
Various options help doctest ignore noise, such as whitespace, in test cases. This can be useful, because it allows us to structure the expected outcome in a better way, to ease reading for the users.
We can also flag some tests that can be skipped. This can be used where we want to document known issues, but haven't yet patched the system.
Both of these situations can easily be construed as noise, when we are trying to run comprehensive testing, but are focused on other parts of the system. In this recipe, we will dig in to ease the strict checking done by doctest. We will also look at how to ignore entire tests, whether it's on a temporary or permanent basis.
With the following steps, we will experiment with filtering out test results and easing certain restrictions of doctest.
- Create a new file called
recipe20.pyto contain the code from this recipe. - Create a recursive function that converts base10 numbers into other bases.
def convert_to_basen(value, base): import math def _convert(remaining_value, base, exp): def stringify(value): if value > 9: return chr(value + ord('a')-10) else: return str(value) if remaining_value >= 0 and exp >= 0: factor = int(math.pow(base, exp)) if factor <= remaining_value: multiple = remaining_value / factor return stringify(multiple) + _convert(remaining_value-multiple*factor, base, exp-1) else: return "0" + _convert(remaining_value, base, exp-1) else: return "" return "%s/%s" % (_convert(value, base, int(math.log(value, base))), base) - Add a docstring that includes a test to exercise a range of values as well as documenting a future feature that is not yet implemented.
def convert_to_basen(value, base): """Convert a base10 number to basen. >>> [convert_to_basen(i, 16) for i in range(1,16)] #doctest: +NORMALIZE_WHITESPACE ['1/16', '2/16', '3/16', '4/16', '5/16', '6/16', '7/16', '8/16', '9/16', 'a/16', 'b/16', 'c/16', 'd/16', 'e/16', 'f/16'] FUTURE: Binary may support 2's complement in the future, but not now. >>> convert_to_basen(-10, 2) #doctest: +SKIP '0110/2' """ import math - Add a test runner.
if __name__ == "__main__": import doctest doctest.testmod() - Run the test case in verbose mode.
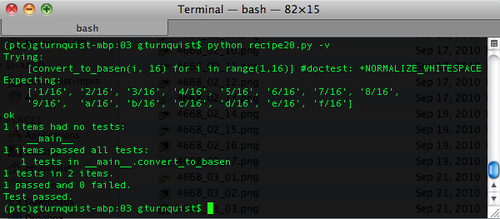
- Copy the code from
recipe20.pyinto a new file calledrecipe20b.py. - Edit
recipe20b.pyby updating the docstring to include another test exposing that our function doesn't convert0.def convert_to_basen(value, base): """Convert a base10 number to basen. >>> [convert_to_basen(i, 16) for i in range(1,16)] #doctest: +NORMALIZE_WHITESPACE ['1/16', '2/16', '3/16', '4/16', '5/16', '6/16', '7/16', '8/16', '9/16', 'a/16', 'b/16', 'c/16', 'd/16', 'e/16', 'f/16'] FUTURE: Binary may support 2's complement in the future, but not now. >>> convert_to_basen(-10, 2) #doctest: +SKIP '0110/2' BUG: Discovered that this algorithm doesn't handle 0. Need to patch it. TODO: Renable this when patched. >>> convert_to_basen(0, 2) '0/2' """ import math - Run the test case. Notice what is different about this version of the recipe; and why does it fail?
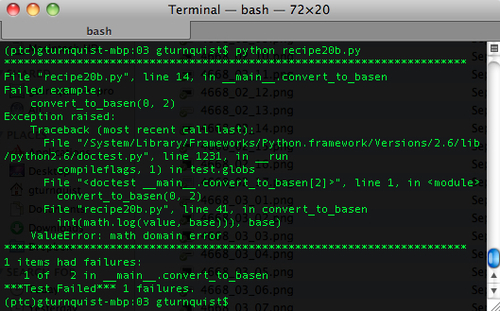
- Copy the code from
recipe20b.pyinto a new file calledrecipe20c.py. - Edit
recipe20c.pyand update the docstring indicating that we will skip the test for now.def convert_to_basen(value, base): """Convert a base10 number to basen. >>> [convert_to_basen(i, 16) for i in range(1,16)] #doctest: +NORMALIZE_WHITESPACE ['1/16', '2/16', '3/16', '4/16', '5/16', '6/16', '7/16', '8/16', '9/16', 'a/16', 'b/16', 'c/16', 'd/16', 'e/16', 'f/16'] FUTURE: Binary may support 2's complement in the future, but not now. >>> convert_to_basen(-10, 2) #doctest: +SKIP '0110/2' BUG: Discovered that this algorithm doesn't handle 0. Need to patch it. TODO: Renable this when patched. >>> convert_to_basen(0, 2) #doctest: +SKIP '0/2' """ import math - Run the test case.
In this recipe, we revisit the function for converting from base-10 to any base numbers. The first test shows it being run over a range. Normally, Python would fit this array of results on one line. To make it more readable, we spread the output across two lines. We also put some arbitrary spaces between the values to make the columns line up better.
This is something that doctest definitely would not support, due to its strict pattern matching nature. By using #doctest: +NORMALIZE_WHITESPACE, we are able to ask doctest to ease this restriction. There are still constraints. For example, the first value in the expected array cannot have any whitespace in front of it. (Believe me, I tried for maximum readability!) But wrapping the array to the next line no longer breaks the test.
We also have a test case that is really meant as documentation only. It indicates a future requirement that shows how our function would handle negative binary values. By adding #doctest: +SKIP, we are able to command doctest to skip this particular instance.
Finally, we see the scenario where we discover that our code doesn't handle 0. As the algorithm gets the highest exponent by taking a logarithm, there is a math problem. We capture this edge case with a test. We then confirm that the code fails in classic test driven design (TDD) fashion. The final step would be to fix the code to handle this edge case. But we decide, in a somewhat contrived fashion, that we don't have enough time in the current sprint to fix the code. To avoid breaking our continuous integration (CI) server, we mark the test with a TO-DO statement and add #doctest: +SKIP.
Both the situations that we have marked up with #doctest: +SKIP, are cases where eventually we will want to remove the SKIP tag and have them run. There may be other situations where we will never remove SKIP. Demonstrations of code that have big fluctuations may not be readily testable without making them unreadable. For example, functions that return dictionaries are harder to test, because the order of results varies. We can bend it to pass a test, but we may lose the value of documentation to make it presentable to the reader.