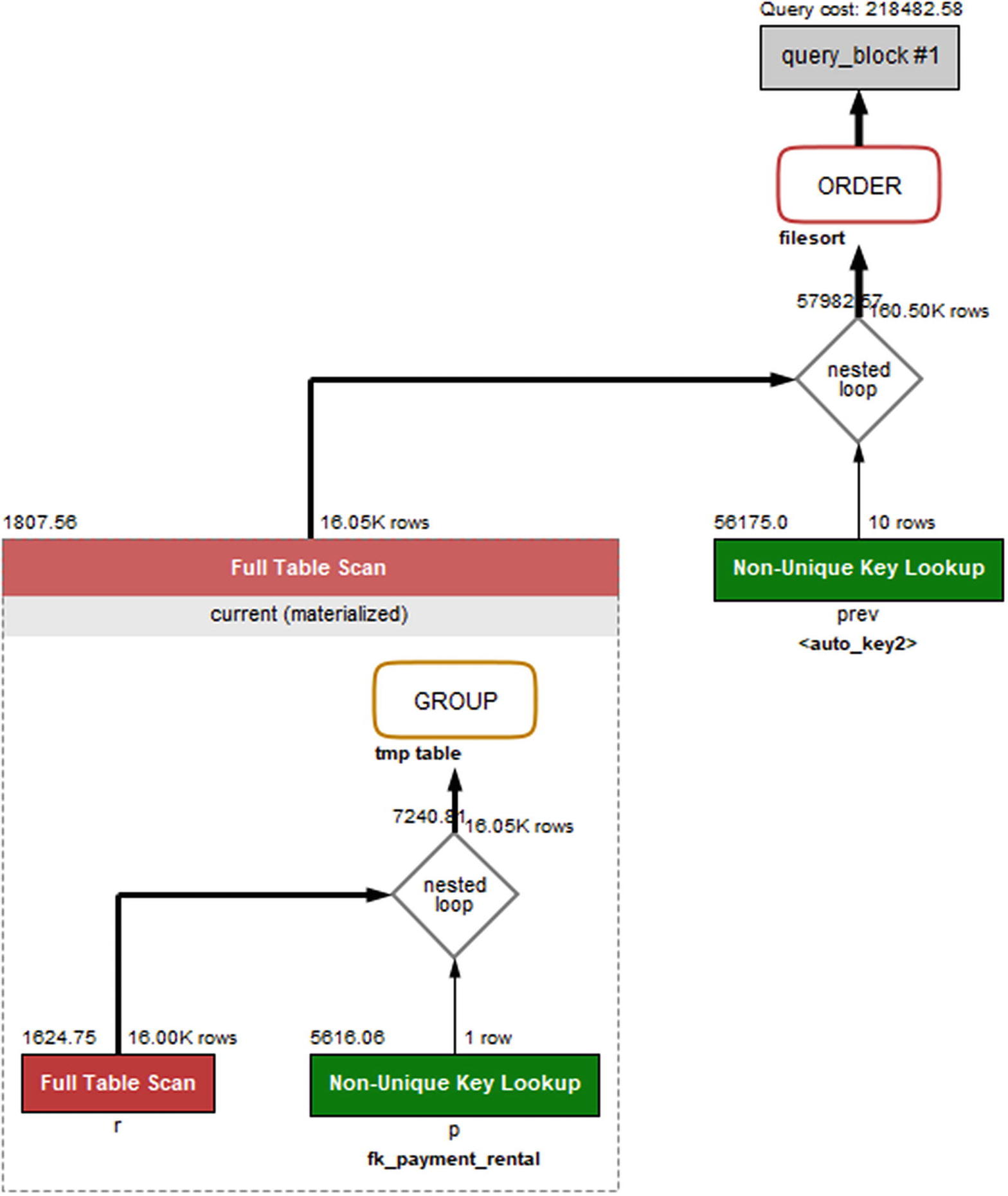
The common table expression is defined first with the WITH keyword and given the name monthly_sales. The table list in the main part of the query can then just refer to monthly_sales. The query executes in around half the time as the original query. An added benefit is that if the business logic changes, you only need to update it in one place which reduces the potential for ending up with a bug in the query. Figure 24-8 shows the query plan for the version of the query using the common table expression.
Figure 24-8
Visual Explain when using a common table expression
The query plan shows that the subquery is only executed once and then reused as a regular table. Otherwise, the query plan remains the same.
You could also have solved this problem using a window function.
Window Functions
Window functions allow you to define a frame where the window functions return values that depend on other rows in the frame. You can use this to generate row numbers and percentage of a total, compare a row to the previous or next row, and more. Here the previous example of finding the monthly sales numbers and comparing them to the previous month will be explored.
You can use the LAG() window function to get the value of a column in the previous row. Listing 24-17 shows how you can use that to rewrite the monthly sales query to use the LAG() window function as well as add the months without sales.
WITH RECURSIVE
month AS
(SELECT MIN(DATE_FORMAT(rental_date,
'%Y-%m-01'
)) AS FirstOfMonth,
MAX(DATE_FORMAT(rental_date,
'%Y-%m-01'
)) AS LastMonth
FROM sakila.rental
UNION
SELECT FirstOfMonth + INTERVAL 1 MONTH,
LastMonth
FROM month
WHERE FirstOfMonth < LastMonth
),
staff_member AS (
SELECT staff_id
FROM sakila.staff
),
monthly_sales AS (
SELECT month.FirstOfMonth,
s.staff_id,
IFNULL(SUM(p.amount), 0) as SalesAmount
FROM month
CROSS JOIN staff_member s
LEFT OUTER JOIN sakila.rental r
ON r.rental_date >=
month.FirstOfMonth
AND r.rental_date < month.FirstOfMonth
+ INTERVAL 1 MONTH
AND r.staff_id = s.staff_id
LEFT OUTER JOIN sakila.payment p
USING (rental_id)
GROUP BY FirstOfMonth, s.staff_id
)
SELECT staff_id,
YEAR(FirstOfMonth) AS Year,
MONTH(FirstOfMonth) AS Month,
SalesAmount,
(SalesAmount
- LAG(SalesAmount, 1, 0) OVER w_month
) AS DeltaAmount
FROM monthly_sales
WINDOW w_month AS (ORDER BY staff_id, FirstOfMonth)
ORDER BY staff_id, FirstOfMonth;
Listing 24-17
Combing CTEs and the LAG() window function
This query at first seems quite complex; however, the reason for this is that the first two common table expressions are used to add sales data for each month between the first and last months with rental data. The cross product (notice how an explicit CROSS JOIN is used to make it clear that the cross join is intended) between the month and staff_member tables is used as a base for the monthly_sales table with an outer join made on the rental and payment tables.
The main query now becomes simple as all the information required can be found in the monthly_sales table. A window is defined by ordering the sales data by staff_id and FirstOfMonth, and the LAG() window function is used over this window. Listing 24-18 shows the result.
The result of the sales query using the LAG() function
Notice how the months without sales data have been added with a sales amount of 0.
Note
The window does not require the values over which it orders the data to be in sequence. If you omit the month and staff_member expressions, the lag for February 2006 becomes August 2005. This may very well be what you want – but it is a different result compared to the solution found by the original query in Listing 24-14. It is left as an exercise for the reader to change the query and see the difference.
Rewrite Subquery As Join
When you have a subquery, an option is to change a subquery to a join. The optimizer will often perform this kind of rewrite on its own when possible, but occasionally, it is useful to help the optimizer on the way.
As an example, consider the following query:
SELECT *
FROM chapter_24.person
WHERE AddressId IN (
SELECT AddressId
FROM chapter_24.address
WHERE CountryCode = 'AUS'
AND District = 'Queensland');
This query finds all persons who live in Queensland, Australia. It can also be written as a join between the person and address tables:
SELECT person.*
FROM chapter_24.person
INNER JOIN chapter_24.address
USING (AddressId)
WHERE CountryCode = 'AUS'
AND District = 'Queensland';
As a matter of fact, MySQL makes this exact rewrite (except the optimizer chooses the address table to be the first since that is where the filters are). This is an example of a semijoin optimization. If you come across a query where the optimizer cannot rewrite the query, you can have rewrites like this in mind. Usually the closer you get to a query just consisting of joins, the better the query performs. However, the life of query tuning is more complicated than that, and sometimes going the opposite way improves the query performance. The lesson is always to test.
Another option you can use is to split a query into parts and execute them in steps.
Splitting a Query Into Parts
A last option is to split a query into two or more parts. With the support for common table expressions and window functions in MySQL 8, this type of rewrite is not needed nearly as often as in older versions of MySQL. Yet, it can be useful to keep in mind.
Tip
Do not underestimate the power of splitting a complex query into two or more simpler queries and gradually generating the query result.
As an example, consider the same query as in the previous discussion where you find all persons who live in Queensland, Australia. You can execute the subquery as a query of its own and then put the result back into the IN() operator. This kind of rewrite works best in applications where the application programmatically can generate the next query. For simplicity, this discussion will just show the SQL required. Listing 24-19 shows the two queries.
mysql> SET SESSION transaction_isolation = 'REPEATABLE-READ';
The queries are executed using a transaction with the REPEATABLE-READ transaction isolation level, which means that the two SELECT queries will use the same read view and thus correspond to the same point in time in the same way as if you executed the question as one query. For a query as simple as this, there is no gain from using multiple queries; however, in the case of really complex queries, it can be an advantage to split out part of the query (possibly including some joins). One additional benefit of splitting queries into parts is also that in some cases you can make caching more efficient. For this example, if you have other queries using the same subquery to find the addresses in Queensland, caching can allow you to reuse the result for multiple uses.
Queue System: SKIP LOCKED
A common task in connection with databases is to handle some list of tasks that are stored in a queue. An example is to handle orders in a shop. It is important that all tasks are handled and that they are handled only once, but it is not important which application thread handles each task. The SKIP LOCKED clause is perfect for such a scenario.
Consider the table jobqueue that is defined as shown in Listing 24-20.
When HandledDate is NULL, then the task has not yet been handled and is up for grabs. If your application is set up to fetch the oldest unhandled task and you want to rely on InnoDB row locks to prevent two threads taking the same task, then you can use SELECT ... FOR UPDATE, for example (in the real world the statement would be part of a larger transaction):
SELECT JobId
FROM chapter_24.jobqueue
WHERE HandledDate IS NULL
ORDER BY SubmitDate
LIMIT 1
FOR UPDATE;
This works well for the first request, but the next will block until a lock wait timeout occurs or the first task has been handled, so the task processing is serialized. The trick is to ensure there is an index on the columns you filter and sort by, and you then use the SKIP LOCKED clause. Then the second connection will simply skip the locked rows and find the first non-locked row fulfilling the search criteria. Listing 24-21 shows an example of two connections each fetching a job from the queue.
Connection 1> START TRANSACTION;
Query OK, 0 rows affected (0.0002 sec)
Connection 1> SELECT JobId
FROM chapter_24.jobqueue
WHERE HandledDate IS NULL
ORDER BY SubmitDate
LIMIT 1
FOR UPDATE
SKIP LOCKED;
+-------+
| JobId |
+-------+
| 1 |
+-------+
1 row in set (0.0004 sec)
Connection 2> START TRANSACTION;
Query OK, 0 rows affected (0.0003 sec)
Connection 2> SELECT JobId
FROM chapter_24.jobqueue
WHERE HandledDate IS NULL
ORDER BY SubmitDate
LIMIT 1
FOR UPDATE
SKIP LOCKED;
+-------+
| JobId |
+-------+
| 2 |
+-------+
1 row in set (0.0094 sec)
Listing 24-21
Fetching tasks with SKIP LOCKED
Now both connections can fetch tasks and work on them at the same time. Once the task has been completed, the HandledDate can be set and the task marked as complete. The advantage of this approach compared with having a lock column that the connection sets is that if the connection for some reason fails, the lock is automatically released.
You can use the data_locks table in the Performance Schema to see which connection has each lock (the order of the locks depends on the thread ids which will be different for you):
The hex values are the encoded datetime values for the SubmitDate column. From the output, it can be seen that each connection holds one record lock in the secondary index and one in the primary key just as expected from the JobId values returned by the SELECT queries.
Many OR or IN Conditions
A query type that can cause confusion when it comes to performance is queries with many range conditions. This typically can be an issue when there are many OR conditions or the IN () operator has many values. In some cases, a small change to the condition may totally change the query plan.
When the optimizer encounters a range condition on an indexed column, it has two options: it can assume all values in the index occur equally frequent, or it can ask the storage engine to do index dives to determine the frequency of each range. The former is the cheapest, but the latter is by far more accurate. To decide which method to use, there is the eq_range_index_dive_limit option (default value is 200). If there are eq_range_index_dive_limit or more ranges, the optimizer will just look at the cardinality of the index and assume all values occur at the same frequency. If there are fewer ranges, the storage engine will be asked for each range.
The performance issues can occur when the assumption that each value occurs equally frequent does not hold. In that case, when passing the threshold set by eq_range_index_dive_limit, the estimated number of rows that match the condition may suddenly change significantly causing a completely different query plan. (When you have many values in the IN () operator, what is really the important thing is that the average number of rows matching the values included is close to the estimate obtained from the index statistics. So the more values you have in the list, the more likely you include a representative sample.)
Listing 24-22 shows an example of the payment table that has a column ContactId with an index. Most of the rows have ContactId set to NULL, and the cardinality for the index comes out as 21.
In the example eq_range_index_dive_limit is set to 5 to avoid the need to specify a long list of values. With four values, the optimizer has requested statistics for each of the four values, and the estimated row count is 4. However, if you make the list of values longer, things start to change:
Suddenly, it is estimated that there are 4785 rows matched instead of the five rows that are really matched. The index is still used, but if the payment table with this condition is involved in joins, then the optimizer may very well choose a nonoptimal join order. If you make the list of values longer, the optimizer will stop using the index altogether and do a full table scan as it believes the index works terribly:
This query only returns seven rows, so the index is highly selective. So what can be done to improve the optimizer’s understanding? Depending on the exact nature of the reason for the poor estimate, there are various possible actions. For this particular problem, you have the following options:
Increase eq_range_index_dive_limit.
Change the innodb_stats_method option.
Force MySQL to use the index.
The easiest solution is to increase eq_range_index_dive_limit. The default value is 200, which is a good starting point. If you have a candidate query, you can test with different values of eq_range_index_dive_limit and determine whether the added cost of doing the index dives is worth the savings from getting a better row estimate. A good way to test a new value of eq_range_index_dive_limit for a query is to set the value in the SET_VAR() optimizer hint:
The reason relying on the cardinality causes such a bad row estimate in this case is that almost all rows have the ContactId set to NULL. By default, InnoDB considers all rows with a NULL value for an index to have the same value. That is why the cardinality comes out at just 21 in this example. If you switch innodb_stats_method to nulls_ignored, the cardinality will be calculated only based on the non-NULL values as shown in Listing 24-23.
mysql> SET GLOBAL innodb_stats_method = nulls_ignored;
The biggest issue with this approach is that innodb_stats_method can only be set globally, so it will affect all tables, and it may have a negative effect for other queries. For this example, set innodb_stats_method back to the default value and recalculate the index statistics again:
This will make the query perform as fast as if it had more accurate statistics. However, if the payment table is part of a join with the same WHERE clause, then the row estimate is still off (6699 rows estimated versus seven actual rows), so the query plan may still come out wrong in which case, you need to tell the optimizer what the optimal join order is.
Summary
This chapter has shown several examples of techniques to improve the performance of queries. The first topic was to look at symptoms of excessive full table scans and then look at two primary causes of full table scans: that the query is wrong and that an index cannot be used. Typical reasons an index cannot be used are that the columns used do not form a left prefix of the index, the data types do not match, or a function is used on the column.
It can also happen that an index is used, but the usage can be improved. This can be to convert an index to cover all columns required for the query, that the wrong index is used, or that rewriting a query with complex conditions can improve the query plan.
It can also be useful to rewrite complex queries. MySQL 8 supports common table expressions and window functions that can be used to both simplify the queries and possibly make them perform better. In other cases, it can help to do some of the rewriting that the optimizer usually would do or to split the query into multiple parts.
Finally, two common cases were discussed. The first was to work with a queue where the SKIP LOCKED clause can be used to efficiently access the first non-locked rows. The second is the case of having a long list of OR conditions or an IN () operator with many values which can lead to surprising changes in the query plans when the number of ranges reaches the number set by the eq_range_index_dive_limit option.
The next chapter looks at improving the performance of DDL and bulk data loads.