
Free and open source software for web-based collaboration
Abstract:
The ability to collaborate and share knowledge is critical within the life sciences industry where business pressures demand reduced development times and virtualisation of project teams. Web-based collaboration tools such as wikis, blogs, social bookmarking, microblogging, etc. can provide solutions to these challenges. In this chapter we shall examine the use of FLOSS for web-based collaboration against the backdrop of a software assessment framework. This framework describes the different phases associated with an evolutionary model for the introduction of new IT capabilities to an enterprise. We illustrate each phase of this framework by presenting a use-case and the key learnings from the work.
13.1 Introduction
Pfizer spends in excess of $7bn annually on research and development across multiple therapeutic areas in research centres across the globe. Within each therapeutic area are a number of separate projects, each working to identify new medicines to treat a specific condition or disease. The people working on each project come from different disciplines (e.g. chemistry, biology, clinical, safety), may be members of more than one project and may move between projects depending on their skills and the requirements of the project. This results in a complex, ever-changing matrix of individuals, who may not even be co-located at one site but who all need to share information to drive decisions. In response to these challenges Pfizer needed to introduce new tools to mitigate the inefficiencies associated with a geographically distributed team, specifically support for virtual working and collaboration.
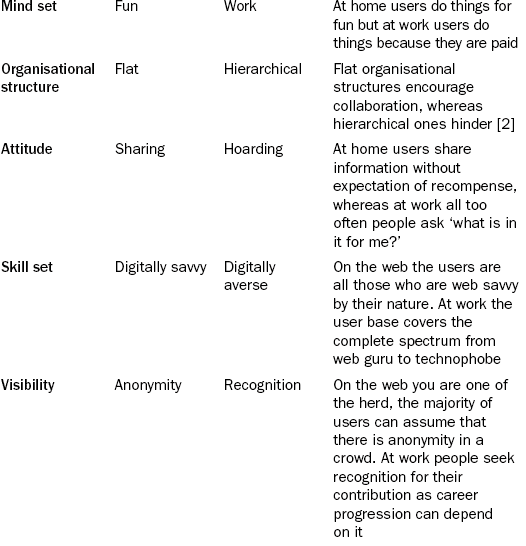
During the first half of the last decade, 2000–2005, a new class of tools had emerged on the web that were enabling users to create, share and comment on web content without the need for technical skills such as HTML. These tools became referred to as Web 2.0 and evolved to power the social computing revolution we see now. As Web 2.0 culture developed, it rapidly became apparent that solutions such as wikis, blogs, social networking, social bookmarking, RSS, etc., which were supporting collaboration on the web, could equally be employed within business to solve the type of challenges described above. Andrew McAfee coined the term Enterprise 2.0 to describe this utilisation of Web 2.0 tools within the enterprise [1]. Web-based examples such as Wikipedia, Facebook, Twitter, Delicious, Blogger, Google Reader, etc. readily demonstrated that they could provide a solution to the collaboration and virtual working challenges businesses were facing. However, it also was very apparent that the user drivers and working practices associated with the success of these systems were very different to those seen within most places of work. Some examples of these differences are outlined in Table 13.1. As a consequence it was clear that if they were going to be successfully utilised to solve the virtual working and collaboration challenges Pfizer was facing, then it was necessary to experiment in order to understand how these differences affected deployment and integrated into colleagues' workflows.


Many of the best tools available around 2006/7, and still even now, had a narrow focus on performing a single task and do not suffer from feature bloat often seen in more traditional enterprise software packages. As a consequence of this these tools provided a clean and simple user interface and the competition for users on the web placed an emphasis on quality of user experience. In our opinion these factors, user interface and user experience, were critical to the success of these tools and in some respects actually more important than their feature lists.
Finally at this time, the commercial market for these tools was quite limited and very immature. In contrast though there were numerous free and open source software (FLOSS) alternatives. Often the FLOSS alternatives were in fact powering some of the most successful social software on the web, or were clones of existing popular offerings. The fact that these tools could be downloaded and installed freely meant that they readily enabled the experimental approach we wanted to follow. The natural way to introduce these capabilities was through an evolutionary path akin to agile/scrum development methodology rather than a more traditional 'big bang' launch. This meant that the introduction of these capabilities would start with a phase of experimentation and progress to proof of concept followed by production deployment and finally transfer of support to a central shared service group. As a result we developed the framework illustrated in Figure 13.1 to introduce, evaluate, develop and deploy these new capabilities.
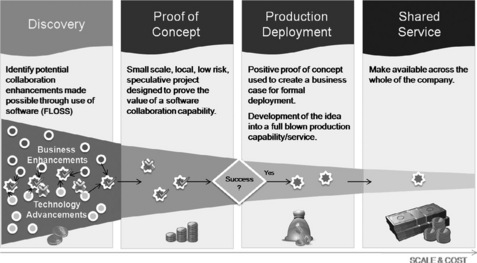
Figure 13.1 The FLOSS assessment framework. Describing the different phases associated with an evolutionary model for the introduction of new IT capabilities to an enterprise
FLOSS can be used at any or all of the stages but it certainly provides distinct cost and availability benefits over commercial software in the initial 'discovery' and 'proof of concept' stages. In some instances FLOSS collaboration systems may be shown to be superior to commercial alternatives in terms of functionality, integration opportunities and scalability, resulting in the solution being deployed into production. In this chapter we shall examine the use of FLOSS for web-based collaboration against the backdrop of our software assessment framework (Figure 13.1). We will illustrate each of these phases in turn, by presenting a use-case and the key learnings from the work.
13.2 Application of the FLOSS assessment framework
13.2.1 Discovery phase
The objective of this first phase is to identify a tool to explore the capability of interest. In addition to simply trying out various solutions, assessing how intuitive the user interface, user experience and features are, it is important to determine compatibility with the production environment and the stability of the solution. Finally, it is also critical to determine whether the solution can be hosted internally, as collaboration inherently requires the creation and sharing of content. Ultimately, to use these tools within real workflows precludes the use of third-party hosted solutions due to the risk of exposing intellectual property.
In assessing/exploring a Web 2.0 capability it is obviously highly advantageous to use FLOSS solutions, as by their nature their use does not impose any of the usual overhead associated with vendor negotiation. In addition, the open source communities have built various solutions that help with the distribution/implementation of FLOSS solutions. In our case we were looking to assess various Web 2.0 capabilities and the availability of virtualised versions of the LAMP stack (Linux OS, Apache server, MySQL and PHP) that could be installed on a Windows desktop i.e. Web On a Stick [3], Server2GO [4] and BitNarmi [5]. The existence of these 'plug and play' self-contained hosting packages made it possible for us to stand up and perform a rapid comparison and assessment of different capabilities, often without the requirement for significant technical support.
However, as tools such as Web On a Stick are self-contained virtualisation solutions, they really only support the basic assessment of different software offerings by an individual. Thus, once a specific solution had been identified as a potential candidate the next stage was to explore the multi-user experience/features it offered. To do this we were able to build a development environment utilising scavenged older hardware on which we either installed Fedora and Xampp [6], or if using a Windows box used a VMware image of Fedora downloaded from Thought Police VMWare Images [7] and then installed Xampp. These solutions proved to be very robust and in many cases these same environments were used to support the Proof of Concept phase.
One important further consideration was compatibility with Pfizer's standard browser, at the time Internet Explorer 6, and testing of any related extensions. In addition before any candidate solution was progressed to Proof of Concept, it was tested for stability, a high-level review of the code base was performed and the activity of the open source community was assessed. Our criteria are in line with those described by Thornber (Chapter 22) and consider issues such as current development status, responsiveness of the support network and general activity on the project.
13.2.2 Research phase use-case: Status.net – microblogging
With the explosion of Twitter [8], it was logical that some involved in research and development in Pfizer would start to wonder if and how microblogging might provide a simple and convenient method to facilitate a free-flow of information, updates and news across their organisational and scientific networks. With this in mind we looked to explore the opportunities of microblogging with the following technology options considered for our first microblogging experiment.
![]() Twitter [8] was quickly discarded because any data posted on that site would be open to all users on the web and hence could not be used to share any company proprietary information.
Twitter [8] was quickly discarded because any data posted on that site would be open to all users on the web and hence could not be used to share any company proprietary information.
![]() Yammer [9], a Software-as-a-Service (SaaS) offering a Twitter-like application for which access could be contained to employees from a single company, was considered but rejected at this stage because of the time that would be needed to investigate the security and costing of this option.
Yammer [9], a Software-as-a-Service (SaaS) offering a Twitter-like application for which access could be contained to employees from a single company, was considered but rejected at this stage because of the time that would be needed to investigate the security and costing of this option.
![]() Workgroup Twitter for SharePoint 2007, a very slick proof-of-concept created by Daniel McPhearson of Zevenseas [10], was considered and although we liked the solution it was rejected for the simple reason that it was limited to providing microblogging capability to a workgroup/ team and could not scale to support organisation-wide microblogging.
Workgroup Twitter for SharePoint 2007, a very slick proof-of-concept created by Daniel McPhearson of Zevenseas [10], was considered and although we liked the solution it was rejected for the simple reason that it was limited to providing microblogging capability to a workgroup/ team and could not scale to support organisation-wide microblogging.
![]() An internally developed desktop client that allowed users to send short messages to and receive updates from a user specified SharePoint list was also available. This tool was used extensively for a number of different applications but for our initial purposes was rejected for the same reason of scope as the Zevenseas Workgroup Twitter application.
An internally developed desktop client that allowed users to send short messages to and receive updates from a user specified SharePoint list was also available. This tool was used extensively for a number of different applications but for our initial purposes was rejected for the same reason of scope as the Zevenseas Workgroup Twitter application.
![]() Status.Net [11] a FLOSS microblogging platform that was being actively developed and supported was our ultimate choice. This solution provides all of the ease-of-use and similar functionality to Twitter but is based on the OStatus standard [12] for interoperability between installations.
Status.Net [11] a FLOSS microblogging platform that was being actively developed and supported was our ultimate choice. This solution provides all of the ease-of-use and similar functionality to Twitter but is based on the OStatus standard [12] for interoperability between installations.
Within not much more than a day, Status.net was downloaded and installed on a virtualised environment running on a spare Windows PC. A new icon was created to replace the default Status.net icon and launched to the alpha testing community as 'Pfollow' (Figure 13.2). Various other aspects of Status.net were quickly tweaked, most significantly the new user creation and login modules were customised to utilise our existing company-wide authentication infrastructure and a completely new URL shortening service based on YOURLS [13] was implemented and integrated into our Pfollow instance.
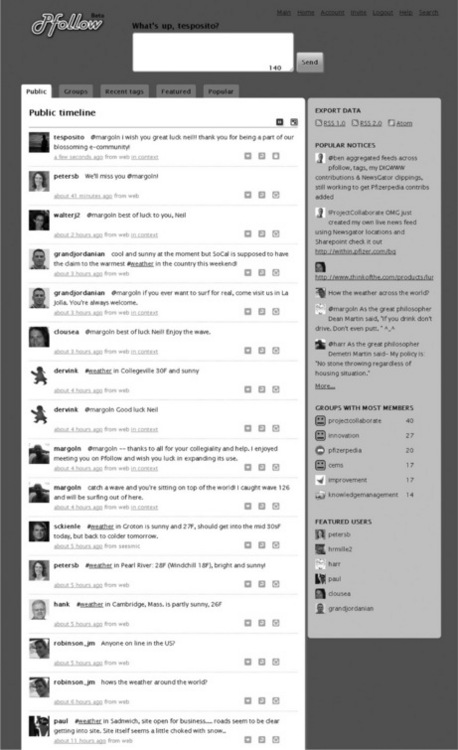
Figure 13.2 A screenshot of Pfollow showing the 'tweets' within the public timeline. This microblogging service is based on the FLOSS solution Status.net
At this stage of exploring a microblogging capability, we had identified Status.net as our go forward solution and had performed preliminary testing with our alpha testing community. On the basis of this we had confidence that it was ready to move into Proof of Concept phase being both stable and scalable. In the next phase we would be opening up Pfollow to a wider audience and focusing on understanding how microblogging could deliver business value. Details of these learnings are presented below.
13.2.3 Proof of Concept phase
The key deliverable from this phase is a decision as to whether a capability delivers business value and if so what the requirements of the service are. In making this decision the following questions needed to be answered. Does the technology actually work in the workplace? Can it integrate into real world workflows? What use cases demonstrate business value? What are the shortcomings of the solution/capability? What adoption patterns do we observe?, etc. In order to answer these questions we needed to perform safe-fail experiments, that is small-scale deployments that do not build critical business dependencies on the capability.
This was a more detailed exploration of the capability than the previous research phase but still did not involve significant development or modification of the chosen software. However, it was recognised very early on that LDAP integration, that is enabling users to use their corporate Windows network ID and password, was critical for getting adoption beyond members of the alpha testing community. In practice, this modification was generally very simple and had the added benefit that it significantly simplified the effort associated with migrating and merging user's content between test instances. Further, a consistent user ID across tools later allowed us to experiment with lightweight integration/cross surfacing of content between tools without the complexity of mapping user accounts, that is creating activity streams.
The data generated in this phase are used to build the business case for funding of a production capability and the requirements that service needs to meet. The purpose is not to promote the solution used during this phase but to enable an accurate assessment of the capability.
13.2.4 Proof of Concept phase use-cases: microblogging and social bookmarking
Pfollow – microblogging
Having identified Status.net as our solution for exploring microblogging (see previous section), the final step was to obtain the Pfollow internal domain name. At this point the new service was advertised to prospective users via existing social media and emails to relevant networks within the company. These users were invited to take part, but were made aware of the experimental nature of the software through a set of terms and conditions related to its use. The primarily underlining fact being that due to the nature of our deployment we needed to reserve the right to switch Pfollow off at any point once our experiment had reached a logical conclusion. Consequently, users needed to be made aware that they should not build business critical dependencies on this service.
The new Pfollow community was fast growing and over a matter of weeks we started to see both individual contributors making an impact and a large number of online groups coming into existence. Initial posts were largely non-work related – instead the equivalent of small talk around the water cooler really, allowing key participants to introduce themselves and get to know each other. For instance, a post each day relaying what the weather was looking like in their neck of the woods, an often common icebreaker at the start of teleconferences, when participants are dialling in from different parts of the world. This provided an easy entry for users to get to grips with the software and get comfortable with the idea of posting to such a public forum where the recipients are largely unseen and unknown.
Some specific work-related use-cases emerged from our experiment.
![]() Ask your extended network a question. Either directed at the general community, sometimes accompanied by a specific hashtag, or targeted to a specific group. The benefit seen here was that users realised they now could quickly and easily call on an extended network of professionals for help.
Ask your extended network a question. Either directed at the general community, sometimes accompanied by a specific hashtag, or targeted to a specific group. The benefit seen here was that users realised they now could quickly and easily call on an extended network of professionals for help.
![]() Share a project/work/status update. This was seen as a good way of publicising progress or the completion of a piece of work, perhaps more widely than might be possible using traditional communication channels.
Share a project/work/status update. This was seen as a good way of publicising progress or the completion of a piece of work, perhaps more widely than might be possible using traditional communication channels.
![]() Advertise something that has been posted online elsewhere. For example, a blog posting, paper or web page. Cross-posting was a popular use of Pfollow as, again, it opened up the existence of a resource or achievement to a much wider audience and was an effective way for an individual to communicate their speciality, knowledge gained or general expertise in a subject area.
Advertise something that has been posted online elsewhere. For example, a blog posting, paper or web page. Cross-posting was a popular use of Pfollow as, again, it opened up the existence of a resource or achievement to a much wider audience and was an effective way for an individual to communicate their speciality, knowledge gained or general expertise in a subject area.
Our experimentation with Status.net served to allow us to quickly identify the following key requirements if we were to proceed with a microblogging service.
![]() The ability to create groups proved to be a highly important feature – we saw special interest groups, project teams and communities of practice utilise Pfollow to quickly and easily form and share information. The fact the groups that had been created were available to view in public listing was also key as it allowed and encouraged people to connect based on their interests and specialities rather than arriving at a connection solely through their particular existing organisational and/or geographical associations.
The ability to create groups proved to be a highly important feature – we saw special interest groups, project teams and communities of practice utilise Pfollow to quickly and easily form and share information. The fact the groups that had been created were available to view in public listing was also key as it allowed and encouraged people to connect based on their interests and specialities rather than arriving at a connection solely through their particular existing organisational and/or geographical associations.
![]() Hashtags were important to allow users to structure and interlink posts and allow areas of interest to emerge and be tracked by interested parties.
Hashtags were important to allow users to structure and interlink posts and allow areas of interest to emerge and be tracked by interested parties.
![]() Support for RSS proved important so that users could subscribe to distinct parts of the overall discussion, for example subscribe to specific groups, users or hashtags, depending on their particular areas of interest.
Support for RSS proved important so that users could subscribe to distinct parts of the overall discussion, for example subscribe to specific groups, users or hashtags, depending on their particular areas of interest.
Overall our microblogging experiment was a success and provided us with the confidence to take the concept further. Status.net was critical in that it provided us with the full set of features required to see the benefits of using this type of technology, allowed us the ability to tweak it as our specific organisational needs dictated and, importantly, provided an ease of use that encouraged our users to embrace the software.
Tags.pfizer.com – social bookmarking
The goal of this project was to explore the use of social bookmarking within Pfizer. By allowing people to share their bookmarks online, social bookmarking services, such as Delicious [14], are turning the world of bookmarking (browser favourites) upside down. Instead of storing bookmarks on desktops, users store them online in a shared site. Not only can users access their bookmarks anywhere, but also so can anyone else. This allows colleagues to discover new sources of information by looking at what others working in similar areas are bookmarking. Furthermore, as users bookmark things that are important to their work or their area of expertise their bookmark collection becomes a tacit repository describing their interests. As a result social bookmarking services can also enable social networking. By looking at bookmarks saved by others, users can discover new colleagues who share their areas of expertise/interest.
To evaluate this capability Scuttle [15], an open source social bookmarking tool, was selected, judged by much the same criteria as described above for Status.net. Scuttle provides similar capabilities to the popular web service Delicious. In addition it supports the Delicious API, which allows bookmarks to be imported from that service and, in principle, allows any Delicious-compatible tools to work with it such as browser toolbar extensions. Further, Scuttle also provides RSS support with feeds automatically generated and filtered by user, tag and multitag/ user combination. Finally, the company Mitre had used Scuttle as the codebase on which they developed Onomi, an inhouse social bookmarking solution [16] giving us confidence that Scuttle was robust, scalable and could work in a business environment.
Initially, a development instance was installed, which was used during the discovery phase for functionality evaluation and stability/load testing.
Having established that this tool was stable and offered the core functionality of a social bookmarking service the team created a second instance, tags.pfizer.com, for the internal community (Figure 13.3).
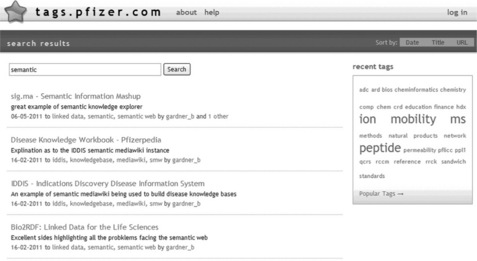
Figure 13.3 A screenshot of tags.pfizer.com. Bookmarks 'tagged' with the term 'semantic' are shown. This social bookmarking service is based on the FLOSS solution Scuttle
During the earlier discovery phase, the development instance of tags. pfizer.com had become heavily populated with technical bookmarks. As a result it was decided that during the Proof of Concept phase two active instances would be maintained. This would allow two communities to develop one IT technical and one with a drug discovery focus. Later these two instances were merged once the business facing community had been established.
To start, a 'private beta' model was used for user recruitment to tags. pfizer.com, targeting known Web 2.0/Enterprise 2.0 early adopters and colleagues familiar with social bookmark services. This was followed by a word of mouth viral campaign, targeting key influences, and finally formal presentations were made to the research community. This approach was used to help overcome the cold start issue, namely an empty bookmark database. To further ameliorate this problem, one of the first groups asked to contribute were information science colleagues. This group worked to populate tags.pfizer.com with bookmarks for key resources used by the colleagues they supported and provided rich and valuable content for other users.
The use of this service was evaluated over a six month period. During this time the number of users, across the two instances, grew to 220, of which ~ 20 per cent were adding new bookmarks on a regular basis. After six months a total of ~ 5500 bookmarks had been added, although this did include bookmarks imported from users' Delicious accounts. Although these metrics indicate that users were obtaining value from this service, more detailed feedback was sought via an online questionnaire and user interviews. The key message that came through from these results was that a majority considered they were obtaining value from this service and would recommend tags.pfizer.com to their colleagues. However, it was also felt that tags.pfizer.com would benefit from increased scale; the more people who used it the more valuable it would become.
This issue of scale has been highlighted by Thomas Vander Wal [17] where he points out that as a social bookmarking service grows (both in the number of users and the number of bookmarks), the value and use of the system changes. This can be broken down into four phases. In the first phase the use is personal, a user saves, tags and re-finds bookmarks. As the community of users grows we move into the second phase, serendipity. Here the user can start to explore other users' bookmarks but the searching is hit or miss. In addition groups/project teams will start to coordinate and use common tags to highlight items of interest to the rest of the group/team. The next phase is social tagging maturity, in this phase users can regularly search and find new and related bookmarks. We would also expect to see the bookmarking service start to support social networking as users also begin to identify colleagues with similar interests based on their tag and/or bookmark fingerprints. In essense the service has evolved from purely a bookmarking service and has become a key tool in social networking that supports/enables complex social networks.
At this point tags.pfizer.com was in the first phase. As such most users were getting value from the service based on the improvement in ability to store and search their bookmarks over that offered via their 'favourites' folder in their browser. Although the benefits of this were evident, the greater value from being able to search/explore other people's bookmarks and identify kindred colleagues was generally not being realised. However, despite this a number of 'islands' of specialty began to build, each starting to exhibit the behaviours/functionality associated with the more mature phases of a social bookmarking service.
In terms of overall functionality, Scuttle provided the core capabilities and successfully enabled social bookmarking within the company. However, to achieve wider adoption some key issues still need to be resolved. First among these is the integration of user accounts with users' Windows network ID and passwords, as well as integration with the browser, that is toolbar extensions. However, at that time Pfizer's standard desktop was based around Internet Explorer 6 and such browser extensions would have required bespoke development. This highlights the conflicts we often see between the rapidly moving external world, where technologies are evolving at a rapid pace, and the internal world where technologies move slower [18]. Finally, this experiment highlighted that the utilisation of this service within the enterprise requires integration with internal systems in ways not required on the web. On the internet, web pages are bookmarked via a browser button or a scriptlet added to the browser links toolbar. This works well in this environment, but within the enterprise users often want to store links to other content, such as documents within content management systems. In this case, the URL for these documents is often not displayed in the browser toolbar but rather accessed via a right mouse click or complex Javascript (or even Flash) functionality. At best, capturing these bookmarks can be achieved through a manual cut and paste; additional complexity that is far from ideal for users. Given these limitations it was decided that if social bookmarking was to be developed as a production service it would require significant development of the Scuttle codebase, development of browser extensions and potentially changes to the user interface of a number of document management systems.
13.2.5 Production deployment phase
At this point in the FLOSS assessment framework, the value of a collaboration tool has been proven and the requirements are well understood. Here, in this phase, the production solution is selected and deployed. Successful usage patterns identified in the previous phases are used to promote the software into the business and drive adoption. New usage patterns will continue to emerge and these need to be captured and utilised to continue to promote the system. At the same time, the wider usage of the web site, service or tool may highlight areas were development/ extension of the capability is required.
Obviously one of the critical decisions at this stage is to determine whether the software explored within earlier Discovery and Proof of Concept phases is suitable to go forward into a production environment. In taking this decision, each potential tool must be assessed with respect to a standard capability requirements document as well as any other factors that influence future support and development of the system. Up to this point, the flexibility provided by the open culture of the FLOSS solutions is generally seen as a positive. However, once deployment to a production environment is being considered, the associated business-critical workflows result in some of these same advantages becoming significant risks.
For example, a FLOSS solution might be considered robust but without an active developer community attached to it, the solution might become non-viable over time. This is particularly true if it is not being updated relative to the technology stack on which it is hosted. Alternatively, a large and active support community can fragment the codebase, resulting in multiple, possibly conflicting branches and variants. In some cases, these risks maybe mitigated by employing third-party vendor support models, a model which is becoming increasingly common. Of course, an organisation can also decide to fork the codebase itself and develop some features specific to its business requirements. Consequently, the burden of full support, along with all the inherent costs falls to that organisation alone. In light of these risks and costs, continuing with a FLOSS solution into production is not a trivial decision.
13.2.6 Production Deployment phase use-case: Pfizerpedia – Enterprise Wiki
MediaWiki is the FLOSS that was originally developed for Wikipedia, the free encyclopaedia web site used by many millions of users every day. As well as powering the family of Wikipedia web sites it is also used by hundreds if not thousands of web sites elsewhere on the web and within a number of large company intranets. The MediaWiki software [19] is available to download for free from http://mediawiki.org and contains a number of class-leading wiki features. Because of the high visibility of the Wikipedia [20] site, the MediaWiki software is very familiar to most users and the software has been explored by a number of life science organisations (see Chapter 16 for another example).
Although MediaWiki is FLOSS, it is clearly high quality and has many traits suitable for deployment in the enterprise. For instance, scalability of MediaWiki has been proven quite clearly by the implementation of Wikipedia on the web. For an enterprise organisation, this scalability is not an advantage solely in terms of performance. It also brings the functions necessary for large numbers of users to happily coexist on the same platform, and system administration tools required to manage the large number of pages that will (rapidly) be created within the wiki.
On the performance front, MediaWiki has been designed from the first to be quick and responsive and its authors have built in many routines, such as aggressive caching, to ensure sustained high performance.
Another key facet of the scalability of MediaWiki is that it has been designed to be easily extended and as a result there are a large number of extensions that can also be freely downloaded from the MediaWiki.org site to expand how it can be used even further. Indeed, a single instance of MediaWiki can take the place of an untold number of individually coded applications that would naturally exist within any organisation, for example see Table 13.2. Note that MediaWiki can be taken to another level of sophistication altogether with the introduction of the Semantic MediaWiki family of extensions and this is covered in detail elsewhere in this book (see Chapters 16 and 17).
Table 13.2
Classifying some of the most common uses of MediaWiki within the research organisation
| Application of MediaWiki | Description |
| Sharing knowledge | One of the most high value uses of MediaWiki within a research organisation is as a way of sharing knowledge derived from various projects. A 'one-stop shop' MediaWiki page on a specific subject that multiple authors from across an organisation contribute to can be a very powerful tool |
| Help and how-to pages | Ease of authoring and cross-referencing content means capturing how-to and help guides are a popular use of MediaWiki. For instance, on the check out the Wired How-To Wiki [21] or the Open Wetware Wiki [22] |
| Lessons learnt/best practices | The low cost of MediaWiki as an application and its complete openness makes it a perfect place to store lessons learnt for future reference |
| Catalogues | A single MediaWiki instance within an organisation is an excellent place to investigate what someone is working on or the service a group can provide. The power comes from being able to access related content, e.g. the 'Innovation' page links to a generic topic of 'Social Problem Solving', which in turn leads to a tool available within the organisation that provides a solution for this need |
| Yellow and white pages | It is incredibly easy to create formal structured directories of people and groups within MediaWiki using the MediaWiki categories feature. If the names of organisational groups should change, MediaWiki handles this in an elegant fashion by allowing you to 'move' pages – automatically creating a link from the old name to the new for anybody who subsequently attempts to access it through an out-of-date cross-link or URL |
| Collaborative authoring | Wikis are unique at providing true collaborative authoring, many authors can improve the same page at the same time. Every MediaWiki page has a 'history' tab, providing a log of exactly who has changed what and a 'discussion' tab to discuss changes. With features like RSS and MediaWiki Email Alerts, users can be notified when specific pages are updated by other authors |
| Profiles | One of the great strengths of MediaWiki is the ability to see exactly who is contributing to what topics. To enhance this feature even further, users can create a page describing themselves, populated with links to areas within the wiki that reflect their work. MediaWiki will automatically aggregate and display their contributions; this can be very valuable when you can remember the name of somebody who contributed to a piece of work but not the name of the topic they contributed to |
Inside Pfizer, a single general-purpose instance of MediaWiki was installed and named Pfizerpedia (Figure 13.4). At inception it was envisioned that this would develop into a scientific encyclopaedia, akin to Wikipedia, for the research and development community. However, it was rapidly recognised that wikis could enable collaboration in a much broader sense and the idea that Pfizerpedia would be restricted to being an encyclopaedia was relaxed. Pfizerpedia evolved to become a knowledge-sharing tool supporting a wide range of use-cases, including encyclopaedia pages, hints and tips pages, user/team/department/ organisation profiles (Figure 13.5), application/process support/help pages (Figure 13.6), acronym disambiguation, portfolio/service catalogues and social clubs. Thus, Pfizerpedia is much more than a collection of factual pages; it is a tool that enables groups to collaborate, share and find information.
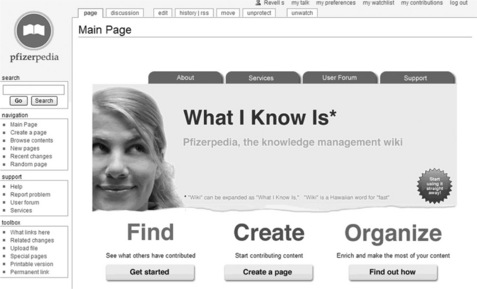
Figure 13.4 A screenshot showing Pfizerpedia's home page. This wiki is based on the FLOSS solution MediaWiki
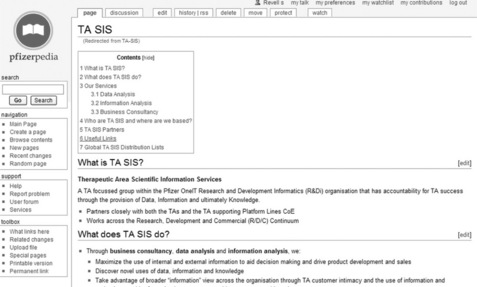
Figure 13.5 A screenshot showing an example profile page for the Therapeutic Area Scientific Information Services (TA SIS) group. Profile pages typically provide a high-level summary of the person/group/organisation along with links to resources and information often held in other systems
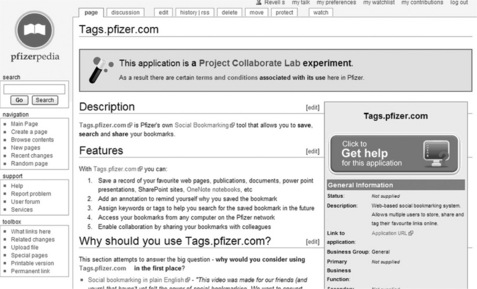
Figure 13.6 A screenshot of the tags.pfizer.com social bookmarking service page from the R&D Application catalogue. This catalogue contains a collection of pages describing the various applications available to the R&D community. Each page provides a high-level description of the application along with links to full help and support pages also within Pfizerpedia
Pfizerpedia has grown from an experimental instance for the R&D community (originally hosted on a PC under a colleague's desk) into a solution that is being adopted across the whole company. As the number of users and volume of content has grown, we have started to examine how we can automate some of the more common tasks associated with managing a wiki, known as 'wiki gardening'. This involves prompting when content may need to be updated and applying appropriate categories, templates and banners across many pages. MediaWiki caters for this via an Application Programming Interface (API), allowing for the creation of 'bots' that can be scheduled to automatically retrieve and update pages. Bots can be programmed in a number of different computer languages including Java,.Net and Python.
In choosing to use MediaWiki as the solution for Pfizerpedia, we made the conscious decision to stay as close to the core MediaWiki distribution as possible to limit our exposure to maintenance and support costs/ overheads. This has meant we have:
![]() never redeveloped any of the codebase for the MediaWiki application itself nor any third-party extensions used. This way the upgrade path for our installation of MediaWiki is pain-free and low effort as we can deploy new versions without the need to reapply company specific customisations;
never redeveloped any of the codebase for the MediaWiki application itself nor any third-party extensions used. This way the upgrade path for our installation of MediaWiki is pain-free and low effort as we can deploy new versions without the need to reapply company specific customisations;
![]() been conservative in our adoption of third-party extensions, again to limit the amount of effort required for our upgrade path and ongoing support;
been conservative in our adoption of third-party extensions, again to limit the amount of effort required for our upgrade path and ongoing support;
![]() tried to limit any third-party extensions installed to being from only those used on the Wikipedia family of web sites, maintained by the same group of developers of the core system itself. This should mean that the development of these extensions is more likely to be in sync with the main MediaWiki software. This should negate the need for revision of extension code by internal developers whenever a new version of MediaWiki is issued.
tried to limit any third-party extensions installed to being from only those used on the Wikipedia family of web sites, maintained by the same group of developers of the core system itself. This should mean that the development of these extensions is more likely to be in sync with the main MediaWiki software. This should negate the need for revision of extension code by internal developers whenever a new version of MediaWiki is issued.
As a result of adopting these principles, we have faced no software issues or outages, low to non-existent support and maintenance costs, and a set of happy and very satisfied users. Our experience confirms MediaWiki as a powerful piece of software that can be applied to many different knowledge-sharing and collaboration scenarios. It boasts features that facilitate connections to people, knowledge and information that do not exist in many other forms of collaboration and content management software. Couple this with the large and highly active support/ development community and it can readily be seen that MediaWiki is an example of a FLOSS solution that can be readily deployed into production with minimal risk.
13.2.7 Shared Service phase
In many respects the challenges and objectives for this final phase are common to all application deployments within large organisations. Here we see a transition of responsibility from the team that developed/ implemented a solution over to the sustain/support team. Typically, in large organisations, this involves two groups; those delivering back-end support and those providing direct end-user support (i.e. a 'helpdesk'). The former requires the technical details about the implementation; which servers the solution is on, how to perform upgrades, what are the dependencies, etc. In contrast, the user support team need to be provided with training material, a knowledge base covering basic troubleshooting, any installation guides, etc. Yet, in the case of collaboration solutions we have found that users often require more than just a technical training session. Focusing only on the function of each feature, how to log in, how to save, etc., misses educating users on how the platform can be used in a social and collaborative context at work. Thus, the training aspect in adopting these tools often requires more emphasis than traditional IT solutions. Many of the basic reasons for this are associated with overcoming the differences in our expectations and behaviours between work and home life (Table 13.1). However, software collaboration tools also require users to develop the social skills and confidence associated with formal community-building and a willingness to explore new ways of working.
Successful collaborative working requires more than just building an online space. People willing and able to engage and manage the community or team and to encourage the members to adopt new working practices are critical. Even better, colleagues able to think beyond existing tools and envision how combinations of individual services can support or enable new working practices are invaluable. The openness and flexibility of web-based collaborative capabilities is a great strength but to take advantage of this capacity requires users to think differently. This really represents a core difference between the Web 2.0 type tools and the traditional solutions with which knowledge workers have been provided. Typically traditional tools designed for knowledge works included hard-coded workflow process, a one-size-fits-all assumption. In contrast, the Web 2.0 tools are open and flexible and allow users to superimpose their own way of working onto a blank canvas. However, it is our experience that users confronted with a blank canvas find this lack of signpost/ guidance quite intimidating. Often, this is enough to prevent them exploring the potential within these capabilities to significantly enhance/ simplify their working. In response to the challenges discussed above, we recognised the need to provide users not just with technical training on tools but also to support community building/developing new working practices. To do this we developed 'consultancy workshops' targeted to those colleagues involved in continuous improvement activities and end-user close IT colleagues. These workshops aimed to provide colleagues with a technical understanding of the new capabilities and skills required to build and maintain online communities. In particular, examples of how these collaboration capabilities have been successfully used with business groups were presented. The key learning here was that these tools can revolutionise the way people collaborate but if you only focus on 'building it', the users might not follow you. Ultimately, success requires enthusiasm and partnership between developers and users, allowing iterative evolution of the software system.
13.2.8 Principle for collaboration
Finally, a few words need to be said about our general learning concerning this type of software. During our experimentation with FLOSS collaboration capabilities, we identified a number of key principles that define the core architecture of collaboration. These form a framework, which applies equally to the technology and the culture. It is our experience that adoption of these principles is required if a culture of collaboration and openness is to develop. The four core principles we developed are:
![]() freedom – the easiest way to prevent collaboration from occurring is to impose overly burdensome control around how colleagues work. If collaboration is to flourish we need to trust colleagues and not impose rigid workflows, inappropriate approval processes (moderation), restriction on who can collaborate with whom (association) and have an open attitude towards sharing information;
freedom – the easiest way to prevent collaboration from occurring is to impose overly burdensome control around how colleagues work. If collaboration is to flourish we need to trust colleagues and not impose rigid workflows, inappropriate approval processes (moderation), restriction on who can collaborate with whom (association) and have an open attitude towards sharing information;
![]() emergence – no two collaborations are the same, each team/group will have different requirements and will develop different working practices. Given this we need to allow patterns and structures to emerge as collaborations develop. This is not to say we should not stimulate behaviours we want or share experiences but rather we should accept this and recognise that we need to avoid a one-size-fits-all approach;
emergence – no two collaborations are the same, each team/group will have different requirements and will develop different working practices. Given this we need to allow patterns and structures to emerge as collaborations develop. This is not to say we should not stimulate behaviours we want or share experiences but rather we should accept this and recognise that we need to avoid a one-size-fits-all approach;
![]() clarity of purpose – in this case, colleagues are confused as they are presented with multiple tools, all of which seem to do the same or a similar task. In the case of Pfizer we had a plethora of different tools that enable various degrees of collaboration; Enterprise Document repositories such as Insight, Documentum, SharePoint, eRooms, Pfizerpedia and so on. The lack of consistent advice around how and when to use these tools inevitably leads to adoption of Outlook for information management, fragmented silos of project data and a lack of any real knowledge management strategy.
clarity of purpose – in this case, colleagues are confused as they are presented with multiple tools, all of which seem to do the same or a similar task. In the case of Pfizer we had a plethora of different tools that enable various degrees of collaboration; Enterprise Document repositories such as Insight, Documentum, SharePoint, eRooms, Pfizerpedia and so on. The lack of consistent advice around how and when to use these tools inevitably leads to adoption of Outlook for information management, fragmented silos of project data and a lack of any real knowledge management strategy.
![]() ease of use – collaboration is about enabling conversations between people. It is not about technology. Therefore, it is critical that technology does not get in the way of collaboration. If a collaborative culture is to be enabled then it must be ensured that colleagues find the tools are intuitive, integrate into their workflows and require minimal training.
ease of use – collaboration is about enabling conversations between people. It is not about technology. Therefore, it is critical that technology does not get in the way of collaboration. If a collaborative culture is to be enabled then it must be ensured that colleagues find the tools are intuitive, integrate into their workflows and require minimal training.
13.3 Conclusion
The availability of free and open source software was a critical enabler in our ability to introduce and build collaborative capabilities for research and development at Pfizer. In the early phases where experimentation and agility were critical, FLOSS allowed us to rapidly explore a capability by examining various different approaches. This was further enabled through the availability of packaged distributions that incorporated the complete technology stack. The ability to download and run a personal version of a tool, on your desktop or even via a USB drive, meant that participation in the Discovery phase was opened up to many more participants than possible with 'traditional' software. This allowed a diverse community of interest to develop and actively contribute from the very beginning. In the Proof of Concept stage, these strengths of FLOSS were also enabling but the fact that many are also of high quality allowed us to explore how collaboration capabilities really add value within the organisation. The ability to test the ideas and 'stories' that were circulating on the web at this time was invaluable and lead us to really appreciate the different challenges that implementing these tools produce. All of this done without one licensing discussion or vendor engagement and for zero investment costs.
As we move into the Production Deployment phase, the emphasis switches from enabling experimentation to deploying a robust solution on which business critical processes may depend. The experience gained from working with the FLOSS solutions was central to making the tools selection at this stage. In many cases, FLOSS solutions scored highly, and often outscored vendor offering in terms of features, user experience and user interface. However, at this point we also needed to take into account how a tool would be supported, developed and maintained. In this respect, many FLOSS solutions scored poorly, and as a consequence compromises may have to be made. Specifically, where a capability fits with a niche or specialist need, the FLOSS community supporting that the tool tends to be small (Scuttle or Status.net, for example). In these cases, the risks and burden in selecting these solutions for a production deployment can be too high. However, where a capability has wide application (e.g. MediaWiki, the Lucene search engine, etc.) then the FLOSS community tends to be large and active. Consequently, third-party support vendors will often have emerged to support these products, which means there is often little to choose from the sustain/maintenance side of the equations between the FLOSS and a commercial solution.
Overall, FLOSS has been critical in our developing collaboration capacity. It is certainly the case that without the availability of software that can be rapidly deployed with minimal initial overhead, we would not have been able to experiment in the way we did during the early phase. Being able to build up experience and understanding as to what collaboration with social media tools really means within a business environment was critical. The learning provided from our FLOSS projects has proved invaluable during the Production Deployment and Shared Service phases and allowed us to create solutions that fit with the new working practices in a Web 2.0-enabled world.
13.4 Acknowledgements
The authors would like to acknowledge the many colleagues who contributed to the various projects described here. In particular Paul Driscoll, Scott Gavin, Chris Bouton, Stephen Jordan, Andrew Berridge, Steve Herring, Jason Marshall, Daniel Siddle, Anthony Esposito and Nuzrul Haque.
13.5 References
[1] McAfee, A. Enterprise 2.0: The Dawn of Emergent Collaboration. MIT Sloan Management Review; 47. April 2006:21–28. [and]. McAfee, A., Enterprise 2.0: New Collaborative Tools for your Organisation's Toughest Challenges. Boston: Harvard Business School Press; 2009.
[2] Patterson R. 'Social Media and the Organisation' FastForward Blog, http://www.fastforwardblog.com/2007/08/29/social-media-and-the-organisation-part-1/. updated August 2007.
[3] MoWeS Portable CH Software, http://www.chsoftware.net/en/mowes/mowesportable/mowes.htm.
[4] Server2Go, http://www.server2go-web.de/.
[5] BitNami, http://bitnami.org/.
[6] Apache Friends, http://www.apachefriends.org/en/xampp.html.
[7] Thought Police VMWare Images, http://www.thoughtpolice.co.uk/.
[8] Twitter, http://twitter.com/.
[9] Yammer, https://www.yammer.com/.
[10] McPherson D. 'Twitter for SharePoint?' Zevenseas Point2Share, http://community.zevenseas.com/Blogs/Daniel/Lists/Posts/Post.aspx?ID=93, updated 24 April 2009.
[11] StatusNet, http://status.net/.
[12] OStatus, http://ostatus.org/about.
[13] YOURLS, http://yourls.org/.
[14] Delicious, http://www.delicious.com/.
[15] Scuttle, http://sourceforge.net/projects/scuttle/.
[16] Damianos L, Griffith J, Cuomo D. Onomi: Social Bookmarking on a Corporate Intranet. http://www.mitre.org/work/tech_papers/tech_papers_06/06_0352/06_0352.pdf.
[17] Vander Wal T. Bottom Up Tagging. http://www.slideshare.net/vanderwal/bottom-up-tagging.
[18] Wingfield, N., It's a Free Country. So why can't I pick the technology I use in the office? The Wall Street Journal 15 November 2009; . http://online.wsj.com/article/SB10001424052748703567204574499032945309844.html
[19] MediaWiki.org, http://www.mediawiki.org/wiki/MediaWiki.
[20] Wikipedia.org, http://www.wikipedia.org/.
[21] Wired How-To-Wiki, http://howto.wired.com/wiki/About_How-To_Wiki.
[22] Open Wetware – Share Your Science. http://openwetware.org/wiki/Main_Page.