
Single-Input, Multiple-Data (SIMD) processing is one of the PPU’s most important strengths. Whether the task involves rendering, simulating, or filtering, a modern processor needs to be able to crunch multiple numbers at once. The PPU provides dedicated hardware for this purpose, and its compatibility with the PowerPC architecture means that Mac users don’t need to modify their applications to run them on the Cell.
Most vector-based applications on the Cell rely on the SPUs rather than the PPU. But there are three important reasons to learn about SIMD coding on the PPU. First, the PPU supports many, but not all, of the instructions in the popular AltiVec instruction set architecture. The SPUs don’t.
Second, the PPU isn’t resource-limited when it comes to storing data and instructions. As will be discussed in Part 4, the SPU can only access 256KB at once, and that’s not a lot of space when you’re developing complex algorithms. If your application is memory intensive, it’s a good idea to test it on the PPU, and when everything works, modify it to execute it on one or more SPUs.
Third, the functions available for the SPU and PPU are essentially similar. The PPU-based vector functions in the AltiVec, SIMD Math, and MASSV libraries have nearly the same names as their SPU counterparts. After you’ve learned SIMD development on the PPU, it’s easy to manage the minor incompatibilities between PPU code and SPU code.
This chapter presents SIMD development on the PPU and the available vector functions. Specifically, it covers three important libraries provided by the SDK: AltiVec, SIMD Math, and MASSV.
The terms scalar and vector have specific meanings in science and engineering, but for the purposes of this chapter, a scalar is a single primitive datatype such as a short, int, float, or double. A vector is a 128-bit quantity containing multiple scalars of a single type. A vector is like an array, but there’s an important distinction: An array operation iterates serially through the array’s elements. A vector operation is performed on the vector’s elements in parallel.
An example will make this clear. If you want to add the elements of two four-element arrays, a and b, your code will look like the following:
c[3]=a[3]+b[3]; c[2]=a[2]+b[2]; c[1]=a[1]+b[1]; c[0]=a[0]+b[0];
This requires four separate additions. If a, b, and c are vectors, the PPU accomplishes the same result in a single, parallelized operation:
c = vec_add(a, b);
vec_add is one of the many functions provided by the AltiVec High-Level Language Interface, which will be covered in detail shortly. But before you learn about the vector functions, it’s important to recognize the different types of vectors they operate on.
All vectors on the Cell (PPU and SPU) are 128 bits wide, but there are many different datatypes depending on the type of scalars contained in the vector. Table 8.1 lists the different types of vectors supported by the PPU.
Table 8.1. PPU Vector Datatypes (Not all are available for the SPU)
Vector Datatype | Scalar Elements |
|---|---|
| 16 8-bit |
| 16 8-bit |
| 16 8-bit |
| 8 16-bit |
| 8 16-bit |
| 8 16-bit |
| 8 16-bit |
| 4 32-bit |
| 4 32-bit |
| 4 32-bit |
| 4 32-bit |
There are two common ways to access the scalars inside a PPU vector. First, you can obtain a pointer to a vector and access its elements with pointer operations. Second, you can create a union of the vector and a scalar array. This forms a single memory location that can be manipulated as a vector using SIMD instructions or accessed as a regular C/C++ array.
Note
At the time of this writing, the SDK tools do not support the vec_extract command or format placeholders for vectors (%vc, %vd, and so on). To display a vector’s contents in PPU code, you need to access each scalar individually.
For example, the code in Listing 8.1 creates a union of a vector unsigned char and a char array. This union can be operated upon as a vector or as an array of characters. Note that the vector must be initialized with 16 characters (16 × 8-bit char = 128-bit vector).
Example 8.1. Accessing Vectors with a Union: ppu_union.c
#include <stdio.h>
#include <altivec.h>
/* Create a union of a vector and
an array of 16 characters */
typedef union {
vector unsigned char vec;
unsigned char scalars[16];
} charVecType;
int main(int argc, char **argv) {
int i;
charVecType charVec;
/* Initialize the vector elements */
charVec.vec = (vector unsigned char)
{'H','e','l','l','o',' ','P','r',
'o','g','r','a','m','m','e','r'};
/* Print each element by accessing the array */
for(i=0; i<16; i++)
printf("%c", charVec.scalars[i]);
printf("
");
return 0;
}There are three important differences between the PPU’s vector datatypes and those used by the SPUs:
The SPUs support
vector doubles andvector long longs that store 64-bit scalars. The PPU can’t process vectors containing 64-bit values. If you want to work withdoubles on the PPU, you’ll have to rely on the scalar Floating-Point Unit (FPU).The PPU supports the
vector pixeldatatype, SPUs don’t. Each 16-bit pixel in the vector is encoded in 1/5/5/5 format, where the first bit represents the pixel’s alpha value, and the 5-bit groups represent the pixel’s red, green, and blue channels.Processing of floating-point vectors on the PPU is much closer to the IEEE 754 standard than on the SPU. The PPU’s handling of these vectors can be configured by modifying registers. This is covered in the following discussion.
By default, the PPU’s Floating-Point Unit (FPU) processes floats according to the single-precision IEEE 754 standard. That is, floats are formatted with a sign bit, an 8-bit exponent, and a 23-bit fraction. The IEEE standard also supports other values: positive/negative infinity, results of invalid operations (NaNs), and denormal numbers.
Denormal numbers are closer to zero than the smallest possible float values, and must be emulated in software when hardware can’t process them. For instance, 5 × 10−40 is a denormal number, and if you run the following code
float x = 5.9e-40;
if (x == 0.0)
printf("Equal");
else
printf("Not equal);the output will be Not equal because the FPU knows how to handle scalar denormals.
But unlike the FPU, the PPU’s Vector/SIMD Execution Unit (VXU) does not strictly adhere to the IEEE standard. It operates in graphics rounding mode, which trades high precision for faster processing. The mode follows the standard for most floats, but makes the following changes:
Denormal values and underflow values are automatically rounded to zero.
Infinity and NaNs are special values, but are processed as if normal.
The positive overflow value is set to 0x7FFFFFFF, larger values are held to this.
The negative overflow value is set to 0xFFFFFFFF, smaller values are held to this.
For example, the code in Listing 8.2 compares a vector of denormal values to a vector of zeroes and displays the results of the comparison.
Example 8.2. Denormalized Values: ppu_denormal.c
#include <stdio.h>
#include <altivec.h>
int main(int argc, char **argv) {
vector float denormals, zeroes;
/* A vector containing four denormal values */
denormals = (vector float)
{5.9e-40, 5.9e-40, 5.9e-40, 5.9e-40};
zeroes = (vector float){0.0, 0.0, 0.0, 0.0};
/* Compare the denormal values to zero */
printf("Result: %d
", vec_all_eq(denormals, zeroes));
return 0;
}The vec_all_eq function returns 1 if the two vectors have identical elements and a 0 otherwise. In this case, the result will be 1 because, unlike the FPU, the VXU sets all denormal values to zero.
There are two ways to configure the VXU’s operation. The first involves setting bit 12 of the Hardware Implementation Register 1 (HID1) to zero. This takes the VXU out of graphics rounding mode and forces it to process floats according to the IEEE standard. But this register is privileged and can’t be written to from within user-mode applications.
The second method is more limited, but can be accessed by user-mode applications. Bit 15 of the Vector Status and Control Register (VSCR) is called the Non-Java Mode/IEEE bit, or NJ. When it’s set to zero, the VXU enters Java mode, which means that denormal and underflow values are processed according to the IEEE standard instead of being automatically set to zero. In all other respects, the VXU continues in graphics rounding mode.
The VXU doesn’t operate in Java mode by default, but this can be changed with the following lines of code:
vector unsigned short old_vscr, new_vscr, mask;
old_vscr = vec_mfvscr(); /* Read the VSCR */
mask = (vector unsigned short)
{0xffff,0xffff,0xffff,0xffff,0xffff,0xffff,0xfeff,0xffff};
new_vscr = vec_and(old_vscr, mask); /* Set Bit 15 to 0 */
vec_mtvscr(new_vscr); /* Write to the VSCR */When bit 15 is set to zero, the VXU will execute in Java mode. If you run the code in Listing 8.2 again, you’ll see that the denormals are handled differently than zeroes.
Java mode provides improved precision at the cost of reduced performance. It takes many cycles for the operating system to process denormals. And although the graphics-rounding mode is an option for the VXU, the SPUs always handle floats in this manner. So if you need your code to execute similarly on the PPU and SPUs, it’s better to stay in non-Java mode.
The operands and results of the PPU’s vector functions are all stored in one of the PPU’s 32 vector registers (VRs). These are required by the AltiVec standard, along with two control registers: the Vector Status and Control Register (VSCR) and the VR Save/Restore Register (VRSAVE).
There are only two unreserved fields in the VSCR. Both are shown in Figure 8.1.
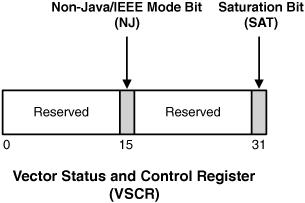
Bit 15 is the NJ (Non-Java Mode/IEEE) bit, discussed in the previous subsection. Bit 31 is the saturation bit (SAT). If the result of a fixed-point operation exceeds the space available to store it, many AltiVec functions set the SAT bit to 1. The following code adds a large number to itself, reads the VSCR, and checks the SAT bit to see whether saturation occurred.
vector unsigned short addend, sum, vscr, mask, zeroes;
addend = (vector unsigned int) /* Contains large scalar */
{0, 0, 0, 0xCCCCCCCC};
sum = vec_adds(addend, addend); /* Saturation! */
vscr = vec_mfvscr(); /* Read the VSCR */
mask = (vector unsigned int) {0, 0, 0, 1};
zeroes = (vector unsigned int) {0, 0, 0, 0};
/* Compare vscr to mask, check for saturation */
int result = vec_all_eq(vec_and(vscr, mask), zeroes);Only one of the scalar operations needs to saturate to raise the SAT bit. There is no simple way to determine which of the four additions caused the overflow.
Figure 8.2 depicts the second vector control register required by the AltiVec standard: the VR Save/Restore Register (VRSAVE).

Each of the 32 bits in the VRSAVE register corresponds to a VR. When an application uses one of the VRs, the corresponding VRSAVE bit is set to 1. When the operating system performs a context switch, it only stores the VRs whose VRSAVE bits have been set to 1. This is faster and more efficient than storing all 32 VRs.
The SDK contains many libraries that can be linked into PPU code, but when it comes to vector operations, the most important are the AltiVec, SIMD Math, and MASSV libraries. The AltiVec library is the oldest and most widely used, and provides a wide assortment of functions for fixed- and floating-point vectors. IBM’s SIMD Math and Mathematics Acceleration Subsystem Vector (MASSV) libraries contain functions that perform advanced mathematical routines.
This section explains each of these libraries: their strengths and weaknesses and how to link them into applications.
Originally developed by Apple in the mid-1990s, AltiVec is one of the first instruction sets focused on vector processing. Motorola Semiconductor (now Freescale Semiconductor) created the first AltiVec-supported devices, and they became the G4 processors in Apple’s computers. IBM has incorporated AltiVec processing in its recent PowerPCs, but because of Freescale’s trademark, you may see it referred to as the Vector Multimedia eXtension instruction set, or VMX.
The AltiVec library provides functions for vector mathematics and general-purpose vector processing. The AltiVec math functions are simple compared to those in the other two libraries, and they operate only on fixed-point values. But of the three libraries, AltiVec is the only one that contains routines for general vector manipulation, such as loading, storing, and permuting vectors. When you need to perform vector comparisons and conversions, AltiVec is the library to use.
AltiVec functions are declared in the altivec.h header file. Applications using these functions must be built with the -maltivec flag.
IBM created the SIMD Math library to provide advanced mathematical routines on top of AltiVec. Its functions operate on vector floats and vector doubles and perform operations related to trigonometry, logarithms, and exponentials. The SPUs can execute all the SIMD Math functions, but the PPU can run only those that operate on vector floats. SIMD Math library functions are named according to their arguments: Those that accept vector double arguments end with d2 and those that accept vector floats end with f4. Otherwise, the functions are used exactly like AltiVec functions.
You can inline a SIMD Math function in your code by preceding its name with an underscore. This inserts the function’s source into your code and usually improves performance by preventing time-intensive context switches. Besides the underscore, the only change you need to make is to include the simdmath/func_name.h header for each of your inline functions, where func_name is the name of the function without the underscore. Listing 8.6 shows how inlined functions are used in code.
If you’re accessing SIMD Math functions without inlining, you only need to include the simdmath.h header file. To add the SIMD Math library to the build process, make sure to add the -lsimdmath flag to the build step.
IBM first developed the Mathematics Acceleration Subsystem (MASS) 1.0 as a set of high-performance math functions for its AIX operating system. These functions were fine-tuned with each release, and the most recent version of MASS is included with the SDK for scalar mathematics. This chapter discusses IBM’s MASS library for vectors, called MASSV.
MASSV functions perform many of the same operations as the SIMD Math functions, but their usage is quite different. MASSV functions don’t access the vector datatypes in Table 8.1, and instead operate on arrays of floats and doubles. Functions that operate on floats start with vs, such as vssin, vsexp, and vscbrt. Functions that operate on doubles start with v, such as vsin and vexp.
All MASSV functions return void and their parameters are arranged in a specific order: the output array(s) first, the input array(s) next, and the last argument is a pointer to the size of the output/input arrays. For example, the MASSV function vscbrt computes cube roots. If the input array (in_array) and output array (out_array) both have 100 elements and the integer num equals 100, the function call
vscbrt(out_array, in_array, &num);
computes the cube roots of 100 values in in_array and places the results in out_array.
Listing 8.3 shows how MASSV functions are used in code. This application creates an array of 60 angles, computes the sine of each angle, and places the results in a second array.
Example 8.3. MASSV Example: ppu_massv.c
#include <stdio.h>
#include <math.h>
#include <massv.h>
#define N 60
int main(int argc, char **argv) {
int i;
int num = N;
float angles[N], sines[N];
/* Generate sixty angles in radians */
for (i=0; i<N; i++)
angles[i] = 2*M_PI*i/N;
/* Compute the sines */
vssin(sines, angles, &num);
/* Display the results */
printf("Sines:
");
for(i=0; i<N; i++)
printf("%f
", sines[i]);
return 0;
}The arguments of vssin are the output array (sines), the input array (angles), and a pointer to an int that tells how many elements are in each array (&n). This function is declared in massv.h, and the MASSV library is linked into applications with the -lmassv_64 flag.
Notice that the vssin function in Listing 8.3 is not surrounded by a for loop. This makes vssin much faster than a for loop containing calls to sinf4, the corresponding function in the SIMD Math library.
Between the AltiVec, SIMD Math, and MASSV libraries, there are many, many vector functions to choose from. This section breaks them down into 12 categories:
Load and store functions: Transferring vectors between registers and memory.
Addition/subtraction functions: Addition, subtraction, averaging, and partial sums.
Multiplication/division functions: Multiplication, division, modulus, remainder.
Conversion, splatting, and packing functions: Vector conversion, compression, and decompression.
Permutation and shifting functions: Rearranging and moving vector elements.
Basic unary functions: Absolute value, rounding/estimation, and reciprocation.
Logic functions: AND, ANDC, NOT, OR, XOR.
Vector comparison: Compares two vectors, returns a vector.
Vector comparison: Compares two vectors, returns a scalar.
Exponent/logarithm functions: Powers, roots, base-2 logs, base-e logs.
Floating-point analysis functions: Analyzes float bits, specifies special values.
Trigonometry functions: Sine, cosine, tangent, inverse functions, hyperbolic functions.
The following tables display all the functions in these categories, and each table entry contains the function name, the library, the return datatype, and the input datatypes. The following abbreviations are used:
A—. The AltiVec library (declared in altivec.h)
S—. The SIMD Math library (declared in simdmath.h)
P—. PPU Intrinsics (declared in ppu_intrinsics.h)
uc, bc, sc—. Vector unsigned char, vector bool char, vector signed char
us, bs, ss—. Vector unsigned short, vector bool short, vector signed short
ui, bi, si—. Vector unsigned int, vector bool int, vector signed int
vp—. Vector pixel
fl—. Vector float
The VMASS functions operate on float arrays (abbreviated as fl[]) and return void.
AltiVec and SIMD Math libraries access memory on 16-byte (128-bit) boundaries. If the load address isn’t aligned, the bottom 4 bits will be ignored, and memory will be accessed at the lower, aligned address. Because alignment is such an important concern, it’s a good idea to use AltiVec’s functions to load and store values. These are listed in Table 8.2.
Table 8.2. Load and Store Functions
Function Name | Lib | Description | Return Datatype | Argument Datatype |
|---|---|---|---|---|
| A | Vector Load Indexed | uc/sc/bc/us/ss/bs/vp/ui/si/bi/fl | integer, ptr to vector or array |
| A | Vector Load Indexed LRU | uc/sc/bc/us/ss/bs/vp/ui/si/bi/fl | integer, ptr to vector or array |
| A | Vector Load Element Indexed | uc/sc/us/ss/ui/si | integer, pointer to scalar |
| A | Vector Load for Shift Left | uc | integer, ptr to vector or array |
| A | Vector Load for Shift Right | uc | integer, ptr to vector or array |
| P | Vector Load Right Indexed | uc/sc/bc/us/ss/bs/vp/ui/si/bi/fl | integer, ptr to vector or array |
| P | Vector Load Right Indexed Last | uc/sc/bc/us/ss/bs/vp/ui/si/bi/fl | integer, ptr to vector or array |
| P | Vector Load Left Indexed | uc/sc/bc/us/ss/bs/vp/ui/si/bi/fl | integer, ptr to vector or array |
| P | Vector Load Left Indexed Last | uc/sc/bc/us/ss/bs/vp/ui/si/bi/fl | integer, ptr to vector or array |
| A | Vector Store Indexed | void | uc/sc/bc/us/ss/bs/vp/ui/si/bi/fl, integer, ptr to vector or array |
| A | Vector Store Indexed LRU | void | uc/sc/bc/us/ss/bs/vp/ui/si/bi/fl, integer, ptr to vector or array |
| A | Vector Store Element Indexed | void | uc/sc/bc/us/ss/bs/vp/ui/si/bi/fl, integer, ptr to vector or array |
| P | Vector Store Right Indexed | void | uc/sc/bc/us/ss/bs/vp/ui/si/bi/fl, integer, ptr to vector or array |
| P | Vector Store Right Indexed Last | void | uc/sc/bc/us/ss/bs/vp/ui/si/bi/fl, integer, ptr to vector or array |
| P | Vector Store Left Indexed | void | uc/sc/bc/us/ss/bs/vp/ui/si/bi/fl, integer, ptr to vector or array |
| P | Vector Store Left Indexed Last | void | uc/sc/bc/us/ss/bs/vp/ui/si/bi/fl, integer, ptr to vector or array |
The first function, vec_ld, loads 16 bytes from memory and returns the vector to the caller. It computes the load address by adding its two arguments: an integer and a pointer. If the resulting address isn’t aligned on a 16-byte boundary, the vector is loaded from the next-lowest 16-byte boundary. vec_ldl is similar, but also tells the cache that the address is least-recently used, meaning the cache line will be the first to be eliminated.
vec_lde performs the same operation as vec_ld. The AltiVec documentation states that it loads a single element into the returned vector and leaves the other elements undefined. In fact, the PPU loads all 16 bytes from the load address into the vector, just like vec_ld.
vec_lvsl and vec_lvsr don’t perform any loading at all. Instead, they determine where the pointer is aligned relative to the 16-byte vector boundary and return a vector that can be used to shift a vector at the unaligned address. This is an involved subject, and the following chapter examines unaligned loads and vector-shifting in detail.
The next four functions in Table 8.2 are PPU intrinsics that perform indexed loads. These functions load less than 16 bytes into vectors when the 4 LSBs of the load address are nonzero. For example, if these 4 bits equal n, vec_lvrx loads n bytes into the result vector from the right and sets the other bytes to zero. vec_rvlxl performs the same operation, but adds a hint that this will be the last time the memory is accessed. vec_lvlx and vec_lvlxl are similar to the right-loaded functions, but load 16-n bytes into the vector, starting from the left.
The AltiVec load functions can be confusing, but they’re important to understand. Listing 8.4 shows how vec_ld, vec_lde, and vec_lvlx are used in code. This application creates an aligned array of integers and accesses the array values with the three load functions.
Example 8.4. AltiVec Load Functions: ppu_load.c
#include <stdio.h>
#include <altivec.h>
#include <ppu_intrinsics.h>
#define N 8
typedef union {
vector unsigned int vec;
unsigned int scalars[4];
} intVecType;
int main(int argc, char **argv) {
int i;
unsigned int int_array[N]
__attribute__ ((aligned(16)));
intVecType vec_a, vec_b, vec_c;
/* Initialize the array */
for(i=0; i<N; i++)
int_array[i] = i;
/* Load the first four ints into vec_a */
vec_a.vec = vec_ld(0, int_array);
for(i=0; i<4; i++) /* 0 1 2 3 */
printf("%u ", vec_a.scalars[i]);
printf("
");
/* Load the next four ints into vec_b */
vec_b.vec = vec_lde(2, int_array+4);
for(i=0; i<4; i++) /* 4 5 6 7 */
printf("%u ", vec_b.scalars[i]);
printf("
");
/* Load 16-7=9 bytes into vec_c, left first*/
vec_c.vec = vec_lvlx(7, int_array);
for(i=0; i<4; i++)
printf("%08x ", vec_c.scalars[i]);
printf("
");
/* 01000000, 02000000, 03000000, 00000000 */
return 0;
}vec_st stores a vector to memory. The storage address is determined by adding the functions arguments: an integer and a pointer. The vector is stored at the nearest 16-byte aligned address less than the sum. vec_stl additionally marks the cache line as least recently used. vec_ste stores a single element into memory, at an address that is aligned at the same size as the element.
The left- and right-indexed storage routines are similar to the corresponding load operations. Each function allows part of a vector to be stored into memory, and the 4 least significant bits of the address determine how many bytes are stored. vec_stvlxl and vec_stvrxl provide a hint that this will be the last time the memory location will be used.
The functions in Table 8.3 add and subtract vectors, compute averages, and perform partial sums. vec_add and vec_sub are the two most common, and they can operate on nearly every vector datatype. The Modulo in the Description column refers to the fact that, for integers, the addition and subtraction is modular. That is, if the result falls outside the variable’s range, the returned answer “wraps around” to the accepted integer range.
Table 8.3. Addition/Subtraction Functions
Function | Lib | Description | Return Datatype | Argument Datatypes |
|---|---|---|---|---|
| A | Vector Add Modulo | uc/sc/us/ss/ui/si/fl | uc/sc/bc/us/ss/bs/ui/si/bi/fl, uc/sc/bc/us/ss/bs/ui/si/bi/fl |
| A | Vector Add Carryout | ui | ui, ui |
| A | Vector Add Saturated | uc/sc/us/ss/ui/si/fl | uc/sc/bc/us/ss/bs/ui/si/bi, uc/sc/bc/us/ss/bs/ui/si/bi |
| A | Vector Subtraction | uc/sc/us/ss/ui/si/fl | uc/sc/bc/us/ss/bs/ui/si/bi/fl, uc/sc/bc/us/ss/bs/ui/si/bi/fl |
| A | Vector Subtract Carryout | ui | ui, ui |
| A | Vector Subtract Saturated | uc/sc/us/ss/ui/si/fl | uc/sc/bc/us/ss/bs/ui/si/bi, uc/sc/bc/us/ss/bs/ui/si/bi |
| S | Vector Difference | fl | fl |
| A | Vector Average | uc/sc/us/ss/ui/si | uc/sc/us/ss/ui/si, uc/sc/us/ss/ui/si |
| A | Vector Sum Saturated | si | si, si |
| A | Vector Sum Saturated Across 1/2 | si | si, si |
| A | Vector Sum Saturated Across 1/4 | ui, si | uc/sc/ss, ui/si |
There are two ways to keep track of integer additions/subtractions whose results fall outside the accepted range. vec_add and vec_sub store the sum/difference in the result vector and set the SAT bit high when saturation occurs. vec_addc and vec_subc use the result vector to store the carry or borrow bits. The actual sums or differences are dropped from memory.
The last three functions in Table 8.3 are more complicated than the functions above them. Each adds elements of the first vector to one another, and then adds the sum or sums to elements in the second vector. The difference between them is how many sums are performed and which elements of the first and second vectors take part. This is shown in Figure 8.3, where the summed elements are depicted in gray.
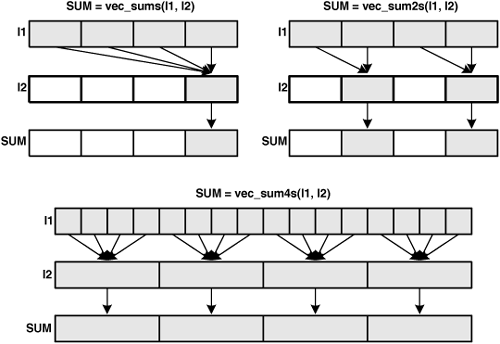
The first of the sum functions, vec_sums, adds all the elements of the first vector to the last element of the second vector and stores the sum in the final element of the result vector. vec_sum2s computes two sums: The first and second element of the first vector are added to the second element of the second vector, and the third and fourth elements of the first vector are added to the last element of the second vector. Both vec_sums and vec_sum2s only operate on vector unsigned ints.
Listing 8.5 shows how vec_add, vec_sums, and vec_sum2s are used in code. vec_a and vec_b are added together using each of the three functions and the result is printed to standard output.
Example 8.5. AltiVec Addition Functions: ppu_add.c
#include <stdio.h>
#include <altivec.h>
#include <ppu_intrinsics.h>
#define N 8
typedef union {
vector signed int vec;
int scalars[4];
} intVecType;
int main(int argc, char **argv) {
int i;
intVecType vec_a, vec_b, vec_sum;
/* Initialize vec_a and vec_b */
vec_a.vec = (vector signed int)
{0x08888888, 0x07777777, 0x06666666, 0x05555555};
vec_b.vec = (vector signed int)
{0x04444444, 0x03333333, 0x02222222, 0x01111111};
/* Add all elements of vec_a and vec_b */
vec_sum.vec = vec_add(vec_a.vec, vec_b.vec);
for(i=0; i<4; i++)
printf("%08x ", vec_sum.scalars[i]);
printf("
");
/* 0ccccccc 0aaaaaaa 08888888 06666666 */
/* Add elements of vec_a to element 0 of vec_b */
vec_sum.vec = vec_sums(vec_a.vec, vec_b.vec);
for(i=0; i<4; i++)
printf("%08x ", vec_sum.scalars[i]);
printf("
");
/* 00000000 00000000 00000000 1ccccccb */
/* Load 16-7=9 bytes into vec_c, left first*/
vec_sum.vec = vec_sum2s(vec_a.vec, vec_b.vec);
for(i=0; i<4; i++)
printf("%08x ", vec_sum.scalars[i]);
printf("
");
/* 00000000 13333332 00000000 0ccccccc */
return 0;
}The last function, vec_sum4s, computes four sums, one for each of the ints in the second vector. But the number of operands in each sum depends on the type of the first vector. If the first vector contains chars, the first four chars are each added to the first int, the second four chars are added to the second int, and so on. If the first vector contains signed shorts, the first two shorts are added to the first int, the next two shorts are added to the second int, and so on. In each case, the SAT bit is raised to 1 if saturation occurs.
AltiVec provides many different routines for multiplying fixed- and floating-point vectors. The SIMD Math Library provides many functions for dividing vectors. These are listed in Table 8.4. MASSV only provides a single function in this category, vsdiv. As will be demonstrated, this is the best-performing function to use for floating-point vector division.
Table 8.4. Multiplication/Division Functions
Function Name | Lib | Description | Return Datatype | Argument Datatypes |
|---|---|---|---|---|
| A/S | Vector Multiply and Add | fl | fl, fl, fl |
| A | Negative Vector Multiply and Subtract | fl | fl, fl, fl |
| A | Vector Multiply Even | us/ss/ui/si | uc/sc/us/ss, uc/sc/us/ss |
| A | Vector Multiply Odd | us/ss/ui/si | uc/sc/us/ss, uc/sc/us/ss |
| A | Vector Multiply/Add Saturated (High) | ss | ss, ss, ss |
| A | Vector Multiply/Add Modulo (Low) | us, ss | us/ss, us/ss, us/ss |
| A | Vector Multiply Round and Add Saturated | ss | ss, ss, ss |
| S | Multiply By Power of 2 | fl | fl, si |
| S | Vector Floating-Point Divide | fl | fl |
| M | Vector Floating-Point Divide | void | fl[], fl[], fl[], int* |
| S | Vector Integer Divide | si | si, si |
| S | Vector Unsigned Integer Divide | ui | ui, ui |
| S | Vector Modulus | fl | fl, fl |
| S | Vector Remainder | fl | fl, fl |
| S | Vector Remainder/Modulus | fl | fl, fl, int * |
Multiply-and-accumulate (MAC) operations form the backbone of signal processing and matrix algebra algorithms. The first two functions serve this purpose for vector floats. vec_madd multiplies the first two vectors and adds the third vector to the product. vec_nmsub multiplies the first two vectors, subtracts the third vector from the product, and returns the negated result.
Unlike floats, the product of two ints can take up to twice the space of either operand. Because the VXU doesn’t support 64-bit datatypes, there are no multiplication functions for 32-bit integers. For this reason, all the functions following vec_madd operate on 16-bit shorts. The first two also take chars as arguments.
vec_mule and vec_mulo store the entire products in the result vector but don’t operate on all the input elements. vec_mule multiplies input elements 0 and 2 and vec_mulo multiplies elements 1 and 3. If the input vectors contain chars, the result is a vector containing shorts. If the input vectors contain shorts, the result is a vector containing ints.
The next three functions multiply all the input elements, but only store parts of the products. vec_mradds multiplies all the shorts of the first two input vectors, drops the low 15 bits of the products, and adds the results to a third vector signed short. vec_mladd is similar, but drops the high 16 bits. This doesn’t set the SAT bit high in the case of overflow. vec_mradds is also similar, but rounds the products upward by adding 214 to each of them.
The three floating-point division functions all perform the same operation, but do so in different amounts of time. The test routine in Listing 8.6 compares their performance by accessing the PPU’s Time Base register. You may want to use a similar application to conduct your own tests.
Example 8.6. Division Comparison: ppu_divcomp.c
#include <stdio.h>
#include <stdlib.h>
#include <massv.h>
#include <ppu_intrinsics.h>
#include <simdmath.h>
#include <simdmath/divf4.h>
#include <simdmath/divf4_fast.h>
/* Number of vectors to be processed */
#define N 100
typedef union {
vector float vec[N];
float scalars[N*4];
} floatType;
int main(int argc, char **argv) {
int i;
unsigned long long start, end;
float time;
floatType a, b, c;
/* Initialize vector/scalar values */
for(i=0; i<N*4; i++) {
a.scalars[i] = (float)rand()/RAND_MAX;
b.scalars[i] = (float)rand()/RAND_MAX;
}
/* Test divf4 (inline) */
start = __mftb();
for (i=0; i<N; i++)
c.vec[i] = _divf4(a.vec[i], b.vec[i]);
end = __mftb();
time = (float)(end-start)/(N*4);
printf("Ticks per op for divf4 (inline): %f
",
time);
/* Test divf4_fast (inline) */
start = __mftb();
for (i=0; i<N; i++)
c.vec[i] = _divf4_fast(a.vec[i], b.vec[i]);
end = __mftb();
time = (float)(end-start)/(N*4);
printf("Ticks per op for divf4_fast (inline): %f
",
time);
/* Test divf4 */
start = __mftb();
for (i=0; i<N; i++)
c.vec[i] = divf4(a.vec[i], b.vec[i]);
end = __mftb();
time = (float)(end-start)/(N*4);
printf("Ticks per op for divf4: %f
",
time);
/* Test divf4_fast */
start = __mftb();
for (i=0; i<N; i++)
c.vec[i] = divf4_fast(a.vec[i], b.vec[i]);
end = __mftb();
time = (float)(end-start)/(N*4);
printf("Ticks per op for divf4_fast: %f
",
time);
/* Test the vsdiv function */
int num_tests = N*4;
start = __mftb();
vsdiv(c.scalars, a.scalars, b.scalars, &num_tests);
end = __mftb();
time = (float)(end-start)/(N*4);
printf("Ticks per op for vsdiv: %f
", time);
return 0;
}
On my system, the results are as follows:
Ticks per op for divf4 (inline): 19.252 Ticks per op for divf4_fast (inline): 3.785 Ticks per op for divf4: 26.34 Ticks per op for divf4_fast: 8.305 Ticks per op for vsdiv: 1.683
On average, the VMASS function vsdiv is faster than any of the SIMD Math routines, inline or otherwise. With regard to accuracy, the values obtained from divf4 and divf4_fast were exactly the same as the results generated by the FPU’s division operator. The vsdiv quotients differed by an average of approximately .000001.
divi4 and divu4 divide signed and unsigned integers, respectively. Both access individual elements of a vector, so unless your application vectors, you’re probably better off dividing scalars. fmodf4 performs the modulo operation, similar to C’s % operator, but for vectors. remainderf4 returns the remainder of the division operation, as does remquof4. remquof4 also provides the magnitude of the integral quotient at the memory location of its third argument.
Table 8.5 lists the functions that convert between vector datatypes and compress (pack) and decompress (splat) vector data. All of them are provided by the AltiVec library.
Table 8.5. Conversion, Splatting, and Packing Functions
Function Name | Lib | Full Name | Return Datatype | Argument Datatypes |
|---|---|---|---|---|
| A | Vector Convert to Float | fl | ui/si, 5-bit unsigned |
| A | Vector Convert to Signed Word | si | fl, 5-bit unsigned |
| A | Vector Convert to Unsigned Word | ui | fl, 5-bit unsigned |
| A | Vector Splat | uc/sc/bc/us/ss/bs/vp/ui/si/bi/fl | uc/sc/bc/us/ss/bs/vp/ui/si/bi/fl, 5-bit unsigned |
| A | Vector Splat Unsigned Byte | uc | 5-bit signed |
| A | Vector Splat Signed Byte | sc | 5-bit signed |
| A | Vector Splat Unsigned Halfword | us | 5-bit signed |
| A | Vector Splat Signed Halfword | ss | 5-bit signed |
| A | Vector Splat Unsigned Word | ui | 5-bit signed |
| A | Vector Splat Signed Word | si | 5-bit signed |
| A | Vector Pack | uc/sc/bc/us/ss/bs | us/ss/bs/ui/si/bi, us/ss/bs/ui/si/bi |
| A | Vector Pack Saturated | uc/sc/us/ss | us/ss/ui/si, us/ss/ui/si |
| A | Vector Pack Saturated Unsigned | uc/us | us/ss/ui/si, us/ss/ui/si |
| A | Vector Pack Pixel | vp | ui, ui |
| A | Vector Unpack Low | ss/bs/ui/si/bi | sc/bc/vp/ss/bs |
| A | Vector Unpack High | ss/bs/ui/si/bi | sc/bc/vp/ss/bs |
| A | Vector Merge Low | uc/sc/bc/us/ss/bs/vp/ui/si/bi/fl | uc/sc/bc/us/ss/bs/vp/ui/si/bi/fl, uc/sc/bc/us/ss/bs/vp/ui/si/bi/fl |
| A | Vector Merge High | uc/sc/bc/us/ss/bs/vp/ui/si/bi/fl | uc/sc/bc/us/ss/bs/vp/ui/si/bi/fl, uc/sc/bc/us/ss/bs/vp/ui/si/bi/fl |
These vector conversion functions are simple to understand. The first, vec_ctf, divides each element of the input vector by 2b, where b is the second argument, a 5-bit unsigned literal. The results are stored in a vector float. vec_cts and vec_ctu work in the opposite way: the input floating-point values are multiplied by 2b. Then the products are truncated and stored in a vector signed int or vector unsigned int.
vec_splat selects one element from the input vector and repeats that element throughout the returned vector. The second argument, a 5-bit literal, selects which of the input elements should be splatted. Of course, the value of this literal can only be as high as the number of elements in the input vector.
The next splat functions are similar, except the 5-bit literal input is the value to be splatted within the result. vec_splat_u8 and vec_splat_s8 repeat the 5-bit value throughout a vector unsigned char or vector signed char. vec_splat_u16 and vec_splat_s16 repeat the 5-bit value inside a vector unsigned short or vector signed short. vec_splat_u32 and vec_splat_s32 repeat the 5-bit value throughout a vector unsigned int or vector signed int.
The four packing functions form the result vector from portions of the two input vectors. vec_pack forms the result vector by combining the high halves of the first input vector’s elements and the low halves of the second input vector’s elements. These high and low halves are truncated from their input elements; there is no rounding or saturation.
vec_packs compresses the elements of two input vectors and places them in a single result vector. For example, if the two input vectors are vector signed ints, vec_packs forces the eight numeric values into a vector signed short. If the input values exceed the storage capacity, the SAT bit is set to 1. vec_packsu works similarly, but stores the results as unsigned vector datatypes. vec_packpx compresses two vector unsigned ints containing 32-bit pixels (four 8-bit channels) into a single vector pixel containing 16-bit pixels (three 5-bit channels, one 1-bit channel).
While vec_packsu compresses two vectors into a vector whose elements are half the size, vec_unpackl and vec_unpackh decompress a vector into a vector whose elements are twice the size. vec_unpackl sets the low halves of the result vector equal to the low elements of the input vector. vec_unpackh sets the low halves of the result vector equal to the high elements of the input vector.
vec_mergel and vec_mergeh operate like vec_pack, but instead of taking the high and low halves of the input elements, they form the result vector from the low or high elements themselves. That is, vec_mergel takes the low elements of the input vector and makes them the even elements of the result. The odd elements in the result are the low elements of the second input vector. vec_mergeh takes the high elements of the first and second input vectors and makes them the even and odd elements of the result.
The AltiVec functions in Table 8.6 manipulate the positions of vector elements, not their values. In each case, the return vector contains some or all the input vectors’ elements, but the arrangement is different. It’s important to keep track of whether the rearrangement is performed at the bit level or the byte level.
Table 8.6. Permutation and Shifting Functions
Function Name | Lib | Full Name | Return Datatype | Argument Datatype |
|---|---|---|---|---|
| A | Vector Permutation | uc/sc/bc/us/ss/bs/vp/ui/si/bi/fl | uc/sc/bc/us/ss/bs/vp/ui/si/bi/fl, uc/sc/bc/us/ss/bs/vp/ui/si/bi/fl, uc |
| A | Vector Select | uc/sc/bc/us/ss/bs/ui/si/bi/fl, | uc/sc/bc/us/ss/bs/ui/si/bi/fl, uc/sc/bc/us/ss/bs/ui/si/bi/fl, uc/bc/us/bs/ui/bi |
| A | Vector Rotate Left | uc/sc/us/ss/ui/si | uc/sc/us/ss/ui/si, uc/us/ui |
| A | Vector Shift Left | uc/sc/us/ss/ui/si | uc/sc/us/ss/ui/si, uc/us/ui |
| A | Vector Shift Left Long | uc/sc/bc/us/ss/bs/vp/ui/si/bi | uc/sc/bc/us/ss/bs/vp/ui/si/bi, uc/us/ui |
| A | Vector Shift Left Octet | uc/sc/us/ss/vp/ui/si/bi | uc/sc/us/ss/vp/ui/si/bi, uc/us/ui |
| A | Vector Shift Left Double | uc/sc/us/ss/vp/ui/si/fl | uc/sc/us/ss/vp/ui/si/fl, uc/sc/us/ss/vp/ui/si/fl, 4-bit unsigned |
| A | Vector Shift Right | uc/sc/us/ss/ui/si | uc/sc/us/ss/ui/si, uc/us/ui |
| A | Vector Shift Right Octet | uc/sc/us/ss/vp/ui/si/bi | uc/sc/us/ss/vp/ui/si/bi, uc/us/ui |
| A | Vector Shift Right Long | uc/sc/bc/us/ss/bs/vp/ui/si/bi | uc/sc/bc/us/ss/bs/vp/ui/si/bi, uc/us/ui |
| A | Vector Shift Right Algebraic | uc/sc/us/ss/ui/si | uc/sc/us/ss/ui/si, uc/us/ui |
vec_perm is the most important of these functions, and creates a new vector by selecting bytes from the two input vectors. It helps to think of the input vectors as one long 32-byte array. The third argument, a vector unsigned char, consists of 32 indices that select bytes from the input array and place them in the result vector.
An example will clarify how vec_perm works. Figure 8.4 shows how indices in the vector unsigned char select bytes from two input vector unsigned ints. The selected bytes are placed in the result vector. Because the two vectors have a total of 32 bytes, the indices must take values between 0 and 31.
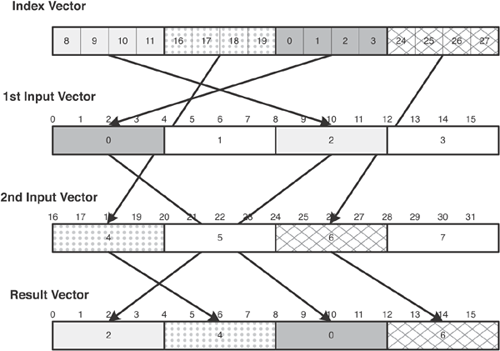
The code in Listing 8.7 shows how to implement this example using vec_perm.
Example 8.7. Vector Permutation Example: ppu_permtest.c
#include <stdio.h>
#include <altivec.h>
typedef union {
vector unsigned int vec;
unsigned int scalars[4];
} intType;
int main(int argc, char **argv) {
vector unsigned int vec_a, vec_b;
vector unsigned char indexVec;
intType result;
/* Initialize the input vectors */
vec_a = (vector unsigned int) {0, 1, 2, 3};
vec_b = (vector unsigned int) {4, 5, 6, 7};
/* Initialize the index vector */
indexVec = (vector unsigned char)
{8, 9, 10, 11, 16, 17, 18, 19,
0, 1, 2, 3, 24, 25, 26, 27};
/* Place the selected bytes in the result */
result.vec = vec_perm(vec_a, vec_b, indexVec);
printf("%u %u %u %u
", result.scalars[0],
result.scalars[1], result.scalars[2],
result.scalars[3]);
return 0;
}
The result is 2 4 0 6, just as in Figure 8.4.
vec_sel also creates a vector by selecting values from two inputs, but it operates on bits. The function accepts three arguments: two input vectors and a selection vector. If bit N of the selection vector equals 0, bit N of the result equals Bit N of the first input vector. If the selection bit equals 1, bit N of the result equals bit N of the second input vector.
The next two functions in Table 8.6, vec_rl and vec_sl, left-shift the bits of each element in the first input vector according to the values of the elements in the second input vector. The difference between them is that vec_rl (r = rotate) places each bit shifted out to the LSB position of the result and vec_sl (s = shift) removes them, placing zeroes in the least significant positions of the result.
vec_sll is similar to vec_sl, but the number of bit shifts is specified by the 3 least significant bits of each element of the second input vector, and these 3 bits must be the same in each element. vec_slo is similar to vec_sll, but bytes are shifted, and the number of shifts is specified by bits 4 down to 1 in the least significant element of the second vector.
vec_sld is more complicated. It accepts three arguments: two input vectors and a 4-bit unsigned literal. The two inputs are effectively concatenated into a 32-byte vector and shifted left as many bytes as the literal specifies. The result vector contains the top 16 bytes of the shifted result.
The shift-right functions operate like the similarly named shift-left functions with one exception: vec_sra. This function shifts bits of the first input vector according to the values in the second vector, but unlike the other shifting functions, the sign bits are preserved.
Table 8.7 lists the basic unary (single-input) functions contained in the AltiVec and SIMD Math libraries. Most perform some kind of estimation: rounding, truncating, and flooring. Others find the absolute value and reciprocals of the scalars inside a vector.
Table 8.7. AltiVec Unary Arithmetic Functions
Function | Lib | Full Name | Return Datatype | Argument Datatype |
|---|---|---|---|---|
| A | Vector Absolute Value | sc/ss/si/fl | sc/ss/si/fl |
| A | Vector Absolute Value Saturated | sc/ss/si | sc/ss/si |
| S | Vector Negate | fl | fl |
| A/S | Vector Ceiling | fl | fl |
| A/S | Vector Floor | fl | fl |
| A | Vector Round | fl | fl |
| S | Vector Round | fl | fl |
| S | Find Nearest Integer | fl | fl |
| A/S | Vector Truncate | fl | fl |
| A | Vector Reciprocal Estimate | fl | fl |
| S | Vector Reciprocal Estimate w/Rounding | fl | fl |
vec_abs and vec_abss are similar except for two differences. First, vec_abs can provide the absolute value of signed fixed-point and floating-point scalars, whereas vec_abss can only be used for signed fixed-point scalars (signed char, signed short, signed int). Second, vec_abss sets the VSCR’s SAT bit when saturation occurs. This only happens when a scalar contains its most negative value.
vec_ceil and vec_floor operate like their scalar counterparts in math.h. vec_ceil finds the smallest integer values that are larger than or equal to the input vector elements and places them in the result vector. vec_floor is similar, but returns the largest integer values that are less than or equal to the input vector elements.
The AltiVec function, vec_round, returns the integer values closest to the input floating-point elements. When an input element lies exactly between two integers, the even integer is returned. The SIMD Math alternative, roundf4, is similar, but returns the higher integer when the input is halfway between integers. nearbyintf4 determines the current rounding mode and rounds accordingly. vec_trunc removes the fractional part of the floating-point inputs and returns the integer values.
Note
These estimation functions return integer values, but the results are stored as floating-point numbers inside a vector float. There are no functions that convert a vector float into a vector of fixed-point values.
The example code in Listing 8.8 shows how these five functions work.
Example 8.8. The AltiVec/SIMD Math Rounding Functions: ppu_rounding.c
#include <stdio.h>
#include <altivec.h>
#include <simdmath.h>
typedef union {
vector float vec;
float scalars[4];
} floatVecType;
int main(int argc, char **argv) {
floatVecType input, result;
/* Initialize the input vector */
input.vec = (vector float) {-2.5, -1.5, 1.5, 2.5};
printf("Input: %.1f, %.1f, %.1f, %.1f
",
input.scalars[0], input.scalars[1], input.scalars[2],
input.scalars[3]);
/* vec_ceil */
result.vec = vec_ceil(input.vec);
printf("vec_ceil: %.1f, %.1f, %.1f, %.1f
",
result.scalars[0], result.scalars[1], result.scalars[2],
result.scalars[3]);
/* vec_floor */
result.vec = vec_floor(input.vec);
printf("vec_floor: %.1f, %.1f, %.1f, %.1f
",
result.scalars[0], result.scalars[1], result.scalars[2],
result.scalars[3]);
/* vec_round */
result.vec = vec_round(input.vec);
printf("vec_round: %.1f, %.1f, %.1f, %.1f
",
result.scalars[0], result.scalars[1], result.scalars[2],
result.scalars[3]);
/* roundf4 */
result.vec = roundf4(input.vec);
printf("roundf4: %.1f, %.1f, %.1f, %.1f
",
result.scalars[0], result.scalars[1], result.scalars[2],
result.scalars[3]);
/* nearbyintf4 */
result.vec = nearbyintf4(input.vec);
printf("nearbyintf4: %.1f, %.1f, %.1f, %.1f
",
result.scalars[0], result.scalars[1], result.scalars[2],
result.scalars[3]);
/* vec_trunc */
result.vec = vec_trunc(input.vec);
printf("vec_trunc: %.1f, %.1f, %.1f, %.1f
",
result.scalars[0], result.scalars[1], result.scalars[2],
result.scalars[3]);
return 0;
}The output is listed as follows:
Input: -2.5, -1.5, 1.5, 2.5 vec_ceil: -2.0, -1.0, 2.0, 3.0 vec_floor: -3.0, -2.0, 1.0, 2.0 vec_round: -2.0, -2.0, 2.0, 2.0 roundf4: -3.0, -2.0, 2.0, 3.0 nearbyintf4: -3.0, -2.0, 2.0, 3.0 vec_trunc: -2.0, -1.0, 1.0, 2.0
It’s interesting to note that vec_round returns 2.0 for both 1.5 and 2.5, whereas roundf4 returns 2.0 and 3.0. This is because the two functions respond differently when the input lies exactly between two integers.
The next two functions in Table 8.7, vec_re and vec_rsqrte, estimate reciprocals with error less than 1/4096. vec_re returns the reciprocals of the input values, whereas vec_rsqrte returns the reciprocals of their square roots. In non-Java mode, denormal values are set equal to zero before processing.
By modifying the code in Listing 8.8, you can see how vec_re and vec_rsqrte process regular and irregular values. The results are as follows:
Input: -4.00, -0.00, 0.00, 4.00 re: -0.25, -inf, inf, 0.25 rsqrte: nan, -inf, inf, 0.50
AltiVec provides functions that perform common logic operations. These are listed in Table 8.8. They operate at the bit level and can accept every vector datatype as an argument.
Table 8.8. Vector Logic Functions
Function Name | Lib | Full Name | Return Datatype | Argument Datatype |
|---|---|---|---|---|
| A | Vector And | uc/sc/bc/us/ss/bs/ui/si/bi/fl | uc/sc/bc/us/ss/bs/ui/si/bi/fl, uc/sc/bc/us/ss/bs/ui/si/bi/fl |
| A | Vector And with Complement | uc/sc/bc/us/ss/bs/ui/si/bi/fl | uc/sc/bc/us/ss/bs/ui/si/bi/fl, uc/sc/bc/us/ss/bs/ui/si/bi/fl |
| A | Vector Or | uc/sc/bc/us/ss/bs/ui/si/bi/fl | uc/sc/bc/us/ss/bs/ui/si/bi/fl, uc/sc/bc/us/ss/bs/ui/si/bi/fl |
| A | Vector Nor | uc/sc/bc/us/ss/bs/ui/si/bi/fl | uc/sc/bc/us/ss/bs/ui/si/bi/fl, uc/sc/bc/us/ss/bs/ui/si/bi/fl |
| A | Vector Exclusive Or | uc/sc/bc/us/ss/bs/ui/si/bi/fl | uc/sc/bc/us/ss/bs/ui/si/bi/fl, uc/sc/bc/us/ss/bs/ui/si/bi/fl |
There is no bitwise complement operator similar to ~ in C/C++. vec_andc can be used instead. It inverts the bits in the second vector and then performs the AND operation on the two inputs. If the first vector is filled with ones, vec_andc returns the bitwise complement of the second vector.
The vector comparison functions in Table 8.9 are similar to the logic operators listed in Table 8.8, but they compare scalar values rather than bits. The AltiVec and SIMD Math libraries both provide functions for this purpose. The difference between them is that the SIMD Math functions accept only floats as arguments, and the AltiVec functions accept any non-bool, non-pixel datatype.
Table 8.9. Vector Comparison: Vector Return
Function Name | Lib | Full Name | Return Datatype | Argument Datatype |
|---|---|---|---|---|
| A | Vector Compare Equal | bc/bs/bi | uc/sc/us/ss/ui/si/fl, uc/sc/us/ss/ui/si/fl |
| S | Vector Compare Equal | ui | fl, fl |
| A | Vector Greater Than | bc/bs/bi | uc/sc/us/ss/ui/si/fl, uc/sc/us/ss/ui/si/fl |
| S | Vector Greater Than | ui | fl, fl |
| A | Vector Greater Than or Equal | bi | fl, fl |
| S | Vector Greater Than or Equal | ui | fl, fl |
| A | Vector Less Than | bc/bs/bi | uc/sc/us/ss/ui/si/fl, uc/sc/us/ss/ui/si/fl |
| S | Vector Less Than | ui | fl, fl |
| A | Vector Less Than or Equal | bi | fl, fl |
| S | Vector Less Than or Equal | ui | fl, fl |
| S | Vector Less Than or Greater Than | ui | fl, fl |
| A | Vector Compare Bounds | si | fl, fl |
| A | Vector Maximum | uc/sc/us/ss/ui/si/fl | uc/sc/bc/us/ss/bs/ui/si/bi/fl, uc/sc/bc/us/ss/bs/ui/si/bi/fl |
| S | Vector Maximum | fl | fl, fl |
| A | Vector Minimum | uc/sc/us/ss/ui/si/fl | uc/sc/bc/us/ss/bs/ui/si/bi/fl, uc/sc/bc/us/ss/bs/ui/si/bi/fl |
| S | Vector Minimum | fl | fl, fl |
These functions are all straightforward to understand and use, but vec_cmpb (Compare Bounds) is different. It returns a vector signed int whose first 2 bits contain the result of the comparison. Bit 0 is high if the first scalar is greater than the second, and low otherwise. Bit 1 is high if the first scalar is less than the negative of the second, and low otherwise. The rest of the bits are cleared.
In many instances, it’s simpler to access the result of a vector comparison with a scalar rather than a vector. These comparison functions, also called AltiVec predicates, are listed in Table 8.10. Each of them compares two vectors and stores the result in an int. The first of these functions, vec_all_eq, was used in Listing 8.2 to distinguish between the denormal vector and the zero vector.
Table 8.10. Vector Comparison: Scalar Return
Function Name | Lib | Full Name | Return Datatype | Argument Datatype |
|---|---|---|---|---|
| A | All Elements Equal | int | uc/sc/bc/us/ss/bs/vp/ui/si/bi/fl, uc/sc/bc/us/ss/bs/vp/ui/si/bi/fl |
| A | All Elements Not Equal | int | uc/sc/bc/us/ss/bs/vp/ui/si/bi/fl, uc/sc/bc/us/ss/bs/vp/ui/si/bi/fl |
| A | Any Elements Equal | int | uc/sc/bc/us/ss/bs/vp/ui/si/bi/fl, uc/sc/bc/us/ss/bs/vp/ui/si/bi/fl |
| A | Any Elements Not Equal | int | uc/sc/bc/us/ss/bs/vp/ui/si/bi/fl, uc/sc/bc/us/ss/bs/vp/ui/si/bi/fl |
| A | All Elements Greater Than | int | uc/sc/bc/us/ss/bs/ui/si/bi/fl, uc/sc/bc/us/ss/bs/ui/si/bi/fl |
| A | All Elements Not Greater Than | int | uc/sc/bc/us/ss/bs/ui/si/bi/fl, uc/sc/bc/us/ss/bs/ui/si/bi/fl |
| A | Any Elements Greater Than | int | uc/sc/bc/us/ss/bs/ui/si/bi/fl, uc/sc/bc/us/ss/bs/ui/si/bi/fl |
| A | Any Elements Not Greater Than | int | uc/sc/bc/us/ss/bs/ui/si/bi/fl, uc/sc/bc/us/ss/bs/ui/si/bi/fl |
| A | All Elements Greater Than or Equal | int | uc/sc/bc/us/ss/bs/ui/si/bi/fl, uc/sc/bc/us/ss/bs/ui/si/bi/fl |
| A | All Elements Not Greater Than or Equal | int | uc/sc/bc/us/ss/bs/ui/si/bi/fl, uc/sc/bc/us/ss/bs/ui/si/bi/fl |
| A | Any Elements Greater Than or Equal | int | uc/sc/bc/us/ss/bs/ui/si/bi/fl, uc/sc/bc/us/ss/bs/ui/si/bi/fl |
| A | Any Elements Not Greater Than or Equal | int | uc/sc/bc/us/ss/bs/ui/si/bi/fl, uc/sc/bc/us/ss/bs/ui/si/bi/fl |
| A | All Elements Less Than | int | uc/sc/bc/us/ss/bs/ui/si/bi/fl, uc/sc/bc/us/ss/bs/ui/si/bi/fl |
| A | All Elements Not Less Than | int | uc/sc/bc/us/ss/bs/ui/si/bi/fl, uc/sc/bc/us/ss/bs/ui/si/bi/fl |
| A | Any Elements Less Than | int | uc/sc/bc/us/ss/bs/ui/si/bi/fl, uc/sc/bc/us/ss/bs/ui/si/bi/fl |
| A | Any Elements Not Less Than | int | uc/sc/bc/us/ss/bs/ui/si/bi/fl, uc/sc/bc/us/ss/bs/ui/si/bi/fl |
| A | All Elements Less Than or Equal | int | uc/sc/bc/us/ss/bs/ui/si/bi/fl, uc/sc/bc/us/ss/bs/ui/si/bi/fl |
| A | All Elements Not Less Than or Equal | int | uc/sc/bc/us/ss/bs/ui/si/bi/fl, uc/sc/bc/us/ss/bs/ui/si/bi/fl |
| A | Any Elements Less Than or Equal | int | uc/sc/bc/us/ss/bs/ui/si/bi/fl, uc/sc/bc/us/ss/bs/ui/si/bi/fl |
| A | Any Elements Not Less Than or Equal | int | uc/sc/bc/us/ss/bs/ui/si/bi/fl, uc/sc/bc/us/ss/bs/ui/si/bi/fl |
| A | Vector Compare Bounds | int | fl, fl |
| A | Vector Compare Out of Bounds | int | fl, fl |
Because only a single scalar is returned, these functions can’t distinguish between the results of individual element comparisons. Instead, some functions tell whether all the elements meet the comparison criteria. Others tell whether any of the elements meet the criteria.
The last two functions, vec_all_in and vec_any_out, determine whether the elements of the first vector lie inside or outside the bounds of the second. Essentially, it checks whether the magnitude of the first vector’s are less than the corresponding elements in the second vector. If all the first vector’s elements are in bounds, vec_all_in returns one, and zero otherwise. If any of the elements are out of bounds, vec_any_out returns one, and zero otherwise.
Oddly, there are more vector functions available to compute exponents and logarithms than there are for multiplication and division. As shown in Table 8.11, most of them are provided by the SIMD Math or MASSV libraries, and all of them operate on vector floats and float arrays.
Table 8.11. Exponent/Logarithm Functions
Function | Lib | Full Name | Return Datatype | Argument Datatypes |
|---|---|---|---|---|
| S | Vector Raise to Power | fl | fl, fl |
| M | Vector Raise to Power | void | fl[], fl[], fl[], int* |
| A | Vector 2 Raised to Exponent | fl | fl |
| S | Vector 2 Raised to Exponent | fl | fl |
| S | Vector Exponential Function | fl | fl |
| M | Vector Exponential Function | void | fl[], fl[], int * |
| M | Vector Exponential Function Minus 1 | void | fl[], fl[], int * |
| S | Vector Square Root | fl | fl |
| M | Vector Square Root | void | fl[], fl[], int * |
| S | Vector Cube Root | fl | fl |
| M | Vector Cube Root | void | fl[], fl[], int* |
| M | Vector Quadratic Root | void | fl[], fl[], int* |
| A | Vector Reciprocal Square Root Estimate | fl | fl |
| S | Vector Reciprocal Square Root | fl | fl |
| M | Vector Reciprocal Square Root | void | fl[], fl[], int* |
| M | Vector Reciprocal Cube Root | void | fl[], fl[], int* |
| M | Vector Reciprocal Quadratic Root | void | fl[], fl[], int* |
| A | Vector Base-2 Logarithm | fl | fl |
| S | Vector Base-2 Logarithm | fl | fl |
| S | Vector Base-10 Logarithm | fl | fl |
| M | Vector Base-10 Logarithm | void | fl[], fl[], int* |
| S | Vector Natural Logarithm | fl | fl |
| M | Vector Natural Logarithm | void | fl[], fl[], int* |
| M | Vector Natural Logarithm of (x + 1) | void | fl[], fl[], int* |
These functions are easy to understand, but the names can be confusing. For example, the e at the end of vec_loge and vec_expte stands for estimate, and neither function has anything to do with the transcendental number, e. The real exponential functions (expf4 and vsexp) and natural logarithm functions (logf4 and vslog) don’t have any helpful modifiers like e, 2, or 10.
High-speed trigonometry is vital in graphic applications, and both the SIMD Math library and MASSV provide functions for this purpose. As shown in Table 8.12, they perform the sine, cosine, and tangent, as well as hyperbolic versions of these functions. Others compute trigonometric inverses, and their names contain an a for the arc- prefix. All input values are interpreted in radians.
Table 8.12. Trigonometric Functions
Function Name | Lib | Full Name | Return Datatype | Argument Datatype |
|---|---|---|---|---|
| S | Vector Sine | fl | fl |
| M | Vector Sine | void | fl[], fl[], int* |
| S | Vector Hyperbolic Sine | fl | fl |
| M | Vector Hyperbolic Sine | void | fl[], fl[], int* |
| S | Vector Arcsine | fl | fl |
| M | Vector Arcsine | void | fl[], fl[], int* |
| M | Vector Hyperbolic Arcsine | void | fl[], fl[], int* |
| S | Vector Cosine | fl | fl |
| M | Vector Cosine | void | fl[], fl[], int* |
| S | Vector Hyperbolic Cosine | fl | fl |
| M | Vector Hyperbolic Cosine | void | fl[], fl[], int* |
| S | Vector Arccosine | fl | fl |
| M | Vector Arccosine | void | fl[], fl[], int* |
| M | Vector Hyperbolic Arccosine | void | fl[], fl[], int* |
| S | Vector Tangent | fl | fl |
| M | Vector Tangent | void | fl[], fl[], int* |
| M | Vector Hyperbolic Tangent | void | fl[], fl[], int* |
| S | Vector Arctangent | fl | fl |
| M | Vector Arctangent of (x/y) | void | fl[], fl[], fl[], int* |
| M | Vector Hyperbolic Arctangent | void | fl[], fl[], int* |
| M | Vector Sine and Vector Cosine | void | fl[], fl[], fl[], int* |
| M | Vector Complex Cosine/Sine | void | fl_Complex[], fl[], int* |
The last two functions, vssincos and vscosisin, are useful when converting polar coordinates (r, θ) to rectangular coordinates (x, y). Both accept an array of angles in radians and compute the sines and cosines of each. vssincos places the sines and cosines into separate float arrays, and vscosisin combines them into an array of float_Complex values, as declared in complex.h. The individual sine/cosine values can be accessed using creal() and cimag(). As an example, Figure 8.5 shows four points on the complex unit circle.

The code in Listing 8.9 converts each of these angles to a complex pair using the MASSV function, vscosisin.
Example 8.9. Polar to Rectangular Conversion: ppu_polar.c
#include <stdio.h>
#include <math.h>
#include <massv.h>
#define N 4
int main(int argc, char **argv) {
int i, num;
/* Initialize the angles */
float angles[N] =
{M_PI/6, 2*M_PI/3, 5*M_PI/4, 13*M_PI/8};
/* Compute the cosines and sines */
num = N;
float _Complex coords[N];
vscosisin(coords, angles, &num);
/* Compute and display the rectangular coordinates */
for (i=0; i<N; i++)
printf("(%f, %fi)
",
creal(coords[i]), cimag(coords[i]));
return 0;
}(0.866025, 0.500000i) (-0.500000, 0.866025i) (-0.707107, -0.707107i) (0.382684, -0.923879i)
The use of trigonometry, vector functions, and complex operators will become much clearer in Chapter 17, “The Fast Fourier Transform (FFT).”
The PPU vector functions in this last group examine elements in a vector float. They are provided by the AltiVec and SIMD Math libraries and listed in Table 8.13.
Table 8.13. Floating-Point Analysis Functions
Function Name | Lib | Full Name | Return Datatype | Argument Datatype |
|---|---|---|---|---|
| S | Signed Bit of Float | ui | fl |
| S | Copy Sign/Magnitude | fl | fl, fl |
| S | Copy Exponent as Float | fl | fl |
| S | Copy Exponent as Integer | si | fl |
| S | Copy Fraction/Exponent | fl | fl, si * |
| S | Check if Zero or Denormal | ui | fl |
| S | Check if Normal | ui | fl |
| S | Check if Infinity | ui | fl |
| S | Check if Finite | ui | fl |
| S | Check if NaN | ui | fl |
| A | All Elements NaN | int | fl |
| A | Any Elements NaN | int | fl |
| A | All Elements Numeric | int | fl |
| A | Any Elements Numeric | int | fl |
These functions are as simple as they look. signbitf4 copies the sign bit of the input elements to those of a vector signed int. copysignf4 copies the sign bit of the elements of the first input vector and the magnitude of the elements of the second input vector.
logbf4 returns a vector float containing the unbiased exponents (binary) of the input float elements. ilogbf4 places the input exponents in a vector signed int. frexpf4 returns the normalized fraction (between ½ and 1) and stores the exponents (base-2) at the location pointed to by the second argument.
The next five functions check the element values of the input vector float for one of various conditions: zero or denormalization, normalization, infinity, finiteness, and if the values are not numbers. If an input element meets a condition, the corresponding element in the output vector will be set to all ones.
The last two functions work similarly to the vector comparison functions in Table 8.10. Instead of a vector, they return ints when their conditions are met. In particular, these functions check for the presence or absence of NaN values within the input.
Vector computation provides many advantages over single-value processing, but the learning curve is significant. There’s an entirely new set of functions that operate on a new set of datatypes. Details such as memory alignment and denormalization, commonly disregarded in scalar code, become crucial in vector-based applications.
The vector functions in this chapter come from three libraries: AltiVec, SIMD Math, and MASSV. AltiVec and the SIMD Math functions operate on 128-bit vectors whose datatypes depend on their elements. AltiVec functions perform basic math routines and general-purpose vector processing. The SIMD Math functions, like the MASSV functions, perform advanced mathematical computation. The difference is that MASSV functions operate on arrays rather than vectors and generally provide much better performance.
The PPU functions listed in this chapter perform a wide range of tasks, including memory operations, logical operations, and high-speed trigonometric operations. This whirlwind tour isn’t nearly sufficient to explain these routines in full, so I strongly recommend that you experiment on your own.