
Chapter 3: Introducing Amazon Comprehend
In the previous chapter, we covered how you can use Amazon Textract for Optical Character Recognition (OCR) and deep dive into its features and specific API implementations. In this chapter, you will get a detailed introduction to Amazon Comprehend and Amazon Comprehend Medical, what their functions are, what business challenges they were created to solve, what features they have, what types of user requirements they can be applied to, and how easy it is to integrate Comprehend with different AWS services, such as AWS Lambda, to build business applications.
In this chapter, we will go through the following sections:
- Understanding Amazon Comprehend and Amazon Comprehend Medical
- Exploring Amazon Comprehend and Amazon Comprehend Medical product features
- Using Amazon Comprehend with your applications
Technical requirements
For this chapter, you will need access to an AWS account. Before getting started, we recommend that you create an AWS account by referring to AWS account setup and Jupyter notebook creation steps in Technical requirements in Chapter 2, Introducing Amazon Textract. While creating an Amazon SageMaker Jupyter notebook, make sure you input AmazonComprehendFullAccess to the IAM role attached with your notebook instance, and follow these steps:
- Once you create the notebook instance and its status is InService, click on Open Jupyter in the Actions menu heading for the notebook instance.
- In the terminal window, type first cd SageMaker and then type git clone https://github.com/PacktPublishing/Natural-Language-Processing-with-AWS-AI-Services. The Python code and sample datasets for Amazon Comprehend examples are in this repository: https://github.com/PacktPublishing/Natural-Language-Processing-with-AWS-AI-Services. Once you navigate to the repository, please select Chapter 3, Introducing Amazon Comprehend – Sample Code.
Check out the following video to see the Code in Action at https://bit.ly/3Gkd1Oi.
Understanding Amazon Comprehend and Amazon Comprehend Medical
In this section, we will talk about the challenges associated with setting up ML (ML) preprocessing for NLP (NLP). Then, we will talk about how Amazon Comprehend and Amazon Comprehend Medical can help solve these pain points. Finally, we will talk about how you can use Amazon Comprehend to analyze the extracted text from documents by using Amazon Textract to extract the data.
Challenges associated with setting up ML preprocessing for NLP
Some of the key challenges while setting up NLP preprocessing are that documents can be semi-structured, unstructured, or can be in various languages. Once you have a large amount of unstructured data, you would probably like to extract insights from the data using some NLP techniques for most common use cases such as sentiment analysis, text classification, NER (NER), machine translation, and topic modeling.
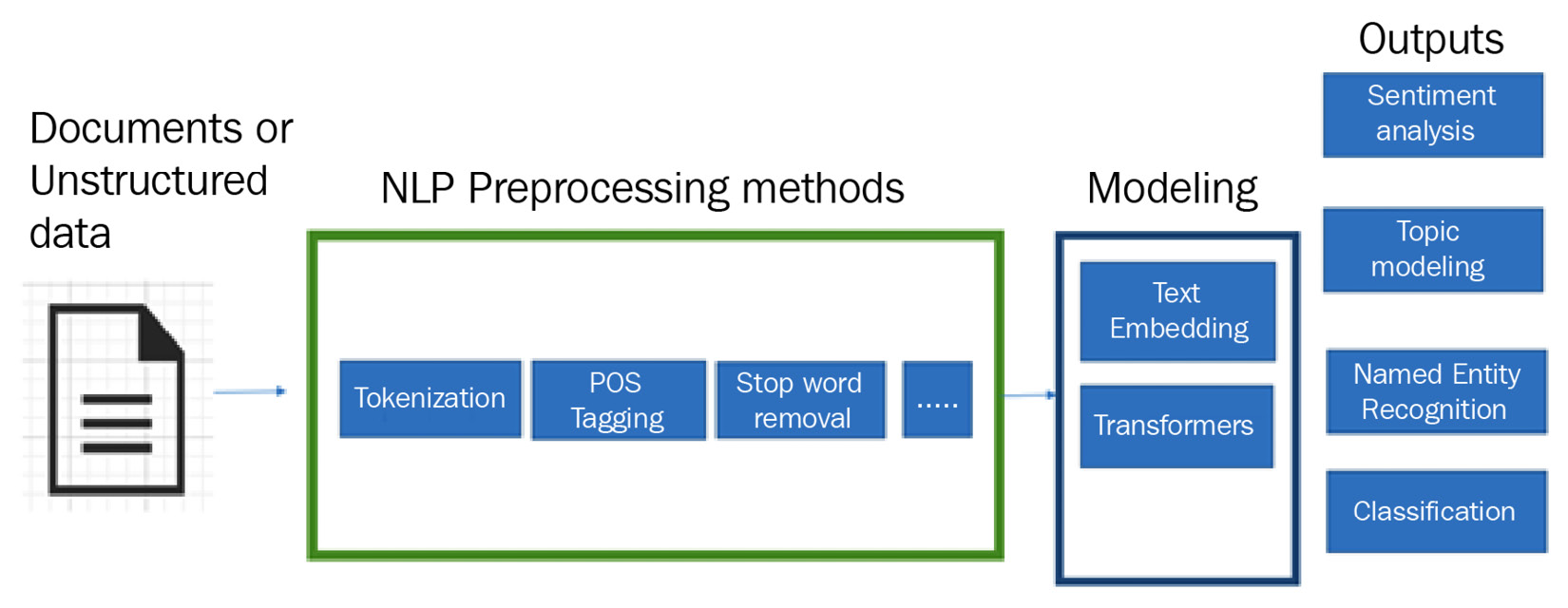
Figure 3.1 – NLP modeling
The challenge with applying these techniques is that the majority of the time is spent in data preprocessing. This applies whether you are doing ML, for example, sentiment analysis, or deep learning to apply key NLP techniques to find insights. If you are doing ML, some of the key preprocessing techniques you would use include the following:
- Tokenization: This simply means you are dividing unstructured text into words or sentences. For example, for the sentence: "This book is focusing on NLP", the tokenized word output will be "This", "book", "is", "focusing", "on", and "NLP". Similarly, if it is a complex text, you can tokenize it by sentences rather than words.
- Stop word removal: Stop words are words that do not have primary meaning in a sentence, for example, "and" "a", "is", "they", and so on, but they have a meaningful impact when we use them to communicate. An example of the stop words in the following text: "This book is focusing on NLP", would be "is" and "on", and these would be removed as part of preprocessing. A use case where you would not remove a stop word would be in certain sectors, such as healthcare, where removing stop words would be a blunder as it will completely change the meaning of the sentence.
- Stemming: Stemming means removing the last few characters of a given word to obtain a shorter form, even if that form doesn't have any meaning. For instance, the words "focusing", "focuses", and "focus" convey the same meaning, and can be clubbed under one stem for computer analysis. So instead of having them as different words, we can put them together under the same term: "focus."
- Lemmatization: This, on the other hand, means converting the given word into its base form according to the dictionary definition of the word. For example, focusing → focus. This takes more time than stemming and is a compute-intensive process.
- Part-of-speech (PoS) tagging: After tokenizing it, this method tags each word as a part of speech. Let's stick with the "This book is focusing on NLP" example. "Book" is a noun and "focusing" is a verb. PoS tags are useful for building parse trees. Parse trees are used in building named entity recognizers and extracting relations between words. PoS tagging is used for building lemmatizers. Lemmatizers will reduce a word to its root form. Moreover, there are various techniques to do PoS tagging, such as lexical-based methods, rule-based methods, and more.
Even after these preprocessing steps, you would still need to apply advanced NLP techniques if you are doing deep learning on top of the preprocessed steps. Some popular techniques are the following:
- Word embedding: These are vector representations of strings with similar semantic meanings. Word embeddings are used as a starting technique for most deep learning NLP tasks and are a popular way of transfer learning in NLP. Some of the common word embeddings are Word2vec, Doc2Vec for documents, GloVe, Continuous Bag of Words (CBOW), and Skip-gram.
- Transformers: In 2017, there was a paradigm shift from the standard way NLP applications were built upon with transformers, for example, using RNNs, LSTMs, or GRUs initialized with word embedding. Transformers have led to the development of pretrained systems such as Bidirectional Encoder Representations from Transformers (BERT) and Generative Pretrained Transformer (GPT). BERT and GPT have been trained with huge general language datasets, such as Wikipedia Corpus and Common Crawl, and can be fine-tuned to specific language tasks.
Some of the challenges with setting up these NLP models include the following:
- Compute-intensive process and requires GPUs and CPUs
- Requires large, labeled datasets for training
- Set up infrastructure for managing the compute and scaling the models in production
- Time-intensive and ML skills are needed to perform modeling
To overcome these challenges, we have Amazon SageMaker, which helps with removing all the infrastructure-heavy lifting of building, training, tuning, and deploying NLP models from idea to execution quickly.
Amazon SageMaker
You can learn more about how to get started with Amazon SageMaker NLP techniques in the book Learn Amazon SageMaker by Julien Simon.
Moreover, talking specifically about implementing transformers in your NLP models, Amazon SageMaker also supports transformer implementation in PyTorch, TensorFlow, and HuggingFace.
The Hugging Face transformers package is an immensely popular Python library providing pretrained models that are useful for a variety of NLP tasks. Refer to this blog to learn more: https://aws.amazon.com/blogs/machine-learning/aws-and-hugging-face-collaborate-to-simplify-and-accelerate-adoption-of-natural-language-processing-models/.
So, we have covered some of the key challenges with preprocessing NLP techniques and modeling. With AWS AI services such as Amazon Comprehend, you don't need to worry about spinning up servers or setting up complex infrastructure for NLP training. You also don't need to worry about all the preprocessing techniques we've covered, for example, tokenization, PoS tagging, and so on.
You also don't need to think about implementing transformers to set up deep learning models to accomplish some of the key NLP tasks, such as text classification, topic modeling, NER, key phrase detection, and a lot more.
Amazon Comprehend and Comprehend Medical give you APIs to accomplish some key NLP tasks (such as sentiment analysis, text classification, or topic modeling) on a variety of unstructured texts (such as emails, chats, social media feeds, or healthcare notes).
In the next section, we will cover how Comprehend and Comprehend Medical can detect insights in text with no preprocessing.
Exploring the benefits of Amazon Comprehend and Comprehend Medical
In this section, we will cover some of the key benefits of Amazon Comprehend and Comprehend Medical by discussing the following examples:
- Integrates NLP APIs that use a pretrained deep learning model under the hood. These APIs can be added to your apps to make them intelligent as you do not need textual analysis expertise to use them.
- Provides scalable NLP processing, as its serverless APIs enable you to analyze several documents or unstructured textual data for NLP without worrying about spinning up servers and managing them.
- Both of these services integrate with other AWS services: AWS IAM, for identity and access management; Amazon S3, for storage; AWS Key Management Service (KMS), to manage security keys during encryption; AWS Lambda, to create serverless architecture. You can perform real-time analysis both from streaming data coming from Amazon Kinesis or a batch of data in Amazon S3, then use the NLP APIs to gain insights on this data and display it in a dashboard using Amazon Quicksight, which is a visualization tool similar to Tableau.
- These services provide encryption of output results and volume data in Amazon S3. With Amazon Comprehend, you can use KMS keys to encrypt the output results of the jobs, as well as the data attached on the storage volume of the compute instance that processes the analysis job under the hood.
- It's cost-effective, as you only have to pay for the text that you will analyze.
Detecting insights in text using Comprehend and Comprehend Medical without preprocessing
Amazon Comprehend and Amazon Comprehend Medical are AWS AI services, similar to Amazon Textract (which we covered in Chapter 2, Introducing Amazon Textract), where you do not need to set up complex models. You call the Amazon Comprehend and Amazon Comprehend Medical APIs and send a text request, and you will get a response back with the detected confidence score. The difference between Amazon Comprehend and Amazon Comprehend Medical is that Comprehend Medical is specific to healthcare NLP use cases. Comprehend Medical uses ML to extract health-related, meaningful insights from unstructured medical text, while Amazon Comprehend uses NLP to extract meaningful information about the content of unstructured text by recognizing the entities, key phrases, language, sentiments, and other common elements in the text.
Some of the key use cases of Amazon Comprehend are as follows:
- Using topic modeling to search documents based on topics: With Amazon Comprehend topic modeling, you have the ability to configure the number of topics you are looking for in your documents or text files. With topic modeling, you can search the documents attached with each topic.
- Using sentiment analysis to analyze the sentiment of what customers think of your product: With Amazon Comprehend sentiment analysis APIs, you can find out how customers feel (such as positive, negative, neutral, or mixed) about their products. For example, suppose you find a restaurant on Yelp. It's a pizza place. You go there, try the pizza, and do not like it, so you post a comment: "The pizza here was not great." Business owners using Comprehend sentiment analysis can quickly analyze the sentiment of this text and act in real time on improving user satisfaction before their business goes down.
- Quick discovery of customer feelings based on topics and entities: You can combine multiple features of Amazon Comprehend, such as topic modeling, with entity recognition and sentiment analysis to discover the topics that your end users are talking about in various forums.
- Bring your own data to perform custom classification and custom entity recognition: Amazon Comprehend provides you with the capability to quickly get started with custom entities. For example, if you are a manufacturing firm and you are looking for certain product codes in the documents, such as PR123, it should be detected as the product code using ML.
You can bring a sample of your data and use Amazon Comprehend Custom entity recognition to get started without needing to worry about writing a complex model. You also do not need to worry about labeling large datasets to get started, as Amazon Comprehend Custom uses transfer learning under the hood. You can get started with a small set of labeled data to create custom entities specific to your use case. Similarly, you can bring your own data and perform custom classification to perform multi-class and multi-label classification to identify classes.
In the case of healthcare records, you can use Amazon Comprehend Medical. You can use Comprehend Medical for the following healthcare applications:
- Using Comprehend Medical APIs to analyze case documents for patient case management and outcomes.
- Using Comprehend Medical APIs to detect useful information in clinical texts to optimize the matching process and drug safety for life sciences and research organizations.
- Using Comprehend Medical to extract billing codes which can decrease the time to revenue for insurance payers involved in medical billing.
- Comprehend Medical also supports ontology linking for ICD-10-CM (International Classification of Diseases – 10th Version – Clinical Modification)and RxNorm. Ontology linking means detecting entities in clinical text and linking those entities to concepts in standardized medical ontologies, such as the RxNorm and ICD-10-CM knowledge bases.
- Detecting PHI data, such as age, date from clinical documents, and set controls, to implement PHI compliance in the medical organization.
We will cover Amazon Comprehend Medical use cases in detail in Chapter 12, AI and NLP in Healthcare.
Using these services to gain insights from OCR documents from Amazon Textract
If you have documents in the form of scanned images or PDFs, you can use Amazon Textract to extract data quickly from these documents and then use Amazon Comprehend to gain meaningful insights from the extracted text, such as entities, key phrases, and sentiment. You can further classify these documents using Amazon Comprehend text classification, and also perform topic modeling to identify key topics within the documents. We will cover how you can use Amazon Textract with Amazon Comprehend together in an architecture in Chapter 4, Automating Document Processing Workflows for Financial Institutions, and in Chapter 5, Creating NLP Search in the section Creating NLP-powered smart search indexes. Moreover, for the healthcare industry, if you have lots of scanned documents such as medical intake forms, patient notes, and so on, you can use Amazon Textract to extract data from these documents and then use Amazon Comprehend Medical to extract key insights from this unstructured text data.
In this section, we first covered the challenges associated with setting up NLP modeling. Then we discussed how Amazon Comprehend and Comprehend Medical can address the pain points associated with setting up NLP models, such as scalability, preprocessing steps, and infrastructure setup. Lastly, we covered how you can automate your documents and enrich them with NLP by combining Amazon Textract and Amazon Comprehend. We have covered how Comprehend and Comprehend Medical can provide rich APIs for building intelligent NLP applications, which are also scalable to process large numbers of documents or unstructured data. In the next section, we will talk about some of the product features of these services using an AWS Console demo.
Exploring Amazon Comprehend and Amazon Comprehend Medical product features
In this section, we will talk about Amazon Comprehend and Amazon Comprehend Medical product features using an AWS Console demo. We will start with Amazon Comprehend, and then move to Amazon Comprehend Medical.
Discovering Amazon Comprehend
Amazon Comprehend enables you to examine your unstructured data, for example, social media feeds, posts, emails, web pages, data extracted from Amazon Textract, phone transcripts, call center records, or really any kind of unstructured textual data. It can help you gain various insights about its content by using a number of pretrained models. Figure 3.2 is a diagram of how Amazon Comprehend actually works:

Figure 3.2 – Amazon Comprehend features
With Amazon Comprehend, you can perform the following on your input unstructured textual data by using the following text analysis APIs:
- Detect Entities
- Detect Key Phrases
- Detect the Dominant Language
- Detect Personally Identifiable Information (PII)
- Determine Sentiment
- Analyze Syntax
- Topic Modeling
These text analysis APIs can be used both in real-time and in a batch manner, while topic modeling is a batch job or asynchronous process and cannot be used for real-time use cases.
There are two modes in which you can use these APIs:
- Real-time in any application: You can use these APIs for real-time use cases by sending one document at a time, or in batch real-time operations by sending 15 documents in a batch and getting a response immediately.
- Batch or asynchronous manner: Where you bring your large batch of data into Amazon S3, point to a dataset, and run any of the preceding analyses in the form of a batch job. The results of the batch job are saved to an S3 bucket.
Note
For synchronous APIs, your text has to be UTF-8 encoded and 5,000 bytes.
Let's take a quick look at some Amazon Comprehend features on the AWS Console. Please refer to the Technical requirements section if you have not already set up your AWS account.
Since we all forget to set up autopay messages to pay our credit card bills, in this demo we will show you a quick analysis of a sample autopay message to extract some key insights using Amazon Comprehend:
- Go to Amazon Comprehend. Click on Launch Amazon Comprehend:

Figure 3.3 – Amazon Comprehend Console
- We will use the following sample autopay text to analyze all of the features of Amazon Comprehend available through the AWS Console:
Hi Alex. Your NoNameCompany Financial Services, LLC credit card account 1111-0000-1111-0010 has a minimum payment of $25.00 that is due by Sunday, June 19th. Based on your autopay settings, we are going to withdraw your payment on the due date from your bank account XXXXXX1121 with the routing number XXXXX0000.
Your latest statement was mailed to 100 XYZ Street, Anytown, WA 98121.
After your payment is received, you will receive a confirmation text message at 555-0100-0000.
If you have questions about your bill, NoNameCompany Customer Service is available by phone at 206-555-0199 or email at [email protected].
- Copy the preceding text and insert it into Real-time analysis → Input text, as shown in Figure 3.4, and click on Built-in, and then Analyze:

Figure 3.4 – Real-time analysis Input text in AWS Console
- Scroll down to see the insights.
Now, we will walk through each Insights API by changing each tab.
Detecting entities
You can see from the screenshot in Figure 3.5 that Amazon Comprehend was able to detect the highlighted entities from the text you entered:

Figure 3.5 – Detect entities insights
- Scroll down to the results to understand more about these entities and what is identified as an entity by Amazon Comprehend's built-in APIs without any customization.
In the following screenshot in Figure 3.6, you can see that Alex has been identified as a Person, and NoNameCompany, the sender of the autopay message, has been identified as an Organization. The date by which Alex's amount is due (June 19th) has been identified as a Date entity, along with their specific confidence scores. The confidence score means how likely a match is to be found by the ML model, which is in a range from 0 to 100. The higher the score, the greater the confidence in the answer. A score of 100 is likely an exact match, while a score of 0 means that no matching answer was found:

Figure 3.6 – Detect entities results
Note
Out of the box, Amazon Comprehend's built-in APIs can detect Person, Location, Quantity, Organization, Date, Commercial Item, Quantity, and Title from any text.
- Let's quickly scroll down to Application integration to see what type of request it expects, and what type of response it gives based on this request for the API:

Figure 3.7 – Comprehend Detect Entities request and response
In the last section of this chapter, we will see how to call these APIs using python boto 3 SDKs and integrate them into your applications.
Detecting key phrases
Change the tab to key phrases to understand what the key phrases are and what Amazon Comprehend has predicted:

Figure 3.8 – Detect key phrases
In English, a key phrase consists of a noun phrase (noun plus modifier) that describes a particular thing. For example, in the text in Figure 3.8, "Hi Alex", "Your NoNameCompany Financial Services", and "minimum payment" are some of the key phrases identified by the Amazon Comprehend API. Without reading the text and just looking at these keywords a person can know it is about a finance company and something to do with a payment, which is really useful when you have large amounts of unstructured text.
Language detection
Change the tab to see the dominant language identified by Amazon Comprehend, as shown in Figure 3.9:

Figure 3.9 – Detect language console demo
Similar to other Comprehend APIs, Amazon Comprehend detects the language of the given text and provides a confidence score along with it. You can use this feature for a book written in multiple different languages, such as both French and Hindi. Using language detection APIs, you can detect the language and classify the percentage of each language the book consists of, and then you can use Amazon Translate, which is an AWS service that translates the text from one language to another. We will see this example in future chapters in order to translate it.
PII detection
Change the tab to PII to see what you will get using the Amazon Comprehend out-of-the-box PII detection API as follows:

Figure 3.10 – PII detection demo
As you can see in Figure 3.10, Amazon Comprehend provides you with Offsets and Labels with its real-time or sync PII APIs. If you want to redact the PII data from your text, you can use an asynchronous job. Amazon Comprehend can detect these PII entities: age, address, AWS access key, AWS secret key, bank-related details (such as bank account and bank routing number), credit card details (such as credit card number and expiry date), identification details (such as driving license ID and passport number), network-related details (such as emails, IP address, and MAC address), URLs; passwords; and usernames.
With this understanding of types of PII entities detected by Amazon Comprehend, let's scroll down to see the entities or results of Offsets detected by PII for the text you entered:

Figure 3.11 – Detect PII results
You also get a confidence score along with the entity and the type of PII entity.
In case you do not want to identify the specific entities and just want to know what type of PII your documents have, you can use the Labels PII feature.
Select the Labels button to see this feature in action:

Figure 3.12 – Detect PII Labels result
From the results shown in Figure 3.12, you can clearly see that Date time, Email, Name, Address, and Phone are some of the pieces of PII related to a person in the text you entered.
Detecting sentiment
Change to the Sentiment tab to understand the sentiment of the text you have entered:

Figure 3.13 – Detect sentiment results
Since the text was related to an autopay message, a neutral sentiment was detected by Amazon Comprehend's Detect Sentiment real-time API. The Amazon Comprehend sentiment analysis feature helps determine whether the sentiment is positive, negative, neutral, or mixed. You can use this feature for various use cases, such as determining the sentiments of an online book review, Twitter sentiment analysis, or any social media sentiment handles, such as Reddit or Yelp reviews sentiment analysis.
Detecting syntax
Click on the last tab, Syntax, to see what type of responses you can get with Amazon Comprehend's Detect Syntax feature:
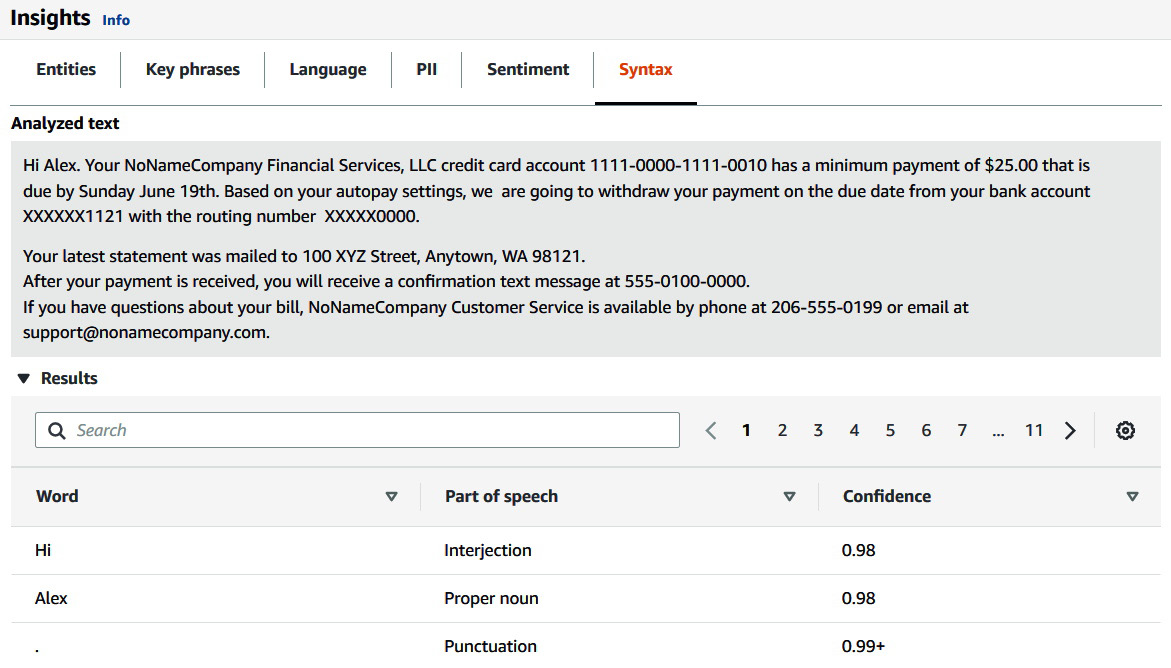
Figure 3.14 – Detect syntax or part of speech results
Amazon Comprehend is able to identify nouns, verbs, and adjectives, and can identify 17 types of parts of speech overall. This feature can be really useful for data preprocessing for NLP models that require PoS tagging.
Note
We covered all the Amazon Comprehend text analysis real-time APIs in detail. You can perform batch real-time operations with all of these APIs we covered and send 25-5,000 bytes (https://docs.aws.amazon.com/comprehend/latest/dg/guidelines-and-limits.html) UTF-8 text documents at once to get real-time results. Comprehend custom has now the ability to bring pdf documents directly for analysis and custom training.
Amazon Comprehend Custom feature
With Amazon Comprehend Custom you can bring your own datasets, quickly create custom entities, and perform custom classification. This feature is a batch or asynchronous feature that involves two steps:
- Train a classifier or entity recognizer by providing a small, labeled dataset. This classifier or entity recognizer uses automated ML (AutoML) and transfer learning to pick and train a model based on your training dataset provided. It also provides an F1 score and precision and recall metrics with this trained model.
- Run batch or real-time analysis on this trained model after you have trained a custom classifier or custom entity recognizer model. You again have two choices to create a batch job using this trained model for batches of data in the form of an "Analysis job" in the Amazon Comprehend console. You can also create a real-time endpoint that can be used for classifying use cases such as live Twitter feeds, news feed or customer service requests, and so on, using this model in near-real-time.

Figure 3.15 – Comprehend custom classification workflow
We will cover Comprehend custom entity features in Chapter 14, Auditing Named Entity Recognition Workflows, and Comprehend custom classification features in Chapter 15, Classifying Documents and Setting up Human in the Loop for Active Learning.
We will cover topic modeling product features in detail in Chapter 6, Using NLP to Improve Customer Service Efficiency.
Amazon Comprehend Events
Amazon Comprehend Events has a specific use case for financial organizations, where you can use this API to see the relationships between various entities extracted through Amazon Comprehend in the case of any important financial events such as press releases, mergers, and acquisitions. You can use this Events batch API to detect events over large documents to answer who, what, when, and where the event happened. To learn more about Comprehend Events, refer to this blog: https://aws.amazon.com/blogs/machine-learning/announcing-the-launch-of-amazon-comprehend-events/.
Deriving diagnoses from a doctor-patient transcript with Comprehend Medical
Amazon Comprehend Medical provides two types of analysis:
- Text analysis APIs: Similar to Amazon Comprehend text analysis APIs, Comprehend Medical has APIs to detect medical entities and detect PHI.
- Oncology detection APIs: These APIs help link the entities with either RxNorm or ICD-10-CM linking. According to the National Institutes of Health (NIH) (https://www.nlm.nih.gov/research/umls/rxnorm/index.html), RxNorm provides normalized names for clinical drugs and links its names to many of the drug vocabularies commonly used in pharmacy management and drug interaction software. By providing links between these vocabularies, RxNorm can mediate messages between systems not using the same software and vocabulary. ICD-10-CM (The ICD-10 Clinical Modification) is a modification of the ICD-10, authorized by the World Health Organization, and used as a source for diagnosis codes in the United States of America. To learn more, refer to its Wikipedia entry: https://en.wikipedia.org/wiki/ICD-10-CM.
Now, we will quickly cover Amazon Comprehend Medical features through the AWS Console again:
- Open the AWS Console: https://console.aws.amazon.com/comprehend/v2/home?region=us-east-1#try-comprehend-medical.
- Click on the Real-time analysis feature in Amazon Comprehend Medical, and enter the following sample text:
Pt is 35 yo woman, IT professional with past medical history that includes
- status post cardiac catheterization in may 2019.
She haspalpitations and chest pressure today.
HPI : Sleeping trouble for present dosage of Catapres. Severe rash on thighs, slightly itchy
Meds : Xanax100 mgs po at lunch daily,
Catapres 0.2 mgs -- 1 and 1 / 2 tabs po qhs
Lungs : clear
Heart : Regular rhythm
Next follow up as scheduled on 06/19/2021
- Copy this text and paste it into Input text, as shown in Figure 3.16, and click on Analyze:
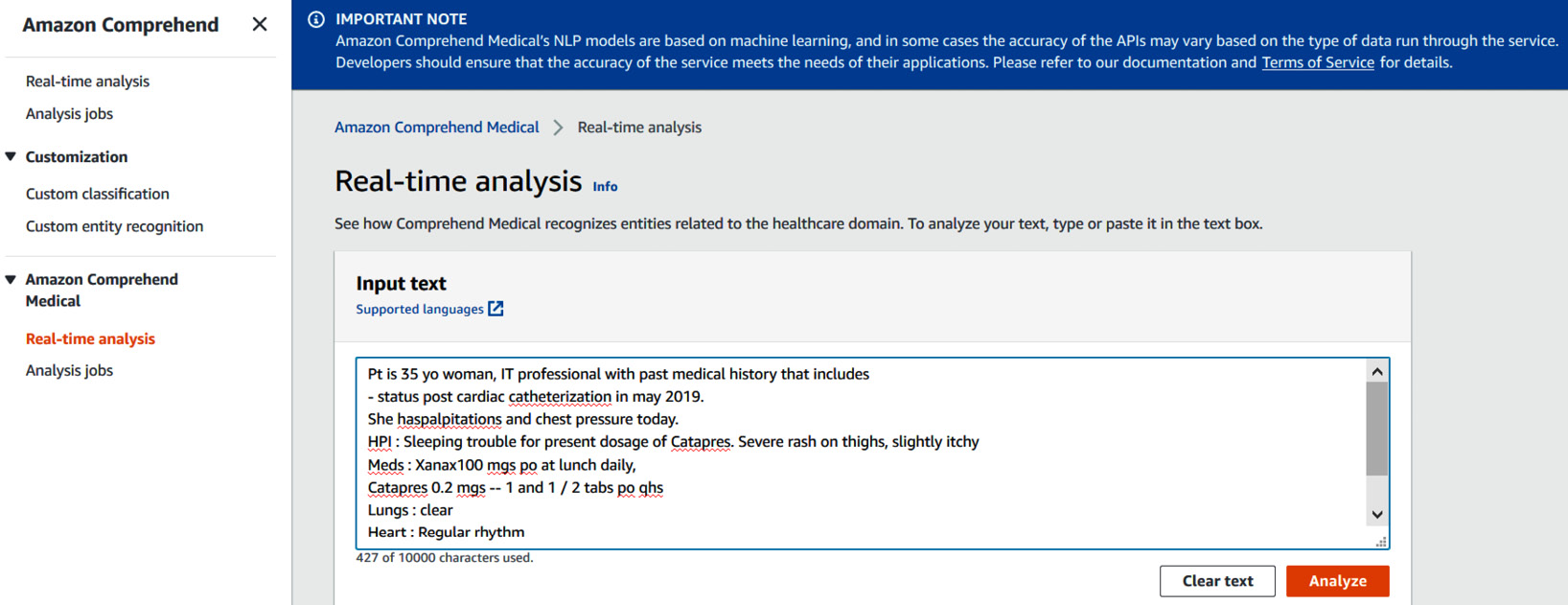
Figure 3.16 – Input text for real-time Amazon Comprehend Medical analysis
Note
With Comprehend Medical real-time APIs, you can analyze up to 200,000 characters.
- Scroll down to see the result of Comprehend Medical entities real-time APIs:

Figure 3.17 – Comprehend Medical detect entities
You can see that Comprehend Medical also provides relationships within these entities, such as Catapres dosage, and the frequency at which the drug should be administered. Amazon Comprehend Medical detects Entity, Type, and Category, such as whether the entity is PHI or treatment or time expression and traits, along with a confidence score.
- Scroll down further to see detected entities in Results. This detects the entity with its Type and Category; for example, 35 is an entity that has been detected, with an entity Type of Age, and a Category of PHI.

Figure 3.18 – Comprehend Medical detect entities results
RxNorm concepts
Use this feature to identify medication as entities:
- Switch tabs to RxNorm. You'll see a screen like the following screenshot:
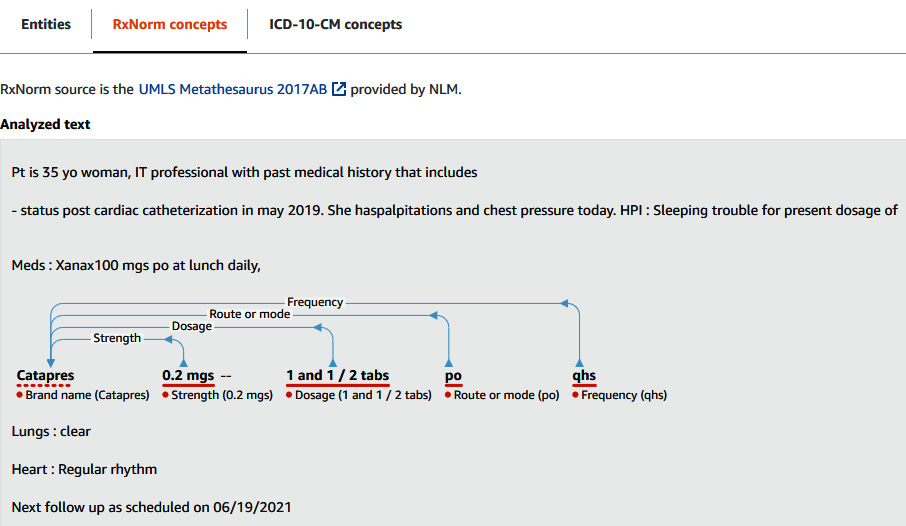
Figure 3.19 – Comprehend Medical InferRxNorm results
If you scroll down to Results, Comprehend Medical shows the RXCUIs for each medication, along with a confidence score. An RXCUI is a machine-readable code that refers to a unique name for a particular drug, and drugs having the same RXCUI are considered to be the same drug. This Comprehend Medical feature provides RxNorm information such as strength, frequency, dose, dose form, and route of administration. You can use this RxNorm feature for scenarios such as the following:
- Patient screening for medications.
- Preventing probable negative reactions, which can be caused by new prescription drugs interacting with drugs the patient is already taking.
- Screening based on drug history, using the RXCUI for inclusion in clinical trials.
- Checking for appropriate frequency and dosage of a drug and drug screening.
ICD-10-CM concepts
Let's change the tab to ICD-10-CM concepts and you will get the following analysis:
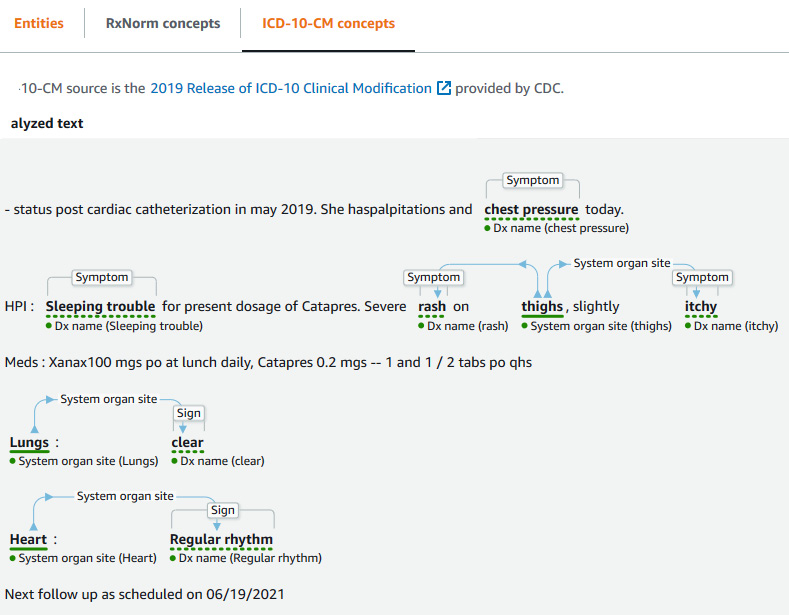
Figure 3.20 – Comprehend Medical InferICD-10-CM results
The InferICD10CM API detects possible medical conditions as entities and links them to codes from the ICD-10-CM, along with a confidence score. In healthcare, these codes are standard medical transaction codes, set for diagnostic purposes to comply with the Health Insurance Portability and Accountability Act (HIPAA), and used for classifying and reporting diseases. You can use these ICD-10-CM codes for downstream analysis as the signs, symptoms, traits, and attributes.
InferICD10CM is well-suited to scenarios such as professional medical coding assistance for patient records, clinical trials and studies, integration with an existing medical software system, early detection and diagnosis, and population health management.
In the next section, we will see these APIs in action by performing a walkthrough of a Jupyter notebook.
Using Amazon Comprehend with your applications
In this section, you will see a detailed walkthrough of broad categories of APIs available for Amazon Comprehend and Comprehend Medical through a Jupyter notebook example, which you can run in your AWS account. To set up the notebook, refer to the Technical requirements section of this chapter.
We will be showing you a subset of key APIs in Comprehend along with their functions, and then will talk about how you can build applications integrating with AWS Lambda, API Gateway, and Comprehend.
Note
We will cover Amazon Comprehend Medical APIs in Chapter 12, AI and NLP in Healthcare.
Let's start with the Amazon Comprehend APIs first. Amazon Comprehend provides three types of API.
- Real-time APIs: For all the text analysis features we covered and Comprehend Custom model endpoints.
- Batch real-time APIs: For all the text analysis features.
- Batch or analysis job APIs: For all text analysis features, topic modeling features, and Comprehend Custom model training.
In the notebook https://github.com/PacktPublishing/Natural-Language-Processing-with-AWS-AI-Services/blob/main/Chapter%2003/Chapter%203%20Introduction%20to%20Amazon%20Comprehend.ipynb, we will cover real-time APIs and batch real-time APIs.
Note
You can implement the same features in other supported APIs such as Java, Ruby, .NET, AWS CLI, Go, C++, JavaScript, and PHP. For more information on Comprehend APIs, refer to the Amazon documentation: https://docs.aws.amazon.com/comprehend/latest/dg/API_Reference.html.
- Let's start with setting up the Python boto3 APIs for Amazon Comprehend:
import boto3
comprehend = boto3.client('comprehend')
- Let's see how we can perform entity extraction using sync or real-time APIs of detect_entities. I am sure you have been reading a lot of Packt books; let's see the following sample text about Packt Publications and what entities we can find from this:
SampleText="Packt is a publishing company founded in 2003 headquartered in Birmingham, UK, with offices in Mumbai, India. Packt primarily publishes print and electronic books and videos relating to information technology, including programming, web design, data analysis and hardware."
- We will call the detect_entities API (comprehend.detect_entities) to extract entities from the sample text:
response = comprehend.detect_entities(
Text=SampleText,
LanguageCode='en')
- The following is the response for extracted entities from the blurb about Packt Publications:
import json
print (json.dumps(response, indent=4, sort_keys=True))
This gives us the following output:

Figure 3.21 – JSON results screenshot
Comprehend was able to successfully detect entities along with their type, and give a response that Packt Publications is an organization located in Birmingham, UK, and Mumbai, India.
- Now we know what Packt Publications is, let's identify some key phrases about this organization using the detect_key_phrases API, but when the text is in French.
Note
Amazon Comprehend supports analysis in multiple languages using these APIs. The supported languages are French, Japanese, Korean, Hindi, Arabic, and Chinese.
Here is a sample text about Packt Publications (https://en.wikipedia.org/wiki/Packt), translated into French using Amazon Translate:
SampleText="Packt est une société d'édition fondée en 2003 dont le siège est à Birmingham, au Royaume-Uni, avec des bureaux à Mumbai, en Inde. Packt publie principalement des livres et des vidéos imprimés et électroniques relatifs aux technologies de l'information, y compris la programmation, la conception Web, l'analyse de données et le matériel"
- We are going to use the detect_key_phrases API with fr as a parameter to LanguageCode to detect key phrases from the preceding French text:
response = comprehend.detect_key_phrases(
Text= SampleText,
LanguageCode='fr'
)
- Let's see the response from Amazon Comprehend:
print (json.dumps(response, indent=4, sort_keys=True))

Figure 3.22 – Comprehend Detect Key Phrase response
Amazon Comprehend is able to identify key phrases along with the location of the text.
Now, what if you wanted to buy a book from Packt Publications, you might want to read the reviews and determine whether they are positive or not.
Using the batch_detect_sentiment API, we will show you how you can analyze multiple reviews at once. For this demo, we will pick some sample reviews from the book 40 Algorithms Every Programmer Should Know (https://www.packtpub.com/product/40-algorithms-every-programmer-should-know/9781789801217):
- We are going to analyze some of the reviews of this book using batch_detect_sentiment:
response = comprehend.batch_detect_sentiment(
TextList=[
'Well this is an area of my interest and this book is packed with essential knowledge','kinda all in one With good examples and rather easy to follow', 'There are good examples and samples in the book.', '40 Algorithms every Programmer should know is a good start to a vast topic about algorithms'
],
LanguageCode='en'
)
- Now, let's see the response for this by running the following code:
print (json.dumps(response, indent=4, sort_keys=True))
This produces the following output:

Figure 3.23 – Comprehend Sentiment Analysis response
Out of these four reviews analyzed, we can definitely see that, overall, it's a positive review for this book. Now, while reading the reviews, there were some reviews in different languages which, being an English reader, I did not understand. Unfortunately, I don't know which languages these reviews use, and therefore what to choose for translation.
- Let's use the batch_detect_dominant_language API of Comprehend to identify what languages these reviews are in before we translate them:
response = comprehend.batch_detect_dominant_language(
TextList=[
'It include recenet algorithm trend. it is very helpful.','Je ne lai pas encore lu entièrement mais le livre semble expliquer de façon suffisamment claire lensemble de ces algorithmes.'
]
)
- Now, let's see the response from Comprehend to figure out the review languages:
print (json.dumps(response, indent=4, sort_keys=True))
This gives us the following output:

Figure 3.24 – Comprehend Detect Language response
It's interesting to find out that out of the two reviews sent to this batch detect the dominant language, one is in English, and one is in French.
We have now covered some of the key APIs, such as detect_entities, detect_key_phrases, batch_detect_sentiment, and batch_detect_dominant_languages.
Now, we will see how we can use these APIs in building an application.
Architecting applications with Amazon API Gateway, AWS Lambda, and Comprehend
In a previous section, we covered Amazon Comprehend's text analysis API. You can easily call these APIs in a serverless manner using a Lambda function. Amazon Lambda is a serverless event-based trigger that can be integrated with Amazon API Gateway and triggered for GET and POST requests. Amazon API gateway is a serverless REST-based service, which allows you to build GET/POST APIs to easily integrate with any application, be it mobile or web app.
You can create an API to be embedded in your application where you send a text to be analyzed using API Gateway; then the API Gateway calls the Amazon Lambda function, based on the type of request it receives. Amazon Lambda can further call Amazon Comprehend APIs (real-time or batch detect real-time APIs). It then passes the Comprehend response to API Gateway, as shown in the architecture diagram in Figure 3.25:

Figure 3.25 – Building real-time application with Amazon Comprehend
Summary
In this chapter, we covered why you would need to use Amazon Comprehend and Amazon Comprehend Medical. We also discussed the challenges associated with setting NLP pipelines.
Then, we introduced these services, and covered some key benefits they provide, for example, not needing ML skills, or easily using the APIs to build scalable NLP solutions. After that, we showed some key product features of Amazon Comprehend and Amazon Comprehend Medical through a Console demo. Some of Amazon Comprehend's features are identifying entities, key phrases, and sentiment, as well as detecting dominant language, topic modeling, and so on. For Amazon Comprehend Medical, we covered how you can use both text analysis APIs and oncology APIs to enrich and extract key information from medical notes. Then we gave you a quick walkthrough of these APIs using a Jupyter notebook and covered sync and batch sync APIs. We gained a basic theoretical understanding of creating a serverless application using these APIs.
In the next chapter, we will talk about how you can integrate Amazon Textract with Amazon Comprehend for automating financial documents.