
There are several approaches to solve problems. At an extreme, you can dive headfirst and try making some changes. While this can seem like a time-saver, more often than not, it just causes frustration, and even when the changes appear to work, you do not know for sure whether you really solved the underlying issue or the issue just temporarily got better.
Instead, the recommendation is to work methodologically by going through analysis and using monitoring to confirm the effect of the changes. This chapter will introduce you to a methodology that can be useful when solving MySQL problems with the focus on performance tuning. The steps in the methodology are first introduced. Then the rest of the chapter discusses each step in more detail as well as why it is important to spend as much time as possible to work proactively.
The methodology described here is based on the methodology used in Oracle support to solve the problems reported by customers.
Overview
MySQL performance tuning can be seen as a never-ending process where an iterative approach is used to gradually improve the performance over time. Obviously, there will be times when there is a specific problem like a query taking half an hour to complete, but it is important to keep in mind that performance is not a binary state, so it is necessary to know what good enough performance is. Otherwise, you will never complete even a single task.
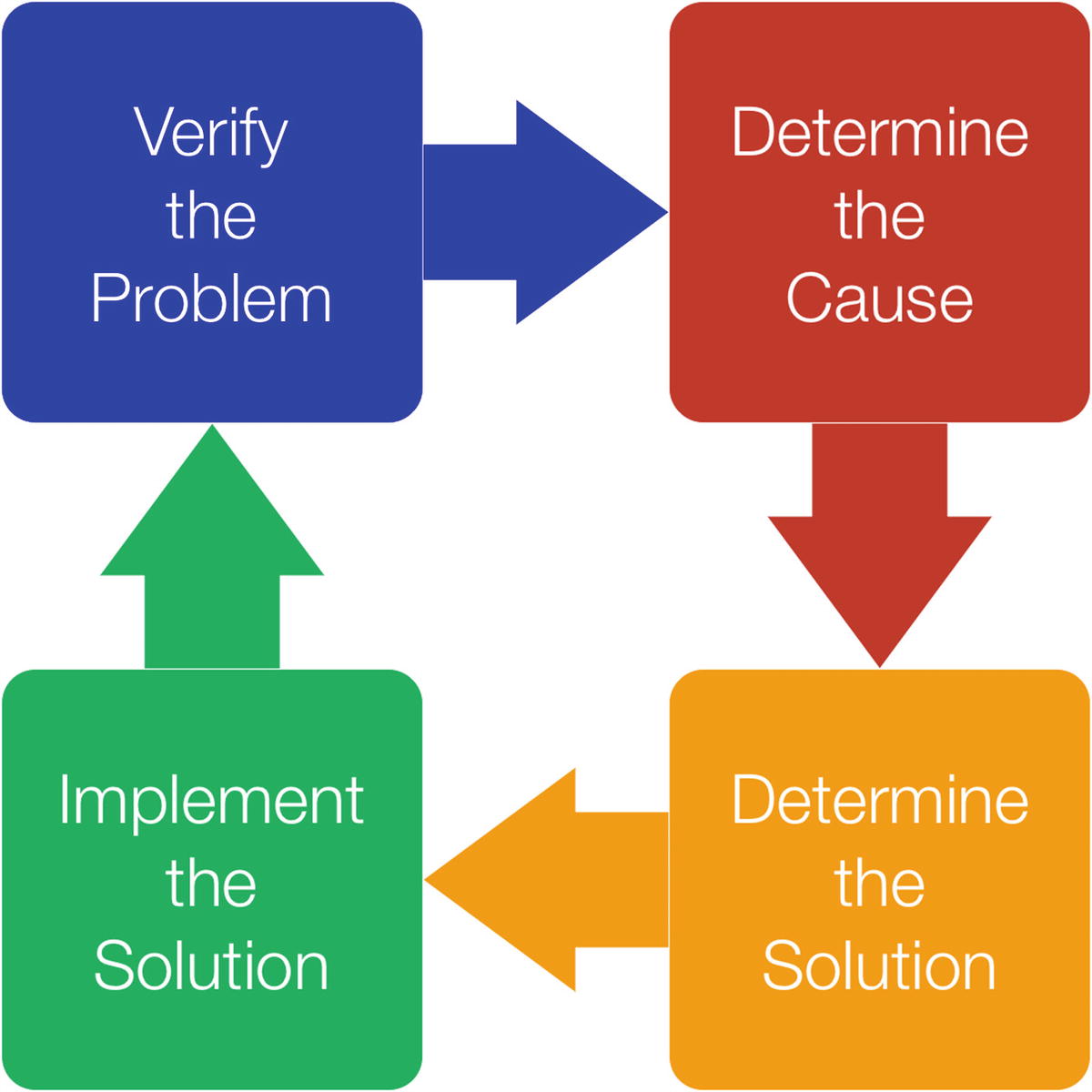
Performance tuning lifecycle
When you encounter a performance problem, the first phase is to verify what the problem is including collecting evidence of the issue and define what the requirement is to consider the problem solved.
The second phase involves determining the cause of the performance issue, and in the third phase you determine the solution. Finally, in the fourth phase you implement the solution. The implementation of the solution should include verifying the effect of the changes.
This cycle works both when doing firefighting during a crisis and when working proactively.
You are then ready to start all over, either doing a second iteration to improve the performance further for the problem you have just been looking at, or you may need to work on a second problem. It may also be that there will be a lengthy period between the cycles.
Verify the Problem
Before you try to determine what causes the problem and what the solution is, it is important that you are clear about what problem you are trying to solve. It is not enough to say “MySQL is slow” – what does that mean? A specific problem may be that “The query used in the second section of the front web page takes five seconds” or that “MySQL can only sustain 5000 transactions per second.” The more specific you are, the better chance you have solving the problem.
The definition of the problem should also include verifying what the problem is. There can be a difference between what the problem seems to be at first and what the real problem is. Verifying the problem may be as simple as executing a query and observing if the query really takes as long as claimed, or it may involve reviewing your monitoring.
The preparation work should also include collecting a baseline from your monitoring or running a data collection that illustrates the problem. Without the baseline, you may not be able to prove that you have solved the issue at the end of the troubleshooting.
Begin with the end in mind.
What is the minimum acceptable target for how quickly the slow query should run, or what is the minimum transaction throughput needed? This will ensure that you know whether the target has been reached when you have made your changes.
When the problem has been clearly defined and verified, you can start analyzing the issue and determine the cause.
Determine the Cause
The second phase is where you determine what the cause of the poor performance is. Make sure you are open-minded and consider the whole stack, so you do not end up staring yourself blind on one aspect that turns out not to have anything to do with the problem.
When you think you know the cause, you also need to argue why that is the cause. You may have an output of the EXPLAIN statement clearly showing that the query performs a full table scan, so that is likely the cause, or you may have a graph showing that the InnoDB redo log was 75% full, so you likely had an asynchronous flush causing temporary performance issues.
Finding the cause is often the hardest part of an investigation. Once the cause is known, you can decide on a solution.
Determine the Solution
It is a two-step process to determine the solution for the issue you investigate. The first step is to find possible solutions; second, you must choose which one to implement.
When you look for possible solutions, it can be useful to do a brainstorm where you write down all the ideas you can think of. It is important that you do not constrain yourself to just consider a narrow area around where the root cause is as often it may be possible to find a solution in a different area. An example are the stalls due to memory fragmentation mentioned in the previous chapter where the solution was to change the configuration of MySQL to use direct I/O to reduce the use of the operating system I/O cache. You should also keep both short-term workarounds and long-term solutions in mind as it may not always be possible to implement the full solution right away, if it requires restarting or upgrading MySQL, changing hardware, or similar.
A sometimes underappreciated solution is to upgrade MySQL or the operating system to get access to new features. However, of course you need to do careful testing to verify that your application works well with the new version with particular care whether there are any changes by the optimizer that cause poor performance for your queries.
The second part of determining the solution is to choose the candidate solution that will work the best. In order to do that, you must argue for each solution why it works and what the pros and cons are. It is important in this step to be honest with yourself and to carefully consider possible side effects.
Once you have a good understanding of all the possible solutions, you can choose which one to proceed with. You may also choose one solution as a temporary mitigation while you work on a more solid solution. In either case, the next phase is to implement the solution.
Implement the Solution
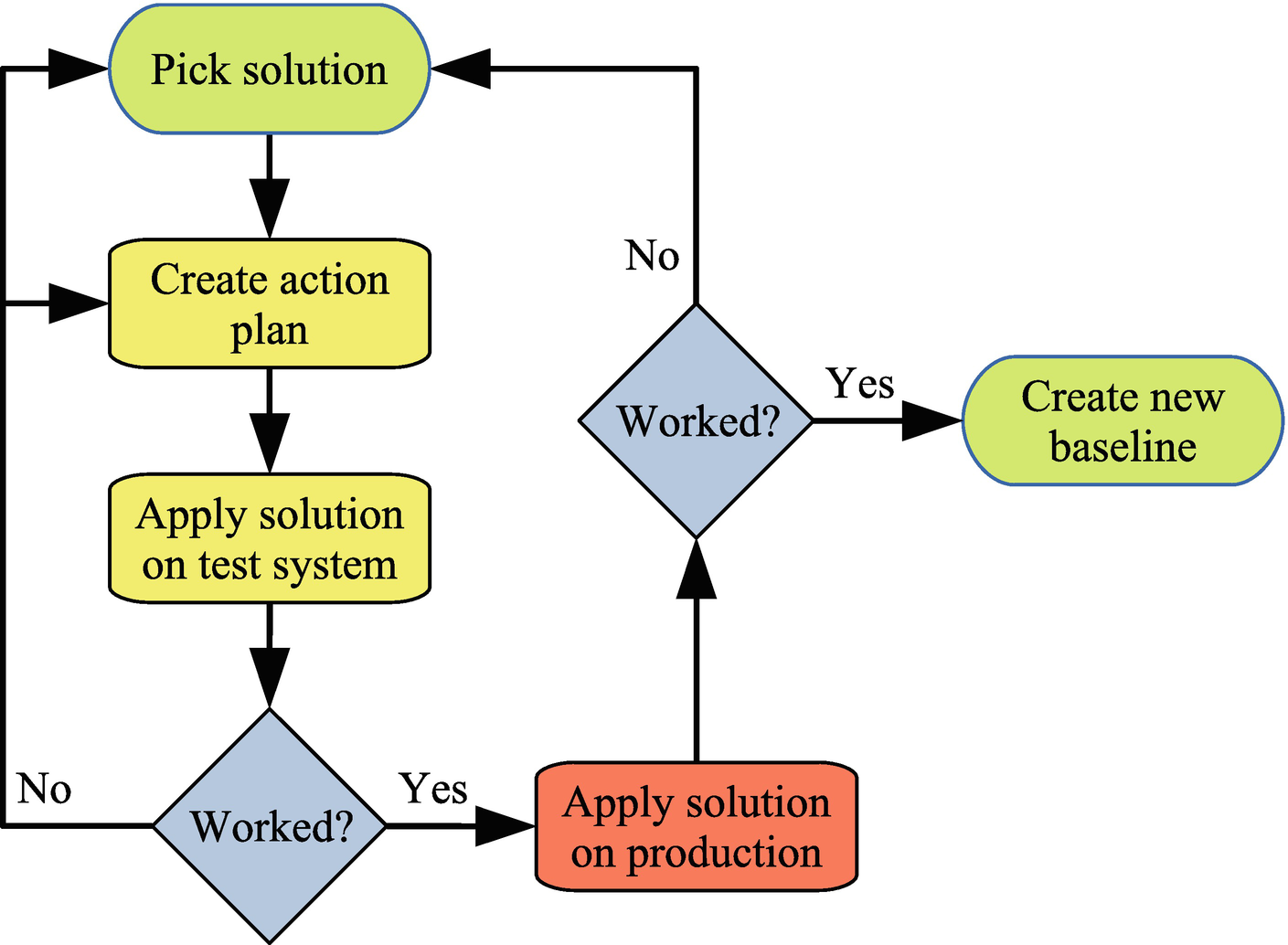
Workflow to implement solution
You take the solution you picked and create an action plan for it. Here it is important to be very specific, so you can ensure that the action plan you test is also the one you end up applying on your production system. It can be useful to write down the exact commands and statements that will be used, so you can copy and paste them, or to collect them in a script, so they can be applied automatically.
You then need to test the action plan on a test system. It is important that it reflects production as closely as possible. The data you have on the test system must be representative of your production data. One way to achieve this is to copy the production data, optionally using data masking to avoid copying sensitive information such as personal details and credit card information out of your production system.
The MySQL Enterprise Edition subscription (paid subscription) includes a data masking feature: www.mysql.com/products/enterprise/masking.html.
The test should verify that the solution solves the problem and that there are no unexpected side effects. What testing is required depends on the problem you are trying to solve and the proposed solution. If you have a slow query, it involves testing the performance of the query after implementing the solution. If you modify the indexes on one or more tables, you must also verify how that affects other queries. You may also need to benchmark the system after implementing the solution. In all cases, you need to compare to the baseline you collected during the issue verification.
It is possible that the first attempt does not work quite as expected. Often, it is just some refinements of the action plan that are needed, other times you may have to completely discard the proposed solution and go back to the previous phase and pick another solution. If the proposed solution partially solves the problem, you may also choose to apply that to the production system and go back to the beginning and evaluate how you can continue to improve the performance.
When you are happy that the testing shows the solution works, you can apply it to the staging system and, if all is still working, the production system. Once you have done that, you again need to verify that it worked. No matter how careful you are at setting up a test system that represents the production system, it is possible that for one reason or another, the solution does not completely work as expected on production. One possibility that the author of this book has encountered is that the index statistics that are random in nature were different, so an ANALYZE TABLE statement to update the index statistics was necessary when applying the solution on the production system.
If the solution works, you should collect a new baseline that you can use for future monitoring and optimizations. If the solution turns out not to work, you need to decide how to proceed by either rolling back the changes and looking for a new solution or doing a new round of troubleshooting and determining why the solution did not work and applying a second solution.
Work Proactively
Performance tuning is a never-ending process. If you have a fundamentally healthy system, most of the work will be proactively where you work at preventing emergencies and where the urgency is relatively low. This will not bring a lot of attention to your job, but it will make your daily life less stressful and the users will be happier.
This discussion is to some degree based on the habit 3 “Put first things first” in Stephen R. Covey’s The 7 Habits of Highly Effective People.
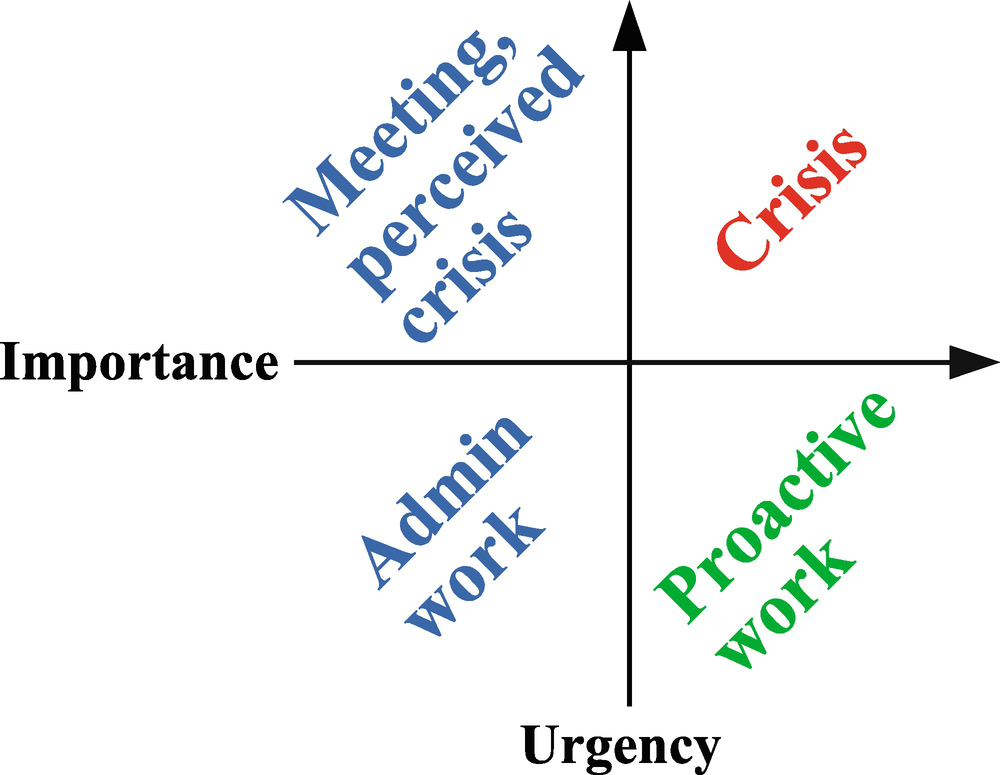
Categorizing tasks according to urgency and importance
The tasks that are simplest to categorize are those that are related to a crisis such as the production system is down and the company loses revenue, because the customers cannot use the product or make purchases. These tasks are both urgent and important. Spending a lot of time on these tasks may make you feel important, but it is also a very stressful way to work.
The most effective way to work with performance problems is to work on important but not urgent problems. This is the proactive work that prevents crisis from happening and consists of monitoring, making improvements before the problems become visible, and so forth. An important task in this category is also to prepare, so you are ready to handle a crisis. This may, for example, be to set up a standby system that you can fail over to in cases of a crisis or procedures to quickly spin up a replacement instance. This can help reduce the duration of a crisis and bring it back into the important but not so urgent category. The more time you spend working on tasks in this category, typically the more successful you are.
The last two categories include the not so important tasks. Examples of urgent but not important tasks include meetings you cannot reschedule, tasks pushed by other people, and a perceived (but not real) crisis. Nonurgent and non-important tasks include administrative tasks and checking emails. Of course, some of these tasks may be required and important for you to keep your job, but they are not important to keep MySQL performing well. While there will always be tasks in these categories that must be handled, it is important to minimize the time spent here.
Part of avoiding working on non-important tasks includes that you understand how important a task is, for example, by defining when the performance is good enough, so you do not end up overoptimizing a query or the throughput. In practice, it can of course be difficult to push back on non-important tasks if they have the attention of other people in the organization (these often tend to be the urgent tasks), but it is important that you do try as much as possible to shift the work back to the important but not urgent tasks to avoid the crisis tasks to take over at a later time.
Summary
This chapter has discussed a methodology that can be used to solve MySQL performance problems (and other types of problems!) as well as the importance of working proactively.
When a problem is reported, you start out verifying what the problem is and determine what is considered to have solved it. For performance problems that are open-ended by nature, it is important to know what is good enough, or you will risk never to stop performing crisis management and go back to proactive work.
Once you have a clear problem description, you can work on determining the cause; and once the cause is clear, you can determine what you want to do to solve the problem. The last phase is to implement the solution which may require you to revisit the potential solutions, if it turns out that the solution you first chose does not work or have unacceptable side effects. In that connection, it is important to test the solution in as realistic a setup as possible.
The last part of the chapter discussed the importance of spending as much time as possible doing proactive work that prevents a crisis from occurring and that helps you be prepared when a crisis does occur. This will help you have a less stressful job and manage a database in better health.
As this chapter has discussed, it is important to test the impact of your solution before you deploy it to your production system. The next chapter covers benchmarking with focus on the Sysbench benchmark.